
The object-oriented paradigm uses the concepts of class and object as basic building blocks in the formation of a consistent model for the analysis, design, and implementation of applications. These concepts can best be explained through a real-world example. Given a room full of people, if you were to ask, “How many people in this room could build an alarm clock if given all the pieces?” at best one or two individuals would raise their hand. If the same room of people were asked, “How many people in this room could set an alarm clock to go off at 9 a.m.?” it is a safe bet that most people would raise their hand. Isn't it absurd that so many people claim to be able to use an alarm clock when they can't even build an alarm clock? The immediate response to this question is, “Of course not! Your question is absurd!”
There are many things in the real world that we are capable of using without knowing anything about their implementation: refrigerators, cars, photocopy machines, and computers, just to name a few. The reason they are easy to use without knowledge of their implementation is that they are designed to be used via a well-defined public interface. This interface is heavily dependent on, but hides from its users, the implementation of the device. This design strategy is what allows the alarm clock manufacturer the freedom to replace the 60 tiny components currently being used in the construction of alarm clocks for three subcomponents made overseas without any offense to the users of alarm clocks.
Another example of public interface versus implementation can be seen within the domain of automobiles. Very few users of automobiles cared when car manufacturers went from mechanical ignition systems (i.e., distributor, points, condenser, etc.) to electronic ignition systems. Why? The public interface remained the same; only the implementation changed. Imagine, however, that you go to a car dealer to buy a new car and the dealer hands you a key and tells you to test drive the car. You sit in the driver's seat and look for the key hole of the ignition. You check the steering column, the dashboard, and the immediate area to no avail. You ask the dealer how to start the car, and he or she says, “Oh, with this model you use the key to open the trunk and inside the trunk you'll find a red button. Just push the red button and the car will start.” Now you are upset because the car maker modified the public interface you have come to associate with automobiles.
One of the basic ideas in the object-oriented paradigm is exactly this philosophy. All implementation constructs in your system should be hidden from their users behind a well-defined, consistent public interface. Users of the construct need to know about the public interface but are never allowed to see its implementation. This allows the implementor to change the implementation whenever he or she desires, so long as the public interface remains the same. As a frequent traveler, I can assure you that the benefits of being able to use alarm clocks without knowledge of their implementation are great. I have stayed in many hotels using a wide assortment of alarm clocks; electric, windup, battery operated, in both digital or analog models. Not once have I sat on a plane worrying that I wouldn't be able to use the alarm clock in my hotel room.
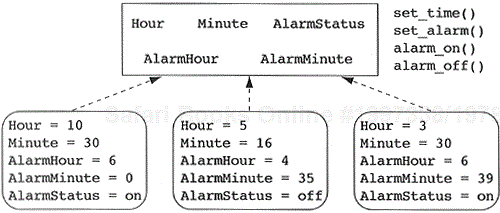
Most readers immediately understood what I meant by the term “alarm clock” even though there probably wasn't an alarm clock nearby. Why is that? You have seen many alarm clocks in your life and realized that all alarm clocks share certain attributes such as a time, an alarm time (both displayed in terms of hours and minutes), and a designation as to whether the alarm is on or off. You also realize that all alarm clocks you have seen allow you to set their time, set their alarm time, and turn the alarm on and off. In effect, you now have a concept, called alarm clock, which captures the notion of data and behavior of all alarm clocks in one tidy package. This concept is known as a class. The physical alarm clock you hold in your hand is an object (or instance) of the alarm clock class. The relationship between the notion of class and object is called the instantiation relationship. An alarm clock object is said to be instantiated from the alarm clock class, while the alarm clock class is said to be the generalization of all alarm clock objects you have encountered (see Figure 2.1).
If I were to tell you that my alarm clock jumped off my nightstand, bit me, then chased after the neighbor's cat, you would almost certainly consider me mad. If I told you my dog did the same things, it would sound quite reasonable. This is because the name of a class not only implies a set of attributes, it also denotes the behavior of the entity. This bidirectional relationship between data and behavior is a cornerstone of the object-oriented paradigm.
An object will always have four important facets:
its own identity (This might only be its address in memory.);
the attributes of its class (usually static) and values for those attributes (usually dynamic);
the behavior of its class (the implementor's view);
the published interface of its class (the user's view).
