
CHAPTER 6: The List ADT
© Ake13bk/Shutterstock
This chapter focuses on the List ADT: its definition, its implementation, and its use in problem solving. Lists are one of the most widely used ADTs in computer science, which is only natural given how often we use them in daily life. We make to-do lists, shopping lists, checklists, party invitation lists, and so on. We even make lists of lists!
Lists are extremely versatile ADTs. They are collections—they provide storage for information. They are similar to stacks and queues in that there is an order imposed on their elements, but unlike stacks and queues, they do not impose any limitations on how those elements are added, accessed, or removed. There are even languages in which the list is a built-in structure. In Lisp, for example, the list is the main data type provided by the language.
As you work through the chapter you may occasionally want to review Figure 6.9 in the chapter summary section—a diagram showing the relationships among the major interfaces and classes for our List ADT.
6.1 The List Interface
From a programming point of view a list is a collection of elements, with a linear relationship existing among its elements. A linear relationship means that, at the abstract level, each element on the list except the first one has a unique predecessor and each element except the last one has a unique successor. The linear relationship among list elements also means that each element has a position on the list. We can indicate this position using an index, just like we do with arrays. So in addition to our lists supporting the standard collection operations add, get, contains, remove, isFull, isEmpty, and size, they will support index-related operations.
The elements of a list are indexed sequentially, from zero to one less than the size of the list, just like an array. For example, if a list has five elements, they are indexed 0, 1, 2, 3, and 4. No “holes” are allowed in the indexing scheme, so if an element is removed from the “middle” of a list, other elements will have their indices lowered. We define methods for adding, retrieving, changing, and removing an element at an indicated index, as well as a method for determining the index of an element. Details can be seen in the ListInterface below.
Each method that accepts an index as an argument throws an exception if the index is invalid. Clients must use valid indices—they can determine the range of valid indices by using the size method. Indices go from 0 to (size() - 1). To allow addition of an element to the end of the list, the valid range for add includes size().
We do not define our own exception class to use with the indexed list, because the Java library provides an appropriate exception called IndexOutOfBoundsException. This class extends RuntimeException, so it is unchecked.
Iteration
Because a list maintains a linear relationship among its elements, we can support iteration through the list. Iteration means that we provide a mechanism to process the entire list, element by element, from the first element to the last element. The Java library provides two related interfaces that deal with iteration: Iterable in the java.lang package, and Iterator in java.util.
Our lists will be required to implement the library’s Iterable interface. This inter-face requires a single method, iterator, that creates and returns an Iterator object. Methods that create and return objects are sometimes called Factory methods.
What is an Iterator object? An Iterator object provides the means to iterate through the list. Iterator objects provide three operations: hasNext, next, and remove. When an Iterator object is created it is set to the beginning of the list. Repeated calls on the next method of the object will return elements of the list, one by one. The hasNext method returns true if the iterator object has not yet reached the end of the list. Clients are expected to use hasNext to prevent going past the end of the list during an iteration. The remove method removes the element that was most recently visited. The Iterator implementation keeps track of whatever information is needed to allow efficient removal of that element when requested.
Because our lists implement Iterable, clients can use the iterator method to obtain an Iterator object and then use the Iterator object to iterate through the list. An example should help clarify. Suppose strings is a List ADT object that contains the four strings “alpha,” “gamma,” “beta,” and “delta.” The following code would delete “gamma” from the list and display the other three strings:
Iterator<String> iter = strings.iterator();
String hold;
while (iter.hasNext())
{
hold = iter.next();
if (hold.equals("gamma"))
iter.remove();
else
System.out.println(hold);
}
Note that a client can have several iterations through a list active at the same time, using different Iterator objects.
What happens if the program inserts or removes an element (by a means other than using the current iterator’s remove) in the middle of iterating through the structure? Nothing good, you can be sure! Adding and deleting elements change the size and structure of the list. The results of using an iterator are unspecified if the underlying collection is modified in this fashion while the iteration is in progress.
Java provides an enhanced for loop to use with array or Iterable objects. Referred to as a for-each loop, this version of the for loop allows programmers to indicate that a block of instructions should be executed “for each” of the objects in the array or Iterable object. The following code would display all of the elements of the strings list:
for (String hold: strings) System.out.println(hold);
The for-each loop acts as an abstraction—it hides the use of the Iterator and its hasNext and next methods, making it even easier for us to iterate through a list.
Assumptions for Our Lists
So far we have determined that our lists will be collections and will support both index and iteration-related operations. Before formally specifying our List ADT we complete our informal specification with the following list of assumptions:
Our lists are unbounded. When implementing a list with an array, we use the same approach as with our array-based unbounded queue and collection implementations. That is, if an element is added to a “full” list, then the capacity of the underlying array is increased.
We allow duplicate elements on our lists. When an operation involves “finding” such an element, it can “find” any one of the duplicates. We do not specify any distinction among duplicate elements in these cases, with the exception of one indexed list method (
indexOf).As with our other ADTs, we do not support
nullelements. As a general precondition for all of our list methods,nullelements cannot be used as arguments. Rather than stating this precondition for each method, we state it once in the general list interface.The indices in use for a list are contiguous, starting at 0. If an indexed list method is passed an index that is outside the current valid range, it will throw an exception.
Two of the index-related operations,
addandset, are optional. Both of these operations allow the client to insert an element into a list at a specified index. For some list implementations, notably a sorted list implementation, this could invalidate the internal representation of the list. By indicating that these operations are optional we permit a sorted list implementation to throw an exception if one of these operations is invoked. Our implementations will throw the Java library suppliedUnsupportedOperationExceptionin such cases.
The Interface
Here is the code for our ListInterface. It is part of the ch06.lists package. Note that it extends both our CollectionInterface and the Java library’s Iterable interface—classes that implement ListInterface must also implement those interfaces and therefore must provide operations add, get, contains, remove, isFull, isEmpty, size, and iterate, in addition to the index-related operations specified explicitly in ListInterface. Study the comments and method signatures of the interface, listed below, to learn more about the details of our List ADT.
//--------------------------------------------------------------------------- // ListInterface.java by Dale/Joyce/Weems Chapter 6 // // Lists are unbounded and allow duplicate elements, but do not allow // null elements. As a general precondition, null elements are not passed as // arguments to any of the methods. // // During an iteration through the list the only change that can safely be // made to the list is through the remove method of the iterator. //--------------------------------------------------------------------------- package ch06.lists; import java.util.*; import ch05.collections.CollectionInterface; public interface ListInterface<T> extends CollectionInterface<T>, Iterable<T> { void add(int index, T element); // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index > size(). // Otherwise, adds element to this list at position index; all current // elements at that position or higher have 1 added to their index. // Optional. Throws UnsupportedOperationException if not supported. T set(int index, T newElement); // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index >= size(). // Otherwise, replaces element on this list at position index with // newElement and returns the replaced element. // Optional. Throws UnsupportedOperationException if not supported. T get(int index); // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index >= size(). // Otherwise, returns the element on this list at position index. int indexOf(T target); // If this list contains an element e such that e.equals(target), // then returns the index of the first such element. // Otherwise, returns -1. T remove(int index); // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index >= size(). // Otherwise, removes element on this list at position index and // returns the removed element; all current elements at positions // higher than index have 1 subtracted from their position. }
6.2 List Implementations
In this section we develop an array-based and a link-based implementation of the List ADT. Because a list is a collection the implementations share some design and code with their Collection ADT counterparts. Here we emphasize the new functionality—the indexing and the iteration. The reader may want to review the design and code of the Collection ADT implementations from Chapter 5 before continuing.
Array-Based Implementation
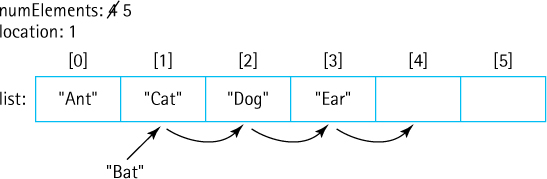
We use the same approach for our array-based list as we did for our array-based collection. Elements are stored in an internal array and an instance variable numElements holds the size of the list. A list of five strings would be represented as:

If a new string is added to the above list it is placed in array slot numElements and then numElements is incremented.
You may recall that when removing an element from an array-based collection we replaced it with the “last” element in the array and decremented numElements:

For a list we cannot use this approach because we must maintain the index order of the remaining elements. Therefore, we use the same approach we did for the sorted array collection:

