
CHAPTER 2
A Cryptography Primer
Man is a warrior creature, a species that ritually engages in a type of warfare where the combat can range from the subtlety of inflicting economic damage, or achieving economic superiority and advantage, to moving someone’s chair a few inches from sitting distance or putting rocks in their shoes, to the heinousness of the outright killing of our opponents. As such, it is in our nature to want to prevent others who would do us harm from intercepting private communications (which could be about them!). Perhaps nothing so perfectly illustrates this fact as the art of cryptography. It is, in its purpose, an art form entirely devoted to the methods whereby we can prevent information from falling into the hands of those who would use it against us—our enemies.
Since the beginning of sentient language, cryptography has been a part of communication. It is as old as language itself. In fact, one could make the argument that the desire and ability to encrypt communication, to alter a missive in such a way so that only the intended recipient may understand it, is an innate ability hardwired into the human genome. Aside from the necessity to communicate, it could very well be what led to the development of language itself. Over time, languages and dialects evolve, as we can see with Spanish, French, Portuguese, and Italian—all “Latin” languages. People who speak French have a great deal of trouble understanding people who speak Spanish, and vice versa. The profundity of Latin cognates in these languages is undisputed, but generally speaking, the two languages are so far removed that they are not dialects, they are separate languages. But why is this? Certain abilities, such as walking, are hardwired into our nervous systems. Other abilities, such as language, are not.
So why isn’t language hardwired into our nervous system, as it is with bees, who are born knowing how to tell another bee how far away a flower is, as well as the quantity of pollen and whether there is danger present? Why don’t we humans all speak the exact same language? Perhaps we do, to a degree, but we choose not to do so. The reason is undoubtedly because humans, unlike bees, understand that knowledge is power, and knowledge is communicated via spoken and written words. Plus we weren’t born with giant stingers with which to simply sting people we don’t like. With the development of evolving languages innate in our genetic wiring, the inception of cryptography was inevitable.
In essence, computer-based cryptography is the art of creating a form of communication that embraces the following precepts:
• Can be readily understood by the intended recipients
• Cannot be understood by unintended recipients
• Can be adapted and changed easily with relatively small modifications, such as a changed passphrase or word
Any artificially created lexicon, such as the Pig Latin of children, pictograph codes, gang-speak, or corporate lingo—and even the names of music albums, such as Four Flicks—are all manners of cryptography where real text, sometimes not so ciphered, is hidden in what appears to be plain text. They are attempts at hidden communications.
1. What Is Cryptography? What Is Encryption?
Ask any ancient Egyptian and he’ll undoubtedly define cryptography as the practice of burying their dead so that they cannot be found again. They were very good at it; thousands of years later, new crypts are still being discovered. The Greek root krypt literally means “a hidden place,” and as such it is an appropriate base for any term involving cryptology. According to the Online Etymology Dictionary, crypto- as a prefix, meaning “concealed, secret,” has been used since 1760, and from the Greek graphikos, “of or for writing, belonging to drawing, picturesque.” [1] Together, crypto + graphy would then mean “hiding place for ideas, sounds, pictures, or words.” Graph, technically from its Greek root, is “the art of writing.” Encryption, in contrast, merely means the act of carrying out some aspect of cryptography. Cryptology, with its -ology ending, is the study of cryptography. Encryption is subsumed by cryptography.
How Is Cryptography Done?
For most information technology occupations, knowledge of cryptography is a very small part of a broader skill set, and is generally limited to relevant application. The argument could be made that this is why the Internet is so extraordinarily plagued with security breaches. The majority of IT administrators, software programmers, and hardware developers are barely cognizant of the power of true cryptography. Overburdened with battling the plague that they inherited, they can’t afford to devote the time or resources needed to implement a truly secure strategy. And the reason, as we shall come to see, is because as good at cryptographers can be—well, just as it is said that everyone has an evil twin somewhere in the world, for every cryptographer there is a de cryptographer working just as diligently to decipher a new encryption algorithm.
Traditionally, cryptography has consisted of any means possible whereby communications may be encrypted and transmitted. This could be as simple as using a language with which the opposition is not familiar. Who hasn’t been somewhere where everyone around you was speaking a language you didn’t understand? There are thousands of languages in the world, nobody can know them all. As was shown in World War II, when Allied Forces used Navajo as a means of communicating freely, some languages are so obscure that an entire nation may not contain one person who speaks it! All true cryptography is composed of three parts: a cipher, an original message, and the resultant encryption. The cipher is the method of encryption used. Original messages are referred to as plain text or as clear text. A message that is transmitted without encryption is said to be sent “in the clear.” The resultant message is called ciphertext or cryptogram. This section begins with a simple review of cryptography procedures and carries them through; each section building on the next to illustrate the principles of cryptography.
2. Famous Cryptographic Devices
The past few hundred years of technical development and advances have brought greater and greater means to decrypt, encode, and transmit information. With the advent of the most modern warfare techniques and the increase in communication and ease of reception, the need for encryption has never been greater.
World War II publicized and popularized cryptography in modern culture. The Allied Forces’ ability to capture, decrypt, and intercept Axis communications is said to have hastened WWII’s end by several years. Here we take a quick look at some famous cryptographic devices from that era.
The Lorenz Cipher
The Lorenz cipher machine was an industrial-strength ciphering machine used in teleprinter circuits by the Germans during WWII. Not to be confused with its smaller cousin, the Enigma machine, the Lorenz cipher could possibly be best compared to a virtual private network tunnel for a telegraph line—only it wasn’t sending Morse code, it was using a code not unlike a sort of American Standard Code for Information Interchange (ASCII) format. A granddaddy of sorts, called Baudot code, was used to send alphanumeric communications across telegraph lines. Each character was represented by a series of 5 bits.
It is often confused with the famous Enigma, but unlike the Enigma (which was a portable field unit), the Lorenz cipher could receive typed messages, encrypt them, send them to another distant Lorenz cipher, which would then decrypt the signal. It used a pseudorandom cipher XOR’d with plaintext. The machine would be inserted inline as an attachment to a Lorenz teleprinter. Figure 2.1 is a rendered drawing from a photograph of a Lorenz cipher machine.
