
Chapter 6. Case Studies in Operationalizing AI
The following case studies show a progression of operationalizing AI, ranging from organizations that are early in the journey to those following mature practices. We thank our colleagues at Red Bull, Capital One, and Wunderman Thompson for sharing their experiences and perspectives on operationalizing AI.
The following case study from Red Bull demonstrates a remarkable data science practice, considering that the company is an established leader in the food and beverage (F&B) vertical, not a tech startup. Its team has exceptionally sophisticated AI applications in production. Having a leader who understands the business in detail while also understanding how to translate between AI technology capabilities and business opportunities has played a vital role in elevating to the corporate executive level the case for establishing a strong AI practice. Given that F&B firms are not generally known as AI innovators, plus the usual need to work within some legacy architectures, the Red Bull team has developed its data and AI strategy remarkably over the past decade. In particular, this case study illustrates the team’s process for determining relative investments in different use cases, which is an early form of implementing an AI Factory.
Red Bull: Sandcastle—Log Cabin—Castle
Red Bull develops and deploys its solutions within the framework of a digital transformation program of a brick-and-mortar company. This means that there is substantial legacy in terms of ways of working, best practices, IT systems, and roles that might not exist in a near-greenfield technology startup environment, where one could build and enable the latest tools and related roles more easily.
Our data science engagements very often include complex machine learning algorithms, but never exclusively. In fact, many use cases leverage simpler algorithms and statistics to extract the relevant information from data. We are therefore prone to broaden our scope when we think about “exploration to deployment” transitions, depending on the nuances of each use case and on how the value can be delivered to the organization most efficiently.
A Nonbinary Approach
Many deployment processes tend to focus on a binary approach, implicitly classifying the maturity of an artifact as in the development or the operations phase. In our experience, this leads to an inevitable culture clash between the data science function and the business application/data engineering function, as both strive to stake their claims around the hypothetical “transition point.”
Reality tends to be more blurred. In our organization, the development and exploration of new use cases typically starts in the data science practice positioned inside the business, as a Center of Excellence (CoE). Once the problem is “solved,” following our internal version of the CRISP-DM process (see Figure 6-1), data science and IT jointly decide how to best deliver the value of the data product to the organization—how to “deploy” the output. The decision could be to simply leave all components of the solution in a “sandcastle” environment based on criteria such as frequency of the deliverable, authorization considerations, and reliability, or to mature at least several components of the solution to a “log cabin” environment, where IT owns or supports the execution. This can make sense when immediately jumping to building a “business application–type solution” may be overkill and a waste of resources.