Here is the beginning of the ABList (Array-Based List) class:
//--------------------------------------------------------------------------- // ABList.java by Dale/Joyce/Weems Chapter 6 // Array-Based List // // Null elements are not permitted on a list. The list is unbounded. // // Two constructors are provided: one that creates a list of a default // original capacity, and one that allows the calling program to specify the // original capacity. //--------------------------------------------------------------------------- package ch06.lists; import java.util.Iterator; public class ABList<T> implements ListInterface<T> { protected final int DEFCAP = 100; // default capacity protected int origCap; // original capacity protected T[] elements; // array to hold this list's elements protected int numElements = 0; // number of elements in this list // set by find method protected boolean found; // true if target found, otherwise false protected int location; // indicates location of target if found public ABList() { elements = (T[]) new Object[DEFCAP]; origCap = DEFCAP; } public ABList(int origCap) { elements = (T[]) new Object[origCap]; this.origCap = origCap; }
As you can see this is very similar to the declarations and constructors of previous array-based implementations of our ADTs. We leave it to the reader to examine the code for the protected helper methods enlarge and find, and the public methods add, remove, contains, get, size, isFull and isEmpty all of which are similar/identical to code we have developed previously.
Index-Related Operations
Now we turn our attention to the five required indexed methods. The four methods that accept an index parameter each follow the same pattern—check the index argument, and if it is outside the allowable range for that operation throw an exception—otherwise carry out the operation. Because of the close logical relationship between the internal representation, an array, and the ADT, an indexed list, the implementation of these operations is very straightforward. Here we examine the code for set:
public T set(int index, T newElement)
// Throws IndexOutOfBoundsException if passed an index argument
// such that index < 0 or index >= size().
// Otherwise, replaces element on this list at position index with
// newElement and returns the replaced element.
{
if ((index < 0) || (index >= size()))
throw new IndexOutOfBoundsException("Illegal index of " + index +
" passed to ABList set method.
");
T hold = elements[index];
elements[index] = newElement;
return hold;
}
Our list indexing starts at 0, just as does our array indexing. So the index argument can simply be used to access the array. The other indexed methods are similar, although of course the add and remove methods require shifting of array elements.
Iteration
Our lists support iteration. They implement the ListInterface that extends the Iterable interface, therefore our list classes must also implement Iterable. The Iterable interface requires a single public method:
Iterator<T> iterator( );
We must design an iterator method that creates and returns an Iterator object. Iterator objects provide three public methods—hasNext, next, and remove. In order for our iterator method to create an Iterator object we must define a new Iterator class that provides these three methods. Where do we put this new class? There are three approaches:
External class. We could create a class that implements
Iteratoras a class in a separate file, for example, theABListIteratorclass. The constructor of this class would accept anABListobject as a parameter. The class should be in thech06. listspackage so that it has access to theprotectedinstance variables ofABList, which it needs to implement the required operations. For example, if the instance variable used to reference theABListobject within the iterator class is namedtheList, theremovemethod might include a line of code liketheList.elements[theList.numElements - 1] = null;
to properly reduce the size of the list after the removal is completed. Note the direct use of the
ABListinstance variableselementsandnumElements. Although we have decided to use a different approach, it is instructive for the reader to study the external class approach—we have included the code forABListIteratorwith the text files. If we did use this approach then the code for theiteratormethod within theABListclass becomes simply:public Iterator<T> iterator() // Returns an Iterator over this list. { return new ABListIterator<T>(this); }Why not use this approach? The greatest drawback is the unusual use of the instance variables of the
ABListclass within the separateABListIteratorclass. Even though the two classes are in the same package this approach goes against the information hiding principles we practice throughout the rest of the text. This strong coupling between two classes that reside in separate files could create issues during later maintenance of theABListclass. We think it is better if the two classes reside in the same file, as is the case with the next two approaches we discuss.Inner class. Rather than creating an
Iteratorclass in an external file we could place all of the code for it inside theABList.javafile. With this approach it is obvious to future maintenance programmers that the two classes are directly related. Furthermore, the inner class can directly access the instance variables of the surrounding class, as it is a member of the surrounding class. With this approach the fragment of code that corresponds to theremovemethod fragment shown before is simplyelements[numElements - 1] = null; and the iterator method becomes public Iterator<T> iterator() // Returns an Iterator over this list. { return new ABListIterator(); }
Anonymous inner class. Java permits programmers to write anonymous classes, classes without names. Instead of defining a class in one place and then instantiating it somewhere else, as is the usual approach, we can define a class exactly at the place in the code where it is being instantiated. Because it is created at the same place it is defined there is no need for a class name. After all, the name is really just used as a connection between the definition and instantiation.
We use this last approach for our required Iterator class, that is, we define it as an anonymous inner class within the iterator method. The only reason we need an Iterator class is so that the iterator method can return it, thus using an anonymous inner class just at the point of need makes sense. The code is shown below. Note that the iterator method essentially consists of the following:
public Iterator<T> iterator()
// Returns an Iterator over this list.
{
return new Iterator<T>()
{
// code that implements an Iterator
};
}
The entire method is listed below—the skeleton view of the method displayed above hopefully helps you to see that an object of type Iterator is being created dynamically and returned by the iterator method.
public Iterator<T> iterator() // Returns an Iterator over this list. { return new Iterator<T>() { private int previousPos = -1; public boolean hasNext() // Returns true if the iteration has more elements; otherwise false { return (previousPos < (size() - 1)) ; } public T next() // Returns the next element in the iteration. // Throws NoSuchElementException - if the iteration has no more elements { if (!hasNext()) throw new IndexOutOfBoundsException("Illegal invocation of next " + " in LBList iterator. "); previousPos++; return elements[previousPos]; } public void remove() // Removes from the underlying representation the last element returned // by this iterator. This method should be called only once per call to // next(). The behavior of an iterator is unspecified if the underlying // representation is modified while the iteration is in progress in any // way other than by calling this method. { for (int i = previousPos; i <= numElements - 2; i++) elements [i] = elements[i+1]; elements [numElements - 1] = null; numElements--; previousPos--; } }; }
The entire implementation of ABList is found in the ch06.lists package.
Link-Based Implementation
As was the case for the array-based approaches, some of the link-based collection implementation design and code can be reused for the link-based list. Here is the beginning of the class, showing the instance variables and constructor:
//--------------------------------------------------------------------------- // LBList.java by Dale/Joyce/Weems Chapter 6 // Link-Based List // // Null elements are not permitted on a list. The list is unbounded. //--------------------------------------------------------------------------- package ch06.lists; import java.util.Iterator; import support.LLNode; public class LBList<T> implements ListInterface<T> { protected LLNode<T> front; // reference to the front of this list protected LLNode<T> rear; // reference to the rear of this list protected int numElements = 0; // number of elements in this list // set by find method protected boolean found; // true if target found, else false protected int targetIndex; // list index of target, if found protected LLNode<T> location; // node containing target, if found protected LLNode<T> previous; // node preceding location public LBList() { numElements = 0; front = null; rear = null; }
All of the instance variables except two have counterparts in the link-based collection implementation of Chapter 5. To support the add method, which adds elements to the end of the list, we maintain a reference rear to the end of the list. Any transformer method must be careful to correctly update both the front and rear references, if appropriate. To support the indexOf method we include a targetIndex variable, which the find method sets, in addition to setting found, location, and previous.
The code for size, get, isEmpty, and isFull is straightforward and is exactly the same as that discussed in Chapter 5 for LinkedCollection. The code for find and remove is also very similar to their linked collection counterparts, although the list find must set the targetIndex variable and the list remove, being a transformer, must update the rear variable under certain conditions. The add method adds the argument element to the end of the list—exactly the same as the enqueue method developed in Chapter 4. The code for all of these methods can be studied by looking at the LBList class in the ch06.lists package.
Index-Related Operations
Here we consider the five required indexed methods. Designing these methods was very easy for the array-based implementation because of the close association between list indices and the underlying array indices. This is not the case for the link-based implementation. When an index is provided as an argument to a method there is only one way to access the associated element—we must walk through the list from the start, the front reference, until we reach the indicated element. For example, here is the code for set:
public T set(int index, T newElement) // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index >= size(). // Otherwise, replaces element on this list at position index with // newElement and returns the replaced element. { if ((index < 0) || (index >= size())) throw new IndexOutOfBoundsException("Illegal index of " + index + " passed to LBList set method. "); LLNode<T> node = front; for (int i = 0; i < index; i++) node = node.getLink(); T hold = node.getInfo(); node.setInfo(newElement); return hold; }
The necessity of walking through the list from the front means that the indexed operation implementations are all going to have O(N) efficiency. If a client is going to use indexing heavily with its lists it might be best for it to use the array-based lists.
The transformer methods that deal with indices, add and remove, are complicated by special cases. For example, the add method follows the same pattern as set; however, the method must take care when adding to the front of list, to the rear of list, or to an empty list:
public void add(int index, T element) // Throws IndexOutOfBoundsException if passed an index argument // such that index < 0 or index > size(). // Otherwise, adds element to this list at position index; all current // elements at that index or higher have 1 added to their index. { if ((index < 0) || (index > size())) throw new IndexOutOfBoundsException("Illegal index of " + index + " passed to LBList add method. "); LLNode<T> newNode = new LLNode<T>(element); if (index == 0) // add to front { if (front == null) // adding to empty list { front = newNode; rear = newNode; } else { newNode.setLink(front); front = newNode; } } else if (index == size()) // add to rear { rear.setLink(newNode); rear = newNode; } else // add in interior part of list { LLNode<T> node = front; for (int i = 0; i < (index – 1); i++) node = node.getLink(); newNode.setLink(node.getLink()); node.setLink(newNode); } numElements++; }
We leave it to the reader to examine the code for the get, indexOf, and remove methods.
Iteration
As we did with the array-based list implementation, we use an anonymous inner class within the iterator method. The instantiated Iterator object keeps track of three instance variables to provide the iteration and to support the required remove operation: currPos references the node that was “just” returned, prevPos references the node before currPos, and nextPos references the node following currPos. For example, if the list contains the strings “Bat,” “Ant,” “Cat,” “Ear,” and “Dog” and an iteration has just returned “Cat,” then the values of the references would be as shown here:

When the Iterator object is instantiated, nextPos is initialized to front and currPos and prevPos are both initialized to null, which properly sets up for the start of the iteration:
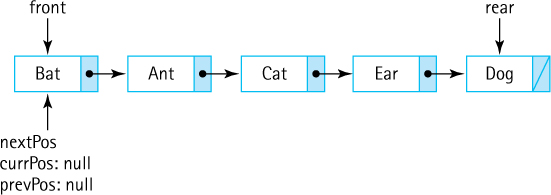
The next method, when invoked, first checks to see if there is a next element to return (if not it throws an exception), then “saves” the information to return, updates all three of the references, and returns the information. See the code below. For example, the first time next is invoked on our sample list it would return the string “Bat” and update the references resulting in this new state:

Recall that if we invoke remove in the middle of an iteration it is supposed to remove the element that was just returned, the element referenced by currPos. It does this by changing the link value of the element before currPos, the element referenced by prevPos. Here is how things would look in our example if the iteration most recently returned “Cat” and remove was then invoked:

Note that remove sets the value of currPos to null, since after removal, the most recent element returned is no longer in the list. This is necessary so the next method does not inappropriately use an “out of date” currPos reference. In the above scenario the node containing “Cat” is potentially garbage and, if so, that memory space will be reclaimed by the Java garbage collector. Here is the iterator code in full. We encourage the readers to trace this code themselves, drawing pictures like those shown here, to validate both the code and their understanding.
public Iterator<T> iterator() // Returns an Iterator over this list. { return new Iterator<T>() { protected LLNode<T> prevPos = null; // node before node just returned protected LLNode<T> currPos = null; // node just returned protected LLNode<T> nextPos = front; // next node to return public boolean hasNext() // Returns true if the iteration has more elements; otherwise false { return (nextPos != null); } public T next() // Returns the next element in the iteration. // Throws NoSuchElementException - if the iteration has no more elements { if (!hasNext()) throw new IndexOutOfBoundsException("Illegal invocation of next " + " in LBList iterator. "); T hold = nextPos.getInfo(); // holds info for return if (currPos != null) prevPos = currPos; // in case element was removed currPos = nextPos; nextPos = nextPos.getLink(); return hold; } public void remove() // Removes from the underlying representation the last element returned // by this iterator. This method should be called only once per call to // next(). The behavior of an iterator is unspecified if the underlying // representation is modified while the iteration is in progress in any // way other than by calling this method. { if (currPos == null) // there is no last element returned by iterator return; else { if (prevPos == null) // removing front element { front = nextPos; currPos = null; if (front == null) // removed only element rear = null; } else { prevPos.setLink(nextPos); currPos = null; } numElements--; } } }; }
The entire implementation of LBList is found in the ch06.lists package.
6.3 Applications: Card Deck and Games
Everyone is familiar with card games: poker, blackjack, hearts, bridge, solitaire, and others. In this section we use our List ADT to support a class that represents a deck of cards, and then use that class in a few sample applications. We create a class that provides a standard deck of 52 playing cards, with ranks of two through ace and the suits clubs, diamonds, hearts, and spades.