To put this discussion in the perspective of software development, a class can be implemented as a record definition with the important addition of the list of operations allowed to work with that record definition. In a procedural language it is easy to find data dependencies on a given function. Simply examine the implementation of the function and look at the data types of all parameters, return values, and local variable declarations. If, however, you want to find the functional dependencies on a data definition, you are required to examine all of the code, looking for functions dependent on your data. In the object-oriented model, both types of dependencies (data to functions and functions to data) are readily available. Objects are variables of a class data type. Their internal details should be visible only to the list of functions associated with their class. This limiting of access to the internal details of objects is called information hiding. It is optional in many object-oriented languages, which leads to our first and most important heuristic.
All data should be hidden within its class.
The violation of this heuristic effectively throws maintenance out the window. The consistent enforcement of information hiding at the design and implementation level is responsible for a large part of the benefits of the object-oriented paradigm. If data is made public, it becomes difficult to determine which portion of the system's functionality is dependent on that data. In fact, the mapping of data modifications to functionality becomes identical to that in the action-oriented world. We are forced to examine all of the functionality in order to determine which is dependent on the public data.
From time to time, a developer will argue, “I need to make this piece of data public because ….” In this case, the developer should ask him or herself, “What is it that I'm trying to do with the data and why doesn't the class perform that operation for me?” In all cases the class is simply missing a necessary operation. Consider the File class in Figure 2.2. The developer accidentally thought that the byte_offset data member should be global to allow for random-access I/O, but what was really needed was an operation(s) to perform that task. (Note to non-C programmers: The functions fseek and ftell are standard C library routines for handling random-access file I/O.) Beware of developers who boldly state, “We can make this piece of data public because it will never change!” One of Murphy's laws of programming will see to it that it is the first piece of data that needs to change.

We can further illustrate the benefits of data hiding by considering an example of a point class whose implementation is in rectangular coordinates (see Figure 2.3). The naive designer might argue that we can make the x- and y-coordinates of the point public because that implementation will never change. Inevitably, some new requirement will force a change to polar coordinates, thereby affecting any user of the class point. Had we made the data hidden, then only the implementors of the class would have needed to modify their code.

Objects should be treated as machines that will carry out operations in their public interface for anyone who makes an appropriate request. Due to the independence of an object toward its user, and the syntax of some of the early languages that implemented object-oriented concepts, the term “sending a message” is used to describe the execution of an object's behavior. When an object is sent a message, it must first decide it if understands the message. Assuming it understands the message, the object maps the message to a function call passing itself as an implied first argument. Deciding the understandability of a message is done at runtime in the case of an interpreted language and at compile time in the case of a compiled language.
The name (or prototype) of an object behavior is called a message. Many object-oriented languages support the notion of overloaded functions or operators. This construct states that two functions in the system can have the same name as long as their argument types differ (intraclass overloading) or they are attached to different classes (interclass overloading). The alarm clock class might have two set_time messages, one that takes two integers and one that takes a character string. This would be an example of intraclass overloading.
void AlarmClock::set_time(int hours, int minutes); void AlarmClock::set_time(String time);
Alternately, alarm clocks and watches might both have a set_time message that takes two integers. This would be an example of interclass overloading.
void AlarmClock::set_time(int hours, int minutes); void Watch::set_time(int hours, int minutes);
It is important to note that a message consists of the function name, argument types, the return type, and the class to which it is attached. This is the primary information that a user of a class needs to know. In some languages and/or systems, additional information may be presented, such as the types of exceptions thrown from the message as well as any relevant concurrency information (e.g., whether the message is synchronous or asynchronous). The implementors of a class are required to know how a message is implemented. The implementation of a message—the code that implements a message—is called a method. Once the thread of control is inside a method, all reference to the data members of the object to which the message was sent is through the implied first argument. This implied first argument of the method is called the self object in many languages (C++ prefers to call it the “this” object). Finally, the list of messages to which an object can respond is called its protocol.
