
Chapter 2. Auditing and Assessing Your IT Ecosystem
How do you avoid the IT complexity dilemma? First things first: to deal with complexity in your application or your IT organization, you need to understand where it comes from.
The first step in understanding complexity is to perform an audit of your application, your teams, your delivery and operations processes, your IT organization, and your company as a whole, to determine what parts of your system contribute to your excess complexity.
Auditing Versus Assessment
Auditing and assessment are two distinct terms that are often used somewhat interchangeably to describe the process of understanding the components that make up a complex system, such as an enterprise application. But what’s the difference between the two?
Auditing is typically defined as the process of creating a controlled inventory. In this context, the word controlled implies governance. For example:
-
A bank can count its money, but it has its records formally reviewed by an independent agency for accuracy when it undergoes an audit.
-
A company keeps its own financial records, but if it is about to be acquired or undergo a merger, its records are audited independently to ensure they are accurate.
-
If you live in the United States, you keep track of your personal finances and you submit records to the Internal Revenue Service every year to specify how much income tax you owe. Occasionally, the IRS audits individuals to validate that the information they are providing is correct and accurate. Other nations have similar processes.
In an IT audit, we are talking about determining, formally or informally, the components of our applications, the infrastructure they are running on, and the systems and processes they utilize.
Large enterprises may invest hundreds of thousands of dollars in such an audit, often hiring an outside auditing firm, and the process might take six months or more. Alternatively, an architect might create a quick diagram in Visio, print it out, and put it in a logbook. Both are essentially audits, but the former is much more formal than the latter.
Assessment is what happens next. Once you know what components make up your systems and applications, you perform an assessment to understand how they work together, what each component is used for, why it exists, how it’s important, and the overall impact it has on the system as a whole. Often, this is part of the audit, but it doesn’t have to be. Assessing often implies grading, scoring, or evaluating. For example:
-
A teacher creates a test as an assessment to see whether their students understand the material they were taught.
-
A coach evaluates how an athlete performs to assess how they can utilize the athlete in a team setting.
-
A voter assesses the pros and cons of each side of an issue before casting their vote.
Auditing and assessing are complementary processes that can be employed together to determine and evaluate the makeup of a large, complex enterprise application infrastructure.
When applied to IT applications, auditing and assessing are more akin to a survey. A survey is a measurement tool that provides a view of the structure and architecture of a system, and that is built and maintained outside the system. It gives us an indication of how our application, infrastructure, business, or system operates and how it’s structured.
What Do You Measure?
In business, including application development and IT infrastructure, our measurements are built around people, processes, and technology:
- People
-
Do we have the right skill sets in the right places to allow our business to function successfully? Are our employees engaged and satisfied? Are we utilizing our people most effectively?
- Processes
-
Do we make good and timely decisions using the right data? Are our business processes efficient and effective? Do we use our time or resources inappropriately?
- Technology
-
Do we have the right technologies for our business to function optimally? Are those technologies running in the right infrastructure? Are we properly utilizing all aspects of our infrastructure? Do we waste technology we have purchased by not using it effectively? Are we inefficient because we have not acquired a piece of technology that could help us?
Determining what to assess is important but highly case dependent. Focusing on questions like those shown here is a good way to brainstorm what to measure. This gives you a great perspective on what to look at when conducting your survey.
Why Do You Measure?
You can’t track how your organization progresses in its growth without understanding the state of the organization and how it’s currently functioning. To determine where you can improve, you must measure where you are currently.
Measure-Try-Measure-Refine
Before you make any change to how a system operates, you need to determine how that change might affect the system. In order to do that, you need to measure the system’s current state. Then, after making the change, you can measure again and assess the impact. This allows you to refine your attempt and measure again. The result is a loop, called the Measure-Try-Measure-Refine loop, illustrated in Figure 2-1.

Figure 2-1. The Measure-Try-Measure-Refine loop
This is a basic process of cyclic improvement, and it goes by many other names. It’s very similar to the Plan-Do-Check-Act (PDCA) or Plan-Do-Study-Act (PDSA) cycle, otherwise known as the Deming cycle.
In this version, we start at the top with the Measure step. We measure our system to understand its current state before making any changes.
We then move on to the Try step. Here, we attempt a change to see whether it will positively or negatively impact our system. Does it help us or hurt us?
