
Chapter 6
Web Browsing
Abstract
Using open source tools to collect memory and analyze it as part of a forensic investigation.
Keywords
operating systems
forensics
operating environments
INFORMATION INCLUDED IN THIS CHAPTER:
• Web browser artifacts
• Messaging artifacts
• E-mail artifacts
Introduction
Most of our lives are lived on the Internet these days. Between e-mail, social networking, YouTube, and a wide variety of other Web sites we visit regularly, our access to the network is very common. In addition, our lives living inside of digital artifacts such as browsing habits, bookmarks, histories, e-mail archives, and logs of who we message, there is no point in pretending that the Internet is not an enormous pathway for attacks. This may come in the form of malware inserted into Web sites or it may just be phishing attacks or other forms of spam that may or may not come with malware. It can be difficult to get actual numbers since the organizations are not required to provide vetted statements, but reliable estimates suggest that spam advertisement of just off-shore pharmacies generates tens of millions of dollars a year for the Russian business interests behind that spam. This is just the amount of money generated from the pharmacy businesses.
E-mail is also used to infect PCs around the world to create a collection of connected computers commonly called a botnet. Many of the worldwide network and system breaches have taken place because someone opened an e-mail message. While laws around the world are not generally on the same page, when it comes to whether these activities are illegal or not, countries such as the United States, Great Britain, and Germany to name just three are all generally on the same page with regards to attacking and compromising systems.
Understanding how to find e-mail messages and parse them correctly is an important skill. Of course, searching for browser artifacts has long been established as important. Almost fifteen years ago, I was asked to dig up some evidence that an employee at a company I was working for, had been using the work computer to look at pornographic Web sites at work. There are so many other reasons to go looking for browsing history and any other pieces of information that may be available related to a user’s Web browsing.
Web- or Internet-based communications have also been increasing over the years. Conference calls through services like WebEx, international calling using services like Skype, instant messaging through a variety of platforms – these are all in common usage and collectively are overtaking the use of traditional desk phones to communicate. There are ways to locate artifacts related to the use of those services and they are just as important as getting call detail records from a telephone company.
A primer on structured query language (SQL)
We are in the era of big data. In the early days of common Internet usage with Web browsers, when Mosaic was the common browser of choice and even after that with Internet Explorer and Netscape, a variety of text-based files were used to store information like history and bookmarks. In the case of Netscape, bookmarks were stored as HTML files, which are of course text-based, though with a well-known structure. Today, though, browsing usage has increased and strictly text-based storage of data is inefficient. Instead, many browsers have moved to using databases to store a lot of information. As a result, in order to perform forensic analysis of browsing activity, it is helpful to understand a little about how databases work.
The most common type of database in use at the moment is relational. Relational databases were first described in 1970 and they are based around the idea of a relation, which is really a set of data all belonging together in a collection. This collection, in practice, is called a table. Each database may consist of multiple tables that are connected in some way, even if it is loosely connected. The table consists of attributes and tuples, where the tuples are actually entries in the table. You can think of attributes as columns in the table and a tuple as a row. A visual representation may make more sense and you can see what each of these words means in context in Figure 6.1.
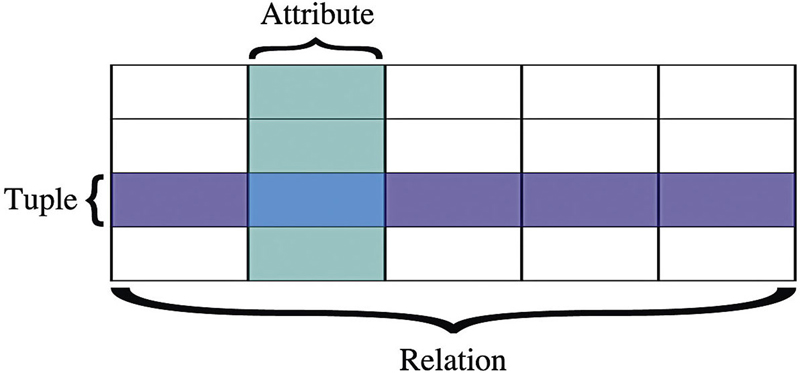
Figure 6.1
We need a programmatic way of getting data into the tables as well as getting it out again. One way of doing that is to use the structured query language (SQL), originally called the structured query English language and abbreviated SEQUEL. The language was developed in the early 1970s and the name had to be changed to avoid a trademark conflict, though the acronym SQL is commonly pronounced sequel1. As with any programming language, it can take ages to learn the intricacies and details to become an expert. However, there are some fundamentals, which we can use that are pretty easy to pick up and we can extract information from the databases, we are looking at using these SQL basics. Let us start with a very simple table, which you can see in Figure 6.2 and which looks a lot like a spreadsheet with the columns and rows.
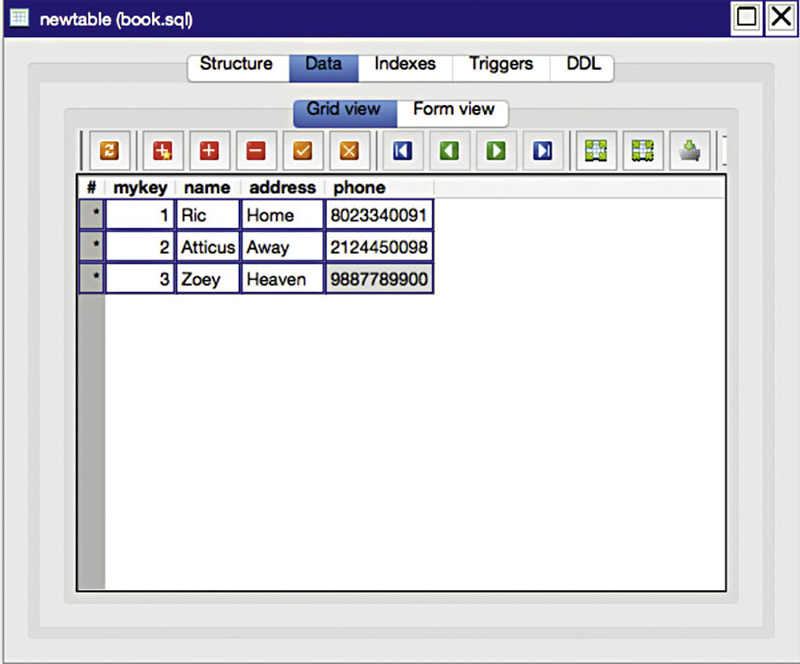
Figure 6.2
You will notice that each column has a name rather than a number. These are the attributes and they have names so we can refer to them. In order to create that table, we would use the following SQL.

You will notice that this looks an awful lot like English, which was really the point. We are going to create a table named mytable. The contents of the table are four attributes. The first attribute is called mykey and it is an integer, means that it is a whole number. This attribute cannot be blank, which means NOT NULL. If we were to try to insert a row without this value, the insert would fail. You will also note that it says PRIMARY KEY, which means, a value that the row or tuple will be identified by. When you specify a value as being a primary key, each value must be unique. You cannot have multiple keys in a single table that all have the same value. Again, this would generate an error within the database. The other attributes within the table are all string values, referred to as a VARCHAR, which means a data type that has a variable number of characters. You can specify exactly how many characters the VARCHAR is constrained to, but in this case, the number of characters is unspecified.
We need to know the attribute names in order to do anything useful like putting data into the database. We do this with an INSERT statement. In order to insert a set of values into the database, the syntax for the INSERT statement would look like this:

This means, we are inserting values into a table named mytable. We can limit the number of attributes we are going to set, but in this case, I have used all of the attribute names, which suggests that I am going to specify values for all of the attributes. If the number of attributes I specify does not match the number of values I am handing in, the insert will fail. The portions of the statements where I have used capital letters are SQL keywords. The rest is related to the structure of the database and the values I am going to pass in. This statement will add a row into our table. At some point, though, we want to get data out and that is going to be the common way we interact with databases. We do not want to insert data because it would corrupt the information, we are investigating. In order to extract data from the database, we use the SELECT statement. If we wanted to pull all of the information out of the table, we would use the following statement:
SELECT * FROM mytable;
It is really that simple. This statement means that we want all the rows and all the columns. We are not going to limit the columns we return, though we could. I also have not set a condition on the select statement, which means, we get all the rows that are available. If we wanted to limit the data we get back, we could alter the SELECT statement. Let us say, I wanted only the name and addr attributes where the key is bigger than 3. That query would look like this:
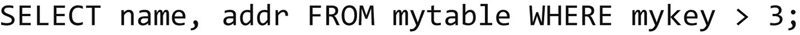
You may have noticed that I have a semi-colon at the end of each line. It is common to terminate SQL statements with a semi-colon. I can use a variety of matching conditions to indicate the data that I want to return from the table. Using different conditional clauses, we can get different results. You can use common conditionals like <, > or =, as well as some others that are geared toward specific data types like dates or strings.
