

CHAPTER
15
RMAN Best Practices
We are often asked questions related to best practices when using RMAN. These are good questions because there is more to backing up a database than just backing up a database. We have spent many chapters talking about setting up RMAN and using it for backup, recovery, and other purposes. Now that we have covered the mechanics of RMAN, let’s discuss best practices.
Best practices are the procedures and processes you follow that help ensure you are using RMAN in the most efficient and effective way. Best practices are guidelines and are not set in stone. Rather, these are general guidelines that are flexible, because each individual enterprise is different and has different requirements. Smaller environments have different requirements than larger ones. Therefore, the best practices you will use may vary from those that others will use.
With that in mind, we provide you with some guidelines in this chapter that might give you some ideas of some best practices you will want to consider. Here are the areas we cover:
![]() Data protection
Data protection
![]() Service-level agreements
Service-level agreements
![]() Standards and processes
Standards and processes
![]() Beyond backup and recovery
Beyond backup and recovery
![]() Best practices
Best practices
However, before we dive into these subjects, let’s take a detour and look at the whole backup and recovery picture from a little different perspective. We’ll look at backup and recovery from the point of view of data protection.
Data Protection
We do a little bit of a disservice by trying to create a definition for something called backup and recovery, which is really a child process of something much bigger that we will call “data protection.” Data protection recognizes that what is important for a database is the data within it. Without that data, there is no database to manage really.
In this section we’ll discuss the following topics:
![]() Enterprise architecture
Enterprise architecture
![]() Backup and recovery
Backup and recovery
![]() High availability
High availability
![]() Disaster recovery
Disaster recovery
![]() Data governance
Data governance
![]() Monitoring and scheduling
Monitoring and scheduling
Each of these disciplines (and probably more we didn’t list) have many subdisciplines within them.
Enterprise Architecture
Why do we list “enterprise architecture” as the first discipline when it comes to data protection? Because it’s the foundation of any successful data protection architecture. When you build your architecture thinking not only of the databases in your charge, but also about the other databases in the organization, you will craft solutions that are more scalable, easier to repeat, and easier to monitor.
Enterprise solutions, if done right, will reduce risk and improve the overall success of whatever it is you are trying to do. They offer repeatable solutions to common problems, and there is a lot about backup and recovery of a database, for example, that begs for a single, repeatable, and simple process.
Enterprise solutions require more discipline when you are designing them. They require you to coordinate with more people and collect more information. Enterprise solutions almost always take more work up front, and generally cost more up front. However, if they are built correctly, maintained correctly, and if the appropriate monitoring is put in place in the beginning, the cost of a system engineered with the enterprise in mind can be significantly less.
Finally, enterprise solutions also generally take a bit more software and can offer a bit more complexity with respect to the initial setup and configuration. Sometimes, efforts even need to be made to stabilize these infrastructures. These are normal kinds of growing pains when you are trying to create a truly enterprise architecture. All of these up-front challenges, when faced and met, will be completely offset by the long-term benefits of a stable enterprise management and monitoring platform, especially when it comes to the question of data protection.
We have largely addressed the central hub of Oracle’s enterprise management infrastructure in this book when we discussed Oracle Cloud Control. When configuring a complete data protection solution, you should seriously consider using Oracle Cloud Control as your enterprise management hub.
Backup and Recovery
Of course, it’s critically important to back up and then recover your Oracle databases. When you are crafting your data protection architecture and strategies, certainly backup and recovery of your databases is important.
We almost always use the phrase “backup and recovery,” putting the term backup first. But are these terms in the right order? Certainly, chronologically they are in the right order: you have to back up a database generally before you can recover it. Also, when you are just learning how to be a DBA, the backup part is the logical beginning for that education you require. You can’t, after all, restore a database unless you have a backup from which you can source that restore exercise.
However, this name betrays what should be the true order of operations that you should be following when it comes to backup and recovery impacting our thinking process when we think about database backups.
For example, how many times have you first asked yourself about how you were going to back up a database? Did it occur to you that maybe you needed to understand how you were going to restore that database first? Although it might seem like the answer to the first question depends on the answer to the second question, we would disagree. We would say that the answer to the second question is a dependency to even beginning to figure out the answer to the first question.
