
Chapter 3: Tuxedo in Detail
There are a couple of Tuxedo's implementation details that it is useful to know when it comes to making the correct technical decisions. One of them is the BBL process present in all Tuxedo applications, and the other is the use of Unix System V IPC queues. Monitoring and sizing Tuxedo's queues is one of the most important tasks for the administrator of a Tuxedo application.
In this chapter, we will cover the following topics:
- Learning what BBL is
- Understanding queues
- Introducing services and load balancing
By the end of this chapter, you will have practical experience of how BBL contributes to application availability. You will understand the relationship between queues and services and the ways in which that can be expressed in the Tuxedo configuration and how load balancing works. You will also know how to get information about queue size and how to change it.
Technical requirements
All the code for this chapter is available at https://github.com/PacktPublishing/Modernizing-Oracle-Tuxedo-Applications-with-Python/tree/main/Chapter03.
The Code in Action video for the chapter can be found at https://bit.ly/2NrZptR.
Learning what BBL is
Before diving into a more specific topic, we should demystify the BBL process. Tuxedo uses all three System V interprocess communication mechanisms: message queues as a transport mechanism, semaphores for synchronization, and shared memory for keeping application configuration and dynamic information about the state of the application.
The shared memory region is called the Bulletin Board and the administration process that runs in each Tuxedo application is called the Bulletin Board Liaison (BBL). Because the Tuxedo application consists of many Unix processes starting, working, stopping, and sometimes crashing at different moments in time, it is important to keep the Bulletin Board up to date and ensure consistency despite misbehaving clients and servers.
Monitoring server processes and restarting them as needed is one of several tasks assigned to the BBL process. To investigate, we start with the Tuxedo application developed in the previous chapter and make a couple of adjustments to the configuration file I have highlighted:
*RESOURCES
MASTER tuxapp
MODEL SHM
IPCKEY 32769
SCANUNIT 10
SANITYSCAN 1
*MACHINES
"63986d7032b1" LMID=tuxapp
TUXCONFIG="/home/oracle/code/03/tuxconfig"
TUXDIR="/home/oracle/tuxhome/tuxedo12.2.2.0.0"
APPDIR="/home/oracle/code/03"
*GROUPS
GROUP1 LMID=tuxapp GRPNO=1
*SERVERS
"toupper.py" SRVGRP=GROUP1 SRVID=1
REPLYQ=Y MAXGEN=2 RESTART=Y GRACE=0
CLOPT="-s TOUPPER:PY"
Additional parameters in the RESOURCES section have the following meaning:
- SCANUNIT: This is the number of seconds between periodic scans executed by the BBL process, and it must be a multiple of 2 or 5. The latest versions of Tuxedo allow specification in milliseconds by adding an "MS" suffix and a number between 1 MS and 30,000 MS. We will use the default value of 10 for our examples to give us plenty of time to observe different behavior.
- SANITYSCAN: This is a multiplier for the interval between periodic sanity checks of Bulletin Board data structures and server processes. We use the value of 1, which provides a sanity check every 10 seconds (SCANUNIT * SANITYSCAN).
We can now load the configuration and start the application, as we learned in the previous chapter. To demonstrate sanity checks, we will perform the following steps:
- List all processes of the Tuxedo application. This should include BBL and python3.
- Terminate our Tuxedo server.
- Ensure that the server process is absent.
- Wait for 10 seconds for BBL to perform a sanity check and restart the server.
- Ensure that the python3 server process has been restarted by BBL.
The commands for doing this are as follows:
ps aux | grep ULOG
kill -s SIGSEGV `pidof python3`
ps aux | grep ULOG
sleep 10
ps aux | grep ULOG
It is important to remember that a process terminated with the SIGTERM signal will not be restarted by Tuxedo because it is considered a graceful shutdown. The kill command uses SIGTERM by default and we use it with the SIGSEGV signal, which is typical for memory-related errors.
There are other duties that BBL performs, and we will discover these gradually in the chapters that follow, but first, we must understand the queue mechanisms used by Tuxedo.