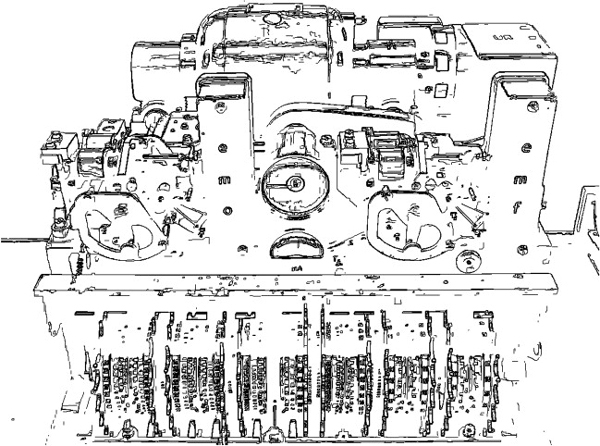
Figure 2.1: The Lorenz machine was set inline with a teletype to produce encrypted telegraphic signals.
Enigma
The Enigma machine was a field unit used in WWII by German field agents to encrypt and decrypt messages and communications. Similar to the Feistel function of the 1970s, the Enigma machine was one of the first mechanized methods of encrypting text using an iterative cipher. It employed a series of rotors that, with some electricity, a light bulb, and a reflector, allowed the operator to either encrypt or decrypt a message. The original position of the rotors, set with each encryption and based on a prearranged pattern that in turn was based on the calendar, allowed the machine to be used, even if it was compromised.
When the Enigma was in use, with each subsequent key press, the rotors would change in alignment from their set positions in such a way that a different letter was produced each time. The operator, with a message in hand, would enter each character into the machine by pressing a typewriter-like key. The rotors would align, and a letter would then illuminate, telling the operator what the letter really was. Likewise, when enciphering, the operator would press the key and the illuminated letter would be the cipher text. The continually changing internal flow of electricity that caused the rotors to change was not random, but it did create a polyalphabetic cipher that could be different each time it was used.
3. Ciphers
Cryptography is built on one overarching premise: the need for a cipher that can reliably, and portably, be used to encrypt text so that, through any means of cryptanalysis—differential, deductive, algebraic, or the like—the ciphertext cannot be undone with any available technology. Throughout the centuries, there have been many attempts to create simple ciphers that can achieve this goal. With the exception of the One Time Pad, which is not particularly portable, success has been limited.
Let’s look at a few of these methods now.
The Substitution Cipher
In this method, each letter of the message is replaced with a single character. See Table 2.1 for an example of a substitution cipher. Because some letters appear more often and certain words appear more often than others, some ciphers are extremely easy to decrypt, and some can be deciphered at a glance by more practiced cryptologists.
By simply understanding probability and with some applied statistics, certain metadata about a language can be derived and used to decrypt any simple, one-for-one substitution cipher. Decryption methods often rely on understanding the context of the ciphertext. What was encrypted—business communication? Spreadsheets? Technical data? Coordinates? For example, using a hex editor and an access database to conduct some statistics, we can use the information in Table 2.2 to gain highly specialized knowledge about the data in
Table 2.1: A simple substitution cipher. Letters are numbered by their order in the alphabet to provide a numeric reference key. To encrypt a message, the letters are replaced, or substituted, by the numbers. This is a particularly easy cipher to reverse.

Table 2.2: Statistical data of interest in encryption. An analysis of a selection of a manuscript (in this case, the preedited version of Chapter 6 of Managing Information Security) can provide insight into the reasons that good ciphers need to be developed.
Character Analysis |
Count |
Number of distinct alphanumeric combinations |
1958 |
Distinct characters |
68 |
Number of four-letter words |
984 |
Number of five-letter words |
1375 |
Chapter 6, “Computer Forensics” by Scott R. Ellis, found in the book Managing Information Security, ed. by John Vacca. A long chapter at nearly 25,000 words, it provides a sufficiently large statistical pool to draw some meaningful analyses.
Table 2.3 gives additional data about the occurrence of specific words in “Computer Forensics”. Note that because it is a technical text, words such as computer, files, email, and drive emerge as leaders. Analysis of these leaders can reveal individual and paired alpha frequencies. Being armed with knowledge about the type of communication can be very beneficial in decrypting it.
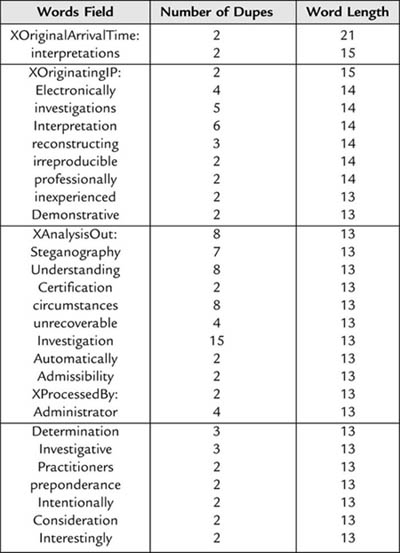
Further information about types of data being encrypted includes word counts by length of the word. Table 2.4 contains such a list for “Computer Forensics”. This information can be used to begin to piece together useful and meaningful short sentences, which can provide cues to longer and more complex structures. It is exactly this sort of activity that good cryptography attempts to defeat.
Were it encrypted using a simple substitution cipher, a good start to deciphering “Computer Forensics” could be made using the information we’ve gathered. As a learning exercise, game, or logic puzzle, substitution ciphers are quite useful. Some substitution ciphers that are more elaborate can be just as difficult to crack. Ultimately, though, the weakness behind a substitution cipher is the fact that the ciphertext remains a one-to-one, directly corresponding substitution; ultimately anyone with a pen and paper and a large enough sample of the ciphertext can defeat it. Using a computer, deciphering a simple substitution cipher becomes child’s play.
