
Chapter 11 introduces Armv8-64 core programming. It begins with a section that illustrates the use of basic integer arithmetic instructions including addition, subtraction, multiplication, and division. The section that follows covers data loads and stores, shift and rotate operations, and bitwise logical manipulations. This second section is especially important since it accentuates notable differences between A32 and A64 assembly language programming.
This chapter also covers details about the semantics and syntax of an A64 assembly language source code file. You will learn the basics of passing arguments and return values between functions written in C++ and A64 assembly language. The subsequent discussions and source code examples are intended to complement the material presented in Chapter 10.
Like the introductory A32 programming chapters, the primary purpose of the source code presented in this (and the next) chapter is to elucidate proper use of the A64 instruction set and basic assembly language programming techniques. The source code that is described in later A64 programming chapters places more emphasis on efficient coding techniques. Appendix A contains additional information on how to build and run the A64 source code examples. Depending on your personal preference, you may want to set up a test system before proceeding with the discussions in this chapter.
Integer Arithmetic
In this section, you will learn the basics of A64 assembly language programming. It begins with a simple program that demonstrates how to perform integer addition and subtraction. This is followed by a source code example that illustrates integer multiplication. The final example explains integer division. Besides common arithmetic operations, the source code examples in this section also explicate passing argument and return values between a C++ and assembly language function. They also show how to use common assembler directives.
Addition and Subtraction
Example Ch11_01
The C++ code in Listing 11-1 begins with the declarations of the assembly language functions IntegerAddSubA_ and IntegerAddSubB_. These functions carry out simple integer addition and subtraction operations using int (32-bit) and long (64-bit) argument values. The "C" modifier that is used in the function declarations instructs the C++ compiler to use a C-style function name instead of a C++ decorated name (recall that a C++ decorated name contains extra prefix and suffix characters to facilitate function overloading). Also included in the C++ code is a template function named PrintResult, which streams results to cout. The C++ function main includes code that exercises the assembly language functions IntegerAddSubA_ and IntegerAddSubB_.
The A64 assembly language code for example Ch11_01 is shown in Listing 11-1 immediately after the C++ code. The first thing to notice is the // symbol. Like the GNU C++ compiler, the GNU assembler treats any text on a line that follows a // as an appended comment. Unlike A32 code, the @ symbol cannot be used for appended comments in A64 assembly language source files. A64 assembly language source code files can also use block comments using the /* and */ symbols.
The .text statement is an assembler directive that defines the start of an assembly language code section. As explained in Chapter 2, an assembler directive is a statement that instructs the assembler to perform a specific action during assembly of the source code. The next statement, .global IntegerAddSubA_, is another directive that tells the assembler to treat the function IntegerAddSubA_ as a global function. A global function can be called by functions that are defined in other source code modules. The ensuing IntegerAddSubA_: statement defines the entry point (or start address) for function IntegerAddSubA_. The text that precedes the : symbol is called a label. Besides designating function entry points, labels are also employed to define assembly language variable names and targets for branch instructions.
The assembly language function IntegerAddSubA_ calculates a + b - c and returns this value to the calling function. It begins with an add w3,w0,w1 instruction that adds the values in registers W0 (argument value a) and W1 (argument value b); the result is then saved in register W3. The use of registers W0 and W1 for argument values a and b is mandated by the GNU C++ calling convention for Armv8-64. According to this convention, the first eight integer (or pointer) arguments are passed in registers W0/X0–W7/X7. Any remaining arguments are passed via the stack. You will learn more about the GNU C++ calling convention later in this chapter and in subsequent chapters.
The next instruction in IntegerAddSubA_, sub w0,w3,w2, subtracts W2 (c) from W3 (a + b) and saves the result in register W0. This completes the calculation of a + b - c. An A64 assembly language function must use register W0 to return a single 32-bit integer (or C++ int) value to its calling function. In the current example, no additional instructions are necessary to achieve this requirement since W0 already contains the correct return value. The final instruction of IntegerAddSubA_ is a ret (return from subroutine). This instruction returns program control back to the calling function. More specifically, the ret instruction performs an unconditional branch (or jump) to the address in register X30 (or link register). Unlike Armv8-32, Armv8-64 defines an explicit instruction mnemonic for function returns. This enables the processor to make better branch predictions since it can now differentiate between a function return and an ordinary branch operation. You will learn more about branch predictions in Chapter 17.
