
Chapter 16. Interfacing with the System

When you finish this chapter, you should understand the following program:
use Cwd;
use File::Spec;
print cwd, "
";
my $dir = File::Spec->rootdir;
chdir $dir;
opendir(DIR, $dir) or die $!;
my @files=readdir DIR;
@files = sort {$a cmp$b} @files;
foreach my $file (@files){
print "$file
" if -r $file;
}
closedir DIR;
chdir $ENV{HOME};
print cwd, "
";
16.1 System Calls
Those migrating from shell (or batch) programming to Perl often expect that a Perl script is like a shell script—just a sequence of UNIX/Linux (or MS-DOS) commands. However, system utilities are not accessed directly in Perl programs as they are in shell scripts. Of course, to be effective there must be some way in which your Perl program can interface with the operating system. Perl has a set of functions, in fact, that specifically interface with the operating system and are directly related to the UNIX/Linux system calls so often found in C programs. Many of these system calls are supported by Windows. The ones that are generally not supported are found at the end of this chapter.
A system call requests some service from the operating system (kernel), such as getting the time of day, creating a new directory, removing a file, creating a new process, terminating a process, and so on. A major group of system calls deals with the creation and termination of processes, how memory is allocated and released, and sending information (such as signals) to processes. Another function of system calls is related to the file system: file creation, reading and writing files, creating and removing directories, creating links, and so forth.1
1. System calls are direct entries into the kernel, whereas library calls are functions that invoke system calls. Perl’s system interface functions are named after their counterpart UNIX system calls in Section 2 of the UNIX manual pages.
The UNIX2 system calls are documented in Section 2 of the UNIX manual pages. Perl’s system functions are almost identical in syntax and implementation. If a system call fails, it returns a -1 and sets the system’s global variable errno to a value that contains the reason the error occurred. C programs use the perror function to obtain system errors stored in errno; Perl programs use the special $! variable.
2. From now on when referring to UNIX, assume that Linux also applies.
The following Perl functions allow you to perform a variety of calls to the system when you need to manipulate or obtain information about files or processes. If the system call you need is not provided by Perl, you can use Perl’s syscall function, which takes a UNIX system call as an argument. (See “The syscall Function and the h2ph Script” in Section 16.3.1.)
In addition to the built-in functions, the standard Perl library comes bundled with a variety of over 200 modules that you can use to perform portable operations on files, directories, processes, networks, and so forth. If you installed ActiveState or Strawberry, you will also find a collection of Win32 modules in the standard Perl library under C:perl64libWin32.
To read the documentation for any of the modules (filenames with a .pm extension) from the standard Perl library, use the Perl built-in perldoc function or the UNIX man command. ActiveState (Win32) provides online documentation found by clicking the Start button, Programs, and then ActiveState.
Explanation
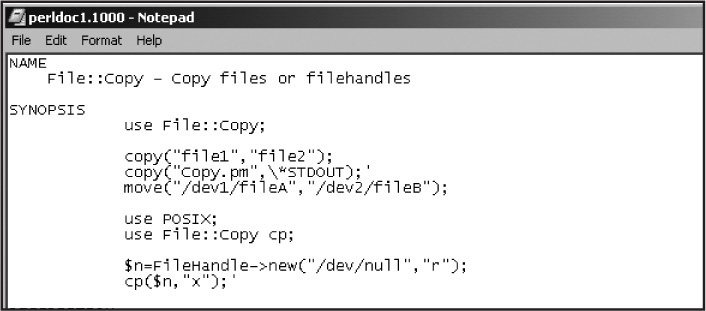
The perldoc function takes a module name as its argument (with or without the .pm extension). The documentation for the module will then display in a window (Notepad on Win32 platforms). This example displays part of the documentation for the Copy.pm module found in the standard Perl library (see Figure 16.1).
16.1.1 Directories and Files
When walking through a file system, directories are separated by slashes. UNIX file systems indicate the root directory with a forward slash (/), followed by subdirectories separated by forward slashes where, if a filename is specified, it is the final component of the path. The names of the files and directories are case sensitive, and their names consist of alphanumeric characters and punctuation, excluding whitespace. A period in a filename has no special meaning but can be used to separate the base filename from its extension, such as in program.c or file.bak. The length of the filename varies from different operating systems, with a minimum of 1 character and on most UNIX-type file systems, up to 255 characters are allowed. Only the root directory can be named / (slash).3
3. The Mac OS file system (HFS) is also hierarchical and uses colons to separate path components.
The Windows file system in broad use today is mainly NTFS (with Windows 8+ switches up to ReFS, the Resilient File System) and separates the volume name and each of the path elements with a backslash () (for example, C:Perl64libXML). The individual components of a path are limited to 260 characters and the path length is limited to approximately 32,000 characters. Files and directory names are not case sensitive, can contain letters and numbers (as well as Unicode and characters in the extended character set (128–255)) that are optionally followed by a period, and a suffix of no more than three characters. The root of the file system is a drive number, such as C: or D:, rather than only a slash. In networked environments, the universal naming convention (UNC) uses a different convention for separating the components of a path; the drive letter is replaced with two backslashes, as in \myserverdirdir.
Backslash Issues
The backslash in Perl scripts is used as an escape or quoting character ( , ,U,$500, and so forth), so when specifying a Win32 path separator, two backslashes are often needed, unless a particular module allows a single backslash or the pathname is surrounded by single quotes. For example, C:PerllibFile should be written "C:\Perl\lib\File" or 'C:PerllibFile'.
