
In this chapter, we address how to determine what to test, and how to test those things. We look at the how to identify the functions and attributes your app has, and what could go wrong with the app from a quality perspective. We then address how to determine when you’ve tested enough, which is always a difficult balancing act. We’ll talk about how your test approach can be used to focus on that balance, covering the important test conditions. Finally, we’ll address regression testing, an important topic with rapidly evolving mobile apps.
CHAPTER SECTIONS
Chapter 2, Test Planning and Design, contains the following six sections:
CHAPTER TERMS
The terms to remember for Chapter 2 are as follows:
• minimal essential test strategy
• operational profiles
• risk analysis
1 IDENTIFY FUNCTIONS AND ATTRIBUTES
The learning objective for Chapter 2, Section 1, is as follows:
MOB-2.1.1 (K2) Explain why use cases are a good source of testing requirements for mobile applications.
As a comment on this learning objective, let me clarify the difference between use cases and user stories. They are not the same thing, even though some people use those phrases interchangeably. Let’s review the ISTQB® definitions for each:
User story: A high-level user or business requirement commonly used in Agile software development, typically consisting of one or more sentences in the everyday or business language capturing what functionality a user needs, any non-functional criteria, and also includes acceptance criteria.
Use case: A sequence of transactions in a dialogue between an actor and a component or system with a tangible result, where an actor can be a user or anything that can exchange information with the system.
Now, it’s not obvious from those definitions, but a use case is generally larger and more detailed than a user story. A use case is how an individual, often referred to as an actor, goes through a sequence of steps with the system to accomplish some task or achieve some goal. Those steps include steps in the normal workflow as well as steps that are part of exception workflows. Exception workflows include error handling resulting from disallowed inputs or actions, but also atypical but allowed inputs or actions. The focus of the use case is not only on the goal or task, but also on the process that plays out between system and actor.
A user story typically corresponds to a few steps from a use case, either steps that are part of the normal workflow or one of the exception workflows. A use case is much closer to what is sometimes called, in Agile terminology, an epic, which is a collection of related user stories. In addition, the focus is almost entirely on the goal or task to be accomplished, not on the steps taken to get there, which is why use cases are more detailed than a single user story or an epic.
Mobile devices tend to have a lot of features, and these features are available to mobile apps to use. This leads to some fundamental differences in both structure and behavior between mobile apps and standard PC apps. If you pick up your PC and stand it on its edge for example, it typically doesn’t care that you’re doing that, nor does it even have any way of knowing that you’re doing that. So, the PC can’t communicate that action to applications running on it.
However, the very power of many mobile apps derives from the fact that they can use all these different interesting sensors in the mobile devices they run on. Although, that’s not true of all mobile apps. For example, Facebook and Twitter work much the same on a PC browser as they do on a mobile device, though the mobile apps’ integration with geolocation and the camera makes some actions much more convenient. For a number of mobile apps, especially games, exploitation of many of the sensors and other mobile device features is key to the way the app works.
Now, you probably are less concerned about mobile device feature use in general than in the specific features used by your app. As part of planning and designing your tests, you need to think about the mobile-specific features your app uses, including the sensors. You need to think about how those features and sensors affect your app and the way it behaves, in the context of the different important quality characteristics your app has. We’ll address quality characteristics and how to focus on the important ones later.
In traditional life cycles, you could sometimes rely on getting a fully defined, detailed set of requirements specifications to help you understand the app’s intended behaviour. If you’re testing a regulated device or app, as discussed earlier, that might well happen.1 However, most mobile app development proceeds in a much more lightweight, low-documentation fashion, often following or adapting Agile methods. So, expect to get either use cases or user stories, depending on the team you’re working with and their chosen life cycle.
Remember, as a tester, you have to play the hand you’re dealt. If all you get are emails from developers with subject lines like, “Descriptions of all the cool stuff I built last night,” then roll with it.
Regardless of whether you receive unstructured emails, use cases, user stories, or traditional specifications, often the focus is on the functionality. Non-functional behaviors, such as performance, reliability, usability, and portability, might be under-specified or entirely unspecified. You must recognize when there’s missing information and discover ways to pull that information from whatever sources are available for it.
Not only must you remember to get details on non-functional behavior, you also must have the ability to test non-functional behavior. Performance, reliability, and usability can be particularly challenging, so I will return to those topics in more detail later.
Table 2.1 Informal use case for navigational app
|
Use case: Set destination Normal workflow |
|
1. User enters their desired destination 2. App confirms the destination from user 3. User refines destination information, submits to app 4. App retrieves current location and relevant map, displays possible routes 5. User confirms route app is to use Exceptions |
|
• App unable to retrieve location information; fail • App unable to retrieve relevant map; fail • User does not refine destination information; timeout and exit • User does not confirm route; timeout and exit |
Table 2.1 shows an example of a use case for a navigational app. One important task in such an app is setting a desired destination, which is a necessary part of finding directions to that destination.
The normal workflow starts with the user entering a destination, such as a restaurant name. The app confirms the user’s selection, which often involves having the user select from a list of matching addresses or simply confirming the address the app found. The app then checks the current location using device sensors, retrieves the relevant map, and finds possible routes. The app comes back to the user, who selects the chosen route. This is the normal workflow, sometimes called the happy path.
Various things can happen along that path, some of which aren’t so happy. Perhaps the device can’t get the current location information. Perhaps it can’t find a relevant map. In either case, it will fail and return the appropriate error message. Perhaps the user doesn’t respond in the dialog, which would result in a timeout and exit.
To go back to a point I made earlier in this section, suppose we wanted to break this use case down into user stories. One user story within this use case might read, “As a user, I want to submit partial destination information, so that I can select my final destination.” This user story corresponds to steps one, two and three of this use case.
Returning to the topic at hand, testing, how can we use a use case like this one for testing? The usual coverage rule is to have at least one test for the normal workflow, and at least one test for each of the exceptions. It often makes sense to apply equivalence partitioning to the workflows, too. For example, we should test with a full address and at least one partial address. We should test with at least one business and at least one residence.
The process for translating use cases into test cases is described in more detail in the ISTQB®’s Advanced Test Analyst syllabus 2018, as well as my book and course that cover that syllabus.2
As a note for the exam, throughout this book I’ll use phrases like use case, decision table, equivalence partitioning, boundary value analysis, and state transition diagrams. If it’s been a long time since you took the ISTQB® Certified Tester Foundation exam, or you never took the exam, you might be rusty on these terms and the test design techniques associated with them.
If so, start by reading Chapter 4 in the ISTQB® Foundation syllabus 2018.3 Next, check to be sure that, for all the techniques discussed in Chapter 4, you can apply those techniques. It’s very likely that you will see some questions on the ASTQB Mobile Tester exam that involve applying the ISTQB® black-box test design techniques discussed in the ISTQB® Foundation syllabus 2018.
2.1 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 1 Learning objective: MOB-2.1.1 (K2) Explain why use cases are a good source of testing requirements for mobile applications
Why do use cases help you test mobile applications?
