
5
Data Warehouse Appliances
By Anupama Nithyanand & Sundara Rajan PA
Data warehouse appliances have existed as long as database systems. But they were restricted to rather a niche application of very large business’ analytics rather than common main stream enterprises. With the proliferation of automated business systems and increased computational and storage power for the operations, the consequent rise in data volumes have warranted these once niche players into a main stream trend. The current approach is to usher in these appliances as edge components in the enterprise data architecture. This paper provides an overview of the technologies and a guideline to achieving maturity in appliance adoption.
Introduction
The value of data in decision making is becoming more relevant. The challenge in turning around data into decision is three fold. First is the increasing volume of data both inside and outside the enterprise. Second is the increasing complexity of analysis with sophisticated algorithms and models to draw new kinds of insight. Third is the operational intelligence for everyone touched by the enterprise.These three factors of complexity in data volume, computing algorithms and stakeholder base (as shown in Figure 1) work against the market forces of reduced time for decision making to survive among the competition and customers.
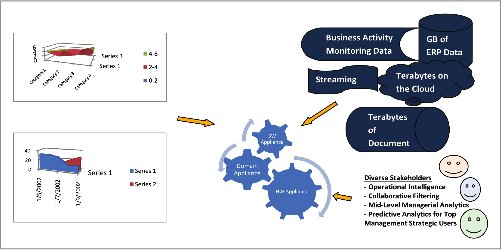
The industry is responding with various innovations in the hardware, software, data gathering, modeling, structuring and processing techniques to address this challenge.
The latency in decision making is partly due to pre-processing necessary in a conventional data warehouse methodology. The other reason is due to decreasing throughput response times in complex analytical queries, and data mining algorithms which do not scale well as the volume of data explodes beyond a threshold value.
Enterprise Appliance Strategy has two approaches:
- Hardware appliances
- Software appliances
| Hardware Appliances | Software Appliances |
|---|---|
| Black Box Plug and Play Operations | Scalable across commodity hardware |
| Single Vendor or Bundled by lead vendor | Configurable Components |
| Complete Support from Vendor | Choice in variations in Configurations |
| Stuck with Vendor, Hardware and other investments | Hardware can be repurposed |
Architectural Drivers and Trade-Offs
The Architectural drivers and Trade-Offs involved in choosing a Data Warehouse appliance are
- The Architectural Drivers
- Real Time Information
- Operational Intelligence for everyone, not only for Strategy and Tactical, but operational as well.
- Intelligence not only for enterprise users, but also for customers in choosing their products.
- Enterprise Search
- Do more with less by Open Source Cost Reduction
- Data on the Cloud
- Contextual Information - Context aware (location, time, identity, activity) – Process Intelligence
- Unstructured Data
- The Trade-Offs between the choices
- Generic Appliance or Domain Specific (both Vertical Domain as in Financial Analysis for Capital Markets, or horizontal domains like Systems log Analytics)
- For the Data Warehouse or Data Mart
- For the Corporate or for a Department
- Single Vendor Black Box or Best of Breed
- Assemble yourself or Lead Vendor assembling for the conglomerate
- Hardware or Software Appliance
- Single Upfront Investment or Pay as you use
Thus there are several questions that the architect needs to answer in choosing an approach for appliance.
Data Warehouse Appliances Trends and Techniques
Data Warehouse Appliances are special purpose machines which are custom built with various combinations of patented hardware and software innovations along with a few commodity hardware and software components.
The industry offering varies with variants in what gets custom built, and what is commodity, where the performance gain is targeted, and what are the various computing and storage styles. We broadly see five types of configurations.
First, is the paradigm where query moves towards data, instead of shipping data to the query. Some of them use Massively Parallel Processing (MPP) Architectures, and some of them use Field Programmable Gate Arrays (FPGA) which doubles as disk controller to make the disks SQL aware. This technique is largely hardware based.
Second, we see parallelizing using algorithms like Map Reduce. Third, we see parallel programming paradigm making use of multi-core processors.
Fourth, we see columnar storage engines. Extreme compression is also used to deliver business analytics at the client applications. Fifth we have open source software implementations. Finally, there are many others that use a combination of all the above like a columnar, MPP database.
High Performance Techniques
Generally the following are used:
- Sequential Processing instead of Random access in case of Disk I/Os.
- In-memory processing instead of Disk I/Os.
- Solid State Disks (memory based) instead of mechanically driven Hard Disks.
- Column stores instead of Row stores for Analytics Data.
- Heavy Compression Technologies.