The File::Spec Module
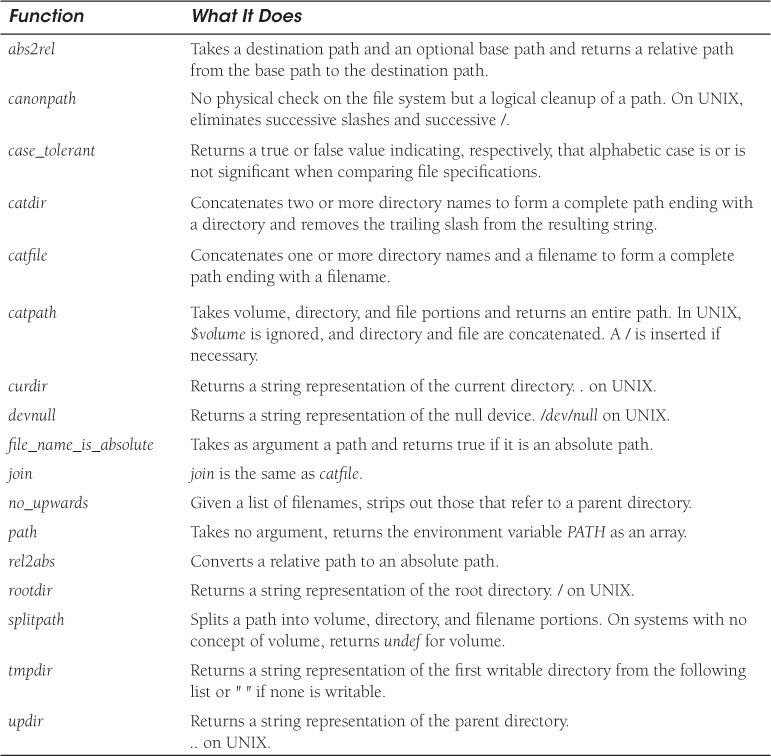
The File::Spec module found in the standard Perl library was designed to portably support operations commonly performed on filenames, such as creating a single path out of a list of path components and applying the correct path delimiter for the appropriate operating system, or splitting up the path into volume, directory, and filename, and so forth. A list of File::Spec functions is provided in Table 16.1. Since these functions are different for most operating systems, File::Spec will choose the appropriate set of routines for the current OS available in separate modules, which includes File::Spec::UNIX, File::Spec::Mac, File::Spec::OS2, File::Spec::Win32, and File::Spec::VMS.
16.1.2 Directory and File Attributes
UNIX
The most common type of file is a regular file. It contains data, an ordered sequence of bytes. The data can be text data or binary data. Information about the file is stored in a system data structure called an inode. The information in the inode consists of such attributes as the link count, owner, group, mode, size, last access time, last modification time, and type. The UNIX ls command lets you see the inode information for the files in your directory. This information is retrieved by the stat system call. Perl’s stat function also gives you information about the file. It retrieves the device number, inode number, mode, link count, user ID, group ID, size in bytes, time of last access, and so on. (See “The stat and lstat Functions” in Section 16.1.12.)
A directory is a specific file type maintained by the UNIX kernel. It is composed of a list of filenames. Each filename has a corresponding number that points to the information about the file. The number, called an inode number, is a pointer to an inode. The inode contains information about the file as well as a pointer to the location of the file’s data blocks on disk. The following functions allow you to manipulate directories, change permissions on files, create links, and so forth.

Windows
Files and directories contain data as well as meta information that describes attributes of a file or directory. The five basic attributes of Win32 files and directories are ARCHIVE, HIDDEN, READONLY, and SYSTEM. The attributes of a file or directory are stored in a byte, with the bit value either on or off. Each bit value is added to the file type so that if you have a hidden, readonly directory, the attribute value is 00010011. See Table 16.2.

To retrieve and set file attributes, use the standard Perl extension Win32::File. All of the functions return FALSE (0) if they fail, unless otherwise noted. The function names are exported into the caller’s namespace by request. See Table 16.3.

To retrieve file attributes, use Win32::File::GetAttributes($Path, $Attributes), and to set file attributes, use Win32::File::SetAttributes($Path,$Attributes). See Table 16.4. The Win32::File also provides a number of constants.

16.1.3 Finding Directories and Files
The File::Find module lets you traverse a file system tree for specified files or directories based on some criteria, like the UNIX find command or the Perl find2perl translator.
The first argument to find() is either a hash reference describing the operations to be performed for each file or a reference to a subroutine. Type perldoc File::Find for details. The wanted() function does whatever verification you want for the file. $File::Find::dir contains the current directory name, and $_ is assigned the current filename within that directory. $File::Find::name contains the complete pathname to the file. You are chdir()ed to $File::Find::dir when the function is called, unless no_chdir was specified. The first argument to find() is either a hash reference describing the operations to be performed for each file or a code reference. See Table 16.5.

16.1.4 Creating a Directory—The mkdir Function
UNIX
The mkdir function creates a new, empty directory with the specified permissions (mode). The permissions are set as an octal number. The entries for the . and .. directories are automatically created. The mkdir function returns 1 if successful and 0 if not. If mkdir fails, the system error is stored in Perl’s $! variable.
Windows
If creating a directory at the MS-DOS prompt, the permission mask has no effect. Permissions on Win32 don’t use the same mechanism as UNIX. For files on FAT partitions, you don’t have to set permissions explicitly on a file. All files are available to all users, and the directory is created with all permissions turned on for everyone.
16.1.5 Removing a Directory—The rmdir Function
The rmdir function removes a directory, but only if it is empty.
16.1.6 Changing Directories—The chdir Function
Each process has its own present working directory. When resolving relative path references, this is the starting place for the search path. If the calling process (for example, your Perl script) changes the directory, it is changed only for that process, not the process that invoked it (normally the shell). When the Perl program exits, the shell returns to the same working directory it started with.
The chdir function changes the current working directory. Without an argument, the directory is changed to the user’s home directory. The function returns 1 if successful and 0 if not. The system error code is stored in Perl’s $! variable.4
4. chdir is a system call provided with Perl for changing directories. The cd command used at the command line is a shell built-in and cannot be used directly in a Perl script.
16.1.7 Accessing a Directory via the Directory Filehandle
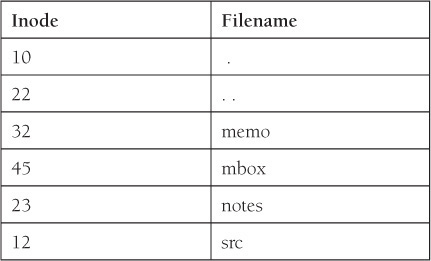
The following Perl directory functions are modeled after the UNIX system calls sharing the same name. Although the traditional UNIX directory contained a 2-byte inode number and a 14-byte filename, not all UNIX systems have the same format. The directory functions allow you to access the directory regardless of its internal structure. The directory functions work the same way with Windows. Figure 16.2 illustrates the directory structure for a typical UNIX system where each file is given an identifying inode number.