We are often asked to determine a DBA’s skill set. One of the metrics used to determine the experience level of a DBA is to explore their thinking about recovery and backup. For example, the junior DBA will be struggling to understand backup and recovery. You can see these struggles as you question them about the mechanical rudiments of how to back up a database. Often they will struggle more on how to recover those backups. The bottom line is that the junior DBA will need help in most recovery situations. They will need the assistance of a senior DBA or Oracle Support. You would never depend on someone at this position to architect any kind of recovery solution. They simply are not ready.
As the DBA progresses in experience, they start to think about and experience various recovery situations and they learn more complex recovery techniques. At some point they have progressed past the junior level into some middle-of-the-road position. You can see this in interviews as they respond to questions about database failures with confidence, displaying a set of skills that say, “I know how to deal with this issue!”
The principal difference between the middle-of-the-road DBA and the truly senior DBA, at this point, is in how they respond to the recovery questions. The middle-of-the-road DBA usually tells me what they would do given a particular situation. They still lack experience, but they have the learning. The truly senior DBA will tell me about what they did in that (or a similar) situation. They not only have developed the skill set, but they have deployed it in real life with success.
We think it’s important to answer the question “How do we back up databases?” You first need to understand the question “How do these databases need to be restored?” It’s important to understand that the restore question isn’t just about the mechanics of the restore; it’s also about understandings the stakeholders with respect to their expectations and needs. It’s about providing scalable services for the enterprise and maintaining control while also providing flexibility. In the end, it’s about maturity.
So, that is the reason we’ve suggested that we should be saying “recovery and backup.” One truly informs the other. Without exploring the first, we cannot properly implement the latter. Therefore, in the rest of this chapter, we will address these questions—which lead to an answer that we call “the enterprise recovery and backup solution.”
Keep in mind that an overall solution is not going to just address backup and recovery with RMAN. In many cases, based on what you will learn, your solution may involve requirements for high availability (HA) and disaster recovery (DR). You need to keep the entire landscape of the recovery solution in your mind when you proceed to architect a solution and not get focused on just the backup and recovery aspect of it. Yes, this is a book on RMAN, but the overall architecture is more than just RMAN, of course!
Something else to consider as we start discussing architecture and infrastructure: As we describe some of the things we recommend you do, you might feel like this is an awful lot of work. You might wonder why it is that some of the details suggested, such as using SLAs, are so important. You might think that things are under control; there have been no outages, so why should you care?
There are a number of reasons you should care, of course. We’ve already mentioned several of them, and we’ll mention several others as this chapter continues. However, there is one reason that we want to point out to you in particular. It is something that can impact even the best and seemingly most stable of infrastructures: the problem of scale. It may be that you crafted the most magnificent and well-documented backup and recovery infrastructure that has ever existed. You have SLAs, you’re meeting requirements, you constantly test, and the results are flawless. However, you might have also noticed that lately your backups are taking just a little longer. Maybe during your recovery testing the database that took an hour to restore now takes two hours. These are subtle indications that your infrastructure is starting to suffer from scaling problems. We’ve seen this happen a number of times. We’ve seen the subtle signs that no one else really noticed because things were running so well that they really didn’t look at areas such as backup times at all. They didn’t notice the quiet trends that were there and growing.
So, the bottom line is that every infrastructure needs to be reviewed from time to time to see not only the obvious problems you know about, but also the nasty problems that are just waiting to show up some day.
What are the things to consider when looking at the issue of backup and recovery when you are planning your architecture? You need to consider the following:
![]() Current and renegotiated backup and recovery SLAs (formal or informal)
Current and renegotiated backup and recovery SLAs (formal or informal)
![]() Current sizes of existing databases
Current sizes of existing databases
![]() Current backup times of these databases
Current backup times of these databases
![]() Anticipated growth of existing databases
Anticipated growth of existing databases
![]() Anticipated growth of backup times for existing databases
Anticipated growth of backup times for existing databases
![]() New databases that will be created
New databases that will be created
![]() Initial sizes and anticipated growth of new databases
Initial sizes and anticipated growth of new databases
![]() Creation, removal, and refreshing of databases during various cycles such as development, testing, and QA
Creation, removal, and refreshing of databases during various cycles such as development, testing, and QA
![]() Retention criteria of both the databases and the database backups
Retention criteria of both the databases and the database backups
These are a few of the numerous considerations you need to make when looking at your solutions for backup and recovery.