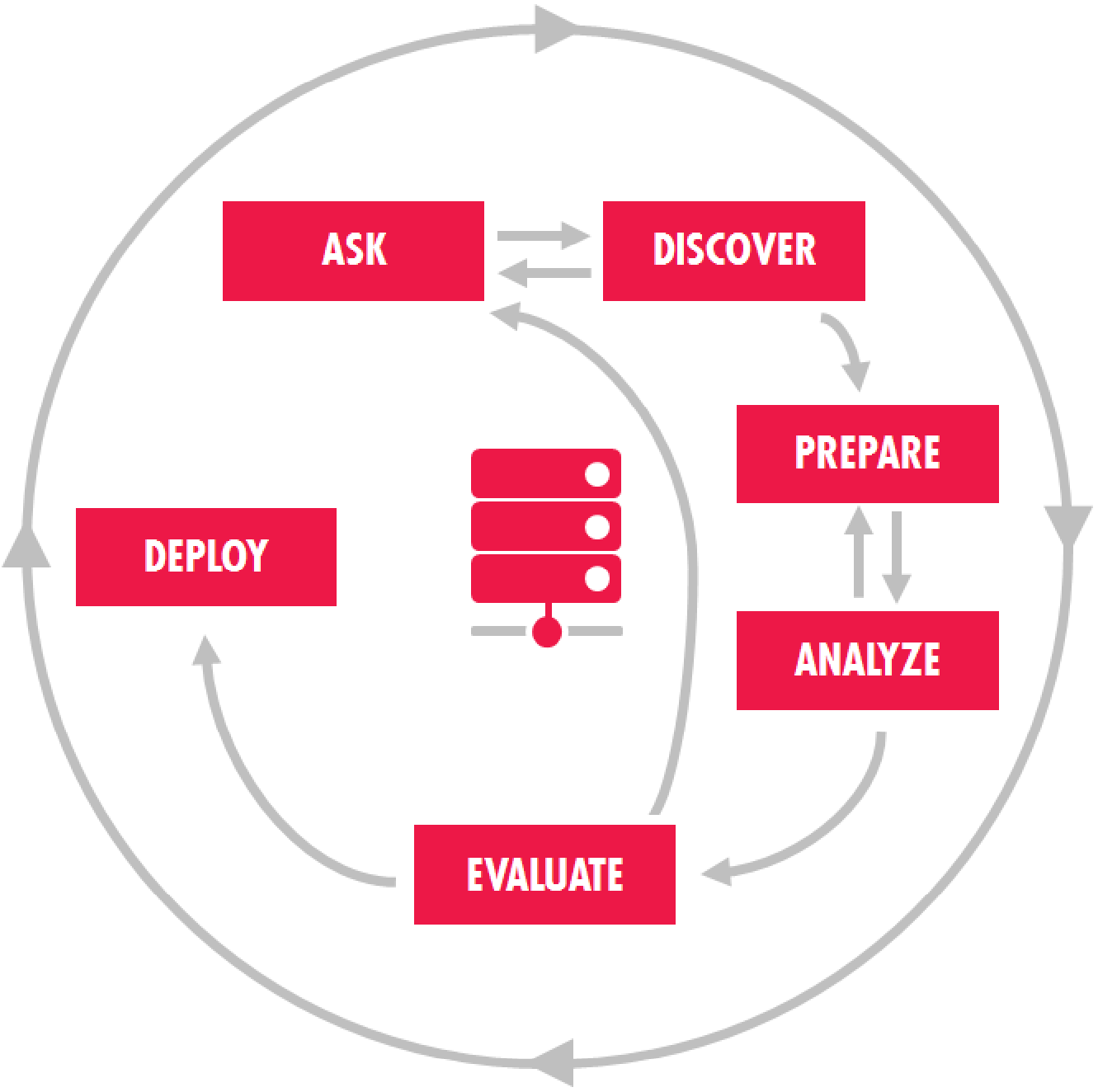
Figure 6-1. Simplified cross-industry standard process for data mining (CRISP-DM). Image courtesy of Red Bull.
Some projects, however, may benefit significantly from automating the data sourcing or data preparation components—for instance, leveraging accepted business intelligence (BI) environments and tools, usually supported by IT data engineers.
In other words, the transition in terms of ownership along the life cycle of the data asset is fluid from data science to IT’s business applications team, as depicted in Figure 6-2.

Figure 6-2. The responsibility shifts from the data science lab to the business applications team based on the maturity of the solution components. Image courtesy of Red Bull.
Transition in Practice
As mentioned before, once the proof of concept has been positively evaluated, we then transition all, none, or parts of the components to a more stable and scalable business applications environment. Crucially, we evaluate the components separately, to find the best balance among business impact, speed, and cost. We have classified these components broadly, as data sourcing, data storage, data preparation, data science, and solution delivery. Many months into a project’s life cycle, the solution that is delivered to the business (jointly by IT business applications and data science) could look like Figure 6-3 “under the hood.”
Given that the demand for this particular asset is still increasing, we are currently evaluating the implementation of a quasi-automated “castle” solution, fully integrated into our business application landscape. Several data science solutions have transitioned to this phase already. All in all, this pragmatic and jointly developed approach is working well and crucially allows data science and IT to work together constructively and on an equal footing. Importantly, this collaboration framework has also built the crucial basis for jointly discussing further extensions on tech requirements and roles needed for the data science initiative to flourish in our non-digital-native organization.

Figure 6-3. Project example in hybrid “PoC/log cabin” configuration. Image courtesy of Red Bull.
Capital One: Model as a Service for Real-Time Decisioning
The following is excerpted from the talk “Model as a Service for Real-Time Decisioning,” presented by Niraj Tank and Sumit Daryani (Capital One) during the MLOps Day track at the O’Reilly Open Source Software Conference (OSCON) in 2019. The authors of this report have outlined highlights from that talk to help illustrate key points about operationalizing AI. You can also watch the full video of their talk and access the slides on O’Reilly’s learning platform.