The opendir Function
The opendir function opens a named directory and attaches it to the directory filehandle. This filehandle has its own namespace, separate from the other types of filehandles used for opening files and filters. The opendir function initializes the directory for processing by the related functions readdir(), telldir(), seekdir(), rewinddir(), and closedir(). The function returns 1 if successful.
The readdir Function
Anyone who has read permission on the directory can read it; meaning, view its contents. You can’t write to the directory itself even if you have write permission. The write permission on a directory means that you can create and remove files from within the directory, not alter the directory data structure itself.
When we speak about reading a directory with the readdir function, we are talking about looking at the contents of the directory structure maintained by the system. If the opendir function opened the directory, in a scalar context, readdir returns the next directory entry. In an array context, it returns the rest of the entries in the directory.
The closedir Function
The closedir function closes the directory that was opened by the opendir function.
The telldir Function
The telldir function returns the current position of the readdir() routines on the directory filehandle. The value returned by telldir may be given to seekdir() to access a particular location in a directory.
The rewinddir Function
The rewinddir function sets the position of DIRHANDLE back to the beginning of the directory opened by opendir. It is not supported on all machines.
The seekdir Function
The seekdir sets the current position for readdir() on the directory filehandle. The position is set by the value returned by telldir().
16.1.8 Permissions and Ownership
UNIX
There is one owner for every UNIX file. The one benefit the owner has over everyone else is the ability to change the permissions on the file, thus controlling who can do what to the file. A group may have a number of members, and the owner of the file may change the group permissions on a file so that the group will enjoy special privileges.
Every UNIX file has a set of permissions associated with it to control who can read, write, or execute the file. There are a total of nine bits that constitute the permissions on a file. The first three bits control the permissions of the owner of the file, the second set controls the permissions of the group, and the last set controls every one else. The permissions are stored in the mode field of the file’s inode.
Windows
Win32 systems do not handle file permissions the way UNIX does. Files are created with read and write turned on for everyone. Files and folders inherit attributes that you can set. By clicking the mouse on a file icon and selecting Properties, you can, in a limited way, select permission attributes, such as Archive, Read-only, and Hidden (see Figure 16.3).
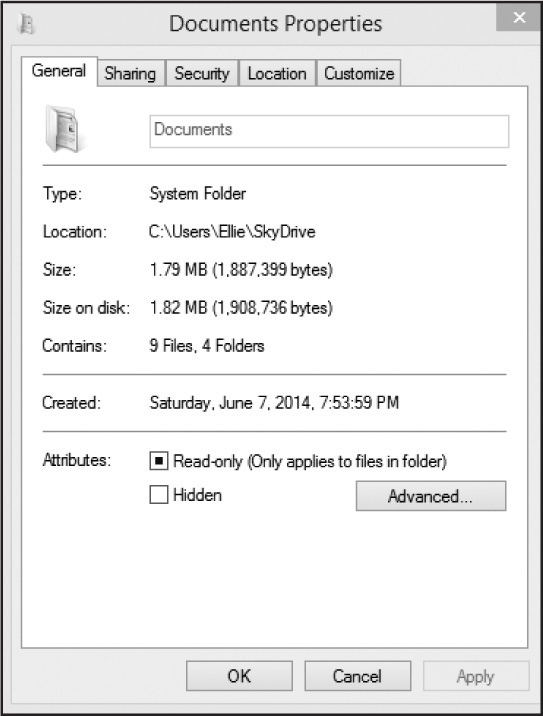
If your platform is Win32, you can set file and folder permissions only on drives formatted to use NTFS.5 To change permissions, you must be the owner or have been granted permission to do so by the owner. If you are using NTFS, go to File Explorer (formerly Windows Explorer) and locate the file or folder for which you want to set permissions. Right-click the file or folder, click Properties, and then click the Security tab. You will be able to allow, deny, or remove permissions from the group or user.
5. NTFS is an advanced file system designed for Windows NT.
See the Win32::FileSecurity module in the Perl Resource Kit for Win32 if you need to maintain file permissions. To retrieve file permissions from a file or directory, use the Win32::FileSecurity::Get($Path, \%Perms) extension, where $Path is the relative or absolute path to the file or directory for which you are seeking permissions, and \%Perms is a reference to a hash containing keys representing the user or group and corresponding values representing the permission mask. See Table 16.6.

The chmod Function (UNIX)
The chmod function changes permissions on a list of files. The user must own the files to change permissions on them. The files must be quoted strings. The first element of the list is the numeric octal value for the new mode. (Today, the binary/octal notation has been replaced by a more convenient mnemonic method for changing permissions. Perl does not use the new method.)
Table 16.7 illustrates the eight possible combinations of numbers used for changing permissions if you are not familiar with this method.
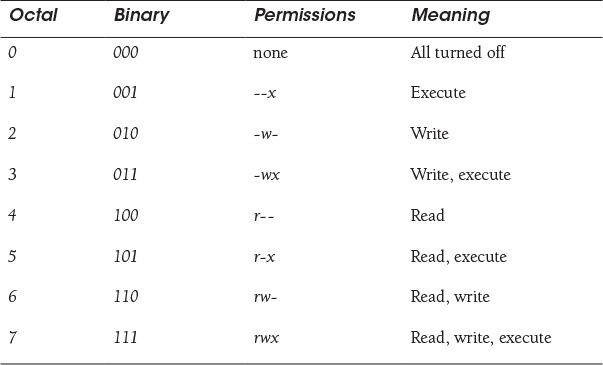
Make sure the first digit is a 0 to indicate an octal number. Do not use the mnemonic mode (for example, +rx), because all the permissions will be turned off.