Multiplication
Example Ch11_02
The assembly language functions IntegerMulA_, IntegerMulB_, IntegerMulC_, and IntegerMulD_ illustrate the use of various A64 multiplication instructions. In function IntegerMulA_, the mul w0,w0,w1 (multiply) instruction multiplies registers W0 (argument value a) by W1 (argument value b). It then truncates the result to 32 bits and saves this value in register W0. The mul instruction is an alias instruction. Recall that an alias instruction is a distinct mnemonic that provides a more expressive description of the operation that is being performed. In the current example, the mul w0,w0,w1 instruction is an alias of madd w0,w0,w1,wzr (multiply-add). You will learn how to use the madd instruction in Chapter 12. Alias instructions are generally unimportant when writing A64 code. However, it is something that you need to be aware of when using a debugger or viewing a listing of disassembled code.
Division
Example Ch11_03
The assembly language function CalcQuoRemA_ begins its execution with a sdiv w4,w0,w1 (signed divide) instruction. This instruction divides the value in register W0 (argument value a) by W1 (argument value b) and saves the quotient in register W4. The next instruction, str w4,[x2], saves the 32-bit signed integer quotient to the memory location pointed to by register X2 (argument value quo). The ensuing mul w5,w4,w1 and sub w6,w0,w5 instructions calculate the remainder (the sdiv instruction does not return a remainder). The final instruction of CalcQuoRemA_, str w6,[x3], saves the remainder to memory location pointed to by rem.
Integer Operations
The source code examples of this section explain how to use common integer load, store, move, shift, and bitwise logical instructions. It is important to master these instructions given their frequency of use. Like A32 assembly language programming, it is sometimes necessary to use multiple instructions or pseudo instructions when writing A64 code especially for load and move operations as you will soon see.
Load and Store Instructions
Example Ch11_04
The C++ code begins with the declarations of the assembly language functions TestLDR1_, TestLDR2_, and TestLDR3_. These functions require two integer arguments, which are used as indices to access elements in a small test array. They also return integer values of varying sizes. The C++ functions TestLDR1, TestLDR2, and TestLDR3 contain code that exercise the aforementioned assembly language functions and display results.
The assembly language code in Listing 11-4 starts with a .data directive. This directive signifies the beginning of section in memory that contains read-write data. The line that starts with the label A1: initializes an eight-element array of .word (32-bit) integers. This is followed by an eight-element array of .quad (64-bit) integers named A2. The final test array, A3, contains eight .short (16-bit) integer elements. Note that the definition of array A3 follows the .text directive, which means that it is a read-only array since the elements are allocated in a code section. Table 2-1 (see Chapter 2) summarizes the GNU assembler directives that are used to allocate storage space and initialize data values.