© Bardocz Peter/Shutterstock
The Card Class
Before creating the card deck class, which will use our List ADT, we need cards to put into the list—we need a Card class. We place both the Card class and the CardDeck class in the support.cards package. A Card object has two obvious attributes—a rank and a suit. The Card class provides two public enum classes, Rank and Suit, which are in turn used for the card attributes. As the enum classes are public they are available for use by other classes and applications. The Card class also provides an image attribute that lets us associate an image file with each card. The image files are also found in the support.cards package. The card images can be used in graphical programs to provide a realistic look to an application. The rest of the Card class is very straightforward. The card attributes, rank, suit, and image are all set through the constructor—once instantiated a card cannot change—cards are immutable. Three getter methods are provided, along with the standard equals, compareTo, and toString. In many games cards are compared on rank only—we follow that approach.
//---------------------------------------------------------------------- // Card.java by Dale/Joyce/Weems Chapter 6 // // Supports playing card objects having a suit, a rank, and an image. // Only rank is used when comparing cards. Ace is "high". //---------------------------------------------------------------------- package support.cards; import javax.swing.ImageIcon; public class Card implements Comparable<Card> { public enum Rank {Two, Three, Four, Five, Six, Seven, Eight, Nine, Ten, Jack, Queen, King, Ace} public enum Suit {Club, Diamond, Heart, Spade} protected final Rank rank; protected final Suit suit; protected ImageIcon image; Card(Rank rank, Suit suit, ImageIcon image) { this.rank = rank; this.suit = suit; this.image = image; } public Rank getRank() { return rank; } public Suit getSuit() { return suit; } public ImageIcon getImage() {return image;} @Override public boolean equals(Object obj) // Returns true if 'obj' is a Card with same rank // as this Card, otherwise returns false. { if (obj == this) return true; else if (obj == null || obj.getClass() != this.getClass()) return false; else { Card c = (Card) obj; return (this.rank == c.rank); } } public int compareTo(Card other) // Compares this Card with 'other' for order. Returns a // negative integer, zero, or a positive integer as this object // is less than, equal to, or greater than 'other'. { return this.rank.compareTo(other.rank); } @Override public String toString() { return suit + " " + rank; } }
The CardDeck Class
Because we know the exact number of cards in a card deck we use our ABList as the internal representation for the CardDeck class. We can instantiate a list of size 52. Note the use of levels of abstraction here—CardDeck is built on top of ABList and ABList is built on top of an array.
The constructor of the CardDeck class instantiates deck of class ABList<Card> and then uses a double for loop, iterating through all combinations of Suit and Rank, to add the desired cards to the deck. The card image files can be identified by manipulating the string representation of suit and rank; as the cards are thereby added to the deck, they are also associated with the appropriate image.
A second instance variable, deal, provides a Card iterator—one that simulates dealing the deck of cards. Creating deal is easy—we just call the iterator method of the deck object. Do not forget, deck is an ABList object and therefore provides an iterator method. Managing the deck and dealing cards is accessed through the public CardDeck methods hasNextCard and nextCard, both of which call the appropriate method of the deal iterator. In addition to creating the deck of cards the constructor initializes deal.
As you can see, the CardDeck class allows an application to “shuffle” the deck of cards. The shuffle algorithm is the same one used by the Java library Collections class. It works through the deck backward, selecting a random position from the preceding portion of the deck, and swaps the card at that position with the card at the current position. To select a random position it uses the Java library’s Random class. The call to rand. nextInt(i) returns a random integer between 0 and i—1. Because the Random class does such a good job with randomization there is no need to “shuffle” the deck multiple times—once is enough. After the cards are shuffled a new deal object is created—one that is all set to deal from the reshuffled deck.
//---------------------------------------------------------------------- // CardDeck.java by Dale/Joyce/Weems Chapter 6 // // Models a deck of cards. Includes shuffling and dealing. //---------------------------------------------------------------------- package support.cards; import java.util.Random; import ch06.lists.ABList; import javax.swing.ImageIcon; public class CardDeck { public static final int NUMCARDS = 52; protected ABList<Card> deck; protected Iterator<Card> deal; public CardDeck() { deck = new ABList<Card>(NUMCARDS); ImageIcon image; for (Card.Suit suit : Card.Suit.values()) for (Card.Rank rank : Card.Rank.values()) { image = new ImageIcon("support/cards/" + suit + "_" + rank + "_RA.gif"); deck.add(new Card(rank, suit, image)); } deal = deck.iterator(); } public void shuffle() // Randomizes the order of the cards in the deck. // Resets the current deal. { Random rand = new Random(); // to generate random numbers int randLoc; // random location in card deck Card temp; // for swap of cards for (int i = (NUMCARDS - 1); i > 0; i--) { randLoc = rand.nextInt(i); // random integer between 0 and i - 1 temp = deck.get(randLoc); deck.set(randLoc, deck.get(i)); deck.set(i, temp); } deal = deck.iterator(); } public boolean hasNextCard() // Returns true if there are still cards left to be dealt; // otherwise, returns false. { return (deal.hasNext()); } public Card nextCard() // Precondition: this.hasNextCard() == true // // Returns the next card for the current 'deal'. { return deal.next(); } }
Application: Arranging a Card Hand
Our first example use of the CardDeck class, CardHandCLI, is a command line interface program that uses the class to generate one five-card hand of playing cards, and allows the user to arrange the cards in the order they prefer. In addition to using the CardDeck class we use an ABList of Card to hold and manage the hand. As cards are dealt one by one the hand, as arranged so far, is displayed using a for each loop (which is only possible because ABList implements Iterable), and the user can indicate where they want the next card placed. The indexed-based add method is then used to place the card in the correct slot.
//--------------------------------------------------------------------- // CardHandCLI.java by Dale/Joyce/Weems Chapter 6 // // Allows user to organize a hand of playing cards. // Uses a command line interface. //---------------------------------------------------------------------- package ch06.apps; import java.util.Scanner; import java.util.Iterator; import ch06.lists.*; import support.cards.*; public class CardHandCLI { public static void main(String[] args) { Scanner scan = new Scanner(System.in); final int HANDSIZE = 5; int slot; Card card; // playing card CardDeck deck = new CardDeck(); // deck of playing cards ListInterface<Card> hand = new ABList<Card>(HANDSIZE); // user's hand deck.shuffle(); hand.add(deck.nextCard()); // deals 1st card and places into hand for (int i = 1; i < HANDSIZE; i++) { System.out.println(" Your hand so far:"); slot = 0; for (Card c: hand) { System.out.println(slot + " " + c); slot++; } System.out.println(slot); card = deck.nextCard(); System.out.print("Slot between 0 and " + i + " to put " + card + " > "); slot = scan.nextInt(); hand.add(slot, card); } System.out.println(" Your final hand is:"); for (Card c: hand) System.out.println(" " + c); } }
sample run of the program is:
Your hand so far: 0 Six of Clubs 1 Slot between 0 and 1 to put Nine of Diamonds > 1 Your hand so far: 0 Six of Clubs 1 Nine of Diamonds 2 Slot between 0 and 2 to put Five of Diamonds > 0 Your hand so far: 0 Five of Diamonds 1 Six of Clubs 2 Nine of Diamonds 3 Slot between 0 and 3 to put Ace of Clubs > 3 Your hand so far: 0 Five of Diamonds 1 Six of Clubs 2 Nine of Diamonds 3 Ace of Clubs 4 Slot between 0 and 4 to put Nine of Clubs > 2 Your final hand is: Five of Diamonds Six of Clubs Nine of Clubs Nine of Diamonds Ace of Clubs
Readers who are familiar with the game of poker will recognize this hand as a “Pair of Nines.” Is that good? We will investigate that question in a subsection below.

Figure 6.1 Sample screenshot of CardHandGUI in action
© Bardocz Peter/Shutterstock
In addition to the CardHandCLI program we also created CardHandGUI. It provides identical functionality, featuring a graphical user interface. A screenshot of the program is displayed in Figure 6.1. Another “Pair of Nines”! Interested readers are encouraged to examine the code, found in the ch06.apps package.
Application: Higher or Lower?
To further demonstrate the use of the CardDeck and Card classes, in particular card comparison, we develop a very simple interactive card game.
The game “Higher or Lower?” can be defined in one sentence. You are dealt a card from a deck of cards and you must predict whether or not the next card dealt will have a higher or lower rank. That is it—here is the application:
//-------------------------------------------------------------------- // HigherLower.java by Dale/Joyce/Weems Chapter 6 // // Plays Higher or Lower? with user through command line interface. //-------------------------------------------------------------------- package ch06.apps; import support.cards.*; // Card, CardDeck import java.util.Scanner; public class HigherLower { public static void main(String[] args) { Scanner scan = new Scanner(System.in); char reply; Card card1, card2; CardDeck deck = new CardDeck(); deck.shuffle(); System.out.println("Welcome to "Higher or Lower". Good luck!"); // First card card1 = deck.nextCard(); System.out.println(" First Card: " + card1); // Get prediction System.out.print("Higher (H) or Lower (L)? > "); reply = scan.nextLine().charAt(0); // Second card card2 = deck.nextCard(); System.out.println(" Second Card: " + card2); // Determine and display results if ((card2.compareTo(card1) > 0) && (reply == 'H')) System.out.println("Correct"); else if ((card2.compareTo(card1) < 0) && (reply == 'L')) System.out.println("Correct"); else System.out.println("Incorrect"); } }
And a sample run:
Welcome to "Higher or Lower". Good luck!
First Card: Nine of Diamonds
Higher (H) or Lower (L)? > L
Second Card: Seven of Spades
Correct
Application: How Rare Is a Pair?
This example shows how to use program simulation to help verify formal analysis, and vice versa. Five-card stud is a popular poker game. Each player is dealt five cards from a standard 52-card playing deck. The player with the best hand wins. As you know playing cards have two qualities: suit (Club, Diamond, Heart, and Spade) and rank (Two through Ace). Hands are rated, from best to worst, as follows:
Royal Flush All cards of the same suit. Ranks from 10 through Ace.
Straight Flush All cards of the same suit. Rank in sequence.
Four of a Kind Four cards with the same rank.
Full House Three cards of one rank, and two cards of a second rank.
Flush All cards of the same suit.
Straight All cards with ranks in sequence (e.g., 4-5-6-7-8). Note that Ace can be used low or high.
Three of a Kind Three cards with the same rank.
Two Pair Two sets of cards of the same rank (e.g., 8-8-3-3-9).
One Pair Two cards of the same rank.
High Card If we have none of the above, the highest-ranking card in our hand is the “high card.”
To help us understand the game of poker, we want to know the probability, when dealt a random five-card hand, that we get at least two cards of the same rank. We are not concerned with straights and flushes; we are only concerned with getting cards of the same rank.
There are two approaches to investigate this question: We can analyze the situation mathematically or we can write a program that simulates the situation. Let us do both. We can then compare and verify our results.
First we use the mathematical approach. The analysis is simplified by turning the question around. We figure out the probability (a real number in the range from 0 to 1) that we do not get two cards of the same rank, and then subtract that probability from 1 (which represents absolute certainty).
We proceed one card at a time. When we are dealt the first card, what is the probability we do not have two cards of the same rank? With only one card, it is certain that we do not have a matching pair! We calculate this fact mathematically by using the classic probability formula of number of favorable events ÷ total number of possible events:

There are 52 total possible cards from which to choose, and picking any of the 52 has the desired “favorable” result (no matches). The probability we have a pair of matching cards is thus 1 – 1 = 0 (impossible). It is impossible to have a pair of matching cards when we have only one card. Why do we need this mathematical complexity to say something that is so obvious? Because it acts as a foundation for our continuing analysis.
Now we are dealt the second card. The first card has some rank between two and ace. Of the 51 cards that are still in the deck, 48 of them do not have the same rank as the first card. Thus there are 48 chances out of 51 that this second card will not match the first card. To calculate the overall probability of two sequential events occurring, we multiply their individual probabilities. Therefore, after two cards the probability that we do not have a pair is

At this point, the probability that we do have a pair is approximately 1 – 0.941 = 0.059.
For the third card dealt, there are 50 cards left in the deck. Six of those cards match one or the other of the two cards previously dealt, because we are assuming we do not have a pair already. Thus there are 44 chances out of 50 that we do not get a pair with the third card, giving us the probability

Continuing in this way we get the following probability that we do not have a pair of matching cards after five cards are dealt:

Therefore, the probability that we get at least two matching cards is approximately 1 – 0.507 = 0.493. We should expect to get at least one pair a little less than half the time.
Now we address the same problem using simulation. Not only does this endeavor help us double-check our theoretical results, but it also helps validate our programming and the random number generator used to simulate shuffling the cards.
We create a program that deals 1 million five-card poker hands and tracks how many of them have at least one pair of identical cards. We use our CardDeck class to provide the deck of cards and, as we did in the previous example application, we represent the poker “hand” with a list of Card objects.
Our approach is to reshuffle the cards for every new hand. As cards are dealt, they are placed in a hand list. For each new card, we check the list to see whether an equivalent card is already in hand. Recall that card equality is based on the rank of the cards. Here is the Pairs application:
//--------------------------------------------------------------------- // Pairs.java by Dale/Joyce/Weems Chapter 6 // // Simulates dealing poker hands to calculate the probability of // getting at least one pair of matching cards. //---------------------------------------------------------------------- import ch06.lists.*; import support.cards.*; // Card and CardDeck public class Pairs { public static void main(String[] args) { final int HANDSIZE = 5; // number of cards per hand final int NUMHANDS = 1000000; // total number of hands int numPairs = 0; // number of hands with pairs boolean isPair; // status of current hand float probability; // calculated probability Card card; // playing card CardDeck deck = new CardDeck(); // deck of playing cards ListInterface<Card> hand = new ABList<Card>(HANDSIZE); // the poker hand for (int i = 0; i < NUMHANDS; i++) { deck.shuffle(); hand = new ABList<Card>(HANDSIZE); isPair = false; for (int j = 0; j < HANDSIZE; j++) { card = deck.nextCard(); if (hand.contains(card)) isPair = true; hand.add(card); } if (isPair) numPairs = numPairs + 1; } probability = numPairs/(float)NUMHANDS; System.out.println(); System.out.print("There were " + numPairs + " hands out of " + NUMHANDS); System.out.println(" that had at least one pair of matched cards."); System.out.print("The probability of getting at least one pair,"); System.out.print(" based on this simulation, is "); System.out.println(probability); } }
As we have seen several times before, the use of predefined classes, such as our ABList class and our CardDeck class, makes programming much easier. Here is the result of one run of this program:
There were 492709 hands out of 1000000 that had at least one pair of matched cards. The probability of getting at least one pair, based on this simulation, is 0.492709
This result is very close to our theoretical result. Additional program runs also produced acceptably close results.
6.4 Sorted Array-Based List Implementation
Many of the lists we use every day are sorted lists. A “To-Do” list is sorted from most important to least important, a list of students is likely to be in alphabetical order, and a well-organized grocery list is sorted by store aisle. Considering how common it is for us to work with sorted lists, it is a good idea to create a version of our List ADT where the elements are kept in sorted order. We will call our new array-based class SortedABList. Like ABList and LBList, SortedABList implements ListInterface.
In Section 5.5, “Sorted Array-Based Collection Implementation,” we designed and coded a collection class whose internal representation was a sorted array. Our goal then was to increase the efficiency of the find operation, which gave us a much more efficient contains method (O(log2N) versus O(N)) and also improved the efficiency of several other operations. Here our goal is to be able to present a sorted list to the client—when they iterate through the list they know it will be presented to them in sorted order. We use the same basic approach to maintaining sorted order as we did for the sorted collection, and we do achieve most of the same efficiency benefits. Much of the design and code of the SortedArrayCollection from the ch05.collections package can be reused.
The Insertion Sort
Let us say the following four elements have previously been added to our list: “Cat,” “Ant,” “Ear,” and “Dog.” Because the list is being kept sorted its internal representation would be

