
3. Oracle Solaris Zones
Operating system virtualization (OSV) was virtually unknown in 2005, when Solaris 10 was released. That release of Solaris introduced Solaris Zones—also called Solaris Containers, and now called Oracle Solaris Zones—making it the first fully integrated, production-ready implementation of OSV. In response, several other implementations have been developed or are planned for other operating systems (OS). Zones use a basic model similar to an earlier technology called jails. Chapter 1, “Introduction to Virtualization,” provided a complete description of OSV. To summarize the key points here, OSV creates virtual OS instances, which are software environments in which applications run; these instances are isolated from each other but share one copy of an OS, or part of an OS and one OS kernel.
Oracle Solaris Zones provide a software environment that appears to be a complete OS instance from within the zone. To a process running in a zone, the primary differences are effects of the robust yet configurable security boundary around each zone. Zones offer a very rich set of features, most of which were originally features of Solaris, but then were applied to zones. The tight level of integration between zones and the rest of Solaris minimizes software incompatibility and improves the overall “feel” of zones. Zones provide the following capabilities:
![]() Configurable isolation and security boundaries
Configurable isolation and security boundaries
![]() Multiple namespaces—one per zone
Multiple namespaces—one per zone
![]() Flexible software packaging, deployment, and flexible file system assignments
Flexible software packaging, deployment, and flexible file system assignments
![]() Resource management controls
Resource management controls
![]() Network access
Network access
![]() Optional direct access to devices
Optional direct access to devices
![]() Centralized or localized patch management
Centralized or localized patch management
![]() Management of zones (e.g., configure, boot, halt, migrate)
Management of zones (e.g., configure, boot, halt, migrate)
This chapter describes the most useful features that can be used with zones, and offers reasons to use them. Although a complete description of each of these features is beyond the scope of this book, more details can be found at docs.oracle.com. The next few sections describe these features and provide simple command-line examples of their usage.
This chapter assumes that you have experience with a UNIX/Linux operating system and are familiar with other Solaris features, including the Solaris 11 packaging system (IPS) and ZFS.
The command examples in this chapter use the prompt GZ# to indicate that a privileged user has assumed the root role so as to execute commands in the computer’s global zone. The prompt zone1# indicates that a command is entered as a privileged user who has assumed the root role in the zone named zone1.
3.1 Introduction
Since their release at the beginning of 2005 as a new feature set of Solaris 10, Oracle Solaris Zones have become a standard environment in many data centers. Further, Solaris Zones are a key architectural element in many Oracle Optimized Solutions. This widespread adoption has been driven by many factors, including zones’ isolation, resource efficiency, observability, configurable security, flexibility, ease of management, and no-cost inclusion in Solaris.
As a form of operating system virtualization, Solaris Zones provide software isolation between workloads. A workload in one zone cannot interact with a workload in another zone. This isolation provides a high level of security between workloads.
Zones are also among the most resource-efficient server virtualization technologies. Their implementation does not insert additional instructions into the code path followed by an application, unlike most hypervisors. For this reason, applications running in zones rarely suffer from excess performance overhead, unlike many other types of virtualization.
Chapter 1 discussed another advantage of OSV over virtual machines: observability. From the management area, called the global zone, a system administrator with appropriate privileges can observe the actions occurring inside zones. This insight improves the system’s manageability, making it easier to develop a holistic, yet detailed view of the consolidated environment.
Combining multiple workloads into one larger system can enable one workload to temporarily run faster because more resources are available to it. In contrast, a prolonged state of overutilization can prevent another workload from meeting its desired response time. Solaris includes a comprehensive set of resource management features that may be used to limit resource consumption in such situations.
To tailor your implementation of zones, you can choose from among a variety of Solaris Zone structures and characteristics. You can also choose the best model for your environment based on the characteristics and features it offers.
The original model, often called “native zones,” reduces the labor involved in managing many virtual environments (VEs). Most software packaging operations are executed in the global zone and applied to all of these zones automatically. Management is easiest from the global zone, but all of these zones are tied to the global zone, and are updated together as a unit.
Immutable Zones are a variant of the previous model, and offer the most robust security. The Solaris file systems in an Immutable Zone cannot be changed from within the zone, even by a privileged user. This model is the ideal choice for web-facing workloads, which are always the most accessible to malicious users.
New to Solaris 11.2, Kernel Zones offer more independence between a zone and the system’s global zone. This model is appropriate when a zone will be managed as a separate entity. One feature that sets kernel zones apart from other types of zones is the ability to move them to a different computer while they are running—that is, live migration.
Solaris 10 Zones are a Solaris 10 software environment in a Solaris 11 system. Software that will not run in a Solaris 11 environment may run in a Solaris 10 Zone instead. These zones are not affected by the package management operations that modify native zones.
Other types also exist, such as cluster zones and labeled zones. This book does not describe them in detail.
The rest of this chapter describes the features that can be modified to tailor the characteristics of Oracle Solaris Zones.
3.2 What’s New in Oracle Solaris 11 Zones
Solaris 10 users may benefit from a concise list of the new features and significant changes in Solaris 11 Zones:
![]() Kernel Zones offer increased isolation and flexibility, and enable live migration.
Kernel Zones offer increased isolation and flexibility, and enable live migration.
![]() Immutable Zones enhance security and manageability by preventing changes to the operating environment.
Immutable Zones enhance security and manageability by preventing changes to the operating environment.
![]() IPS simplifies Solaris software packaging and ensures consistent and supportable configurations.
IPS simplifies Solaris software packaging and ensures consistent and supportable configurations.
![]() Integration with the Solaris 11 Automated Installer enables automated provisioning of systems with Solaris Zones.
Integration with the Solaris 11 Automated Installer enables automated provisioning of systems with Solaris Zones.
![]() Solaris Unified Archives dramatically increase the flexibility of deployment and recovery, including any-to-any transformation.
Solaris Unified Archives dramatically increase the flexibility of deployment and recovery, including any-to-any transformation.
![]() Multiple per-zone boot environments improve the system’s availability and flexibility.
Multiple per-zone boot environments improve the system’s availability and flexibility.
![]() Solaris 10 Zones deliver an operating environment that is compatible with Solaris 10.
Solaris 10 Zones deliver an operating environment that is compatible with Solaris 10.
![]() Zones may be NFS servers.
Zones may be NFS servers.
![]() Integration with network virtualization features improves the network isolation of high-scale environments, and enables the creation of arbitrary network architectures within one Solaris instance.
Integration with network virtualization features improves the network isolation of high-scale environments, and enables the creation of arbitrary network architectures within one Solaris instance.
![]() Live zone reconfiguration improves the availability of Solaris Zones.
Live zone reconfiguration improves the availability of Solaris Zones.
![]() Zone monitoring is greatly simplified with a new command,
Zone monitoring is greatly simplified with a new command, zonestat(1M).
These new features and changes are described in this chapter.
3.3 Feature Overview
The Solaris Zones feature set was introduced in the initial release of Solaris 10 in 2005, and later extended in Solaris 11. The Solaris Zones implementation of OSV includes a rich set of capabilities. This section describes the features of zones and provides brief command-line examples illustrating the use of those features.
Solaris Zones are characterized by a high degree of isolation, with the separation between them being enforced by a robust security boundary. They serve as the underlying framework for the Solaris Trusted Extensions feature set. Trusted Extensions has achieved the highest commonly recognized global security certification, which is a tribute to the robustness of the security boundary around each zone.
The Oracle Solaris 10 documentation used two different terms to refer to combinations of its OSV feature set: containers and zones. Solaris 11 no longer distinguishes between those terms, and this book uses the term zones exclusively. However, Solaris Zones are similar in many ways to other OSV implementations that have been added to other operating systems since the release of Solaris Zones. Many of those implementations are also called “containers.”
This chapter describes the features of a Solaris 11.3 system, providing brief examples of their use. Some of the features described in this section did not exist in early updates to Solaris 11. To determine the availability of a particular feature, see the “What’s New” documents for Solaris 11 at docs.oracle.com.
3.3.1 Basic Model
When you install Oracle Solaris 11 on a system, the original operating environment—a traditional UNIX-like system—is also called the global zone. A sufficiently privileged user running in the global zone can create “non-global zones,” which are usually called “zones” for simplicity. Several types of zones exist. We will call the default “native zones” or simply “zones” when there is no ambiguity.
Most types of zones cannot contain other zones, as shown in Figure 3.1. The exception is kernel zones, which may contain their own non-global zones. If a kernel zone does have its own zones, we will call its global zone the kernel global zone; its non-global zones are called “hosted zones.” However, we discourage nesting zones in this manner, due to the additional complexity and lack of compelling use cases for this practice.

In a system with Solaris Zones, the global zone is the platform management area with the sole purpose of managing zones and the system’s hardware and software resources. It is similar to the control domain (or “dom0”) of a hypervisor-based system in two ways:
![]() The global zone requires resources to operate, such as CPU cycles and RAM. If an application running in the global zone consumes too much of a resource needed by the global zone’s management tools, it may become difficult or even impossible to manage the system.
The global zone requires resources to operate, such as CPU cycles and RAM. If an application running in the global zone consumes too much of a resource needed by the global zone’s management tools, it may become difficult or even impossible to manage the system.
![]() Users and processes in the global zone are not subject to all of the rules of zones. In terms of process observability, for example, a process in one zone cannot detect processes in other zones. As with a one-way mirror, processes in the global zone—even non-privileged ones—can detect processes in the zones, but users in the zones cannot see processes in the global zone. There is one exception to this observability rule: Processes in a kernel zone are invisible to processes in the global zone.
Users and processes in the global zone are not subject to all of the rules of zones. In terms of process observability, for example, a process in one zone cannot detect processes in other zones. As with a one-way mirror, processes in the global zone—even non-privileged ones—can detect processes in the zones, but users in the zones cannot see processes in the global zone. There is one exception to this observability rule: Processes in a kernel zone are invisible to processes in the global zone.
For these reasons, we recommend limiting the set of users who can access the global zone to system administrators, and limiting their activities to tasks related to the management of hardware and system software.
The system administrator uses Solaris commands in the global zone to perform tasks directly related to hardware, including installation of device driver software. The Solaris Fault Management Architecture (FMA) is also managed from the global zone, because its tools require direct access to hardware. Most zones do not have direct access to hardware. Zone management tools such as zonecfg(1M) and zoneadm(1M) can be used only in the global zone.
A kernel zone is a special case. It can manage the resources that are available to it, but cannot manage those resources that have not been assigned to it. As an example, suppose you assign two CPU cores to a kernel zone. The kernel zone can then manage those two CPU cores, but it cannot use other cores at all. In general, we will use the phrase “global zone” to mean the base instance of Solaris running on the hardware, with direct access to all hardware, rather than to mean the operating environment of a kernel zone.
Zones have their own life cycle, which remains somewhat separate from the life cycle of the global zone. After Solaris has been installed and booted, zones can be configured, installed, booted, and used as if they were discrete systems. They can easily and quickly be booted, halted, and rebooted. In fact, booting or halting a zone takes less than 5 seconds, plus any time needed to start or halt applications running in the zone. When you no longer need a zone, you can easily destroy it.
One difference between Solaris Zones and virtual machines is the relationship between the VE and the underlying infrastructure. Zones do not use processes in the global zone to perform any tasks, except the occasional use of management features. The processes associated with a zone access the Solaris kernel directly, using exactly the same methods—system calls—as they use when they are not running in a zone. When a zone’s process accesses an I/O device, or a kernel resource, it uses the same methods and the same code. This consistency explains the lack of performance overhead incurred by an application running in a native zone.
Kernel zones use a different method, because they run their own copies of the Solaris kernel. A kernel zone’s kernel makes efficient, customized calls into the global zone’s kernel so as to access devices. This method is similar in some ways to the paravirtualization used by some virtual machines.
Zones are very lightweight entities, because they are not an entire operating system instance. They do not need to test the hardware or load a kernel or device drivers. Instead, the base OS instance does all that work once—and each zone then benefits from this work when it boots and then accesses the hardware, if permitted by the list of privileges configured for the zone (see Section 3.3.2.1 for a discussion of privileges). Given these characteristics, zones, by default, use very few resources.
A default configuration uses approximately 3 GB of disk space, and approximately 90MB of RAM when running; other types of zones may use more space. When it is not running, a zone does not use any RAM at all. Further, because there is no virtualization layer that runs on a CPU, zones have negligible performance overhead. (All OSV technologies should have this trait.) In other words, a process in a zone follows the same code path that it would outside of a zone unless it attempts to perform an operation that is not allowed in a zone. Because it follows the same code path, it has the same performance.
Solaris Zones were originally designed to support VEs that use the same version of Solaris. To enable the use of other versions (called “brands”), a framework was created to perform translations of low-level computer operations.
One of these brands is Solaris 10. A Solaris 10 Zone behaves just as a Solaris 10 system does, with a few exceptions. Another brand implements low-level high-availability (HA) functionality for Solaris Cluster. The newest brand is kernel zones, which are described later in this chapter.
Although a zone is a slightly different environment from a normal Oracle Solaris system, a basic design principle underlying all zones is software compatibility. A good rule of thumb is this: “If an application runs properly as a non-privileged user in a Solaris 11 system that does not have zones, it will run properly in a native zone.” Nevertheless, some applications must run with extra privileges—traditionally, applications that must run as a privileged user. These applications may not be able to gain the privileges they need and, therefore, may not run correctly in a zone. In some cases, it is possible to enable such applications to run in a zone by adding more privileges to that zone, a topic discussed later in this chapter. Kernel zones do not have this limitation, as we shall see later.
3.3.2 Isolation
The primary purpose of zones is to isolate workloads that are running on one Oracle Solaris instance. Although this functionality is typically used when consolidating workloads onto one system, placing a single workload in a single zone on a system has a number of benefits. By design, the isolation provided by zones includes the following factors:
![]() Each zone has its own objects: processes, file system mounts, network interfaces, and System V IPC objects.
Each zone has its own objects: processes, file system mounts, network interfaces, and System V IPC objects.
![]() Processes in one zone are prevented from accessing objects in another zone.
Processes in one zone are prevented from accessing objects in another zone.
![]() Processes in different zones are prevented from directly communicating with each other, except for typical intersystem network communication.
Processes in different zones are prevented from directly communicating with each other, except for typical intersystem network communication.
![]() A process in one zone cannot obtain any information about a process running in a different zone—even confirmation of the existence of such a process.
A process in one zone cannot obtain any information about a process running in a different zone—even confirmation of the existence of such a process.
![]() Each zone has its own namespace and can choose its own naming services, which are mostly configured in
Each zone has its own namespace and can choose its own naming services, which are mostly configured in /etc. For example, each zone has its own set of users (via LDAP, /etc/passwd, and other means).
![]() Architecturally, the model of one application per OS instance maps directly to the model of one application per zone while reducing the number of OS instances to manage.
Architecturally, the model of one application per OS instance maps directly to the model of one application per zone while reducing the number of OS instances to manage.
In addition to the functional or security isolation constraints listed here, zones provide for resource isolation, as discussed in the next section.
3.3.2.1 Oracle Solaris Privileges
The basis for a zone’s security boundary is Solaris privileges. Thus, understanding the robust security boundary around zones starts with an understanding of Solaris privileges.
Oracle Solaris implements two sorts of rights management. User rights management determines which privileged commands a non-privileged user might execute. Consider the popular sudo program as an example of this kind of rights management. Process rights management determines which low-level, fine-grained, system-call–level actions a process can carry out.
Oracle Solaris privileges implement process-rights management. Privileges are associated with specific actions—usually actions that are not typically permitted for non-privileged users. For example, there is a Solaris privilege associated with modifying the system’s clock. Normally, only privileged users are permitted to change the clock. Solaris privileges reduce security risks: Instead of giving a person the root password just so that person can modify the system clock, the person’s user account is given the appropriate privilege. The user is not permitted to perform any other actions typically reserved for the root role. Instead, the Solaris privileges allow the system administrator to grant a process just enough privilege to carry out its function but no more, thereby reducing the system’s exposure to security breaches or accidents.
For that reason, in contrast to the situation noted with earlier versions of Solaris and with many other UNIX-like operating systems, the root role in Oracle Solaris is able to perform any operation not because its UID number is zero, but rather because it has the required privileges. However, a privileged user can grant privileges to another user, enabling specific users to perform specific tasks or sets of tasks. When a process attempts to perform a privileged operation, the kernel determines whether the owner of the process has the privilege(s) required to perform the operation. If the user—and therefore the user’s process—has that privilege, the kernel permits that user to perform the associated operation.