- Bringing Query to the Data.
- Streaming Data through the Query.
- Alternative Shared Nothing and Parallel Architectures (Multi-core, Many-core, Cluster, Non-Uniform Memory Access (NUMA), Massively Parallel Processors (MPP), and GRID) to Linear Models.
- Parallel Algorithms like Map Reduce or Data Flow Frameworks
Work is also done outside of the database to co-ordinate queries across nodes, exploit parallelism, maximize interconnect performance, etc.
Smart Queries
Rather than moving data into memory or across the network for processing, disk controllers do basic processing as data is read off the disk, filtering records and delivering only the relevant information. Database query functions like parsing, filtering, and projecting are run at full disk reading speed. Data flows from disk to memory in a stream and not in disjointed steps requiring materializing partial results. The I/O memory bus on the host computers are used only for assembling final results.
Columnar Databases
The columnar architecture enables:
- Aggressive data compression techniques like run-length encoding.
- Multiple physical sort orders.
- Automatic log-less recovery by query.
- High availability without hardware redundancy.
- Column values are linked into rows implicitly based on the relative position of values in each column.
SQL Accelerators
To execute queries in parallel to accelerate execution time. File Systems with indexes are used to store transaction data for search retrieval for compliance needs since such applications do not need a database with locking, recovery etc. Domain specific applications like pricing also exist for an industry vertical domain developed by experts who have a very long experience in developing and testing models weathered over many highs and lows of business cycles. Open source players provide service through cloud especially viable for startups to load their data, process it on the cloud, and the results back.
Early Adoption Challenges and Benefits
The challenges are both for traditional control centric enterprises as well as federated enterprises.
The control centric enterprises are accustomed to a single Enterprise Data Warehouse aligned with multiple domain specific data marts.
The federated, empowered enterprise is a loose conglomerate of independently run business units with each having their data marts sharing a few key dimensions to logically form a corporate data warehouse formation.
- The Total Cost of Ownership (TCO) of the hardware and software appliances, additional facilities to host, maintain, cool, bureaucracy for approvals.
- Finding people with new technology expertise to host, develop, maintain, and deliver the systems and applications would be very hard, especially if the appliance is a niche player.
- Setting the expectations of stakeholders and growing with them in maturity to understand the requirements, usage and administration for the new adopter.
- How to roll out the appliances targeting the most value to be delivered first? Here again the first one to get it runs the risk of being on the bleeding edge, at the same time, reaping the reward of being the pioneer in getting the early edge over the others.
- How to scale it across the enterprise? While this may be a challenge - they might actually reap the benefits of costs involved in order bulk for the entire enterprise from that vendor, and also progressively leveraging their maturity in the know-how of usage of this technology.
- In case of bottom-up data marts, their unique challenge could be that only the department which sees the opportunity has to cough up the entire TCO. If there is an earlier implementation in the enterprise, it could benefit from their inside experience and knowledge. Although, they may not have the problem of scaling, and deciding who else to roll out to – since it is limited to within their department.
The ways to counter these challenges are to prepare a business case of lost opportunities, and it’s potential.
As is the case emerging, any enterprise needs to have something unique to offer to stay ahead in the market space. That unique insight is derived from the collective intelligence of so many points of data that are collected from various stakeholders, points of sale, geographies, logistics and vendors. Combined with other factors like budget, competition, etc, there can be a balanced score card of departments that would benefit most with most value delivered. The organization should take that cue card to implement the program in stages.
The advantages of going the appliance way are:
- Early experience to get the feet wet in the new appliance arena, since this is not something that can be ignored. Eventually when we have to switch to these technologies, we should not be caught unawares.
- Getting an edge over the competition in getting strategic information quickly. In many cases, domain vertical/industry specific patented algorithms and models can really make or break a business by providing predictive analytics and strategic decisions which will many times pay over the expense of appliance approach.
- The maturity in understanding the potential and the uses of appliances might trickle down to adoption in other important areas.
Architectural Trends for Enterprise Integration
The Enterprise Data Warehouse (EDW) is normally augmented with multiple Data Marts, Analytical Engines, and On Line Analytical Processors (OLAP) Servers. Also peer-to-peer data marts which form a logical data warehouse through shared dimensions also exist. The Enterprise Data Warehouse needs a central database staging area for getting all the data together to cleanse it as part of the Extract-Transform-Load (ETL) process.
In other scenarios, very specialized functions have their unique domain specific analytics coded and optimized for performance for that specific type of data. The Data Warehouse or Data Mart feeds these specialized appliances and get the results out.
