
For the last 30 years, object-oriented techniques have become the standard for software analysis and development. Since C++ fully supports OO programming, it is essential that you have a good understanding of OO techniques in order to solve many of the challenges presented by options and derivatives programming.
This chapter presents a practical summary of the programming topics you need to understand in order to become proficient in the relevant OO concepts and techniques used in the field of options and derivatives analysis. Some of the topics covered in this chapter include:
Fundamental OO concepts in C++: A quick review of OO concepts as implemented in C++, with examples based on derivatives and options.
Problem partitioning: How to partitioning a problem into classes and related OO concepts, using specific C++ techniques.
Designing a solution: How to use classes and objects to solve problems in financial engineering.
ReusingOO components: How to create reusable C++ components that can be integrated to your own full-scale applications, or even distributed as an external library.
OO Programming Concepts
Object-oriented programming provides set of principles that can facilitate the development of computer software. Using OO programming techniques, you can easily organize your code and create high-level abstractions for application logic and commonly used component libraries. In this way, OO techniques can be used to improve and reuse existing components, as well as simplify the overall development. OO programming promotes a way of creating software that uses logical elements operating at a higher level of abstraction.
When considering different styles of software programming, it is important to use tools and languages that provide an adequate level of support for the desired programming style. C++ was designed to be a multi-paradigm programming language (see Figure 4-1); therefore, it can properly support more than one style of programming, including:
Structured programming: In structured programming, code is organized in terms of functions and data structures. Each function uses standard control flow structures, such as for, while, do, and if/then/else, to organize code. While this programming style was used in isolation, nowadays it is more commonly used as part of an OO or functional approach.
Functional programming: In this style of programming, functions are the most important element of composition. Functions are also used as a first-class citizens: they can be stored and passed as parameters to other functions in this programming paradigm. The C++11 standard has improved support for functional programming, as seen in Chapter 8.
Generic, or template-based programming: Templates allow programmers to create parameterized types. Such types can be used to implement concepts that are independent of the specific type employed. A common example is a container class such as std::vector, which can be used to store values of any type in a sequence of elements stored in contiguous memory.
Object-oriented programming: A programming style where code is organized in classes and shared in the form of objects. In the OO paradigm, objects can respond to operations that are implemented as member functions in C++. Encapsulation and inheritance are common mechanisms used to support the implementation of OO systems.

Figure 4-1. A comparison of concepts use in four programming paradigms enabled by C++
C++ offers complete support for OO concepts. Some of these support elements have already been used in the previous chapters of this book, including classes, objects that can be instantiated from these classes, as well as their supporting elements such as constructors, and destructors, among others. In this chapter, you will learn more about OO concepts that are frequently used in real-world applications, with examples that are directly used in the implementation of options and derivatives in C++.
Remember that the main elements of OO programming can be summarized as follows:
Encapsulation: This concept refers to the division of programmatic responsibilities into different language elements. C++ offers classes that can be used to encapsulate desired functionality in a clear way. When planning applications and coding them in C++, it is always a good idea to determine the main concepts that need to be represented as classes and encapsulate the related procedural code into member functions of that class.
Inheritance: C++ allows programmers to extend a class with new operations. This is possible through the concept of inheritance, when a new class assumes all operations previously available in an existing class, called its parent. Inheritance also allows programmers to add new functionality to existing classes, through the inclusion of new member functions that provide the required functionality.
Polymorphism: Inherited classes in C++ extend available classes through the addition of new member functions. Inherited classes also modify the behavior of existing member functions that have been marked with the virtual keyword. Polymorphism in C++ is defined through the use of virtual functions, which are then dispatched using a virtual function table, as implemented by most compilers.
Although C++ provides much more than pure OO programming, these elements alone can nonetheless be used to create very complex and efficient applications in various areas, and in this case on financial applications. In the remaining of this chapter, you will see how these OO concepts can be utilized to solve problems occurring on financial derivatives.
Note
Software development using OO techniques not only allows separation between implementation and interface, but it also requires the clear definition of such concepts. A good C++ programmer will excel at decomposing problems into smaller components, which can then be coded into separate classes. While I can only give examples of this process in this book, design and analysis of OO software is a complex and important phase that should be part of your effort during each software project.