3.3.2.2 Zones Security Boundary
A zone has a specific configurable subset of all privileges. The default subset provides normal operations for the zone, and prevents the zone’s processes from learning about or interacting with other zones’ users, processes, and devices. The root role in the zone inherits all of the privileges that the zone has. Non-privileged users in a zone have, by default, the same set of privileges that non-privileged users in the global zone have.
The platform administrator can configure zones as necessary, including increasing or decreasing the maximum set of privileges that a zone has. No user in that zone can exceed that maximum set—not even privileged users. Those privileged users can modify the set of privileges assigned to the various users in that zone, but cannot modify the set of privileges that the overall zone can have. In other words, the maximum set of privileges that a zone has cannot be escalated from within the zone. At the same time, processes with sufficient privileges, running within the global zone, can interact with processes and other types of objects in zones. This type of interaction is necessary for the global zone to manage zones. For example, the privileged users in the global zone must be able to diagnose a performance issue caused by a process in one zone. They can use DTrace to accomplish this task because privileged processes in the global zone can interact with processes in zones in certain ways.
Also, unprivileged users in the global zone can perform some operations that are commonplace on UNIX systems, but that are unavailable to non-privileged users in a zone. A simple example is the ability to list all processes running on the system, whether they are running in zones or not. For some systems, this capability is another reason to prevent user access to the global zone.
The isolation of zones is very thorough in Oracle Solaris. The Solaris Zones feature set is the basis for the Solaris Trusted Extensions feature set, and the capabilities of Solaris Trusted Extensions are appropriate for systems that must compartmentalize data. Solaris 11 with Solaris Trusted Extensions achieved Common Criteria Certification at Evaluation Assurance Level (EAL) 4+, the highest commonly recognized global security certification. This certification allows Solaris 11 to be deployed when multilevel security (MLS) protection and independent validation of an OS security model is required. Solaris 11 achieved this certification for SPARC and x86-based systems, for both desktop and server functionality.
The isolation of zones is implemented in the Oracle Solaris kernel. As described earlier, this isolation is somewhat configurable, enabling the global zone administrator to customize the security of a zone. By default, the security boundary around a zone is very robust. This boundary can be further hardened by removing privileges from the zone, which effectively prevents the zone from using specific features of Solaris. The boundary can be selectively enlarged by enabling the zone to perform specific operations such as setting the system clock.
The entire list of privileges can be found on the privileges(5) man page. Table 3.1 lists the privileges that are most commonly used to customize a zone’s security boundary. The third column in Table 3.1 indicates whether the privilege is part of the default privilege set for zones. Note that some nondefault settings described elsewhere, such as ip-type=shared, change the list of privileges automatically.

Some privileges can never be added to a zone. These privileges control hardware components directly (e.g., turning a CPU off) or control access to kernel data. The prohibition against accessing the kernel data is intended to prevent one zone from examining or modifying data about another zone. Table 3.2 lists these privileges.
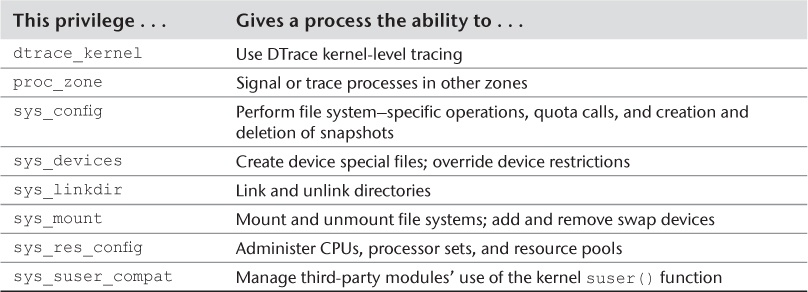
The configurable security of zones is very powerful and flexible. In addition to the privileges listed in Table 3.1, each zone has additional properties that you can use to tailor the security boundary and capabilities of Solaris Zones. Table 3.3 lists these resources and properties and indicates the section in this book that describes them.

3.3.3 Namespaces
Each zone has its own namespace. In UNIX systems, a namespace is the complete set of recognized names for entities such as users, hosts, printers, and others. In other words, a namespace represents a mapping of human-readable names to names or numbers that are more appropriate to computers. The user namespace maps user names to user identification numbers (UIDs). The host name namespace maps host names to IP addresses. As in any Oracle Solaris system, namespaces in zones can be managed using the /etc/nsswitch.conf file.
One simple outcome of having an individual namespace per zone is separate mappings of user names to UIDs. When managing zones, remember that a user in one zone with UID 238 is different from a user in another zone with UID 238. This concept should be familiar to people who have managed NFS clients. Also, each zone has its own Service Management Facility (SMF). SMF starts, monitors, and maintains network services such as SSH. As a consequence, each zone appears on the network just like any other Solaris system, using the same well-known port numbers for common network services.
3.3.4 Brands
Each zone includes a property called its brand. A zone’s brand determines how it interacts with the Oracle Solaris kernel. Most of this interaction occurs via Solaris system calls. A native zone uses the global zone’s system calls directly, whereas other types add a layer of software that translates the zone’s system call definitions into the system calls provided by the kernel for that Solaris distribution. A kernel zone has its own kernel, which uses a special mechanism to communicate with the system’s global zone.
Each Solaris distribution—for example, Solaris 11—has a default brand for its zones. The default brand for Solaris 11 is called solaris, but other brands exist for Solaris 11. Table 3.4 lists the current set of brands.

3.3.5 Packaging and File Systems
Solaris engineers tightly integrated the different feature sets of Solaris so that each benefits from the capabilities of the others. This section describes the integration of zones, IPS, and ZFS.
3.3.5.1 File System Location
A zone’s Solaris content exists in ZFS file systems. By default, the file systems are part of the global zone’s root pool. You can choose to implement a zone in its own pool, which enables zone mobility. Non-Solaris content, such as application data, may be stored in ZFS or non-ZFS file systems.
A set of ZFS file systems is created for each native zone. This step is necessary so that the Solaris 11 packaging system and boot environments will work correctly. In turn, the zone benefits from all of the advantages of ZFS.
Most zones use ZFS storage that is managed in the global zone. Such an approach to storage uses ZFS mirroring or RAIDZ to protect against data losses due to disk drive failure, and automatically benefits from ZFS checksums, which protect against myriad forms of data corruption.
When you create a zone, Oracle Solaris creates the necessary file systems, in which all of the zone’s directories and files reside. The highest level of those file systems is mounted on the zone’s zonepath, one of the many properties of a zone. The default zonepath is /system/zones/<zonename>, but you can also change it to a valid file system name in a ZFS pool.
3.3.5.2 Packaging
Solaris 11 uses IPS for operating system and application software package management. IPS and related features enable you to manage the entire life cycle of software in a Solaris environment, including package creation, manual and automated deployment of Solaris and applications, and updating of those software packages. This section assumes that you are already familiar with IPS, so it does not describe this system’s features except in terms of their application to Solaris Zones. For more information on IPS and related features such as the Automated Installer and Distribution Constructor, see the Oracle Solaris Information Library at www.oracle.com.
With IPS and its related features, you can perform the following functions:
![]() Understand the set of packages and their contents that are installed in a native zone or that are available to a native zone
Understand the set of packages and their contents that are installed in a native zone or that are available to a native zone
![]() Add optional software to a zone, and update or remove that software
Add optional software to a zone, and update or remove that software
![]() Create and destroy boot environments in a native zone
Create and destroy boot environments in a native zone
![]() Create repositories in a zone, including Solaris repositories and repositories of other software
Create repositories in a zone, including Solaris repositories and repositories of other software
In the context of IPS, an “image” is an installed set of packages. An image that can be booted is called a boot environment (BE). An instance of Solaris can have one or more BEs. Each BE consists of several ZFS file systems, but in general you do not manage the file systems individually. You use the command beadm(1M) to manage BEs, including creating and destroying them, activating the BE to be booted next, and mounting a BE temporarily to view or modify it, among other tasks.
A native zone in a S11 instance is called a “linked image.” Each linked image has its own copy of most of the Solaris package’s content, but not all of it. Its Solaris content has hard-coded dependencies on some global zone packages; that is, these dependencies cannot be modified by the user. In the documentation, this type of linking is occasionally called a “parent–child” relationship, where the global zone is the parent and the native zone’s linked image is the child.
Every native zone has a BE that matches a BE in the global zone. However, global zone BEs that predate the installation of a native zone will not have a matching BE in the native zone.
3.3.5.3 Updating Packages
Solaris IPS greatly simplifies the process of updating Solaris on a computer. When used in a system without zones, the following command will update all of the packages maintained by IPS to the newest versions available:
GZ# pkg update
If certain core packages will be updated, Solaris automatically creates a new BE, using ZFS snapshots, and prepares the system to use that BE when Solaris is next rebooted. If a new BE is not needed, the software updates may be available immediately.1
1. We advise the frequent use of ZFS snapshots as an “undo” feature.
When you update Solaris in the global zone using that method, all of the native zones are automatically updated. This operation will also update all of the packages installed in the global zone. If you have installed additional packages in native zones, they will be updated as well.
By default, native zones are updated serially. If desired, you can use the -C option to indicate that a certain number of zones should be updated simultaneously.
In addition, you can choose to update any packages that you installed separately into a zone. However, as with all updates, IPS will update these packages according to the dependency rules that are configured into each package. For example, you might find that you must update the global zone first, before updating a specific package in a zone.
3.3.6 Boot Environments
Solaris 11 automatically uses multiple boot environments, which are related bootable Solaris environments of one Solaris instance. The name and the purpose of this feature are similar to those of the corresponding features in Solaris 10 boot environments, but the implementation in Solaris 11 is new, and much more tightly integrated with other Solaris 11 features such as ZFS and zones. This level of integration leverages the combined strengths of the BEs and the other Solaris 11 features.
When you update Solaris 11, it automatically creates a new boot environment that will be used the next time that Solaris boots. When it creates that boot environment, it also creates a new boot environment for each native zone that is currently installed. Moreover, rebooting into a different boot environment configures the associated BEs configured for those zones. When any one of them boots, it will boot into the BE associated with the global zone’s currently running BE.
You should be aware of some subtle side effects of this implementation. If you install Solaris, and then update it, create a zone, and reboot into the original BE, it will seem as if the zone has disappeared. That is an illusion, however: The zone is still available in the updated BE. However, because it did not exist when the original BE was running, booting back into that BE returns the system to its state at the time when the original BE was running—a state that did not include the zone.
A zone can only boot into a BE associated with the BE currently running in the global zone. The output from the command beadm list marks unbootable BEs with the flag “!”. However, a privileged user in a native zone can create a new BE that will be associated with the currently running BE in the global zone. At that point, the zone will have two BEs from which it can choose. Either BE may be modified, and a privileged user in that zone may activate either BE and reboot the zone.
3.3.7 Deployment
You can use a few different methods to deploy native zones. The most basic method requires the use of two Solaris commands, zonecfg(1M) and zoneadm(1M). The Solaris Automated Installer can install zones into a system while it is also installing Solaris. Solaris Unified Archives can store a zone or a Solaris instance that contains one or more zones. The rest of this section will describe the two zone administrative commands, as well as zone-specific information for Unified Archives.
Using the command zonecfg, you can specify a zone’s configuration or modify the configuration, potentially while the zone is running. The zoneadm command controls the state of a zone. For example, you would use zoneadm to install Solaris into a zone, or to boot a zone.
Solaris Unified Archives enable you to manage archives of Solaris environments, both physical and virtual. The Unified Archives tools also perform transformations during deployment, which means converting an archive of a physical system into a virtual environment, or vice versa. Further, an archive of a physical system can include its Solaris Zones, and they can be deployed individually or together.
The Unified Archives command can create two types of archives: system recovery archives and clone archives. System recovery archives are useful for restoring a system during a disaster recovery event. In contrast, clone archives allow you to easily provision a large number of almost identical systems or zones. Unified Archives are described in detail later in this chapter.
3.3.8 Management
As the global zone administrator, you can configure one or more other global zone users as administrator(s) of a zone. The following abilities can be delegated to a zone administrator, as described later in this chapter:
![]() Use
Use zlogin(1) from the global zone, to access the zone as a privileged user
![]() Perform management activities such as installing, booting, and migrating the zone
Perform management activities such as installing, booting, and migrating the zone
![]() Clone the zone to create a new one
Clone the zone to create a new one
![]() Modify the zone’s configuration for the next boot or reboot
Modify the zone’s configuration for the next boot or reboot
![]() Temporarily modify the zone’s configuration while it runs
Temporarily modify the zone’s configuration while it runs
3.4 Feature Details
Features that can be applied to zones include all of the configuration and control functionality you would expect from an operating system and from a virtualization solution. Fortunately, almost all of the features specific to zones are optional. Thus, you can investigate and use each set of features separately from the others.
The zone-related features can be classified into the following categories:
![]() Creation and basic management, such as booting
Creation and basic management, such as booting
![]() Packaging
Packaging
![]() File systems
File systems
![]() Security
Security
![]() Resource controls
Resource controls
![]() Networking
Networking
![]() Device access
Device access
![]() Advanced management features, such as live migration
Advanced management features, such as live migration
Many of the configuration features may be modified while the zone runs. For example, you can add a new network interface to a running zone. This ability is described in a later section, “3.4.7.2 Live Zone Reconfiguration.”
The following sections describe and demonstrate the use of these features.
3.4.1 Basic Operations
The Solaris Zones feature set includes both configuration tools and management tools. In the typical case, you will begin the configuration of a zone using one command. After you have configured the zone, Solaris stores the configuration information. Management operations, such as installing and booting the zone, are performed with another command; this section describes those commands.
3.4.1.1 Configuring an Oracle Solaris Zone
The first step in creating a zone is to configure it with at least the minimum information.
All initial zone configuration is performed with the zonecfg(1M) command, as illustrated in the following example. The first command merely shows that there are no non-global zones on the system yet.
GZ# zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / solaris shared
GZ# zonecfg -z myzone
myzone: No such zone configured
Use 'create' to begin configuring a new zone.
zonecfg:myzone> create
create: Using system default template 'SYSdefault'
zonecfg:myzone> exit
GZ# zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / solaris shared
- myzone configured /zones/roots/myzone solaris excl
GZ# zonecfg -z myzone info
zonename: myzone
zonepath: /system/zones/myzone
brand: solaris
autoboot: false
autoshutdown: shutdown
bootargs:
file-mac-profile:
pool:
limitpriv:
scheduling-class:
ip-type: exclusive
hostid:
tenant:
fs-allowed:
anet:
linkname: net0
lower-link: auto
...
The output from the info subcommand of zonecfg shows all of the global properties of the zone as well as some default settings. Table 3.5 lists most of the global properties and their meanings. Other properties are discussed in the subsections that follow.

A zone can be reconfigured after it has been configured, and even after it has been booted. However, any change in its configuration will not take effect until the next time that the zone boots unless you use the –r option with zoneadm, as described in the section “3.4.7.2 Live Zone Reconfiguration.” The next example changes the zone so that the next time the system boots, the zone boots automatically.
GZ# zonecfg -z myzone
zonecfg:myzone> set autoboot=true
zonecfg:myzone> exit
3.4.1.2 Installing and Booting the Zone
After you have configured the zone, you can install it, making it ready to run.
GZ# zoneadm -z myzone install
Preparing to install zone <myzone>.
Creating list of files to copy from the global zone.
Copying <7503> files to the zone.
Initializing zone product registry.
Determining zone package initialization order.
Preparing to initialize <1098> packages on the zone.
Initialized <1098> packages on zone.
Zone <myzone> is initialized.
The file </zones/roots/myzone/root/var/sadm/system/logs/install_log> contains a log of
the zone installation.
GZ# zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / native shared
- myzone installed /zones/roots/myzone native shared
During the installation process, zoneadm creates the file systems and directories required by the zone. Directories that contain system configuration information, such as /etc, are created in the zone’s file structure and populated with the default configuration files.
Zones boot much faster than virtual machines, mostly because there is so little to do. The global zone creates a zinit process that starts the zone’s Services Management Facility (SMF) and creates a few other processes. Those processes then spawn other processes that initialize the system’s services within the zone. At that point, the zone is ready for use.
GZ# zoneadm -z myzone boot
GZ# zoneadm list -cv
ID NAME STATUS PATH BRAND IP
0 global running / native shared
1 myzone running /zones/roots/myzone native shared
When first booting after installation, the zone needs system configuration information to complete this step; this information is usually collected by Solaris systems when you are installing Solaris. You can provide this information via the zlogin(1) command, which enables privileged global zone users to access a zone. With just one argument—the zone’s name—zlogin enters a shell in the zone as the root role. Arguments after the zone’s name are passed as a command line to a shell in the zone, and the output is displayed to the user of zlogin. One important option is -C, which provides access to the zone’s virtual console. A privileged user in the global zone can use that console whenever it is not already in use. The privilege to use zlogin can be granted either through Solaris RBAC, with the solaris.zone.login authorization, or with the delegated administration feature. For more information on the latter, see the section “3.4.7.1 Delegated Administration” later in this chapter.
