
2. Use Cases and Requirements
Consolidation via virtualization delivers more productivity than is possible with a smaller environment. This chapter explores the uses of virtualization and the requirements that must be fulfilled to achieve its goals.
2.1 Introduction
In this chapter, we visit the following cases, discussing the value and notable requirements of each:
![]() General workload consolidation: resource management and availability
General workload consolidation: resource management and availability
![]() Asynchronous workloads: balancing resource utilization throughout the day
Asynchronous workloads: balancing resource utilization throughout the day
![]() Software development: consolidation of similar environments
Software development: consolidation of similar environments
![]() Test and staging: consolidation of similar environments
Test and staging: consolidation of similar environments
![]() Simplifying workload mobility
Simplifying workload mobility
![]() Maintaining a legacy OS on new hardware
Maintaining a legacy OS on new hardware
![]() Flexible, rapid provisioning
Flexible, rapid provisioning
![]() Relieving scalability constraints of a given OS via multiple instances
Relieving scalability constraints of a given OS via multiple instances
![]() Fine-grained operating system modifications
Fine-grained operating system modifications
![]() Configurable security characteristics
Configurable security characteristics
2.2 General Workload Consolidation
The most common use of virtualization is the consolidation of multiple, often unrelated, workloads from multiple computers into one computer. This approach avoids potential problems caused by mixing applications in the same virtual environment (VE). Once it has been determined that it is safe to run a particular application in a specific implementation of virtualization, there should be no need to verify a particular instance of that application or a particular combination of application instances for correct functionality.
Although the applications may function correctly, their performance characteristics will probably change when they are running in a consolidated environment. Several different factors may cause this change:
![]() Shared I/O channels are typical in most virtualization implementations, and will reduce available bandwidth to networks and persistent storage.
Shared I/O channels are typical in most virtualization implementations, and will reduce available bandwidth to networks and persistent storage.
![]() Disks may be shared, increasing read and write transaction latency.
Disks may be shared, increasing read and write transaction latency.
![]() If there are more workloads than CPUs, workloads may wait longer before getting a time slice on a CPU, thereby increasing response time.
If there are more workloads than CPUs, workloads may wait longer before getting a time slice on a CPU, thereby increasing response time.
![]() If multiple workloads share a set of physical CPUs and there are more workloads than CPUs, there is a greater chance of a process being assigned to a different CPU than the previous time slice, negating the benefits of a CPU’s caches.
If multiple workloads share a set of physical CPUs and there are more workloads than CPUs, there is a greater chance of a process being assigned to a different CPU than the previous time slice, negating the benefits of a CPU’s caches.
In addition to the potential for decreased performance, workload performance may be less consistent in a consolidated environment unless resource controls are used. On any one day, two workloads might experience their daily peaks in CPU utilization at different times, and response times may be similar to those observed on unconsolidated systems. The next day, the peaks for those two workloads might coincide, leading to competition for physical resources such as CPUs and RAM. Response times for each workload may then suffer.
In other words, aggregate CPU usage of one workload should not change because of consolidation, but the deviation from average response time may increase. However, a complete understanding of the performance demands of the workloads should allow you to minimize this problem, because you will be able to place VEs on different systems to minimize this kind of performance deviation.
Resource partitioning technologies, including some virtual machine implementations, dedicate hardware resources to each resource partition. This practice insulates each partition from the CPU consumption of other domains. You can use this feature to improve performance consistency.
Besides the effects of workload consolidation, virtualization can cause changes in workload performance. Many virtualization technologies require use of the system CPUs to perform virtualization activities. The result is performance overhead, in the form of CPU cycles that are not performing work directly related to the applications. The amount of overhead depends on several factors, including the following:
![]() The method of virtualization (e.g., partitioning, virtual machines, or operating system virtualization):
The method of virtualization (e.g., partitioning, virtual machines, or operating system virtualization):
![]() A partitioned system does not run virtualization software and has no overhead.
A partitioned system does not run virtualization software and has no overhead.
![]() A hypervisor runs on the system CPUs and creates overhead, but this is generally limited to I/O activities if the CPU has virtualization-assist features.
A hypervisor runs on the system CPUs and creates overhead, but this is generally limited to I/O activities if the CPU has virtualization-assist features.
![]() Paravirtualization can significantly decrease performance overhead caused by a hypervisor.
Paravirtualization can significantly decrease performance overhead caused by a hypervisor.