A. Use cases help developers build an application that meets the users’ needs.
B. Use cases should be used to identify how certain conditions result in certain actions.
C. Use cases help you focus on what users want to accomplish with the application.
D. Use cases should be used to create operational profiles for performance and reliability testing.
2 IDENTIFY AND ASSESS RISKS
The learning objective for Chapter 2, Section 2, is as follows:
MOB-2.2.1 (K2) Describe different approaches to risk analysis.
This learning objective relates to another technique described in the ISTQB® Certified Tester Foundation syllabus 2018, which is risk-based testing, covered in Chapter 5. You should read this section of the syllabus if you’re not familiar with it, or it’s been a long time since you went through it. In addition, if you want further information about risk-based testing, there are a number of articles, templates, videos, and recorded webinars on the RBCS website (www.rbcs-us.com) which you can access free.
Let’s start by defining a risk. We can informally define risk as a possible negative outcome. The two key elements in this definition are possibility and negativity. A risk is neither impossible nor certain. If a risk becomes an outcome, that outcome is undesirable. Risks are of different levels, as we know from real life.
For any realistic-sized system, testing cannot reduce the risk of failure in production to zero, due to the impossibility of exhaustive testing. While testing does reduce the risk of failure in production, most approaches to testing reduce risk in a suboptimal and opaque fashion.
Risk-based testing allows you to select test conditions, allocate effort for each condition, and prioritize the conditions in such a way as to maximize the amount of risk reduction obtained for any given amount of testing. Further, risk-based testing allows reporting of test results in terms of which risks have been mitigated and which risks have not.
Risk-based testing starts with a process of analyzing risk to the quality of the system. First, you work with your fellow project team members to identify what could go wrong with the system. These are the quality risks, or, to use another common name, the product risks. For a map app that gives walking or driving directions, examples would include failure to properly determine location, failure to display distance in the default units (for example, metric versus imperial), and use of a too-small font that makes street names and landmark names difficult to read. In risk-based testing, these quality risks are potential test conditions. To determine which of the risks are test conditions, you and your colleagues assess the level of each risk. Important risks will be tested. The testing effort associated with each risk depends on its level of risk. The order in which a risk is tested depends on its level of risk, too.
The easiest way to assess the level of risk is to use two factors: likelihood and impact. Likelihood has to do with the odds of a risk becoming an outcome. Impact has to do with the financial, reputational, safety, mission, and business consequences if the risk does become an outcome.
For example, people buy life insurance for premature death. As the saying goes, insurance is a bet that you want to lose. For all insurance, it’s likely that you will pay more than you ever collect, and you’re happy if that’s the case. Hopefully, premature death is unlikely, unless you engage in highly self-destructive lifestyle behaviors. (In that case, the life insurance companies won’t insure you.) So, premature death has a low likelihood. However, the impact can be very high. For example, suppose you are a primary breadwinner for your family, you have three kids, all under 18, and you die. Unless you have life insurance—or you had the good sense to be born with inherited wealth—that will be a devastating event for your family.
It can work the other way, too. For example, in many places in the world, going outside in the summer involves the risk of sunburn. The likelihood is very high. Usually—barring unusual disease outbreaks—the impact is very low. So, this is a risk managed through clothing and sunscreen, rather than insurance.
Testing software prior to release reduces the likelihood of undetected, serious bugs escaping into production; that is, it reduces risk to overall system quality. Anything that could go wrong and reduce product quality, that’s a quality risk.
When thinking of quality risks, think broadly. Consider all features and attributes that can affect customer, user, and stakeholder satisfaction. Consider the project team, the IT organization, and the entire company. Quality, to use J.M. Juran’s definition, is fitness for use, which is the presence of attributes that satisfy stakeholders and the absence of attributes that would dissatisfy them.4
Another useful definition of quality, from Phil Crosby, is conformance to requirements, which is software that behaves the way use cases, user stories, design documents, public claims of capability (for example, on websites and sales materials), and other such documents describe.5
Bugs can cause the software to fail to meet requirements or to exhibit other dissatisfying behaviors. Bugs can affect functional or non-functional behaviors. When you’re doing risk analysis, don’t just think about functional quality risks. Think about non-functional quality risks as well.
In addition to quality risks, there is another kind of risk, called project risks. Project risks are bad things that could happen that would affect your ability to carry out the project successfully.
Here are some examples of quality risks:
• app soft keyboard input appears very slowly in field during login;
• app cannot find a location when using network (rather than GPS) for location information;
• app crashes if Wi-Fi or cellular data connectivity is lost during account creation.
Here are some examples of project risks:
• key project participant quits prior to the end of the project;
• equipment needed for testing not delivered in time;
• project sponsors cancel project funding during project.
Risk-based testing is primarily about mitigating quality risks through testing prior to release. However, proper management of testing requires management of test-related project risks too.
Examples of mobile app quality risks in different categories
Mobile apps can be affected by a variety of quality risks across various categories. To help spur your thinking, here are some examples, for a mobile ecommerce app:
• Functional: inaccurately calculates tax on purchases;
• Localization: does not use the proper currency;
• Reliability: app crashes on launch or during usage;
• Performance: app responds too slowly during checkout;
• Usability: customer confused by put-in-cart dialog boxes;
• Portability: app works incorrectly on Android devices;
• Physical: app cannot use location information to determine proper locale;
• Error handling: customer able to submit invalid purchase information.
As I mentioned, these are only examples. Your app’s specific risks will vary, and may include risks in other categories as well as the ones listed above.
How to identify and assess quality risks
As I said before, you must consider functional and non-functional risks. You also need to consider physical aspects, the ways in which the mobile app interacts with the physical world via the device’s sensors.
One of the mistakes testers sometimes make when they start doing risk-based testing is to sit down alone and say, “Right, I’ll just take all the requirements, and then ask myself, for each requirement, what could go wrong. Voila! Those are the risks.” While it is true that those are some of the risks, those are not all of the risks. Why? Because the requirements are imperfect and incomplete, and your personal understanding of the project and product is also imperfect and incomplete.
You can address this by including business and technical stakeholders in the risk identification and assessment process. This is harnessing the wisdom of the crowd to reach a better decision than any one person, no matter how smart, could. The inclusion of a wide range of stakeholders is another reason why you need to use a lightweight, quality risk analysis process. Busy stakeholders will not participate in a process seen as a high-overhead, low-value process encumbrance.
While we’ll return to the topic of non-functional quality attributes in the next chapter, right now let’s focus on the intersection of physical and functional attributes, and thus the quality risks present at those intersections.
On the functional side, there’s what the software can do, its features, the problems it can solve, the entertainment it can provide, what the display looks like, and so forth. It might have audio elements to it, such as the ability to play music or take voice instructions. It might have visual elements, from simple visual cues to the ability to stream videos. There can be tactile elements, both in terms of you providing input via the touchscreen and the app providing output by vibrating.