The first time that the zone boots, it immediately issues its first prompt to the zone’s virtual console. After connecting to the virtual console, you might need to press Enter once to get a new terminal type prompt. After you respond to a short series of questions, the zone will reboot and is then ready for use.
Alternatively, instead of providing the system configuration information manually as just described, you could automate the configuration process. The first step in this process is to create a system configuration file; this file should then immediately be renamed so that you do not overwrite it the next time this automated process runs.
goldGZ# sysconfig create-profile –o /opt/zones
<questions and responses omitted>
goldGZ# mv /opt/zones/sc_profile.xml /opt/zones/web_profile.xml
The other commands are similar to the previous examples, but use the configuration profile that you just created. These two commands configure and install a new zone:
voyGZ# zonecfg –z web20 create
voyGZ# zoneadm –z web20 install –c /opt/zones/web_profile.xml
3.4.1.3 Halting a Zone
Not only does the zoneadm command install and boot zones, but it also stops them. Two methods exist to terminate these zones; one is graceful, and the other is not.
The shutdown subcommand gracefully stops the zone. Using it is the same as executing the following command:
GZ# zlogin myzone /usr/bin/init 0
The halt subcommand to zoneadm simply kills the processes in the zone. It does not run scripts that gracefully shut down the zone but, as you might suspect, it is faster than the shutdown command.
Figure 3.2 shows the entire life cycle of a zone, along with the commands you can use to manage one.

3.4.1.4 Modifying a Zone
Before installation of a zone, all of its parameters may be modified—both resources and properties. A zone may subsequently be modified after its installation is complete, and even later, after it has been running. Nevertheless, a few parameters, such as the brand, may not be modified after the zone has been installed. The rest of the parameters may be modified so that the changes to them will take effect the next time that the zone boots. To cause changes to parameters to take effect immediately, you must specifically indicate this preference by including the appropriate option to the zonecfg command. The section “3.4.7.2 Live Zone Reconfiguration” describes this type of modification.
Although the zonepath and rootzpool parameters may not be modified after the zone’s installation, a zone may be moved by using the zoneadm command. Moving a zone that uses a rootzpool will not move the contents of the zone, but rather will merely modify the zonepath.
The list of resources and properties that can be changed, for each type of zone, is listed on the brand-specific man page: solaris(5), solaris10(5), and solaris-kz(5).
3.4.1.5 Modifying Zone Privileges
Earlier in this chapter, we discussed Oracle Solaris privileges, including the fact that you can modify the set of privileges that a zone can have. If you change the privileges that a zone can have, you must reboot the zone before the changes will take effect. The following example depicts the steps to add the sys_time privilege to an existing zone:
GZ# zonecfg -z web
zonecfg:web> set limitpriv="default,sys_time"
zonecfg:web> exit
GZ# zoneadm -z web boot
3.4.2 Packaging
Solaris systems retrieve packages from a package repository. Native zones use the global zone’s “system repository” to access repositories. In essence, the global zone acts as a proxy, retrieving information and package content on behalf of the native zone. In addition, a zone can configure other publishers and obtain content from them. The system repository can proxy http, https, file-based repositories available to the global zone, and repository archives (.p5p files). The last option is the most convenient method to move and install a single custom package.
You can configure a global zone with a publisher that the global zone does not use, but that is used by its zones. For this scheme to work correctly, the global zone must be able to access the publisher. Such an approach may be very useful when multiple zones will install packages that the global zone should not install. If only one zone needs access to a publisher, it may be simpler to configure that access within the zone itself.
A native zone can see the global zone’s publisher configuration and, therefore, the configurations of the publishers it automatically accesses via the global zone. For example, in the global zone, the following output lists two publishers, neither of which is proxied:
jvictor@tesla:~$ pkg publisher -F tsv
PUBLISHER STICKY SYSPUB ENABLED TYPE STATUS URI PROXY
solaris true false true origin online http://pkg.oracle.com/solaris/release/ -
However, in a native zone, the same command distinguishes between publishers that use the global zone as a proxy (“solaris”) and publishers configured in the zone itself (“localrepo”). The latter might be an NFS mount, as shown in the second command here:
testzone:~# mount -F nfs repo1:/export/myrepo /mnt/localrepo
testzone:~# pkg set-publisher –g file:///mnt/repo localrepo
testzone:~# pkg publisher -F tsv
PUBLISHER STICKY SYSPUB ENABLED TYPE STATUS URI PROXY
localrepo true true true origin online file:///mnt/repo/ -
solaris true true true origin online http://pkg.oracle.com/solaris/release/ http://localhost:1008
A native zone accesses a system repository via two required services. One service, the zone’s proxy client, runs in the zone; its complete name is application/pkg/zones-proxy-client:default. The other service runs in the global zone: application/pkg/zones-proxyd:default. Both services are enabled automatically, but examination of their states may simplify the process of troubleshooting packaging problems in zones. A native zone cannot change the configuration of publishers that it accesses via the global zone.
Changing a global zone’s publishers also changes the repositories from which its zones get packages. For that reason, before you remove a publisher from the global zone’s list, you should confirm that its zones have not installed any packages from the soon-to-be-removed publisher. If the zone can no longer access that publisher, it will not be able to update the software, and it may not be able to uninstall that package.
3.4.3 Storage Options
Several options exist that specify the location of storage for the zone itself and the locations of additional storage beyond the root pool. Also, some options related to storage enable you to further restrict the abilities of a zone, thereby enhancing its security. These options are discussed in this section.
3.4.3.1 Alternative Root Storage
Instead of storing a zone in the global zone’s ZFS root pool, you can store it in its own zpool. Although that pool can reside on local storage, an even better option is to use remote storage that can be accessed by another Solaris computer. Ultimately, remote shared storage simplifies migration of zones.
The configuration of a zone onto shared storage requires only one additional configuration step: specifying the location of the storage. To configure the root pool storage for a zone, use zonecfg(1M) and its rootzpool resource. The storage can be any of these types, and different storage types can be mixed within one pool. Note, however, that mixing storage types can lead to adverse performance and has security implications. Currently, the following types of storage are supported:
![]() Direct device (e.g.,
Direct device (e.g., dev:dsk/c0t0d0s0)
![]() Logical unit (FC or SAS) (e.g.,
Logical unit (FC or SAS) (e.g., lu.name.naa.5000c5000288fa25)
![]() iSCSI (e.g.,
iSCSI (e.g., iscsi:///luname.naa.600144f03d70c80000004ea57da10001 or iscsi:///target.iqn.com.sun:02:d0f2d311-f703,lun.6)
For more details on those storage types and their specification, see the suri(5) man page.
Solaris will automatically create a ZFS pool in the storage area.
3.4.3.2 Adding File Systems
Access to several types of file systems may be added to a zone. Some of these types allow multiple zones to share a file system. This ability can be useful, but is vulnerable to two pitfalls: synchronization of file modifications and security concerns.
Storage managed by ZFS can be added in two different ways. The first approach is to mount a ZFS file system that exists in the global zone into a non-global zone. In the zone, this file system is simply a directory. The second method is to make a global zone file system appear to be a pool in a non-global zone.
The first method assumes that the ZFS file system rpool/myzone1 exists in the global zone. When the zone boots, its users will be able to access that file system at the directory /mnt/myzfs1. Processes running in the zone can access the storage available to the ZFS file system rpool/myzone.
GZ# zonecfg -z myzfszone
zonecfg:myzone> add fs
zonecfg:myzone:fs> set dir=/mnt/myzfs1
zonecfg:myzone:fs> set special=rpool/myzone1
zonecfg:myzone:fs> set type=zfs
zonecfg:myzone:fs> end
This method cannot be used to share files between zones. When this approach is used, if two zones are configured with the same ZFS file system, the first to boot will run correctly. An attempt to boot the second zone, however, will fail. Further, the file system will not be available to users in the global zone.
We recommend setting a quota on all file systems assigned to zones so that one zone does not fill up the pool and prevent other workloads from using the pool.
The second method assigns a ZFS data set to the zone. This method delegates administration of the data set to the zone. A privileged user in the zone can control attributes of the data set and create new ZFS file systems in it. That user also controls attributes of those file systems, such as quotas and access control lists (ACLs).
You can add a ZFS file system or volume to a zone as a ZFS pool. To the global zone, this resource appears to be a file system. Inside the zone, it appears to be a ZFS pool. Administration of the data set is delegated to the zone, so that a privileged user in the zone can control attributes of the data set and create new ZFS file systems in it. That user also controls attributes of those file systems, such as quotas and ACLs.
Although a privileged user in the zone can manage the data set from within, a global zone administrative user can manage the top-level data set, including setting a quota on it.
When using the zonecfg command, you supply the name of the data set as it is known in the global zone, along with an “alias”—the name of the zpool as seen in the zone. If you omit the alias, Solaris uses the final component of the file system name as the name of the pool.
GZ# zonecfg –z myzone
zonecfg:myzone> add dataset
zonecfg:myzone:dataset> set name=mypool/myfs
zonecfg:myzone:dataset> set alias=zonepool
zonecfg:myzone:dataset> end
zonecfg:myzone> exit
Regardless of the type of file system being used, any arbitrary directory that exists in the global zone can be mounted into a zone, with either read-only or read-write status. This step requires the use of a loopback mount, as shown in the next example for a different zone:
GZ# zonecfg -z myufszone
zonecfg:myzone> add fs
zonecfg:myzone:fs> set dir=/shared
zonecfg:myzone:fs> special=/zones/shared/myzone
zonecfg:myzone:fs> set type=lofs
zonecfg:myzone:fs> end
zonecfg:myzone> exit
In this example, the dir parameter specifies the global zone’s name for that directory. The special parameter specifies the directory name in the zone on which to mount the global zone’s directory.
A brief digression is warranted here: When managing zones, keep in mind the two different perspectives that are possible for all objects such as files, processes, and users. In the last example, a process in the global zone would normally use the path name /zones/shared/myzone to refer to that directory. A process in the zone, however, must use the path /shared.
Alternatively, a non-ZFS file system can be mounted into a zone so that only the zone can access it. Processes in other zones then cannot use that file system, and only privileged users in the global zone can access the file system. In the next example, dir has the same meaning as in the previous example, but special indicates the name of the block device that contains the file system. The raw property specifies the name of the raw device.
GZ# zonecfg -z myufszone
zonecfg:myzone> add fs
zonecfg:myzone:fs> set dir=/mnt/myfs
zonecfg:myzone:fs> set special=/dev/dsk/c1t0d0s5
zonecfg:myzone:fs> set raw=/dev/rdsk/c1t0d0s5
zonecfg:myzone:fs> set type=ufs
zonecfg:myzone:fs> end
zonecfg:myzone> exit
All of these mounts—ZFS, UFS, lofs, and others—are created when the zone is booted. For more information on the various types of file systems that can be used within a zone, see the Oracle Solaris 11 documentation.
3.4.3.3 Read-Only Zones
It seems that every month brings a news story describing the latest theft of personal or corporate data from supposedly secure computers. Solaris offers a diverse set of security features intended to prevent various types of attacks. One of these features is read-only, or “immutable,” zones.
Some attacks rely on the perpetrator’s ability to change the configuration of a system, or modify some of its system software. To thwart this type of attack, Solaris 11 Zones can be configured in such a way that the configuration, or the programs that make up Solaris, cannot be modified from within the zone, even by someone who was able to gain some or all of the privileges available within that zone.
Three choices are available for this kind of configuration, each of which specifies the Solaris files that are writable:
1. Only configuration files can be modified, including everything in /etc/*, /var/*, and root’s home directory /root/*. With this method, packages cannot be installed, and the configuration of syslog and the audit subsystem can be changed. This choice of configuration, which is intended to prevent an attacker from modifying commands and leaving Trojan horses, is named flexible-configuration.
2. Only content in /var/* may be modified, except for some directories that contain configuration information. This method prevents attacks that require changing passwords, adding users, changing network information, and more. It is named fixed-configuration.
3. No content in the root pool can be changed. This method prevents attacks that require modifying any parts of Solaris. Unfortunately, it may also prevent some software from functioning correctly, such as software that temporarily stores files in /var/tmp. This choice is named strict.
You can achieve this level of protection by adding just one line to the configuration:
GZ# zonecfg –z troy
zonecfg:troy> create
zonecfg:troy> set file-mac-profile=strict
zonecfg:troy> exit
These strategies raise a key question: If even a privileged user in a zone cannot change its configuration files, how can those files be changed when necessary? The Trusted Path feature enables a privileged user in the global zone to use the –T option to the zlogin command. With this feature, the user can modify files that cannot be modified from within the zone. To use this feature, a user either will need the Solaris RBAC authorization solaris.zone.manage/<zonename> or must be delegated the authorization named manage.
For more details on the latter strategy, see the section entitled “Delegated Administration” later in this chapter.
3.4.4 Resource Management
Resource management includes monitoring resource usage for the purpose of setting initial control levels, and modifying controls in the future to accommodate normal growth. The Solaris Zones feature set includes comprehensive resource management features, also called resource controls. These controls allow the platform administrator to manage those resources that are typically controlled in VEs. Use of these controls is optional, and most are disabled by default. We strongly recommend that you take advantage of these features, as they can prevent many problems caused by over-consumption of a resource by a workload. The following resources were mentioned in previous chapters:
![]() CPU capacity—that is, the portion of a CPU’s clock cycles that a VE can use
CPU capacity—that is, the portion of a CPU’s clock cycles that a VE can use
![]() Amount of RAM used
Amount of RAM used
![]() Amount of virtual memory or swap space used
Amount of virtual memory or swap space used
![]() Network bandwidth consumed
Network bandwidth consumed
![]() Use of kernel data structures—both structures of finite size and ones that use another finite resource such as RAM
Use of kernel data structures—both structures of finite size and ones that use another finite resource such as RAM
This section describes the resource controls available for zones. It also demonstrates the use of Solaris tools to monitor resource consumption by zones. You should apply these monitoring tools before attempting to configure the resource controls, so that you will clearly understand the baseline resource needs of each workload.
The zonecfg command is the most useful tool for setting resource controls on zones. By default, its settings do not take effect until the next time the zone boots, but a command-line option may be used to specify immediate reconfiguration of a running zone.
The zonestat(1M) command is a very powerful monitoring tool. It reports on both resource caps and resource usage. Examples are provided in the sections that follow.
Other useful commands that apply resource controls include prctl(1) and rcapadm(1M), both of which have an immediate effect on a zone. Resource control settings can also be viewed with the commands prctl, rcapstat(1), and poolstat(1M), in addition to zonestat.
Oracle Solaris 11 includes a wide variety of tools that report on consumption of specific resources, including prstat, poolstat(1M), mpstat(1M), rcapstat(1M), and kstat(1M). Many of these features can be applied to zones using command-line options or other methods. In addition, Oracle Enterprise Manager Ops Center was designed as a means to perform complete life-cycle management of both virtual and physical systems, including monitoring of resource consumption by the global zone and by individual zones. This section discusses only those tools that are included with Oracle Solaris 11. Chapter 7, “Automating Virtualization,” discusses OEM Ops Center and OpenStack, another virtualization life-cycle system.
One of the greatest strengths of Solaris Zones is common to most OSV implementations but absent from other forms of virtualization—namely, the ability of tools running in the management area to provide a holistic view of system activity, by aggregating all VEs, as well as a detailed view of the activity in each VE. The monitoring tools described in this section are widely used Solaris tools that provide either a holistic view, a detailed view, or options to obtain both views.
Oracle Solaris includes a text-based “dashboard” for Solaris Zones: zone-stat(1). Similar to other “stat” monitoring commands, zonestat takes an argument that sets the length of the interval(s) during which it collects data, reporting averages at the end of each interval. Without any other arguments, the output shows basic information.