High Availability
Along with the question of backup and recovery, there are still many other questions that need to be asked. The next logical area that needs to be addressed is high availability (HA). The primary purpose of HA is to abstract the user from the system as a whole and prevent them from suffering from any single point of failure within that system.
In the Oracle world, HA comes in many forms:
![]() Oracle Clusterware
Oracle Clusterware
![]() Oracle Real Application Clusters (RAC)
Oracle Real Application Clusters (RAC)
![]() Various network and hardware redundancies
Various network and hardware redundancies
HA adds additional complexities into the overall database infrastructure, and sometimes these complexities can be overlooked and lead to unexpected failures. This can be demonstrated by an experience that we had with a customer once. They thought that they had architected a very robust HA configuration (We’re changing some details to protect the identity of the customer, but the general information is correct). The customer was running a RAC cluster with several instances. They had designed what they thought was a very robust HA architecture with two separate networks supporting user connections and two additional networks supporting the cluster interconnect. The disks were running ASM with triple mirroring, offering a great deal of redundancy.
However, one day, everything just stopped. Both nodes fenced and then shut down, and when they restarted, the instances would not come up. After a great deal of investigation, the truth emerged. When the disk array was installed, everyone believed that it was configured with two different disk controller cards. They believed that the array provided them with multipathing as well as redundancy should one of those cards fail.
Upon trying to recover the disk array, it was found that there was only one card active on the disk array. The second card was sitting in the array, ready to go, but it had never been connected or activated. As we looked at the Fibre Channel switch, we found that there was even a cable that had been run to the array, but it had apparently just never been connected. The moral of the story is that HA is complex, and it’s so easy to just miss one little thing. We only tell this story as a cautionary tale. Architecting a robust HA solution is an incredible part of providing for data protection. It just requires a great deal of careful planning and designing, and a good peer review isn’t a bad idea either.
There is another side of HA to be aware of, one that might not seem immediately apparent. Sometimes you can have a system that is so highly redundant that when something does fail, nobody notices. The thing just keeps on humming, running along—and nobody notices that a disk failed or that a network cable has become disconnected. If you are not monitoring your system and its components for failure, then you might just miss those failures.
This can result in a system that appears to be stable but in fact is becoming more and more unstable over time. This highlights the importance of monitoring as a part of an overall enterprise data protection strategy. HA strategies add a number of additional working pieces. In a way, it reminds me of when I was growing up in Oklahoma, where we used to say that the difference between a two-wheel drive and a four-wheel drive was that the four-wheel drive could get you stuck much further away from civilization. As such, a four-wheel drive can give you a bit of a sense of invulnerability. An HA architecture can have somewhat of the same impact.
Finally, adding any kind of HA infrastructure will increase the overall capital and operational costs of your infrastructure. This is something to keep in mind. You should be able to identify these costs to the stakeholders, ensuring that they understand the overall costs of their requirements. We often find that stakeholders will ask for uptimes of five 9’s (99.999), but when presented with the costs of meeting such an objective, they quickly reduce those requirements to something that their budget can afford.
Disaster Recovery
Sometimes people confuse HA with disaster recovery (DR). HA is designed to hide various failures from the user in such a way that the user never sees the failure. However, there are situations that HA cannot really address very well, such as the fallout from a tornado, tsunami, or earthquake. It is for these kinds of disasters that we architect DR plans as a part of our overall data protection plan.
If there are additional costs required for HA solutions, there are even greater costs associated with providing DR services. Often this cost is taken for granted by stakeholders who ask for things, not appreciating the investment required. It is important in the overall planning process for a data protection scheme that we equate the requirements given to us by stakeholders into dollars so that they can better understand the costs of what they are requiring.