You may think of databases as needing a server. The reality is that while databases do commonly use servers, meaning applications that manage the storage for a number of databases as well as the connections to the server from various clients. However, it is possible to use what is called an embedded database, which means that the storage management is embedded into the application and the databases are really just a collection of files on disk. This is commonly the case where browsers are concerned. One of the most popular embedded databases is called Sqlite and it is the one we will be using the most, since it is what Chrome and Firefox use to start with. There are a number of applications you can use to interact with these Sqlite databases depending on the operating system you use, including extensions for some browsers that you can use to open and query these database files, we are going to be working with. In terms of this chapter, I will be using a combination of tools, including the sqlite command line program.
Web browsing
There are a number of Web browsers that are available across multiple operating systems. Many of these browsers work on multiple operating systems. We will be spending our time with four browsers and a little time on a fifth browser. First, we have to cover Internet Explorer. It is only used on the Windows operating system currently, though it used to be in development for other operating systems as well. Since, Windows is the predominant desktop operating system and Internet Explorer is still a significant player in the browser space, we have to cover it. Additionally, programs that use the underlying libraries that make Internet Explorer work may leave artifacts in the same places that Internet Explorer does.
The second browser that we need to cover is Chrome. Chrome runs on Windows, Linux and Mac OS X. There is also an open source version of Chrome called Chromium. Chromium will run on multiple operating systems and looks like Chrome, so the artifacts will look the same. Another open source-based browser is Firefox. Firefox uses the Gecko rendering engine (the component of the browser that takes the source code and makes it look like something) from the Mozilla Foundation. The same engine is in use by several other open source browsers. In addition, the primary browser used by Debian-based Linux distributions is Iceweasel, which is based on Firefox.
Finally, the last major browser to cover is Safari, developed by Apple for use on Mac OS X and Windows. Safari is included by default in Mac OS X, but it commonly comes in fourth in usage percentages Well below Safari in usage statistics is Opera, though it has long and a fairly loyal following. As a result, we will touch briefly on Opera over the course of this coverage.
Google Chrome
Google Chrome is a browser that runs on a wide variety of operating systems. Interestingly, many Web browsers have a shared history, when it comes to underlying components. Google took the WebKit engine from Apple, which created WebKit from a fork of an open source-rendering engine called KHTML. WebKit served as the foundation for Chrome until 2013, when Google began developing its own rendering engine that is based on a fork of WebKit. Google calls this new rendering engine Blink. In order to extend the functionality of Chrome, Google allows third party developers to create extensions, though it is far more controlled about what developers are allowed access to than Firefox, which began using add-ons before Chrome even existed.
In terms of configuration settings and user-related details, we will be looking at Sqlite3 databases. What I did not mention earlier is that in addition to being a Web browser, Chrome is an application delivery platform. Instead of having to develop standalone applications, you can develop applications to be displayed inside of Chrome. All installation, updating, and management is done inside of Chrome. The reason for mentioning this is because there are some applications that can be used to view Sqlite databases inside Chrome. One of them, TadpoleDB, uses Chrome to deliver an interface to the tadpoledb.com Web site. You can upload your Sqlite databases through the client interface displayed in Chrome and then browse the data, which includes executing queries. For our purposes, since this is potentially personal or sensitive information, I am going to stay local and use a native client rather than uploading a database to a remote website.
Chrome stores the important information in different places depending on the operating system. Table 6.1 indicates the directory path you can look for the user-specific databases for each operating system.
Table 6.1
Chrome Database Locations by Operating System
| Operating system | Path |
| Windows XP | C:Documents and SettingsusernameLocal SettingsApplication DataGoogleChromeUser DataDefaultPreferences |
| Windows Vista and above | C:UsersusernameAppDataLocalGoogleChromeUser DataDefaultPreferences |
| Mac OS X | /Users/username/Library/Application Support/Google/Chrome/Default/Preferences |
| Linux | /home/username/.config/google-chrome/Default/Preferences |
The preferences file is a plain text file. It has a clear format that can be discerned by looking at it and fields are named in such a way that you may be able to either easily determine or at least guess what they mean. Below is a section from the preferences file on a Windows 7 system. This particular section refers to the login status with Google, including the username that was used to authenticate. One thing about Chrome is that once you are logged in with Google, you can sync various settings and preferences across different instances of Chrome on different systems, if you are logging in with the same Google credentials. Further down in the file, you can see the different capabilities that sync with Google including apps, bookmarks, passwords, preferences, and themes. This not only means that you have a consistent experience across different instances of Chrome on different systems, but also that you are storing all of this information with Google, so it can be pushed down to the different systems you are using Chrome on.
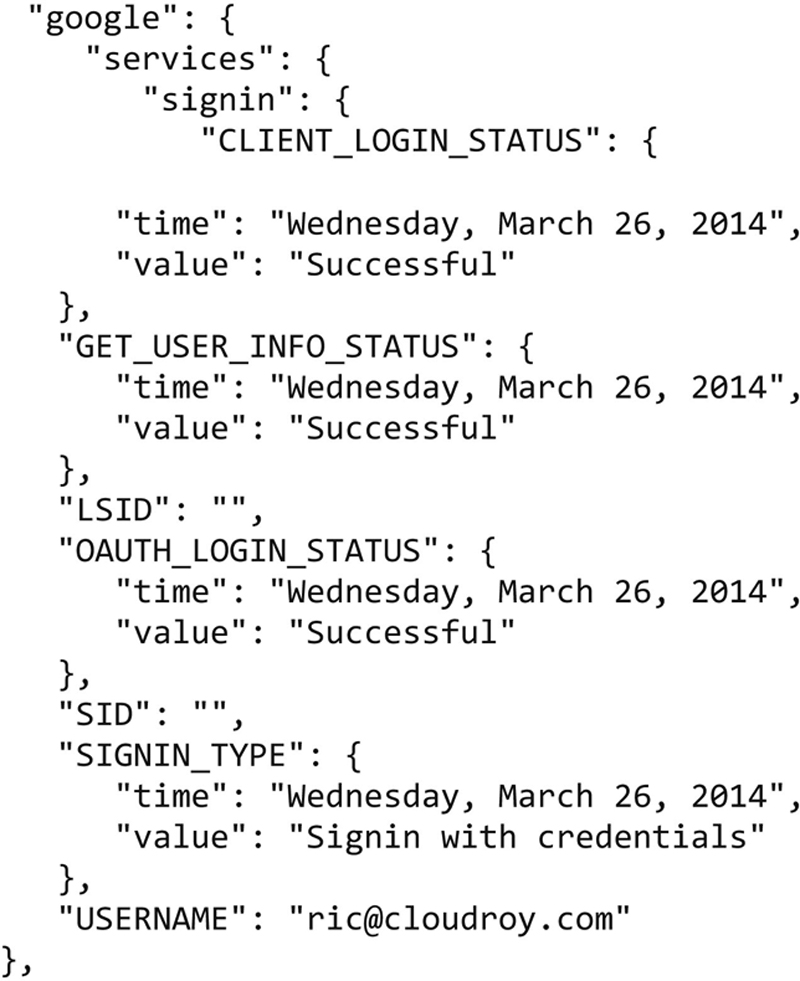
There are a number of files in the default directory and some of them are actually databases, though it may not be immediately apparent that they are databases. When you open up the history file, you get to see how the database is constructed, including the schema. The schema, which you can see for the history database in Figure 6.3, is a description of the data carried in the database. This includes the tables in the database as well as the attributes or columns in each of the tables. While there are several tools we could use for this, I am using one called SqliteBrowser. It will open up local Sqlite databases and provide us a visual look at the database and its contents.