The Shift Cipher
Also known as the Caesar cipher, the shift cipher is one that anyone can readily understand and remember for decoding. It is a form of the substitution cipher. By shifting the alphabet a few positions in either direction, a simple sentence can become unreadable to casual inspection. Example 2.1 is an example of such a shift.
Table 2.3: Five-letter word recurrences in “Computer Forensics”: A glimpse of the leading five-letter words found in the preedited manuscript. Once unique letter groupings have been identified, substitution, often by trial and error, can result in a meaningful reconstruction that allows the entire cipher to be revealed.
Words Field |
Number of Recurrences |
Files |
125 |
Drive |
75 |
There |
67 |
46 | |
These |
43 |
Other |
42 |
about |
41 |
where |
36 |
would |
33 |
every |
31 |
Court |
30 |
Their |
30 |
First |
28 |
Using |
28 |
which |
24 |
Could |
22 |
Table |
22 |
After |
21 |
image |
21 |
Don’t |
19 |
Tools |
19 |
Being |
18 |
Entry |
18 |
Interestingly, for cryptogram word games, the spaces are always included. Often puzzles use numbers instead of letters for the substitution. Removing the spaces in this particular example can make the ciphertext somewhat more secure. The possibility for multiple solutions becomes an issue; any number of words might fit the pattern.
Today many software tools are available to quickly and easily decode most cryptograms (at least, those that are not written in a dead language). You can have some fun with these tools; for example, the name Scott Ellis, when decrypted, turns into Still Books. The name of a friend of the author’s decrypts to “His Sinless.” It is apparent, then, that smaller-sample simple substitution ciphers can have more than one solution.
Much has been written and much has been said about frequency analysis; it is considered the “end-all and be-all” with respect to cipher decryption. This is not to be confused with cipher breaking, which is a modern attack against the actual cryptographic algorithms themselves. However, to think of simply plugging in some numbers generated from a Google search is a bit naïve. The frequency chart in Table 2.5 is commonplace on the Web.
Table 2.4: Leaders by word length in the preedited manuscript for “Computer Forensics”. The context of the clear text can make the cipher less secure. There are, after all, only a finite number of words. Fewer of them are long.
It is beyond the scope of this chapter to delve into the accuracy of the table, but suffice it to say that our own analysis of the chapter’s 118,000 characters, a technical text, yielded a much different result; see Table 2.6. Perhaps it is the significantly larger sample and the fact that it is a technical text that makes the results different after the top two. Additionally, where computers are concerned, an actual frequency analysis would take into consideration all ASCII characters, as shown in Table 2.6.
Table 2.5: “In a random sampling of 1000 letters,” this pattern emerges.
Letter |
Frequency |
E |
130 |
T |
93 |
N |
78 |
R |
77 |
I |
74 |
O |
74 |
A |
73 |
S |
63 |
D |
44 |
H |
35 |
L |
35 |
C |
30 |
F |
28 |
P |
27 |
U |
27 |
M |
25 |
Y |
19 |
G |
16 |
W |
16 |
V |
13 |
B |
9 |
X |
5 |
K |
3 |
Q |
3 |
J |
2 |
Z |
1 |
Total |
1000 |
Frequency analysis is not difficult; once all the letters of a text are pulled into a database program, it is fairly straightforward to do a count of all the duplicate values. The snippet of code in Example 2.2 demonstrates one way whereby text can be transformed into a single column and imported into a database.
The cryptograms that use formatting (every word becomes the same length) are considerably more difficult for basic online decryption programs to crack. They must take into consideration spacing and word lengths when considering whether or not a string matches a word. It stands to reason, then, that the formulation of the cipher, where a substitution that is based partially on frequency similarities and with a whole lot of obfuscation so that when messages are decrypted they have ambiguous or multiple meanings, would be desirable for simple ciphers. However, this would only be true for very short and very obscure messages that could be code words to decrypt other messages or could simply be sent to misdirect the opponent. The amount of ciphertext needed to successfully break a cipher is called unicity distance. Ciphers with small unicity distances are weaker than those with large ones.
Table 2.6: Using MS Access to perform some frequency analysis of “Computer Forensics”. Characters with fewer repetitions than z were excluded from the return. Character frequency analysis of different types of communications yield slightly different results.
“Computer Forensics” Letters |
Frequency |
E |
14,467 |
T |
10,945 |
A |
9239 |
I |
8385 |
O |
7962 |
S |
7681 |
N |
7342 |
R |
6872 |
H |
4882 |
L |
4646 |
D |
4104 |
C |
4066 |
U |
2941 |
M |
2929 |
F |
2759 |
P |
2402 |
Y |
2155 |
G |
1902 |
W |
1881 |
B |
1622 |
V |
1391 |
|
1334 |
, |
1110 |
K |
698 |
0 |
490 |
X |
490 |
Q |
166 |
7 |
160 |
* |
149 |
5 |
147 |
) |
147 |
( |
146 |
J |
145 |
3 |
142 |
6 |
140 |
Æ |
134 |
Ó |
134 |
Ô |
129 |
Ö |
129 |
4 |
119 |
Z |
116 |
Total |
116,798 |
Example 2.1 A sample cryptogram. Try this out:
Gv Vw, Dtwvg?
Hint: Caesar said it, and it is Latin [2].
Example 2.2
1: Sub Letters2column ()
2: Dim bytText () As Byte
3: Dim bytNew() As Byte
4: Dim lngCount As Long
5: With ActiveDocument.Content
6: bytText = .Text
7: ReDim bytNew((((UBound(bytText()) + 1) * 2) - 5))
8: For lngCount = 0 To (UBound(bytText()) - 2) Step 2
9: bytNew((lngCount * 2)) = bytText(lngCount)
10: bytNew(((lngCount * 2) + 2)) = 13
11: Next lngCount
12: Text = bytNew()
13: End With
14: End Sub
Ultimately, substitution ciphers are vulnerable to either word-pattern analysis, letter-frequency analysis, or some combination of both. Where numerical information is encrypted, tools such as Benford’s Law can be used to elicit patterns of numbers that should be occurring. Forensic techniques incorporate such tools to uncover accounting fraud. So, though this particular cipher is a child’s game, it is useful in that it is an underlying principle of cryptography and should be well understood before continuing. The primary purpose of discussing it here is as an introduction to ciphers.