Understanding queues
As we learned in Chapter 1, Introduction and Installing Tuxedo, parts of Tuxedo's APIs were standardized in XATMI specifications with the hope that developing applications according to XATMI specifications would lead to vendor-neutral solutions and it would be easy to port applications from one XATMI implementation to another. This idea looks good on paper, but no specification can cover all aspects of behavior and be abstract at the same time. No surprises there.
The server provides resources that the client can access. A server can also act as a client and ask for the resources provided by another server as shown in the following diagram. The XATMI specification does not say how the request and response should be delivered between the client and server:

Figure 3.1 – Client-server model
Tuxedo uses queues for that. Servers have a request queue where they receive requests from clients. Servers and clients have a response queue where responses from servers are processed as shown in the following diagram. There is a configuration parameter (REPLYQ=N) that allows the server to use a single queue for both requests and replies, but I suggest avoiding this feature:

Figure 3.2 – Client-server model with queues
The configuration file of our first application did not mention any queues, so where do they come from?
Configuring queues
Tuxedo is implemented on top of Unix System V IPC queues and that explains some of the behavior and features Tuxedo has. For starters, a System V IPC queue API does not support timeout for enqueue and dequeue operations (unlike the newer POSIX queue API) and Tuxedo has to implement operation timeouts using other mechanisms. We will learn about this in Chapter 7, Distributed Transactions.
System V IPC queues come with three configuration parameters. To find out the current values, use the following command:
sudo sysctl -a | grep kernel.msgm
On the Docker image we created, it will display the following values:
kernel.msgmax = 8192
kernel.msgmnb = 16384
kernel.msgmni = 32000
The meaning of each cryptic parameter is as follows:
- msgmax: This is the maximum size of an individual message.
- msgmnb: This is the maximum number of bytes in a single queue.
- msgmni: This is the maximum number of queues in the system.
However, Tuxedo can work around these limits and transfer tens, if not hundreds, of megabytes of data even if the message size exceeds the queue size or the individual message size. This technique is called file transfer. Under certain conditions, instead of storing the whole message in the queue, Tuxedo will store the message in a temporary file and put a tiny message in the queue containing the filename as shown:

Figure 3.3 – Message transport
It is hard to tell how many messages fit in the queue because Tuxedo may choose between storing the whole message in the queue or the file under two conditions:
- The message size is larger than the queue size or message size limit.
- The message size is lower than the message size limit, but there is insufficient space in the queue due to messages the queue already contains.
However, file transfer comes at a price: storing a message on a physical filesystem is slower than storing it in the queue. To improve performance, you must make sure that most of the messages in your application do not exceed the message size maximum and that the queue size is big enough to contain all messages. A properly tuned system should never fill its queues. We will develop tools to monitor queues in Chapter 6, Administering the Application Using MIBs.
For example, to support messages with a size of up to 32 Kb and queues to accommodate 100 such messages, you should do the following:
sudo sysctl -w kernel.msgmax=32768
sudo sysctl -w kernel.msgmnb=3276800
Unfortunately, the whole Tuxedo application has to be restarted in order for changes to take effect and therefore it is better done ahead of time when preparing the environment for the application.
The main disadvantage of message-oriented middleware is that it requires an extra component called a message broker, which can introduce performance and reliability issues. Tuxedo is broker-less in this aspect because queues live in the OS kernel, as the following diagram demonstrates:
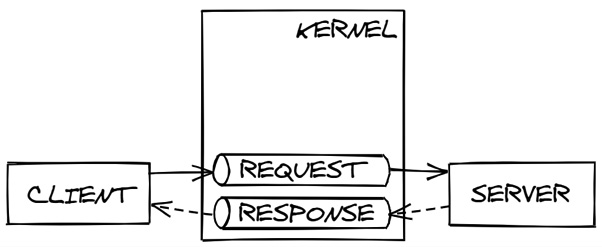
Figure 3.4 – Kernel queues
But if Tuxedo does not have a message broker, how are other message broker's tasks performed, such as routing the message to one or more destinations, load balancing, and location transparency?