These functional elements can be cross-referenced with the physical elements that interact with them. You can put together a matrix showing intersections between functional elements and the physical elements, for example, different buttons, icons, and graphics that produce and are produced by certain features, the way that the battery and power management change the way the functionality behaves, the way the app uses rotational sensors, accelerometers, location information, and cameras, and any other sort of physical sensor the device has. Notice that these physical elements are not functions on their own, but they are used by the functions, and many of the functions won’t work without them. Therefore, using a matrix to identify these physical/functional interactions can help you see risks.
When you assess likelihood and impact of a risk, if you have an app that’s already out in production, you should look at production metrics. While I can’t give you an exhaustive list of metrics, here are some ideas:
• How many times has your app been downloaded? This applies to a native app. With a mobile website, you might look at the number of registered users.
• What is the number of downloads versus active application users? Obviously, if you have a relatively high number of downloads, but a low number of application users, that could indicate problems that are leading to a low active user rate.
• You can look at new users versus lost users, with the lost users being the difference between the total downloads and the active application users. You want the new user numbers to be high relative to the lost users, and the lost user numbers to be as low as possible.
• Frequency of use is another metric to consider. How often people do certain kinds of things is important to keep in mind. Obviously, the screens and features that are more frequently used have higher risk from an impact point of view. If they’re broken, then that creates more problems for people.
• Consider depth of visit and duration. How much time do people spend on the app, and what do they do? What kind of screens do they visit? This depends on your app, too. For example, with Yelp, if Yelp is doing its job right, you should be able to get in and out of that app quickly. In a matter of a minute or maybe less, you should be able to find the restaurant that you want, or the nightclub that you want. So, it might indicate a problem if Yelp had a very high depth of visit numbers versus Facebook, for example. Facebook wants you to buy stuff from their advertisers, so, to expose you to lots of ads, they want you to stick around. They want long duration and deep depth of visit.
• If you have a high bounce rate—the “I tried it once, and I’ve never used it again” number—there’s clearly something wrong with your app. What is wrong isn’t necessarily obvious. Is it reliability, is it performance, is it usability, or is it absence of functionality? Clearly, something is wrong, because a high bounce rate means people hate your app.
So, these are some metrics to consider. There are also metrics discussed in the ISTQB® Certified Tester Foundation syllabus 2018, the ISTQB® Agile Tester syllabus 2014,6 and the ISTQB® Certified Advanced Test Manager syllabus 20127 with respect to risk analysis that are worth taking a look at.
The process of risk-based testing
Let’s summarize the risk-based software testing process. We analyze the quality risks, identifying the risks, and then assess their level based on likelihood and impact. Based on the level of risk, we will determine what to test, how much, and in what order. By doing so, we will minimize the residual level of risk for the system as a whole.
In the case of mobile app testing, the process must involve very lightweight techniques, because of the time pressures involved and the iterative life cycles often used. In addition, the risk analysis process should feed into the estimation process, since risk analysis determines the overall effort needed for testing. Likewise, the estimation techniques also need to be lightweight, again due to time and life cycle constraints.
Interconnecting risk analysis and estimation provides a clean way for the project team to collectively determine what to test, how much, and in what order. With that done, you can design and create a set of tests that cover the identified risks. The coverage for each risk is based on the level of risk. You then run those tests in a sequence based on the level of risk, too.
The life cycle influences the way risk-based testing works. In a sequential life cycle, quality risk analysis occurs at the beginning of the project and everything follows from that for the next three months, six months, or even a year. However, for most mobile app development, you won’t have a one-year-long development effort. For example, if you are using Agile or some similar process, quality risk analysis happens at the beginning of each iteration, as part of the iteration planning process.
Based on your risk analysis, the higher the risk, the more you test and the earlier you test. The lower the risk, the less you test and the later you test. The sequencing of the tests is clear, as you simply group the tests by the level of risk associated with the risks they cover, then run them in order of the level of risk. (I’m simplifying a bit here, since the arrival of new features in an iteration creates regression risk for features already tested, and some attention must be paid to the regression risks. We’ll return to this topic later.)
Next, we have to consider, on a certain level of risk, what that means in terms of the number of tests to create. Unfortunately, the mapping of level-of-risk to level-of-test-effort isn’t a simple calculation. Fortunately, I have an article on my website about selection of test design techniques based on the level of risk. It’s called “Matching Test Techniques to the Extent of Testing.” It’s only four pages long, and will give you some insights for effort allocation.8
Now, I said that prioritization of testing based on risk is clear, and that’s true. It’s very easy to determine the theoretical order in which you’ll run the tests. However, you can’t test software until you receive it, so risk-based test prioritization often requires risk-based development prioritization. This is true because most of the time you’ll work in an iterative or incremental type of life cycle. Features are delivered to you for testing as they are completed. If features are built out of risk order, you can’t run your tests in risk order.
You may be familiar with the phrase forcing function with respect to usability. It refers to the way an app guides someone toward the right way to use it. You’ve encountered the forcing function if you ever think, as you’re using an app, “Yes, it’s just so obvious. In order to access that feature, you do this, then you do this, then you do this.” You might not even notice when the app is easy to use, just like a fish probably doesn’t notice the water as long as it’s in it.
However, like a fish out of water, you’re quite likely to notice the absence of the forcing function, because the absence will be experienced as frustration. You know those feelings, I’m sure. The “what is it doing?” and “what am I supposed to do next here?” feelings.
You can think of risk as a forcing function. Risk should guide you in your decisions about what to test, in what order, and how much. If you are doing safety critical or mission critical applications, you might use a formal risk analysis technique such as Failure Mode and Effect Analysis, which involves identifying not only risks, but the potential causes of those risks and how those risks would affect stakeholders. However, it’s more likely you’ll use a lightweight technique, such as Pragmatic Risk Analysis and Management (PRAM), a technique I’ve been using for 20-plus years, which is what is described here. Such lightweight techniques don’t create a lot of documentation. You can capture their outputs on a spreadsheet or even a paper-based task-board.9
Structuring the quality risk analysis
Figure 2.1 shows a template that you can use to capture your risk analysis information, if you use the PRAM technique. You can find a list of general-quality risk categories in Table 2.2. You should use that list as the starting point for your risk identification process, working through it with your stakeholders. As you work through the checklist, you will populate the left column of the template. Remember that not all quality risk categories will apply to your app. Review them, select the categories that do, and then, in each risk category, identify the specific risks.
Once you have identified the risks, you can populate the likelihood and the impact columns as you assess the level of risk for each risk item. I use a five-point scale for likelihood and impact. The scales run from very high to very low for both likelihood and impact.
For likelihood, usually, interpreting the scale is relatively straightforward. How likely is it that we would have bugs related to this risk item in our product? How often have we seen similar bugs in the past?10
In terms of impact, though, distinguishing very high impact, from high impact, from medium impact, from low impact, from very low impact, that varies quite a bit from company to company, and app to app. So, when you first start using risk-based testing, work with your stakeholders to create well-defined criteria for those different impact levels to make sure that everybody is speaking the same language.