Further topics of interest and places to find information involving substitution ciphers are the chi-square statistic, Edgar Allan Poe, Sherlock Holmes, Benford’s Law, Google, and Wikipedia.
The Polyalphabetic Cipher
The previous section clearly demonstrated that though the substitution cipher is fun and easy, it is also vulnerable and weak. It is especially susceptible to frequency analysis. Given a large enough sample, a cipher can easily be broken by mapping the frequency of the letters in the ciphertext to the frequency of letters in the language or dialect of the ciphertext (if it is known). To make ciphers more difficult to crack, Blaise de Vigenère from the 16th-century court of Henry III of France proposed a polyalphabetic substitution. In this cipher, instead of a one-to-one relationship, there is a one-to-many. A single letter can have multiple substitutes. The Vigenère solution was the first known cipher to use a keyword.
It works like this: First, a tableau is developed, as in Table 2.7. This tableau is a series of shift ciphers. In fact, since there can be only 26 additive shift ciphers, it is all of them.
In Table 2.7, a table in combination with a keyword is used to create the cipher. For example, if we choose the keyword rockerrooks, overlay it over the plaintext, and cross-index it to Table 2.7, we can produce the ciphertext. In this example, the top row is used to look up the plaintext, and the leftmost column is used to reference the keyword.
For example, we lay the word rockerrooks over the sentence, “Ask not what your country can do for you.” Line 1 is the keyword, line 2 is the plain text, and line 3 is the ciphertext.
Keyword: ROC KER ROOK SROC KERROOK SRO CK ERR OOK
Plaintext: ASK NOT WHAT YOUR COUNTRY CAN DO FOR YOU
Ciphertext: RGM XSK NVOD QFIT MSLEHFI URB FY JFI MCE
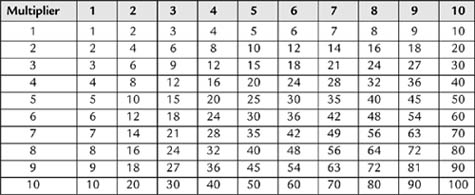
The similarity of this tableau to a mathematical table like the one in Table 2.8 becomes apparent. Just think letters instead of numbers and it becomes clear how this works. The top row is used to “look up” a letter from the plaintext, the leftmost column is used to locate the overlaying keyword letter, and where the column and the row intersect is the ciphertext.
This similarity is, in fact, the weakness of the cipher. Through some creative “factoring,” the length of the keyword can be determined. Since the tableau is, in practice, a series of shift ciphers, the length of the keyword determines how many ciphers are used. The keyword rockerrook, with only six distinct letters, uses only six ciphers. Regardless, for nearly 300 years many people believed the cipher to be unbreakable.
Table 2.7: Vigenère’s tableau arranges all of the shift ciphers in a single table. It then implements a keyword to create a more complex cipher than the simple substitution or shift ciphers. The number of spurious keys, that is, bogus decryptions that result from attempting to decrypt a polyalphabetic encryption, is greater than those created during the decryption of a single shift cipher.
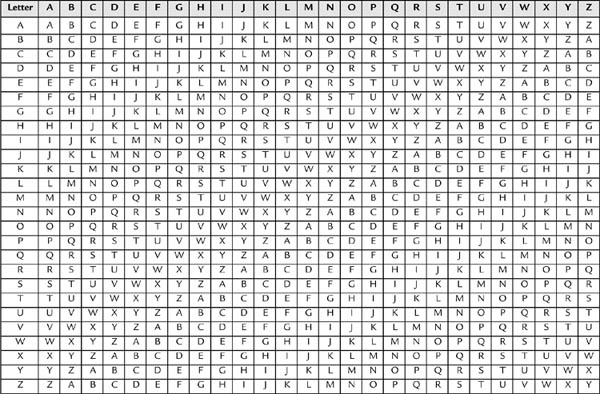
Table 2.8: The multiplication table is the inspiration for the Vigenère tableau. Multiplier
The Kasiski/Kerckhoff Method
Now let’s look at Kerckhoff’s principle—“only secrecy of the key provides security” (not to be confused with Kirchhoff’s law, a totally different man and rule). In the 19th century, Auguste Kerckhoff said that essentially, a system should still be secure, even when everyone knows everything about the system (except the password). Basically, his feeling was that if more than one person knows something, it’s no longer a secret. Throughout modern cryptography, the inner workings of cryptographic techniques have been well known and published. Creating a portable, secure, unbreakable code is easy if nobody knows how it works. The problem lies in the fact that we people just can’t keep a secret!
Example 2.3 A repetitious, weak keyword combines with plaintext to produce an easily deciphered ciphertext
Keyword to to .toto.to. to. toto o to
Plaintext It is. whatit .is, isn’t.. it?
Ciphertext BH....BG..PVTH....BH
BG...BGG...H...BH
In 1863 Kasiski, a Prussian major, proposed a method to crack the Vigenère cipher. His method, in short, required that the cryptographer deduce the length of the keyword used and then dissect the cryptogram into a corresponding number of ciphers. Each cipher would then be solved independently. The method required that a suitable number of bigrams be located. A bigram is a portion of the ciphertext, two characters long, that repeats itself in a discernible pattern. In Example 2.3, a repetition has been deliberately made simple with a short keyword (toto) and engineered by crafting a harmonic between the keyword and the plaintext.
This might seem an oversimplification, but it effectively demonstrates the weakness of the polyalphabetic cipher. Similarly, the polyalphanumeric ciphers, such as the Gronsfeld cipher, are even weaker since they use 26 letters and 10 digits. This one also happens to decrypt to “On of when on of,” but a larger sample with such a weak keyword would easily be cracked by even the least intelligent of Web-based cryptogram solvers. The harmonic is created by the overlaying keyword with the underlying text; when the bigrams “line up” and repeat themselves, the highest frequency will be the length of the password. The distance between the two occurrences will be the length of the password. In Example 2.3, we see BH and BG repeating, and then we see BG repeating at a very tight interval of 2, which tells us the password might be two characters long and based on two shift ciphers that, when decrypted side by side, will make a real word. Not all bigrams will be indicators of this, so some care must be taken. As can be seen, BH repeats with an interval of 8, but the password is not eight digits long (but it is a factor of 8!). By locating the distance of all the repeating bigrams and factoring them, we can deduce the length of the keyword.