GZ$ zonestat 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
SUMMARY Cpus/Online: 4/4 PhysMem: 31.8G VirtMem: 33.8G
----------CPU---------- --PhysMem-- --VirtMem-- --PhysNet—
ZONE USED %PART STLN %STLN USED %USED USED %USED PBYTE %PUSE
[total] 0.06 1.53% 0.00 0.00% 9200M 28.2% 6652M 19.2% 459 0.00%
[system] 0.00 0.00% - - 7710M 23.6% 4606M 13.3% - -
global 0.06 1.52% - - 1398M 4.29% 1972M 5.69% 459 0.00%
zone1 0.00 0.00% - - 91.0M 0.27% 73.6M 0.21% 0 0.00%
The output shown here has several components:
![]() An announcement that data is being collected
An announcement that data is being collected
![]() An announcement of the first interval report
An announcement of the first interval report
![]() The interval report itself, which includes:
The interval report itself, which includes:
![]() Data aggregated across the global zone and all zones
Data aggregated across the global zone and all zones
![]() Data limited to processes running in the global zone
Data limited to processes running in the global zone
![]() Data aggregated across each zone during the interval
Data aggregated across each zone during the interval
The section labeled “CPU” shows the amount of CPU time used for each entry, normalized to one CPU thread, as well as the portion of CPU time used compared to that available to the zone during that interval. The “PhysMem” and “VirtMem” sections provide data about RAM and virtual memory. The latter considers both RAM and swap space used, and compares them to the total amount configured. The final section, “PhysNet,” displays network data.
The zonestat monitoring command can be used with a plethora of options to produce final aggregated reports, details of individual groups of CPUs and network ports, both physical and virtual, and much more. Some of these options will be illustrated later in this chapter.
3.4.4.1 CPU Controls
Oracle Solaris offers multiple methods for controlling a zone’s use of CPU time. The simplest is Dynamic Resource Pools, which enable you to exclusively assign CPUs to a zone; the resulting set of CPUs is called a pool. Perhaps the most flexible means of CPU control is the Fair Share Scheduler (FSS). FSS allows multiple zones to share the system’s CPUs, or a subset of them, while ensuring that each zone receives sufficient CPU time to meet its service level agreement (SLA). Lastly, CPU caps enforce a maximum amount of computational ability on a zone. Although you can use a zone without any CPU controls, we recommend applying these controls to achieve consistent performance.
Dynamic Resource Pools
By default, all processes in all zones share the system’s processors. An alternative—Solaris Dynamic Resource Pools—ensures that a workload has exclusive access to a set of CPUs. When this feature is used, a zone is configured to have its own pool of CPUs for its exclusive use. Processes in the global zone and in other zones never run on that set of CPUs. This type of resource pool is called a temporary pool, because it exists only when the zone is running. Alternatively, it may be called a private pool, reflecting that those CPUs are dedicated (private) to just one zone and its processes.
A resource pool can be of fixed size, or it can be configured to vary in size within a range that you choose. In the latter situation, the OS will shift CPUs between pools as their needs change, as shown in Figure 3.3. Each CPU is assigned to either a (non-default) resource pool or the default pool. The default pool, which always exists, holds all CPUs that have not been assigned to other pools. CPUs in the default pool are used by global zone processes and processes in zones that are not configured to use a pool.

A private pool is not created until its zone boots. If sufficient CPUs are not available to fulfill the needs of the configuration, the zone will not boot, and a diagnostic message will be displayed instead. In that case, you must take one of the following steps to enable the zone to boot:
![]() Reconfigure the zone with fewer CPUs.
Reconfigure the zone with fewer CPUs.
![]() Reconfigure the zone to share CPUs with other zones.
Reconfigure the zone to share CPUs with other zones.
![]() Shift CPUs out of the private pools of other zones and into the default pool.
Shift CPUs out of the private pools of other zones and into the default pool.
![]() Move the zone to a system with sufficient CPUs.
Move the zone to a system with sufficient CPUs.
The simplest approach is to configure pools to have fixed size (e.g., 4 CPUs). A zone that uses a private, fixed-size pool will always be able to use all of the compute capacity of those CPUs. If you choose to use fixed-size pools, you can ignore the ability to dynamically adjust the sizes of the resource pools.
Other situations call for flexibility—specifically, the ability to automatically react to a change in processing needs. For example, consider Figure 3.3, which shows a 32-CPU system with a default pool of 4–32 CPUs and with zones named Web, App, and DB, which are configured with pools of 2–6 CPUs, 8–16 CPUs, and 8–12 CPUs, respectively. Solaris will attempt to assign the maximum quantity of CPUs to each pool, while leaving the default pool with its minimum quantity of CPUs. By default, the quantity of CPUs assigned to each pool is balanced within the configuration constraints.
In the example shown in Figure 3.3, the Web zone will get 6 CPUs, and the App and DB zones will each get 11 CPUs, leaving 4 CPUs for the default pool. After the zones have been running for a while, if the CPU utilization of a pool exceeds a configurable threshold, Solaris will automatically shift 1 CPU into it from an under-utilized pool.
Figure 3.4 shows graphs of CPU allocation and utilization for three different zones and the system’s default pool. As the workloads become more active, they need more processing capacity, and Solaris dynamically provides this resource as necessary.

For example, “Web CPUs” in Figure 3.4 is the number of CPUs configured in the Web zone’s pool as time passes. As the utilization of one pool grows so that it exceeds a configurable threshold, Solaris shifts a CPU into the pool. As the workload increases, Solaris shifts more CPUs until it has reached the maximum quantity configured for that pool, or until there are no more CPUs that can be shifted to the pool. After the utilization of a pool has decreased below the threshold for a suitably long period, Solaris shifts a CPU out of the zone’s pool and back into the default pool.
Note that the App zone’s pool and the DB zone’s pool have a minimum of 8 CPUs each. During at least some periods of time, these pools have excess capacity that other zones cannot use. Maintaining that excess capacity offers a notable benefit: Those zones can use that capacity instantly when they need it, without waiting for Solaris to shift a CPU to their own pools. In other words, they can react more quickly to changing needs for processor time.
Configuring Resource Pools
Configuring a zone to use a private pool is very easy, with a variety of options being available to increase the flexibility of this process. To dedicate two CPUs to a zone named web, run the following commands:
GZ# zonecfg -z web
zonecfg:web> add dedicated-cpu
zonecfg:web:dedicated-cpu> set ncpus=2
zonecfg:web:dedicated-cpu> end
zonecfg:web> exit
GZ# zoneadm -z web boot
The set of CPUs assigned to a zone using this method can be changed while the zone runs, using the live zone reconfiguration feature described later in this chapter.
Global zone administrators can view the current configuration of pools, and CPU usage relative those pools, with the zonestat command.
GZ# zonestat -r psets 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
PROCESSOR_SET TYPE ONLINE/CPUS MIN/MAX
pset_default default-pset 2/2 1/-
ZONE USED %USED STLN %STLN CAP %CAP SHRS %SHR %SHRU
[total] 0.48 16.2% 0.00 0.00% - - - - -
[system] 0.03 1.26% - - - - - - -
global 0.44 14.9% - - - - - - -
PROCESSOR_SET TYPE ONLINE/CPUS MIN/MAX
web dedicated-cpu 2/2 2/2
ZONE USED %USED STLN %STLN CAP %CAP SHRS %SHR %SHRU
[total] 0.00 0.09% 0.00 0.00% - - - - -
[system] 0.00 0.05% - - - - - - -
web 0.00 0.04% - - - - - - -
Note that the zone is associated with a processor set that contains the CPUs. It is possible to manually create a resource pool and assign one or more zones to that pool. The zonestat output would then show multiple zones in the listing for one processor set. This technique will not be explored in detail, as it is beyond the scope of this book.
To change the pool size so that it will be a dynamic quantity the next time the zone boots, you can run the following commands to allocate between two and four processors to the zone. The first command enables the service poold, which dynamically adjusts the pool size but is not needed for static pools. This service monitors resource pools that have been configured with a variable quantity of CPUs. It tracks CPU utilization of those pools and, if one is over-utilized, shifts a CPU to it from an under-utilized pool. If multiple pools are over-utilized, the importance parameter informs the OS of the relative importance of this pool compared to other pools.
GZ# svcadm enable pools/dynamic
GZ# zonecfg -z web
zonecfg:web> add dedicated-cpu
zonecfg:web:dedicated-cpu> set ncpus=2-4
zonecfg:web:dedicated-cpu> set importance=5
zonecfg:web:dedicated-cpu> end
zonecfg:web> exit
GZ# zoneadm -z web boot
The size of a pool can be changed while the zone runs by manually shifting CPUs from one pool to another. This step is performed by using the live zone reconfiguration feature described later in this chapter.
Until now we have ignored the meaning of the acronym “CPU” while describing features that address it, the CPU’s use, and the Solaris kernel’s interpretation of it. For decades, “CPU” meant the chip that ran machine instructions, one at a time. The operating system created a process, branched execution to it, and cleaned up when it was done. A multiprogramming OS ran one process for a small period of time, then switched the CPU to another process if one was ready to run.
Today, however, both multicore processors and multithreaded cores are available. Multicore processors are simply multiple CPUs implemented on a single piece of silicon, although some models provide some shared resources for those cores, such as shared cache. Multithreaded cores improve throughput performance by duplicating some—but not all—of a core’s circuitry within the core. To make the most of those hardware threads, the operating system must be able to efficiently schedule processes onto the threads, preferably with some knowledge of the CPU’s internal workings and memory architecture.
Oracle Solaris has a long history of efficiently scheduling hundreds of processes on dozens of processors, going back to the E10000 with its 64 single-core CPUs. Because of its scalability, Solaris was modified to schedule processes on any hardware thread in the system, maximizing the total throughput of the platform.
Unfortunately, this scheme can be a bit confusing when you are configuring resource pools, because each type of CPU has its own type and amount of hardware threading. Each CPU also has its own per-thread performance characteristics. Table 3.6 lists various CPUs that will run Oracle Solaris 11 and core and thread data. It also shows some sample systems.

Because Solaris identifies each hardware thread as a CPU, you can create very flexible resource pools. For example, on an Oracle T7-2, a SPARC-based computer with 2 CPU chips, you can create twelve 32-CPU pools and still have 128 CPUs left for the global zone! Most multithreaded CPUs have some shared cache, so if you want to optimize performance you should configure CPU quantities in multiples of 4 or 8, depending on the architecture of that CPU.
Certainly, all of that flexibility is very useful—but in many situations, other factors are even more important. Some workloads will run best if you configure the zone with one or more entire cores. Similar features enable you to choose specific cores by identification number. The psrinfo -t command displays the ID number of CPU threads, CPU cores, and CPU sockets. The following example shows the difference in syntax, and configures four cores for use by a zone:
GZ# zonecfg –z dbzone
zonecfg:dbzone> add dedicated-cpu
zonecfg:dbzone:dedicated-cpu> set cores=4-7
zonecfg:dbzone:dedicated-cpu> end
zonecfg:dbzone> exit
Variations of that feature allow you to choose specific hardware threads or entire CPU chips, which are called “sockets.”
Finally, the kernel does not enforce a limit on the total number of CPUs configured in different pools or zones until they are actually running. Thus you could configure and install ten 120-core zones on a T5-8 as long as you run only one zone at a time. Alternatively, you could configure and run 10 zones, each with 100 CPUs (threads). In other words, you can over-subscribe CPUs.
Fair Share Scheduler
The Fair Share Scheduler was discussed in Chapter 2, “Use Cases and Requirements.” FSS can control the allocation of available CPU resources among workloads based on the level of importance that you assign to them. This importance is expressed by the number of CPU shares that you assign to each workload. FSS compares the number of shares assigned to a particular workload to the aggregate number of shares assigned to all workloads. For example, if one workload has 100 shares and the total number of shares assigned to all workloads is 500, the scheduler will ensure that the workload receives at least one-fifth of the compute capacity of the available CPUs.
The last point is very important, as a key advantage of this CPU control mechanism over the other options is that it does not waste idle CPU cycles. With FSS, any workload can use idle CPU cycles as long as each workload receives its guaranteed minimum compute time. The FSS method does not force any process to wait if a CPU is available somewhere within the system, unlike the other methods of CPU control.
To use FSS with zones, you must first enable it for use across the Solaris instance. As is often the case, one command is needed to tell Solaris to change a specific setting the next time Solaris boots, and a different command is needed to tell Solaris to change its behavior immediately. The dispadmin(1M) command shown here changes the default scheduler to be used the next time that Solaris boots. The priocntl(1) command changes the default scheduler that Solaris is using now for all existing processes.
GZ# dispadmin -d FSS
GZ# priocntl -s -c FSS -i all
Once FSS has become the default scheduler, you must assign sufficient shares to the global zone to ensure that its processes get sufficient CPU time. Choose a value that is of the same magnitude as the values used for the other zones. Set a value with zonecfg for the next time the system boots. Also, use prctl to set a value for right now. The order of execution does not matter.
GZ# zonecfg -z global
zonecfg:web> set cpu-shares=100
zonecfg:web> exit
GZ# prctl -t privileged -n zone.cpu-shares -v 100 -i zone global
The next step is to allocate 100 cpu-shares to a zone, using the following command:
GZ# zonecfg -z web
zonecfg:web> set cpu-shares=100
zonecfg:web> exit
GZ# zoneadm -z web boot
After the zone is rebooted, this value can be queried with the following command:
GZ$ zonestat -r psets 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
PROCESSOR_SET TYPE ONLINE/CPUS MIN/MAX
pset_default default-pset 4/4 1/-
ZONE USED %USED STLN %STLN CAP %CAP SHRS %SHR %SHRU
[total] 1.15 38.6% 0.00 0.00% - - 2 - -
[system] 0.01 0.49% - - - - - - -
web 0.99 33.1% - - - - 100 50% 33.1%
global 0.14 4.92% - - - - 100 50% 5.2%
This resource constraint can also be changed dynamically for a running zone, using the live zone reconfiguration feature described later in this chapter.
Whenever share assignments are changed or zones using FSS are added or removed, the proportion of CPU time allowed for each zone changes to reflect the new total number of shares. The new proportions will be shown by zonestat.
A final note on efficiency and FSS: Although this method does not leave idle CPU cycles if a workload needs to use them, the presence of a large number of zones on a busy system will tax the scheduler. In this scenario, the scheduling algorithm will use a measurable amount of CPU cycles. On medium and large systems, dozens of running zones would be needed for this effect to be noticeable.
Oracle Solaris CPU Caps
The final CPU resource control available for zones is the CPU cap. You can use such a cap to tell Solaris that the processes of a specific zone should not be allowed to use more than a certain amount of CPU time, measured in terms of a CPU, over a small sampling period. This cap allows granularity to be specified in hundredths of a CPU—for example, 5.12 CPUs.
For example, to assign a CPU cap equivalent to 1.5 CPUs, use the following command:
GZ# zonecfg -z web
zonecfg:web> add capped-cpu
zonecfg:web:capped-cpu> set ncpus=1.5
zonecfg:web:capped-cpu> end
zonecfg:web> exit
GZ# zoneadm -z web boot
This value can be queried with the following command:
# zonestat -r psets 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
PROCESSOR_SET TYPE ONLINE/CPUS MIN/MAX
pset_default default-pset 4/4 1/-
ZONE USED %USED STLN %STLN CAP %CAP SHRS %SHR %SHRU
[total] 1.12 37.6% 0.00 0.00% - - 0 - -
[system] 0.01 0.51% - - - - - - -
web 0.99 33.1% - - 1.50 66.2% - - -
global 0.11 3.93% - - - - no-fss - -
Similarly, this resource constraint can be changed dynamically for a running zone, using the live zone reconfiguration feature described later in this chapter.
Unlike when dedicated CPUs are assigned to a zone, you can run several zones with CPU caps even if the sum of their caps exceeds the quantity of CPUs in the system. In other words, you can over-subscribe CPUs with this resource control.
You can combine a CPU cap with FSS to ensure that a zone receives a specific minimum amount of compute time, but no more than another specified amount. It does not make sense to apply both a CPU cap and a pool to a zone, and the kernel does not allow this kind of dual control.
CPU controls should be used to prevent one workload from using more CPU time than it should, either accidentally or intentionally as a result of a denial-of-service attack.
Choosing a CPU Control
Each of those CPU controls affects processing in different ways. Which one should you use? Every situation is different, but some general statements can be made about the conditions in which their use is optimal.
![]() Dedicated CPUs allow you to minimize software licensing costs for some software. Instead of licensing the software for all 384 CPU cores in a SPARC M6-32, for example, you may be able to assign a much smaller quantity (e.g., 16) to a zone and pay for only a 16-core software license. When configured correctly, dedicated CPUs also maximize the performance of the associated zone because its processes are more likely to return to the same CPU every time that CPU gets a time slice, thereby reducing the effects of cache eviction and maintaining data in memory attached to that CPU.
Dedicated CPUs allow you to minimize software licensing costs for some software. Instead of licensing the software for all 384 CPU cores in a SPARC M6-32, for example, you may be able to assign a much smaller quantity (e.g., 16) to a zone and pay for only a 16-core software license. When configured correctly, dedicated CPUs also maximize the performance of the associated zone because its processes are more likely to return to the same CPU every time that CPU gets a time slice, thereby reducing the effects of cache eviction and maintaining data in memory attached to that CPU.