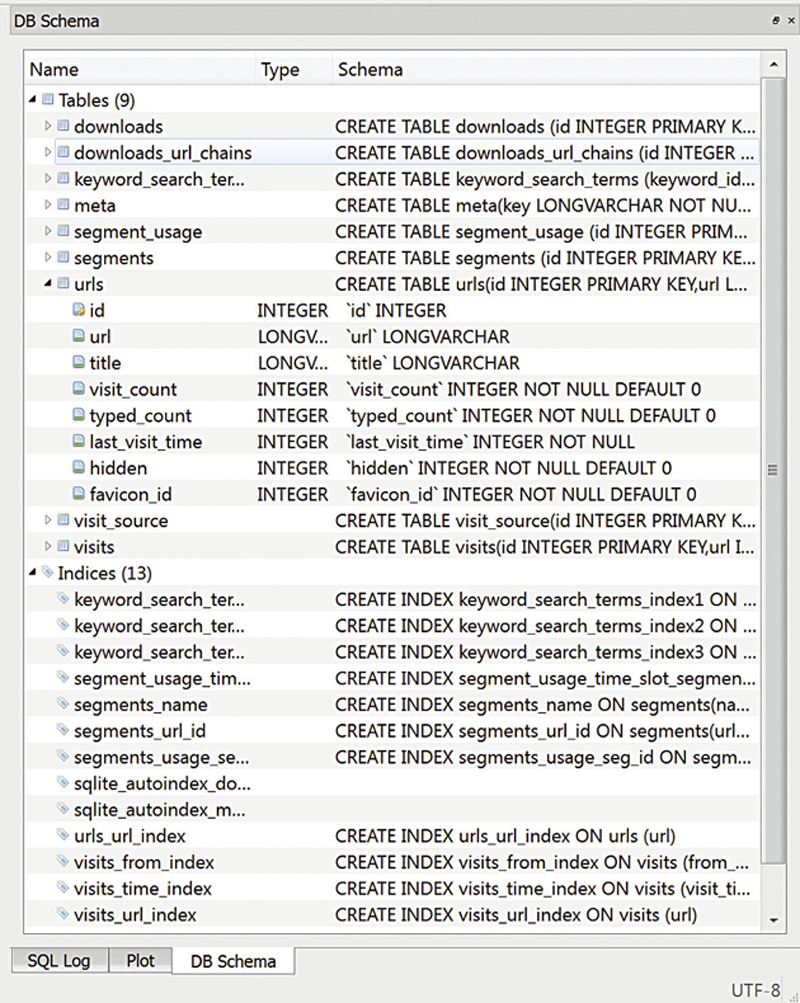
Figure 6.3
Using a visual browser like the one we are using, we can drill into the data. Using just the visual approach, though, will only get us so far. One of the ways that SQL databases are commonly used is having data from one table refer to data from another table. In Figure 6.4, we can see the visits table. The piece we are missing from this is the actual URL that has been visited. In place of the URL, we have a number. This number refers to a row in the URLs table that is also part of this particular database. We need a way to link those two values. This requires performing a SQL query, so we can join the two tables. There are a number of joins that are available, depending on how you want to pull the information together. What we are going to do is to use an inner join, which means that we are going to pull the information from both tables based on specific criteria because we need to know the actual URL from the URLs table, rather than just the URL ID that is available in the visits table.
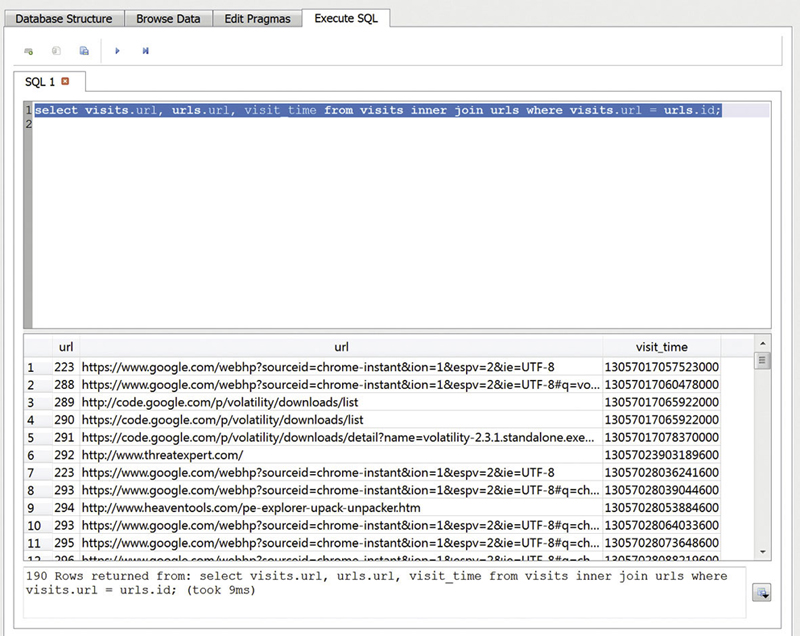
Figure 6.4
This requires slightly some more complicated SQL syntax than we have seen before. What we are going to execute is SELECT visits.url, urls.url, visit_time FROM visits INNER JOIN urls WHERE visits.url = urls.id.While this starts with a SELECT that was covered earlier, we quickly move to a different way of referring to the different attributes in each table. In the case where we say visits.url, we are talking about the URL attribute in the visits table. We have to be specific like this because we are talking about multiple tables and there may be the same attribute name in both the tables. That happens to be the case here, so, we also have to say urls.url to be clear that we are going to grab that attribute as well. We indicate that we are pulling any attribute that we have not specifically referred from the visits table, so visit_time comes from the visits table. We are using an inner join, so we specifically say that we are doing an inner join. Finally, we have to set the conditional. We need to make sure that we pull the right row out of the URLs table, so we have to specify that where, visits.url is equal to urls.id, we are going to display the information we have selected. You can see the results in Figure 6.4.
These sorts of SQL queries can be challenging, especially if you are not sure what fields across the two tables map together. Keep in mind that the key field is the unique identifier and that unique identifier is going to be the one used as an identifier in other tables. In the case that we looked before, the URL field in the visits table refers to the ID field in the URLs table. That ID field is the unique identifier that we can use to grab the text from the URLs table, since that is where we get the information that will actually make some sense to us. These joins are necessary to save space. Why use space to put the same information in multiple tables, when you can refer to information stored in one table.
One area we should talk about here because we saw it in the results of this query. We can see the time the URL was visited. The first URL visited in our results was visited at 13057017057523000. You may not recognize it but that is a time. There are a number of different time formats. A common one is the UNIX Epoch time, measured as the amount of time in seconds or milliseconds from January 1, 1970, which is considered to be beginning of the UNIX Epoch. There are a number of ways to perform that conversion including the Web site www.epochconverter.com. This particular timestamp, though, is not based on the UNIX epoch. Instead, it goes back much further. The timestamp is a 64-bit integer value that does not start with epoch time. It indicates the number of seconds since midnight on 1/1/1601 UTC.
The thing about SQL is that there are often a number of ways to execute queries to get the same sort of information. Where we did a specific join above, we can do a query that is not a specific join but still joins the tables. We can also have SQL to perform the date conversion for us. The following query will extract the information we need and simultaneously give us a human readable time.

The value 11644473600 is the number of seconds since January 1, 1601. We subtract that value off and we end up with the amount of time between UNIX epoch time and the real time, which can easily be converted using the datetime function. When we run this query, we end up with a list very similar to what we had before, but we have human readable dates. This query also throws in the title from the URL, which we had not pulled before. You can see the results of this query in Figure 6.5.
