
| Tip 4 | Tame Complexity |
 | [White Belt] You’ll be dealing with complex code from day one. |
If you’ve never met a program you couldn’t understand, you haven’t been programming long enough. In industry, it won’t be long before you run into a mind-bogglingly gnarly mess of code: The Behemoth, The Spaghetti Factory, The Legacy System from Hell. I once inherited a program whose previous owner, upon hearing that he’d have to add a substantial new feature, quit his job instead. (And I couldn’t blame him.)
Complexity in software systems is unavoidable; some problems are just hard, and their solutions are complex. However, much of the complexity you find in software is a mess of our own making. In his book The Mythical Man-Month [Bro95], Fred Brooks separates the two sources of complexity into necessary and accidental complexity.
Here’s a way to think about the difference between necessary and accidental complexity: what complexity is inherent in the problem domain? Say you’re faced with a program that has date/time-handling code scattered all over the place. There’s some necessary complexity when handling time: months have different numbers of days, you have to consider leap years, and so forth. But most programs I’ve seen have loads of accidental complexity relating to time: times stored in different formats, novel (and buggy) methods to add and subtract times, inconsistent formats for printing times, and much more.
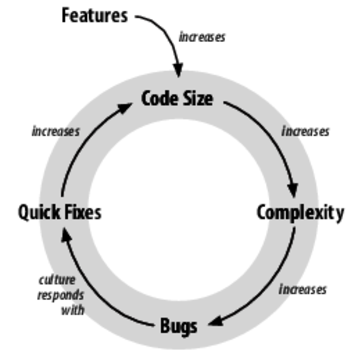
Figure 1. The complexity death spiral
The Complexity Death Spiral
It’s very common in programming that the accidental complexity in a product’s code base gradually overwhelms the necessary complexity. At some point, things devolve into a self-amplifying phenomenon that I call the complexity death spiral, illustrated in Figure 1, The complexity death spiral.
Problem 1: Code Size
As you build a product, its code size will grow vastly beyond any school or hobby project. Code bases in industry are measured in thousands to millions of lines of code (LOC).
In Lions’ Commentary on UNIX 6th Edition [Lio77], John Lions commented that 10,000 lines of code is the practical limit of program size that a single programmer can understand and maintain. UNIX 6th Edition, released back in 1975, weighed in at 9,000 LOC (minus machine-specific device drivers).
By comparison, in 1993 Windows NT had 4 to 5 million lines of code. Ten years later, Windows Server 2003 had 2,000 developers and 2,000 testers who managed a whopping 50 million LOC.[6] Most industry projects aren’t as big as Windows, but they’re well past the 10,000 mark that Lions drew in the sand. This scale means that there is nobody in the company who understands the whole code base.
Problem 2: Complexity
As products grow in size, the conceptual elegance of the original idea gets lost. What was once a crystal-clear idea to the two guys in their garage becomes a murky swamp with dozens of developers wading through it.
Complexity does not necessarily follow code size; it is possible for a large code base to be broken into many modules, each with a clear purpose, elegant implementation, and well-known interactions with neighboring modules.
However, even well-designed systems become complex when they become large. When no single person can understand the whole system, then by necessity multiple people must each keep their idea of their piece of the system in their head—and nobody has exactly the same idea.
Problem 3: Bugs
As the product soars in complexity, bugs inevitably come along for the ride. No way around it—even great programmers aren’t perfect. But not all bugs are created equal: the ones in a highly complex system are especially nasty to track down. Ever hear a programmer say, “I dunno, man, the system just crashed.” Welcome to debugging in hell.
Problem 4: Quick Fixes
The question isn’t whether the product will have bugs or not—it will. The question is how the engineering team responds. Under pressure to get the product out the door, all too often programmers resort to quick fixes.
The quick fix patches over the problem rather than addresses the root cause. Often the root cause isn’t even found. Here’s an example:
- PROGRAMMER:
-
The program crashes when it tries to put a job on the network queue but the queue doesn’t respond within ten seconds.
- MANAGER:
-
Make it retry the queue operation a hundred times.
What’s the root cause? Who knows, with enough retries you can patch over just about anything. But as with auto body repair, at some point there’s more Bondo than actual car left.
The more insidious problem is that when a fix doesn’t address the root cause of a problem, the problem usually doesn’t go away at all—it just moves somewhere else. In the previous dialogue, perhaps retrying a hundred times covers up the problem pretty well, but what happens when 101 retries are needed? The manager just pulled the number out of thin air, and the Bondo fix just made the problem harder to see.
Pile on the quick fixes, and now we’ve come full-circle to increased code size.
Toward Clarity
When people think of the opposite of complex, they usually think simple. However, because of the necessary complexity of our field, we can’t always write simple code. The better opposite of complex is clear. Is it clear to the reader what your code is doing?