![]() FSS is a good all-around CPU control, but has its limitations. All zones can access all of the CPUs, so there are never idle CPU cycles that cannot be used by a zone that is trying to use more—which is sometimes a problem with dedicated CPUs or a CPU cap. A new zone can be added without reassigning CPUs—a step that may be required when using dedicated CPUs. However, the FSS scheduling algorithm can consume an unacceptable amount of CPU time if dozens of zones’ processes must be scheduled.
FSS is a good all-around CPU control, but has its limitations. All zones can access all of the CPUs, so there are never idle CPU cycles that cannot be used by a zone that is trying to use more—which is sometimes a problem with dedicated CPUs or a CPU cap. A new zone can be added without reassigning CPUs—a step that may be required when using dedicated CPUs. However, the FSS scheduling algorithm can consume an unacceptable amount of CPU time if dozens of zones’ processes must be scheduled.
![]() A workload can achieve optimal performance if it can monopolize a CPU’s internal resources. This outcome can be achieved with dedicated CPUs, but not with FSS or a CPU cap.
A workload can achieve optimal performance if it can monopolize a CPU’s internal resources. This outcome can be achieved with dedicated CPUs, but not with FSS or a CPU cap.
![]() A CPU cap can be used to limit the amount of CPU time consumed by a zone, perhaps to enforce a contractual limit. It can also be applied to set reasonable user expectations among a small set of early users of a system. Otherwise, users may become accustomed to the response time they observe when they can use all of the CPUs in the system, only to be disappointed later by the system’s response time when they are sharing the CPUs with users added later.
A CPU cap can be used to limit the amount of CPU time consumed by a zone, perhaps to enforce a contractual limit. It can also be applied to set reasonable user expectations among a small set of early users of a system. Otherwise, users may become accustomed to the response time they observe when they can use all of the CPUs in the system, only to be disappointed later by the system’s response time when they are sharing the CPUs with users added later.
CPU Usage Monitoring Tools
In addition to zonestat, Oracle Solaris 11 includes some CPU monitoring tools that are available on most UNIX-like operating systems as well as some that are unique to Solaris. These tools include ps, prstat, poolstat, and mpstat. Some of these tools also include command-line options that are specific to zones.
For example, the ps command has two new options to help observe zones:
![]()
-Z: Adds a new column of output labeled ZONE (the name of the zone in which the process is running)
![]()
-z <name>: Limits the output to processes in the zone specified by <name>
The following example shows output from the ps command, limited to the processes in one zone. Notice that zsched has a parent PID of 1, which is the global zone’s init process. Also, note that zsched is the parent of the zone’s init process, and that the zone’s svc.startd and svc.configd services have been inherited by the global zone’s init process.
GZ# ps -fz myzone
UID PID PPID C STIME TTY TIME CMD
root 1076 1 0 18:15:15 ? 0:00 zsched
root 1089 1076 0 18:15:16 ? 0:00 /sbin/init
root 1091 1 0 18:15:16 ? 0:06 /lib/svc/bin/svc.startd
root 1093 1 0 18:15:16 ? 0:08 /lib/svc/bin/svc.configd
...
Of course, users of the zone can use the ps command. As mentioned earlier, the zlogin command can be issued from the global zone to run a program in the zone—in this case, ps -ef.
GZ# zlogin myzone ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1335 1331 0 15:22:51 ? 0:00 ps -fz myzone
root 1076 1076 0 18:15:15 ? 0:00 zsched
root 1089 1076 0 18:15:16 ? 0:00 /sbin/init
root 1091 1076 0 18:15:16 ? 0:06 /lib/svc/bin/svc.startd
root 1093 1076 0 18:15:16 ? 0:08 /lib/svc/bin/svc.configd
...
In the previous output, note that from within the zone, we are not allowed to know anything about the outside world. Even the PID number of the global zone’s init process remains hidden from us. The kernel replaces that forbidden information with safe information—in this case, the PID of the zone’s zsched process. Any process that would normally be inherited by init is, seemingly, inherited by zsched. Note also that the parent PID of zsched is hidden—through the display of a PPID equal to its PID!
The -Z option adds the ZONE column to the ps output. This column is very helpful when you are trying to understand the relationship between processes and the zone with which they are associated.
GZ# ps -efZ
ZONE UID PID PPID C STIME TTY TIME CMD
global root 0 0 0 15:24:18 ? 0:25 sched
global root 1 0 0 15:24:20 ? 0:00 /sbin/init
...
myzone root 1076 1 0 18:15:15 ? 0:00 zsched
global root 1075 1 0 18:15:15 ? 0:00 zoneadmd -z myzone
global root 1500 1042 0 21:46:19 pts/3 0:00 ps -efZ
3.4.4.2 Memory Controls
Zones also offer several memory controls. Each control can be configured separately, or various controls can be used in combination. Some memory controls constrain the use of a physical resource, such as the RAM cap or the virtual memory cap. The latter is actually a physical resource despite its name—it is the sum of RAM and swap space.
Other memory controls limit the use of special types of memory resources that the kernel allocates, including locked memory and shared memory. The virtual memory system does not page those memory pages out to the swap device. If one zone allocates a large amount of locked memory or shared memory, it can prevent other zones from allocating sufficient memory to run well. The ability to lock down pages must be limited to prevent one zone from locking down all of its memory pages, thereby potentially starving other zones and preventing them from using RAM. This feat can be accomplished through the proper use of resource controls.
Virtual Memory Tools
A virtual memory cap prevents one zone from using more swap space than it should. Over-utilization of this resource can happen when a workload grows too quickly or when an application “leaks” memory. It can also result from a denial-of-service attack that tries to starve the system of swap space. A system that runs out of swap space has few options for recovering from this state: It will either crash, stop itself gracefully, or forcefully halt processes in an attempt to free up swap space.
The virtual memory cap that can be assigned to each zone is called a “swap cap.” That name is a bit misleading, because it really limits the amount of virtual memory—that is, the allocated physical RAM plus swap disk. The following command can be used to limit a zone to 4 GB of virtual memory:
GZ# zonecfg -z web
zonecfg:web> add capped-memory
zonecfg:web:capped-memory> set swap=4g
zonecfg:web:capped-memory> end
zonecfg:web> exit
GZ# zoneadm -z web boot
After the zone has been rebooted, the processes running in that zone will be able to use only 4 GB of virtual memory, in aggregate. The first attempt by one of those processes to use more virtual memory will fail with the same error code that appears when all virtual memory has been exhausted on a system:
web# ls
bash: fork: Not enough space
In essence, an application in that zone will behave as if it is running on a nonvirtualized system that has exhausted its virtual memory by filling up the swap partitions. Unfortunately, some applications do not handle this condition gracefully. For this and other reasons, caution should be used to avoid this situation in normal operating situations. Choosing a reasonable quantity for this cap is similar to sizing swap space for a non-virtualized system.
Because this kind of cap on virtual memory is an administrative constraint, you can configure zones to have an aggregate cap larger than the amount of VM configured in the system. In other words, you can over-subscribe the swap cap.
This limit can also be changed while the zone is running. For more information, see the section “Live Zone Reconfiguration” later in this chapter.
Virtual Memory Usage Monitoring Tools
You can monitor the amount of virtual memory used by each zone with the zone-stat command.
$ zonestat -r memory 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
...
VIRTUAL-MEMORY SYSTEM MEMORY
vm_default 33.8G
ZONE USED %USED CAP %CAP
[total] 6917M 19.9% - -
[system] 4671M 13.4% - -
global 2099M 6.06% - -
zone1 73.6M 0.21% - -
web 73.4M 0.21% 16.0G 0.44%
The amount of virtual memory used by a zone is shown in the “CAP” column. In the same output, the “USED” column shows the amount of RAM used by the zone’s processes. Notice how little RAM and virtual memory zones need.
Physical Memory Tools
Other zones, including the global zone, will not be directly affected if one zone has reached its virtual memory cap. Nevertheless, they might be affected if most or all of the RAM is consumed as a side effect. Whether there is a shortage of virtual memory or not, the over-consumption of RAM will cause excessive paging, which might affect all zones on the system.
To protect against over-consumption of RAM by one zone, you can establish a memory cap for physical memory. To add a memory cap to the zone configured earlier, enter the following command:
GZ# zonecfg -z web
zonecfg:web> select capped-memory
zonecfg:web:capped-memory> set physical=2g
zonecfg:web:capped-memory> end
zonecfg:web> exit
GZ# zoneadm -z web reboot
We used select in that example instead of add because a capped-memory entry was added in the previous example.
Physical Memory Usage Monitoring Tools
You can monitor the amount of virtual memory used by each zone with the zonestat command.
$ zonestat -r memory 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
PHYSICAL-MEMORY SYSTEM MEMORY
mem_default 31.8G
ZONE USED %USED CAP %CAP
[total] 9345M 28.6% - -
[system] 7648M 23.4% - -
global 1513M 4.64% - -
web 92.6M 0.28% 2048M 4.52%
Alternatively, you can modify this physical memory cap while the zone is running. For more information, see the section “3.4.7.2 Live Zone Reconfiguration” later in this chapter.
How should the OS enforce a RAM cap? If a process running in a memory-capped zone attempts to exceed its memory usage limit, the application behavior should be consistent with the application behavior in a non-virtualized system with insufficient RAM. In other words, the OS should begin forcing memory pages out to swap disk. Other than the performance penalty of paging, this action should be transparent to the application. However, performance would become inconsistent if the application was temporarily suspended while memory pages were paged out. Because paging takes time, it should be possible for the application to continue to allocate RAM while the pager tries to catch up. The operation of enforcing the cap must be asynchronous.
An optional feature of Oracle Solaris is the resource capping daemon, a program called rcapd(1M). One of its objectives is to limit the amount of RAM that a zone’s processes can use at one time. If a zone’s processes begin to use more memory than the physical memory cap that has been specified for that zone, rcapd will begin to force memory pages associated with that zone out to swap disk. To maintain consistency with non-capped behavior, the application is allowed to continue running while paging occurs. As a result, a zone’s processes may temporarily exceed its physical memory cap.
As with the virtual memory cap, this memory cap does not reserve space for a zone. Because no RAM is wasted waiting for a zone to use it, you can over-subscribe this cap.
Care should be taken when setting this cap. Caps that are set too low will cause excessive paging, which can drag down overall system performance. This outcome is especially likely if other zones are also causing paging or are using the same disk or storage I/O connection.
Also, the program that enforces the RAM cap, rcapd, uses some CPU cycles to track the amount of memory used by the various processes. This overhead will become noticeable on larger systems with hundreds of processes or millions of memory pages in use.
If you use the resource capping feature, you should monitor the amount of work that the kernel performs to manage these caps. You can use the rcapstat command with its -z option to accomplish this goal:
GZ# rcapstat -z 5
id zone nproc vm rss cap at avgat pg avgpg
1 ProdWeb1 30 0K 0K 8G 0K 0K 0K 0K
1 ProdWeb1 - 644M 454M 8G 0K 0K 0K 0K
1 ProdWeb1 - 966M 908M 8G 0K 0K 0K 0K
1 ProdWeb1 - 1610M 1362M 8G 0K 0K 0K 0K
1 ProdWeb1 - 2568M 1702M 8G 0K 0K 0K 0K
This output shows that the zone never uses more than roughly 2.5 GB of RAM, an amount well under the cap of 8 GB. If any paging activity (values greater than zero) appears in the four columns on the right, their presence indicates that the zone’s processes are paging. A small amount of infrequent paging is normal for operating systems that manage virtual memory, but frequent paging, or infrequent paging of large amounts of memory, is a sign of a problem. In those situations, the zone is using more RAM than you expected, either because there is a problem with the workload or because you chose a value that is too low for normal operations.
Another Solaris command that can report information on a per-processor-set basis is vmstat. The default output reports basic paging activity, which is collected separately for each processor set. If you run vmstat in a zone, the paging activity reported is that of the processors in the zone’s processor set.
The -p option to vmstat reports details of paging activity. When that option is used with vmstat in a zone that is running in a processor set, the paging activity information reported is that of the zone’s processors.
Another tool for providing visibility into per-zone paging is zvmstat, a tool found in the DTrace Toolkit.2 Its output provides similar information to the vmstat command, but the data is aggregated per zone. This tool also displays the amount of paging for each type of page:
2. The DTrace Toolkit can be found in /usr/dtrace/DTT.
![]() Executable: program binary
Executable: program binary
![]() Anonymous: memory allocated by the program
Anonymous: memory allocated by the program
![]() File: memory pages that represent portions of a file
File: memory pages that represent portions of a file
GZ# zvmstat 3
ZONE re mf fr sr epi epo epf api apo apf fpi fpo fpf
global 43 431 1766 16760 65 0 678 0 378 378 1 4 710
myzone 0 1 0 0 0 0 0 1 0 0 0 0 0
myzone2 0 0 0 0 0 0 0 0 0 0 0 0 0
ZONE re mf fr sr epi epo epf api apo apf fpi fpo fpf
global 0 0 4 0 0 0 0 0 0 0 0 4 4
myzone 25 276 0 0 5 0 0 45 0 0 57 0 0
myzone2 0 0 0 0 0 0 0 0 0 0 0 0 0
ZONE re mf fr sr epi epo epf api apo apf fpi fpo fpf
global 0 1 12 0 0 0 0 1 0 0 0 12 12
myzone 1 17 0 0 0 0 0 10 0 0 0 0 0
myzone2 0 0 0 0 0 0 0 0 0 0 0 0 0
Shared Memory and Locked Memory Tools
Some applications use shared memory so that multiple processes can access one set of data. For example, database software uses shared memory to store table indexes. If that data is paged out to disk, database performance will be severely affected. When applications use shared memory pages via Solaris OSM (Optimized Shared Memory), ISM (Intimate Shared Memory), or DISM (Dynamic ISM), those memory pages are locked into memory and cannot be paged out by the operating system.
In some cases, overly aggressive software might use more shared memory than is appropriate. Also, this functionality might be used to craft a denial-of-service attack. Although a RAM cap will prevent some of these problems, the design of virtual memory systems is based on the assumption that most of a workload’s memory pages can be paged out.
Under normal operations, a workload that needs 30 GB of RAM in a 32 GB system may need to lock down only 2 GB. Allowing its processes to lock all 30 GB may reduce the RAM available to other zones to the point that they cannot function normally. To prevent a zone from hoarding so much shared memory that other workloads begin to suffer from deprivation, a resource cap for shared memory can be established. Enter the following command to set a shared memory cap of 2 GB for the zone:
GZ# zonecfg -z web
zonecfg:web> set max-shm-memory=2g
zonecfg:web> exit
GZ# zoneadm -z web reboot
Just as with the other examples, this resource constraint can be changed dynamically for a running zone, using the live zone reconfiguration feature described later in this chapter.
In addition to shared memory, a program can lock down other memory pages. Oracle Solaris provides this functionality for well-behaved applications so as to improve their performance. Of course, this ability can be abused—just as shared memory can be. To limit the amount of memory that a zone can lock down, enter the following command:
GZ# zonecfg -z web
zonecfg:web> select capped-memory
zonecfg:web:capped-memory> set locked=2g
zonecfg:web:capped-memory> end
zonecfg:web> exit
GZ# zoneadm -z web boot
This resource constraint can also be changed dynamically for a running zone, using the live zone reconfiguration feature.
Because the proc_lock_memory privilege is included in a zone’s default privilege set, we strongly encourage the use of this memory cap.
Monitoring Shared Memory and Locked Memory
The zonestat commands makes it easy to monitor the use of shared and locked memory:
$ zonestat -r shm-memory 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
SHM_MEMORY SYSTEM LIMIT
system-limit -
ZONE USED %USED CAP %CAP
[total] 9984K 0.00% - -
[system] 0 0.00% - -
global 9984K 0.00% - -
web 0 0.00% 2048M 0.00%
To monitor locked memory:
$ zonestat -r memory 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
...
LOCKED-MEMORY SYSTEM MEMORY
mem_default 31.8G
ZONE USED %USED CAP %CAP
[total] 4635M 14.2% - -
[system] 4431M 13.6% - -
global 204M 0.62% - -
web 0 0.00% 2048M 0.00%
3.4.4.3 Miscellaneous Controls
One method that is notorious for over-consuming system resources is a fork bomb. This method does not necessarily consume a great deal of memory or CPU resources, but rather seeks to use up all of the process slots in the kernel’s process table. Software bugs can wreak similar havoc. Because non-global zones share the Solaris kernel, processes in one zone can fill the process table and affect other zones. Two related resource controls exist to forestall these situations.
