
Advantages of DB2 data sharing
DB2 data sharing improves the availability of DB2, enables scalable growth, and provides more flexible ways to configure your environment. You don't need to change SQL in your applications to use data sharing, although you might need to do some tuning for optimal performance.
Improves availability of data
More DB2 users demand access to DB2 data every hour of the day, every day of the year. DB2 data sharing helps you meet this service objective by improving availability during both planned and unplanned outages.
As Figure 12.1 illustrates, if one subsystem fails, users can access their DB2 data from another subsystem. Transaction managers are informed that DB2 is down and can switch new user work to another DB2 subsystem in the group.
Figure 12.1. How data sharing improves availability during outages. If a DB2 subsystem or the entire central processor complex (CPC) fails, work can be routed to another system.

For unplanned outages, the z/OS automatic restart manager can automate restart and recovery.
While the increased availability of DB2 has some performance cost, the overhead for interprocessor communication and caching of changed data is minimized. DB2 provides efficient locking and caching mechanisms and uses coupling facility hardware. A coupling facility is a special logical partition that runs the coupling facility control program. It provides high-speed caching, list processing, and locking functions in a Sysplex. The DB2 structures in the coupling facility benefit from high availability. The coupling facility uses automatic structure rebuild and duplexing of the structures that are used for caching data. ![]()
Enables scalable growth
As you move more data processing onto DB2, your processing needs can exceed the capacity of a single system. This section describes how data sharing relieves that constraint.
Without data sharing
Without DB2 data sharing, you have these options for relief:
Copy the data, or split the data into separate DB2 subsystems.
This approach requires that you maintain separate copies of the data. No communication takes place among DB2 subsystems, and the DB2 catalog is not shared.
Install another DB2 subsystem and rewrite applications to access the original data as distributed data.
This approach might relieve the workload on the original DB2 subsystem, but it requires changes to your applications and has performance overhead of its own. Nevertheless, for DB2 subsystems that are separated by great distance or for a DB2 subsystem that needs to share data with a system outside the data sharing group, the distributed data facility is still your only option.
Install a larger processor and move data and applications to that machine.
This option can be expensive. In addition, this approach demands that your system come down while you move to the new machine.
With data sharing
With DB2 data sharing, you can take advantage of the following benefits:
Incremental growth
The Parallel Sysplex cluster can grow incrementally. You can add a new DB2 subsystem onto another central processor complex and access the same data through the new DB2 subsystem. You no longer need to manage copies or distribute data. All DB2 subsystems in the data sharing group have concurrent read-write access, and all DB2 subsystems use a single DB2 catalog.
Workload balancing
DB2 data sharing provides flexibility for growth and workload balancing. With the partitioned data approach to parallelism (sometimes called the shared-nothing architecture), a one-to-one relationship exists between a particular DBMS and a segment of data. By contrast, data in a DB2 data sharing environment does not need to be redistributed when you add a new subsystem or when the workload becomes unbalanced. The new DB2 member has the same direct access to the data as all other existing members of the data sharing group.
DB2 works closely with the z/OS Workload Manager (WLM) to ensure that incoming work is optimally balanced across the systems in the cluster. WLM manages workloads that share system resources and have different priorities and resource use characteristics.
Example: Assume that large queries with a low priority are running on the same system as online transactions with a higher priority. WLM can ensure that the queries don't monopolize resources and don't prevent online transactions from achieving acceptable response times. WLM works in both a single system and a multisystem (data sharing) environment.
Capacity when you need it
A data sharing configuration can handle your peak loads. You can start data sharing members to handle peak loads, such as end-of-quarter processing, and then stop them when the peak passes.
You can take advantage of all of these benefits, whether your workloads are for online transaction processing (OLTP), or a mixture of OLTP, batch, and queries.
Higher transaction rates
Data sharing gives you opportunities to put more work through the system. As Figure 12.2 illustrates, you can run the same application on more than one DB2 subsystem to achieve transaction rates that are higher than is possible on a single subsystem.
Figure 12.2. How data sharing enables growth. You can move some of your existing DB2 workload onto another central processor complex (CPC).