4. Modern Cryptography
Some of cryptography’s greatest stars emerged in WWII. For the first time during modern warfare, vast resources were devoted to enciphering and deciphering communications. Both sides made groundbreaking advances in cryptography. Understanding the need for massive calculations (for the time—more is probably happening in the RAM of this author’s PC over a period of five minutes than happened in all of WWII), both sides developed new machinery—predecessors to the modern solid-state computers—that could be coordinated to perform the calculations and procedures needed to crack enemy ciphers.
The Vernam Cipher (Stream Cipher)
Gilbert Sandford Vernam (1890–1960) was said to have invented the stream cipher in 1917. Vernam worked for Bell Labs, and his patent described a cipher in which a prepared key, on a paper tape, combined with plaintext to produce a transmitted ciphertext message. The same tape would then be used to decrypt the ciphertext. In effect, the Vernam and “one-time pad” ciphers are very similar. The primary difference is that the “one-time pad” cipher implements an XOR for the first time and dictates that a truly random stream cipher be used for the encryption. The stream cipher had no such requirement and used a different method of relay logic to combine a pseudo-random stream of bits with the plaintext bits. More about the XOR process is discussed in the section on XOR ciphering. In practice today, the Vernam cipher is any stream cipher in which pseudo-random or random text is combined with plaintext to produce cipher text that is the same length as the cipher. RC4 is a modern example of a Vernam cipher.
Example 2.4 Using the random cipher, a modulus shift instead of an XOR, and plaintext to produce ciphertext
Plaintext 1
t h i s w i l l b e s o e a s y t o b r e a k i t w i l l b e f u n n y
20 8 9 19 23 9 12 12 2 5 19 15 5 1 19 25 20 15 2 18 5 1 11 9 20 23 9 12 12 2 5 6
21 14 14 25
Cipher One
q e r t y u i o p a s d f g h j k l z x c v b n m q a z w s x e r f v t
17 5 18 20 25 21 9 15 16 1 19 4 6 7 8 10 11 12 26 24 3 22 2 14 13 17 1 26 23 19
24 5 18 6 22 20
CipherText 1
11 13 1 13 22 4 21 1 18 6 12 19 11 8 1 9 5 1 2 16 8 23 13 23 7 14 10 12 9 21 3
11 13 20 10 19
k m a m v d u a r f l s k h a i e a b p h w m w g n j l w u c k m t j s
Plaintext 2
T h i s w i l l n o t b e e a s y t o b r e a k o r b e t o o f u n n y
20 8 9 19 23 9 12 12 14 15 20 2 5 5 1 19 25 20 15 2 18 5 1 11 15 18 2 5 20 15 15
6 21 14 14 25
Ciphertext 2, also using Cipher One.
11 13 1 13 22 4 21 1 4 16 13 6 11 12 9 3 10 6 15 0 21 1 3 25 2 9 3 5 17 8 13 11
13 20 10 19
k m a m v d u a e p m f k l i f j f o z u a c y b i c e q h m k m t j s
The One-Time Pad
The “one-time pad” cipher, attributed to Joseph Mauborgne [3], is perhaps one of the most secure forms of cryptography. It is very difficult to break if used properly, and if the key stream is perfectly random, the ciphertext gives away absolutely no details about the plaintext, which renders it unbreakable. And, just as the name suggests, it uses a single random key that is the same length as the entire message, and it uses the key only once. The word pad is derived from the fact that the key would be distributed in pads of paper, with each sheet torn off and destroyed as it was used.
There are several weaknesses to this cipher. We begin to see that the more secure the encryption, the more it will rely on other means of key transmission. The more a key has to be moved around, the more likely it is that someone who shouldn’t have it will have it. The following weaknesses are apparent in this “bulletproof” style of cryptography:
• Key length has to equal plaintext length.
• It is susceptible to key interception; the key must be transmitted to the recipient, and the key is as long as the message!
• It’s cumbersome, since it doubles the traffic on the line.
• The cipher must be perfectly random.
• One-time use is absolutely essential. As soon as two separate messages are available, the messages can be decrypted. Example 2.4 demonstrates this.
Since most people don’t use binary, the author takes the liberty in Example 2.4 of using decimal numbers modulus 26 to represent the XOR that would take place in a bitstream encryption (see the section on the XOR cipher) that uses the method of the one-time pad.
Table 2.9: A simple key is created so that random characters and regular characters may be combined with a modulus function. Without the original cipher, this key is meaningless intelligence. It is used here in a similar capacity as an XOR, which is also a function that everyone knows how to do.

Example 2.5
The two ciphertexts, side by side, show a high level of harmonics. This indicates that two different ciphertexts actually have the same cipher. Where letters are different, since XOR is a known process and our encryption technique is also publicly known, it’s a simple matter to say that r = 18, e = 5 (see Table 2.9) and thusly construct an algorithm that can tease apart the cipher and ciphertext to produce plaintext.
A numeric value is assigned to each letter, per Table 2.9. By assigning a numeric value to each letter, adding the plaintext value to the ciphertext value, modulus 26, yields a pseudo-XOR, or a wraparound Caesar shift that has a different shift for each letter in the entire message.
As this example demonstrates, by using the same cipher twice, a dimension is introduced that allows for the introduction of frequency analysis. By placing the two streams side by side, we can identify letters that are the same. In a large enough sample, where the cipher text is sufficiently randomized, frequency analysis of the aligned values will begin to crack the cipher wide open because we know that they are streaming in a logical order—the order in which they were written. One of the chief advantages of 21st-century cryptography is that the “eggs” are scrambled and descrambled during decryption based on the key, which you don’t, in fact, want people to know. If the same cipher is used repeatedly, multiple inferences can be made and eventually the entire key can be deconstructed. Because plaintext 1 and plaintext 2 are so similar, this sample yields the following harmonics (in bold and boxed) as shown in Example 2.5.