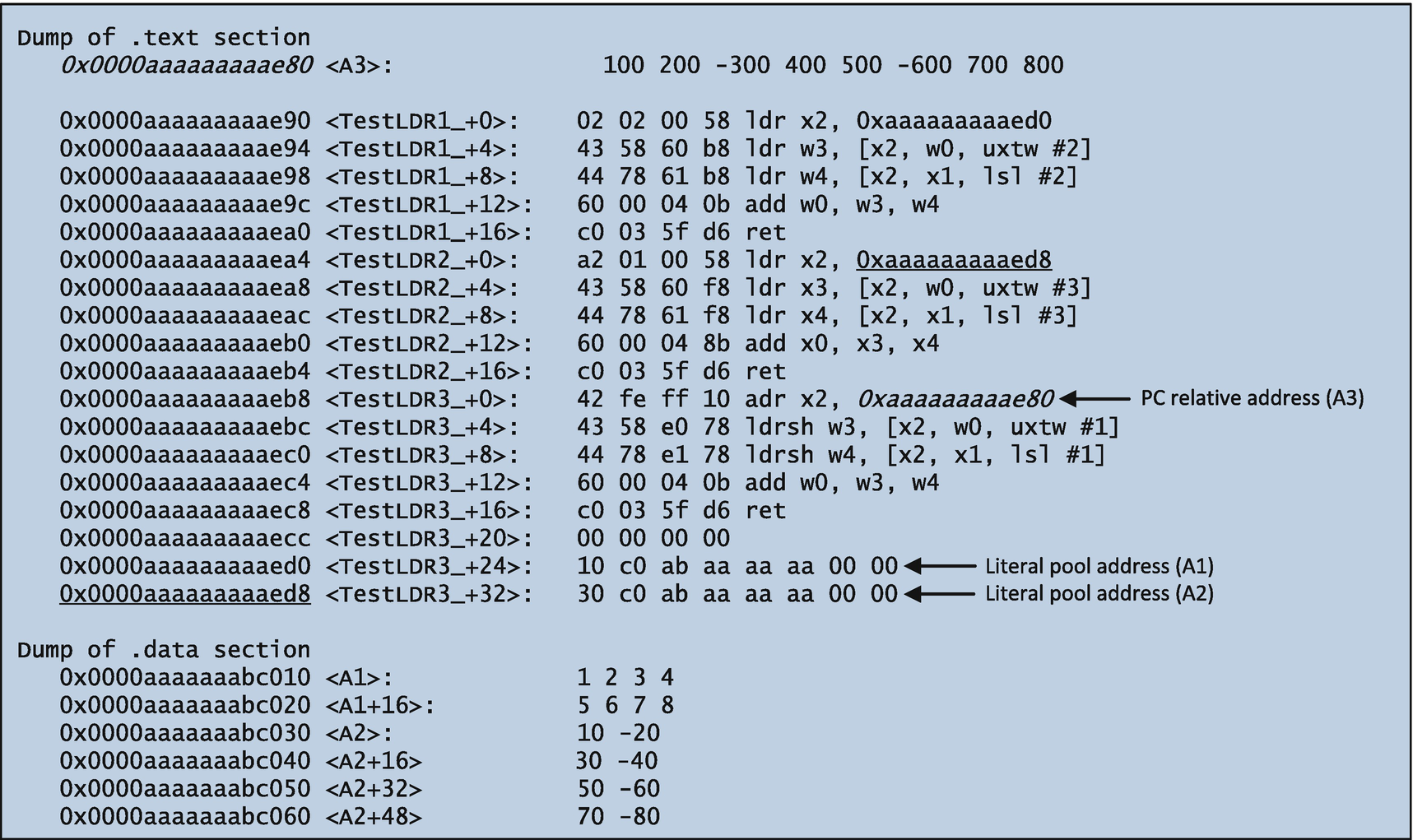
Machine code for TestLDRx_ functions
The next instruction in TestLDR1_, ldr w3,[x2,w0,uxtw 2], uses extended register memory addressing (see Chapter 10, Table 10-3) to load element A1[i] into register W3. This instruction zero-extends (as specified by the extended operator uxtw) the word value in W0 (argument value i) to 64 bits, left shifts this 64-bit intermediate result by two, and adds X2 (address of array A1) to calculate the address of element A1[i]. Extended register addressing also supports other operators including sxtb, sxth, sxtw, uxtb, and uxth (the “s” versions sign-extend the index register operand). The ensuing ldr w4,[x2,x1,lsl 2] instruction loads A1[j] into register W4. This instruction employs a lsl operator to calculate the required address since X1 (argument value j) is already a 64-bit wide integer.
Function TestLDR2_ uses a similar sequence of instructions to load elements from array A2, which contains quadword instead of word values. Note that the uxtw and lsl operators shift the array indices in registers W0 and X1 by three instead of two bits since the target array contains quadword elements.
Move Instructions
Example Ch11_05
The C++ code in Listing 11-5 is straightforward. It begins with the declarations of the assembly language functions MoveA_, MoveB_, MoveC_, and MoveD_. These functions contain code that illustrate the loading of constant values using a variety of A64 move instructions. The remaining C++ code exercises the assembly language move functions and displays results.
Assembly language function MoveA_ begins with a mov w7,1000 (move wide immediate) that loads 1000 into register W7. This instruction (and all other A64 instructions that use a W register destination operand) also sets the upper 32 bits of X0 to zero. Like its A32 counterpart, the A64 mov instruction can be used to load a subset of all possible 32-bit wide integer constants into a W register. Following the str w7,[x0] instruction is a mov w7,65536000 instruction that loads 65536000 into register W7. The mov instruction is an alias of the movz (move wide with zero) instruction. This instruction moves an optionally shifted 16-bit constant value into a register.
The ensuing movz w7,1000,lsl 16 instruction also loads 65536000 into register W7. When loading a 32-bit constant into a W register, the alias instruction mov should be employed when possible instead of a movz instruction since the former is easier to read and type. The final move instruction example in MoveA_, mov w7,-131072, loads a negative value into W7.
Function MoveB_ illustrates the use of the mov and movz instructions using 64-bit constants and X register destination operands. Note than when a movz instruction uses an X register destination operand, the lsl operator can use a shift bit count of 0 (the default), 16, 32, or 48 bits.