To answer that question, we then do another round of Measure. We measure our system again and compare the current state with the original state to see how it has changed. This allows us to determine whether what we tried improved our situation or made it worse.
We then Refine our attempt to account for the problems or expand on the benefits. The net result should be that we are in an improved situation.
This leads us back to the top, where the cycle begins all over again: Measure-Try-Measure-Refine, then repeat. This is the process of continuous improvement.
The key point is that we must measure before and after we make any change and determine the difference between the two measurements in order to evaluate the impact of our attempt. You can’t tell if you’ve improved unless you know your situation before and after every change you make.
The Benefits of Measurement
Every change has a cost associated with it. Those costs may be tangible (engineering costs, testing costs, the operational impact of a change, etc.) or intangible (e.g., opportunity costs). Sometimes we make a change that improves our situation, but the cost outweighs the value of the improvement. We may have made a localized improvement, but overall we are not better off because the cost was too great. Only by measuring can we understand the real value of the change we made, as well as the associated cost.
Another benefit of measurement is that it lets you know when you’re done. The cycle could go on forever, but sooner or later the improvements you are able to make will no longer be worth the cost of making them. As Figure 2-2 illustrates, measurements will tell you when to stop: when you have reached your goal, or when you have made as many improvements as you can without incurring unreasonable costs or burdens.

Figure 2-2. Measure to determine when it’s time to stop
In summary, measurement helps us:
-
Determine our current system’s state and where we are in our process so we know where to focus our energies to improve.
-
Analyze our changes to see whether they’ve made things better or worse, or improved things enough to justify the cost of the change.
-
Determine when it is time to stop attempting to make improvements.
How Deep Do You Measure?
Earlier I gave the example of a large enterprise spending six months on a large, formal system audit. This is a form of measurement. It will give a complete view of the state of the system that is accurate and highly detailed—but as depicted in Figure 2-3, it will show the system state as it was six months ago, when the audit started.
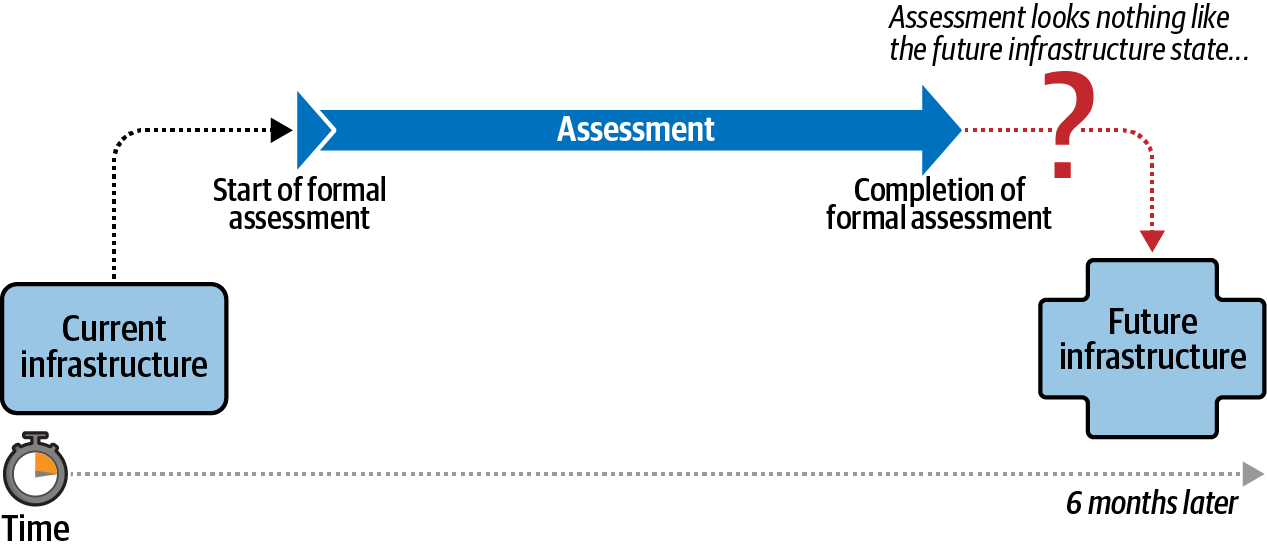
Figure 2-3. A formal assessment is inaccurate the moment it’s completed
Such an audit is not of any use to us in managing systemic improvements, when we are trying to incrementally improve between each measurement cycle. If we can only make small changes every six months at the end of a formal audit/measurement cycle, then we can’t make changes very quickly, and our entire Measure-Try-Measure-Refine process fails. In order to confront the IT complexity dilemma, we need to break out of these long, unwieldy, and expensive evaluation cycles. The duration of our Measure-Try-Measure-Refine loop should be measured in days or hours, not in months or years.