Dual BI Architectures to cater to both power users and casual users have crossed the minds of some who not long ago witnessed the best practice of not mixing On Line Transaction Processing (OLTP) ad reporting workloads, thereby heralding Data Warehouses, Operational Data Stores, Data Marts, etc. While the casual users use regular reporting, the power users run ad-hoc reports warranting a separate analytic architecture, apart from the regular DW/Data Mart which supply the regular reports.
High performance analytics are often off-loaded from Enterprise Data Warehouse for Pattern and Time Series Analyses. Data Mining operations, simulations, optimization and complex data profiling and transformations are good candidates to warrant deployment on a separate analytic appliance.
They can be
- Physical sandbox as a separate DW appliance to off load heavy duty analytics.
- Virtual sandbox inside the Enterprise DW
- Desktop sandbox using in-memory databases
There are various configurations that an architect can arrive at by choosing a mix and match of the best of breed appliances to suit special purposes.
Depending on the type of data like transactions, archives, records, log data – a combination of analytical appliance components can be chosen to architect a cost-effective, scalable, energy-efficient, and most performant Enterprise Data Architecture portfolio of building blocks to cater to various stakeholders.
Concluding Remarks
While some of the appliances might have broader use in the enterprise, some of them might be very specific and niche. Some of them might be used for pre-processing in the Extract-Transform-Load (ETL) stages, while other might be used for visualization and complex modeling closer to the client side and end users.
The appliances are inter-related in their uses and roles each of them assume in the data warehouse architecture. While some of them could be used as Enterprise Data Warehouses, some of them could double as department specific data marts, and some of them only for say specifically domain specific financial modeling. These interconnects between various roles appliances play to make up the turbo-charged data warehouse architecture to faster deliver the results, need not be done in a big-band approach, but in a phased manner, starting around the niche edges and slowly moving over to the center in tune with the business and changing market place for the smarter enterprise.
References
1. Michael Stonebraker, John Woodfill, Jeff Ranstrom, Margeurite Murphy, Marc Meyer and Eric Allman, University of California, Berkeley, “Performance Enhancements to a Relational Database System”, http://portal.acm.org/citation.cfm?id=319984 - ACM Transactions on Database Systems, Vol. 8, No.2, June 1983
2. Haran Boral, David J. DeWitt, “Database Machines: An idea whose time has passed? A Critique of the future of database machines”, http://www.cs.umd.edu/class/spring2009/cmsc724/database-machines.pdf, Computer Sciences Technical Report #504, July 1983
3. David J. DeWitt, Robert H. Gerber, Goetz Graefe, Michael L. Heytens, Krishna B. Kumar, M.Muralikrishna, “GAMMA - A High Performance Dataflow Database Machine” - Computer Sciences Department, University of Wisconsin http://pages.cs.wisc.edu/~dewitt/includes/paralleldb/vldb86.pdf and published in Proceedings of VLDB 86 Proceedings of the 12th International Conference on Very Large Data bases, http://portal.acm.org/citation.cfm?id=671463, 1986
4. Tyson Condie, Neil Conway, Peter Alvaro, Joseph M. Hellerstein, Khaled Elmeleegy, and Russell Sears, “MapReduce online - In Proceedings of the 7th USENIX conference on Networked systems design and implementation (NSDI′10)”, USENIX Association, Berkeley, CA, USA, 21-21, 2010
5. Omer Trajman (Vertica), Alain Crolotte(Teradata), David Steinhoff(ParAccel), Raghunath Nambiar (Hewlett-Packard), Meikel Poess (Oracle), “Database Are Not Toasters: A Framework for Comparing Data Warehouse Appliances”, http://www.tpc.org/tpctc2009/tpctc2009-04.pdf and www.springerlink.com/content/vh3004748x33j461/. Springer, 2009
6. Greenplum Datasheet, “Greenplum Database 3.2: World’s Most Powerful Analytical Database”, http://www.greenplum.com/pdf/Greenplum_Data_baseDataSheet.pdf
7. MySQL Magazine, “Introducing Kickfire”, http://www.paragon-cs.com/mag/issue4.pdf, Spring 2008
Authors
 |
Anupama Nithyanand ([email protected]) is a Lead Principal in E&R. Data, Architecture, XML and Java Technologies are her areas of interest. |
 |
Sundara Rajan PA ([email protected]) is a Lead in E&R. Data and Architecture are his domains of expertise. He has published newsletters and journal articles on data architecture. |