The first cap is named max-processes. By default, a zone may create an unlimited number of processes. If you wish to prevent this kind of behavior, you can set this cap to a value that is higher than the number of processes that would normally be used.
A simple zone may have only approximately 25 processes. One or two users, or a simple application, may use only a few more processes. Thus, a cap of 100 processes may be reasonable, as shown in the following example:
GZ# zonecfg -z web
zonecfg:web> set max-processes=100
zonecfg:web> exit
GZ# zoneadm -z web reboot
In Oracle Solaris, a running process starts with just one thread of execution, also called a lightweight process (LWP). Many programs generate new software threads, becoming multithreaded processes. By default, Solaris systems can run more than 85,000 LWPs simultaneously. By comparison, a zone that has booted but is not yet running any applications may have as few as 75 LWPs. To prevent a zone from creating too many LWPs, a limit can be set on their use. The following command sets a limit of 300 LWPs for the zone:
GZ# zonecfg -z web
zonecfg:web> set max-lwps=300
zonecfg:web> exit
GZ# zoneadm -z web reboot
This parameter should not be set so low that the limit interferes with normal operation of the application. Instead, you should identify an accurate baseline for the number of processes and LWPs for a given zone, and then set this variable at an appropriate level. These resource constraints can also be changed dynamically for a running zone.
Unless you trust the users of the zone and their applications, we encourage the use of these caps to minimize the impact of fork bombs.
The number of processes and LWPs can be monitored with zonestat:
$ zonestat -r processes,lwps 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
PROCESSES SYSTEM LIMIT
system-limit 29.2K
ZONE USED %USED CAP %CAP
[total] 166 0.54% - -
[system] 0 0.00% - -
global 147 0.49% - -
web 19 0.06% 200 9.50%
LWPS SYSTEM LIMIT
system-limit 2047M
ZONE USED %USED CAP %CAP
[total] 1022 0.00% - -
[system] 0 0.00% - -
global 956 0.00% - -
zone1 66 0.00% 400 16.5%
In this example, the Web zone currently has 19 processes and 66 LWPs. These values will change as processes are created or exit. They should be inspected over a period of time to establish a more reliable baseline and updated when the software, requirements, or workload changes.
To maximize the benefits obtained by applying these controls, you should pair them with a CPU control—for example, FSS or resource pools. Implementation of such a control will slow the rate of process and LWP creation. Sufficient CPU power must be available to global zone processes so that the platform administrator can fix the problem.
3.4.4.4 DTrace and Holistic Observability
DTrace is a feature set of Oracle Solaris that enables you to gather specific or aggregated data that is available to the kernel. Short DTrace commands or scripts specify the individual pieces of data or aggregations of data that you wish to see. DTrace collects only the requested data, and then presents it to you. This parsimonious behavior minimizes the amount of CPU time that the kernel spends gathering the data you want. The design of DTrace makes it inherently safe to use: It is impossible to create an infinite loop in DTrace, and it is impossible to dereference an invalid pointer. For these and other reasons, it is safe to use DTrace on production systems. In contrast, you should not use the typical kernel debugger on live kernels.
OSV implementations include just one OS kernel, which is shared by all of the VEs. This facet of the OSV model enables you to use OS tools such as DTrace to look at all of the VEs as entities, or to peer into each VE and view its constituent parts.
Earlier, we saw how we could use DTrace to examine aggregate memory usage, with the zvmstat script. You can also use DTrace to gather and report data for a single zone. For example, if the output of the vmstat command revealed an unusually high system call rate, you could use these DTrace commands to determine which zone is causing these calls, which system call is being made the most often, and which program is issuing these calls.
GZ# dtrace -n 'syscall:::entry { @num[zonename] = count(); }'
dtrace: description 'syscall:::entry' matched 234 probes
^C
appzone 301
global 11900
webzone 91002
GZ# dtrace -n 'syscall:::entry/zonename=="webzone"/
{ @num[probefunc] = count(); }'
dtrace: description 'syscall:::entry' matched 234 probes
^C
exece 1
fork1 1
...
fstat6 9181
getdents64 9391
lstat64 92482
GZ# dtrace -n 'syscall::lstat64:entry/zonename=="webzone"/
{ @num[execname] = count(); }'
dtrace: description 'syscall::lstat64:entry' matched 1 probe
^C
find 107277
GZ# dtrace -n 'syscall::lstat64:entry/zonename="webzone" &&
execname=="find"/ { @num[uid] = count(); }'
dtrace: description 'syscall::lstat64:entry' matched 1 probe
^C
1012 16439
Based on the preceding output, we know that the user with UID 1012 was running the find program in zone webzone, which was causing most of those system calls.
When used in combination, DTrace and Solaris Zones can solve problems that are otherwise difficult or impossible to solve. For example, when troubleshooting a three-tier architecture, you might want to create a chronological log of events on the three different systems. Each system has its own clock, making this feat impossible to accomplish. To gather the needed data, you could re-create the three tiers as three zones on the same system. Because the three zones would then share the kernel’s clock, a DTrace script could collect data on the processes in the three different tiers, using a single time reference.
3.4.4.5 Resource Management Summary
Oracle Solaris offers an extensive set of resource management controls and tools to monitor resource consumption, enabling you to manage workload performance in high-density consolidated environments.
3.4.5 Networking
Almost all zones need access to a network to be useful. A zone can have network access via one or more of the computer’s physical network ports (NICs). Usually, multiple zones share that access by using virtual NICs (VNICs)—a new feature in Solaris 11.
By default, a non-global zone is given exclusive access to networking, an approach called “exclusive IP.” Exclusive IP not only maximizes network isolation between zones, but also limits the control that the global zone can exert over a zone’s networking. Further, the default configuration is one VNIC per zone, which enables many zones to share a physical NIC, while still controlling their own network stack. With this configuration, after a zone boots, it can implement its own network configuration, including IP address, default router, and more.
Instead of accepting this default, you can configure a zone to have exclusive access to one or more physical NICs, or shared access to one or more NICs or VNICs. An administrator in the global zone controls the network configuration for a zone that uses the “shared IP” model.
3.4.5.1 Introduction to Virtual Networks
In 2011, Solaris introduced an extensive set of virtual networking features, including VNICs and IPoIB datalinks, virtual switches (vSwitches), and the ability to create virtual routers. These features may be combined in arbitrary architectures, such as the one shown in Figure 3.5. (A complete description of the virtual networking features can be found in the Oracle Solaris documentation.)

Solaris Zones were modified to use these features. An “automatic network” (anet) resource specifies properties for a VNIC or IPoIB data link that will be created automatically by Solaris when the zone boots; this link is also automatically destroyed when the zone stops. The anet resource includes a comprehensive set of properties that give you the ability to configure the following items:
![]() A name for the VNIC;
A name for the VNIC; net0 is the default
![]() A physical NIC; by default, Solaris chooses an appropriate one at boot time
A physical NIC; by default, Solaris chooses an appropriate one at boot time
![]() A list of IP addresses that the zone can use; limited to shared-IP zones
A list of IP addresses that the zone can use; limited to shared-IP zones
![]() A default router
A default router
![]() Whether MAC address spoofing or IP address spoofing should be prevented
Whether MAC address spoofing or IP address spoofing should be prevented
![]() The method that Solaris should use to choose a MAC address for this link
The method that Solaris should use to choose a MAC address for this link
![]() A VLAN address
A VLAN address
![]() Numerous quality of service (QoS, or COS) properties, including a cap on bandwidth that this link can consume
Numerous quality of service (QoS, or COS) properties, including a cap on bandwidth that this link can consume
![]() Properties to control software-defined networking
Properties to control software-defined networking
![]() InfiniBand properties
InfiniBand properties
By using these properties, a privileged user in the global zone can control the amount of freedom that a zone has to choose its network configuration.
3.4.5.2 Exclusive-IP Zones
Because exclusive-IP zones manage their own networking configuration, few parameters are needed to configure them. Specifically, the zone configures the IP parameters. For many situations, there is no need to specify networking properties within zonecfg. The following list shows a subset of the default settings:
linkname: net0
lower-link: auto
defrouter not specified
link-protection: mac-nospoof
mac-address: random
auto-mac-address: 2:8:20:bd:af:42
A default configuration includes one VNIC, named net0, which will be connected to an appropriate global zone NIC when the zone boots. The zone must configure its own IP address and default router, or retrieve that information from a DHCP server. A random MAC address was chosen for this zone by Solaris, and that address will be used each time the zone boots.
You can manage networking in an exclusive-IP zone with the same methods and commands as you would use in a non-virtualized system. To perform those steps, you must first log in to the zone as a privileged user.
The following example adds a second VNIC that uses a specific NIC.
GZ# zonecfg -z zone1
zonecfg:zone1> add anet
zonecfg:zone1:anet> set linkname=net1
zonecfg:zone1:anet> set lower-link=net3
zonecfg:zone1:anet> set maxbw=100m
zonecfg:zone1:anet> info
anet 1:
linkname: net1
lower-link: e1000g0
defrouter not specified
maxbw: 100m
allowed-dhcp-cids not specified
link-protection: mac-nospoof
mac-address: auto
...
zonecfg:zone1:anet> end
zonecfg:zone1> exit
As you might expect, you can monitor network usage of individual NICs with the zonestat command.
GZ$ zonestat -r network –n net3 3
Collecting data for first interval...
Interval: 1, Duration: 0:00:03
NETWORK-DEVICE SPEED STATE TYPE
net3 1000mbps up phys
ZONE TOBYTE MAXBW %MAXBW PRBYTE %PRBYTE POBYTE %POBYTE
[total] 44.6K - - 28.4K 0.00% 13.5K 0.00%
zone1 42.5K 100m 0.3% 28.4K 0.00% 13.5K 0.00%
global 1168 - - 0 0.00% 0 0.00%
The non-obvious columns in this output are described here:
![]() TOBYTE: the number of bytes sent or received by that zone
TOBYTE: the number of bytes sent or received by that zone
![]() PRBYTE: the number of bytes received that used physical bandwidth
PRBYTE: the number of bytes received that used physical bandwidth
![]() %PRBYTE: PRBYTE, as a percentage of the available bandwidth
%PRBYTE: PRBYTE, as a percentage of the available bandwidth
![]() POBYTE: the number of bytes sent that used physical bandwidth
POBYTE: the number of bytes sent that used physical bandwidth
![]() %POBYTE: POBYTE, as a percentage of the available bandwidth
%POBYTE: POBYTE, as a percentage of the available bandwidth
3.4.5.3 Shared-IP Zones
Many situations call for network configuration within a zone. Centralized network management is appropriate for other zones, such as a group of horizontally scaled web servers with identical configurations. Centralized management calls for shared-IP zones.
All network controls, including routing, for shared-IP zones are managed from the global zone. Exclusive-IP zones manage their own networking configuration, including the assignment of IP addresses, routing table management, and bringing their network interfaces up and down.
Configuring network access for a shared-IP zone begins with removal of the anet resource, because such resources are not allowed in a shared-IP zone:
GZ# zonecfg -z myzone
zonecfg:myzone> remove anet 0
zonecfg:myzone> set ip-type=shared
zonecfg:myzone> add net
zonecfg:myzone:net> set physical=e1000g0
zonecfg:myzone:net> set address=192.168.4.4
zonecfg:myzone:net> set defrouter=192.168.1.1
zonecfg:myzone:net> end
zonecfg:myzone> exit
You can use the same syntax to add access to additional NICs.
3.4.5.4 Highly Available Networking
Oracle Solaris 11 offers several methods to combine multiple network ports so as to achieve continued network access in the face of port failure (high availability), increased network bandwidth, or both. This section discusses the newest option, Data Link Multipathing (DLMP). DLMP is simpler than IP Multipathing (IPMP), and offers more flexibility than trunking.
DLMP combines two or more physical NICs into one “aggregation.” VNICs can be created on top of the aggregation. Each VNIC uses one NIC, but if a failure occurs, any VNIC assigned to it is automatically assigned to a different NIC.
The following commands create a DLMP aggregation and modify a zone so that its network port, net0, uses the aggregation instead of using a NIC that is chosen when the zone boots:
GZ# dladm create-aggr -m dlmp -l net0 -l net1 -l net2 aggr0
GZ# zonecfg –z web01
zonecfg:web01> select anet 0
zonecfg:web01:anet> set lower-link=aggr0
zonecfg:web01:anet> end
zonecfg:web01> exit
3.4.5.5 Networking Summary
The default network type (exclusive IP) is appropriate unless network management of multiple zones should be centralized in the global zone. The addition of virtual network features to Solaris 11 greatly expands the most desirable network configurations.
3.4.6 Direct Device Access
The security boundary around a zone prevents direct access to devices, because many types of direct device access allow one zone to affect other zones. One means of enforcing these boundaries is to establish a minimal list of device entries available to the zone. By default, a zone has very few entries in its /dev directory, and it does not have a /devices directory at all. The entries in /dev are limited to pseudo-devices that are considered safe and necessary, such as /dev/null.
Sometimes, however, you might want to give a zone direct access to a device. For example, you might want to test some software in a zone in a lab environment, but the test might require creating and destroying a UFS file system from within the zone. To do this, the zone needs device entries for the disk device that will contain the file system. You can accomplish this task with the add device subcommand, as shown in the following example:
GZ# zonecfg -z zone1
zonecfg:zone1> add device
zonecfg:zone1:device> set match=/dev/rdsk/c1t0d0s6
zonecfg:zone1:device> end
zonecfg:zone1> add device
zonecfg:zone1:device> set match=/dev/dsk/c1t0d0s6
zonecfg:zone1> end
GZ# zlogin zone1
zone1# newfs /dev/rdsk/c1t0d0s6
zone1# mount /dev/dsk/c1t0d0s6 /opt/local
The direct device method gives a zone’s privileged users direct control over a file system’s devices, thereby facilitating direct management of the file system. At the same time, these users gain greater control over the system’s components, which may enable them to affect other zones. For example, just as the root user in a non-virtualized system can use device access to panic a UNIX system, so assigning direct device access to a zone may give users the ability to panic the system, stopping all of the zones. Also, enabling two zones to access one device may cause data corruption, and may have the unintended effect of creating a covert communication channel. Be very cautious when adding devices to a zone.
Because of the potentially negative implications of direct device access, you should use a different method, when possible, to achieve a similar goal. For example, instead of implementing direct access to storage devices, you might provide access to a ZFS pool with the zpool or rootzpool storage resources.
Finally, many third-party devices require device drivers that are not delivered with Solaris. The installation of these drivers must be performed in the global zone.
3.4.7 Virtualization Management Features
Life-cycle management of zones involves very few commands. You have already seen the two commands used to create, boot, and halt a zone. One of them, zoneadm, is also used to move a zone’s root directory within the same system, and to move the zone to a different system.
In addition to the zoneadm subcommands discussed earlier, other features provide additional flexibility and abilities when working with zones. Some of these features are discussed in this section. The first, delegated administration, gives otherwise unprivileged users the ability to manage one or more zones. The second, live zone reconfiguration, enables privileged users to modify a zone while it runs. Following that, we describe other features that can be used to simplify and accelerate the provisioning of zones.
3.4.7.1 Delegated Administration
Many situations call for one or more of a system’s zones to be managed by someone who does not manage the system as a whole. For these situations, Solaris offers the ability to delegate administration of those zones to an otherwise unprivileged Solaris user of the global zone. That user becomes a “zone administrator,” who is able to interact with a zone directly from the global zone. There are no limits on the quantity of zones that one user can manage, and no limit on the number of users who can manage a zone.
Several distinct types of operations can be delegated to a zone administrator (ZA). These responsibilities can be combined so that all of the operations are delegated to the ZA.
The simplest type of delegation enables a ZA to log into the zone by using the zlogin(1) command. This command creates a shell process running in the zone as the root user, or as the zone’s user when specified with the -l option.
A privileged global zone user can configure this delegation for the ZA with zonecfg:
GZ# zonecfg –z myzone
zonecfg:myzone> add admin
zonecfg: myzone:admin> set user=jeff
zonecfg: myzone:admin> set auths=login
zonecfg: myzone:admin> end
zonecfg: myzone > exit
The ZA can then use zlogin:
jeff$ pfexec zlogin –l zoneuser myzone
Another authorization option is “manage,” which enables the ZA to use the management features of the zoneadm(1M) command, including booting and halting the zone, and many others.