Two facets to clarity help us reduce accidental software complexity: clarity of thought and clarity of expression.
Clear Thought
When we reason about a problem, we seek to make a clear statement like “There should be exactly one way to store a time.” Why, then, does Unix C code have a mix of time structures like time_t, struct timeval, and struct timespec?[8] That’s not so clear.
How do you reconcile your clear statement with the complexity of Unix timekeeping? You need to fence off the complexity, or abstract it into a single module. In C this might be a structure and functions that operate on it; in C++ it would be a class. Modular design allows the rest of your program to reason about time in a clear manner without knowing the innards of the system’s timekeeping.
Once you can reason about time as a separate module of your program, you can also prove that your timekeeping is correct. The best way to do this is with separate tests, but a peer review or written specification would also work. It’s far easier to test and rigorously prove a chunk of logic when it’s separate than when it’s embedded in a larger body of code.
Clear Expression
As you think clearly about a module and isolate it from the rest of your program, the resulting program also expresses its purpose more clearly, too. Your code dealing with the problem domain should truly focus on the problem domain. As you pull secondary code out into its own modules, the remaining logic should read more and more like a specification of the problem domain (though perhaps with more semicolons).
Let’s look at a before-and-after comparison. I’ve seen this kind of C++ code numerous times:
| Time.cpp | |
| | void do_stuff_with_progress1() |
| | { |
| | struct timeval start; |
| | struct timeval now; |
| | |
| | gettimeofday(&start, 0); |
| | // Do stuff, printing a progress message |
| | // every half second |
| | while (true) { |
| | struct timeval elapsed; |
| | gettimeofday(&now, 0); |
| | timersub(&now, &start, &elapsed); |
| | |
| | struct timeval interval; |
| | interval.tv_sec = 0; |
| | interval.tv_usec = 500 * 1000; // 500ms |
| | |
| | if (timercmp(&elapsed, &interval, >)) { |
| | printf("still working on it...
"); |
| | start = now; |
| | } |
| | // Do stuff... |
| | } |
| | } |
The point of the loop is the “do stuff” part, but there’s twenty lines of POSIX timekeeping gunk before you ever get there. There’s nothing incorrect about it, but…ugh. Isn’t there a way to keep the loop focused on its problem domain rather than timekeeping?
Let’s pull all the time gunk into its own class:
| Time.cpp | |
| | class Timer |
| | { |
| | public: |
| | Timer(const time_t sec, const suseconds_t usec) { |
| | _interval.tv_sec = sec; |
| | _interval.tv_usec = usec; |
| | gettimeofday(&_start, 0); |
| | } |
| | |
| | bool triggered() { |
| | struct timeval now; |
| | struct timeval elapsed; |
| | |
| | gettimeofday(&now, 0); |
| | timersub(&now, &_start, &elapsed); |
| | |
| | return timercmp(&elapsed, &_interval, >); |
| | } |
| | |
| | void reset() { |
| | gettimeofday(&_start, 0); |
| | } |
| | |
| | private: |
| | struct timeval _interval; |
| | struct timeval _start; |
| | }; |
Now we can simplify the loop:
| Time.cpp | |
| | void do_stuff_with_progress2() |
| | { |
| | Timer progress_timer(0, 500 * 1000); // 500ms |
| | |
| | // Do stuff, printing a progress message |
| | // every half second |
| | while (true) { |
| | if (progress_timer.triggered()) { |
| | printf("still working on it...
"); |
| | progress_timer.reset(); |
| | } |
| | |
| | // Do stuff... |
| | } |
| | } |
The computer is doing the same stuff in both cases, but consider what the second example does for the program’s maintainability:
-
The Timer class can be tested and proven independent of its use in the program.
-
The timekeeping in the “do stuff” loop has meaningful semantics—triggered and reset—rather than a bunch of get, add, and compare functions.
-
It’s now clear where the timekeeping ends and the (fictional) meat of the loop begins.
As you work on code that’s big and gnarly, consider this for each part: what is this code trying to say? Is there a way to say it more clearly? If it’s a problem of clear expression, you may need to abstract out the bits that are getting in the way, as with the Timer class shown earlier. If the code is still a mess, it may be the product of unclear thought, and that needs rework at the design level.
Actions
Focus on one aspect of programming—like timekeeping—that can be isolated and reasoned about rigorously. Dig through the project you’re working on and identify places where the code could be made clearer if that logic was abstracted into its own module.
Try your hand at a more modular approach: take a couple places where things are messy and separate the necessary complexity from the accidental complexity. Don’t sweat the details at this point; just see how clearly you can express the necessary business logic, with the assumption that you have separate modules to handle the supporting logic.