The talk from Capital One opened the MLOps Day track at OSCON 2019 with an interesting case study from a well-established enterprise practice, showing its exemplary MLOps work as an important subset of operationalizing AI. Tank and Daryani opened the day with a detailed description of their “model as a service” platform. It provides patterns for comprehensive workflows for both model building (data science teams) and model serving (production engineers). This creates a separation of concerns where different kinds of teams can work independently, each with their own specific process and tooling, but still work closely together on the ML models for sophisticated features of model deployment and monitoring. It was also interesting to hear them talk about risk management and oversight by model governing bodies (compliance) involved at several steps within this architecture:
The model is just one part of your whole business application. That’s traditionally how everyone approaches it—we’ll package it as one application. So the model becomes a part of that large-scale application. What that means is that the data scientist that has gone to school/university to study about modeling and data science, they’re not engineers. They don’t understand the models are a product. […] They have to rely on engineering teams. […] That makes it hard to go to production.1
The approach by Capital One clearly illustrates an organizational awareness of the impact of machine learning on the business. Instead of considering each deployed AI/ML model as an isolated application or service, its approach took the combined perspectives from three interacting groups, with three intersecting workflows:
-
Data science teams
-
Operations teams
-
Governance committees
One fundamental problem is that, while each of these teams has people with considerable depth in their own areas of expertise, they cannot afford to acquire depth in the other teams’ areas of expertise. In that case, how can business processes and platforms be designed to reduce cognitive load and increase mutual trust, while allowing these teams to interoperate effectively?
At the organizational level, the primary goal was to make ML deployment affordable within the enterprise environment. In other words, research projects may devote years to improving one aspect of an ML workflow, while in industry the time-to-market (TTM) metric is a key indicator for whether projects live or die. How can that TTM metric be accelerated enough to make ML usage affordable in production?
At the department level, each group must be able to work relatively independently. Also, each group needs to have its own control gates for what it contributes.
The resulting architecture leverages Seldon Core for packaging models to be ready for testing and deployment, then Jenkins for a test pipeline, and then Kubernetes for deployment. One important aspect of the test pipeline is its ability to capture results and send those back to the data science team by using notifications. This makes testing more efficient for each team involved and also helps build trust in the development pipeline.
What the team at Capital One has accomplished is to define a separation of concerns for effective interactions between the three kinds of teams involved. Importantly, this does not require an overwhelming amount of synchronization, which would increase costs and risks. A separation of concerns is a typical approach in computer science for leveraging abstraction layers to manage complex problems, especially in system architectures. In this case, the architecture leverages practices to make ML deployment affordable within an enterprise environment. This is a good example of combining both the theory and practice of computer science to make a complex problem considerably more manageable.
Wunderman Thompson: AI Factory Brings Solutions to Clients at Scale
Wunderman Thompson exists to inspire growth for ambitious brands. Part creative agency, part consultancy, and part technology company, it provides end-to-end capabilities at a global scale to deliver inspiration across the entire brand and customer experience.
Wunderman Thompson is 20,000 people strong in 90 markets around the world, where its people bring together creative storytelling, diverse perspectives, inclusive thinking, and highly specialized vertical capabilities to drive growth for clients. They offer deep expertise across the entire customer journey, including communications, commerce, consultancy, customer relationship management (CRM), customer experience, data, production, and technology.
Wunderman Thompson’s Identity Network (IDN) drives these capabilities. The IDN brings together three factors:
- Granular human insights data
- Machine learning
- Scaled customer activation
These aspects, when combined, modeled, and operated together, drive meaningful business outcomes for clients. The IDN’s human insights are fed by more than three thousand transactional datasets (representing $1.1 trillion in annual transactional data), more than 150 compiled household data sources, and more than one thousand contextual datasets that are used to create a complete Identity Graph. Machine learning is then applied and used to derive fresh insights from this wealth of identity data and create innovative solutions for clients. These solutions are targeted at acquiring and retaining customers and maximizing their value, and are delivered through channels like direct mail, email, social media, addressable TV, and other digital touchpoints.
Challenge and Opportunity
Wunderman Thompson Data had an existing modeling environment that presented various challenges in terms of how quickly it could roll out new AI solutions and scale them. The legacy environment worked only on aggregated data, trained on relatively small samples, used a maximum of two hundred features, required simple inputs, and was single threaded. The company quickly recognized that this legacy environment was not sufficient to realize the full potential of its capabilities and meet client demand. Leadership—in particular, global CEO of Wunderman Thompson Data Jacques van Niekerk and chief product officer and president, data products, Michael Murray—understood the need for a systematic approach to leverage data assets, turbocharge its modeling initiatives, and deliver market-leading, AI-driven solutions at scale.