Cracking Ciphers
One method of teasing out the frequency patterns is through the application of some sort of mathematical formula to test a hypothesis against reality. The chi-square test is perhaps one of the most commonly used; it allows someone to use what is called inferential statistics to draw certain inferences about the data by testing it against known statistical distributions.
Using the chi-square test against an encrypted text would allow certain inference to be made, but only where the contents, or the type of contents (random or of an expected distribution), of the text were known. For example, someone may use a program that encrypts files. By creating the null hypothesis that the text is completely random, and by reversing the encryption steps, a block cipher may emerge as the null hypothesis is disproved through the chi-square test. This would be done by reversing the encryption method and XORing against the bytes with a block created from the known text. At the point where the non-encrypted text matches the positioning of the encrypted text, chi-square would reveal that the output is not random and the block cipher would be revealed.
![]()
Observed would be the actual zero/one ratio produced by XORing the data streams together, and expected would be the randomness of zeroes and ones (50/50) expected in a body of pseudorandom text.
Independent of having a portion of the text, a large body of encrypted text could be reverse encrypted using a block size of all zeroes; in this manner it may be possible to tease out a block cipher by searching for non random block sized strings. Modern encryption techniques generate many, many block cipher permutations that are layered against previous iterations (n-1) of permutated blocks. The feasibility of running such decryption techniques would require both a heavy-duty programmer, statistician, an incredible amount of processing power, and in-depth knowledge of the encryption algorithm used. An unpublished algorithm would render such testing worthless.
Some Statistical Tests for Cryptographic Applications by Adrian Fleissig
In many applications, it is often important to determine if a sequence is random. For example, a random sequence provides little or no information in cryptographic analysis. When estimating economic and financial models, it is important for the residuals from the estimated model to be random. Various statistical tests can be used to evaluate if a sequence is actually a random sequence or not. For a truly random sequence, it is assumed that each element is generated independently of any prior and/or future elements. A statistical test is used to compute the probability that the observed sequence is random compared to a truly random sequence. The procedures have test statistics that are used to evaluate the null hypothesis which typically assumes that the observed sequence is random. The alternative hypothesis is that the sequence is non random. Thus failing to accept the null hypothesis, at some critical level selected by the researcher, suggests that the sequence may be non random.
There are many statistical tests to evaluate for randomness in a sequence such as Frequency Tests, Runs Tests, Discrete Fourier Transforms, Serial Tests and many others. The tests statistics often have chi-square or standard normal distributions which are used to evaluate the hypothesis. While no test is overall superior to the other tests, a Frequency or Runs Test is a good starting point to examine for non-randomness in a sequence. As an example, a Frequency or Runs Test typically evaluates if the number of zeros and ones in a sequence are about the same, as would be the case if the sequence was truly random.
It is important to examine the results carefully. For example, the researcher may incorrectly fail to accept the null hypothesis that the sequence is random and thereby makes a Type I Error. Incorrectly accepting the null of randomness when the sequence is actually non random results in committing a Type II Error. The reliability of the results depends on having a sufficiently large number of elements in a sequence. In addition, it is important to perform alternative tests to evaluate if a sequence is random [4].
Notably, the methods and procedures used in breaking encryption algorithms are used throughout society in many applications where a null hypothesis needs to be tested. Forensic consultants use pattern matching and similar decryption techniques to combat fraud on a daily basis. Adrian Fleissig, a seasoned economist, makes use of many statistical tests to examine corporate data (see side bar, “Some Statistical Tests for Cryptographic Applications”).
The XOR Cipher and Logical Operands
In practice, the XOR cipher is not so much a cipher as it is a mechanism whereby ciphertext is produced. Random binary stream cipher would be a better term. The terms XOR, logical disjunction, and inclusive disjunction may be used interchangeably. Most people are familiar with the logical functions of speech, which are words such as and, or, nor, and not. A girl can tell her brother, “Mother is either upstairs or at the neighbor’s,” which means she could be in either state, but you have no way of knowing which one it is. The mother could be in either place, and you can’t infer from the statement the greater likelihood of either. The outcome is undecided.
Alternately, if a salesman offers a customer either a blue car or a red car, the customer knows that he can have red or he can have blue. Both statements are true. Blue cars and red cars exist simultaneously in the world. A person can own both a blue car and a red car. But Mother will never be in more than one place at a time. Purportedly, there is widespread belief that no author has produced an example of an English or sentence that appears to be false because both of its inputs are true [5]. Quantum physics takes considerable exception to this statement (which explains quantum physicists) at the quantum mechanical level. In the Schrodinger cat experiment, the sentence “The cat is alive or dead” or the statement “The photon is a particle and a wave until you look at it, then it is a particle or a wave, depending on how you observed it” both create a quandary for logical operations, and there are no Venn diagrams or words that are dependant on time or quantum properties of the physical universe. Regardless of this exception, when speaking of things in the world in a more rigorously descriptive fashion (in the macroscopically nonphenomenological sense), greater accuracy is needed.
Example 2.6 Line 1 and line 2 are combined with an XOR operand to produce line 3.
Line 1, plaintext : 1 0 0 1 1 1 0 1 0 1 1011 11
Line 2, random cipher “”: 1 0001 101 010 010 01
Line 3, XOR ciphertext: 0 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0
To create a greater sense of accuracy in discussions of logic, the operands as listed in Figure 2.2 were created. When attempting to understand this chart, the best thing to do is to assign a word to the A and B values and think of each Venn diagram as a universe of documents, perhaps in a document database or just on a computer being searched. If A stands for the word tree and B for frog, then each letter simply takes on a very significant and distinct meaning.
In computing, it is traditional that a value of 0 is false and a value of 1 is true. An XOR operation, then, is the determination of whether two possibilities can be combined to produce a value of true or false, based on whether both operations are true, both are false, or one of the values is true.