Encapsulation
The idea of encapsulation is to define abstract operations that can be implemented by a single class. Once these operations have been made available, clients of a class can use them without being exposed to the internal details of the implementation such as variables, constants, and other internal code that is only used locally to implement the required features .
One of the important aspects of encapsulation is the ability to hide data, which then becomes the member variables of the target class. Consider for example a class that represents a credit default swap. The class should contain enough information to determine how to store and trade such financial instruments. For an example of data that must be encapsulated into such a class, you might want to consider the following:
Underlying instrument: The financial instrument that is the basis for the contract. It could be, for example, a set of bonds for a particular company, cash, or some other pre-established financial instrument.
Counterpart: The institution that is the target of the default swap payments. The payment is generally made when the target institution defaults.
Payoff value: The monetary value of the default swap contract. This payoff is transferred between institutions if the contract payment condition is triggered.
Term: The term of the contract, after which it ceases to exist.
Spread cost: The recurring payment made by the buyer to maintain the contract. Many contracts require equal payments of a spread that is due at regular periods, such as every month or every year.
By using encapsulation to represent a CDS contract , a C++ developer can simply create a class that contains all these data elements. For example, here is a simple CDS class that represents the concepts described previously.
enum CDSUnderlying {CDSUnderlying_Bond,CDSUnderlying_Cash,// other values here...};class CDSContract {public:CDSContract();CDSContract(const CDSContract &p);∼CDSContract();CDSContract &operator=(const CDSContract &p);// other member functions here...private:std::string m_counterpart;CDSUnderlying m_underlying;double m_payoff;int m_term;double m_spreadCost;};
With this definition, you encapsulate all the information that corresponds to a CDS contract into a single class. Because the data members are private, this means that only the class can directly access their state. The main advantage of such an arrangement is that no code outside the CDSContract class is allowed to access the private data, achieving true encapsulation.
If it is necessary to provide access to one or more data members of a class, there are two options. The data member could be moved to the public section of the class, but this would make it possible for the data member to change without knowledge of the CDSContract class.
A better way of doing this is to provide an access member function in a case-by-case way. You could, for example, allow the counterpart and payoff member variables to be accessed by other objects through member functions, as shown here:
class CDSContract {public:CDSContract();CDSContract(const CDSContract &p);∼CDSContract();CDSContract &operator=(const CDSContract &p);std::string counterpart() { return m_counterpart; }void setCounterpart(const std::string &s) { m_counterpart = s; }double payoff() { return m_payoff; }void setPayoff(double payoff) { m_payoff = payoff; }private:std::string m_counterpart;CDSUnderlying m_underlying;double m_payoff;int m_term;double m_spreadCost;};
Using this strategy, any change happening to the m_counterpart and m_payoff will occur only through an operation on the CDSContract class. This means that the class can react to any changes in these values, providing proper encapsulation of that data. For example, suppose that you want to reset the payoff value whenever the counterpart for the CDS contracts changes. This could be done the following way:
class CDSContract {public:// ...std::string counterpart() { return m_counterpart; }void setCounterpart(const std::string &s);double payoff() { return m_payoff; }void setPayoff(double payoff) { m_payoff = payoff; }private:std::string m_counterpart;CDSUnderlying m_underlying;double m_payoff;int m_term;double m_spreadCost;static double kStandardPayoff;};void CDSContract::setCounterpart(const std::string &s){m_counterpart = s;setPayoff(kStandardPayoff);}
Whenever the counterpart for the contract changes, the class reacts by resetting the payoff to a standard value (defined by the constant kStandardPayoff). That would not be possible if the m_counterpart data member were not properly encapsulated into the CDSContract class.
Inheritance
The benefits of encapsulation make it easy to implement and maintain code written in C++. However, it is commonly necessary to extend that code to handle situations that could not be anticipated by the designer of the original class. In that case, you can use inheritance as a powerful way to adapt your classes to new requirements.
With the use of inheritance , it is possible to create a new class that contains the same data and behavior as an existing class. The new class is called a derived class and the original class is called a base or parent class. For example, a loan only credit default swap is a CDS where the protection is based on secured loans made on the target entity.