Suppose now a new string “Bat” is added to the list. The add method invokes the find method that efficiently determines where the new element should be inserted. In this case the element belongs at index 1 so the find method sets the value of the instance variable location to 1 and then the add method proceeds to shift the necessary elements and insert “Bat” into the newly opened slot at index location:
Because this same approach is used every time an element is added to the list, the list is maintained in sorted order.
The approach described above is actually a well-known sorting algorithm called Insertion Sort. Suppose we have a set of N elements that we wish to sort. We can instantiate a SortedABList object and repeatedly add the elements to it. As each successive element is added to the list, it is inserted into its proper place with respect to the other, already sorted elements. After all of the elements have been added we can iterate through the list to retrieve the elements in sorted order.
What is the order of growth efficiency for Insertion Sort? When we add an element to the list we may have to shift previously added elements one slot in order to make room for the new element. In the worst case when the new element is the “smallest” of the elements added so far—for example, consider adding “Aardvark” to the list shown above—we have to shift all of the current elements. If we are very unlucky and our original set of elements is presented to us in reverse order, then each time we add an element all of the previous elements need to be shifted.
Shifting an element in the array and copying in the newly added element both are carried out with an assignment statement. So we can consider the assignment statement a fundamental operation for the Insertion Sort algorithm. We will count how many assignment statements are needed in the worst case scenario, and we will call the use of the assignment statement a “step.”
When the first element is added nothing needs to be shifted, but the new element must be copied into the array. So that requires one step. When the second element is added we would need one shift and one copy; therefore two steps. By the time we add the Nth element we need N – 1 shifts and one copy, therefore N steps. The total number of steps required is
1 + 2 + 3 + ... + (N – 1) + N
Applying a well-known summation formula tells us this sum is equal to N(N + 1)/2. If we expand N(N + 1)/2 as ½N2 + ½N, it is easy to see that the order of growth is N2. This analysis and result is similar to what we did in Section 1.6, “Comparing Algorithms: Order of Growth Analysis,” for the Selection Sort algorithm. Although an O(N2) sorting algorithm is not considered to be “fast,” the Insertion Sort is a good sorting approach to use in situations such as our List ADT where the elements to be sorted are passed to the storage container one at a time.
Unsupported Operations
As we just discussed, a SortedABList object keeps the elements added to it in sorted order. It does this by carefully inserting added elements into the appropriate location of the internal array. Note that besides the standard add method, the List ADT includes two other ways for elements to be placed into a list, the index-based add and set methods.
If we allow clients to add or set elements at a specified index of the list, then it is possible a client would invalidate the carefully created ordering of the array. This in turn would cause the find method to malfunction. There is a simple solution to this issue. We state as a general precondition of the class that the index-based add and set operations are not supported. If invoked we have those methods throw an UnsupportedOperationException, which is an unchecked exception provided by the Java library. Here is the code for the two unsupported methods:
public void add(int index, T element) // Throws UnsupportedOperationException. { throw new UnsupportedOperationException("Unsupported index-based add . . . } public T set(int index, T newElement) // Throws UnsupportedOperationException. { throw new UnsupportedOperationException("Unsupported index-based set . . . }
Comparator Interface
For the SortedArrayCollection of Chapter 5 the elements in the array were maintained in natural order, that is, in the order defined by the element class’s compareTo method. In that case we were only interested in increasing the efficiency of the find operation, so the natural order worked as well as any other ordering. We simply had to require that elements added to the collection implemented the Comparable interface, thus ensuring that they implemented the compareTo method.
For our List ADT, however, our goal is to present a sorted list to the client. It might be that a client does not want to use the natural order of the elements. After all, there often are many ways we can sort lists—a list of students could be sorted by name, by test average, by age, by height, and so on. We want to allow clients of our SortedABList to be able to specify for themselves how the elements should be sorted.
The Java library provides another interface related to comparing objects, a generic interface called Comparator. This interface defines two abstract methods:
public abstract int compare(T o1, T o2); // Returns a negative integer, zero, or a positive integer to // indicate that o1 is less than, equal to, or greater than o2 public abstract boolean equals(Object obj); // Returns true if this Comparator equals obj; otherwise, false
The first method, compare, is very similar to the familiar compareTo method. It takes two arguments, however, rather than one. The second method, equals, is specified in the same way as the equals method of the Object class and can be inherited from Object. Recall that it usually is important for the equals and compareTo methods of a class to be consistent—likewise it is also important for the equals and compare methods of a Comparator class to be consistent. We do not address the equals method again in this discussion as we do not use it within our implementation of the sorted list.
Comparing two objects using compareTo requires invoking the method on one of the objects. For example, if fp1 and fp2 are both FamousPerson objects they could be compared as follows:
if (fp1.compareTo(fp2)) . . .
There can be only one compareTo method defined on the FamousPerson class, and therefore only one way to sort such objects if we rely on the compareTo method. This is the so-called natural order, and in the case of the FamousPerson class the elements would be ordered alphabetically by last name, first name.
Using an approach based on the Comparator class allows for multiple sorting orders. We can define as many methods related to an element class that return a Comparator object as we want. Here is a method, yearOfBirthComparator, which returns a Comparator object allowing us to sort FamousPerson elements by year of birth. It is exported from the FamousPerson class and uses the anonymous inner-class technique introduced in the Iteration subsection of Section 6.2, “List Implementations”:
public static Comparator<FamousPerson> yearOfBirthComparator()
{
return new Comparator<FamousPerson>()
{
public int compare(FamousPerson element1, FamousPerson element2)
{
return (element1.yearOfBirth - element2.yearOfBirth);
}
};
}
Exercise 6.30 asks you to provide several more comparison options for the FamousPerson class.
Constructors
How does a client class of SortedABList specify which Comparator to use for ordering the elements? Simple, it passes the Comparator as an argument to the constructor of the class when it instantiates the sorted list. The SortedABList class includes a protected variable comp of type Comparator<T>:
protected Comparator<T> comp;
Here is the constructor of the class:
public SortedABList(Comparator<T> comp)
{
list = (T[]) new Object[DEFCAP];
this.comp = comp;
}
As you can see the value of the instance variable comp is set through the constructor. Within the find method of the class, comparison is accomplished using comp:
result = comp.compare(target, elements[location]);
So, for example, if a client wants a list of FamousPerson sorted by their year of birth they would instantiate a SortedABList object with the appropriate comparator:
SortedABList<FamousPerson> people = new SortedABList<FamousPerson>(FamousPerson.yearOfBirthComparator());
But, what if the client does want to use the natural order of the element class, the order as defined by the compareTo method. To allow easy use of the natural order we define a second constructor, one that takes no parameters. This constructor generates a Comparator object based on the compareTo method of the element class, using the anonymous inner-class approach, and assigns that comparator to comp. So if the parameter-less constructor of SortedABList is invoked, then the natural ordering of the elements is used for sorting purposes by default. The second constructor is:
public SortedABList()
// Precondition: T implements Comparable
{
list = (T[]) new Object[DEFCAP];
comp = new Comparator<T>()
{
public int compare(T element1, T element2)
{
return ((Comparable)element1).compareTo(element2);
}
};
}
An Example
The following program reads information about famous computer scientists from a file named FamousCS.txt and uses it to create and then display a sorted list of the information. It allows the user of the program to indicate how to sort the information, either by name (the natural order) or by birth year. In the former case the program instantiates the list using the parameter-less constructor, and in the latter case it passes the constructor the “sort by year of birth” comparator. The code and sample output follows.
//--------------------------------------------------------------------------- // CSPeople.java by Dale/Joyce/Weems Chapter 6 // // Reads information about famous computer scientists from the file // input/FamousCS.txt. Allows user to indicate if they wish to see the list // sorted by name or by year of birth. //--------------------------------------------------------------------------- package ch06.apps; import java.io.*; import java.util.*; import ch06.lists.*; import support.*; public class CSPeople { public static void main(String[] args) throws IOException { // Get user's display preference Scanner scan = new Scanner(System.in); int choice; System.out.println("1: Sorted by name? 2: Sorted by year of birth?"); System.out.print(" How would you like to see the information > "); choice = scan.nextInt(); // Instantiate sorted list SortedABList<FamousPerson> people; if (choice == 1) people = new SortedABList<FamousPerson>(); // defaults to natural order else people = new SortedABList<FamousPerson>(FamousPerson.yearOfBirthComparator()); // Set up file reading FileReader fin = new FileReader("input/FamousCS.txt"); Scanner info = new Scanner(fin); info.useDelimiter("[,\n]"); // delimiters are commas, line feeds FamousPerson person; String fname, lname, fact; int year; // Read the info from the file and add it to the list while (info.hasNext()) { fname = info.next(); lname = info.next(); year = info.nextInt(); fact = info.next(); person = new FamousPerson(fname, lname, year, fact); people.add(person); } // Display the list, using the advanced for loop System.out.println(); for (FamousPerson fp: people) System.out.println(fp); } }
To save space we only show the first few lines of output. First we show the result if the user chooses option 1:
1: Sorted by name? 2: Sorted by year of birth? How would you like to see the information > 1 John Atanasoff(Born 1903): Invented digital computer in 1930. Charles Babbage(Born 1791): Concept of machine that could be programmed. Tim Berners-Lee(Born 1955): "Inventor" of the World Wide Web. Anita Borg(Born 1949): Founding director of IWT. . . .
And if they choose option 2:
1: Sorted by name? 2: Sorted by year of birth? How would you like to see the information > 2 Blaise Pascal(Born 1623): One of inventors of mechanical calculator. Joseph Jacquard(Born 1752): Developed programmable loom. Charles Babbage(Born 1791): Concept of machine that could be programmed. Ada Lovelace(Born 1815): Considered by many to be first computer programmer. . . .
This concludes our section. The code of the SortedABList class that we “skipped over” is essentially identical to code developed for previous ADTs. You can find SortedABList in the ch06.lists package.
6.5 List Variations
Just as there are many variations of types of, and uses for, lists in everyday life there are multiple approaches to implementing and using lists as a data structure.
Java Library Lists
In the Variations sections of Chapters 2, 4, and 5 we reviewed the Java Standard Library support for stacks, queues, and collections. We do not attempt to cover the Java Collections Application Programming Interface (API) in detail as a subject within this text. Our goal in these Variations sections related to the API is to point the interested reader to the information and encourage independent study of the topics. Moving forward, we will just briefly mention the library constructs related to the ADT under consideration when appropriate.
The library provides a List interface that inherits from both the Collection and Iterable interfaces of the library. The library’s list interface is significantly more complex than ours, defining 28 abstract methods. It is implemented by the following classes: AbstractList, AbstractSequentialList, ArrayList, AttributeList, CopyOnWriteArrayList, LinkedList, RoleList, RoleUnresolvedList, Stack, and Vector. Of special note are the ArrayList—we used an ArrayList in Section 2.5, “Array-Based Stack Implementations,” to implement a stack—and the LinkedList, that “implements a doubly linked list.”
Linked List Variations
Linked lists are sometimes used as an ADT, for example, the LinkedList class of the Java library, and sometimes used as a means of implementing another structure, for example, the way we used linked lists so far to implement stacks, queues, collections, and lists.
We have already seen several kinds of linked list structures. We used a singly linked list with a single access link (Figure 6.2a) to implement a stack in Section 2.8, “A Link-Based Stack,” and a collection in Section 5.6, “Link-Based Collection Implementation.” We used a single linked list with access links to both the front and rear (Figure 6.2b) to implement a queue in Section 4.5, “Link-Based Queue Implementations,” and a list in Section 6.2, “List Implementations.” We discussed how to use a circular linked list with a single access reference (Figure 6.2c) to implement a queue in Section 4.5, “Link-Based Queue Implementations,” and how to implement a deque using a doubly linked list (Figure 6.2d) in Section 4.7, “Queue Variations.”
When implementing methods for a linked list, we see that special cases often arise for the first and last nodes on the list. One way to simplify these methods is to make sure that we never add or remove elements at the ends of the list. How can we do this? It is often a simple matter to set up dummy nodes to mark the ends of a list. This is especially true for sorted lists because we can indicate the dummy nodes by using values outside of the permitted range of the contents of the list. A header node, containing a value smaller than any possible list element key, can be placed at the beginning of the list. A trailer node, containing a value larger than any legitimate element key, can be placed at the end of the list (Figure 6.2e).
Sometimes linked lists are themselves linked together in multiple levels to form a more complex structure. We discuss using multiple levels of linked lists in Chapter 10 to implement a Graph ADT. Interconnected lists are sometimes used to support complex yet efficient algorithms, for example a Skip List is a multilevel list (Figure 6.2f) that supports both efficient addition of nodes and efficient search for nodes.
The material in this text provides you the foundations needed to study, understand, use, and create all of the above variations of linked lists and more.
A Linked List as an Array of Nodes
We tend to think of linked structures as consisting of self-referential nodes that are dynamically allocated as needed, as illustrated in Figure 6.3a. But this is not a requirement. A linked list could be implemented in an array; the elements might be stored in the array in any order and “linked” by their indices (see Figure 6.3b). In this subsection, we discuss an array-based linked list implementation.