So, when you create an inventory of your system, when you conduct a review of your applications, when you measure the current state of your application and its infrastructure, how deep should you measure the system?
One viewpoint says that you need to have a deep and detailed view into your application and its infrastructure. You need to know about every CPU, data memory chip, network segment, cable, application procedure, service, node, etc. If you don’t know everything, you know nothing. This viewpoint is what leads to the six-month formal external audits we talked about previously. Requiring precise measurement of everything means you can’t possibly know everything you need to know in a timely manner. It can also lead to knowledge without understanding: by the time you have measured everything, you have no context for applying the understanding you’ve gained.
Too much data isn’t always helpful, especially if the cost of getting that data makes the data inherently less useful. If it takes you six months to collect the data, you can’t use that data to determine what changes you need to make today to make things better tomorrow.
Instead, you will need to compromise. You’ll need to collect some subset of the data, with the expectation that the subset you collect gives you the insight you need to extrapolate the rest of the data. Figure 2-4 illustrates this.

Figure 2-4. Rather than doing a full assessment, you can do a partial assessment and extrapolate the results
But what data do you need? Let’s assume you have a large system that is running many large applications and you want to do an inventory that lets you know how many infrastructure components are needed by each application. You are doing this so you can compare these numbers to the amount of inventory you actually have on hand and understand whether you have excess capacity or are running your services too lean. Taking a complete inventory would be too expensive and take too long—but how can you determine what you have without doing a full inventory of the entire system? Let’s look at some possibilities.
Option 1: Look at only some attributes of the inventory (such as compute) and ignore others (such as networking or storage).
One option is to look at only a subset of your infrastructure. For example, you might look only at the CPUs. How many CPUs do you have? How powerful are they? How much raw computation power does that represent? You can then determine how much computation power you have assigned to each of the parts of each of your applications.
In focusing only on raw computation power, you’re ignoring other important aspects of the infrastructure an application requires, such as memory, storage, and network resources. The extrapolation you make is that if one application has twice the compute resources as another, you can assume it also has twice the networking, memory, and storage resources.
However, this assumption is rarely accurate. Just because an application has twice as many CPUs assigned to it as another, or has CPUs that are twice as powerful, does not mean that those CPUs have twice as much memory, or twice as much database storage, or twice as much networking capacity.
Using one type of resource as a proxy for your entire system inventory leads to inaccurate data and bad expectations.
Option 2: Look at a single application or service in its entirety, and ignore all other applications/services.
Another approach you can take when creating your inventory is to look at a subset of your applications or services. For example, you might decide to investigate a single application in its entirety. You determine how much computation it requires, and how much memory, storage, networking capacity, etc. You figure out what services compose this application, and what external services the application requires to operate. You make a complete inventory of everything required to run this one particular application.
Then you make the assumption that all the other applications or services in your system will have a similar set of requirements, based on some point of comparison. For example, if your analyzed application needs 25 servers and another application needs 50 servers, you can assume that the other application uses twice as much everything as your analyzed application.
This is perhaps a bit more accurate than option 1, but as you can imagine, it is still inaccurate. How much infrastructure a given application or service requires does not have much bearing on how much another application or service requires. Any two applications will likely look very different internally, and may use a very different mix of support services. You are still no closer to understanding the complete infrastructure needs for your entire system.
So, if neither of these options is a very useful model for getting a complete picture of the inventory needs of your system, how can you do that, short of performing a full, multimonth audit of your entire infrastructure?
The options considered here attempted to speed up the inventory process by pulling out a subset of important data from the dataset and extrapolating from that. But as we saw, this resulted in inaccuracies. Instead, how about simply spending less time creating the inventory list in the first place? Rather than trying to accurately and completely create an inventory of a small section of your infrastructure, you can create a general overview inventory that may not be very accurate, but will represent your entire system. I refer to this as an adaptive assessment.
Adaptive Assessment
Let’s accept the fact that this may not initially be a very accurate inventory. Instead, as time goes on and you adjust your system, you’ll add more data to your existing (incomplete and inaccurate) inventory, improving it little by little. That is, with each change, you’ll adapt your inventory, adding more data to it and making it a slightly more accurate overall assessment of your system.