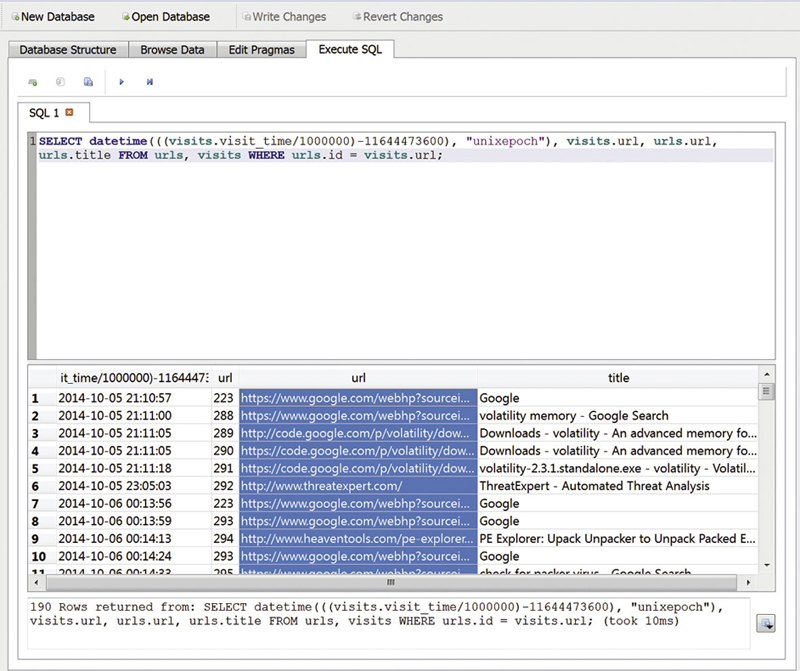
Figure 6.5
There are, of course, a number of databases that may be worth investigating. The following are database files that are stored within the same default directory that the history database is stored in (Table 6.2).
Table 6.2
Chrome Databases
| File | Description |
| Cookies | Stores the cookie details from Web sessions |
| Favicons | Stores the icon associated with a Web site that shows up in the address bar after the connection with the site has been made. |
| History | Stores the browsing history |
| Logins | Stores login information from Web sites that have been visited |
| Network action predictor | Used to speed up rendering of pages |
| Origin bound certs | Stores information related to transport layer security (TLS) certificates |
| QuotaManager | Stores information related to the quota manager, that handles quota for various application programming interfaces (API) |
| Shortcuts | Provides hints about how to fill in the omni box when you start typing. |
| Top sites | Provides URLs for sites that have been visited a lot in order to populate the top sites page. |
| Web data | Stores information about data that has been put into Web forms for retrieval later. |
| Web RTC Identity Store | Stores information about communications services that make use of the Web real time communication API. |
Internet Explorer
Internet Explorer is Microsoft’s Web browser that is now only available with their Windows operating system, though it used to run on Mac OS, Solaris and other operating systems. Internet Explorer has evolved over time, especially as use of the Internet has changed and increased. We are now storing a lot more information about use and we need good ways to retrieve that information. Just as with Chrome, we have to keep track of cookies, history, and pages that have been visited. This requires several files and those file types have changed over time and certainly the locations of the files has changed with different versions of Windows.
Web Cache
The cache is the storage of files that have been retrieved from the Web. We cache the files primarily to speed up our browsing. Each page can set a cache control value indicating how long a life the page should have. This helps us determine which pages may be dynamic and which may be more static. In cases, where the cache control is set fairly high, we do not have to bother wasting time with requests because we expect it will not be changing. Instead, we pull the content off our disk, which is considerably faster, we hope. Every browser maintains a cache of pages, images, and other files that have been downloaded from servers around the Internet. In the case of Internet Explorer, the Web cache changed in IE 10. Before that, Microsoft used the cache file format. With IE 10, Microsoft began using the extensible storage engine database file (EDB) format. This moved the cache into a database and away from more of a flat file model.
You can easily find the cache files themselves and search through them on the file system, or you can find the EDB file on the hard drive and analyze it to locate the specific files that you may find relevant, based on their URL and modification times. The database stores all of that information, as well as the location of the cache file. The cache file will have a different name than the file name that was stored on the server. If the file on the server was called aliishot.jpg, for example, that does not mean that the file in the Web cache will also be stored with that name, so we need a way of looking up the data based on the URL and then finding the file name on the file system. Fortunately, there are tools that are capable of doing that and you do not even need to figure out the structure and format of the EDB file on the disk. You can use a tool like Nirsoft’s IECacheView to look at the cache on your system. You can see the results of running IECacheView in Figure 6.6.
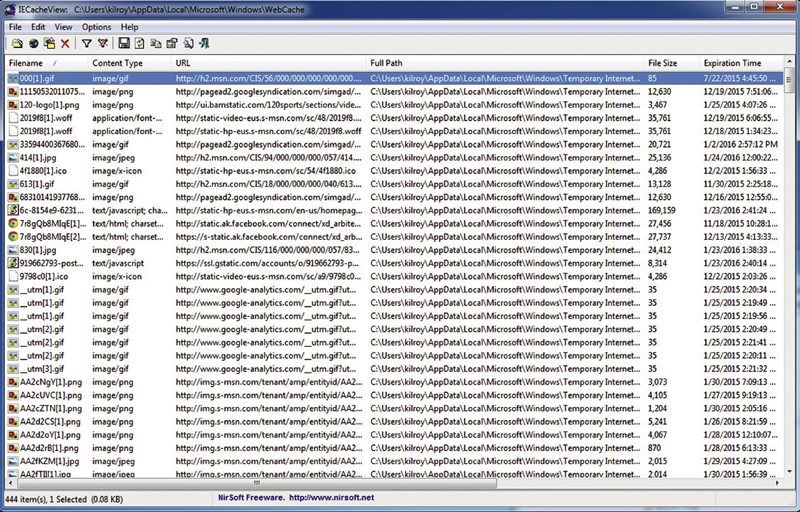
Figure 6.6
The cache viewer shows the file name on our file system, as well as the modification time and date, which means that the time, the file was stored or was last touched. This may include updating the timeout value on the cache. This is also a value that is stored in the database, by the way. You can see when the cached file is expected to expire and needs to be refreshed. Of course, your system does not wait until the very last moment of that timeout value, before refreshing the file. Instead, it performs checks partway through the valid time.
The Web cache is stored in
C:Users\%USER%AppDataLocalMicrosoftWindowsWebCache for IE 10. Replace %USER% with the actual name of the user in the file path. On older systems, you would use C:Documents and Settings\%username%Local SettingsTemporary Internet FilesContent.ie5, again replacing %username% with the name of the user you are trying to analyze. If you are using a version of IE prior to 10 but you are using Windows Vista or Windows 7, you would go to C:Users\%username%AppDataLocal SettingsMicrosoftTemporary Internet Files to get to the Web cache. On a Windows 8 system, it would be located in C:Users\%username%AppDataLocalMicrosoftWindowsNetCache.
Cookies
Every time you visit a Web page, there are small pieces of data that are exchanged between your system and the Web server. This is a way of tracking you and making sure you get the experience, you want related to that Web site. As an example, if you go to weather.com and look up the weather for your location, you may well want to see that same weather each time you visit the page, so you do not have to keep looking it up every time. As a result, the Web server will ask your client to store a small piece of information, called a cookie, on your file system, so when the Web server asks again, your system can return it. These cookies have the potential to store a lot of information. At a minimum, it will store a reference to a website that a user had visited.
Again, we rely on Nirsoft for a tool that will open the cache file. They have a free tool called IECookieViewer that you can see in Figure 6.7. Each line in the upper pane shows you the various cookies that are available, including the site they have been generated from. Each cookie, though, can have several values with it so when you select one of the cookies, you can see the key/value pairs in the lower pane. Much of this information may not be very useful to us because it probably looks random. In the case of authentication cookies, where a user needs to indicate that they have actually authenticated to a server, they should be random so they cannot easily be predicted or duplicated.