Figure 6.2 Linked list variations
In our previous reference-based implementations of lists, we used Java’s built-in memory management services when we needed a new node for addition or when we were finished with a node and wanted to remove it. Obtaining a new node is easy in Java; we just use the familiar new operation. Releasing a node from use is also easy; just remove our references to it and depend on the Java run-time system’s garbage collector to reclaim the space used by the node.
For the array-based linked representation, we must predetermine the maximum list size and instantiate an array of nodes of that size. We then directly manage the nodes in the array. We keep a separate list of the available nodes, and we write routines to allocate nodes to and deallocate nodes from this free list.

Figure 6.3 Linked lists in dynamic and static storage
Why Use an Array?
We have seen that dynamic allocation of list nodes has many advantages, so why would we even consider using an array-of-nodes implementation? Recall that dynamic allocation is just one advantage of choosing a linked implementation; another advantage is the greater efficiency of the add and remove algorithms. Most of the algorithms for operations on a linked structure can be used for either an array-based or a reference-based implementation. The main difference arises from the requirement that we manage our own free space in an array-based implementation. Sometimes managing the free space ourselves gives us greater flexibility.
Another reason to use an array of nodes is that some programming languages do not support dynamic allocation or reference types. You can still use linked structures if you are programming in one of these languages, using the techniques presented in this subsection.
Finally, sometimes dynamic allocation of each node, one at a time, is too costly in terms of time—especially in real-time system software such as operating systems, air traffic controllers, and automotive systems. In such situations, an array-based linked approach provides the benefits of linked structures without the same run-time costs.
A desire for static allocation is one of the primary motivations driving the array-based linked approach, so we drop our assumption that our lists are of unlimited size. Here, our lists will not grow as needed. Clients should not add elements to a full list.
How Is an Array Used?
Here we return to our discussion of how a linked list can be implemented in an array. We outline an approach and leave the actual implementation as an exercise. We can associate a next variable with each array node to indicate the array index of the succeeding node. The beginning of the list is accessed through a “reference” that contains the array index of the first element in the list. Figure 6.4 shows how a sorted list containing the elements “David,” “Joshua,” “Leah,” “Miriam,” and “Robert” might be stored in an array of nodes.

Figure 6.4 A sorted list stored in an array of nodes
Do you see how the order of the elements in the list is explicitly indicated by the chain of next indices?
What goes in the next index of the last list element? Its “null” value must be an invalid address for a real list element. Because the nodes array indices begin at 0, the value –1 is not a valid index into the array; that is, there is no nodes[-1]. Therefore, –1 makes an ideal value to use as a “null” address. We could use the literal value –1 in our programs:
while (location != -1)
It is better programming style to declare a named constant, however. We suggest using the identifier NUL and defining it to be –1:
protected static final int NUL = -1;
When an array-of-nodes implementation is used to represent a linked list, the programmer must write routines to manage the free space available for new list elements. Where is this free space? Look again at Figure 6.4. All of the array elements that do not contain values in the list constitute free space. Instead of the built-in allocator new, which allocates memory dynamically, we must write our own method to allocate nodes from the free space. Let us call this method getNode. We use getNode when we add new elements to the list.
When we remove an element from the list, we need to reclaim its space—that is, we need to return the removed node to the free space so it can be used again later. We cannot depend on a garbage collector; the node we remove remains in the allocated array so it is not reclaimed by the run-time engine. We need to write our own method, freeNode, to put a node back into the pool of free space.
We need a way to track the collection of nodes that are not being used to hold list elements. We can link this collection of unused array elements together into a second list, a linked list of free nodes. Figure 6.5 shows the array nodes with both the list of elements and the list of free space linked through their next values. The first variable is a reference to a list that begins at index 0 (containing the value “David”). Following the links in next, we see that the list continues with the array slots at index 4 (“Joshua”), 7 (“Leah”), 2 (“Miriam”), and 6 (“Robert”), in that order. The free list begins at free, at index 1. Following the next links, we see that the free list also includes the array slots at indices 5, 3, 8, and 9. We see two NUL values in the next column because there are two linked lists contained in the nodes array; thus the array includes two end-of-list values.
That concludes our outline for an approach to implementing a linked list with an array. Of course, a lot of work remains to be done to actually accomplish the implementation. See Exercise 37.

Figure 6.5 An array with a linked list of values and free space
6.6 Application: Large Integers
In the previous section we reviewed several common variations of linked lists: singly linked, doubly linked, circular, lists with headers and trailers, lists with front only or front and rear pointers, and multilevel lists. More variations are possible, of course, especially considering you can “mix and match” approaches, for example, creating a circular linked list with a front-only pointer that uses headers and trailers, and so on.
In this section we will create a variant of the linked list that is designed to help us solve a specific problem. In addition to using classic data structures and creating reusable ADTs it is also important to be able to design, create, and use structures on an as-needed basis.
Large Integers
The range of integer values that can be supported in Java varies from one primitive integer type to another. Appendix C contains a table showing the default value, the possible range of values, and the number of bits used to implement each integer type. The largest type, long, can represent values between –9,223,372,036,854,775,808 and 9,223,372,036,854,775,807. Wow! That would seem to suffice for most applications. Some programmer, however, is certain to want to represent integers with even larger values. We create a class LargeInt that allows the programmer to manipulate integers in which the number of digits is limited only by the amount of memory available.1
Because we are providing an alternative implementation for a mathematical object, an integer number, the operations are already familiar: addition, subtraction, multiplication, division, assignment, and the relational operators. In this section, we limit our attention to addition and subtraction. We ask you to enhance this ADT with some of the other operations in the exercises.
In addition to the standard mathematical operations, we need to consider how to create our LargeInt objects prior to attempting to add or subtract them. We cannot use a constructor with an integer parameter, because the desired integer might be too large to represent in Java—after all, that is the idea of this ADT. Therefore, we decide to include a constructor that accepts a string argument that represents an integer and instantiates the corresponding LargeInt object.
We assume the sign of a large integer is positive and provide a way to make it negative. We call the corresponding method setNegative. Additionally, we must have an observer operation that returns a string representation of the large integer. We follow the Java convention and call this operation toString.
The Internal Representation
Before we look at the algorithms for these operations, we need to decide on our internal representation. The fact that a large integer can be any size leads us to a dynamic memory-based representation. Also, given that an integer is a list of digits, it is natural to investigate the possibility of representing it as a linked list of digits. Figure 6.6 shows two ways of storing numbers in a singly linked list and an example of addition. Parts (a) and (c) show one digit per node; part (b) shows several digits per node. We develop our Large Integer ADT using a single digit per node. (You are asked in the exercises to explore the changes necessary to include more than one digit in each node.) Thus we have decided to represent our large integers as linked lists of digits. Because a single digit can be represented by Java’s smallest integer type, the byte, we decide to use linked lists of byte values.
What operations must be supported by this linked list? The first thing to consider is how large integer objects are to be constructed. We have already decided to build our representation, one digit at a time, from left to right across a particular large integer. That is how we initialize large integers directly. But large integers can also be created as a result of arithmetic operations. Think about how you perform arithmetic operations such as addition—you work from the least significant digit to the most significant digit, obtaining the result as you proceed. Therefore, we also need to create large integers by inserting digits in order from least significant to most significant. Thus our linked list should support insertion of digits at both the beginning and the end of the list.
Given the unique requirements for our Large Integer representation we create a list class specifically for this project. We call it LargeIntList.

Figure 6.6 Representing large integers with linked lists

Figure 6.7 A doubly linked list with two references
The LargeIntList class
At this point we review our requirements. Our lists must hold elements of the primitive-type byte; we will use the wrapper class Byte. The lists need not support isFull, isEmpty, add, contains, get, remove, nor any of the indexed operations. In fact, the only list operations that we have been using that are required by this new list construct are the size operation and the iterator operations. We also need to process elements from left to right and from right to left, so we need to support two iterators: forward and reverse. In addition, we need to add elements at the front of our lists, addFront, and at the back of our lists, addEnd.
To support the requirement of traversing the list by going either forward or backward we decide to use a reference-based doubly linked structure for our implementation. To begin our backward traversals, and to support the new addEnd operation, it is clear that we need easy access to the end of the list. We decide to maintain two list references, one for the front of the list and one for the back of the list. Figure 6.7 shows the general structure of the internal representation of our LargeIntList class.
Here is the beginning of the LargeIntList class. We use nodes of the DLLNode class (introduced in Section 4.7, “Queue Variations”). We use instance variables to track the first list element, the last list element, and the number of elements on the list. The info attribute of the DLLNode class holds a value of type Byte, as discussed earlier.
//--------------------------------------------------------------------------- // LargeIntList.java by Dale/Joyce/Weems Chapter 6 // // A specialized list to support Large Integer ADT //--------------------------------------------------------------------------- package ch06.largeInts; import support.DLLNode; import java.util.Iterator; public class LargeIntList { protected DLLNode<Byte> listFirst; // Ref to the first node on list protected DLLNode<Byte> listLast; // Ref to the last node on the list protected int numElements; // Number of elements in the list public LargeIntList() // Creates an empty list object { numElements = 0; listFirst = null; listLast = null; }
The size method is essentially unchanged from previous implementations—it simply returns the value of the numElements instance variable.
public int size()
// Returns the number of elements on this list.
{
return numElements;
}
The iterator methods are straightforward. There is no requirement for removing nodes during an iteration so the returned iterators need not support that operation. This simplifies their design considerably.
public Iterator<Byte> forward() // Returns an Iterator that iterates from front to rear. { return new Iterator<Byte>() { private DLLNode<Byte> next = listFirst; // next node to return public boolean hasNext() // Returns true if the iteration has more elements; otherwise false. { return (next != null); } public Byte next() // Returns the next element in the iteration. // Throws NoSuchElementException - if no more elements { if (!hasNext()) throw new IndexOutOfBoundsException("Illegal invocation of " + " next in LargeIntList forward iterator. "); Byte hold = next.getInfo(); // holds info for return next = next.getForward(); return hold; } public void remove() // Throws UnsupportedOperationException. { throw new UnsupportedOperationException("Unsupported remove " + "attempted on LargeIntList forward iterator."); } }; } public Iterator<Byte> reverse() // Returns an Iterator that iterates from front to rear. { return new Iterator<Byte>() { private DLLNode<Byte> next = listLast; // next node to return public boolean hasNext() // Returns true if the iteration has more elements; otherwise false. { return (next != null); } public Byte next() // Returns the next element in the iteration. // Throws NoSuchElementException - if no more elements { if (!hasNext()) throw new IndexOutOfBoundsException("Illegal invocation of " + "next in LargeIntList reverse iterator. "); Byte hold = next.getInfo(); // holds info for return next = next.getBack(); return hold; } public void remove() // Throws UnsupportedOperationException. { throw new UnsupportedOperationException("Unsupported remove " + "attempted on LargeIntList forward iterator."); } }; }
The addition methods are simplified because we do not have to handle the general case of addition in the middle of the list. The addFront method always adds at the beginning of the list and the addEnd method always adds at the end of the list. Here we look at addFront (see Figure 6.8a).