Figure 2.1 A quality risk analysis template
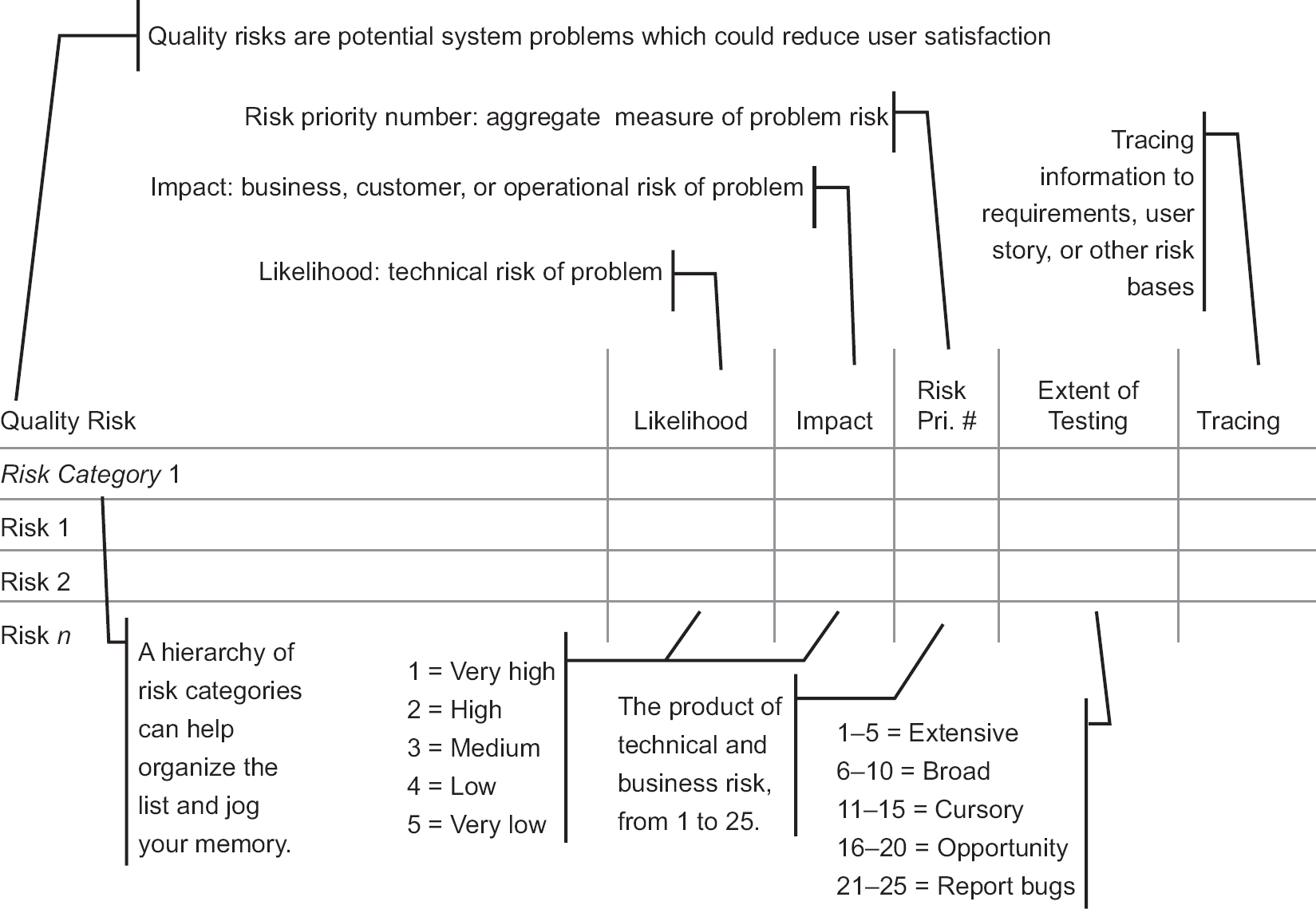
Table 2.2 Quality risk categories
|
Quality risk category |
What kind of problems fit into this category |
|
Competitive inferiority |
Failures to match competing systems in quality. |
|
Data quality |
Failures in processing, storing, or retrieving data. |
|
Date and time handling |
Failures in date-based and/or time-based inputs/outputs, calculations, and event handling. |
|
Disaster handling and recovery |
Failure to degrade gracefully in the face of catastrophic incidents and/or failure to recover properly from such incidents. |
|
Documentation |
Failures in operating instructions for users or system administrators. |
|
Error handling and recovery |
Failures due to foreseeable mistakes such as user input errors. |
|
Functionality |
Failures that cause specific features not to work, either in terms of giving the wrong answer or not solving the problem. |
|
Installation, setup, upgrade, and migration |
Failures that prevent or impede deploying the system, migrating data to new versions, including unwanted side effects (for example, installing of additional, unwelcome, unintended software such as spyware, malware, etc.). |
|
Interoperability |
Failures that occur when major components, subsystems, or related systems interact. |
|
Load, capacity, and volume |
Failures in scaling of system to expected peak concurrent usage levels. |
|
Localization |
Failures in specific localities, including languages, messages, taxes and finances, operational issues, and time zones. |
|
Networked and distributed |
Failure to handle networked/distributed operation, including latency, delays, lost packet/connectivity, and unavailable resources. |
|
Operations and maintenance |
Failures that endanger continuing operation, including backup/restore processes. |
|
Packaging/fulfillment |
Failures associated with the packaging and/or delivery of the system or product. |
|
Performance |
Failures to perform (i.e. response time, throughput, and/or resource utilization) as required under expected loads. |
|
Portability, configuration, and compatibility |
Failures specific to different supported platforms, supported configurations, configuration problems, and/or cohabitation with other software/systems. |
|
Failures to meet reasonable expectations of availability, mean time between failure, and recovery from foreseeable adverse events. |
|
|
Security/privacy |
Failures to protect the system and secured data from fraudulent or malicious misuse, problems with availability, violations of relevant security or privacy regulations, and similar issues. |
|
Standards compliance |
Failure to conform to mandatory standards, company standards, and/or applicable voluntary standards. |
|
States and transactions |
Failure to properly respond to sequences of events or to particular transactions. |
|
User interface and usability |
Failures in human factors, especially at the user interface. |
By the way, notice I use a descending scale, so as the numbers go up, the level of risk goes down. If you don’t like that, you can flip these around and have five be very high, and one be very low. Either way, you have numbers ranging from one to five in the Likelihood column and in the Impact column.
So, now you’ve assessed likelihood and impact, each rated on a five-point scale from one to five. Using a formula in this spreadsheet, in the Risk Priority Number column, you can simply multiply likelihood and impact. That calculation gives you an aggregate measure of risk. I call that the risk priority number.