The chmod Function (Windows)
ActivePerl supports a limited version of the chmod function. However, you can only use it for giving the owner read/write access. (The group and other bits are ignored.)
The chmod function returns the number of files that were changed.
The chown Function (UNIX)
The chown function changes the owner and group of a list of files. Only the owner or superuser can invoke it.6 The first two elements of the list must be a numerical uid and gid. Each authorized UNIX user is assigned a uid (user identification number) and a gid (group identification number) in the password file.7 The function returns the number of files successfully changed.
6. On BSD UNIX and some POSIX-based UNIX, only the superuser can change ownership.
7. To get the uid or gid for a user, use the getpwnam or getpwuid functions.
The umask Function (UNIX)
When a file is created, it has a certain set of permissions by default. The permissions are determined by what is called the system mask. On most systems, this mask is 022 and is set by the login program.8 A directory has 777 by default (rwxrwxrwx), and a file has 666 by default (rw-rw-rw). Use the umask function to remove or subtract permissions from the existing mask.
8. The user can also set the umask in the .profile (sh or ksh) or .cshrc (csh) initialization files.
To take write permission away from the “others” permission set, the umask value is subtracted from the maximum permissions allowed per directory or file:
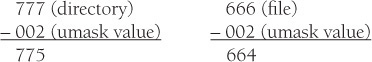
The umask function sets the umask for this process and returns the old one. Without an argument, the umask function returns the current setting.
16.1.9 Hard and Soft Links
UNIX
When you create a file, it has one hard link; that is, one entry in the directory. You can create additional links to the file, which are really just different names for the same file. The kernel keeps track of how many links a file has in the file’s inode. As long as there is a link to the file, its data blocks will not be released to the system. The advantage to having a file with multiple names is that there is only one set of data, or master file, and that file can be accessed by a number of different names. A hard link cannot span file systems and must exist at link-creation time.
A soft link is also called a symbolic link and sometimes a symlink. A symbolic link is really just a very small file (it has permissions, ownership, size, and so forth). All it contains is the name of another file. When accessing a file that has a symbolic link, the kernel is pointed to the name of the file contained in the symbolic link. For example, a link from thisfile to /usr/bin/joking/otherfile links the name thisfile to /usr/bin/joking/otherfile. When thisfile is opened, otherfile is the file really accessed. Symbolic links can refer to files that do or don’t exist and can span file systems and even different computers. They can also point to other symbolic links.9
9. Symbolic links originated in BSD and are supported under many ATT systems. They may not be supported on your system.
Windows
The Win32 system introduced shortcuts, special binary files with a .lnk extension. A shortcut is similar to a UNIX symlink, but it is processed by a particular application rather than by the system and is an alias for a file or directory. Shortcuts are icons with a little arrow in a white box in the left corner (see Figure 16.4).
If you are using Windows 8, see “How to create software shortcut methods in the desktop mode of Windows 8” at http://support.microsoft.com/kb/2820848/en-gb.
See the Win32::Shortcut module to create, load, retrieve, save, and modify shortcut properties from a Perl script. To give you a sample of how to use the Win32::Shortcut module, the following example is just one of several from the Perl documentation:
use Win32::Shortcut;
$LINK = Win32::Shortcut->new();
$LINK->{'Path'} = "C:\Directory\Target.exe";
$LINK->{'Description'} = "Target executable";
$LINK->Save("Target.lnk");
$LINK->Close();
The link and unlink Functions (UNIX)
The link function creates a hard link (that is, two files that have the same name) on UNIX systems. The first argument to the link function is the name of an existing file; the second argument is the name of the new file, which cannot already exist. Only the superuser can create a link that points to a directory. Use rmdir when removing a directory.
The unlink function deletes a list of files on both UNIX and Windows systems (like the UNIX rm command or the MS-DOS del command). If the file has more than one link, the link count is dropped by one. The function returns the number of files successfully deleted. To remove a directory, use the rmdir function, since only the superuser can unlink a directory with the unlink function.
The symlink and readlink Functions (UNIX)
The symlink function creates a symbolic link. The symbolic link file is the name of the file that is accessed if the old filename is referenced.
The readlink function returns the value of the symbolic link and is undefined if the file is not a symbolic link.
16.1.10 Renaming Files
The rename Function (UNIX and Windows)
The rename function changes the name of the file, like the UNIX mv command. The effect is to create a new link to an existing file and then delete the existing file. The rename function returns 1 for success and returns 0 for failure. This function does not work across file system boundaries. If a file with the new name already exists, its contents will be destroyed.
16.1.11 Changing Access and Modification Times
The utime Function
The utime function changes the access and modification times on each file in a list of files, like the UNIX touch command. The first two elements of the list must be the numerical access and modification times, in that order. The time function feeds the current time to the utime function. The function returns the number of files successfully changed. The inode modification time of each file in the list is set to the current time.
16.1.12 File Statistics
The information for a file is stored in a data structure called an inode, maintained by the kernel. For UNIX users, much of this information is retrieved with the ls command. In C and Perl programs, this information may be retrieved directly from the inode with the stat function. See the File::stat module, which creates a user interface for the stat function. Although the emphasis here is UNIX, the stat function also works with Win32 systems.
The stat and lstat Functions
The stat function returns a 13-element array containing statistics retrieved from the file’s inode. The last two fields, dealing with blocks, are defined only on BSD UNIX systems.10
10. Wall, L., Christianson, T., and Orwant, J., Programming Perl, 3rd ed., O’Reilly & Associates: (2000), p. 188.
The lstat function is like the stat function, but if the file is a symbolic link, lstat returns information about the link itself rather than about the file it references. If your system does not support symbolic links, a normal stat is done.
The special underscore filehandle is used to provide stat information from the file most previously stat-ed. The 13-element array returned contains the following elements stored in the stat structure. (The order is a little different from the UNIX system call stat.)