More capacity to process complex queries
Sysplex query parallelism enables DB2 to use all the processing power of the data sharing group to process a single query. For users who do complex data analysis or decision support, Sysplex query parallelism is a scalable solution. Because the data sharing group can grow, you can put more power behind those queries even as those queries become increasingly complex and run on larger and larger sets of data.
Figure 12.3 shows that all members of a data sharing group can participate in processing a single query.
Figure 12.3. Query processed in parallel by members of a data sharing group. Different DB2 members process different partitions of the data.

This is a simplification of the concept—several DB2 subsystems can access the same physical partition. To take full advantage of parallelism, use partitioned table spaces.
Supports flexible configurations
DB2 data sharing lets you configure your system environment much more flexibly.
As Figure 12.4 shows, you can have more than one DB2 data sharing group on the same z/OS Sysplex. You might, for example, want one group for testing and another for production data.
Figure 12.4. A possible configuration of DB2 data sharing groups. Although this example shows one DB2 for each z/OS system, your environment could have more.
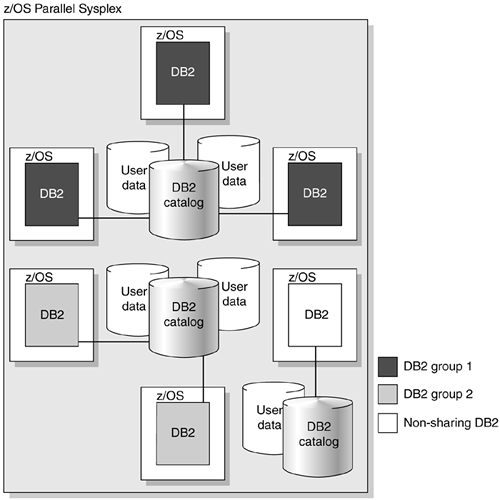
You can also run multiple members on the same z/OS image (not shown in Figure 12.4).
Flexible operational systems
Figure 12.5 shows how, with data sharing, you can have query user groups and online transaction user groups on separate z/OS images. This configuration lets you tailor each system specifically for that user set, control storage contention, and provide predictable levels of service for that set of users. Previously, you might have needed to manage separate copies of data to meet the needs of different user groups.
Figure 12.5. Flexible configurations with DB2 data sharing. Data sharing lets each set of users access the same data, which means that you no longer need to manage multiple copies.

Flexible decision support systems
Figure 12.6 shows two different decision support configurations. A typical configuration separates the operational data from the decision support data. Use this configuration when the operational system has environmental requirements that are different from those of the decision support system. The decision support system might be in a different geographical area, or security requirements might be different for the two systems.
Figure 12.6. Flexible configurations for decision support. DB2 data sharing lets you configure your systems in the way that works best within your environment.

DB2 offers another option—a combination configuration. A combination configuration combines your operational and decision support systems into a single data sharing group and offers these advantages:
You can occasionally join decision support data and operational data with SQL.
You can reconfigure the system dynamically to handle fluctuating workloads. For example, you might choose to dedicate CPCs to decision support processing or operational processing at different times of the day or year.
You can reduce the cost of computing:
- The infrastructure that is used for data management is already in place.
- You can create a prototype of a decision support system in your existing system and then add processing capacity as the system grows.
To set up a combination configuration, separate decision support data from operational data as much as possible. Buffer pools, disks, and control units that you use in your decision support system should be separate from those that you use in your operational system. This separation greatly minimizes any negative performance impact on the operational system.
If you are unable to maintain that level of separation or if you have separated your operational data for other reasons such as security, using a separate decision support system is your best option.
Flexibility to manage shared data
Data sharing can simplify the management of applications that must share some set of data, such as a common customer table. Maybe these applications were split in the past for capacity or availability reasons. But with the split architecture, the shared data must be synchronized across the multiple systems (that is, by replicating data).
Data sharing gives you the flexibility to configure these applications into a single DB2 data sharing group and to maintain a single copy of the shared data that can be read and updated by multiple systems with good performance. This is an especially powerful option when businesses undergo mergers or acquisitions or when data centers are consolidated.
Leaves application interfaces unchanged
Your investment in people and skills is protected because existing SQL interfaces and attachments remain intact when sharing data.
You can bind a package or plan on one DB2 subsystem and run that package or plan on any other DB2 subsystem in a data sharing group.