![]() Operating system virtualization results in more processes in the single OS instance. This can be challenging for some operating systems, but the overhead directly associated with virtualization activities is negligible.
Operating system virtualization results in more processes in the single OS instance. This can be challenging for some operating systems, but the overhead directly associated with virtualization activities is negligible.
![]() The mix of computing activity versus I/O activity:
The mix of computing activity versus I/O activity:
![]() Computing activity does not increase overhead because the process runs directly on the CPU.
Computing activity does not increase overhead because the process runs directly on the CPU.
![]() Memory-intensive applications can increase overhead unless the CPU has features to minimize this possibility.
Memory-intensive applications can increase overhead unless the CPU has features to minimize this possibility.
![]() For hypervisors, I/O activity must be controlled to prevent one VE from accessing information owned by another VE: This activity increases overhead.
For hypervisors, I/O activity must be controlled to prevent one VE from accessing information owned by another VE: This activity increases overhead.
![]() Hardware features may simplify some virtualization tasks, reducing overhead.
Hardware features may simplify some virtualization tasks, reducing overhead.
The combination of unpredictable patterns of effective performance and the potential for denial-of-service attacks makes resource management an essential component of any virtualization solution. Resource controls ensure that the consolidated systems can meet their service level objectives and be protected from resource starvation. Six resource categories are commonly managed:
![]() CPU capacity: Controls are used to ensure that each VE gets enough CPU time to provide appropriate responsiveness and to prevent denial-of-service attacks, either from compromised VEs on the same system or from traditional network attacks.
CPU capacity: Controls are used to ensure that each VE gets enough CPU time to provide appropriate responsiveness and to prevent denial-of-service attacks, either from compromised VEs on the same system or from traditional network attacks.
![]() Amount of RAM used: Controls should be used to ensure that each VE has enough RAM to perform well.
Amount of RAM used: Controls should be used to ensure that each VE has enough RAM to perform well.
![]() Amount of virtual memory or swap space used: Unless each VE has its own private swap device or partition, this type of control can be used to ensure that each VE has enough swap space to work correctly and to prevent denial-of-service attacks.
Amount of virtual memory or swap space used: Unless each VE has its own private swap device or partition, this type of control can be used to ensure that each VE has enough swap space to work correctly and to prevent denial-of-service attacks.
![]() Network bandwidth consumed: Controls can be used to provide an appropriate quality of service for each workload and to prevent denial-of-service attacks.
Network bandwidth consumed: Controls can be used to provide an appropriate quality of service for each workload and to prevent denial-of-service attacks.
![]() Persistent storage bandwidth consumed: Some technologies offer the ability to limit the amount of storage bandwidth consumed by one VE.
Persistent storage bandwidth consumed: Some technologies offer the ability to limit the amount of storage bandwidth consumed by one VE.
![]() Use of kernel data structures: Examples include shared memory identifiers, including structures of finite size and structures that use another finite resource such as RAM.
Use of kernel data structures: Examples include shared memory identifiers, including structures of finite size and structures that use another finite resource such as RAM.
2.2.1 Types of Resource Controls
Several methods to control sharing of resources exist. One method is to divide a resource into chunks and assign each chunk to one workload. Resources with a finite size, such as RAM or CPUs, can be divided using that method. However, this approach wastes a portion of the resource because the portion that is currently assigned to one VE is not in use but could be used by another VE. Some implementations of this method reduce the amount of waste by dynamically resizing the reserved resource based on resource usage.
A second method to control resource allocation is a software-regulated limit, also called a resource cap. The controlling mechanism—a hypervisor or the operating system—prevents VEs from using more than a specified amount of the resource. The remaining, unused portions of the resource can be used by other VEs.
A third method to apportion CPU cycles—and the least wasteful of the three methods—is the fair share scheduler (FSS). If there is sufficient capacity for every VE to get the amount of CPU cycles it wants, each VE can use that amount. Conversely, if there is contention for the resource, instead of enforcing a maximum amount of consumption, this method guarantees availability of a minimum portion of a resource. An FSS allocates the resource in portions controlled by the administrator—a strategy akin to that underlying the concept of a service level agreement (SLA), which corporate customers often require.
Allocation of network bandwidth is similar to allocation of CPU cycles. If you are patient, you can always get more of a resource—for example, a time slice for CPUs, or a time slot for network access. For this type of resource, it may not make sense to reserve a quantity, but it does make sense to cap the rate at which one VE consumes the resource over a brief sampling period.1
1. There are exceptions—for example, very-low-latency applications such as video and financial transactions that require reserved bandwidth to function correctly.