With the adaptive assessment approach, rather than striving for perfection in complete inventory (which will take too long) or part of the inventory (which will be unrepresentative), we estimate the inventory of the entire system. Then, over time, we refine the estimate and make it more and more accurate.
It’s an iterative approach to inventory assessment. Figure 2-5 illustrates this process. In the adaptive assessment, you are trading some amount of inaccuracy for speed. In other words, you are exchanging granularity of assessment for development speed.
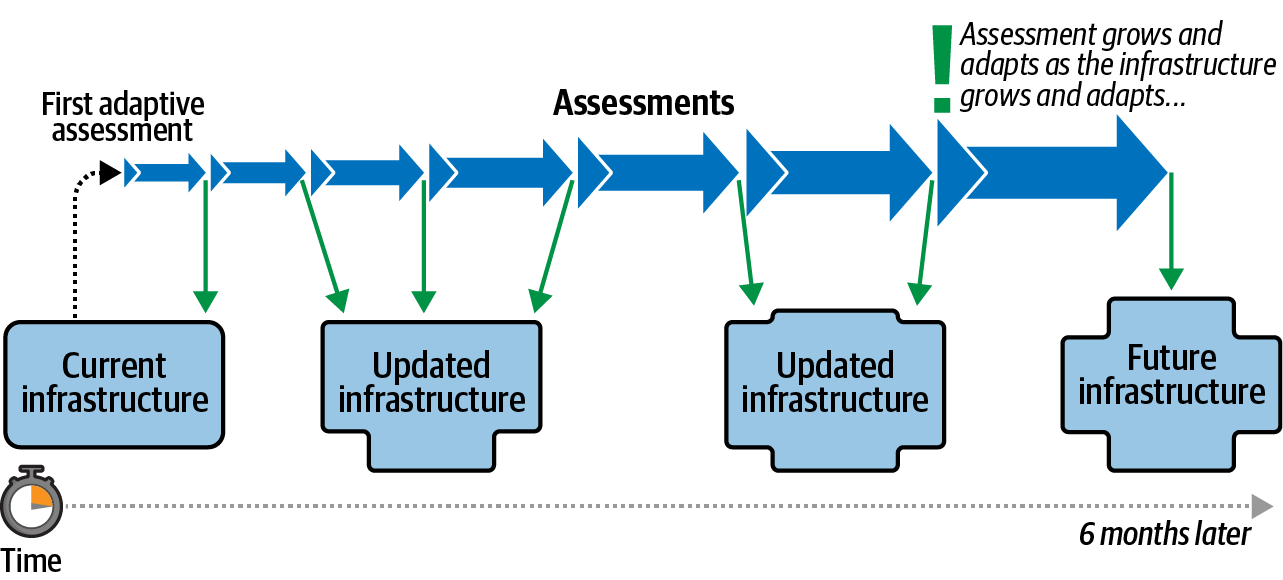
Figure 2-5. An adaptive assessment grows and expands with your infrastructure
Realizing your inventory will be worthless if it takes six months to finish (because the inventory you have six months from now will not be the same inventory that you have now), you instead create a shallow assessment of your inventory and refine it over time. As a result, you will have a much more relevant and useful inventory for a greater period of time. You will make your initial, albeit inaccurate, inventory assessment very quickly, then refine it and add more detail to it as your system changes. Little by little, it will become more accurate. Because the inventory didn’t take much time to create in the first place, it will remain a more accurate representation of your current state than of an outdated historical state.
The Value of an Adaptive Assessment
The true value of an adaptive assessment is time. We will begin to talk about adaptive organizations in the next chapter, but briefly, an organization with an adaptive architecture requires decision-making cycles measured in days or weeks at most. In many cases, the action execution cycles are measured in minutes or days. Since a formal audit can take weeks or months to complete, it’s useless to an adaptive organization, and wasteful. Waiting six months for the results of a formal audit is just not practical, and even if you could wait that long, the result would be a view of your systems that is six months out of date and useless. If you make daily decisions and changes, the assessment will be woefully outdated months before you ever see it.
An adaptive assessment gives you some actionable information immediately. Even if you don’t have full access to everything that would be available in a formal audit, what you do have available to you is available at the right time. Some data when you actually need it is infinitely better than complete data when it’s too late to be useful.