Data Governance and Security
You may think you have bought the wrong book when we mention data governance and security (in fact, one could argue that these should be treated as separate topics—but for the purposes of this chapter we can safely combine them). What do these topics have to do with backup and recovery or even HA or DR? It turns out that the answer is, quite a lot. Data governance and security cover a lot of ground, but essentially together they have to do with the integrity, ownership, and security of data within your database. How is it that this kind of responsibility intersects with backup and recovery architecture?
First, imagine the potential impacts of the loss of a backup to some competitor with little integrity. Or, perhaps, consider the relationships in the data in disparate databases that are all used by a single application. Although an Oracle database can maintain internal relational integrity within that database, often there are other databases with related data that an application will access at the same time. There is no built-in constraint mechanism to ensure the integrity of those external relationships.
Imagine that there is an application that depends on databases ABC, DEF, and XYZ. Imagine that the ABC database fails, while DEF and XYZ remain active. In this case, your backup and recovery, HA, and DR strategies need to consider these relationships, especially when it comes to recovery of the ABC database. For example, if you cannot perform a recovery to the point of failure (perhaps the online redo logs were lost), then what is the relational impact on the surviving databases? It is best to plan for such problems before they happen—and not after. Believe us, we’ve been there.
So, data protection and data governance are really synonymous. One of the tasks within data governance is to assign ownership to the data within the database. These owners (sometimes called governors) are responsible for all aspects of the data assigned to them, including access control. Protection of the data exceeds protection of the data within the active database. The protection of the data in the backup images, the disaster recovery databases, and any other places that the data might be stored needs to be considered when you are developing your enterprise data backup and recovery architecture and its accompanying standards and requirements.
From the security point of view, at the end of the day almost anything related to data security really is a dependency of proper data governance. In this respect, the owner of the data is responsible for all aspects of that data, including who has access to it and what kind of access. They also control how the data is used and how it is shared, and they are responsible for the classification of the sensitivity of the data. All of these elements have direct impacts on the overall data recovery solution you will need to deploy for your databases.
Notice that we have significantly increased the scope of the things you need to consider when developing enterprise backup strategies. Clearly, we are talking about more than just encrypting data as it’s moved to backup media. It’s about controlling who has access to and can restore backups. It’s about controlling where backups can be restored to, as well as what requirements revolve around restoring backups to various destinations (requirements such as redaction or specific needs for data subsetting, for example).
All too frequently these architectural issues are almost handled in a void—each defined on the fly as the needs arise, with the wheel being reinvented numerous times. This does not happen, hopefully, when we think about backup and recovery in terms of an overall enterprise data protection environment. This approach is a huge mistake and creates huge risks that need to be avoided.
Monitoring and Scheduling
Perhaps the most overlooked aspect of the development of an overall enterprise backup and recovery architecture is monitoring and scheduling. Often the solutions chosen are not truly enterprise solutions, and these solutions do not scale well.
For example, many places will use shell scripts to execute backups. These shell scripts are sometimes stored locally on each individual server, or perhaps they are stored on a common NFS mount. Each of these solutions provides significant change management issues. The problem becomes even more complex when you try to manage different versions of the backup script, for whatever reason. In large enterprise environments, the management of large numbers of backup scripts across your infrastructure can be complex and risky.
Then there is scheduling of these shell scripts. Often we find that customers will use a local scheduling utility, such as CRON, to schedule these backups. One of the shortcomings of this solution becomes apparent if a server itself goes down and CRON is not able to start the backups. We’ve seen cases where databases had been created and the required CRON jobs to back up those databases did not get created. This can certainly cause all sorts of issues if these missing backups are allowed to continue unchecked.
This leads us to the topic of monitoring and reporting on backups. It is important to have ways of crosschecking the databases in your environment and their current backup status. It’s important to know when backups occurred and whether they were successful or failed. It’s also important to have crosschecks of all the databases in your environment and whether they have ever been backed up.
All of these issues need to be considered when creating your overall data protection solution. You can have all the tools in place, but if they don’t work and you don’t know they are not working, then all of your work was just wasted. With this in mind, let’s move on to a discussion of just how we create a professional data protection solution.