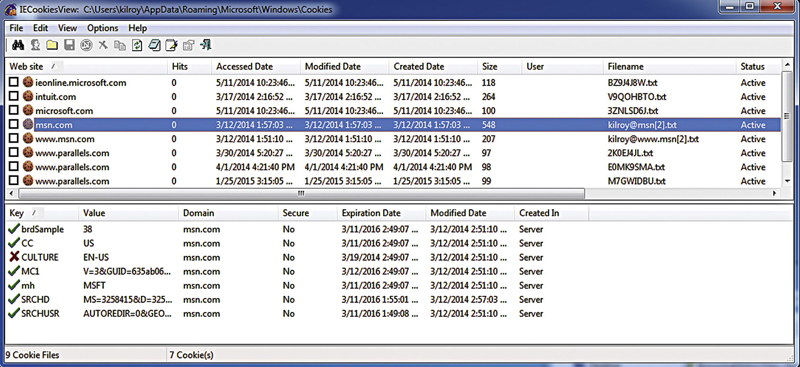
Figure 6.7
Having a utility like this to pull the cookies off the disk is very helpful, especially if, as in the case of this one, it can be run from an external USB stick. There are no external libraries that are required and no existing registry keys so there is no installer. It is a standalone executable file that can be stored on a USB stick and carried to any device you want to analyze. The same is true for the previous Nirsoft utility we analyzed.
With Windows 7, the cookie location is in
C:Users\%username%AppDataRoamingMicrosoftWindowsCookies. This is changed in Windows 8. With Windows 8 and 8.1, the location is now C:Users\%username%AppData MicrosoftWindowsINetCookies. With Windows XP, they were stored with the temporary Internet files in C:Documents and Settings\%username%Local SettingsTemporary Internet Files.
History
Of course, knowing where a user has been visiting is important. Assuming the history has not been cleared, you can use a number of tools to get the history of the user from a system. Again, Nirsoft comes to the rescue for us. We can use BrowsingHistoryView to get the data from Internet Explorer, as well as other common Internet browsers. You can see the startup dialog in Figure 6.8, asking which browsers I want to check for history. Once you have selected your browsers, the tool will extract all the history and display it. The history will show locations as well as access times that can be used to generate a timeline of activities.
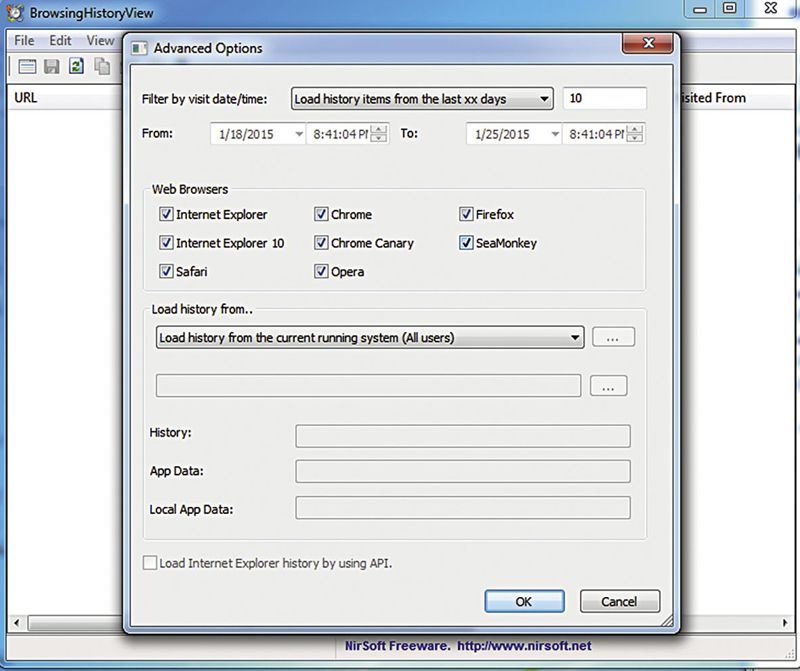
Figure 6.8
The location of the history has changed with different versions of Internet Explorer as well as with different versions of Windows. Under Windows XP, the history was stored in C:Documents and Settings\%username%Local SettingsHistory. With Windows Vista, the location of the history changed to
C:Users\%username%AppDataLocalMicrosoftWindowsHistory.
You will notice that the history location falls under the Windows directory and not the Internet Explorer directory. This is because Windows keeps track of all history including files and Web sites that have been visited.
Safari
Apple replaced the default browser in Mac OS X in 2003 with Safari, a browser developed internally at Apple. Prior to Safari, Apple was shipping Mac OS X with Netscape and, for a period of time, Internet Explorer. Safari does not only run on Mac OS X, however. It will also run on Windows systems. As with most applications under Mac OS X, the data for Safari is stored under an application-specific directory within the users library folder. Safari data is stored in /Users/username/Library/Safari. Just like other browsers, we have specific information that we want to track – history and cache for a start. Additionally, Safari keeps track of the last browsing session, which would be the list of tabs that were open and the sites they were open to. Safari will also have a list of files that had been downloaded. Table 6.3 shows the location of the different files that Safari maintains. The table lists the file locations by operating system.
Table 6.3
Safari Data Locations by Operating System
| Artifact | Operating system | Location |
| Cache | Mac OS | /Users/$USER/Library/Caches/com.apple.Safari |
| Cache | Windows XP | C:Documents and Settings\%USERNAME%Local SettingsApplication DataApple ComputerSafari
|
| Cache | Windows 7 | C:Users\%USERNAME%AppDataLocalApple ComputerSafari
|
| History | Mac OS X | /Users/$USER/Library/Safari/History.plist |
| History | Windows XP | C:Documents and Settings\%USERNAME%Application DataApple ComputerSafariHistory.plist
|
| History | Windows 7 | C:Users\%USERNAME% AppDataRoamingApple ComputerSafariHistory.plist
|
| Downloads | Mac OS X | /Users/$USER/Library/Safari/Downloads.plist |
| Downloads | Windows XP | C:Documents and Settings\%USERNAME%Application DataApple ComputerSafariDownloads.plist
|
| Downloads | Windows 7 | C:Users\%USERNAME% AppDataRoamingApple ComputerSafariDownloads.plist |
The plist files are binary property lists. There are a number of tools that may be used to open those files, including Xcode, provided by Apple for Mac OS X as a development platform. Other tools like Plist Pad will run on Windows and work with XML plist files but do not support binary plists. Since this is the format for these files associated with Safari, this particular tool is not as helpful, so it is necessary to know whether the tool you are trying will support binary plists as well as XML plists.
The cache, however, is stored as a Sqlite database. You can read this using any Sqlite browser. You can see one of the tables in Figure 6.9. The database keeps track of all of the cache entries. The entries themselves are stored in the fsCachedData directory underneath the directory, where the Cache.db file is stored, depending on the operating system where the data is located.
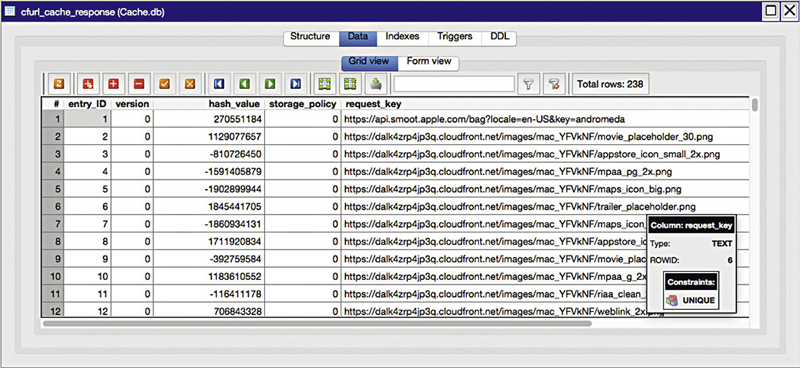
Figure 6.9
In the case of the history, the date and time of the access of the file is stored as the number of seconds since January 1, 2001 at 00:00:00 UTC. Outside of the typical browsing history, cache and downloads, there are also plist files for the last session in a file called LastSession.plist and the top sites, which is a small number of pages that are commonly accessed. This list of pages can be displayed on a new tab in Safari. The list of top sites is also stored in a binary plist file called TopSites.plist.
Messaging services
There are a large number of messaging services available and there are also a number of multi-protocol clients that will aggregate services connections into a single client. One significant messaging service is Google Hangouts that previously had some other names. Hangouts does not require a client, though. It runs completely through a Web browser, which means all of the content regarding friends lists and conversational content is stored with Google’s servers.