The following resource controls are available in virtualization implementations. They can be used to manage the resource categories listed earlier.
![]() CPU partitioning is the ability to assign a particular CPU or set of CPUs to a VE. It reserves all of the compute power of a set of CPUs, but any unused CPU cycles cannot be used by another VE and are wasted unless the reservation can be changed dynamically and automatically. However, this method provides predictable performance and avoids performance overhead. A workload assigned to a set of CPUs will always have access to its assigned CPUs, and will never be required to wait until another VE completes its time slice. A resource manager can reduce wasted capacity by reassigning idle CPUs.
CPU partitioning is the ability to assign a particular CPU or set of CPUs to a VE. It reserves all of the compute power of a set of CPUs, but any unused CPU cycles cannot be used by another VE and are wasted unless the reservation can be changed dynamically and automatically. However, this method provides predictable performance and avoids performance overhead. A workload assigned to a set of CPUs will always have access to its assigned CPUs, and will never be required to wait until another VE completes its time slice. A resource manager can reduce wasted capacity by reassigning idle CPUs.
The amount of waste will be determined by two factors: (1) reconfiguration latency—the time it takes to shift a CPU from one partition to another and (2) resource granularity—the unconsumed partition of, at most, a single CPU. This model of CPU control is shown in Figure 2.1.

![]() A software scheduler such as FSS may allow the administrator to enforce minimum response times either directly or via VE prioritization. Early implementations included software schedulers for VM/XA on mainframes and BSD UNIX on VAX 11/780s in the 1980s. This approach is often the best general-purpose solution. It is very flexible, in that the minimum amount of processing power assigned to each VE can be changed while the VE is running. Moreover, a software scheduler does not force workloads to wait while unused CPU cycles are wasted.
A software scheduler such as FSS may allow the administrator to enforce minimum response times either directly or via VE prioritization. Early implementations included software schedulers for VM/XA on mainframes and BSD UNIX on VAX 11/780s in the 1980s. This approach is often the best general-purpose solution. It is very flexible, in that the minimum amount of processing power assigned to each VE can be changed while the VE is running. Moreover, a software scheduler does not force workloads to wait while unused CPU cycles are wasted.
System administrators can use an FSS to enforce the assignment of a particular minimum portion of compute capacity to a specific workload. A quantity of shares—a unitless value—is assigned to each workload, as depicted in Figure 2.2. The scheduler sums the shares assigned to all of the current workloads, and divides each workload’s share quantity by the sum to obtain the intended minimum portion.

Insufficient memory can cause more significant performance problems than insufficient CPU capacity. If a workload needs 10% more CPU time than it is currently getting, it will run 10% more slowly than expected. By comparison, if a program needs 10% more RAM than it is currently getting, the result will be excessive paging. Such paging to the swap disk can decrease workload performance by an order of magnitude or more.
Excessive memory use by one VE may starve other VEs of memory. If multiple VEs begin paging, the detrimental effects on performance can be further exacerbated by various factors:
![]() A shared I/O channel can be a bottleneck.
A shared I/O channel can be a bottleneck.
![]() If VEs share swap space, fragmentation of the swap space can cause excessive head-seeking within the swap area.
If VEs share swap space, fragmentation of the swap space can cause excessive head-seeking within the swap area.
![]() If each VE has a separate swap area but all of these areas are present on one disk drive, the drive head will continuously seek between the two swap areas.
If each VE has a separate swap area but all of these areas are present on one disk drive, the drive head will continuously seek between the two swap areas.
If paging cannot be avoided, swap areas should be spread across multiple drives or, if possible, placed on low-latency devices such as solid-state drives (SSDs). In most cases, it is difficult to justify the extra cost of those devices. Instead, you should try to avoid paging by configuring sufficient RAM for each VE.
Memory controls can be used to prevent one VE from using so much RAM that another VE does not have sufficient memory for its work. Indeed, the appropriate use of memory controls should be a general practice for consolidated systems. Inappropriate use of memory controls can cause poor performance if applications are granted use of less RAM than the “working set” they need to operate efficiently. Memory controls should be used carefully and with knowledge of actual RAM requirements.
Per-VE memory partitioning (RAM reservation or swap reservation) is available for some virtualization implementations. This type of control provides each VE with immediate access to all of its memory, but any reserved-but-unused memory is wasted because no other VE can use it. Also, modifying the reservation after the VE is running is not possible in some implementations.