1. Device number
2. Inode number
3. Mode
4. Link count
5. User ID
6. Group ID
7. For a special file, the device number of the device it refers to
8. Size in bytes, for regular files
9. Time of last access
10. Time of the last modification
11. Time of last file status change
12. Preferred I/O block size for file system
13. Actual number of 512-byte blocks allocated
16.1.13 Packing and Unpacking Data
Remember the printf and sprintf functions? They were used to format their arguments as floating-point numbers, decimal numbers, strings, and so forth. The pack and unpack functions take this formatting a step further. Both functions act on strings that can be represented as bits, bytes, integers, long integers, floating-point numbers, and so forth, but pack can also act on general data as well as strings. The format type tells both pack and unpack how to handle these strings.
The pack and unpack functions have a number of uses. These functions are used to pack a list into a binary structure and then expand the packed values back into a list. When working with files, you can use these functions to create uuencode files, relational databases, Unicode strings, and binary files.
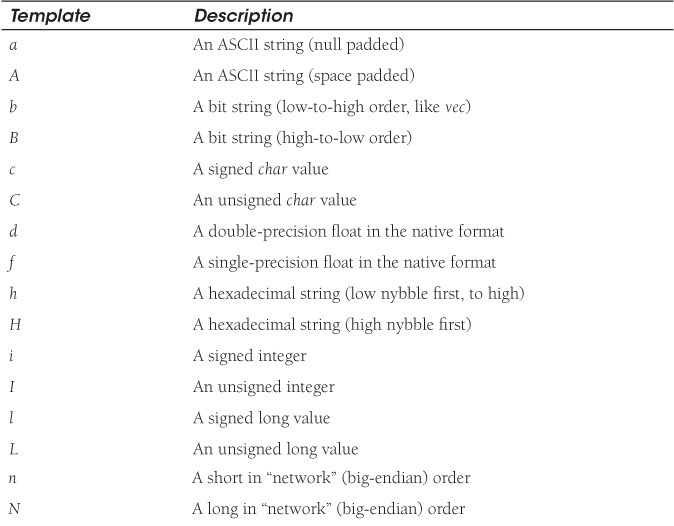
When working with files, not all files are text files. Some files, for example, may be packed into a binary format to save space, store images, and so forth. These files are not readable as is the text on this page. You can use the pack and unpack functions to convert the lines in a file from one format to another. The pack function converts a list into a scalar value that may be stored in machine memory. The template shown in Table 16.8 is used to specify the type of character and how many characters will be formatted. For example, the string c4, or cccc, packs a list into 4 unsigned characters, and a14 packs a list into a 14-byte ASCII string, null padded. The asterisk (as in H*) is a repeating character representing all characters until the end of the string. The unpack function converts a binary formatted string into a list. The opposite of pack puts a string back into Perl format.

16.2 Processes
Your Perl script is a program that resides on disk. When the program is placed in memory and starts execution, it is called a process. Each process has a number of attributes that are inherited from its parent, the calling process. Perl has a number of functions that will allow you to retrieve the information about the process. Before examining these functions, a short discussion about processes may help you to understand (or recall) the purpose of some of Perl’s system calls.
16.2.1 UNIX Processes
Every process has a unique process ID, a positive integer called the pid. Every process has a parent except process 0, the swapper. The first process init, pid 1, is the ancestor of all future processes, called descendants, or more commonly, child processes.
In Figure 16.5, the Perl process is a descendant of the UNIX shell (sh). The first process is pid#1, called init. The init process spawns getty, which execs login and login execs sh, the shell program. From the shell program, the Perl process is spawned; that is, the shell is Perl’s parent.
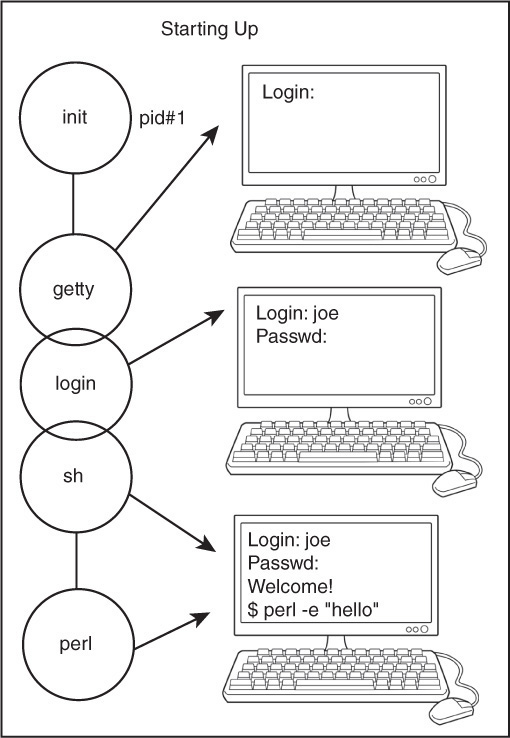
Each process also belongs to a process group, a collection of one or more processes used for job control and signal handling. Each process group also has a unique pid and a process leader. When you log on, the process group leader may be your login shell. Any process created from your shell will be a member of this process group. The terminal opened by the process group leader is called the controlling terminal, and any processes it spawns inherit it. Any signals sent to the process will be sent to all processes in the group. That is why, when you press <CTRL>+C, the process you are running and any of its children will terminate. Perl provides functions to obtain the process group ID and to set the process group.
When a process is created, it is assigned four numbers indicating who owns the process. They are the real and effective user ID, and the real and effective group ID. The user ID, called the real uid, is a positive integer that is associated with your login name. The real uid is the third field in the /etc/passwd file. When you log on, the first process created is called the login shell, and it is assigned the user ID. Any processes spawned from the shell also inherit this uid. Any process running with the uid of zero is called a root, or superuser, process with special privileges.
There is also a group ID number, called the real gid, which associates a group with your login name. The default gid is the fourth field in the password file, and it is also inherited by any child process. The system administrator can allow users to become members of other groups by assigning entries in the /etc/group file.
The following is an entry from the passwd file, illustrating how the uid and gid values are stored (fields are separated by colons).
The effective uid (euid) and effective guid (guid) of a process are normally set to the same number as the real uid and real gid of the user who is running the process. UNIX determines what permissions are available to a process by the effective uid and gid. If the euid or guid of a file is changed to that of another owner, when you execute a program, you essentially become that owner and get his access permissions. Programs in which the effective uid or effective gid have been set are called set user ID programs, or setuid programs. When you change your password, the /bin/passwd program has a setuid to root, giving you the privilege to change your password in the passwd file, which is owned by root.