This useful type of CDS could be modeled as a new class that inherits from the original CDSContract class. If you need to create a derived class LoanOnlyCDSContract from a base class CDSContract, the C++ syntax would be the following:
class LoanOnlyCDSContract : public CDSContract {public:// constructors go herevoid changeLoanSource(const std::string &source);private:std::string m_loanSource;};
The public keyword is used to indicate that the public interface of the base class CDSContract is still available to the new class. The changeLoanSource member function is used to determine the source of the loan used by the CDS contract. The loan source is then stored in the m_loanSource member variable.
Notice that inheritance creates a new class that has access to all of the public and protected interfaces of the base class. So, you still can call any method from the original CDSContract class when working with LoanOnlyCDSContract. On the other hand, private functions and data members are not available to the derived class. If you envision that a class could be used as the base for a hierarchy, it should provide access to some of the non-public interface using protect variables and functions. As a result, inheritance also requires a certain level of cooperation between base and derived classes.
Note
Inheritance requires that the new class be used in a context similar to the original class. Therefore, inheritance shouldn’t be used to create classes that have just a superficial similarity to the original class. In particular, a class that inherits from a base class could be used in the same code as the original class. If this is not true for the new class you need, it is better to create a separate class with a specialized interface.
Inheritance is the base technology used to accomplish many of the other techniques available in OO programming. Therefore, ideas such as polymorphism and abstract functions are possible due to the use of inheritance.
Polymorphism
While inheritance in itself provides a useful extension mechanism, its biggest advantage is the possibility of changing the original behavior of the base class in specific situations. In C++, this is enabled by using the virtual keyword to mark member functions that have polymorphic behavior.
For example, suppose that the CDSContract class is required to calculate the contract value at a particular date. This operation can be performed at the class level, but it will be slightly different for each particular implementation. Concrete implementations of the class may want to take into consideration particular factors that are not available at the base class level, such as differences in underlying, contract structures, and calculation models.
For these and other reasons, determining the best way to calculate the contract value may not be possible at the base class, and it must be delegated to derived class. Such derived class will possess additional data that can be used to compute the contract price with more precision than what is possible on the base class.
This behavioral change can be performed in the derived classes if you use C++ virtual mechanism. Syntactically, this polymorphic behavior can be implemented as long as the member function is modified with the virtual keyword in the original class. The virtual keyword is a C++ tool that allows functions to behave differently according to the concrete instance that is executing the function call.
For example, to support the required polymorphic behavior to calculate the contract value, the CDSContract base class should be coded as follows.
class CDSContract {public:CDSContract();CDSContract(const CDSContract &p);∼CDSContract();CDSContract &operator=(const CDSContract &p);std::string counterpart() { return m_counterpart; }void setCounterpart(const std::string &s);double payoff() { return m_payoff; }void setPayoff(double payoff) { m_payoff = payoff; }virtual double computeCurrentValue(const Date &d);private:std::string m_counterpart;CDSUnderlying m_underlying;double m_payoff;int m_term;double m_spreadCost;static double kStandardPayoff;};
The virtual double computeCurrentValue(const Date &d); line declares a new member function that can be overridden by derived classes.
Note
Virtual methods need to be recognized by the compiler. Therefore, the virtual keyword has to appear directly in the base class, not only in the derived classes. If a member function is supposed to have polymorphic behavior, you have to use virtual to signal this information to the compiler. Overriding a non-virtual member function doesn’t create a polymorphic object and will result in a warning in most compilers.
The classes derived from CDSContract can implement the virtual member function declared previously, so that it can be invoked when instances of that derived class are created. Here how this can be done for the
The isTradingDay member function returns true if the current date is not a holiday or a weekend day:
class LoanOnlyCDSContract : public CDSContract {public:// constructors go herevoid changeLoanSource(const std::string &s);virtual double computeCurrentValue(const Date &d);private:std::string m_loanSource;};
The implementation for a virtual function, both in the base class as well as the derived classes, is not different from the syntax used in other member functions. It is used in the compiler to determine the correct way to handle virtual functions that are called.