Best Practices
Now we return to the subject at hand: best practices. In this section we discuss the following topics, suggesting some best practices you will want to consider employing:
![]() Service-level agreements
Service-level agreements
![]() Standards and processes
Standards and processes
Service-Level Agreements
Service-level agreements (SLAs) are negotiated between people providing services (in this case, you the DBA) and those who are utilizing the services. An SLA does not define how you are providing the service, but it does define the level of service you are providing. For example, an SLA might define that you are providing support services between 8 A.M. and 5 P.M., Monday through Friday.
Some places use SLAs, some don’t. We prefer SLAs because they tend to clarify expectations. They eliminate confusion and, trust us, when the chips (or the database) are down, there is already enough confusion to deal with. SLAs do not need to be complex, and it’s much easier to deal with them when you have standardized your services.
Two primary parameters should be defined in an SLA. These are the recovery point objective and the recovery time objective for the databases covered by the SLA. The recovery point objective defines the amount of data loss that is allowable in the event that the database fails.
The recovery time objective indicates how long a database outage can exist. This defines the tolerance for downtime that the database can have. Together, these two parameters define the decisions made with respect to the services that will be required.
In order to standardize services, we create what is commonly called a “services menu.” This menu defines the services you commonly offer to your user community. It can also define the costs of those services. The defined recovery time and recovery point objectives of an SLA will feed into the services that are selected from the services menu.
Additionally, we like to negotiate what is called a “technology menu,” which defines the technologies the entire community agrees are going to be used on a regular basis. Together, these two tools make the clear definition of an SLA much easier to complete. Let’s look at the services menu and the technology menu in a bit more detail.
A Services Menu
Oftentimes we ask customers open-ended questions such as, “How do you want to back up your database?” or “Do you need disaster recovery services?” These are dangerous and expensive questions. In even a moderately sized enterprise, open-ended questions like these can create a snarl of different backup and recovery requirements. Perhaps the question is one of availability.
Ask a user what kind of availability they require and they will usually answer, “We need it up all the time,” or they will try to be accommodating and say they only need it from 9 to 5, when in fact they really have developers on the system at all hours of the night. We’ve had many times when the latter happened, only to find out when we took the database down at 6 P.M. for maintenance that we knocked 100 developers off the system.
A services menu is often a much better solution. A services menu provides a list of limited service offerings for stakeholders to choose from. It is essentially telling the stakeholders, “These are the services we can offer you, and (optionally) this is what it will cost you.” A services menu may contain two or three options, or it might contain several options. It may be a fixed set of options or it might be à la carte. Here is an example of a menu for data protection services:
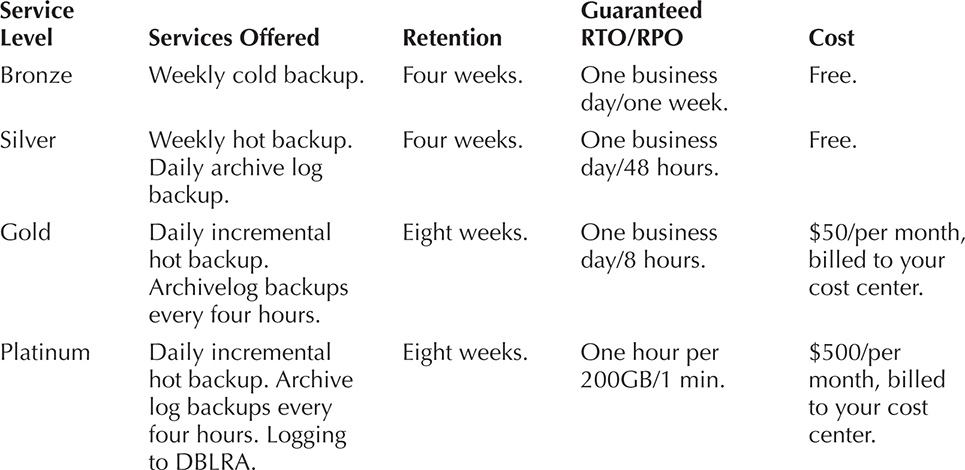




Notice that this menu provides both standardization and flexibility for the customer and the enterprise. The flexibility comes at a price that reflects the additional costs and effort required to customize those services. Note that just because we provide some customized services does not mean that significantly impacts the enterprise infrastructure we want to create. Indeed, whatever we do in the menu, we need to ensure it is easy to implement and standardize within the new infrastructure, processes, and tools we will be using. If you are going to include a service that is not easy to standardize, think twice about it and then make sure you charge sufficiently for it, reflecting the complexity it’s adding to the organization.