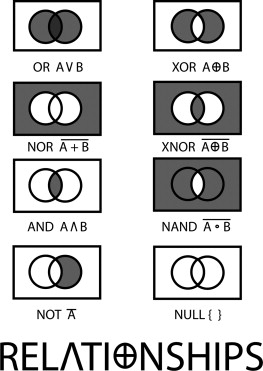
Figure 2.2: In each Venn diagram, the possible outcome of two inputs is decided.
1 XOR 1 = 0
0 XOR 0 = 0
1 XOR 0 = 1
0 XOR 1 = 1
In an XOR operation, if the two inputs are different, the resultant is TRUE, or 1. If the two inputs are the same, the resultant value is FALSE, or 0.
In Example 2.6, the first string represents the plaintext and the second line represents the cipher. The third line represents the ciphertext. If, and only exactly if, just one of the items has a value of TRUE, the results of the XOR operation will be true.
Without the cipher, and if the cipher is truly random, decoding the string becomes impossible. However, as in the one-time pad, if the same cipher is used, then (1) the cryptography becomes vulnerable to a known text attack, and (2) it becomes vulnerable to statistical analysis. Example 2.7 demonstrates this by showing exactly where the statistical aberration can be culled in the stream. If we know they both used the same cipher, can anyone solve for Plaintext A and Plaintext B?
Block Ciphers
Block ciphers work very similarly to the polyalphabetic cipher with the exception that a block cipher pairs together two algorithms for the creation of ciphertext and its decryption. It is also somewhat similar in that, where the polyalphabetic cipher used a repeating key, the block cipher uses a permutating, yet repeating, cipher block. Each algorithm uses two inputs: a key and a “block” of bits, each of a set size. Each output block is the same size as the input block, the block being transformed by the key. The key, which is algorithm based, is able to select the permutation of its bijective mapping from 2n, where n is equal to the number of bits in the input block. Often, when 128-bit encryption is discussed, it is referring to the size of the input block. Typical encryption methods involve use of XOR chaining or some similar operation; see Figure 2.3.
Block ciphers have been very widely used since 1976 in many encryption standards. As such, cracking these ciphers became, for a long time, the top priority of cipher crackers everywhere. Block ciphers provide the backbone algorithmic technology behind most modern-era ciphers.
Example 2.7
To reconstruct the cipher if the plaintext is known, PlaintextA can be XOR’d to ciphertextB to produce cipherA! Clearly, in a situation where plaintext may be captured, using the same cipher key twice could completely expose the message. By using statistical analysis, the unique possibilities for PlaintextA and PlaintextB will emerge; unique possibilities means that for ciphertext = x, where the cipher is truly random, this should be at about 50% of the sample. Additions of ciphertext n þ 1 will increase the possibilities for unique combinations because, after all, these binary streams must be converted to text and the set of binary stream possibilities that will combine into ASCII characters is relatively small. Using basic programming skills, you can develop algorithms that will quickly and easily sort through this data to produce a deciphered result. An intelligent person with some time on her hands could sort it out on paper or in an Excel spreadsheet. When the choice is “The red house down the street from the green house is where we will meet” or a bunch of garbage, it begins to become apparent how to decode the cipher.
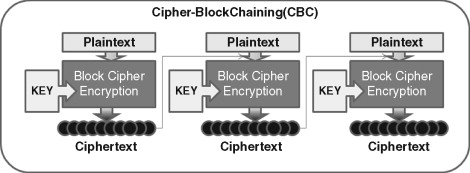
Figure 2.3: XOR chaining, or cipher-block chaining (CBC), is a method whereby the next block of plaintext to be encrypted is XOR’d with the previous block of ciphertext before being encrypted.
CipherA and PlaintextA are XOR'd to produce ciphertextA:
PlaintextA: 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
cipherA: 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
ciphertextA: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
PlaintextB and cipherA are XOR'd to produce ciphertextB:
ciphertextB: 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
cipherA: 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
PlaintextB: 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
|,-----Column1 ---------.|,--------Column2 ------|
Note: Compare ciphertextA to ciphertextB!
5. The Computer Age
To many people, January 1, 1970, is considered the dawn of the computer age. That’s when Palo Alto Research Center (PARC) in California introduced modern computing; the graphical user interface (no more command line and punch cards), networking on an Ethernet, and object-oriented programming have all been attributed to PARC. The 1970s also featured the Unix clock, Alan Shepherd on the moon, the U.S. Bicentennial, the civil rights movement, women’s liberation, Robert Heinlein’s sci-fi classic, Stranger in a Strange Land, and, most important to this chapter, modern cryptography. The late 1960s and early 1970s changed the face of the modern world at breakneck speed. Modern warfare reached tentative heights with radio-guided missiles, and warfare needed a new hero. And then there was the Data Encryption Standard, or DES; in a sense DES was the turning point for cryptography in that, for the first time, it fully leveraged the power of modern computing in its algorithms. The sky appeared to be the limit, but, unfortunately for those who wanted to keep their information secure, decryption techniques were not far behind.
Data Encryption Standard
In the mid-1970s the U.S. government issued a public specification, through its National Bureau of Standards (NBS), called the Data Encryption Standard or, most commonly, DES. This could perhaps be considered the dawn of modern cryptography because it was very likely the first block cipher, or at least its first widespread implementation. But the 1970s were a relatively untrusting time. “Big Brother” loomed right around the corner (as per George Orwell’s 1984), and the majority of people didn’t understand or necessarily trust DES. Issued under the NBS, now called the National Institute of Standards and Technology (NIST), hand in hand with the National Security Agency (NSA), DES led to tremendous interest in the reliability of the standard among academia’s ivory towers. A shortened key length and the implementation of substitution boxes, or “S-boxes,” in the algorithm led many to think that the NSA had deliberately weakened the algorithms and left a security “back door” of sorts.