Skype is also a messaging service that has additional features like video and audio communication. Skype has a long history but at the moment, it is owned by Microsoft and offers messaging as well as voice and video to clients. Because it can send messages and also has a list of contacts, it is worthwhile to take a look at the data that is being stored. On a Windows system, we would be looking at C:Users<username>AppDataRoamingSkype<skypeuser> where you replace <username> and <skypeuser> with the actual user values you are looking for. Under Mac OS X, the information would be stored under /Users/<username>/Library/Application Support/Skype/<skypeuser>. The primary database is named main.db.
One of the first things, we will be looking for, is the list of contacts. In the case of Skype, data is stored in a couple of different formats. The first one, we will be looking at, is the XML configuration file named config.xml. In addition to configuration data, this file also stores information about missed calls as well as servers that the client will talk to. Here is a snippet from the config.xml file, showing the registrar server for missed calls.
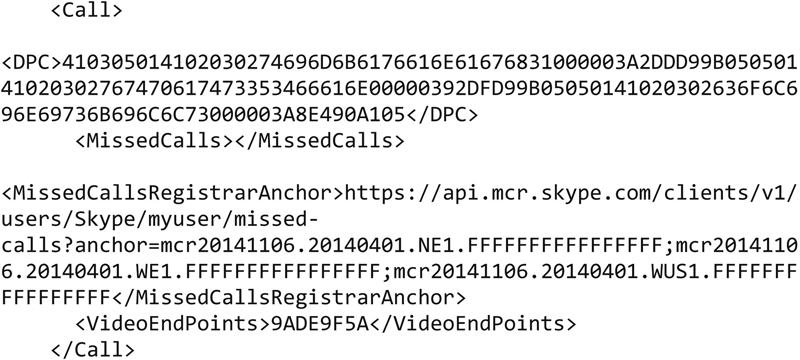
In addition to data about missed calls, there is also a list of contact information within the config.xml file. Under the <CentralStorage> node is another node named <u>, where there is a list of contacts that the user has stored. There are also timestamps stored in the config.xml file indicating connection times. The timestamps in config.xml are stored in Unix timestamp format. There are a number of places to convert the timestamp into a human readable form. For example, the timestamp 1419731534 converts to Sun, 28 Dec 2014 01:52:14 GMT using the Web site www.onlineconverters.com. This particular value comes from the <ConnectivityTimestamp> node, indicating the last time this particular system connected to the Skype network.
Aside from the xml file, Skype uses Sqlite to store additional data. There are a handful of database files. The most interesting database is called main.db. Inside main.db, there are number of tables including tables for contacts and calls. You can see the complete list of the tables that are in the database in Figure 6.10.
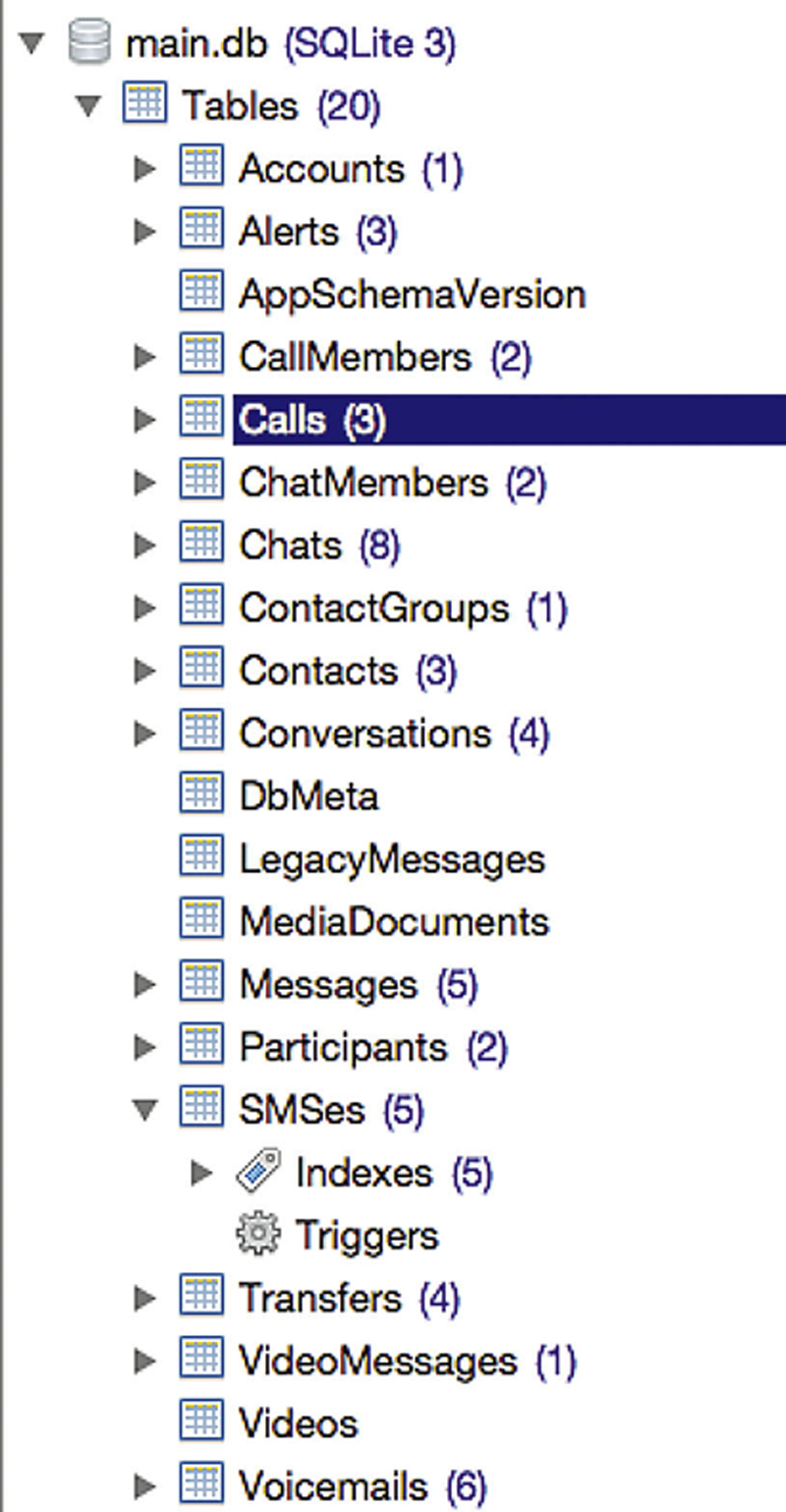
Figure 6.10
While there are other database files in the user’s Skype directory, the one where you will get nearly all of the interesting information is this main.db database file. From here, we can also get the list of contacts that were cached in the config.xml file. We can also get a list of accounts associated with this particular installation. You can also get a list of calls and conversations. You can see a list of calls in Figure 6.11. This includes starting times, also stored in Unix timestamp format. The calls table also stores information about whether the call was a conference call and the other participants who were involved in the call. You can also get an indication of whether there were call quality problems.
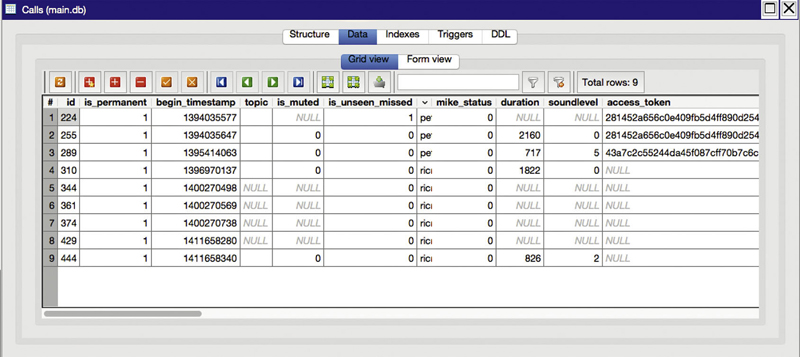
Figure 6.11
While Skype is not the only messaging platform, it is a good one to cover the possible artifacts that may be interesting to look at and it also covers two significant data formats that may be commonly in use. Other messaging platforms may use proprietary storage techniques or they may simply use plain text files. However, Sqlite and XML are widely used because it is very easy to embed a storage format inside your application from existing libraries without having to put a lot of work in yourself.