GZ# zonecfg –z myzone
zonecfg:myzone> add admin
zonecfg: myzone:admin> set user=jeff
zonecfg: myzone:admin> set auths=manage
zonecfg: myzone:admin> end
zonecfg: myzone > exit
The ZA can then use zoneadm:
jeff$ pfexec zoneadm –z myzone reboot
Table 3.7 lists all of the possible authorizations and the abilities that they give to a ZA:

3.4.7.2 Live Zone Reconfiguration
One advantage of virtual environments relative to physical systems is the ease of modifying the configuration. Entering commands to change the configuration of a virtual network is much easier than recabling a physical network. Not only does this ability reduce complexity, but it also opens up the possibility of modifying a configuration while the workload runs.
Solaris offers you the ability to make a temporary configuration change to a running zone, or to make a persistent change that will take effect only after the zone boots again. If you want the change to take effect immediately and then also during the next boot, you must perform both steps. With this feature, called live zone reconfiguration, you can modify many of the characteristics while the zone’s workload runs.
The next example demonstrates the use of live configuration:
GZ# zlogin myzone dladm
LINK CLASS MTU STATE OVER
net0 vnic 1500 up ?
GZ# zonecfg –rz myzone
zonecfg:myzone> add anet
zonecfg:myzone:anet> set linkname=net9
zonecfg:myzone:anet> end
zonecfg:myzone> commit
zone 'myzone': Checking: Adding anet linkname=net9
zone 'myzone': Applying the changes
zonecfg:myzone> exit
GZ# zlogin myzone dladm
LINK CLASS MTU STATE OVER
net0 vnic 1500 up ?
net9 vnic 1500 up ?
To maintain a proper security boundary, some zone properties, such as limitpriv, cannot be changed using live reconfiguration. Table 3.8 lists the properties and resource types that may be changed while the zone runs. (A dash indicates a feature that is never allowed with that brand. The letter “P” indicates a feature that is only partially supported.) An updated list is maintained in the per-brand man pages solaris(5), solaris-kz(5), solaris10(5), and labeled(5).

3.4.7.3 Deploying Zones with Unified Archives
Solaris 11 introduced Unified Archives to achieve highly flexible and scalable platform recovery and cloning. Recovery archives are intended to re-deploy a computer with the same Solaris configuration, including the same host name, IP addresses, and more. Clone archives are intended for deployment of many similar workloads, and do not include per-system configuration information.
An archive can consist of a global zone, with or without some or all of its zones, or you can create an archive of one or more zones without a global zone. In all of those cases, from an archive you can deploy a zone as a new zone, a new global zone, or a new kernel zone. Further, you can deploy a global zone as a non-global zone. Archives may be deployed with Solaris Automated Installer, with the zoneadm command, or as Unified Archives bootable media.
As an example, you might create a clone archive that includes three zones: a standard web server zone, an application server zone, and a database zone. If you store this archive on a central file server, you can then use provisioning tools to deploy the desired type of environment on an as-needed basis, then provide more specific, per-instance configuration information.
Although you can create an archive of a zone from within the zone itself, the archive will be more useful if you create the archive from the global zone. An archive of a zone created from its global zone will include configuration information for the zone.
To illustrate this approach, we will add the use of Unified Archives to an earlier example of zone creation. The first command creates an archive that includes all zones on the system. The other commands deploy one zone from that archive.
goldGZ# archiveadm create /server1/prod.uar
voyGZ# zonecfg –z web20 create -a /server1/prod.uar –z web
voyGZ# zoneadm –z web20 install –c /opt/zones/web_profile.xml
–a /server1/prod.uar -z web
3.4.7.4 Migrating Zones
Zones offer the ability to migrate a zone from one instance of Oracle Solaris to another. In this context, an instance can be a computer running a copy of Solaris, or it can be a VE running Solaris in a Dynamic Domain, in an Oracle VM Logical Domain, or on another hypervisor.
The types of migration permitted depend on the type of zone, and on the type of storage that is used for the zone. All types of zones may be migrated when they are not running. Doing so requires a service outage, but is the most flexible method. In addition, kernel zones may be migrated while they run, or they may be suspended briefly or indefinitely, and then restarted in a different Solaris instance. The rest of this section describes “cold” migration, which is the migration of a zone that has been stopped. A later section on kernel zones describes “warm” and “live” migration.
Two zoneadm subcommands are used to implement “cold” migration. The detach subcommand prepares a zone for migration and removes it from the list of zones that can be booted on the current system. The contents of the zone, underneath its zonepath, can then be transferred to the destination system using common file transfer methods, if necessary.
Migrating a zone is usually a straightforward process. The following example assumes that the zone was installed into shared storage by configuring a rootzpool:
hostA-GZ# zoneadm –z twilight shutdown
hostA-GZ# zonecfg –z twilight export –f /net/zones/twilight.cfg
hostA-GZ# zoneadm –z twilight detach
hostB-GZ# zonecfg –z twilight –f /net/zones/twilight.cfg
hostB-GZ# zoneadm –z twilight attach
hostB-GZ# zoneadm –z twilight boot
The destination system must be configured to have the same update of Oracle Solaris, or a newer update, than the original system. If the destination is newer, you should use the -u option to the attach subcommand.
You can also use the -u option when you are updating a system that includes zones to minimize the downtime of certain zones. The first step is to detach all of the zones; this step is followed by updating the system. When those steps are complete, certain zones may be quickly reattached to the system with the attach -u subcommand to zoneadm, followed by attachment of the remaining zones.
If the zone’s root directory resides on storage space that is not shared with the destination system, the zone’s contents must be archived with ZFS or by creating a Unified Archive. The archive must then be moved to the destination system, where zoneadm can be used to install it without unpackaging the archive. Obviously, shared storage for the zone or the data of its workload smooths zone migration considerably.
3.5 Oracle Solaris Kernel Zones
Solaris Kernel Zones are a new feature of Solaris 11, first introduced in Solaris 11.2. Kernel zones offer increased isolation between the zone and the global zone, and between kernel zones and other non-global zones.
This section discusses the differences between kernel zones and native zones that have been previously mentioned. They include many additional features as well as some brand-specific limitations. Because kernel zones may have their own zones, it is occasionally necessary to differentiate between the computer’s global zone and the kernel zone’s global zone. In such situations, we use the term “system global zone” for the former and “kernel global zone” for the latter.
The primary reasons to use a kernel zone instead of a native zone include package independence, greater software isolation, greater security isolation, independent allocations of RAM and swap disk space, and reduced observability (e.g.. the need to use zlogin myzone ps instead of ps). Reduced observability, for example, can be used to prevent users in the global zone from learning anything about the workload.
Kernel zones represent a hybrid of OSV and virtual machines. On the one hand, the CLI uses the same commands, and both require a running global zone. On the other hand, the border between a system global zone and its kernel zones is much clearer. The border also enables live migration, described later in this section.
3.5.1 Support
Kernel zones rely on hardware support for both SPARC and x86 systems. Most modern computers that use one of those CPU types provide the necessary support, including laptop computers. The virtinfo(1M) command displays information about the types of zones supported on that computer.
GZ# virtinfo
NAME CLASS
non-global-zone supported
kernel-zone supported
3.5.2 Creation and Basic Properties
Creating a simple kernel zone is a very simple process, as the few necessary properties have reasonable default settings. Here, we provide a very simple example of kernel zone configuration. The command to install a kernel zone is no different from that used to install a native zone. A more detailed example is shown in Code Sample 3.1 (found at the end of this chapter).
GZ# zonecfg -z potter create –t SYSsolaris-kz
Instead of configuring the zonepath property, you can specify storage that will be used for the kernel zone’s root pool. If you do not explicitly specify this storage, Solaris automatically creates a ZFS volume named rpool/VARSHARE/zones/<zonename>/disk0. On that storage, Solaris creates a ZFS pool to be used as the zone’s root pool. Within the zone, its root pool has one disk.
The default is convenient for simple situations, but prevents migration to a different Solaris instance unless the zone is stopped first. Also, there is no redundancy visible to the zone. Each of these limitations can be addressed.
To enable warm or live migration, the kernel zone must be configured to use shared, external storage for its root pool. This storage appears to the kernel zone as one or more virtual disks.
Several types of shared storage may be used for kernel zones, including NFS shares and SAN or iSCSI LUNs. If you provide one storage object, Solaris will use it for the root pool. If you configure two devices, Solaris will mirror them when it creates the root pool. Examples of storage objects are listed in suri(5).
The default configuration for a kernel zone includes 4 GB of RAM. This memory is exclusively reserved for that kernel zone when the zone boots. These memory pages cannot be paged out by the system global zone—a constraint that improves the consistency of performance from one day to the next, but limits the number of kernel zones that can run simultaneously. The property used to configure the amount of dedicated RAM is capped-memory:physical.
A kernel zone manages its use of that area of RAM. Just like any other operating system that uses virtual memory, a kernel zone uses some storage as swap space. Just like any Solaris 11 system, the default swap device is part of the root pool. Although modern systems are usually configured to avoid any paging at all, you should consider the implications of paging on the I/O performance of other workloads in the system. If the processes in one kernel zone attempt to use more memory than the memory configured for that zone, it will begin paging to its device(s). To the system global zone, this operation is simply I/O and, therefore, consumes I/O bandwidth. The I/O transactions may be protected by encrypting I/O within the kernel zone, if desired.
3.5.3 Packaging
Solaris’s package configuration for the kernel zone is completely independent of the package configuration for the system global zone. Thus, you can choose the same publisher as the global zone, or a different one. Kernel zones do not use proxies like native zones. Package management procedures are even more similar to those used with stand-alone systems than the procedures used with native zones are.
Several options exist to install a kernel zone that is a different Solaris version than the global zone. You can specify a custom manifest, use Solaris media, or use a Unified Archive.
3.5.4 Security
The security boundary around a native zone is configurable, meaning you can tailor access from the native zone to its global zone resources. In contrast, the security boundary around a kernel zone is static. The only configurable interactions between a kernel zone and its global zone are access to CPU time, RAM, and I/O.
A global zone cannot set the file-mac-profile property for one of its kernel zones, but you can make a kernel zone immutable. Instead of using the system’s global zone to configure this property, you can access the kernel zone’s own global zone and then use zonecfg from there. Of course, to ensure the intended level of security, this limitation cannot be reverted from within the kernel global zone. A specific option permits a sufficiently privileged user in the system global zone to modify an immutable kernel zone. For more details, see the section “3.4.3.3 Read-Only Zones” and Code Sample 3.2 at the end of this chapter.
3.5.5 Resource Controls
Although the resource consumption of kernel zones can be limited (in the same way that constraints can be placed on the resource consumption of native zones), there is less need for granular controls on kernel zones. For example, the number of processes that a kernel zone’s users have created has no impact on any users of the global zone, or users of any other zones, for that matter. Consequently, you cannot set the properties max-processes or max-lwps for a kernel zone. If a kernel zone’s administrator desires to cap the number of processes that a user of that zone can create, the administrator must use the standard Solaris methods to cap process use. The solaris-kz(5) man page provides a complete list of the properties that do not have meaning for a kernel zone.
By default, a kernel zone’s processes share the system global zone’s CPUs, and can run up to four of those processes at a time if sufficient CPU resources are available in the global zone. In other words, that zone is configured with four virtual CPUs. If you like, you can change the number of virtual CPUs configured for a kernel zone. Of course, the amount of work accomplished by a kernel zone’s processes will still be limited by the amount of CPU time that the system global zone schedules for the kernel zone.
In addition, kernel zones can be configured to use the CPU resource controls described in Section 3.4.4. Both of these controls give a zone exclusive access to physical CPU resources, but the dedicated-cpu feature is easier to use.
Unlike for other types of zones, Solaris reserves a section of RAM for a kernel zone. A property stores the amount of RAM to be configured when the kernel zone boots—namely, the “physical” property of the capped-memory resource. The default value for this property is 2 GB, although that value is usually too small. Like most properties, you can set the “physical” property when you originally create the zone, or you can modify it later. For a kernel zone, this property cannot be modified with the live zone reconfiguration method.
From the perspective of the global zone, all of a kernel zone’s RAM is locked and cannot be paged. A kernel zone performs its own paging, and manages its own virtual address space, just as any UNIX-type system manages its virtual memory. This includes the ability of a kernel zone to use swap space in its root pool. The default size of swap storage is 1 GB, but this size can be changed using the same method as is employed on a stand-alone Solaris system—that is, by modifying the size of the ZFS swap volume in the root pool.
3.5.6 File Systems and Devices
Because of the additional characteristics that keep a kernel zone isolated from the system global zone, file systems that are available in the global zone cannot be configured into a kernel zone. Instead, you can specify storage devices and use them to create file systems or use them as raw devices. Here is an example.
GZ# zonecfg –z dbzone
zonecfg:dbzone> add device
zonecfg:dbzone:device> set storage=nfs://dev:staff@fs1/export/dev/testdb
zonecfg:dbzone:device> end
zonecfg:dbzone> exit
Local devices may also be added, with the following syntax:
zonecfg:dbzone:device> set match=/dev/rdsk/c10t0d0
Only storage devices may be configured.
3.5.7 Networking
Kernel zones benefit from the rich set of networking features available to native zones, with a few exceptions. To maintain the level of isolation appropriate for kernel zones, these zones must use the exclusive-IP networking model.
As with other zones, a default configuration for kernel zones includes one anet—a VNIC that uses a physical NIC.
If you configure additional network devices into a zone, you should label them with id values in zonecfg. Doing so simplifies some configuration tasks, especially if you plan to migrate the zone. The id property of the default network device in a kernel zone is automatically configured to have a value of zero.
3.5.8 Management
Managing a kernel zone is very similar to managing a native zone, albeit with a few differences. Those differences are highlighted in the following subsections.
3.5.8.1 Problem Diagnosis
Earlier in this chapter, we described the ability to diagnose software issues inside a native zone, while working in the global zone, using DTrace and other tools. Because of the additional isolation of a kernel zone, these tools cannot “see” inside a kernel zone.
To remedy this shortcoming, Solaris has the ability to generate a core dump of a kernel zone. To maximize self-consistency of the core image, the zone is paused while the image is saved. If this behavior is not appropriate for the situation, you can specify an option that permits the zone to continue running. The coreadm(1M) command controls the default storage location, but you can change that location when you first save the core. Here is an example:
GZ# zoneadm –z hungzone savecore
The mdb(1) command analyzes core images.
3.5.8.2 Suspend, Resume, and Deploy
Because a kernel zone owns a complete virtual memory map, processing can be temporarily suspended, and the entire memory image can be copied to storage. Later, this image can be copied back into RAM and processing can continue at the next instruction. This technique opens up new possibilities for managing zones.
The copy of memory created in this way contains the state of any workloads running in the zone. When you resume processing, it continues at the next machine instruction, working with the same data. Resuming a suspended image can take just a few seconds, depending on the amount of memory that had been allocated by processes running in the zone.
The suspend feature enables you to perform the following tasks:
![]() Temporarily pause a zone and its workload to free up RAM for some other use
Temporarily pause a zone and its workload to free up RAM for some other use
![]() Reduce the amount of time needed to bring a workload to a state where it can operate efficiently (e.g., a static data warehouse)
Reduce the amount of time needed to bring a workload to a state where it can operate efficiently (e.g., a static data warehouse)
![]() Start several kernel zones and suspend many or all of them, so that one or more of them can be resumed quickly, perhaps improving business agility
Start several kernel zones and suspend many or all of them, so that one or more of them can be resumed quickly, perhaps improving business agility
A storage location is required that will hold the memory image when processing is suspended. This location is stored in the zone property suspend:path or suspend:storage. The former is a full path name. The latter is a storage object; its syntax is described in suri(5).
3.5.8.3 Migration
Another new management option possible for kernel zones is the ability to move to a different computer without stopping its workload. This ability is very useful when the goal is to balance the load of multiple systems, or to perform hardware maintenance on the computer, or maintenance operations on the system global zone.
Solaris 11 supports two slightly different types of migration: warm and live. To the users of the workload, the primary difference between these two types is the period of time during which processing does not occur. For a live migration, that time is a fraction of a second, making this method appropriate for active workloads with no convenient time for interruption. By comparison, the interruption in processing is much longer with warm migration. This technique can be used when an interruption measured in minutes is preferable to the service outage caused by rebooting the zone on the destination system, but there is insufficient bandwidth to support live migration.
Although the difference to users is simply the duration of time that the workload is paused, the requirements and the steps to perform these two types of migration are very different.
Warm migration requires a suspend resource (described in the previous section). Further, that resource must be made accessible to the destination system before the zone resumes operation. Internal storage is not appropriate for kernel zones that may be migrated.
In contrast, live migration requires the zone’s root pool to exist on shared storage, available to both the original and destination global zones. Live migration also requires specific Solaris services to be running on the destination host.
Two commands are required to perform a warm migration: suspending the zone and resuming it on the other computer. Live migration does not store the zone’s image as warm migration does, so it requires only one command. With live migration, the memory image is simply copied to the other computer, and then I/O and execution are transferred.