Recently, virtual machine implementations have begun to include methods that enable the hypervisor to reduce a guest’s RAM consumption when the system is under memory pressure. This feature causes the VE to begin paging, but allows the guest to decide which memory pages it should page out to the swap device.
![]() A per-VE limit, also called a memory cap, is more flexible and less wasteful than a memory partition or reservation. The virtualization software tracks the amount of memory in use by each VE. When a VE reaches its cap, infrequently used pages of memory are copied to swap space for later access, using the normal demand paging virtual memory system. There is a potential drawback, however: As with dedicated memory partitions, overly aggressive memory caps can cause unnecessary paging and decrease workload performance.
A per-VE limit, also called a memory cap, is more flexible and less wasteful than a memory partition or reservation. The virtualization software tracks the amount of memory in use by each VE. When a VE reaches its cap, infrequently used pages of memory are copied to swap space for later access, using the normal demand paging virtual memory system. There is a potential drawback, however: As with dedicated memory partitions, overly aggressive memory caps can cause unnecessary paging and decrease workload performance.
![]() Other controls have been implemented on miscellaneous resources offered by the hypervisor or OS. One such resource is locked memory. Some operating systems allow applications to lock data regions into memory so that they cannot be paged out. This practice is widely used by database software, which works best when it can lock a database’s index into memory. As a consequence, frequently used data is found in memory, rather than on relatively slow disk drives. If the database is the only workload on the system, it can choose an appropriate portion of memory to lock down, based on its needs; there is no need to be concerned about unintended consequences.
Other controls have been implemented on miscellaneous resources offered by the hypervisor or OS. One such resource is locked memory. Some operating systems allow applications to lock data regions into memory so that they cannot be paged out. This practice is widely used by database software, which works best when it can lock a database’s index into memory. As a consequence, frequently used data is found in memory, rather than on relatively slow disk drives. If the database is the only workload on the system, it can choose an appropriate portion of memory to lock down, based on its needs; there is no need to be concerned about unintended consequences.
On a consolidated system, the database software must still be able to lock down that same amount of memory. At the same time, it must be prevented from locking down so much more RAM than it needs that other workloads suffer from insufficient memory.
Well-behaved applications will not cause problems with locked memory, but an upper bound should be set on most VEs.
![]() Per-VE limits on network bandwidth usage can be used to ensure that every VE gets access to a reasonable portion of this resource.
Per-VE limits on network bandwidth usage can be used to ensure that every VE gets access to a reasonable portion of this resource.
![]() Per-VE network bandwidth reservations can be used to ensure that a particular workload always has the bandwidth it needs, even if that means wasting some bandwidth.
Per-VE network bandwidth reservations can be used to ensure that a particular workload always has the bandwidth it needs, even if that means wasting some bandwidth.
2.2.2 Need for Availability
With one workload per system, a hardware failure in a computer can affect only that workload and, potentially, any workloads on other systems on which it depends. In contrast, consolidating multiple unrelated workloads onto one system requires different planning, because a hardware failure can then bring down multiple services. High-availability (HA) solutions are justified by the greater total value of workloads in the computer.
Fortunately, VEs can be configured as nodes in HA clusters using products such as Oracle Solaris Cluster or Veritas Cluster Server. If you want to minimize just downtime due to application failure or OS failure, the primary and secondary VEs can be configured on one computer.
More commonly, the two nodes are configured on different computers to minimize downtime due to hardware failure. Multiple HA pairs can be configured in the same cluster. Often, primary nodes are spread around the computers in the cluster to balance the load under normal operating conditions, as shown in Figure 2.3. This configuration requires sufficient resources on each node to run both workloads simultaneously if one computer fails, albeit perhaps with degraded performance.

A slight twist on the HA concept uses several computers or VEs to simultaneously provide the same service to its consumers. With this model, the failure of any one computer or VE will not cause a service outage. The remaining entities continue providing the service, but the load-balancing mechanism no longer sends transactions to the failed unit.
Because no service outage occurs, this model is often preferred to the simpler failover model. Nevertheless, it can be used only with certain types of applications. Applications that provide a read-only service, such as DNS lookups, scale well with this model. In contrast, applications that modify data, such as databases, must be modified to synchronize the modification activities across the cluster nodes.