Figure 6.8 Adding at the beginning and at the end of the new list
The method begins by creating the new node and initializing its attributes. The new node is the new front of the list, so we know that its forward link should reference the current front of the list, and its back link should be null. An if statement guards the case when the addition occurs into an empty list (see Figure 6.8b). In that case, both the listFirst and listLast instance variables must reference the new node, as it is both the first and last element of the list. Otherwise, the back link of the previous first element is set to reference the new element, along with the listFirst instance variable.
public void addFront (byte element) // Adds the value of element to the beginning of this list { DLLNode<Byte> newNode = new DLLNode<Byte>(element); // node being added newNode.setForward(listFirst); newNode.setBack(null); if (listFirst == null) // Adding into an empty list { listFirst = newNode; listLast = newNode; } else // Adding into a non-empty list { listFirst.setBack(newNode); listFirst = newNode; } numElements++; }
The code for the addEnd method is similar (see Figure 6.8c):
public void addEnd (byte element) // Adds the value of element to the end of this list { DLLNode<Byte> newNode = new DLLNode<Byte>(element); // node being added newNode.setForward(null); newNode.setBack(listLast); if (listFirst == null) // Adding into an empty list { listFirst = newNode; listLast = newNode; } else // Adding into a non-empty list { listLast.setForward(newNode); listLast = newNode; } numElements++; }
The LargeInt Class
We will use LargeIntList objects to hold the linked list of digits that form part of the internal representation of our Large Integers. Now we can concentrate on the rest of the definition of the class. In addition to digits, integers have a sign, which indicates whether they are positive or negative. We represent the sign of a large integer with a boolean instance variable sign. Furthermore, we define two boolean constants, PLUS = true and MINUS = false, to use with sign.
Here is the beginning of the class LargeInt. It includes the instance variables, two constructors, and the three methods setNegative (to make a large integer negative), addDigit (to build a large integer digit by digit), and toString (to provide a string representation of a large integer, complete with commas separating every three digits). We place it in the package ch06.largeInts along with LargeIntList.
//--------------------------------------------------------------------------- // LargeInt.java by Dale/Joyce/Weems Chapter 6 // // Provides a Large Integer ADT. Large integers can consist of any number // of digits, plus a sign. Supports an add and a subtract operation. //--------------------------------------------------------------------------- package ch06.largeInts; import java.util.Iterator; public class LargeInt { protected LargeIntList numbers; // Holds digits // Constants for sign variable protected static final boolean PLUS = true; protected static final boolean MINUS = false; protected boolean sign; public LargeInt() // Instantiates an "empty" large integer. { numbers = new LargeIntList(); sign = PLUS; } public LargeInt(String intString) // Precondition: intString contains a well-formatted integer // // Instantiates a large integer as indicated by intString { numbers = new LargeIntList(); sign = PLUS; int firstDigitPosition; // Position of first digit in intString int lastDigitPosition; // Position of last digit in intString // Used to translate character to byte char digitChar; int digitInt; byte digitByte; firstDigitPosition = 0; if (intString.charAt(0) == '+') // Skip leading plus sign firstDigitPosition = 1; else if (intString.charAt(0) == '-') // Handle leading minus sign { firstDigitPosition = 1; sign = MINUS; } lastDigitPosition = intString.length() - 1; for (int count = firstDigitPosition; count <= lastDigitPosition; count++) { digitChar = intString.charAt(count); digitInt = Character.digit(digitChar, 10); digitByte = (byte)digitInt; numbers.addEnd(digitByte); } } public void setNegative() { sign = MINUS; } public String toString() { Byte element; String largeIntString; if (sign == PLUS) largeIntString = "+"; else largeIntString = "-"; int count = numbers.size(); Iterator<Byte> forward = numbers.forward(); while (forward.hasNext()) { element = forward.next(); largeIntString = largeIntString + element; if ((((count - 1) % 3) == 0) && (count != 1)) largeIntString = largeIntString + ","; count--; } return(largeIntString); }
Note the many levels of abstraction used here with respect to our data. In a previous chapter we defined the doubly linked list node class DLLNode. That class was used above as part of the internal representation of the LargeIntList class, which in turn is being used here as part of the internal representation of the LargeInt class. Once we finish the creation of the LargeInt class we can use it within applications to manipulate large integers. The application uses LargeInt which uses LargeIntList which uses DLLNode which uses two references variables.
Addition and Subtraction
Do you recall when you learned about addition of integers? Remember how special rules applied depending on what the signs of the operands were and which operand had the larger absolute value? For example, to perform the addition (–312) + (+200), what steps would you take? Let us see: The numbers have unlike signs, so we subtract the smaller absolute value (200) from the larger absolute value (312), giving us 112, and use the sign of the larger absolute value (–), giving the final result of (–112). Try a few more additions:
(+200) + (+100) = ?
(–300) + (–134) = ?
(+34) + (–62) = ?
(–34) + (+62) = ?
Did you get the respective correct answers (+300, –434, –28, +28)?
Did you notice anything about the actual arithmetic operations that you had to perform to calculate the results of the summations listed above? You performed only two kinds of operations: adding two positive numbers and subtracting a smaller positive number from a larger positive number. That is it. In combination with rules about how to handle signs, these operations allow you to do all of your sums.
Helper Methods
In programming, as in mathematics, we also like to reuse common operations. Therefore, to support the addition operation, we first define a few helper operations. These base operations should apply to the absolute values of our numbers, which means we can ignore the sign for now. Which common operations do we need? Based on the preceding discussion, we need to be able to add together two lists of digits, and to subtract a smaller list from a larger list. That means we also have to be able to identify which of two lists of digits is larger. Thus we need three operations, which we call addLists, subtractLists, and greaterList.
Here we begin with greaterList. We pass greaterList two LargeIntList arguments; it returns true if the first argument represents a larger number than the second argument, and false otherwise. When comparing strings, we compare pairs of characters in corresponding positions from left to right. The first characters that do not match determine which number is greater. When comparing positive numbers, we have to compare the numbers digit by digit only if they are the same length. We first compare the lengths; if they are not the same, we return the appropriate result. If the number of digits is the same, we compare the digits from left to right. In the code, we originally set a boolean variable greater to false, and we change this setting if we discover that the first number is larger than the second number. In the end, we return the boolean value of greater.
protected static boolean greaterList(LargeIntList first,
LargeIntList second)
// Precondition: first and second have no leading zeros
//
// Returns true if first represents a larger number than second;
// otherwise, returns false
{
boolean greater = false;
if (first.size() > second.size())
greater = true;
else
if (first.size() < second.size())
greater = false;
else
{
byte digitFirst;
byte digitSecond;
Iterator<Byte> firstForward = first.forward();
Iterator<Byte> secondForward = second.forward();
// Set up loop
int length = first.size();
boolean keepChecking = true;
int count = 1;
while ((count <= length) && (keepChecking))
{
digitFirst = firstForward.next();
digitSecond = secondForward.next();
if (digitFirst > digitSecond)
{
greater = true;
keepChecking = false;
}
else
if (digitFirst < digitSecond)
{
greater = false;
keepChecking = false;
}
count++;
}
}
return greater;
}
If we exit the while loop without finding a difference, the numbers are equal and we return the original value of greater, which is false (because first is not greater than second). Because we blindly look at the lengths of the lists, we must assume that the numbers do not include leading zeros (e.g., the method would report that 005 > 14). We make the greaterList method protected: Helper methods are not intended for use by the client programmer; they are intended for use only within the LargeInt class itself.
We look at addLists next. We pass addLists its two operands as LargeIntList parameters, and the method returns a new LargeIntList as the result. The processing for addLists can be simplified if we assume that the first argument is larger than the second argument. We already have access to a greaterList method, so we make this assumption.
We begin by adding the two least significant digits (the unit’s position). Next, we add the digits in the 10s position (if present) plus the carry from the sum of the least significant digits (if any). This process continues until we finish with the digits of the smaller operand. For the remaining digits of the larger operand, we may need to propagate a carry, but we do not have to add digits from the smaller operand. Finally, if a carry value is left over, we create a new most significant location and place it there. We use integer division and modulus operators to determine the carry value and the value to insert into the result. The algorithm follows:
Apply the algorithm to the following examples to convince yourself that it works. The code follows.
322 388 399 999 3 1 988 0 44 108 1 11 44 99 100 0 --- --- --- --- --- --- --- --- 366 496 400 1010 47 100 1088 0
protected static LargeIntList addLists(LargeIntList larger,
LargeIntList smaller)
// Precondition: larger > smaller
//
// Returns a specialized list that is a byte-by-byte sum of the two
// argument lists
{
byte digit1;
byte digit2;
byte temp;
byte carry = 0;
int largerLength = larger.size();
int smallerLength = smaller.size();
int lengthDiff;
LargeIntList result = new LargeIntList();
Iterator<Byte> largerReverse = larger.reverse();
Iterator<Byte> smallerReverse = smaller.reverse();
// Process both lists while both have digits
for (int count = 1; count <= smallerLength; count++)
{
digit1 = largerReverse.next();
digit2 = smallerReverse.next();
temp = (byte)(digit1 + digit2 + carry);
carry = (byte)(temp / 10);
result.addFront((byte)(temp % 10));
}
// Finish processing of leftover digits
lengthDiff = (largerLength - smallerLength);
for (int count = 1; count <= lengthDiff; count++)
{