Introducing services and load balancing
Unlike other messaging-oriented middlewares that operate with queues, Tuxedo operates with another abstraction level on top of that – a service. A service may be backed by one or more queues and multiple services may use the same queue. The mapping between service names and queues is stored in the Bulletin Board. The client uses this mapping information and chooses the appropriate queue and tells the kernel which queue to use for a request, as shown in the following diagram. No mapping is required for the response queue as the client tells the server exactly which queue to use for the response:

Figure 3.5 – A service
There are a couple of ways in which the service abstraction over queues can be used, so let's explore them in detail.
Exploring the MSSQ configuration
MSSQ stands for Multiple Servers Single Queue. In modern terminology, we would say that a queue has multiple consumers. Instead of each server having its request queue, multiple servers can share the same request queue. The main advantage is that any idle server can pick the next request from the queue and improve latency. The opposite of that would be a full queue for a single server struggling to complete all the requests, while other servers are idle with their request queues empty. Another advantage is that a server can crash or can be upgraded to a new version without any interruptions or downtime for the client because other servers continue processing requests.
Multiple servers wait for the request to arrive on the same request queue, and the first one that receives the message processes it and returns a response, as shown in the following diagram:
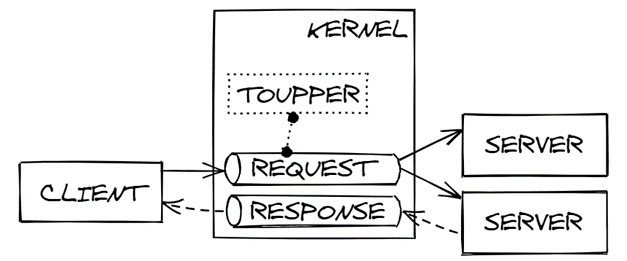
Figure 3.6 – Multiple Servers Single Queue
To see how it works, let's use the application we developed in the previous chapter and modify the configuration file:
*RESOURCES
MASTER tuxapp
MODEL SHM
IPCKEY 32769
*MACHINES
"63986d7032b1" LMID=tuxapp
TUXCONFIG="/home/oracle/code/03/tuxconfig"
TUXDIR="/home/oracle/tuxhome/tuxedo12.2.2.0.0"
APPDIR="/home/oracle/code/03"
*GROUPS
GROUP1 LMID=tuxapp GRPNO=1
*SERVERS
"toupper.py" SRVGRP=GROUP1 SRVID=1
REPLYQ=Y MAXGEN=2 RESTART=Y GRACE=0
CLOPT="-s TOUPPER:PY"
MIN=2 MAX=2
RQADDR="toupper"
The main change is that we start two copies of the server instead of one. One way to achieve this would be to copy the configuration of the first server and duplicate it with a new unique SRVID. But there is a better way to do this in Tuxedo:
- MIN: This is the number of copies of the server to start automatically. The default value is 1. If this number is greater than 1, the server identifier, SRVID, will be assigned automatically up to SRVID + MAX – 1.
- MAX: This is the maximum number of server copies that can be started. It defaults to the same value as MIN. All copies above MIN must be started manually.
- RQADDR: This is the symbolic queue name and allows multiple servers to use the same physical queue. If it is not given, GRPNO.SRVID is used to create a unique symbolic queue name.
After that, we will change the client.py program to call the service 100 times:
import tuxedo as t
for _ in range(100):
_, _, res = t.tpcall("TOUPPER", "Hello, world!")
print(res)
Then we load the new configuration and start the application to see that it starts two instances of our Tuxedo server and that both instances use the same queue name:
echo psr | tmadmin
After that, we can run the client program and observe how the requests completed (RqDone) column has changed:
python3 client.py
echo psr | tmadmin
You should see that each server instance has processed 50 requests or a number close to that. And that is exactly what we expected: requests are evenly distributed among server instances. If you feel adventurous, you can modify the client with an infinite loop, run it, kill one of the server instances, and see whether you still get the responses.
In the previous output, you will also notice a mysterious value around 2,500 as Load Done, but that is better explained with the next configuration.
Exploring the SSSQ configuration
SSSQ stands for Single Server Single Queue. Each server has its request queue in this setup. Since Tuxedo is broker-less, it is the responsibility of the client to perform load balancing and choose the appropriate queues for the request. While it may seem like a step back from the MSSQ configuration, SSSQ has its pros as well:
- It is recommended when messages are big and quickly fill the queue. Having multiple queues in such a scenario is better.