The use of a virtual function is determined by its polymorphic invocation through pointers and references. For example, consider the following code using CDSContract and LoanOnlyCDSContract:
void useContract(bool isLOContract, Date ¤tDate){CDSContract *contract = nullptr;if (isLOContract){contract = new LoanOnlyCDSContract();}else{contract = new CDSContract(); // normal CDS contract}contract->computeCurrentValue(currentDate);delete contract;}
The useContract function is passed two arguments: the Boolean value isLOContract, which indicates that the contract used is a loan-only CDS. The second argument is the current date for use of the contract. The first line in the function:
CDSContract *contract = nullptr;determines the base class of the object that will be created. As with any OO object in C++, a pointer (or reference) to a base class can be used to point to objects of any descent class. In this case, a pointer to the CDSContract class (being the base class) can also be used to point to objects of type LoanOnlyCDSContract. The pointer is initialized to nullptr.
Note
The keyword nullptr was introduced in the C++11 standard. It provides a way to initialize pointers with a null value without the use of a macro such NULL (which is used in C but normally avoided in C++), or the value 0, which can be easily confused with a numeric expression.
The next lines determine the exact type that will be instantiated. If the isLOContract flag is set to true, a new object of type LoanOnlyCDSContract is created using the new keyword. Otherwise, the function creates an object of type CDSContract as the default value. In a more complex application, types should not be encoded using flags, but passed as a parameter or supplied by some of the part of the application.
The next line
contract->computeCurrentValue(currentDate);uses the pointer contract to perform a polymorphic call to computeCurrentValue. The polymorphic call mechanism will determine the correct implementation for the member function, depending on the exact class of the instance pointed to by the contract pointer. The next section explains how this mechanism works in practice, and how it affects the creation and use of objects in C++.
Polymorphism and Virtual Tables
The first step in using polymorphism via virtual functions is to understand how they differ from regular member functions. When a virtual function is called, the compiler has to determine the type of call and translate it into binary code that will perform the call to the correct implementation. This is done in C++ using the so-called virtual table mechanism.
A virtual table is a vector of functions that is created for each class that uses at least one virtual function. The virtual table stores the addresses of virtual functions that have been declared for that particular type, as shown in Figure 4-2.
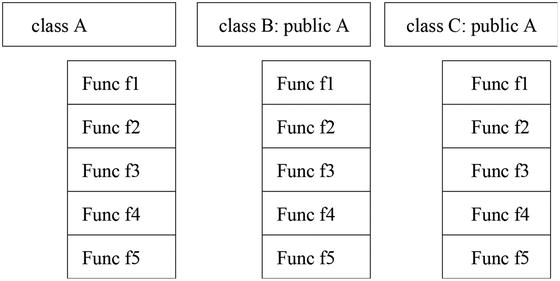
Figure 4-2. Virtual functions shared by classes A, B, and C and stored in their respective virtual function tables
As shown in Figure 4-2, class A is the base class and it contains a number of virtual functions, here denoted by the names f1 to f5. The slots in these tables store pointers to the implementation used by the class. Two other classes—B and C—are declared as derived classes via a public interface. This makes classes B and C inherit each a virtual table that contains at least the same function pointers (derived classes can add more virtual functions if they wish to do so).
Each class can define its own version of the virtual function, and as a result the pointer to that function is stored in the corresponding location of the virtual table. The virtual table is populated in the compiler as it creates the data structures necessary for each class. At execution time, the virtual table is available for code executed by each of the classes defined in this example.
During runtime, the code generated by the C++ compiler can retrieve the location in the table where the function pointer is stored. Then the function is called with the given parameters. First, the compiler retrieves the location of the virtual table associated with the class. Then, the compiler finds the function pointer at a predefined displacement from the beginning of the table. Finally, the program makes an indirect call using the function pointer stored at that location.
If you use this information to understand how C++ code works, you can see how the CDSContract and its derived class would execute a call to the computeCurrentValue member function, as shown in the following line of code:
contract->computeCurrentValue(currentDate);The first step performed by the implementation is to find the virtual table for the particular object that is stored in the contract pointer. Then, the slot corresponding to the virtual function computeCurrentValue is searched, usually at a fixed distance from the beginning of the vector as determined by the compiler. Finally, the function pointer retrieved in this way is called indirectly, resulting in a function call to the correct implementation.