digit1 = largerReverse.next();
temp = (byte)(digit1 + carry);
carry = (byte)(temp / 10);
result.addFront((byte)(temp % 10));
}
if (carry != 0)
result.addFront((byte)carry);
return result;
}
Now we examine the helper method subtractLists. Remember that we only need to handle the simplest case: Both integers are positive, and the smaller one is subtracted from the larger one. As with addLists, we accept two LargeIntList parameters, the first being larger than the second, and we return a new LargeIntList.
We begin with the pair of digits in the unit’s position. Let us call the digit in the larger argument digit1 and the digit in the smaller argument digit2. If digit2 is less than digit1, we subtract and insert the resulting digit at the front of the result. If digit2 is greater than digit1, we borrow 10 and subtract. Then we access the digits in the 10s position. If we have borrowed, we subtract 1 from the new larger and proceed as before. Because we have limited our problem to the case where larger is larger than smaller, both either run out of digits together or larger still contains digits when smaller has been processed. This constraint guarantees that borrowing does not extend beyond the most significant digit of larger. See if you can follow the algorithm we just described in the code.
protected static LargeIntList subtractLists(LargeIntList larger,
LargeIntList smaller)
// Precondition: larger >= smaller
//
// Returns a specialized list, the difference of the two argument lists
{
byte digit1;
byte digit2;
byte temp;
boolean borrow = false;
int largerLength = larger.size();
int smallerLength = smaller.size();
int lengthDiff;
LargeIntList result = new LargeIntList();
Iterator<Byte> largerReverse = larger.reverse();
Iterator<Byte> smallerReverse = smaller.reverse();
// Process both lists while both have digits.
for (int count = 1; count <= smallerLength; count++)
{
digit1 = largerReverse.next();
if (borrow)
{
if (digit1 != 0)
{
digit1 = (byte)(digit1 - 1);
borrow = false;
}
else
{
digit1 = 9;
borrow = true;
}
}
digit2 = smallerReverse.next();
if (digit2 <= digit1)
result.addFront((byte)(digit1 - digit2));
else
{
borrow = true;
result.addFront((byte)(digit1 + 10 - digit2));
}
}
// Finish processing of leftover digits
lengthDiff = (largerLength - smallerLength);
for (int count = 1; count <= lengthDiff; count++)
{
digit1 = largerReverse.next();
if (borrow)
{
if (digit1 != 0)
{
digit1 = (byte)(digit1 - 1);
borrow = false;
}
else
{
digit1 = 9;
borrow = true;
}
}
result.addFront(digit1);
}
return result;
}
Addition
Now that we have finished the helper methods, we can turn our attention to the public methods provided to clients of the LargeInt class. First, we look at addition. Here are the rules for addition you learned when studying arithmetic:
Addition Rules
If both operands are positive, add the absolute values and make the result positive.
If both operands are negative, add the absolute values and make the result negative.
If one operand is negative and one operand is positive, subtract the smaller absolute value from the larger absolute value and give the result the sign of the larger absolute value.
We use these rules to help us design our add method. We can combine the first two rules as follows: “If the operands have the same sign, add the absolute values and make the sign of the result the same as the sign of the operands.” Our code uses the appropriate helper method to generate the new list of digits and then sets the sign based on the rules. Remember that to use our helper methods we pass them the required arguments in the correct order (larger first). Here is the code for add:
public static LargeInt add(LargeInt first, LargeInt second) // Returns a LargeInt that is the sum of the two argument LargeInts { LargeInt sum = new LargeInt(); if (first.sign == second.sign) { if (greaterList(first.numbers, second.numbers)) sum.numbers = addLists(first.numbers, second.numbers); else sum.numbers = addLists(second.numbers, first.numbers); sum.sign = first.sign; } else // Signs are different { if (greaterList(first.numbers, second.numbers)) { sum.numbers = subtractLists(first.numbers, second.numbers); sum.sign = first.sign; } else { sum.numbers = subtractLists(second.numbers, first.numbers); sum.sign = second.sign; } } return sum; }
The add method accepts two LargeInt objects and returns a new LargeInt object equal to their sum. Because it is passed both operands as parameters and returns the result explicitly, it is defined as a static method that is invoked through the class, rather than through an object. For example, the code
LargeInt LI1 = new LargeInt();
LargeInt LI2 = new LargeInt();
LargeInt LI3;
LI1.addDigit((byte)9);
LI1.addDigit((byte)9);
LI1.addDigit((byte)9);
LI2.addDigit((byte)9);
LI2.addDigit((byte)8);
LI2.addDigit((byte)7);
LI3 = LargeInt.add(LI1, LI2);
System.out.println("LI3 is " + LI3);
would result in the output of the string “LI3 is +1986.”
Subtraction
Remember how subtraction seemed harder than addition when you were learning arithmetic? Not anymore! We need to use only one subtraction rule: “Change the sign of the subtrahend, and add.” We do have to be careful about how we “change the sign of the subtrahend,” because we do not want to change the sign of the actual argument passed to subtract—that would produce an unwanted side effect of our method. Therefore, we create a new LargeInt object, make it a copy of the second parameter, invert its sign, and then invoke add:
public static LargeInt subtract(LargeInt first, LargeInt second) // Returns a LargeInt that is the difference of the two argument LargeInts { LargeInt diff = new LargeInt(); // Create an inverse of second LargeInt negSecond = new LargeInt(); negSecond.sign = !second.sign; Iterator<Byte> secondForward = second.numbers.forward(); int length = second.numbers.size(); for (int count = 1; count <= length; count++) negSecond.numbers.addEnd(secondForward.next()); // Add first to inverse of second diff = add(first, negSecond); return diff; }
The LargeIntCLI Program
The LargeIntCLI program, in the ch06.apps package, allows the user to enter two large integers, performs the addition and subtraction of the two integers, and reports the results. Study the code below. You should be able to identify the statements that declare, instantiate and initialize, transform, and observe large integers.
//-------------------------------------------------------------------- // LargeIntCLI.java by Dale/Joyce/Weems Chapter 6 // // Allows user to add or subtract large integers. //--------------------------------------------------------------------- import java.util.Scanner; import ch06.largeInts.LargeInt; public class LargeIntCLI { public static void main(String[] args) { Scanner scan = new Scanner(System.in); LargeInt first; LargeInt second; String intString; String more = null; // used to stop or continue processing do { // Get large integers. System.out.println("Enter the first large integer: "); intString = scan.nextLine(); first = new LargeInt(intString); System.out.println("Enter the second large integer: "); intString = scan.nextLine(); second = new LargeInt(intString); System.out.println(); // Perform and report the addition and subtraction. System.out.print("First number: "); System.out.println(first); System.out.print("Second number: "); System.out.println(second); System.out.print("Sum: "); System.out.println(LargeInt.add(first,second)); System.out.print("Difference: "); System.out.println(LargeInt.subtract(first,second)); // Determine if there is more to process. System.out.println(); System.out.print("Process another pair of numbers? (Y=Yes): "); more = scan.nextLine(); System.out.println(); } while (more.equalsIgnoreCase("y")); } }
Here is the result of a sample run of the program:
Enter the first large integer: 15463663748473748374988477777777777777777 Enter the second large integer: 4536748465999347474948722222222222222223 First number: +15,463,663,748,473,748,374,988,477,777,777,777,777,777 Second number: +4,536,748,465,999,347,474,948,722,222,222,222,222,223 Sum: +20,000,412,214,473,095,849,937,200,000,000,000,000,000 Difference: +10,926,915,282,474,400,900,039,755,555,555,555,555,554 Process another pair of numbers? (Y=Yes): N
You are encouraged to try the program out for yourself. If you do, you may discover a few problem situations. These situations form the basis for some end-of-chapter exercises.
Summary
The List ADT is versatile and important. A list is a collection (providing add, remove, contains, and get operations) and supports indexed operations. A list is also iterable—to understand, design, and create list-related classes we studied iteration, and in particular the Java Iterable and Iterator interfaces. We learned how to use an anonymous inner class to create and return an Iterator object.
As has been our practice in previous chapters, we defined our List ADT as a Java interface and implemented it using both arrays and linked lists. Of special interest was the relatively complex task of supporting the iteration-related remove method for the linked list implementation—we tracked and used two extra reference variables, pointing into the linked list, during the iteration just to support this operation.
To demonstrate the utility of the List ADT we used it to create a CardDeck class. We also provided several examples of the use of CardDeck, some of which used additional list objects besides the deck itself.
Our sorted array-based list implementation provides the extra benefits to clients of keeping their data organized in “increasing” order. During the development of this implementation we learned how to indicate that an operation is not supported (throw the UnsupportedOperationException) since a sorted list cannot allow indexed-based add or set operations. We also learned how to use the Comparator interface so that clients of the class can indicate alternate ordering conditions in addition to the “natural ordering” of the elements.
In the variations section we briefly discussed the Java library list support and reviewed various kinds of linked lists. We even saw how to implement a linked list using an array—which really helps us understand there is a difference between an abstract concept such as “Linked List” and its internal representation, in this case an array. With this technique, the links are not references into the free store but rather indices into the array of nodes. This type of linking is used extensively in systems software.
The application presented at the end of the chapter designed a Large Integer ADT, for which the number of digits is bounded only by the size of memory. The Large Integer ADT required a specialized list for its implementation. Thus we created a new class LargeIntegerList. This case study provided a good example of how one ADT can be implemented with the aid of another ADT, emphasizing the importance of viewing systems as a hierarchy of abstractions.
Figure 6.9 is an abbreviated UML diagram showing the primary list-related classes and interfaces discussed or developed in this chapter. Note that the Iterable, Comparable, and Comparator interfaces shown in the diagram reside in the Java library. Everything else is found within the text’s bookfiles folder.