- SSSQ is better when you have a large number of servers. MSSQ may experience contention and perform worse with more than 10 servers on a single queue.
- SSSQ can offer unique services in addition to the common ones. All servers in the MSSQ configuration must provide the same services.
Each server waits for the request on its request queue and the client chooses the most appropriate request queue according to the load balancing algorithm. Refer to the following diagram:

Figure 3.7 – Single Server Single Queue
The configuration file for an SSSQ setup is as follows:
*RESOURCES
MASTER tuxapp
MODEL SHM
IPCKEY 32769
LDBAL Y
*MACHINES
"63986d7032b1" LMID=tuxapp
TUXCONFIG="/home/oracle/code/03/tuxconfig"
TUXDIR="/home/oracle/tuxhome/tuxedo12.2.2.0.0"
APPDIR="/home/oracle/code/03"
*GROUPS
GROUP1 LMID=tuxapp GRPNO=1
*SERVERS
"toupper.py" SRVGRP=GROUP1 SRVID=1
REPLYQ=Y MAXGEN=2 RESTART=Y GRACE=0
CLOPT="-s TOUPPER:PY"
MIN=2 MAX=2
In addition to using MIN and MAX, which we learned about previously, we skip RQADDR and let Tuxedo assign a unique queue for each server. The most important addition is as follows:
- LDBAL: This turns load balancing between the queues on (Y) or off (N). It is off by default because of some perceived performance overhead due to additional calculations needed, but I have not observed it in practice. More importantly, without load balancing, Tuxedo will pick the first queue and fail to use any others.
Tuxedo's load balancing algorithm is described in detail in a white paper published by Oracle: https://www.oracle.com/technetwork/middleware/tuxedo/overview/ld-balc-in-oracle-tux-atmi-apps-1721269.pdf. In short, it assigns each service a weight, calculates how much each queue weighs, and picks the lightest one. Unfortunately, it does not take into account the size of the message and the space available in the queue, so it may choose the queue where a much slower file transfer is needed.
We can load the new configuration and start the application to see that it starts two instances of our Tuxedo server and that each instance uses a different queue name:
echo psr | tmadmin
After that, we can run the client program that executes 100 requests and observe how the requests completed (RqDone) column has changed:
python3 client.py
echo psr | tmadmin
You should see that only one server instance has processed all 100 requests or a number close to that. Why did the second instance of the server not process any requests? The weight is assigned to the queue when the request is put into it and decreased once the request is retrieved from the queue. Since we serially call services one after another instead of in parallel, the queue's weight is 0 when load balancing is performed and the first queue is picked up. We can launch several clients in parallel to utilize the second instance of the server:
python3 client.py & python3 client.py & python3 client.py
echo psr | tmadmin
But even now, you will see that the load is not evenly distributed among server instances.
As there are pros and cons to both configurations, it is not easy to choose one for your application. My experience with a specific application shows that a hybrid approach works best: multiple queues, each in an MSSQ setup, combining the best properties of both. Oracle's TPC-C benchmark setup uses SSSQ mode. Finding the best setup for your application and hardware can only be ascertained by multiple iterations of tuning the configuration and measuring the result.
Summary
In this chapter, we configured the Tuxedo application's sanity checks and witnessed how it restarts crashed processes. We learned about sizing queues and how those queues are used to deliver requests and responses between the client and server. Finally, we learned about services and their relationship with queues by modifying the configuration and examining the application behavior.
We have learned a lot about the inner workings of Tuxedo and message queues, but the message itself and the data contained in queues remain abstract and mysterious. There are specific message data types that Tuxedo supports and we will learn about these in the next chapter.
Questions
- What termination signal will cause BBL to not restart the server?
- Is there a direct limit in terms of messages in the queue?
- What is the Tuxedo term for a single queue with multiple consumers?
- What is the Tuxedo term for a single queue with a single consumer?
Further reading
- Tuxedo documentation at https://docs.oracle.com/cd/E72452_01/tuxedo/docs1222/.