16.2.2 Win32 Processes
The process model for Windows differs from UNIX systems, and since Perl was originally designed for UNIX, a number of library routines were added to the standard Perl library to accommodate the Windows world. The Win32 directory (C:/Perl/lib/Win32) is a Windows-specific directory that comes with Windows versions of Perl and contains a number of modules for creating, suspending, resuming, and killing processes. The Win32::Process module contains a number of functions to manipulate processes. Here is a listing from the Win32 directory:
AuthenticateUser.pm Internet.pm Registry.pm
ChangeNotify.pm Mutex.pm Semaphore.pm
Client.pl NetAdmin.pm Server.pl
Clipboard.pm NetResource.pm Service.pm
Console.pm ODBC.pm Shortcut.pm
Event.pm OLE Sound.pm
EventLog.pm OLE.pm Test.pl
File.pm PerfLib.pm TieRegistry.pm
FileSecurity.pm Pipe.pm WinError.pm
IPC.pm Process.pm test-async.pl
16.2.3 The Environment (UNIX and Windows)
When you log on, your shell program inherits a set of environment variables initialized by either the login program or one of shell’s startup files (.profile or .login). These variables contain useful information about the process, such as the search path, the home directory, the user name, and the terminal type. The information in environment variables, once set and exported, is inherited by any child processes that are spawned from the process (parent) in which they were initialized. The shell process will pass the environment information on to your Perl program.
The special %ENV hash contains the environment settings. If you change the value of an environment setting in your Perl script, it is set for this process and any of its children. The environment variables in the parent process, normally the shell, will remain untouched.
16.2.4 Processes and Filehandles
As discussed in Chapter 10, “Getting a Handle on Files,” processes can be opened in Perl via either an input or output filehandle. For example, if you want to see all the currently running processes on your machine, you could create a filehandle for the UNIX ps command. (See Chapter 10 for details. See also “The system Function” in Section 16.3.4.)
Login Information—The getlogin Function
The getlogin function returns the current login from /etc/utmp. If the empty string is returned from getlogin, use getpwuid. The getpwuid function takes the uid of the user as an argument and returns an entry from the password file associated with that uid.
The $< variable evaluates to the real uid of this process.
Special Process Variables (pid, uid, euid, gid, egid)
Perl provides some special variables that store information about the Perl process executing your script. If you want to make your program more readable, you can use the English module in the standard Perl library to represent these variables in English.
• $$ The process ID of the Perl program running this script
• $< The real uid of this process
• $> The effective uid of this process
• $( The real gid of this process
• $) The effective gid of this process
The Parent Process ID—The getppid Function and the $$ Variable
Each process on the system is identified by its process identification number (pid), a positive integer. The special variable $$ holds the value of the pid for this process. This variable is also used by the shell to hold the process ID number of the current process.
The getppid function returns the process ID of the parent process.
The Process Group ID—The pgrp Function
The pgrp function returns the current group process for a specified pid. Without an argument or with an argument of 0, the process group ID of the current process is returned.
16.2.5 Process Priorities and Niceness
The kernel maintains the scheduling priority selected for each process. Most interactive and short-running jobs are favored with a higher priority. The UNIX nice command allows you to modify the scheduling priority of processes. On moderately or heavily loaded systems, it may be to your advantage to make CPU-intensive jobs run slower so that jobs needing higher priority get faster access to the CPU. Those jobs that don’t hog the processor are called nice.
The nice value is used in calculating the priority of a process. A process with a positive nice value runs at a low priority, meaning that it receives less than its share of the CPU time. A process with a negative nice value runs at a high priority, receiving more than its share of the processor. The nice values range from -20 to 19. Most processes run at priority zero, balancing their access to the CPU. (Only the superuser can set negative nice values.)
The following functions, getpriority and setpriority, are named for the corresponding system calls, found in Section 2 of the UNIX man pages.
The getpriority Function
The getpriority function returns the current priority (nice value) for a process, a process group, or a user. Not all systems support this function. If not implemented, getpriority produces a fatal error. WHICH is one of three values: 0 for the process priority, 1 for the process group priority, and 2 for the user priority. WHO is interpreted relative to the process identifier for the process priority, process group priority, or user priority. A value of zero represents the current process, process group, or user.
The setpriority Function (nice)
The setpriority function sets the current priority (nice value) for a process, a process group, or a user. It modifies the scheduling priority for processes. If the setpriority system call is not implemented on your system, setpriority will throw an error.
WHICH is one of three values: 0 for the process priority, 1 for the process group priority, and 2 for the user priority. WHO is interpreted relative to the process identifier for the process priority, process group priority, or user priority. A value of zero represents the current process, process group, or user. NICEVALUE is the nice value. A low nice value raises the priority of the process and a high nice value decreases the priority of the process. (Confusing!)
Unless you have superuser privileges, you cannot use a negative nice value. Doing so will not change the current nice value.
16.2.6 Password Information
UNIX
The following functions iterate through the /etc/passwd file and retrieve information from that file into an array. These functions are named for the same functions found in the system library (see Section 3 of the UNIX manual) and perform the same tasks. If you are interested in obtaining information about the /etc/group file, the Perl functions getgrent, getgrgid, and getgrnam all return a four-element array with information about group entries. A description of these functions is in the UNIX manual pages. Here is an example of an /etc/passwd file:
root:YhTLR4heBdxfw:0:1:Operator:/:/bin/csh
nobody:*:65534:65534::/:
sys:*:2:2::/:/bin/csh
bin:*:3:3::/bin
uucp:*:4:8::/var/spool/uucppublic:
news:*:6:6::/var/spool/news:/bin/csh
sync::1:1::/:/bin/sync
ellie:aVD17TSsBMfYg:9496:40:Ellie Shellie:/home/jody/ellie:/bin/ksh
Windows
Windows stores information about users in a binary database called SAM (Security Accounts Manager), part of the Registry. Because the data is stored in binary format, normal Perl read operations won’t work. It is better to use the Win32 extensions to get user information. Win32::NetAdmin is bundled with ActiveState under perlsitelibwin32. (See Table 16-9.) You can manipulate a user account with two functions of this module: UserGetAttributes and UserSetAttributes.