The key is to keep the end goal in mind. Ultimately you do want to end up with as accurate an assessment as possible, both in terms of the quality of the information and the accuracy of the information at the present time (i.e., an inventory that represents the current state of the system, not some point-in-time view of the system in the past).
The question, then, is this: how do you decide what level of granularity you are willing to sacrifice in your assessment in order to have the data you need in a timely manner? Put another way, how granular must the data be to be useful, and when do you need it?
Creating an Adaptive Assessment
We start with this optimistic goal: we want everything.
But we need to temper that goal with a reality check: we are willing to accept errors in what we collect. We may end up with guesses and estimates in much of our assessment in order to get our results more quickly.
We will be using the error bar approach to create our adaptive assessment. This approach results in a complete assessment—a complete inventory of our system—but that assessment is based on guesses and estimates, which may be wrong. Hence, they have “error bars.” Our long-term goal is to revise our estimates as we gain more information to reduce the size of the error bars, ultimately creating a more accurate assessment, as shown on the righthand side of Figure 2-5. Our short-term goal is to create a complete inventory, with errors, quickly. This is opposed to the extrapolation approach, which strives for a partial inventory quickly, or the formal audit, which strives for a complete inventory, without errors, after a long time.
A classic error bar approach starts with colloquial knowledge about the system. “I believe we have 48 network access ports in our primary service rack.” Close enough; we’ll use that number for our inventory for now. At some point in the future we can verify the number: if we find it’s 50 instead of 48, we can adjust our assessment, making it more accurate. But in the meantime, we have a workable number we can deal with. Knowing that we have around 48 ports in our rack is infinitely more useful than not having any idea how many there are and needing to wait several months to have an accurate count.
Adaptive assessments say, “I value being educated sooner rather than later, and I understand I will get more educated as time goes on.”
Decisions Based on Adaptive Assessments
We will be using our assessments to make decisions, but it’s important to understand that those assessments are not absolute. They are estimates, and will be adjusted and refined over time. Our data—our assessment—is agile.
As a result, the decisions we make using this data need to be agile as well. We need to be willing to rethink and reimplement past decisions when we are presented with more accurate and refined data. However, this does not mean we can flip-flop on decisions routinely.
Decision flexibility is a struggle for many IT organizations. Some organizations cannot change direction easily, even when faced with clear and compelling evidence that they are headed in the wrong direction. Meanwhile, other organizations can’t stay focused on anything and constantly move back and forth in a series of nondecisions. Neither is a good place to be.
To use adaptive assessments effectively, you need to be willing and able to make decisions that stick, but also be willing to rethink those decisions when and if the refined data you have available suggests a change.
Your data has error bars, so your decisions must have error bars too. Flexibility is important, while still making actionable decisions.
The most important skill you need as an organization is adaptivity. Your architectures need to be adaptive, not overly robust. An architecture that is rigid and resistant to change is not an architecture that is suitable for adaptive assessment.
Loose Coupling
Many architectural patterns support adaptive assessments, but one of the most valuable patterns you should embrace in all your architectural decisions—application, infrastructure, business—is the pattern of loose coupling.
In a loosely coupled architecture, the connection between any two modules within the architecture is as loose and flexible as possible. This concept applies to application architectures (such as service-oriented architectures), infrastructure architectures (such as cloud-centric architectures), and business and organizational architectures:
-
In the case of application architectures, loose coupling means you must create solid APIs and contractual agreements between software services that define the expected interactions between the services. The APIs define and manage inter-service expectations, but they do not put any requirements on the actual methods, systems, and architectures used in the internal implementation of the services themselves.
-
In the case of infrastructure architectures, loose coupling means you should depend on using infrastructure services, such as cloud-based services, that have predefined expectations about how they work. However, the user of these services does not need knowledge of how the infrastructure service itself is actually constructed or how it functions.
-
In the case of organizational architectures, loose coupling means defining the ownership and responsibilities of individual teams independently from the ownership and responsibilities of other teams or the organization as a whole. Teams have clearly defined goals that are achievable independently, without requiring undue intervention from neighboring or interfacing teams.
In my book Architecting for Scale (O’Reilly), you can read much more about loose coupling. The book lays out five tenets for building highly scalable applications and organizations, several of which describe patterns that involve loose coupling. Tenet 2 is about loosely coupled applications (service-oriented architectures). Tenet 5 is about loosely coupled infrastructures (cloud-based architectures). Tenet 3 talks about loosely coupled organizations and processes. And Tenet 4 talks about risk management, which is an important part of building and using adaptive architectures.