Oracle Solaris Cluster implements this model via its Scalable Services functionality for web server software and some other applications. Oracle also provides this capability for a database service with the Oracle RAC product.
Figure 2.4 shows two VEs in each of two computers that are part of a scalable cluster. Each computer has two VEs that are providing the same service. This model is often used when the application does not scale well. After a failure, only one fourth of the processing power of the cluster is lost.

2.2.3 Summary
In summary, consolidated systems offer clear benefits, but they also require a return to some of the mainframe practices of the past, including more assertive efforts to manage the resources and availability of the system. Using VEs as cluster nodes improves isolation between workloads, making it easier to run more applications in the cluster.
2.3 Asynchronous Workloads
Many workloads are active for a certain period of time each workday but otherwise use few system resources. For example, employees of a small business might all work in one time zone, and their online transaction processing (OLTP) environment might have few transactions running at night. In contrast, a batch job for the same business might run for 6 hours each night. Although the business may use two separate systems for these workloads, the average utilization for each system will be less than 40%.
You can combine those two workloads on one system in several ways. For example, you can take advantage of the differences in their schedules by running both workloads on the same system, hoping that there will not be any adverse interactions between them. Alternatively, you can prevent adverse interactions by isolating the workloads with virtualization. If the two workloads need roughly equivalent resources to provide the desired response time and completion time, the graph of utilization versus time might look like Figure 2.5.

2.4 Software Development and Other Bursty Workloads
A software developer typically generates intense system activity during short periods of time when compiling software, followed by periods of little activity. This uneven workload results in computers that are under-utilized most of the time, wasting most of the investment in those systems.
If a programmer’s computer is occupied by compiling only 5% of the time, 20 programmers could share one computer if they took turns compiling their own jobs. Of course, that is not an ideal situation, and would likely reduce productivity while each programmer waited for a turn to compile his or her programs. Several optimizations can be made to that model, but the following problems must still be solved:
![]() Programmers must not be able to harm another programmer’s activities.
Programmers must not be able to harm another programmer’s activities.
![]() Some programmers will need specific versions of the operating system and its components, including development tools and test environments.
Some programmers will need specific versions of the operating system and its components, including development tools and test environments.
![]() Software development that modifies the operating system must be tested on a non-shared operating system.
Software development that modifies the operating system must be tested on a non-shared operating system.
In other words, the activities of each programmer must be isolated from the activities of the others. Each programmer needs an instance of an operating system for each target operating system. In many cases, each programmer needs an operating system instance for code development as well. However, for many types of programming, multiple developers can share an operating system instance.
Consolidation allows multiple programmers to use the same hardware resources. Virtualization provides the necessary isolation if application separation is needed.
Although this use case has been described as “software development,” the concepts apply equally well to any large set of workloads that are characterized by frequent bursts of activity and have loose response time requirements.
2.5 Testing and Staging
Many test environments are configured for a specific testing purpose but are under-utilized because testing is not performed every day. It may not make sense to reinstall an operating system and configure it each time a different test is to be run, as that practice would lead to a proliferation of test servers—which is a waste of capital investment.
Most functional testing can be performed in a virtualized environment without affecting the outcome of the tests. This setup allows consolidation of many testing environments, with one test per VE. The VE runs only while its test is being performed. Normally, only one of the VEs is running.
Other factors must be considered as well. In particular, this model is best applied to functional testing rather than performance or scalability tests. For example, one test might require exclusive access to all of the storage bandwidth of the system’s I/O bus to produce meaningful results. It may not be possible to provide sufficient isolation of this test, so tests must be scheduled at different times. Fortunately, most virtualization technologies allow VEs to be turned off individually, leaving just a single test environment running. With this approach, many teams can share one system, utilizing a small number of test systems with little unscheduled time.
Performance testing in virtualized environments is appropriate only if the workload will be deployed in a VE. Similar resource controls should be applied to the test and production environments.
Another advantage of testing with VEs is the ability to take a snapshot (a point-in-time image) of a VE and save it to disk. This snapshot can be copied, and the copy may then be used to ensure that each successive iteration starts from exactly the same state, with the same system configuration and test data.
2.6 Simplifying Workload Mobility
Systems should originally be configured with sufficient excess resource capacity to accommodate expected growth in workload needs. Even when systems are initially set up with extra capacity, workloads may occasionally outgrow the physical capacity of the system. If the computer was purchased with empty slots (e.g., for CPU or memory), additional resources can be added to the system to expand it and accommodate this growth.