You might look at the menu and wonder about the costing model that’s demonstrated. In many cases we have added both fixed costs (well, annually recurring) and monthly recurring costs. It’s often important to consider that when you sell services, you are not just selling the current hardware you have on hand. You also need to be costing your services out in such a way that you can continue to buy new hardware to support future needs, and don’t forget the hardware refreshes, too. Someone needs to pay for those. Finally, don’t forget that there is a cost in the initial configuration that needs to be absorbed.
A Technology Menu
You might have noticed that in the services menu we didn’t mention anything about how or where we were going to provide the services. We have abstracted the mechanisms from the stakeholders. This simplifies the decision-making processes. They simply decide what services they want and how much they can pay. Sometimes it’s going to be a balancing act between what they think they need and what they can pay for; however, as far as hardware, infrastructure, and such go, they really don’t need to play in that space.
You and others in the IT organization do need to play in that space, however. Given that many enterprises often employ many people, and those many people have many different ideas of how to perform a task, there can be lots of confusion and even arguments over the technologies that get used. You would be amazed at how much time can be wasted just trying to decide if we are going to use shell scripts, OEM, Java, Python, or whatever for some basic project with simple deliverables. Enter the technology menu.
The technology menu clearly identifies the following for the enterprise:
![]() Emerging technologies
Emerging technologies
![]() Supported technologies
Supported technologies
![]() Desupported technologies
Desupported technologies
The technology menu provides a quick list of how we do things. Let’s look at each of the different sections of this list and what they mean and how technologies are allocated to these sections.
Emerging Technologies The emerging technologies section lists new technologies that we are currently investigating but are not approved for common use. Usually these are bleeding-edge technologies that offer significant advantages over currently supported technologies. Not all technologies on the list are bleeding edge, though. New versions of the Oracle Database software, including even the security-related updates, might well appear on this part of the list for a while. Once they are tested and approved, they would be moved on to the supported technologies section.
The following rules typically exist for an emerging technology on the list:
![]() It goes through a process to be added to the list.
It goes through a process to be added to the list.
![]() A process exists for projects to be approved to use the technology.
A process exists for projects to be approved to use the technology.
![]() Once approved, a project may use the technology.
Once approved, a project may use the technology.
![]() A process exists to move the technology to the supported technology list.
A process exists to move the technology to the supported technology list.
Supported Technologies Supported technologies are those technologies in the enterprise that have been tested and approved for use. They have standards written for them, and they have processes and procedures written around how they are used. They are stable and commonly in use. Each item is listed with specific supported versions so that the enterprise has a consistent set of software running.
With respect to data protection technologies such as the Oracle Database itself, Cloud Control, RMAN, and Data Guard, all should be listed as supported technologies. Supported technologies feed into establishing standards for the enterprise. Standards are important, especially when it comes to data protection. We will cover standards later in this chapter.
Desupported Technologies As technologies age, they become obsolete. Versions change, vendors no longer support products, and so on. However, it is often not possible to just pull the plug on these kinds of products. Many times there are vendor dependencies on products. For example, a particular application vendor might not yet have certified on a supported version of the Oracle Database. We can’t just upgrade these databases on a whim, yet we don’t want new projects to start using these desupported versions of the database software either.
In most cases, these technologies will have been on the supported list. When the technology menu is created, processes are created that regularly review the supported technologies list and move any technologies that are no longer going to be supported for new projects, but still exist in the enterprise, to the desupported technologies part of the list. Once the software is permanently removed from the environment, it should be removed from the list completely.
Standards and Processes
Standards and processes are ways of defining what best practices you are following and how you will follow them. The technology menu and the services menu are both standards. How these standards are implemented (such as how you actually perform the backup of the database) is a process.
With respect to backup and recovery, there are a number of standards and processes you will want to define. These might include the following:
![]() The backup standards and process you will use. For example, you might decide that your standard is to use incremental backups with one full and seven incremental backups. You might also determine to perform monthly archival backups.