So, assuming a descending scale, consider a risk with a risk priority of number one. Here’s a risk that is very likely to happen. In addition, it’s a risk with a very high impact. In other words, this risk is associated with a failure that could potentially pose an existential crisis to the company if it occurs in production.
Compare that to a risk with a risk priority number of 25. It’s very unlikely to happen and has a very low impact. In other words, very few people would be affected by it, and even those people wouldn’t care much.
At this point, it becomes clear how risk can guide our testing. Something with a risk priority number of 1, super scary and almost certain to happen, well, we better test the hell out of that, because, if we miss serious bugs in that area, we’re in big trouble later. Something with a risk priority number of 25, utterly trivial and almost certain not to happen, well, maybe we get around to testing that, maybe not.
There are also a couple of other extremes possible, related to risks that are very likely but with very low potential impact and risks that are very unlikely but with very high potential impact. You’ll need to consider carefully how to deal with such situations, especially with safety-critical or mission-critical systems where very high impact can mean death or the loss of millions of dollars.
Given the risk priority number, we can use that number to sequence tests. Tests that cover a risk with a risk priority number closer to 1 get run earlier. Tests that cover a risk with a risk priority number closer to 25 get run later—if at all. Remember, the risk priority number is heuristic, and the level of risk can change, so be flexible in the use of this rule of thumb.
So that’s test prioritization, but how about allocation of test effort? As you can see, I’ve given the extent of testing based on ranges of risk priority number. There are five levels of test effort allocation: extensive, broad, cursory, opportunity, and report bugs only. (These correspond to the levels of effort described in the article I mentioned earlier, “Matching Test Techniques to the Extent of Testing”, available on the RBCS website.)
The particular size of the ranges associated with each level of test effort allocation can vary, so consider what’s shown here only an example. In this example, if the risk priority number for a particular risk is anywhere from 1 to 5, there will be extensive testing on that risk. If the risk priority number is 6 to 10, there will be broad testing. If the risk priority number is 11 to 15, there will be cursory testing. If the risk priority number is 16 to 20, you look for opportunities to test that risk as part of something else, but it doesn’t get its own tests. And if the risk priority number is 21 to 25, there will be little to no testing, but you will report bugs related to this risk if you see them.
Finally, at the rightmost side of the template is the Tracing column. If your risks are based on user stories, use cases, requirements, and so forth, then you capture that traceability information here. Now, you might say, “Wait a minute, I think you just contradicted yourself, Rex, because you said earlier that you just look at requirements when you’re analyzing risks. You talk to stakeholders, too.”
Yes, that is true. You start off by talking to people. You interview business and technical stakeholders to identify the risks, and assess their level of risk. Once you’ve done that, you go through the use cases, the user stories, what have you, and establish the relationship between the requirements that you have—in whatever form—and the risks that you’ve identified. If you come across a requirement that doesn’t relate to any identified risk, you should add risks for that requirement because you’re missing risks.
It’s also possible that you will have risks that don’t relate to a specific requirement. You might say that’s a problem with the requirements. And you might be right about that. And maybe that’s a problem that needs to be fixed. But it’s outside the scope of testing. So, I’d suggest that, if you find risks that don’t relate to any specific requirement, you report those risks to the people who own the requirements—say, the product owner in a Scrum life cycle—and let them solve the problem.
2.2 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 2 Learning objective: MOB-2.2.1 (K2) Describe different approaches to risk analysis
Assume that you have been asked to determine the testing needed for a brand-new mobile application. It will run on Apple and Android phones and tablets, and will allow users to purchase movie tickets online, including reserving seats and ordering food in advance. Because complex graphics are used during seat selection, speed of connection is important. Because transactions must be atomic—that is, either seats are reserved and paid for or no seat is reserved and no charge is made—reliability and performance matter.
What would be a good first step towards a risk analysis for this application?
A. Consider production metrics related to usability and performance.
B. Schedule a risk-identification brainstorming session with other project participants.
C. Assess the likelihood and impact of each risk using a four-point scale from critical to low.
D. Identify examples of risks based on physical, functional, and non-functional aspects.
3 DETERMINE COVERAGE GOALS
The learning objective for Chapter 2, Section 3, is as follows:
MOB-2.3.1 (K2) Explain how coverage goals will influence the level and type of testing to be conducted.
So, you’ve done your risk analysis, and you know the risks and their associated level of risk. Now you need to think of what I refer to as dimensions of coverage. These are the different things you need to cover in your tests and how deeply you will need to cover them.
Once again, project and product stakeholders need to be part of this process, determining what to test. Collectively, we must determine coverage goals so that we can all say, “Yes, this is what we need to test and this is how much we need to test it.” It must be a collective decision, because there’s usually a balance to be struck between, on the one hand, “are we covering enough to reduce the level of risk to an acceptable level?”, versus, on the other hand, “can we actually get all this testing done?”
Reaching that decision is likely somewhat iterative. What you first suggest from a coverage point of view and what you ultimately arrive at are not the same thing. As test professionals, we tend to want more testing, while product people, marketing people and sales people, well, they often want to have their cake and eat it too, which means pressure to finish quicker.
Determining the relevant dimensions of mobile test coverage
What do I mean by dimensions of coverage? Well, the obvious dimensions of coverage are things like requirements, user stories, and use cases. This is often where people stop. They say, “I tested the requirements, I tested the use cases, I tested the user stories. What else is there?” Well, remember, requirements are always incomplete and imperfect. So, certainly, you must do verification of whatever requirements you’ve received. And, when you do that, you need traceability between your tests and the requirements they cover, so that, when the requirements change, you can make some educated guesses about what to do from a regression testing point of view, as well as figuring out what tests to update.
The quality risks that you identified in Section 2 are another dimension of testing. As I mentioned in that section, you should have traceability between your tests and your risks. So again, you might need to make some updates to your tests, and you might need to do some more regression testing based on that.
Major functional areas are another important dimension. It’s possible that this dimension is already handled by the requirements and risks, but you should check for complete coverage.
Now, I would hope that your developers are using automated unit testing, included in some sort of continuous integration framework. If so, they should be looking at code coverage. In my opinion, they should achieve 100 percent branch coverage, also called decision coverage, in their code. If they’re not, there are important paths in the code that are not being tested, and that’s an incompletely covered dimension of testing.
You should also look at bug taxonomies. There are various bug taxonomies that you can find on the internet to give you some ideas. Bug taxonomies are basically classifications of bugs that you have seen in the past. There’s always a chance one of those bugs could come back and bite you again.11
Similarly, consider technical debt. These are areas of the product that you know have weaknesses. Test those weaknesses.
Consider the different supported devices for the product. We’ll come back to this again later, but at the very least you want to cover the equivalence partitions discussed in the previous chapter, and possibly even pairwise testing if you’re worried about combinational issues.
Since we’re talking about mobile apps, you must consider different forms of connectivity. Again, we’ll come back to this later, but think about how your app communicates. It’s probably not just through Wi-Fi. There might be cellular; there might be Bluetooth; there might be other forms of communication.