The Win 32 net.exe command also displays information about the user and the system.
You cannot transfer encrypted passwords from UNIX to Win32 systems, and vice versa. They are cryptologically incompatible. To manage passwords, use the Win32::AdminMisc or the Win32::NetAdmin module extension. See Table 16.10.

For Windows users, the following functions for obtaining group and user information have not been implemented:
endgrent(), endpwent(), getgrent(), getgrgid(), getgrnam(),
getpwent(), getpwnam(), getpwuid(), setgrent(), setpwent()
At your prompt, type perldoc perlport to help with portability issues between different operating systems.
Getting a Password Entry (UNIX)—The getpwent Function
The getpwent function retrieves information from the /etc/passwd file. The return value from getpwent is a nine-element array consisting of:
1. Login name
2. Encrypted password
3. User ID
4. Group ID
5. Quota
6. Comment
7. Gcos (user information)
8. Home directory
9. Login shell
Getting a Password Entry by Username—The getpwnam Function
The getpwnam function takes the user name as an argument and returns a nine-element array corresponding to that user’s name field in the /etc/passwd file.
Getting a Password Entry by uid—The getpwuid Function
The getpwuid function takes a numeric user ID (uid) as an argument and returns a nine-element array corresponding to that user’s uid entry in the /etc/passwd file.
16.2.7 Time and Processes
When working in a computer environment, programs often need to obtain and manipulate the current date and time. UNIX systems maintain two types of time values: calendar time and process time.
The calendar time counts the number of seconds since 00:00:00 January 1, 1970, UTC (Coordinated Universal Time, which is a new name for Greenwich Mean Time, although UTC does not adjust for leap seconds).
The process time, also called CPU time, measures the resources a process utilizes in clock time, user CPU time, and system CPU time. The CPU time is measured in clock ticks per second.
Perl has a number of time functions that interface with the system to retrieve time information.
If you want a list of CPAN modules for manipulating dates and times, go online to http://www.techrepublic.com/article/manipulate-dates-and-time-with-these-10-perl-cpan-modules. There, you’ll get a list of 10 popular modules, a full description, and a link to the download page. The modules include:
• Date::Manip
• DateTime
• Time::Format
• Time::Interval
• Date::Convert
• Benchmark
• Time::Normalize
• Regexp::Common::time
• MySQL::DateFormat
• Net::Time
Since Perl 5.10, the Time::Piece module was added to the standard library to simplify the handling of date and time, discussed next.
The Time::Piece Module
The Time::Piece module is available in the standard Perl library (since version 5.10) to replace the localtime and gmtime functions. It provides a built-in constructor to create a date/time object and methods to get the current date and time, the weekday, year, month, and so forth. It also provides support for working with different locales, doing comparisons and calculations on dates and times, and methods for parsing and formatting the time and date. For full documentation, type at your prompt:
perldoc Time::Piece
The times Function
The built-in times function returns a four-element array consisting of the CPU time for a process, measured as follows:
• User time—Time spent executing user’s code
• System time—Time spent executing system calls
• Children’s user time—Time spent executing all terminated child processes
• Children’s system time—Time spent executing system calls for all terminated child processes
The time Function (UNIX and Windows)
The time function returns the number of nonleap seconds since January 1, 1970, UTC. Its return value is used with the gmtime and localtime functions to put the time in a human-readable format. The stat and utime functions also use the time functions when comparing file modification and access times.
The gmtime Function
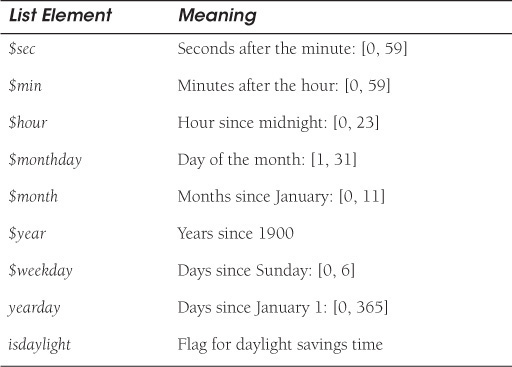
The gmtime function converts the return value of the time function to a nine-element array consisting of the numeric values for the GMT. If you are a C programmer, you will recognize that these values are taken directly from the tm structure found in the header file /usr/include/time.h. See Table 16.11.
The localtime Function
The localtime function converts the UTC to a nine-element array with the local time zone.
16.2.8 Process Creation UNIX
What happens when your Perl program starts executing? Here is a brief sketch of what goes on. Normally, the Perl program is executed from the shell command line. You type the name of your script (and its arguments) and then press the ENTER key. At that point, the shell starts working. It first creates (forks) a new process called the child process. The child is essentially a copy of the shell that created it. There are now two processes running, the parent and child shells.
After the child process is created, the parent shell normally sleeps (waits) while its child process gets everything ready for your Perl program; that is, it handles redirection (if necessary), pipes, background processing, and so forth. When the child shell has completed its tasks, it then executes (execs) your Perl program in place of itself. When the Perl process completes, it exits (exits), and its exit status is returned to the waiting parent process, the shell. The shell wakes up, and a prompt appears on the screen. If you type in a UNIX command, this whole process is repeated.
It’s conceivable that your Perl program may want to start up a child process to handle a specific task; for example, a database application or a client/server program.
The fork Function
You use the fork function to create processes on UNIX systems. The fork function is called once and returns twice. It creates a duplicate of the parent (calling) process. The new process is called the child process. The child process inherits its environment, open files, real and user IDs, masks, current working directory, signals, and so on. Both processes, parent and child, execute the same code, starting with the instruction right after the fork function call.
The fork function lets you differentiate between the parent and child because it returns a different value to each process. It returns 0 to the child process and the pid of the child to the parent process. It is not guaranteed which process will execute first after the call to the fork function.