Although the sequence of steps necessary to call a virtual function appear to be complex, modern compilers can generate very efficient code using the virtual table technique. By means of code optimization, virtual function calls frequently end up as just a call to a function pointer.
Virtual Functions and Virtual Destructors
Another member function that can be annotated with the virtual keyword is the destructor. As you may remember, a destructor is called automatically (in the code generated by the compiler) when an object goes out of scope, with the objective of reclaiming resources used by the object.
The destructor may also be used through the keyword delete. When a delete is used, the code calls the destructor and frees the memory used by the object up to that moment. As a result, the pointer is not valid after the delete is called.
It is important to consider the role of the destructor when virtual functions are part of a class. The reason is that object cleanup is a class-specific activity, which needs to be overridden for each individual derived class that contains additional resources (such as memory, network connections, or graphical contexts). As a result, the destructor usually has different implementations that are necessary to perform the proper cleanup and de-allocation activities.
For these reasons, the correct way to handle destructors in polymorphic classes is to use the virtual mechanism in their definition. This provides the means for each subclass to call a specific destructor even when called from a base pointer.
For example, consider what happens when the destructor in the base class is not virtual.
class CDSContract {public:CDSContract();CDSContract(const CDSContract &p);∼CDSContract() { std::cout << " base class delete " << std::endl; }CDSContract &operator=(const CDSContract &p);std::string counterpart() { return m_counterpart; }void setCounterpart(const std::string &s);double payoff() { return m_payoff; }void setPayoff(double payoff) { m_payoff = payoff; }virtual double computeCurrentValue(const Date &d);// ...};
The derived class LoanOnlyCDSContract would have the following simple definition, which just prints an informational message:
class LoanOnlyCDSContract : public CDSContract {public:LoanOnlyCDSContract() { std::cout << " derived class delete " << std::endl; }// constructors go herevoid changeLoanSource(const std::string &s);virtual double computeCurrentValue(const Date &d);private:std::string m_loanSource;};
If called from client code, these definitions may result in undefined behavior. For example, consider the following fragment:
void useBasePtr(CDSContract *contract, Date ¤tDate){contract->computeCurrentValue(currentDate);delete contract;}
This code receives a pointer of type CDSContract, uses it to call a virtual function, and then uses the delete operator on it. When called in the following way:
void callBasePtr(){Date date(1,1,2010);useBasePtr(new LoanOnlyCDSContract(), date);}
The code has undefined behavior, because the compiler cannot guarantee that the destructor of the derived class will be found and executed. From the compiler point of view, a non-virtual destructor doesn’t need to be called when the object is destroyed.
To fix this problem, the right thing to do is to declare the destructor as virtual in the base class. A simple change in this definition can accomplish this:
class CDSContract {public:CDSContract() {}CDSContract(const CDSContract &p);virtual ∼CDSContract() { std::cout << " base delete " << std::endl; }CDSContract &operator=(const CDSContract &p);// ... other members here};
Once a virtual destructor has been declared in the base class, all descendant classes will also contain a virtual destructor, independent of using the virtual keyword. This is guaranteed by the presence of a virtual table containing the address of the destructor, as described in the previous section. The result of the callBasePtr function after this change is guaranteed to be the following:
$ ./CDSAppderived class deletebase class delete
Abstract Functions
Another mechanism used to implement polymorphism in C++ are abstract functions . Such abstract functions are closely related to virtual functions, but their presence marks the containing class as an abstract class, which cannot be directly instantiated.
An abstract class is frequently used when a function should be provided in derived classes, but there is no clear default behavior that could be provided by the base class. This is a common situation when a base class provides only the framework for an algorithm, with details that are purposefully left unspecified. The idea is that the derived classes will necessarily provide the missing functionality that would make the derived classes useful for a particular application.
The syntax for abstract functions is similar to the syntax for virtual functions. The member function is preceded with the virtual keyword as previously seen. In addition, the syntax = 0; is used to terminate the declaration of the abstract function. Notice that only a declaration is needed, since no implementation is necessary for an abstract function (although it can be provided if available).