There are two special messages to which classes/objects can respond. The first is an operation that users of a class call in order to construct objects of the class. This is called a constructor of the class. A class may have many constructors, each taking a different set of initialization parameters. For example, we may be able to construct alarm clocks by giving the class five integer arguments specifying the hours, minutes, alarm hours, alarm minutes, and alarm status; or we may want to pass two strings and an integer argument. Each string would be of the form “hour:minutes,” signifying the time and alarm time, respectively, while the integer would specify the alarm status. Some classes have a dozen or more constructor functions.
The second special message to which classes/objects can respond is an operation that cleans up an object prior to its removal from the system. This operation is called a destructor of the class. Most object-oriented languages have only one destructor per class since any decisions that need to be made at runtime can be stored as part of the object's state. There is no need to pass additional arguments into the method. We will refer to both constructors and destructors during various topics within this text. Consider them the initialization and clean-up mechanisms of the object-oriented paradigm.
Users of a class must be dependent on its public interface, but a class should not be dependent on its users.
The rationale behind this heuristic is one of reusability. An alarm clock might be used by a person in a bedroom (see Figure 2.4). The person is obviously dependent on the public interface of the alarm clock. However, the alarm clock should not be dependent on the person. If the alarm clock were dependent on its user, namely the person, then it could not be used to build a timelock safe without attaching a person to the safe. These dependencies are undesirable, since we want to be able to lift the alarm clock out of its domain and deposit it into another domain with no user dependencies. It is best to view the alarm clock as a little machine having no knowledge of its users. It simply performs the behaviors defined in its public interface for whoever sends it a message.

Minimize the number of messages in the protocol of a class.
The exact opposite of this heuristic was published some years back. The claim was that if a class implementor can think of some operation for a class, then someone will want to use it in the future. Why not implement it? If you follow this heuristic, then you will love my LinkedList class—it has 4,000 operations in its public interface. The problem is that you want to execute a merging of two LinkedList objects. You assume the LinkedList class must have this operation so you scan its alphabetized list of messages. You cannot find an operation called merge, union, combine, or any other known synonym. Unfortunately, it is an overloaded plus operator (operator+ in C++). The problem with large public interfaces is that you can never find what you are looking for. This is a serious problem with reusability in general. By keeping the interface minimal, we make the system easier to understand and the components easier to reuse.
Implement a minimal public interface that all classes understand [e.g., operations such as copy (deep versus shallow), equality testing, pretty printing, parsing from an ASCII description, etc.].
If the classes that a developer designs and implements are to be reused by other developers in other applications, it is often useful to provide a common minimal public interface. This minimal public interface consists of functionality that can be reasonably expected from each and every class. The interface serves as a foundation for learning about the behaviors of classes in a reusable software base. We will discuss specific items for this minimal public interface in more detail in Chapter 9.
Do not put implementation details such as common-code private functions into the public interface of a class.
This heuristic is designed to reduce the complexity of the class interface for its users. The basic idea is that users of a class do not want to see members of the public interface which they are not supposed to use. These items belong in the private section of the class. A common-code private function is created when two methods of a class have a sequence of code in common. It is usually convenient to encapsulate this common code in its own method. This method is not a new operation; it is simply an implementation detail of two operations of the class. Since it is an implementation detail, it should be placed in the private section of the class, not the public section (see Figure 2.5).

In order to get a more real-world feel for common-code private functions, consider the class X to be a linked list, f1 and f2 to be the functions insert and remove, and the common-code private function f to be the operation for finding the location in the linked list for an insertion or removal.
Do not clutter the public interface of a class with items that users of that class are not able to use or are not interested in using.
This heuristic is related to the previous one in that any common-code functions placed in the public interface are only cluttering that interface since users of the class do not want to call such functions. They are not new operations of the class. Some languages, such as C++, allow for the erroneous inclusion of other types of functions in the public interface of a class. For example, it is legal in C++ to place the constructor of an abstract class in the public interface of that class even though the user of the class will receive a syntax error if he or she attempts to use such a constructor. The more general heuristic (2.6) is included to preclude these problems.
A number of heuristics deal with coupling and cohesion between/within classes. We strive for tight cohesion within classes and loose coupling between classes. This runs parallel to heuristics in the action-oriented paradigm which attempt to achieve the same goals with functions. Tight cohesion in a function implies that all the code making up the function is closely related. Loose coupling between functions implies that when one function wishes to use another, it should always enter and exit the function from one point. This leads to action-oriented heuristics such as, “A function should be structured such that it has only a single return statement.”