The use of S-boxes in the standard was not generally understood until the design was published in 1994 by Don Coppersmith. The S-boxes, it turned out, had been deliberately designed to prevent a sort of cryptanalysis attack called differential cryptanalysis, as was discovered by IBM researchers in the early 1970s; the NSA had asked IBM to keep quiet about it. In 1990 the method was “rediscovered” independently and, when used against DES, the usefulness of the S-boxes became readily apparent.
Theory of Operation
DES used a 64-bit block cipher combined with a mode of operation based on cipher-block chaining (CBC) called the Feistel function. This consisted of an initial expansion permutation followed by 16 rounds of XOR key mixing via subkeys and a key schedule, substitution (S-boxes), and permutation [6]. In this strategy, a block is increased from 32 bits to 48 bits (expansion permutation). Then the 48-bit block is divided in half. The first half is XORs, with parts of the key according to a key schedule. These are called subkeys. Figure 2.4 shows this concept in a simplified format.
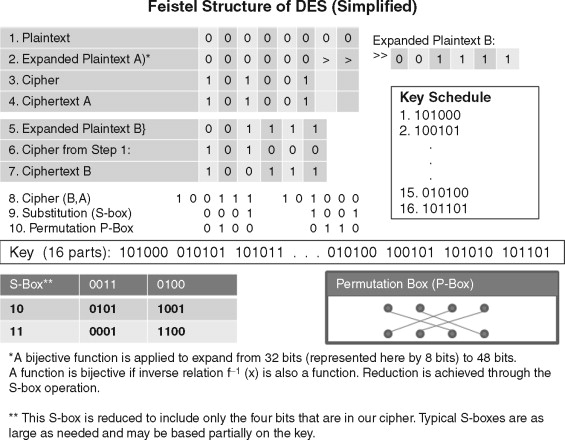
Figure 2.4: The Feistel function with a smaller key size.
The resulting cipher is then XOR’d with the half of the cipher that was not used in step 1. The two halves switch sides. Substitution boxes reduce the 48 bits down to 32 bits via a nonlinear function and then a permutation, according to a permutation table, takes place. Then the entire process is repeated again, 16 times, except in the last step the two halves are not flipped. Finally, this diffusive strategy produced via substitution, permutation, and key schedules creates an effective ciphertext. Because a fixed-length cipher, a block cipher, is used, the permutations and the S-box introduce enough confusion that the cipher cannot be deduced through brute-force methods without extensive computing power.
With the increase in size of hard drives and computer memory, the need for disk space and bandwidth still demand that a block cipher algorithm be portable. DES, Triple DES, and the Advanced Encryption Standard (AES) all provide or have provided solutions that are secure and practical.
Implementation
Despite the controversy at the time, DES was implemented. It became the encryption standard of choice until the late 1990s, when it was broken when Deep Crack and distributed.net broke a DES key in 22 hours and 15 minutes. Later that year a new form of DES called Triple DES, which encrypted the plaintext in three iterations, was published. It remained in effect until 2002, when it was superseded by AES.
Rivest, Shamir, and Adleman (RSA)
The release of DES also included the creation and release of Ron Rivest, Adi Shamir, and Leonard Adleman’s encryption algorithm (RSA). Rivest, Shamir, and Adleman, based at the Massachusetts Institute of Technology (MIT), publicly described the algorithm in 1977. RSA is the first encryption standard to introduce (to public knowledge) the new concept of digital signing. In 1997 it was revealed through declassification of papers that Clifford Cocks, a British mathematician working for the U.K. Government Communications Headquarters (GCHQ), had, in 1973, written a paper describing this process. Assigned a status of top secret, the work had previously never seen the light of day. Because it was submitted in 1973, the method had been considered unattainable, since computing power at the time could not handle its methods.
Advanced Encryption Standard (AES or Rijndael)
AES represents one of the latest chapters in the history of cryptography. It is currently one of the most popular of encryption standards and, for people involved in any security work, its occurrence on the desktop is frequent. It also enjoys the free marketing and acceptance that it received when it was awarded the title of official cryptography standard in 2001 [7]. This designation went into effect in May of the following year.
Similarly to DES, AES encrypts plaintext in a series of rounds, involves the use of a key and block sizes, and leverages substitution and permutation boxes. It differs from DES in the following respects:
• It supports 128-bit block sizes.
• The key schedule is based on the S-box.
• It expands the key, not the plaintext.
• It is not based on a Feistel cipher.
• It is extremely complex.
The AES algorithms are to symmetric ciphers what a bowl of spaghetti is to the shortest distance between two points. Through a series of networked XOR operations, key substitutions, temporary variable transformations, increments, iterations, expansions, value swapping, S-boxing, and the like, a very strong encryption is created that, with modern computing, is impossible to break. It is conceivable that, with so complex a series of operations, a computer file and block could be combined in such a way as to produce all zeroes. Theoretically, the AES cipher could be broken by solving massive quadratic equations that take into consideration every possible vector and solve 8000 quadratic equations with 1600 binary unknowns. This sort of an attack is called an algebraic attack and, where traditional methods such as differential or differential cryptanalysis fail, it is suggested that the strength in AES lies in the current inability to solve supermultivariate quadratic equations with any sort of efficiency.
Reports that AES is not as strong as it should be are likely, at this time, to be overstated and inaccurate, because anyone can present a paper that is dense and difficult to understand and claims to achieve the incredible [8]. It is unlikely that, any time in the near or maybe not-so-near future (this author hedges his bets), AES will be broken using multivariate quadratic polynomials in thousands of dimensions. Mathematica is very likely one of the most powerful tools that can solve quadratic equations, and it is still many years away from being able to perform this feat.
References
[1] www.etymonline.com.
[3] Wikipedia, Gilbert Vernam entry.
[4] Adrian Fleissig is the Senior Economist of Counsel for RGL Forensics, 2006–present. He is also a Full Professor, California State University Fullerton (CSUF) since 2003 with a joint Ph.D. in Economics and Statistics. North Carolina State University; 1993.
[5] Barrett, Stenner. The myth of the exclusive “Or”. Mind 1971;80(317):116–21.
[6] Sorkin A. LUCIFER: A cryptographic algorithm. Cryptologia 1984;8(1):22–35.