For an example, consider that the CDSContract class has a member function to process a credit event. In the world of credit default swaps, a credit event is what happens when a company calls for bankruptcy. Processing this event is different for each entity and CDS type; therefore, I would like to have such a member function as an abstract virtual function:
class CDSContract {public:CDSContract() {}CDSContract(const CDSContract &p);virtual ∼CDSContract() { std::cout << " base delete " << std::endl; }CDSContract &operator=(const CDSContract &p);std::string counterpart() { return m_counterpart; }void setCounterpart(const std::string &s);double payoff() { return m_payoff; }void setPayoff(double payoff) { m_payoff = payoff; }virtual double computeCurrentValue(const Date &d);virtual void processCreditEvent() = 0;// ...};
If a base class includes even one abstract virtual function, it becomes an abstract class that cannot be itself instantiated. The reason is that the class can be thought of as “incomplete,” since at least one of its virtual functions has no implementation. Given these definitions, the following code would become invalid:
CDSContract *createSimpeleContract(){CDSContract *contract = new CDSContract(); /// Wrong: CDSContract is now Abstractcontract->setCounterpart("IBM");return contract;}
Once an abstract member function has been defined, the classes that are direct descents are required to implement that function, or else they will become abstract too. For example, the descendant class LoanOnlyCDSContract now has to implement processCreditEvent in order to be used by client code. Even a trivial implementation would allow LoanOnlyCDSContract to be instantiated.
class LoanOnlyCDSContract : public CDSContract {public:LoanOnlyCDSContract() { std::cout << " derived class delete " << std::endl; }// constructors go herevoid changeLoanSource(const std::string &s);virtual double computeCurrentValue(const Date &d);virtual void processCreditEvent();private:std::string m_loanSource;};void LoanOnlyCDSContract::processCreditEvent(){}
Abstract member functions can be freely used even inside the abstract class, where the body of that member function is not defined. For example, this is a valid definition for the CDSContract::computeCurrentValue member function:
double CDSContract::computeCurrentValue(const Date &d){if (!counterpart().empty()){processCreditEvent(); // make sure there is no credit event;}return calculateInternalValue(); // use an internal calculation function}
Building Class Hierarchies
One of the advantages of OO code is the ability to organize your application around conceptual frameworks defined by classes. A class hierarchy allows the sharing of common logic that can be easily reused in other contexts. Proper use of class hierarchy can reduce the amount of code duplication and lead to applications that are more understandable and easy to maintain.
A class hierarchy can be developed around important concepts used by the application. For example, in a derivatives-based application, the class CDSContract would be a candidate to become the root of a class hierarchy. Figure 4-3 shows a possible class hierarchy for CDS contracts, containing derived classes for the following types of contracts:
LoanOnlyCDSContract: CDS contracts that are based on loans to other institutions and have special logic for processing these loans.
HedgedCDSContract: A CDS contract type where hedging is performed using other asset classes with the goal of reducing contract risk.
NakedCDSContract: A particular CDS contract where the contract seller does not own the underlying asset negotiated in the contract.
FixedInterestCDSContract: A CDS type where the contract requires a fixed interest rate for the duration of the specified agreement.
VariableInterestCDSContract: A type of CDS where the contracts are defined using variable interest rates, using a well-known benchmark for interest rates.
TaxAdvantagedCDSContract: A particular type of CDS contract that takes advantage of a special tax structure.
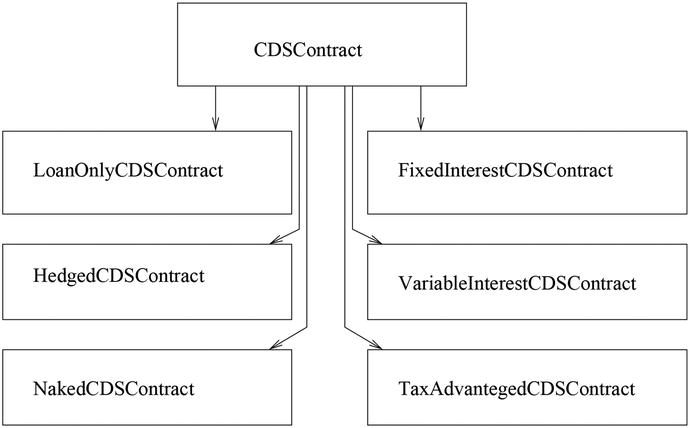
Figure 4-3. A class hierarchy rooted on the base class CDSContract
All these CDS contract derivatives would benefit from code sharing from the base class CDSContract. As a result, common functionality such as CDS pricing, contract creation, and contract maintenance can be stored in a central place and used by as many different types of CDS contracts as possible.