Geography can be another dimension. If your app will be used internationally, there are different types of connectivity in different countries, and your GPS information will be different.
Your users are also a dimension of coverage. Have you identified all your different groups of users? Have you identified their capabilities? Do you know what they’re likely to know, and not to know? What are the personas that they have? Are they patient? Are they impatient? How do they interact with software? What operational profiles—that is, the mixes of transactions and users that will be active at any given moment—are likely to affect your servers?
These are just some dimensions. Not all of these will necessarily apply, and there might be others that will apply that aren’t listed here, so you need to consider them. The more dimensions that are applicable, the more breadth of testing is required. The higher the risk in any of these areas, the more in depth you need to go. As the depth and the breadth of testing expand, the testing effort increases, the number of necessary test environments increases, and the duration increases. So, we’re back to negotiating a balance with your stakeholders.
For example, consider how coverage goals can vary across two apps. Suppose I’ve got an app developed for use in businesses engaged in senior care, assisted living, and so forth. The app will be used by the senior person. It manages their medical stats; for example, having the user take their blood pressure readings and enter them daily. It reminds them of medications and doctor’s appointments. It tracks their exercise and what they ate. All this personal information gets stored on a central server for various kinds of data analytics.
Contrast that against an informational app that has no storage of any sort of data related to people on a central server. The informational app allows you to subscribe to various kinds of newsfeeds from different news providing web services.
Obviously, your relevant test dimensions for these two apps are very different. What are the different types of testing that need to be performed and how much? For example, is security an issue for the informational app? Not really. However, security is a huge issue for the personal health app. For one thing, there’s a regulatory consideration for that app with respect to the Health Insurance Portability and Accountability Act in the United States and similar rules about personal medical information in the UK.
Similarly, usability considerations are very different. Seniors might have various kinds of limitations on what they can do with their hands. You can’t use small buttons and checkboxes and so forth, and, while the features could be complicated, the user interface can’t be.
The risks are quite different. There’s a fairly simple set of risks for the informational app. There’s a more complex set of risks for the personal health app, and the risks are a lot higher. Suppose the health app loses track of somebody’s medications and stops reminding that person to take their blood pressure medication. Bam! They have a stroke.
For each app, we need to consider who’s using it, and when are they using it. The whole operational profile mix is different. The profile will be very cyclical with the health app versus event driven for the informational app.
So, the testing necessary is very, very different for these two apps. It’s definitely not one size fits all.
2.3 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 3 Learning objective: MOB-2.3.1 (K2) Explain how coverage goals will influence the level and type of testing to be conducted
Assume that you have been asked to determine the testing needed for a brand-new mobile application. It will run on Apple and Android phones and tablets, and will allow users to purchase movie tickets online, including reserving seats and ordering food in advance. Because complex graphics are used during seat selection, speed of connection is important. Because transactions must be atomic—that is, either seats are reserved and paid for or no seat is reserved and no charge is made—reliability and performance matter.
Information related to which of the following coverage goals is mentioned in this scenario?
A. connectivity;
B. risks;
C. code;
D. no coverage-related information is mentioned.
Question 4 Learning objective: term understanding (K1)
What is an operational profile?
A. The representation of a distinct set of tasks performed by the component or system, possibly based on user behavior when interacting with the component or system, and their probabilities of occurrence.
B. Hardware and software products installed at users’ or customers’ sites where the component or system under test will be used. The software may include operating systems, database management systems, and other applications.
C. Testing conducted to evaluate a component or system in its operational environment.
D. A black-box test design technique where test cases are selected, possibly using a pseudo-random generation algorithm, to test non-functional attributes such as reliability and performance.
4 DETERMINE TEST APPROACH
The learning objective for Chapter 2, Section 4, is recall of syllabus content only.
So far in this chapter, we have discussed determining what the app does, using that information to identify and assess the risks that exist for the app, and in turn using that information, together with other sources of information, to identify what we wish to cover – our coverage goals. As the saying goes, though, if wishes were fishes none of us would starve.
To put our coverage goals into action, you need a strategy, and further you need a specific way to implement your strategy for the current project. The ISTQB® term for the implementation of a test strategy is test approach, so that’s the term I’ll use here. If you are unclear about test strategies, test approaches and test plans, you should pause reading this book and review Chapter 5 of the ISTQB® Foundation syllabus before continuing with this section.
Assuming you are up to speed on test approaches, let’s discuss what you need to cover in a mobile app test approach. Environments are a main consideration, of course. You need to determine the different devices needed for testing and where you will get them. We’ll return to this topic in detail later in this book, when we discuss the factors that influence choices of purchased devices, rented devices, cloud devices, simulators, and emulators. Environments includes peripherals, too, if your app supports them; items such as Bluetooth keyboards, flat-screen televisions (for HDMI connections or IR control), and so forth.
You need to take into account your users and other people issues. For your users, consider their personas, abilities, and disabilities. For example, remember the hypothetical senior health app I discussed earlier. Older people tend to have eyesight limitations and mobility limitations, and may have much less exposure to technology. How will your testing take that into account?
Another approach consideration is what’s sometimes called the application domain or alternatively the industry context. This includes the business problem solved by the app and what considerations exist there. For example, if you are testing a banking app, security is huge. So, you have to consider how you will test things like authentication, susceptibility to man-in-the-middle attacks, and many other security concerns. It might be that you don’t have the expertise to do security testing, so you might need to engage a security testing expert.
You should also consider the issue of what is in scope and out of scope as part of your approach. For example, in some organizations, different teams handle security and usability. In that case, these two areas of testing should be explicitly out of scope in your test approach.
As I’ve mentioned before, it’s likely that we’ll need to achieve a balance between what we’d like to test and what we actually can test, given the constraints of schedule and budget. Your test approach should address that.
The test approach should identify the test oracles. A test oracle is something that you can consult to determine the expected result of a test. Certainly, the oracles include the requirements, but, as I said earlier, most requirements are incomplete and imperfect. So, other oracles include previous releases of your app, competitors’ apps, industry standards, and common user expectations related to performance, reliability, and usability.
The test approach should include exit criteria or, in Agile organizations, definitions of done. What would constitute “ready for delivery” in terms of the app? What constitutes “done” in terms of testing, completeness of the testing work? It’s a common practice for testing to end once you’ve run out of time, provided no one is aware of any show stoppers, but that’s pretty weak. Such an exit criterion should only be used for apps where quality doesn’t matter, and, in that case, why is your organization bothering to test it at all?
The test approach should also discuss the type of test methods and tools you’ll use and the different quality characteristics you are concerned with. We will return to these topics in Chapters 3 and 4.
Another part of your test approach relates to test documentation. How detailed will your test plan be, and why? For example, in a fast-paced life cycle, you probably won’t have time to write a 30-page test plan, but what does need to be documented? Are there regulations that affect your documentation, such as those that apply to regulated medical, avionics, or other safety-critical apps? Are you working with a distributed test team and do you need to communicate across time zones?