Just prior to the start of function MoveC_ are three .equ directives. The .equ VAL1,2000000 defines VAL1 as a symbolic name for the constant 2000000. The next two directive statements, .equ VAL1_LO16,(VAL1 & 0xffff) and .equ VAL1_HI16,((VAL1 & 0xffff0000) >> 16), define symbolic names for the low- and high-order 16 bits of VAL1, respectively. The first instruction of MoveC_, mov w7,VAL1, is commented out. If you remove the comment and build the project using make, the GNU assembler will generate an “immediate cannot be moved by a single instruction” error message. The next two instructions, mov w7,VAL1_LO16 and movk w7,VAL1_HI16,lsl 16 (move wide with keep), illustrate an instruction sequence that loads 2000000 into register W7. The mov instruction loads VAL1_LO16 into register W7. The ensuing movk instruction loads VAL1_HI into bit positions 31:16 of register W7 and leaves bits 15:0 unchanged. Function MoveC_ also contains an ldr w7,=VAL1 instruction that loads VAL1 into W7. This instruction form is easier to read but is also slower since it requires an extra memory read cycle to load VAL1 from a literal pool.
The final move function is named MoveD_. This function illustrates how to use the movk instruction to load a 64-bit constant into an X register. The .equ directives that precede the start of MoveD_ include expressions that split the constant VAL2 into four 16-bit wide values. The constant VAL3 is also split into two 16-bit wide values. Removing the comment from the mov x7,VAL2 instruction and running make will generate another GNU assembler error message. To load VAL2 into register X7, a series of mov and movk instructions is required. The first instruction of the sequence, mov x7,VAL2_00, loads VAL2_00 into register X7. The ensuing movk x7,VAL2_16,lsl 16 instruction loads VAL2_16 into bit positions 31:16 of register X7 and leaves all other bits unchanged. The movk x7,VAL2_32,lsl 32 and movk x7,VAL2_48,lsl 48 instructions load bit positions 47:32 and 63:48, respectively. When necessary, this four-instruction sequence is the recommended method for loading a 64-bit wide constant since the AArch64 execution state is optimized for this type of sequence. It is often reasonable to use a ldr x7,=VAL2 instruction for a one-time initialization since it is easier to read and type, but this approach should be avoided inside a for-loop.
Shift Instructions
Example Ch11_06
Assembly language function ShiftA_ demonstrates the use of the asr, lsl, lsr , and ror instructions using immediate operand bit counts. Following execution of these instructions, ShiftA_ uses a series of str instructions that save the result of each shift/rotate operation to array x. It should be noted that the immediate bit count forms of the asr , lsl, lsr , and ror instructions are aliases for sbmf (signed bit field move), ubfm (unsigned bit field move), ubfm, and extr (extract register), respectively. This is something to keep in mind when using a debugger.
Function ShiftB_ resembles ShiftA_ in that it employs the same shift and rotate instructions. However, ShiftB_ uses the variable bit count forms of the asr , lsl, lsr , and ror instructions. Note that the second source operand of these instructions is a register that contains the shift/rotate bit count. The variable bit count forms of asr, lsl, lsr , and ror instructions are aliases for asrv (arithmetic shift right variable), lslv (logical shift left variable), lsrv (logical shift right variable, and rorv (rotate right variable), respectively.
Bitwise Logical Operations
Example Ch11_07
The C++ code in Listing 11-7 performs straightforward test case initialization and displays results. Function BitwiseOpsA_ illustrates the use of the and (bitwise AND), orr (bitwise OR), and eor (bitwise exclusive OR) instructions using W register operands. These instructions can also be used with X register operands.
Summary
The add and sub instructions perform signed and unsigned integer addition and subtraction using 32- or 64-bit wide operands.
The mul instruction performs signed and unsigned integer multiplication; it saves the low-order 32/64 bits of the resultant 64-/128-bit product. The smull and umull instructions carry out multiplication using 32-bit signed or unsigned integers. The full 64-bit wide product is saved.
The sdiv and udiv instructions perform signed and unsigned integer division, respectively. These instructions calculate only the quotient.
Extended register addressing can be used to load elements from an array using byte, halfword, or word indices.
The movz instruction loads a 16-bit immediate constant (with optional shift) into a W or X register. The mov instruction is an alias of movz and is often used instead of movz to improve code readability.
The movk instruction loads a 16-bit immediate constant (with optional shift) into a register without altering other bits.
The and, orr , and eor instructions carry out bitwise logical AND, OR, and exclusive OR operations.
The GNU C++ calling convention for Armv8-64 uses registers X0/W0–X7/W7 to pass integer or pointer arguments to a function. A function must use register X0 or W0 to return a 64-bit or 32-bit wide integer value to its caller.