In the object-oriented paradigm, we mirror the goals of loose coupling and tight cohesion at the class level. There are five basic forms of coupling between classes: nil coupling, export coupling, overt coupling, covert coupling, and surreptitious coupling. Nil coupling is the best, as it implies two classes that have absolutely no dependency on one another. You may eliminate one of the classes without affecting the other class. Of course, it is not possible to have a meaningful application built with only nil coupling. The best we can produce with only nil coupling is a class library, a collection of stand-alone classes that have nothing to do with one another. Export coupling states that one class is dependent on the public interface of another class, that is, it uses one or more published operations of another class. Overt coupling occurs when one class uses the implementation details of another class with permission. A good example of overt coupling can be found in the “friend” mechanism in C++. A C++ class X can grant friendship to another class Y, thereby granting the methods of class Y access to the private implementation details of class X. Covert coupling is the same as overt coupling except no permission is granted to the class Y. If we invent a language that allows a class Y to state, “I am a friend of class X and will take access to its private implementation,” then the classes X and Y are covertly coupled. The last form of coupling, surreptitious coupling, states that a class X knows the internal details of class Y through some means. If a class X uses a public data member of class Y, then X is said to be surreptitiously coupled to class Y. This is the most dangerous form of coupling because it creates a strong implicit dependency between the behavior of Y and the implementation of X.
Classes should only exhibit nil or export coupling with other classes, that is, a class should only use operations in the public interface of another class or have nothing to do with that class.
All other forms of coupling allow a class to give away implementation details to other classes, thereby creating implied dependencies between the implementations of the two classes. These implied dependencies always cause future maintenance problems when one of the classes wishes to change its implementation.
Class cohesion strives to ensure that all of the elements of a class are strongly related. A number of heuristics apply to this property.
A class should capture one and only one key abstraction.
A key abstraction is defined as a main entity within a domain model. Key abstractions often show up as nouns within requirements specifications. Each key abstraction should map to only one class. If it maps to more than one class, then the designer is probably capturing each function as a class. If more than one key abstraction maps to the same class, then the designer is probably creating a centralized system. These classes are often called vague classes and need to be split into two or more classes that capture one abstraction each. In Chapter 3 we will explore these two degenerate designs in more detail.
Keep related data and behavior in one place.
A violation of this heuristic will cause a developer to program by convention. That is, to accomplish some atomic system requirement, he or she will need to affect the state of the system in two or more areas. The two areas are actually of the same key abstraction and therefore should have been captured in the same class. The designer should watch for objects that dig data out of other objects via some “get” operation. That type of activity implies that this heuristic is being violated. Consider a user of a stove class trying to preheat an oven for cooking. The user should only send the stove an are_you_preheated?() message. The oven can test if the actual temperature has reached the desired temperature, along with any other constraints concerning the preheating of ovens. A user who decides if the oven is preheated by asking the oven for its actual temperature, its desired temperature, the status of its gas valve, the status of its pilot light, etc., is violating this heuristic. The oven owns the information of temperature and gas cooking apparatus; it should decide if the object is preheated. It is important to note the need for “get” methods (e.g., get_actualtemp(), get_desiredtemp(), get_valvestatus(), etc.) in order to implement the incorrect preheat method.
Spin off nonrelated information into another class (i.e., noncommunicating behavior).
The developer should look for classes with a subset of methods that operate on a proper subset of the data members. The extreme case is a class where half of the methods work on one half of the data members and the other half of the methods work on the other half of the data members (see Figure 2.6).

For a more real-world example, consider a dictionary class. For small dictionaries the best implementation is a property list (a list of words and their definitions), but for larger dictionaries a hash table is better (i.e., faster). Both dictionary implementations require the ability to add and find words. A design of a dictionary class that exhibits noncommunicating behavior is shown in Figure 2.7.