Journey to AI at Scale
The journey to AI was kickstarted when Wunderman Thompson Data decided to collaborate with IBM on a prospecting use case, scoped to three initial clients. The collaboration brought together the elements of people, process, and platform to lay the foundation for what would later become an AI Factory. From a people perspective, IBM and Wunderman Thompson Data set up a One Team structure, where a small team with different skills (business owner, data engineering, data science, IT operations, etc.) was assembled from both companies. From a process perspective, the team adopted a set of best practices for various stages of the initiative, ranging from discovery sessions to scope and structure of the use case, and from Agile sprints for exploring and building the ML pipelines to working with IT operations to test, deploy, and monitor models. From a platform perspective, the team used IBM’s Cloud Pak for Data running on Amazon Web Services as a collaborative platform to support various personas through different stages of the AI life cycle.
The platform allowed the company to leverage the full power of its IDN, train on millions of rows of data, use thousands of features that make up the identity of individuals, iterate quickly through algorithm and hyperparameter optimizations, and produce scalable ML pipelines. The results showed significant uplift in customer-prospecting outcomes and drove business appetite for scaling to additional clients and use cases.
With the initial success, attention turned to scaling the modeling needs from a handful of clients to hundreds and doing this in the most cost-effective way. The foundational elements of people, process, and platform played a major role in accomplishing this. A growing team executes a set of best practices for each stage of the AI life cycle, using the Cloud Pak for Data platform, now running on multiple clouds. Wunderman Thompson currently executes hundreds of models every week just for its clients’ prospecting use cases.
COVID-19 RRR
As of the writing of this report, communities are starting to take various measures to reopen businesses while reducing the risk of further COVID-19 outbreaks. Navigating the recovery is daunting. Wunderman Thompson Data saw an opportunity to help its clients navigate these uncertain times with AI-powered health and economic guideposts. Its initial public entry into this work are the COVID-19 Risk, Readiness, and Recovery Indexes. They deliver an initial view of the health and economy of markets down to the local level.
The company was able to rapidly create COVID-19-relevant RRR indexes, designed to give businesses and community leaders crucial information—including a Predictive Recovery Index that looks forward into recovery timing for communities—that can help them determine a pace for reopening and renewing marketing activities. Beyond the public view, Wunderman Thompson Data is customizing the dashboard through private clients’ views, incorporating a client’s CRM data, business location information, or vendor and supply chain data to deliver custom insights within its defined markets. Wunderman Thompson is modeling outcomes, monitoring economic progress in “green shoot” communities—where it is appropriate and necessary to focus—and undertaking localized marketing and media activation to help restart the economy for businesses and communities.
The AI Factory concept was central to rolling out this new application quickly in response to the challenging and unexpected market conditions that COVID-19 presented. Wunderman Thompson was able to go from idea to deployed application in a few weeks.
Expanding to Other Operating Companies
The AI Factory construct has allowed Wunderman Thompson Data to not just scale its core business applications and respond quickly to new ideas and fast-moving client requirements, but also to expand into new opportunities. The company is now collaborating with other operating companies under the WPP company umbrella, combining the power of the IDN with additional data and insights from these sister companies. As an example, it worked with a sister company to improve revenue prediction based on ad spend. The sister company brought ad spend and client revenue data to the table. Wunderman Thompson Data combined the power of the IDN with this data and rolled out an application that predicts client revenue by ad spend, city, and channel within 5% of actuals on a weekly basis. The AI Factory allowed the combined team to scope the use case; establish business KPIs; combine and explore data; try out hypotheses; build ML pipelines; and test, validate, and deploy an AI-driven solution in less than six weeks. The same approach is used to scale across the enterprise, unleashing the true potential of AI across business scenarios and clients.
We now have an AI Factory that allows us to tap into the full power of Wunderman Thompson’s Identity Network and provide solutions at scale and speed to our clients. The Factory allows us to go from a new business idea to an AI solution in the matter of weeks, not months.
Michael Murray, Chief Product Officer
1 Niraj Tank and Sumit Daryani, “Model as a Service for Real-Time Decisioning,” OSCON 2019.