The backup standards and process you will use. For example, you might decide that your standard is to use incremental backups with one full and seven incremental backups. You might also determine to perform monthly archival backups.
![]() Your database retention standard and the process to manage that standard you will use. For example, you might decide that your retention policy will provide the ability to do point-in-time restores for 30 days.
Your database retention standard and the process to manage that standard you will use. For example, you might decide that your retention policy will provide the ability to do point-in-time restores for 30 days.
![]() Backup media management/tiering standards and processes you will use. For example, you might have a 90-day backup retention policy. You may want to keep the first 30 days on local disk storage, and you might choose to keep the remaining 60 days on cheaper tape storage. Your policy would define how you will move these backups between these two backup tiers.
Backup media management/tiering standards and processes you will use. For example, you might have a 90-day backup retention policy. You may want to keep the first 30 days on local disk storage, and you might choose to keep the remaining 60 days on cheaper tape storage. Your policy would define how you will move these backups between these two backup tiers.
![]() The database restore standards and processes you will use.
The database restore standards and processes you will use.
![]() How you will schedule backups. For example, you might choose to use Oracle Cloud Control to schedule your database backups (which we strongly suggest).
How you will schedule backups. For example, you might choose to use Oracle Cloud Control to schedule your database backups (which we strongly suggest).
Now that we’ve talked about standards and processes, let’s talk about best practices.
RMAN Best Practices
So, we have talked SLAs, standards, and processes; now let’s talk about best practices with respect to RMAN. First, it’s difficult to define best practices that apply in all cases. Therefore, the best practices we discuss here are more guidelines to help get you started in defining the best practices that will apply in your situation.
That being said, here is a list of recommend RMAN best practices:
![]() Determine the available I/O throughput for the devices to which you will be backing up. Oracle’s Orion I/O testing tool can be used for this purpose. The results of this testing will provide you with metrics required to determine exactly how fast your database can be backed up and how fast it can be restored. This testing can also determine if there are bottlenecks in your I/O subsystem that need to be addressed. Know the speeds and feeds of your entire architecture. This really is rule number one.
Determine the available I/O throughput for the devices to which you will be backing up. Oracle’s Orion I/O testing tool can be used for this purpose. The results of this testing will provide you with metrics required to determine exactly how fast your database can be backed up and how fast it can be restored. This testing can also determine if there are bottlenecks in your I/O subsystem that need to be addressed. Know the speeds and feeds of your entire architecture. This really is rule number one.
![]() Remember that the requirements of the business for recovery (with respect to both time to recover and data loss) drive the backup and recovery solution.
Remember that the requirements of the business for recovery (with respect to both time to recover and data loss) drive the backup and recovery solution.
![]() Automate your database creation processes to ensure that backups are always scheduled when a database is created.
Automate your database creation processes to ensure that backups are always scheduled when a database is created.
![]() Maintain consistency as much as possible in your database backup, recovery, and RMAN-related configurations.
Maintain consistency as much as possible in your database backup, recovery, and RMAN-related configurations.
![]() When possible, run your database in ARCHIVELOG mode and use online backups. Although it might be tempting to run development and other databases in NOARCHIVELOG mode, if at all possible, you should run all your databases in the same logging mode.
When possible, run your database in ARCHIVELOG mode and use online backups. Although it might be tempting to run development and other databases in NOARCHIVELOG mode, if at all possible, you should run all your databases in the same logging mode.
![]() For best performance, define an Oracle Fast Recovery Area on the local disk and back up to that set of disks first. If you wish to use less expensive or slower storage, use that as Tier-2 storage.
For best performance, define an Oracle Fast Recovery Area on the local disk and back up to that set of disks first. If you wish to use less expensive or slower storage, use that as Tier-2 storage.
![]() Use RMAN’s stored configuration capabilities. Standardize these configurations and audit them on a regular basis.
Use RMAN’s stored configuration capabilities. Standardize these configurations and audit them on a regular basis.
![]() Define your RMAN retention policies.
Define your RMAN retention policies.