Figure 6.9 List-related classes and interfaces
Exercises
6.1 The List Interface
-
For each of the methods declared in
ListInterfaceidentify what type of operation it is (observer, transformer, or both). -
How would you change
ListInterfaceif we dropped our assumption thatLists are unbounded?
Duplicate elements are not allowed on a list?
-
Suppose
indListis a list that contains seven elements. Supposevalueholds an element that is not already on the list. For each of the following method invocations, indicate whether they would result in theIndexOutOfBoundsExceptionbeing thrown. Each part of this question is independent.indList.add(6, value)indList.add(7, value)indList.add(8, value)indList.set(6, value)indList.set(7, value)indList.remove(value)indList.get(value)indList.remove(-1)indList.remove(0)
-
Assume
stringsis anIterablelist ofStringobjects. Using a while loop, list and iterator operations, create code with functionality equivalent tofor (String hold: strings) System.out.println(hold);
-
Based on the definition of
ListInterfaceand assumingstringsis alistofStringobjects which has just been instantiated, show the output of:System.out.println(strings.isEmpty()); System.out.println(strings.add("alpha")); strings.add("gamma"); strings.add("delta"); System.out.println(strings.add("alpha")); System.out.println(strings.remove("alpha")); System.out.println(strings.isEmpty()); System.out.println(strings.get("delta")); System.out.println(strings.contains("delta")); System.out.println(strings.contains("beta")); System.out.println(strings.contains("alpha")); System.out.println(strings.size());strings.add(0,"alpha")); strings.add(0,"gamma"); strings.add(1,"delta"); strings.add(1,"beta"); strings.add(1,"alpha"); strings.add(3,"omega"); strings.add(2,"pi"); strings.set(1,"comma"); strings.remove(3); for (String hold: strings) System.out.println(hold);
strings.add(0,"alpha")); strings.add(0,"gamma"); strings.add(1,"delta"); strings.add(1,"beta"); strings.add(1,"alpha"); strings.add(3,"omega"); strings.add(2,"pi"); strings.set(1,"comma"); Iterator<String> iter; String temp; while (iter.hasNext()) { temp = iter.next(); if (temp.equals("alpha")) iter.remove(); } for (String hold: strings) System.out.println(hold);
6.2 List Implementations
-
Describe/define/explain
The relationship between Java’s
IterableandIteratorinterfacesAn inner class
An anonymous inner class
The functionality of an
Iterator removemethod
-
Show the values contained in the instance variables of the
samplelist after each of the following sequences of operations.ABList<String> sample = new ABList<String>(5); sample.add("A"); sample.add("C"); sample.add("D"); sample.add("A"); sample.contains("D"); sample.remove("C");ABList<String> sample = new ABList<String>(5); sample.add("A"); sample.add(0,"C"); sample.add(0,"D"); sample.contains("E"); sample.remove(2); sample.set(1,"Z"); sample.get("A"); sample.add(1,"Q");LBList<String> sample = new LBList<String>(); sample.add("A"); sample.add("C"); sample.add("D"); sample.add("A"); sample.contains("D"); sample.remove("C");LBList<String> sample = new LBList<String>(); sample.add("A"); sample.add(0,"C"); sample.add(0,"D"); sample.contains("E"); sample.remove(2); sample.set(1,"Z"); sample.get("A"); sample.add(1,"Q");
-
 Programming tasks:
Programming tasks:Add a
toStringmethod to theABListclass that returns the contents of the list as a nicely formatted string. You should then use thetoStringmethod, as appropriate, in the rest of this exercise.Create an application
TestBasicthat demonstrates that the “basic” list operations (add,remove,contains,get,andsize) supported byABListwork as expected.Create an application
TestIndexedthat demonstrates that the index-related list operations supported byABListwork as expected.Create an application
TestIteratorthat demonstrates that the iterator-related list operations supported byABListwork as expected.
-
Repeat the previous exercise except for the
LBListclass. -
Describe the ramifications of each of the following changes to
ABList:The final statement in the
enlargemethod is deleted.In the first statement in the indexed
addmethod change ">" to ">=".In the first statement in the
setmethod, change ">=" to ">".The statements
T hold = elements[index];andelements[index] = newElement;are reversed in thesetmethod.In the indexed
removemethod the –1 is deleted from the for loop termination condition.In the iterator code the
previousPosvariable is initialized to 0 instead of –1.In the iterator code, the final statement is deleted from the
removemethod.
-
Consider the indexed operation:
removeAll(T target, int start, int end)—removes all elements from the list that are equal totargetthat are held in between indexstartand indexend.The
removeAllmethod is not well specified. Carefully define your detailed vision forremoveAllincluding preconditions and exceptions that will be thrown.Implement
removeAllfor theABListclass and create a driver application that demonstrates it works correctly.Implement
removeAllfor theLBListclass and create a driver application that demonstrates it works correctly.
-
Describe the “special cases” specifically addressed by each of the following methods and how they are handled—for example, adding an element to an empty list is a “special case.”
The
ABList addmethodThe
ABList setmethodThe
LBListindexedaddmethodThe
LBListindexedremovemethodThe
LBListiteratorremovemethod
-
Fill in the following table with the order of growth of the indicated operations for the given implementation approach—assume the list holds N elements:
operation ABList LBList addgetcontainsremoveisEmptyindexed addindexed setindexOfindexed getiterator nextiterator remove
6.3 Applications: Card Deck and Games
-
Application: This chapter specifies and implements a List ADT.
Design an algorithm for an application-level method
lastthat accepts aStringlist as an argument and returns aString. If the list is empty, the method returnsnull. Otherwise, it returns the last element of the list. The signature for the method should beString last(ListInterface<String> list)
Devise a test plan for your algorithm.
Implement and test your algorithm.
-
Application: This chapter specifies and implements a List ADT.
Design an algorithm for an application-level method
comparethat accepts twoStringlists as arguments and returns anintrepresenting a count of the number of elements from the first list that are also on the second list. The signature for the method should beint compare(ListInterface<String> list1, ListInterface<String> list2)Devise a test plan for your algorithm.
Implement and test your algorithm.
-
The
CardClass developed in this section uses the Javaenumtype to help model a standard playing card. Describe two other useful models that could be created with the help ofenum. -
When you play cards you normally shuffle the deck several times before dealing. Yet the shufling algorithm used in our
CardDeckclass “walks” through thedeckof cards only once. Explain the difference between these two situations. -
Describe the effects each of the following changes would have on the
CardDeckclass:In place of using the
ABListclass it uses theLBListclass.The
NUMCARDSconstant is initialized to 100.Within the constructor the order of the double for loop is reversed—that is the ranks are the outer loop and the suits are the inner loop.
Within the
shufflemethod the loop termination condition is changed toi >= 0.
-
Add the following methods to the
CardDeckclass, and create a test driver for each to show that they work correctly.int cardsRemaining()returns a count of the number of undealt cards remaining in the deck.Card peek()returns the next card from the deck without removing it— precondition is thathasNextreturnstrue.void reset()resets the deck back to its original order, that is, to the order exhibited by a new deck.
-
 The
The CardHandCLIapplication allows the user to “arrange” a hand of five cards. However, some poker games use seven cards per hand and in a game such as bridge there are 13 cards per hand. Change theCardHandCLIapplication so that the number of cards in the hand is passed to the application as a command line argument. -
The following enhancements to the
HigherLowerapplication are intended to be completed in the sequence listed:It accepts upper- or lowercase H and L replies from the user.
It repeatedly deals a hand until there are no more cards left in the deck.
The user starts with a “stake” of 100 chips. After seeing the first card the user can risk from one to their total number of chips. If the user predicts correctly their number of chips is increased by the number of chips they risked; if they are incorrect it is decreased by that amount. The game ends when all the cards are dealt or when they run out of chips.
If the second card is equal to the first card the user “loses” double their risk.
-
Implement a graphical user interface-based version of the Higher-Lower application.
-
In-Between is a well-known card game. Many variations exist—we define it as follows. One deck of cards is used. A game consists of one or more “hands.” A player starts with a certain number of chips called the “stake” (say 100) and must risk one or more chips on each hand, before seeing any cards. As long as the player still has chips and there are three or more cards left in the deck (enough to play a hand), the game continues. For each hand the player must risk between one and their total number of chips. Two cards are dealt “face up.” Then a third card is dealt. If the third card is “in-between” the first two cards, based on the ranks of the cards, the player’s chips are increased by the amount risked. Otherwise they are decreased by that amount.
Implement the game. The application user is the “player.”
If the first two cards dealt are the same rank, that hand is over and the player is awarded two chips.
Allow the player at his or her discretion to double the risk after seeing the first two cards.
-
Implement a graphical user interface–based version of the In-Between game (see previous exercise).
-
Similar to Exercise 20, change the
Pairsapplication so that the number of cards in a hand is passed to the application as a command line argument. Use the new program to investigate the probability of getting at least a pair in a seven-card poker hand. Calculate the theoretical probability of the same (or have your program do it for you!), using the approach described in this section, and compare it to the output of your program. Is it close? -
In a “hand” of bridge a deck of cards is dealt to four players, each receiving 13 cards. The players then proceed to bid on who will get to play the hand—player’s bid partially based on how highly he or she evaluates their hand and partially based on what their opponents and their partner bid. There are many different ways to evaluate a bridge hand, including various point counting systems. A simple point counting system is as follows: count each ace as 4 points, each king as 3 points, each queen as 2 points, and each jack as 1 point. Then add 1 additional point for each suit in which you have five cards, 2 points for a six-card suit, 3 points for a seven-card suit, and so on. For example, if your hand consists of the ace, queen, five, four, and three of clubs, the jack of diamonds, and the ace, king, queen, jack, ten, nine, and two of spades, your hand’s point value would be 21 points.
Create an application
BridgeHandthat allows a user to arrange a hand of 13 cards, much like theCardHandapplication. The program then prompts the user to enter the point value of the hand, using the counting approach described. Finally, the program reads in the user’s response and provides appropriate feedback (“Correct” or “Incorrect, the actual point value is . . .”).Create an application
HandsCountsthat generates 1,000,000 bridge hands and outputs the smallest, largest, and average point value, using the counting approach described above.Expand
HandsCountsso that when finished it also prints out one hand with the smallest point value and one hand with the highest point value.
6.4 Sorted Array-Based List Implementation
-
For each of the following lists describe several useful ways they might be sorted:
Books
University course descriptions
Professional golfer information
Summer camper registration information
-
Create an application (that uses the
SortedABList) that reads a list of strings from a file and outputs them in alphabetical order. -
Create an application (that uses the
SortedABList) that allows a user to enter a list of countries that he or she has visited and then displays the list in alphabetical order, plus a count of how many countries are on the list. If the user mistakenly enters the same country more than once, the program should inform the user of their error and refrain from inserting the country into the list a second time. -
Currently the
FamousPersonclass defines the natural order of its elements to be based on the alphabetical order of people names (last name, then first name). It also provides aComparatorthat defines order based on increasing year of birth. Augment the class to include morepublic staticmethods that return Comparators as described below. Augment theCSPeopleapplication to demonstrate that the new Comparators work properly.Order alphabetically by name (first name, then last name)
Order by year of birth—decreasing
Order by length of “fact”—increasing
-
Fill in the following table with the order of growth of the indicated operations for the given implementation approach. Assume the list holds N elements (partial repeat of Exercise 13):
operation ABListLBListSortedABListaddgetcontainsremoveisEmptyindexed addindexed setindexOfindexed getiterator nextiterator remove -
A bridge hand consists of 13 playing cards. Many bridge players arrange their hands left to right first by decreasing suit (spades, hearts, diamonds, clubs) and within each suit by decreasing rank (ace through 2). Add a method
bridgeComparatorto theCardclass of thesupportpackage that returns aComparator<Card>object that can be used to sort cards in this fashion. Demonstrate by creating an application that instantiates a deck of cards, deals four bridge hands, and then displays the hands side by side, for example the output might start with something such as:Ace of Spades Ace of Hearts Jack of Hearts Ace of Diamonds Queen of Hearts Ace of Clubs Ten of Clubs King of Clubs Queen of Clubs King of Spades Nine of Diamonds Ten of Hearts . . . . . . . . . . . .
-
These applications should create random five card poker hands using the
CardDeckclass. You may find that sorting the hand in various ways aids in the determination of the hand rank.PokerValueshould generate a single five-card poker hand and output the best rank associated with the hand—is it a “three of a kind” or a “straight flush,” and so forth? Hand ranks are listed from best to worst on page 370.PokerOddsshould generate 10 million five-card poker hands and output the relative percentage of times each of the card ranks listed on page 370 occurs. Each hand contributes only to the count of its highest possible rank. Do some research and compare your result to the known probabilities for poker hands.
6.5 List Variations
-
John and Mary are programmers for the local school district. One morning John commented to Mary about the interesting last name the new family in the district had: “Have you ever heard of a family named ZZuan?” Mary replied “Uh, oh; we have some work to do. Let’s get going.” Can you explain Mary’s response?
-
Assume you implemented our Sorted List ADT using the Linked List as an Array of Nodes approach described in this section. Assume the size of the array is N. What is the order of growth for the efficiency of initializing the free list? For the methods
getNodeandfreeNode?
Figure 6.10 Linked list as an array of nodes
-
Use the linked lists contained in the array pictured in Figure 6.10 to answer these questions. Each question is to be considered independently of the other questions.
What is the order in which array positions (indices) appear on the free space list?
Draw a figure that represents the array after the addition of “delta” to the list.
Draw a figure that represents the array after the removal of “gamma” from the list.
-
Implement our List ADT using the Linked List as an Array of Nodes approach described in this section. Also implement a test driver application that demonstrates that your implementation works correctly.
6.6 Application: Large Integers
-
True or False? Explain your answers. The
LargeIntListclassUses the “by copy” approach with its elements.
Implements the
ListInterfaceinterface.Keeps its data elements sorted.
Allows duplicate elements.
Uses the
LLNodeclass of thesupportpackage.Throws an exception if an iteration “walks off” the end of the list.
Throws an exception if an element is added when it is “full.”
Supports addition of elements at the front of the list, the end of the list, and anywhere in between.
Can hold objects of any Java class.
Has only O(1) operations, including its constructor.
Provides more than one
Iterator.
-
Discuss the changes that would be necessary within the
LargeIntclass if more than one digit is stored per node. -
The Large Integer Application does not “catch” ill-formatted input. For example, consider the following program run:
Enter the first large integer: twenty Enter the second large integer: two First number: +-1-1-1,-1-1-1 Second number: +-1-1-1 Sum: +-1-1-1,-2-2-2 Difference: +-1-1-1,000 Process another pair of numbers? (Y=Yes): n
Fix the program so that it is more robust, and so that in situations such as that shown above it writes an appropriate error message to the display.
-
Consider the multiplication of large integers.
Describe an algorithm.
Implement a multiply method for the
LargeIntclass.Add multiplication to the Large Integer Application.
-
The protected method
greaterListof theLargeIntclass assumes that its arguments have no leading zeros. When this assumption is violated, strange results can occur. Consider the following run of the Large Integer Application that claims 35 – 3 is –968:Enter the first large integer: 35 Enter the second large integer: 003 First number: +35 Second number: +003 Sum: +038 Difference: -968 Process another pair of numbers? (Y=Yes): n
Why do leading zeros cause a problem?
Identify at least two approaches to correcting this problem.
Describe the benefits and drawbacks of each of your identified approaches.
Choose one of your approaches and implement the solution.