There are a couple of aspects to forensic analysis of e-mail. The first is simply finding the storage files on the file system. More importantly, perhaps, is being able to investigate the e-mail messages. The reason, this is more important because e-mail is easy to fake. Being able to read through the headers of an e-mail message is critical to be able to understand what is happening with an e-mail message. Where did it come from? What about the e-mail address and the source system? There are some things that can be faked and others that are impossible to fake because of the way the network works. I can pretend to be anything that I want but when it comes to tracking the Internet Protocol (IP) address the messages come from, that is up to the server and if one system makes a connection to another, the receiving system has to know the real IP address of the connecting system or else messages would not get back to the connecting system and the communication will simply fail.
There are different formats for mail files, depending on the client. Clients that have an older heritage may use what is called an mbox format. The mbox format was originated on UNIX systems and leaves messages intact. The mbox format is strictly text-based, where messages get appended to an existing file, including all of the headers, since the message is maintained in Internet message format. The very first header indicates that the start of a new message is a From: header. There are a number of viewers available for the mbox format, since it is been around for so long. In fact, a large number of e-mail clients are capable of reading in from the mbox format. Since it is a text format, it is also easy to read in any plain text viewer.
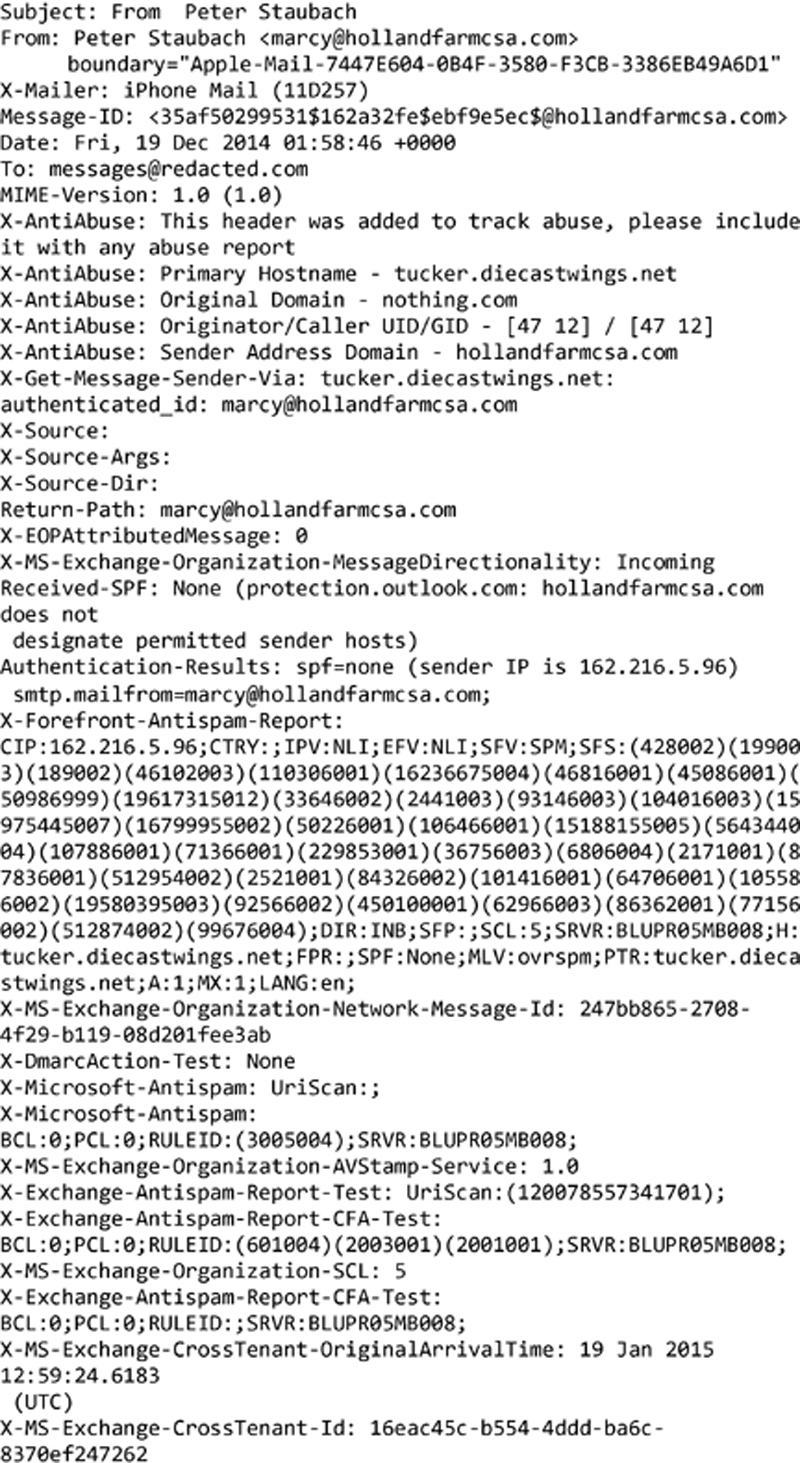
Once you have a message, you need to know how to read it, so let us take a look at a spam message that I have received recently and pull it apart. The following are headers from a message that showed up in my Junk folder that appears to come from one of my cousins. At least the name is correct, though the e-mail address is certainly not and many of the other headers simply make no sense and do not connect up well.
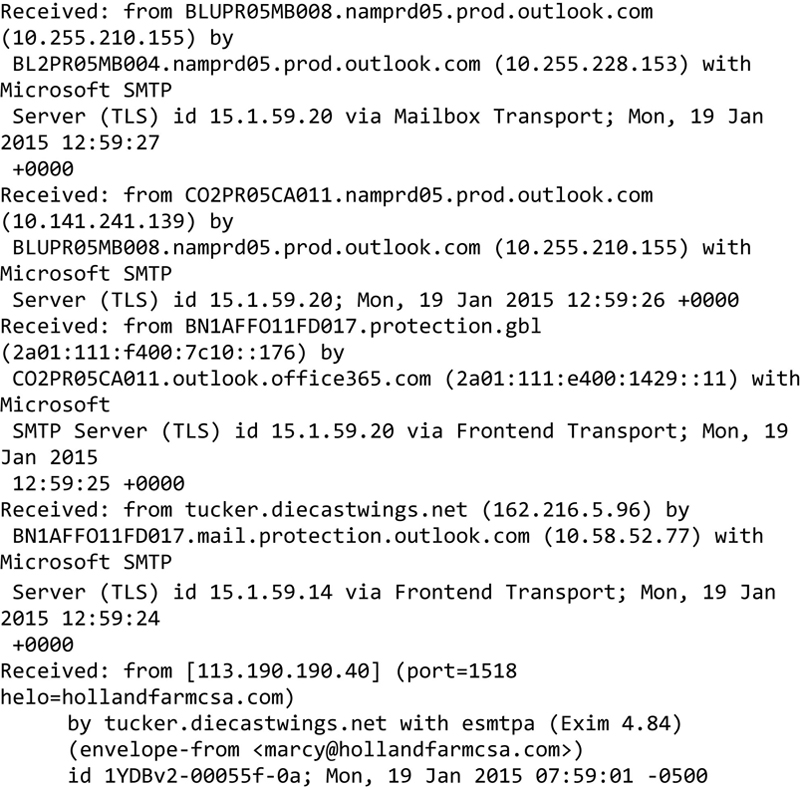
The first thing to look at is the message path. This is indicated by the list of received headers. This shows you all of the simple message transfer protocol (SMTP) servers, the e-mail has come through. SMTP is the protocol used to send messages from the sender to the mail server where the recipient’s mailbox is located. The mail server we are most interested in is the one at the very bottom of the stack. This is the very first server that was contacted by the sender, so itis the one closest to the people who sent the message. It will also indicate the address that contacted the SMTP server. According to this header, the message was received from the IP address 113.190.190.40. We can figure out where this IP address is in a number of different ways. The first is to use a whois lookup. If you have a Mac OS X system or a Linux system, you can use the whois utility that comes with your OS. You can also go to a Web site like Geek Tools (www.geektools.com) and use the whois link there. According to whois, the IP address belongs in Vietnam. This is a flag since I know my cousin does not live in, nor he has been to Vietnam.