For either warm or live migration, the original and destination systems must be sufficiently similar to support these features. Incompatibilities of a destination system might potentially include older CPUs that are missing features available on the original system, a different amount of CPUs or RAM configured for the kernel zone, or missing devices.
One of the first steps performed automatically during a live migration is verification that the destination system is sufficiently compatible. Also, the command to migrate a zone has an option that tests compatibility, but does not perform the migration. The following example shows the simplicity of live zone migration:
carditos# zoneadm –z monarch migrate canada
Of course, live migration requires cooperation between the two Solaris systems. The receiving end of the live migration must be running services that authenticate the migration and receive the image, among other tasks. Those services must be enabled once, with the following command:
svcadm enable –s svc:/system/rad:remote svc:/network/kz-migr:stream
By default, live migrations of kernel zones are encrypted to prevent an outsider from capturing the image while in flight.
The incompatibilities mentioned as obstacles to live migration will also prevent successful warm migration. A failure to boot after warm migration can be followed by an attempt on another system, including the original one. Performing a warm migration requires a few commands; pay careful attention to the prompts shown here:
GZ1# zonecfg –z zone1 export –f /net/zonecfgs/zone1.cfg
GZ2# zonecfg –z zone1 –f /net/zonecfgs/zone1.cfg
GZ1# zoneadm –z zone1 suspend
GZ2# zoneadm –z zone1 boot
Both live and warm migration require that appropriate I/O resources are available on the target host. In some situations, the name of a device (e.g., a lower-link property for an anet resource) will be different. You can compensate for that discrepancy by configuring a zone of the same name on the remote host and making appropriate modifications before performing the migration.
3.6 Solaris 10 Zones
Thousands of SPARC systems are currently running the Solaris 10 operating system. In most cases, the desire to take advantage of innovations in Oracle Solaris 11 can be fulfilled by migrating the workload to a native zone on a Solaris 11 system. This process is usually straightforward because of the binary compatibility from one version of Solaris to the next, backed by the Oracle Solaris Binary Application Guarantee. People often place these workloads into native zones.
In other situations, such migration might prove difficult or its results uncertain. Perhaps the workload includes shell scripts that work correctly on Solaris 10 but not on Solaris 11. Perhaps your organization tuned the workload for Solaris, but retuning for Solaris 11 would require recompiling the software and the source code is no longer available. Perhaps redeployment in a Solaris 11 environment would require recertification, which is impractical for hundreds of computers that will be replaced within the next year anyway. For any of these or other reasons, you might strongly prefer to maintain a Solaris 10 environment for the workload. This raises a key question: Are other options available?
The Solaris 10 Zones feature set replicates a Solaris 10 software environment within a zone on a Solaris 11 system. All of the software from the original system runs on the Solaris 11 system without translation or emulation of binary instructions; the only translations required involve the system calls.
The original Solaris 10 environment can be a Solaris 10 system without zones, or a Solaris 10 native zone. This process works best with the last update: Solaris 10 1/13. Earlier updates may require patches for all features to work correctly. For example, the Solaris 10 package and patch tools require patches to work correctly in Solaris 10 Zones. The Solaris 11 global zone needs the package named brand-solaris10.
Two tools are available that can simplify the process of migration. The first tool, zonep2vchk(1M), verifies that the configuration of a Solaris 10 system is suitable for conversion to a Solaris 10 Zone. Among other things, this tool attempts to find any binaries that would not work correctly in a Solaris 10 Zone. With an option, this tool will also output a suitable zone configuration file. You can find zonep2vchk in a Solaris 11 system, and copy it to the Solaris 10 systems that you want to examine.
In addition, a P2V tool is included that uses an archive of the file system of the original computer to populate the file system of the new zone. The entire process typically takes 30–60 minutes to complete and can be automated. After the original system is archived with the flarcreate, tar, cpio, or pax command, only four commands are needed to create, boot, and log in to the zone. The following example assumes that the Solaris 10 system is named sol10 and that the Solaris 10 and Solaris 11 systems use /net/server as mount points for a shared NFS file system:
Sol10# flarcreate –L pax -S -n mys10 /net/server/balrog.flar
...
Archive creation complete.
Note that Solaris 10 sparse-root zones must be placed in the ready state before archive creation, so as to mount file systems from the global zone.
Before booting the Solaris 10 Zone, the original Solaris 10 system should be halted because it contains the same configuration information, including the same IP address.
GZ# zonecfg -z balrog
zonecfg:balrog> create -t SYSsolaris10
zonecfg:balrog> exit
GZ# zoneadm -z balrog install -p -a /net/server/balrog.flar
Source: /net/server/balrog.flar
...
Result: Installation completed successfully.
GZ# zoneadm -z balrog boot
GZ# zlogin -C balrog
[Connected to zone 'balrog' console]
[NOTICE: Zone booting up]
SunOS Release 5.10 Version Generic_Virtual 64-bit
Copyright (c) 1983, 2010, Oracle and/or its affiliates. All rights reserved.
Hostname: balrog
balrog console login:
Multiple Solaris 10 Zones can be hosted on the same system. When the migration is complete, the new system will have the structure shown in Figure 3.6.

After migration, you can use the same methods to manage the Solaris 10 Zone as you used before migration. Specifically, the Solaris 10 package and patch tools are still available, and they continue to be the preferred method for managing Solaris packages.
Solaris 10 Zones can also take advantage of other Solaris 11 innovations. For example, they can be placed on a ZFS file system and gain the benefits of ZFS, particularly its robustness due to its checksummed data and metadata blocks. You can also use DTrace to examine programs running in these zones.
Solaris 10 Zones can be NFS clients, but not NFS servers. They also cannot use file-mac-profile, which means that they cannot be immutable zones.
If the original system has Solaris 10 native zones, those zones must be migrated to other hosts before the global zone is migrated—migrating the global zone will disable any remaining zones. Moving these zones to Solaris 11 systems, as Solaris 10 Zones, is not difficult. Instead of using the install subcommand of zoneadm, you use the attach subcommand to migrate the native zones.
Finally, if the original Solaris 10 system had Solaris 8 Containers or Solaris 10 Containers, they cannot be moved to a Solaris 11 system. If you must continue to use Solaris 8 Containers, you must retain at least one Solaris 10 system.
Of course, once you have migrated a Solaris 10 system or zone to a Solaris 11 system, you must still maintain it. Although new updates to Solaris 10 are not being released, Solaris 10 patches continue to be created.
Solaris 10 introduced the concept of a boot environment (BE), which comprises all of the Solaris package content necessary to boot Solaris. One Solaris can maintain multiple BEs, with different versions of packages, and you can boot from any one BE still installed on that system. A Solaris 10 system uses one disk drive per BE. That scheme limits the BEs’ usefulness, and usually requires breaking the root drive mirrored pair; in turn, this process increases risk while patching or updating Solaris.
A Solaris 10 zone benefits from multiple boot environments, but does not suffer from the need to break the mirror. The global zone uses ZFS to store the Solaris 10 zone—by default—which means that snapshots can be used to store multiple BEs per Solaris 10 zone.
The following commands show the steps to create and enable a new BE for a Solaris 10 zone:
z10# zfs snapshot rpool/ROOT/zbe-0@snap
z10# zfs clone -o mountpoint=/ -o canmount=noauto rpool/ROOT/zbe-0@snap rpool/ROOT/newBE
cannot mount 'rpool/ROOT/newBE' on '/': directory is not empty
filesystem successfully created, but not mounted
At this point you can mount and modify the newly created BE:
z10# zfs mount -o mountpoint=/mnt rpool/ROOT/zbe-0
z10# patchadd -R /mnt -M /var/sadm/spool 104945-02
Then you can activate the BE so that it is used when the zone next boots:
z10# zfs get com.oracle.zones.solaris10:activebe rpool/ROOT
NAME PROPERTY VALUE SOURCE
rpool/ROOT com.oracle.zones.solaris10:activebe zbe-0 local
z10# zfs set com.oracle.zones.solaris10:activebe=newBE rpool/ROOT
Solaris 10 Zones are an excellent method to move older Solaris workloads to newer, consolidated systems. Following such migrations, the workloads benefit from the increased flexibility of Solaris 11 features.
3.7 Strengths of Oracle Solaris Zones
Oracle Solaris Zones deliver all of the strengths of the OSV model:
![]() Compute efficiency. Zones have almost zero overhead, giving them an advantage over hypervisors, which use CPU cycles for I/O transactions, and over partitioning, which leaves CPU cycles unused even when another workload could use those resources.
Compute efficiency. Zones have almost zero overhead, giving them an advantage over hypervisors, which use CPU cycles for I/O transactions, and over partitioning, which leaves CPU cycles unused even when another workload could use those resources.
![]() Storage efficiency. A zone can use as little as 100MB of disk space and as little as 40MB of RAM.
Storage efficiency. A zone can use as little as 100MB of disk space and as little as 40MB of RAM.
![]() Hardware independence. Zones do not depend on any hardware features and do not have any code specific to one instruction set. They are currently supported on x86/x64 and SPARC architectures, making Solaris Zones one of the few virtualization technologies available on multiple CPU architectures.
Hardware independence. Zones do not depend on any hardware features and do not have any code specific to one instruction set. They are currently supported on x86/x64 and SPARC architectures, making Solaris Zones one of the few virtualization technologies available on multiple CPU architectures.
![]() Observability. The kernel controls access to all information regarding its zones, so tools such as DTrace can simultaneously view internal details of multiple zones and their processes.
Observability. The kernel controls access to all information regarding its zones, so tools such as DTrace can simultaneously view internal details of multiple zones and their processes.
In addition, zones offer several advantages over other forms of OSV:
![]() Solaris 8 Containers and Solaris 9 Containers allow you to run all of the software from an older system on a system running Solaris 10.
Solaris 8 Containers and Solaris 9 Containers allow you to run all of the software from an older system on a system running Solaris 10.
![]() The
The solaris10 brand allows you to run Solaris 10 software on Solaris 11.
![]() The flexible and dynamic resource controls can automatically adapt to the changing needs of one or more workloads.
The flexible and dynamic resource controls can automatically adapt to the changing needs of one or more workloads.
![]() A configurable security boundary provides the ability to relax or strengthen the privileges of each zone individually.
A configurable security boundary provides the ability to relax or strengthen the privileges of each zone individually.
![]() Zones are a tightly integrated feature of Oracle Solaris, and benefit from innovations in Solaris such as ZFS, IPS, and DTrace.
Zones are a tightly integrated feature of Oracle Solaris, and benefit from innovations in Solaris such as ZFS, IPS, and DTrace.
3.8 Summary
Oracle Solaris Zones are a very popular, mature, and feature-rich form of system virtualization that are used in production environments in data centers all over the world. In practice, the more common uses of zones include the following situations:
![]() Consolidating applications from multiple servers to fewer servers, especially as a no-cost virtual server.
Consolidating applications from multiple servers to fewer servers, especially as a no-cost virtual server.
![]() Hardening an OS environment with read-only mounts and minimal privileges, especially for Internet-facing environments.
Hardening an OS environment with read-only mounts and minimal privileges, especially for Internet-facing environments.
![]() Hosting environments such as cloud computing, Internet service providers (ISPs), and web hosting, where a homogeneous environment is preferred by the hosting organization, and where quick provisioning is important. Each customer’s operations can be configured on multiple systems, ready to boot on the most lightly loaded system.
Hosting environments such as cloud computing, Internet service providers (ISPs), and web hosting, where a homogeneous environment is preferred by the hosting organization, and where quick provisioning is important. Each customer’s operations can be configured on multiple systems, ready to boot on the most lightly loaded system.
![]() Software development environments, which also benefit from rapid provisioning and homogeneity, giving each developer full privileges in that zone.
Software development environments, which also benefit from rapid provisioning and homogeneity, giving each developer full privileges in that zone.
![]() Rapid provisioning for short-lived environments—for example, functionality testing. A cloned zone provides a well-defined starting point.
Rapid provisioning for short-lived environments—for example, functionality testing. A cloned zone provides a well-defined starting point.
![]() High-scale virtualization, in which dozens or hundreds of VEs reside in one computer, because of the superior efficiency of Solaris Zones.
High-scale virtualization, in which dozens or hundreds of VEs reside in one computer, because of the superior efficiency of Solaris Zones.
Released as a feature set of Solaris 10 in early 2005, Oracle Solaris Zones have achieved broad support from independent software vendors. Network virtualization adds a new dimension to their usefulness for Solaris and the future.
Code Sample 3.1 Detailed Creation of Kernel Zone
root@tesla:/export/home/jvictor# zonecfg -z potter
Use 'create' to begin configuring a new zone.
zonecfg:potter> create -t SYSsolaris-kz
zonecfg:potter> info
zonename: potter
brand: solaris-kz
autoboot: false
autoshutdown: shutdown
bootargs:
pool:
scheduling-class:
hostid: 0xa7a4b83
tenant:
anet:
lower-link: auto
allowed-address not specified
configure-allowed-address: true
defrouter not specified
allowed-dhcp-cids not specified
link-protection: mac-nospoof
mac-address: auto
mac-prefix not specified
mac-slot not specified
vlan-id not specified
priority not specified
rxrings not specified
txrings not specified
mtu not specified
maxbw not specified
bwshare not specified
rxfanout not specified
vsi-typeid not specified
vsi-vers not specified
vsi-mgrid not specified
etsbw-lcl not specified
cos not specified
evs not specified
vport not specified
iov: off
lro: auto
id: 0
device:
match not specified
storage.template: dev:/dev/zvol/dsk/%{global-rootzpool}/VARSHARE/zones/%{zonename}/disk%{id}
storage: dev:/dev/zvol/dsk/rpool/VARSHARE/zones/potter/disk0
id: 0
bootpri: 0
capped-memory:
physical: 4G
zonecfg:potter> exit
root@tesla:/export/home/jvictor# zoneadm -z potter install
Progress being logged to /var/log/zones/zoneadm.20150716T010458Z.potter.install
pkg cache: Using /var/pkg/publisher.
Install Log: /system/volatile/install.16299/install_log
AI Manifest: /tmp/zoneadm15783.QTaakF/devel-ai-manifest.xml
SC Profile: /usr/share/auto_install/sc_profiles/enable_sci.xml
Installation: Starting ...
Creating IPS image
Installing packages from:
solaris
origin: http://pkg.oracle.com/solaris/release/
The following licenses have been accepted and not displayed.
Please review the licenses for the following packages post-install:
consolidation/osnet/osnet-incorporation
Package licenses may be viewed using the command:
pkg info --license <pkg_fmri>
DOWNLOAD PKGS FILES XFER (MB) SPEED
Completed 482/482 64490/64490 559.6/559.6 543k/s
PHASE ITEMS
Installing new actions 88235/88235
Updating package state database Done
Updating package cache 0/0
Updating image state Done
Creating fast lookup database Done
Installation: Succeeded
Done: Installation completed in 1581.112 seconds.
Code Sample 3.2 Configuring an Immutable Kernel Zone
jvictor@tesla:~$ sudo zlogin potter
[Connected to zone 'potter' pts/3]
Oracle Corporation SunOS 5.11 11.2 August 2014
root@potter:~# zonecfg -z global
zonecfg:global> set file-mac-profile=fixed-configuration
zonecfg:global> exit
updating /platform/i86pc/boot_archive
updating /platform/i86pc/amd64/boot_archive
root@potter:~# reboot
[Connection to zone 'potter' pts/3 closed]
jvictor@tesla:~$ sudo zlogin potter
[Connected to zone 'potter' pts/3]
Oracle Corporation SunOS 5.11 11.2 August 2014
root@potter:~# cat "10.1.1.1 myhost" >> /etc/hosts
-bash: /etc/hosts: Read-only file system
root@potter:~# zonecfg -z global
WARNING: you do not have write access to this zone's configuration file. Going into read-only mode.
zonecfg:global> info
file-mac-profile: fixed-configuration
pool:
fs-allowed:
zonecfg:global> exit
root@potter:~# exit
[Connection to zone 'potter' pts/3 closed]
jvictor@tesla:~$ sudo zlogin -T potter
[Connected to zone 'potter' pts/3]
Oracle Corporation SunOS 5.11 11.2 August 2014
root@potter:~# echo "10.1.1.1 myhost" >> /etc/hosts
root@potter:~# zonecfg -z global
zonecfg:global> info
file-mac-profile: fixed-configuration
pool:
fs-allowed:
zonecfg:global> set file-mac-profile=none
zonecfg:global> exit
updating /platform/i86pc/boot_archive
updating /platform/i86pc/amd64/boot_archive
root@potter:~# reboot