Although creating class hierarchies is a useful technique for code maintenance and sharing, inheritance may not be the best strategy for code organization in some cases. It is important to be able to identify the situations in which other approaches would work better. Here are some potential disadvantages of using inheritance :
Increased coupling between classes: Once you decide to use inheritance, there is a big interdependence between classes. A small change in the base class can affect all descendent classes. If there is a situation where the base class can vary frequently in functionality and responsibilities, then inheritance may not be the best solution.
Physical dependencies at compilation time: In C++, inheritance also creates a compile-time dependency between classes. To generate correct code, the C++ compiler needs to access the definition of each base class. This may result in increased compilation time, which is sometimes undesirable, especially in large software projects.
Increased information coupling: Class hierarchies may also require developers to learn the multiple implementations of different classes at different levels. This is necessary especially when classes are not well designed and information about their operations is not clear.
Object Composition
Another strategy to organize and code using OO techniques is object composition . Composition is an alternative to inheritance, where you can use the behavior of an object without the dependency caused by direct class/subclass relationship.
To use object composition, you need to store the object that has the desired behavior as a member variable for the containing object. This is the basic strategy, which can be implemented in at least three ways in C++:
Storing a pointer to an object: In this case, only a pointer to the object is stored as part of the class. This option allows an object to be created inside the class or passed as a parameter from a user of the class and then stored in a member variable.
Storing a reference to an object: This option allows the class to receive a reference to an existing object, but doesn’t allow the object to be created after the constructor is executed. A reference in C++ cannot be reassigned, which leads to a requirement that the stored object needs to be valid the whole time the container object exists.
Storing the object as a member variable: In this case, the containing class assumes responsibility for storing the required object. In this case, it is also necessary for the compiler to know the exact size of the object stored as a member variable.
With object composition, a class can use functionality provided by another class without the use of inheritance .
For example, suppose that the CDSContract class needs a fast calculation of integrals. In this case, a good approach is to use an object-composition strategy to access the functionality of integration, instead of adding this functionality to the base class. You could do this, for example, by passing to the CDSContract constructor a pointer to a MathIntegration object and storing that pointer as a member function. The code would look like this:
class MathIntegration;class CDSContract {public:CDSContract() {}CDSContract(MathIntegration *mipt);CDSContract(const CDSContract &p);virtual ∼CDSContract() { std::cout << " base delete " << std::endl; }CDSContract &operator=(const CDSContract &p);// other member functions hereprivate:std::string m_counterpart;CDSUnderlying m_underlying;double m_payoff;int m_term;double m_spreadCost;MathIntegration *m_mipt;static double kStandardPayoff;};
When necessary, the pointer could be used to access the functionality stored in the MathIntegration class. The best thing about this kind of design is that there is little coupling between the CDSContract and MathIntegration classes. Each one can evolve separately, by adding new functions as necessary, without the need for mutual dependencies.
Conclusion
In this chapter, you read an overview of OO concepts provided in C++ and how they are used in the financial development community to solve problems occurring with options and derivatives.
The first part of this chapter summarized the basic characteristics of OO as implemented in C++, including the main concepts of encapsulation, inheritance, and polymorphism. You learned about the technique used in C++ to implement polymorphic behavior through virtual functions. You also saw how virtual functions are stored in virtual tables that are created for each class that contains virtual functions.
This chapter also presented some examples of using OO to efficiently solve common problems in financial programming, as applied to options and derivatives. The next chapter proceeds to template-based concepts and explains how they can be used to create high-performance solutions to problems in the area of financial derivatives processing.