2.4 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 5 Learning objective: recall of syllabus content only (K1)
In which of the following ways do risks to application quality affect the test approach?
A. prioritization of testing;
B. evaluation of pass/fail status of a test;
C. contingency planning for staff turnover;
D. accessibility testing.
5 IDENTIFY TEST CONDITIONS AND SET SCOPE
The learning objective for Chapter 2, Section 5, is as follows:
MOB-2.5.1 (K2) Describe how test analysts should take the device and application into consideration when creating test conditions.
With our coverage goals set and the test approach, and our means to achieve those goals defined, we are ready to get specific about the test conditions. Test conditions is another ISTQB® phrase, which, simply put, means what to test, or the list of stuff you will cover with your tests. The ISTQB® distinguishes between test conditions—what to test—and test cases—which are how to test.
Test analysis is the process that identifies the test conditions, and it comprises many of the activities we’ve been discussing so far. Test design is the process that elaborates test conditions into test cases, at some appropriate level of detail. Whatever that level of detail is, and however test conditions and test cases will be documented, you should explain this in your test approach, so people have clear expectations about the test documentation.
An example of a test condition might be (if you are testing an ecommerce application), test successful purchases with all supported credit cards. It says what to test, but it doesn’t say how to test it. That said, a clever and experienced tester might very well be able to figure out, based on such test conditions alone, how to do the testing. Well, if that’s true, you and your colleagues are clever and experienced. You don’t need any further guidance to tell you how to test those conditions.
Further, suppose there is no regulatory requirement for you to document the tests in any more detail. In that case, you might decide not to document test cases, but rather just the test conditions. Obviously, there’s a significant skills consideration here. Do you and your fellow testers have the competence to design test cases on the fly, while executing the tests, without anything documented beyond the test conditions? Or will you—or maybe some of the other testers—need more detail, in the form of logical test cases or even concrete test cases?
Whatever level of documentation your test cases will have—none, some, a lot—you need to map your risk analysis to your test conditions, so that you have clear guidance regarding how much time to spend creating and executing the test cases. Remember, in the section on risk analysis, I mentioned my article, “Matching Test Techniques to the Extent of Testing,” which explains which techniques to use based on the level of risk. This is the point where that guidance becomes important, because, without clear guidance, you will over-test some conditions and under-test others.
Now, it might be that you and your fellow testers don’t need detailed test cases in advance, but you do want to be specific about your test conditions. This can be especially useful if you want to capture details of your test cases as you run them. To return to our example, instead of a test condition that simply says, complete a purchase with each supported credit card, you might have four specific test conditions:
• complete a purchase with American Express®;
• complete a purchase with Discover;
• complete a purchase with Visa;
• complete a purchase with MasterCard®.
I have four test conditions, one for each supported card. It’s clear what the supported cards are, so we won’t miss any. Further, when I run the tests, if any one test fails, I know specifically which credit card is not working. I can also use a simple text capture tool, or a more sophisticated tool such as Rapid Reporter, to capture the specific steps, the specific inputs, and the specific results.12
Some of my clients who use such tools then load the post hoc test cases into a test management tool and establish traceability, thus having the benefits of a fully documented set of tests. The downside of this post hoc approach to documenting tests is that you’re taking time away from test execution to document the tests. That could reduce the overall extent of testing that you can do, so consider the tradeoff.
In some cases, assuming you do document them, you might be better off writing the test cases before you start test execution. I’ve had testers in certain Agile teams tell me, “The first half of the sprint is pretty slow for us. The developers tend to create these large user stories. They don’t have anything for us to test until halfway through the sprint, but then we’re hellishly busy, because all the content of the sprint starts raining down on us for the rest of the sprint.” If this is your life, and you need to have documented test cases, you might want to spend time documenting the test cases early in the sprint rather than documenting the test cases as they’re being run.
Remember that, in risk-based testing, you want to run your tests in risk order, so that you find the scary bugs early. So, whether you run directly from test conditions or use test cases, you’ll need them prioritized based on risk. When you start test execution, you want to start with the most important tests.
It might be that you get to a point where you run out of time. In risk-based testing, the test conditions you haven’t covered should be relatively low risk, compared to the ones you did cover. This is not an ideal situation, though. It’s better if you look at ways to cover your lower-risk test conditions opportunistically, as part of testing other test conditions. To use a trivial example, if authenticating user names and passwords is considered low risk, that’s obviously something that we can easily test as part of testing something else.
Even if the test cases aren’t documented, the test conditions should be documented, at the appropriate level of detail, so that they can be reviewed by your business and technical stakeholders. It is also important that, when you capture those test conditions in your test management tool, whatever it is, you capture traceability information. This way, the test conditions trace back to the various dimensions of test coverage that we talked about earlier, such as user stories, risks, supported configurations, and the like. When the test conditions can be tracked back to specific coverage items, this allows you to report your test results in terms of risk mitigation. For example, suppose you have this risk, app accepts credit card transactions that should be rejected. Suppose there are four tests associated with that risk. If all four of those tests pass, we can say that risk has been mitigated. If, instead, three out of the four tests have been run and those tests pass, but there’s one test left to be run, the risk is not fully mitigated yet, because there’s still stuff we don’t know.
Now, let’s say you’ve run all four tests and two out of the four tests have failed. Here again, the risk is not mitigated, because we have at least two known problems. That said, the risk is reduced, because those bugs can be fixed and the tests rerun. Now, if the tests pass, then that risk is fully mitigated. As you can see, when you can talk about conditions that pass and don’t pass, you can talk about risks that are mitigated and not mitigated. This makes test results fully transparent to your non-tester stakeholders.
All too often, we testers make the mistake of reporting test results as follows: “We ran 262 tests; 198 of them passed. Thirty of them failed. The rest are yet to be run. We found 96 bugs. Of those, 87 have been fixed. The remainder are still open.”
Non-testers listen to those kinds of test status reports totally mystified. They are thinking, if not saying, “What does that mean? Are we done? Are we almost done? Does the app suck or is it almost ready for users?”
However, when you start talking about risks that are not mitigated and risks that are mitigated, test conditions that work and don’t work, people get that. That allows them to make smart decisions about releases, project status, and so forth.
When you’re creating your test conditions, remember the physical stuff, remember the functional stuff, and remember the non-functional stuff. The non-functional stuff is easy to forget. The physical stuff is what makes testing a mobile app different than testing a PC application.13
As discussed before, let risk be your guide in terms of how much testing you do in these different areas. It’s very easy to get distracted by the bright shiny object, leading to people spending too much time testing things that are actually not high risk. The approach to risk analysis discussed earlier will allow you to then think about your test conditions in these physical, functional and non-functional areas, and come up with the specific test conditions you need to cover, together with the breadth and depth of coverage that is necessary for each one of those conditions.