If we want to know specifically where the IP address is located, we can use another Web site that will give us a geographic location. There are a number of Web sites that will do this and the locations are not always exact because they rely on metadata that would be provided by service providers. However, they are reasonably accurate so we can use the IP address we have and plug it in. According to geoiptool.com, the IP address in question is the city of Dung in the region of Thanh Hoa in Vietnam. Based on the whois information, we know that the IP address in question belongs to the Vietnam Post and Telecom Corporation. If this was a company that might respond to a subpoena or other legal document, we could contact the company and get further information about the IP address at the time of the e-mail message.
We do have some additional places we can look. First, we can check the SMTP server that was first to receive the message. It claims to be tucker.diecastwings.net and the IP address there is 162.216.5.96. I can do a lookup of the IP address and it does resolve to tucker.diecastwings.net so that matches and appears legitimate. Beyond that, we can check domain names that show up in the headers. The only one is hollandfarmcsa.com. This is not always the case in message headers like this but it happens to be here. In a legitimate set of message headers, you will get all legitimate information but sometimes, you need to dig a little. We can look up the domain name hollandfarmcsa.com by using whois. According to the information whois provides, it belongs to someone named Marcelyn in Deerfield, NH. This would make sense, considering the e-mail address this appears to be from is [email protected].
What have we learned from this? We can determine where the message originated. If we wanted, we could look up all of the intermediate SMTP servers that have handled this message. In this case, it is a lot of different servers in the Microsoft infrastructure, as it gets passed through to the server where e-mail sent to me is stored. This is, in part, because of the spam filtering Microsoft does on messages hosted with them. If you pass through several anti-virus or spam filtering gateways, you will generally see those IP addresses show up in the received list.
So far, we have talked about text-based storage and investigation. Not all mail clients store their messages in text-based formats. In the case of Outlook, for example, local storage is in what Microsoft calls personal folders. These are commonly stored in .pst files in the directory of each user. There are also .ost files that are used for offline storage in the case of connections to an exchange server.
There are a number of tools that will read the .pst files and provide you with the contents. One of them is a utility that extracts the .pst file and puts them into an mbox format. You can see the process of using readpst in Figure 6.12. This is a Linux utility and the output is a set of mbox files stored in the directory that you specify. Once the messages are in mbox form, they are in plain text and can be read with any plain text viewer. If you are on Linux and are inclined to write programs, there is a library that will read PST files. This is the library that was used to create readpst. The output from the tool is here, though the e-mail messages we are looking at are nearly two decades old. You can see the boundaries indicating that libPST was used to create the file.
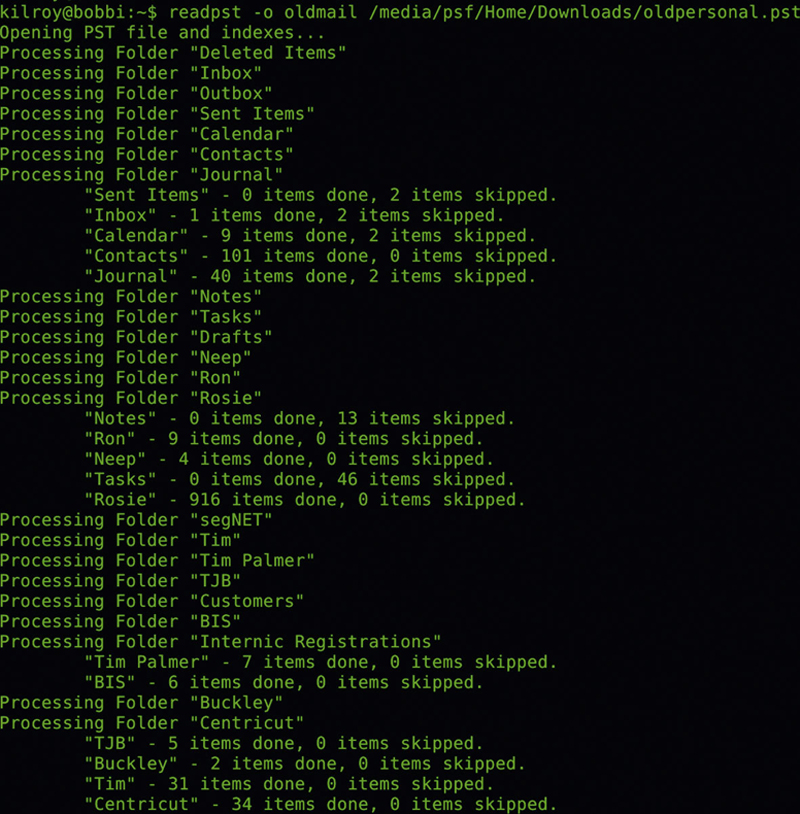
Figure 6.12
Fortunately, you are not limited to command line tools under Linux. There are Windows programs as well. One of the utilities you can use to read PST files is Outlook PST Viewer, which you can see in Figure 6.13. One of the advantages is that it is very easy to use. You tell it where your .PST file is and it opens it up for you, displaying your messages just as you would if you were using Outlook itself. You can see the folder list in the left hand pane and the message list on top on the right and then the text of the message below that, if you have selected a message to view.
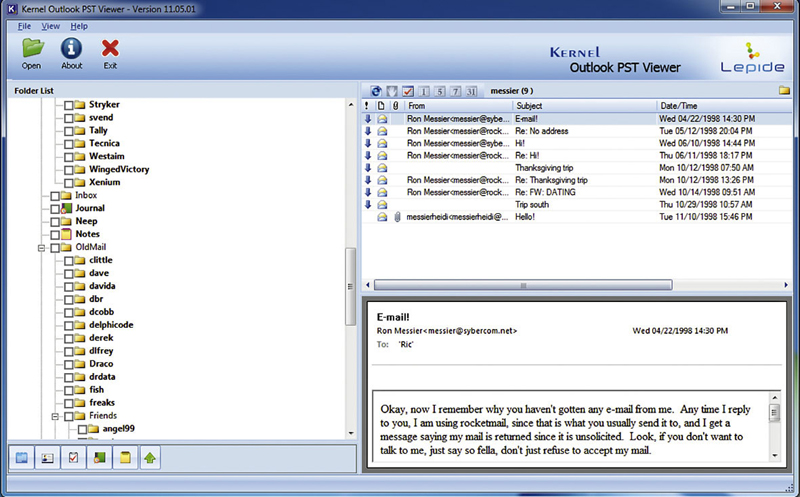
Figure 6.13
One of the downsides of it, though, is that you cannot extract individual e-mail messages into a separate file for closer analysis and you cannot see the complete set of headers, as you would be able to from Outlook itself. However, in addition to e-mail messages, Outlook stores a lot of information in its PST files. Outlook is, after all, more than just an e-mail client. It is a personal information manager, so it will store contacts and calendar in addition to the messages and notes. Older versions of Outlook also used something called a journal, allowing users to store notes that could be flagged as calls, appointments, or other specific types. Outlook PST Viewer will show all of these additional types of information in addition to just being able to show the messages.
Conclusions
The Internet has become a very important communications medium over the past decade and a half or more. What this means is that there is a lot of Internet-related data on systems, including e-mail messages, Internet browsing history, and of course, various messaging platforms. With so much data in play, vendors want to be able to access it quickly and this means there is probably a need for an embedded database. While Microsoft has their own versions of embedded databases, including for storing messages on client devices, other software development companies have begun to really rely on Sqlite as the embedded database of choice.
A major advantage to using an established software platform like Sqlite is you do not have to spend a lot of time coming up with your own storage mechanisms. You just have to worry about including the Sqlite libraries and then develop to the Sqlite API. It saves a lot of time and provides a stable platform to store data and retrieve it quickly. The good thing about this from the forensics side is that you can learn a little SQL and how to use a Sqlite browser and you have a big jump on acquiring information across a wide variety of platforms.
Exercises
1. Extract the history from a Google Chrome installation. Get the very first entry in the database.
2. Find a message from your Junk mail folder and check to see whether the hostnames and IP addresses match. Is there anything out of order with it?
3. Get the cookies from Internet Explorer. How many cookies are stored on the system?
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.