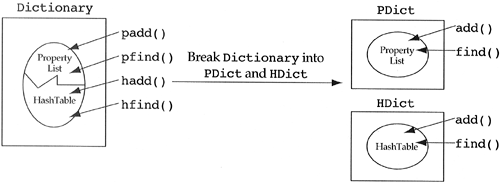
This solution assumes that the users of the dictionary class will have knowledge of how large the dictionary is going to be; they are required to make the decision between hash table and linked list implementations. In general, displaying implementation details in the class name and allowing users to make such decisions are bad ideas. A better solution to this problem is shown in Chapter 5 since it requires the inheritance relationship. In that solution a single dictionary class hides its representation as an internal detail. The dictionary class decides to change its representation when the size of the dictionary reaches a predetermined threshold.
In addition to fixed data and behavioral descriptions, objects have local state (i.e., a snapshot) at runtime of the dynamic values of an object's data descriptions. The collection of all possible states of a class's objects, along with the legal transitions from one state to another, is called the dynamic semantics of the class. Dynamic semantics allow an object to respond differently to the same message sent at two different times in the life of the object. Consider the following abstract example:
Method junk for the class X
if (local state #1) then
do something
else if (local state #2) then
do something different
End Method
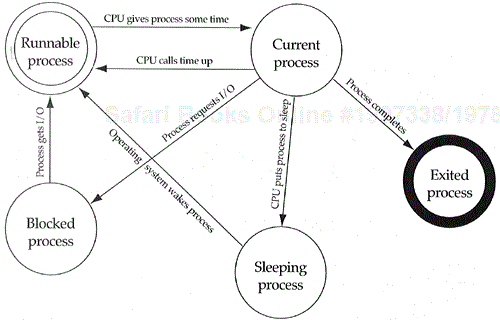
The dynamic semantics of objects are an integral part of any object-oriented design. In general, any class with interesting dynamic semantics should have those semantics documented in a state-transition diagram (see Figure 2.8). Classes with interesting dynamic semantics include those classes having a finite number of states, with well-defined transitions from one state to another. The state-transition diagram in Figure 2.9 details the dynamic semantics of the processes in an operating system. It shows that processes can be in a runnable state, the current process state, the blocked state, the sleeping state, or the exited state. In addition, processes can be created only in the runnable state; they can be destroyed only in the exited state; they can exit only if they are in the current process state; and they can become the current process only if they are first a runnable process. This information can be very useful for creating test suites for our class and its objects. Some designers accidentally model dynamic semantics as static semantics. This mistake leads to a proliferation of classes, a serious problem in the object-oriented paradigm. We will explore this problem and its avoidance in Chapter 5 when discussing the inheritance relationship.

In addition to the classes we have discussed so far, there is an important type of abstraction we need to explore. Consider the following questions: Have you ever eaten a fruit? How about an appetizer? What about a dessert? Many people answer yes to all three questions. In the event that you answered yes to any of these questions, consider these questions: What does a fruit taste like? How many calories are in a dessert? How much does an appetizer cost?
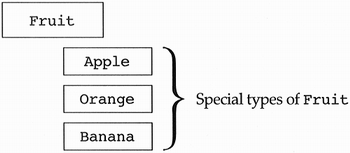
I claim that nobody has eaten a fruit. Lots of people have eaten apples, bananas, and oranges, but nobody has eaten a .3-pound red fruit. Likewise, a waiter approaches you in a restaurant and asks you what you would like for dinner. You answer, “an appetizer, an entree, and a dessert.” If the waiter simply walks away, you've got a problem since you like shrimp cocktail but hate melon (two potential appetizers). We agree that there is no such thing as a fruit, appetizer, or dessert object, but these terms do capture useful information. If I held up an alarm clock and said, “What do you think of my fruit?” you would think I was crazy. If I held up an apple and asked the same question, you would consider me sane. The notion of fruit captures useful information even though you cannot create objects of it. It is, in effect, a class (concept) that does not know how to instantiate objects of its type.
Classes that do not know how to instantiate objects are called abstract classes.
Classes that do know how to instantiate objects are called concrete classes.
Watch out for the commonly used term abstract data type, or ADT. It is sometimes used as a synonym for class with no distinction between abstract class and concrete class.
An important use of abstract classes in the object-oriented paradigm is to facilitate the construction of inheritance hierarchies, that is, they connote the notion of category headings (see Figure 2.10). We will discuss their usefulness in Chapter 5.