![]() Be careful not to define backup retention policies in more than one place. For example, if you back up your database to an SBT tape device, RMAN should maintain the retention alone—do not allow the tape software to also control retention of the backup media.
Be careful not to define backup retention policies in more than one place. For example, if you back up your database to an SBT tape device, RMAN should maintain the retention alone—do not allow the tape software to also control retention of the backup media.
![]() To ensure optimal performance of the database and database backups, never back up to disks that contain database data.
To ensure optimal performance of the database and database backups, never back up to disks that contain database data.
![]() Carefully parallelize backups, without over consuming CPU or I/O resources.
Carefully parallelize backups, without over consuming CPU or I/O resources.
![]() Never allow RMAN to lose track of the location of your backup sets. Ensure that RMAN is always used to move backups between various backup media tiers. Also ensure that if you back up to tape that you use the RMAN MML layer, rather than tape vendor backup software that does not update the database control file or the RMAN recovery catalog.
Never allow RMAN to lose track of the location of your backup sets. Ensure that RMAN is always used to move backups between various backup media tiers. Also ensure that if you back up to tape that you use the RMAN MML layer, rather than tape vendor backup software that does not update the database control file or the RMAN recovery catalog.
![]() Define and use a standardized set of RMAN configuration settings.
Define and use a standardized set of RMAN configuration settings.
![]() Use the RMAN recovery catalog. Use the virtual private catalog to separate the different backup and recovery environments (production, test, and development). This will make duplication of databases easier in your environment.
Use the RMAN recovery catalog. Use the virtual private catalog to separate the different backup and recovery environments (production, test, and development). This will make duplication of databases easier in your environment.
![]() Keep track of all the databases you have in your environment and crosscheck that list against the RMAN recovery catalog to ensure that all the databases in your environment are actually being backed up. Oracle Cloud Control–related views can provide the source of your database configuration information.
Keep track of all the databases you have in your environment and crosscheck that list against the RMAN recovery catalog to ensure that all the databases in your environment are actually being backed up. Oracle Cloud Control–related views can provide the source of your database configuration information.
![]() If backup space availability is of greater concern than restore times, or if your backup strategy includes backups to tape, then use incremental backups. Ensure you enable block change tracking.
If backup space availability is of greater concern than restore times, or if your backup strategy includes backups to tape, then use incremental backups. Ensure you enable block change tracking.
![]() If restore times are superior to space availability, use incrementally updated backups.
If restore times are superior to space availability, use incrementally updated backups.
![]() Practice database restores from your production backups often.
Practice database restores from your production backups often.
![]() If you are using Active Data Guard, you should offload your backups to the Active Data Guard database.
If you are using Active Data Guard, you should offload your backups to the Active Data Guard database.
![]() We strongly recommend that you back up to disks that are managed by ASM. Provision the inner sectors of the disk for backups. The outer sectors of the disk are faster and should be reserved for data. The inner sectors are slower and should be reserved for backups.
We strongly recommend that you back up to disks that are managed by ASM. Provision the inner sectors of the disk for backups. The outer sectors of the disk are faster and should be reserved for data. The inner sectors are slower and should be reserved for backups.
![]() When backing up a database with many files of different sizes, use the section size parameter to further parallelize backups.
When backing up a database with many files of different sizes, use the section size parameter to further parallelize backups.
![]() Encrypt your backups.
Encrypt your backups.
![]() If you are backing up tablespaces where data needs to be encrypted, use TDE tablespace encryption rather than TDE column–level compression to eliminate double encryption in the resulting backups.
If you are backing up tablespaces where data needs to be encrypted, use TDE tablespace encryption rather than TDE column–level compression to eliminate double encryption in the resulting backups.
![]() Remember, sometimes simpler is better. Complex architectures can complicate performance tuning.
Remember, sometimes simpler is better. Complex architectures can complicate performance tuning.
Of course, no list is really complete. However, we feel this list gives you a good start and provides you with some things to think about.
Summary
In this chapter we tried to provide you with some nontechnical guidelines and best practices to follow with respect to RMAN. As you can see from the contents of this chapter, and from many of the other chapters in this book, there is a great deal more to database backup and recovery than just backing the database up or recovering it!