Figure 2.6 shows a system at three points in time. In the first instance, the system is partially filled with a type of component, such as CPUs; the workload uses only a portion of the available resource. In the middle snapshot, the workload has grown to the point where it is consuming almost all of the physical resource. However, the system was purchased without a full complement of that resource. After filling the available physical slots, as shown in the last snapshot, the workload can grow even further without suffering performance problems.

At some point, however, further system enhancements are neither possible nor desirable. Although in some cases the workload can be broken down into multiple components and run on multiple small systems, this solution is rarely appropriate. Instead, the workload must be moved to a new, larger system. Without virtualization, that process can be time-consuming and involve many manual, error-prone steps. In addition, the new system may need to be certified for proper installation and operation—another significant investment.
Virtualization provides useful separation between the VE and the hardware. This containment simplifies the process of extracting a VE from the original system and moving it to a new system. This operation, which is often called migration, is depicted in Figure 2.7.

Three types of migration are possible, each of which is characterized by the amount of time during which the workload is not providing service, and by the amount of workload state that is lost during the migration.
“Cold” migration is simply the orderly halting of the original environment and its workload, the transfer of files from the old system to new storage or reconfiguration of shared storage, followed by start-up on the new computer. If shared storage is used to house the environment, this process is straightforward and does not require a lengthy service outage. If the application should retain its state, however, it might be necessary to save that state to persistent storage and reload the information when the VE restarts.
The other two types of migration—“warm” migration and “live” migration—do not require halting and rebooting the VE. Unlike cold migration, processes are not shut down during use of these methods, so they maintain the state of their current activities. Both warm migration and live migration require the use of shared storage for the OS, applications, data, and swap space.
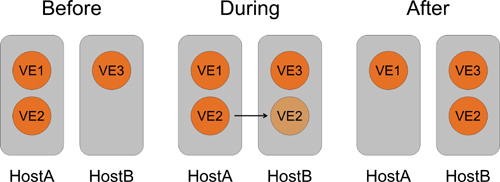
Warm migration, shown in Figure 2.8, implies a noticeable service outage, usually on the order of tens of seconds. During that period, the system effectively pauses the VE in its original system, creates a new VE in the destination system, and copies a memory image of the related processes to the target system. The processes then continue their execution on the target system and the memory image for those processes on the original system is destroyed.

Figure 2.9 depicts live migration, which differs from warm migration in terms of the length of service outage. This outage is short enough that users do not notice it. Further, applications running on other systems are not affected by the outage. Unlike warm migration, which briefly pauses the VE while its memory pages are copied to the destination, live migration methods copy the VE while it is running. After the memory pages have been copied, the VE is paused and a final set of data is transferred. Control of the VE then passes to the target system. This transfer of control often takes less than one second.
Another form of migration is the conversion from a physical environment to a virtual environment, and from one virtualization technology to another. When discussing these activities, we use the letters “P” and “V” as a shorthand notation for “physical” and “virtual,” respectively. For instance, moving an existing OS instance from a physical computer to a virtual machine provided by a hypervisor is called P2V. All four permutations are possible, and are shown at a high level in Table 2.1.

2.7 Maintaining a Legacy Operating System on New Hardware
Across the world, many older computers are running operating systems that are a version or more behind the current version. The difficulty of upgrading these computers to use new hardware or a new version of the OS varies. In some cases, software tools can be used to upgrade the operating system while the application is still running. Other systems are simply impossible to upgrade. Many systems fall between those two extremes.
For many of those systems, the best choice is rehosting the application on new hardware with new operating system features, while still maintaining the application and its configuration. Achieving this “best of both worlds” solution requires a low-level layer of software—for example, a new version of an operating system that can pretend to be an old version. The new version provides a virtual instance of an old version through a software layer, which translates old system calls into new ones. The result is the ability to maintain an older application environment while also benefiting from a new OS and new hardware.
2.8 Flexible, Rapid Provisioning
The computer industry has developed many solutions to address the challenge of deploying an operating system on a computer. Many of these software solutions rely on the use of low-level tools embedded in the hardware of the target system. Because they are simple tools, their flexibility is limited, and the provisioning software must take on almost all of the burden of OS deployment. For example, hardware features rarely include a simple command to install an OS image from a repository to local disk and boot from it. Also, because provisioning systems rely on hardware from different manufacturers, many methods must be maintained in an up-to-date state.