Be sure the abstractions that you model are classes and not simply the roles objects play.
Is Mother or Father a class, or are they the roles that certain Person objects play? The answer depends on the domain that a designer is modeling. If, in the given domain, Mother and Father have different behavior, then they should probably be modeled as classes. If they have the same behavior, then they are different roles that objects of the Person class play. For example, we can view a family as an object of the class Father, an object of the class Mother, and several Child objects. An alternative might be to think of a family as a Person object called father, a Person object called mother, and an array of Person objects called children (see Figure 2.11). The distinction depends on differing behavior. Before creating separate classes, be sure the behavior is truly different and that you do not just have a situation where each role is using a subset of the Person functionality. Remember, there is nothing wrong with an object using a subset of its class's behavior.

Some designers test if a member of a public interface cannot be used in a given role. If it cannot be used, this implies the need for a different class. If it is simply not being used, then it is the same class used in multiple roles. For example, if an operation of mother is go_into_labor(), then mother is best implemented as a separate class since fathers are incapable of going into labor. However, if our family lives in a sexist society where only mothers are to execute the change_diaper() method, then mother is simply a role of the person class. This decision is made because fathers could execute the change_diaper() method if necessary. This point gets convoluted in more abstract domains where it is not clear what cannot be executed versus what a designer or domain chooses not to execute.
During the design process, object-oriented designers are clearly drawn to make or not make a particular role into a class. This implies that there is a missing heuristic waiting to be discovered. The preceding paragraph gives a best guess to this heuristic, but I am not yet satisfied that it will apply to all domains.
- Abstract class
A class that does not know to instantiate objects of itself.
- Class
The encapsulation of data and behavior in a bidirectionally related construct. Correlates to a concept in the real world. Synonyms include abstract data type or ADT.
- Concrete class
A class that knows how to instantiate objects of itself.
- Constructor
A special operation of a class that is responsible for building/initializing objects of the class.
- Destructor
A special operation of a class that is responsible for destroying/cleaning up objects of that class.
- Dynamic semantics
The collection of all possible states that an object of a class can have, along with the allowable transitions from one state to another. Often documented through a state-transition diagram.
- Information hiding
The ability of a class to hide its implementation details from the users of objects of that class.
- Instantiation relationship
The relationship between a class and its object(s). Classes are said to instantiate objects.
- Key abstraction
A key abstraction is defined as a main entity within a domain model. Key abstractions often show up as nouns within the domain vocabulary.
- Message
The name of an operation defined on a class. In strongly typed languages, a message may include the name, return type, and argument types of the operation (i.e., its prototype).
- Method
The implementation of a message.
- Object
An example member of a class consisting of its own identity, the behavior of the class, the interface of the class, and a copy of the class's data. Also called an instance of the class.
- Overloaded function
The ability to have two functions with the same name so long as their argument types differ (intraclass overloading) or they are attached to different classes (interclass overloading).
- Protocol
The list of messages to which a class can respond.
- Self object
The reference to the object to which a message is sent, when it is within the method.
Heuristic 2.1. All data should be hidden within its class.
Heuristic 2.2. Users of a class must be dependent on its public interface, but a class should not be dependent on its users.
Heuristic 2.3. Minimize the number of messages in the protocol of a class.
Heuristic 2.4. Implement a minimal public interface that all classes understand [e.g., operations such as copy (deep versus shallow), equality testing, pretty printing, parsing from an ASCII description, etc.].
Heuristic 2.5. Do not put implementation details such as common-code private functions into the public interface of a class.
Heuristic 2.6. Do not clutter the public interface of a class with things that users of that class are not able to use or are not interested in using.
Heuristic 2.7. Classes should only exhibit nil or export coupling with other classes, that is, a class should only use operations in the public interface of another class or have nothing to do with that class.
Heuristic 2.8. A class should capture one and only one key abstraction.
Heuristic 2.9. Keep related data and behavior in one place.
Heuristic 2.10. Spin off nonrelated information into another class (i.e., noncommunicating behavior).
Heuristic 2.11. Be sure the abstractions that you model are classes and not simply the roles objects play.