Examples of Adaptive Assessments
There are many ways to perform adaptive assessments. How do you get started? Here are a couple of examples that apply to IT infrastructure assessments.
Example 1: The Brainstorming Adaptive Assessment
An adaptive assessment can start with nothing more than a group brainstorm aimed at identifying the parts of your infrastructure and how they work together. The result may not be very accurate at all, but it is still a useful assessment of your system because it gives you a view of how people think the system is constructed. As you find mistakes and correct errors, you’ll grow that understanding and you’ll be able to refine your team’s internal understanding of how the system actually functions. You should encourage your team to update the assessment every time they interact with the system and make changes so that the assessment continues to improve over time.
Your brainstorming session is an adaptive assessment because it meets the two core requirements:
- Generates results quickly
- It generates results at some level of quality very quickly. After the initial brainstorming meeting, you have an assessment. It may not be accurate yet, but it’s a start and has immediate value.
- Improves over time
- The results improve as time goes on. As your team keeps updating the assessment as they make changes, the assessment keeps improving.
Example 2: The Cloud Tagging Adaptive Assessment
When using cloud architectures, a convenient way to start an assessment of your operational infrastructure is to virtually tag individual components of your infrastructure. This is particularly useful in cloud-based systems, as most cloud providers give you the tools necessary to tag individual infrastructure components. As you begin tagging infrastructure components with specific attributes, you’ll start to see how you are utilizing your cloud infrastructure. You can tag infrastructure components to show which applications use a specific component, what teams are responsible for managing it, who is responsible for paying for it, and who to contact to determine when the component is being used, or whether the component is still being used at all.
Once you’ve done some tagging of your cloud infrastructure resources, you can generate reports based on those tags to find out all sorts of useful things, like who owns which components, what teams use which services, who uses excessive resources, who has spare resources, and who is running their resources too hot.
By putting policies into place requiring all new cloud components to be properly tagged and encouraging teams interacting with existing cloud components to add tags if they don’t have them yet, you’ll keep improving your assessment of how your cloud infrastructure is working over time.
Eventually, you may even want to utilize a cloud service that will enforce tagging rules. Some enterprises set up policies that ensure tagging by simply systemically deleting resources that are not tagged correctly. Nothing will encourage a team to make sure their cloud infrastructure resources are properly tagged more than having a critical infrastructure component simply disappear from their application because it wasn’t tagged properly!
Your cloud tagging assessment is an adaptive assessment because it meets the two core requirements:
- Generates results quickly
- It generates results at some level of quality very quickly. Simply tagging a few very visible resources will give you some level of reporting ability.
- Improves over time
- The results improve as time goes on. Every time you create a new cloud resource going forward, make sure to tag it appropriately (software can actually require this task before it creates the resource). Existing untagged resources are tagged as they are noticed. Over time, a greater percentage of resources will be properly tagged.
The Survey Analogy
At the beginning of this chapter, I suggested that surveying is a better description of what we are doing than auditing or assessing, which are the traditionally used terms. The process of an adaptive assessment is more accurately described as a survey from another perspective as well.
Think about using surveys as a way to get information about people. Politicians conduct surveys all the time. Companies with visible brand loyalty use surveys to understand the value of their brand. Employers use surveys too; for example, conducting employee satisfaction surveys to determine how their employees are doing.
Let’s think about such a survey for a minute. When we conduct an employee satisfaction survey, we get a list of the percentages of respondents who gave specific answers to the included questions. That’s all. We then attempt to deduce whether our employees are happy or not from the answers. This is an assumption based on the data, not a true and complete reflection of employee happiness.
As time goes on, we can repeat the survey. We can even fine-tune some of the questions to get better and more accurate results. By comparing the results over time, we can get a more accurate picture of whether our employees are happy or not, as well as whether the things we are doing are improving employee happiness.
These surveys are non-IT examples of adaptive assessments.
Summary
An adaptive assessment is a fast and effective way to conduct an audit or assessment of your business, processes, applications, and infrastructure. It assumes that some data, even if not 100% accurate, is better than no data at all. A successful adaptive assessment is characterized by (1) generating quick results and (2) improving the quality of those results over time.