It is important that you go through this process of analysis, carefully deciding what to test. It can be tempting to go looking for some universal list of test conditions that must be covered for mobile apps. If such a list does exist out on the vast internet, it is the brainchild of a fool. While you can use ideas from the internet to help you come up with good test conditions, it is by following proven best practices of test analysis that you’ll get the right list.
To illustrate this concept, let’s return to the senior personal health app example. Here’s an example of a physical test condition: gathering heart rate sensor information when available. If the phone has a built-in heart rate sensor, or it connects via Bluetooth to something that does heart rate sensing, the app should use that information, and this test condition says we should test that.
Here’s another example of a physical test condition: saving the location of the user when sensor data is gathered or when the user enters data. Any time sensor data, such as heart rate data, is captured or the user makes an entry, the app should use the geolocation sensor to determine where the user currently is and save that information along with the sensor or input data. This test condition says we should test that.
Here’s an example of a functional test condition: charting weight, body mass index, blood pressure, and resting heart rate over time.
Here’s an example of a non-functional test condition: encryption of the patient data using a strong key that’s unique to each user. This way, even if somebody manages to crack into one of the patient’s datasets, it doesn’t mean that the hacker would be able to get into all of them.
Now, obviously, those are not the only four test conditions for this app, but those are four in each of the three areas.
2.5 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 6 Learning objective: MOB-2.5.1 (K2) Describe how test analysts should take the device and application into consideration when creating test conditions
Which of the following is a test condition that is related to the physical capabilities of a device?
A. Enter a first and last name; click create account; verify account.
B. Check app acceptance of valid credit.
C. Verify app ability to locate nearest petrol station.
D. Verify app ability to resume downloads on reconnect.
6 REGRESSION TESTING
The learning objective for Chapter 2, Section 6, is recall of syllabus content only.
It’s a hassle, but you must consider regression tests. Stuff changes. Firmware changes, often without any notice. Devices change, though at least you’ll have a way to know when they do. Interoperating software changes, probably without any easy way to know it did without doing some research. Network providers make changes, and they probably won’t bother to warn you. Connectivity protocols can change. People can start using your app in new locations. Entirely new devices come out, or new sensors are added to existing devices.
One mobile testing course attendee mentioned a situation where their app did not change, but they had to support a new version of a browser. This required lots of regression testing. This is a potential risk of using the mobile-optimized website or hybrid app approach to going mobile, rather than a native app. If your app is accessed through a browser, you’re tied to the vendor of that browser.
That’s also true if your native app uses any other app on the device. If that app changes, it could break your app. This is compounded by the fact that there’s no implied warranty of fitness or any other sort of guarantee associated with software, as exists for most physical products. Instead, we have these ridiculous click-through agreements that basically say a vendor can change their software any time they want, and, if by so doing, they burn your house down, effectively, they have no responsibility for the consequences, even if they were negligent in their testing of their own app. This allows software companies to completely shift the external costs of failure onto their customers and end users, unless you hold them accountable through one-star reviews and the like. Until software engineering matures a lot more as a profession, expect to need to do a lot of externally triggered regression testing.
You are probably updating your app frequently, because that’s common practice with mobile apps. Even if you’re not updating your app frequently, you’re going to regression test frequently, because every single hour of every single day somebody else is changing something that could break your app. So keep track of what’s changing out there that could affect your app, and regression test accordingly.
Given the frequency of regression testing, and the number of regression tests you might need, you probably should look at some approach for automation. We will cover that later in this book. Not only do these automated regression tests require care and feeding, remember that your test environments must be kept current, too. Be careful that your simulators are up to date as well.
2.6 Test your knowledge
Let’s try one or more sample exam questions related to the material we’ve just covered. The answers are found in Appendix C.
Question 7 Learning objective: recall of syllabus content only (K1)
Which of the following statements is true?
A. Mobile regression tests cannot be automated.
B. Regression risk is lower for mobile applications.
C. Regression testing can be necessary even if the application doesn’t change.
D. Regression testing can be done entirely with simulators.
In this chapter, you’ve seen ways to determine what to test, and how to test those things. You considered how to identify the functions and attributes your app has, and how those functions and attributes could fail. You saw that there are strategies to help you achieve the right balancing act between testing too much and testing too little. You’ve seen how to define a test approach that focuses you on the important test conditions and keeps the testing effort within scope. Finally, you’ve considered the important topic of regression testing.
1 Though even in such environments, documentation is not perfect. As one reviewer of this book wrote, “Regulated apps [sometimes] fall short of receiving solid use cases, requirements, or even functional specs. [There can be a] lack of expected behavior and thus requirements are not fleshed out until software is developed and tested … Testers may need to provide information about limitations, boundaries and baselines.”
2 My book on the Advanced Test Analyst syllabus is Advanced Software Testing: Volume 1 (second edition, 2015 San Rafael, CA: Rocky Nook), and my company offers an Advanced Test Analyst course as well.
3 See the ISTQB® Certified Tester Foundation syllabus 2018 here: https://certifications.bcs.org/upload/pdf/swt-foundation-syllabus.pdf
4 Juran’s definition of quality can be found in his 1992 book Juran on Quality by Design: The New Steps for Planning Quality into Goods and Services (Free Press: New York).
5 You can find this definition of quality, along with a number of other useful ideas, in Phil Crosby’s 1979 book Quality Is Free (New York: McGraw-Hill).
6 See https://certifications.bcs.org/category/18255
7 See https://certifications.bcs.org/category/18219
8 You can find the article mentioned here: https://rbcs-us.com/resources/articles/matching-test-techniques-to-the-extent-of-testing/
9 You can find a good description of Pragmatic Risk Analysis and Management (PRAM) in my 2014 book Advanced Software Testing: Volume 2 (second edition, San Rafael, CA: Rocky Nook). Failure Mode and Effect Analysis is described in D.H. Stamatis’s 2003 book Failure Mode and Effect Analysis: FMEA from Theory to Execution (Milwaukee, WI: American Society for Quality Press).
10 It is important to note that likelihood does not refer to the frequency of the failure’s occurrence in actual use. Frequency of occurrence is a consideration when evaluating impact, since this is a question of defect importance.
11 The original bug taxonomy was included by Boris Beizer in 1990, in one of the fundamental and still relevant books on testing, Software Testing Techniques (New York: Van Nostrand Reinhold). I reproduced this in my own 2009 book Managing the Testing Process, Third Edition (Hoboken, NJ: John Wiley & Sons). Cem Kaner and Giri Vijayaraghavan published a detailed paper on the generation of such taxonomies in 2003 which you can find here: www.testingeducation.org/articles/bug_taxonomies_use_them_to_generate_better_tests_star_east_2003_paper.pdf
12 You can find information about Rapid Reporter at: http://testing.gershon.info/reporter/
13 You can find more information on how physical factors affect mobile apps here: https://rbcs-us.com/resources/webinars/webinar-the-more-things-change-location-the-more-they-stay-the-same-9-22-2017/