Virtualization can provide a rich set of tools as a foundation on which virtual environments are deployed. Its use simplifies the software that deploys virtual environments. An industry standard, Open Virtualization Archive (OVA) has been developed for VM images, enabling the deployment of an image created with one vendor’s hypervisor onto that of another vendor simply by copying the image. Those technological advancements enable the storage of preconfigured operating system images that can be copied easily to create a new VE and accessed via a shared storage framework such as SAN or NAS.
Because of the small disk footprint of OS virtualization environments, provisioning from a preconfigured master image may take less than 1 second. This speed is causing people to see system provisioning and updating in a whole new light. One example of newfound flexibility is described next.
Figure 2.10 depicts a VE provisioning system. In this diagram, the provisioning system owns the master images for the various applications used by the data center, with one image per application. Each image has been tailored for the use of that particular application, including remote file system mount points for the application, an appropriate level of security hardening, user accounts, and other factors. When a new instance of a particular application is needed, a management tool is used to perform the following tasks:
1. Clone the image.
2. Fine-tune the image—for example, with a link to the data to be used.
3. Complete the process of making the image ready for use, including steps necessary for use on a particular server.
4. Detach the image from the provisioning system and boot it on the deployment server.

2.9 Relieving Scalability Constraints
When you purchase a computer, especially a server, you must determine the maximum resource capacity that will be needed over the life of the system, including the quantity of CPUs, the amount of RAM, and other resources. If the workload grows to consume the maximum quantity of a particular resource, you must purchase a larger system and move the workload to it. Without virtualization, this type of upgrade typically means installing the operating system and applications on the new computer, which is a time-consuming and error-prone process.
With virtualization, fewer larger systems can be deployed, reducing the complexity associated with managing many systems. When a workload outgrows its system, an existing system with sufficient unused capacity can usually be found. By taking advantage of the various tools available to migrate a VE from one system to another, this process can be as simple as clicking and dragging an icon in a management application. Figure 2.11 shows a migration to a larger system, where the application will rarely be constrained by the quantity of resources in the computer.
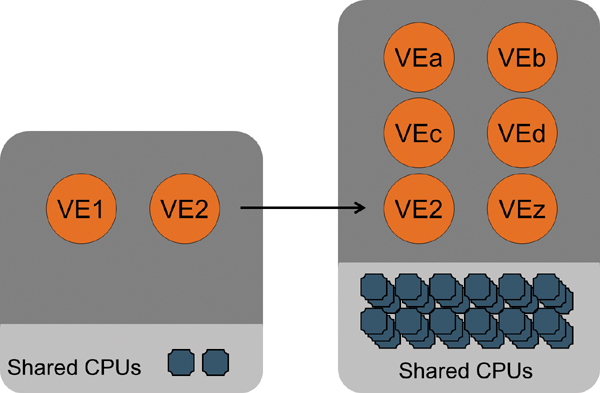
2.10 Fine-Grained Operating System Modification
A challenge of consolidated but non-virtualized workloads is the decreased flexibility of the system. One workload may need a particular version of an operating system or a specific set of tuning parameters for the operating system. One application may be tested and supported only with a specific set of operating system components installed. Without virtualization, it is sometimes difficult to meet the needs of every workload on a consolidated system.
System virtualization technologies virtualize an instance of an operating system or of a computer. In each case, one VE can be tailored to meet the needs of its workload, while another VE is customized to meet the needs of another workload.
2.11 Configurable Security Characteristics
Single-user systems have clear security needs, such as firewalls to keep out intruders. Multiuser systems share all of these needs but also have some unique security requirements of their own—for example, mechanisms to protect one user from another. Systems with VEs also have their own specific security considerations.
Some virtualization technologies offer the ability to modify the security environment of VEs. Configurable security enables you to selectively harden different aspects of a VE by allowing a VE to perform only those actions needed for its workload. An example is immutable zones, which are described in Chapter 3, “Oracle Solaris Zones.”
Any software component has the potential to create a security weakness, and virtualization software is no different. In turn, virtualization software must be subjected to the same stringent security analysis that other infrastructure software undergoes. For more on this topic, see the book Solaris Security Essentials.
If the hypervisor can limit inter-VE interactions to those already possible between separate computers, the hypervisor cannot be used as a covert channel, and the shared system’s security is not compromised compared to separate systems.
2.12 Summary
Virtualization can be applied to a diverse set of situations. The specific technologies that you choose must include features and characteristics that support your environment and intended uses.