Normally, the wait, exec, and exit functions work in conjunction with the fork function so that you can control what both the parent and the child are doing. The parent, for example, waits for the child to finish performing some task, and after the child exits, the parent resumes where it left off.
Figure 16.6 illustrates how the UNIX shell uses the fork system call to create a new process. After you type the name of your Perl program at the shell prompt, the shell forks, creating a copy of itself called the child process. The parent shell sleeps (waits). The child shell executes (execs) the Perl process in its place. The child never returns. Note that ENV variables, standard input, output, and standard error are inherited. When the Perl program completes, it exits and the parent shell wakes up. The shell prompt reappears on your screen. The Perl program could use the fork function to spawn off another application program.
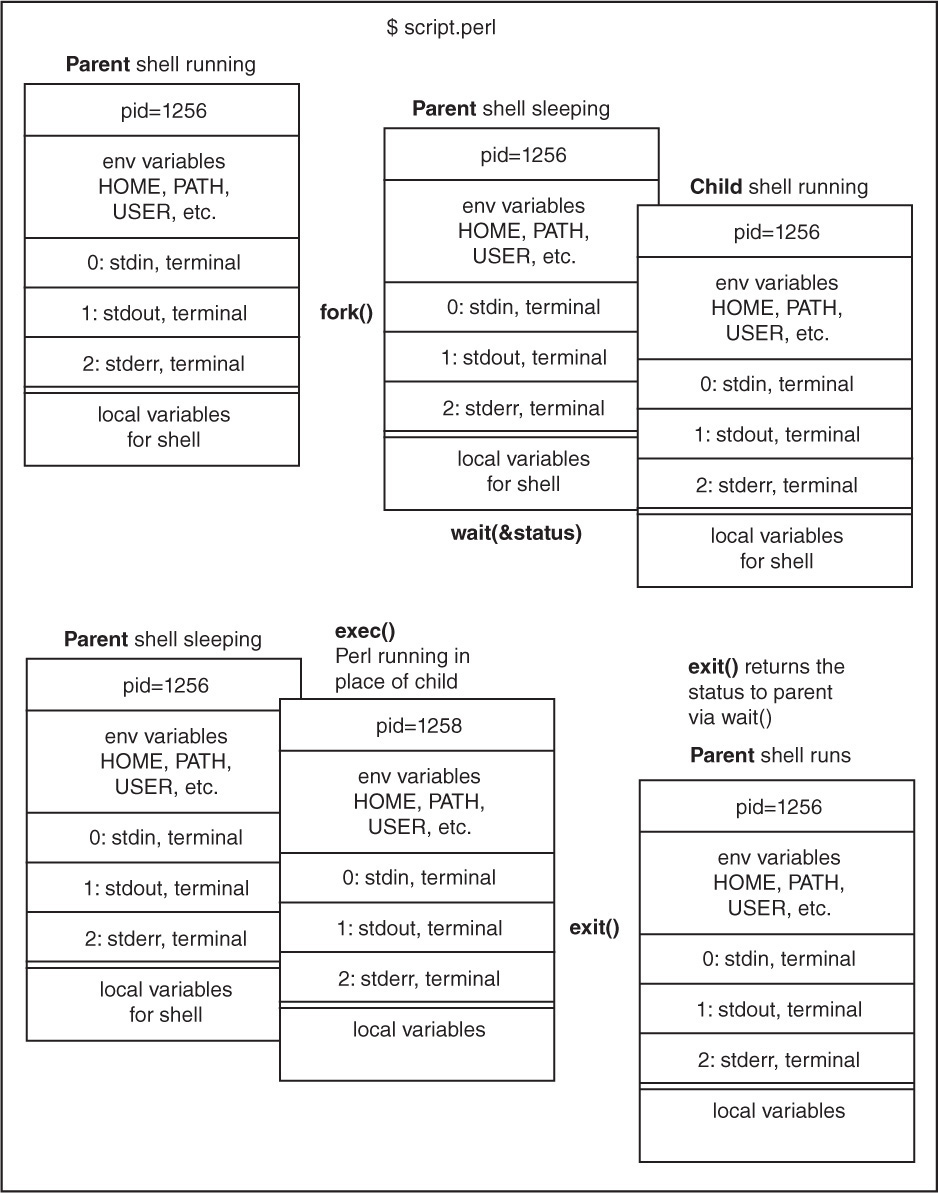
The exec Function
While fork creates a brand new process, the exec function initiates a new program in place of the currently running program. Normally, the exec function is called after fork. Perl inherits attributes from the shell, and a process that is executed from within Perl also inherits Perl’s attributes, such as pid, gid, uid, signals, directories, and so forth. If, then, the exec function is called directly (no fork) from within a Perl script, the new program executes in place of the currently running Perl program. When that program completes, you do not return to your Perl program. Since exec does not flush the output buffer, the $| variable needs to be set to ensure command buffering.
The filehandles STDIN, STDOUT, and STDERR remain open following a call to the exec function.
At the system level, there are six different exec functions used to initiate new programs. Perl calls the C library function execvp if more than one argument is passed to the exec function. The arguments are the name of the program to execute and any other arguments that will be passed to that program. If a single scalar is passed to the exec function and it contains any shell metacharacters, the shell command /bin/sh -c is passed the command for interpretation.
The wait and waitpid Functions
The wait function waits for a child process to finish execution. After a fork call, both processes, parent and child, execute. The wait function forces the parent to wait until its child is finished and returns the pid of the child process to the parent. If there are no child processes, wait returns a -1.11
11. The waitpid function also waits for a child process to finish execution, but it can specify which child it will wait for, and it has special flags that control blocking.
The exit Function
The exit function causes the program to exit. It can be given an integer argument ranging from values between 0 and 255. The exit value is returned to the parent process via the wait function call. By convention, UNIX programs exiting with a zero status are successful, and those exiting with nonzero failed in some way. (Of course, the criteria for success for one programmer may not be the same as those for another.)
16.2.9 Process Creation Win32
You can use the system and exec functions and backquotes on Win32 systems just the same as you would with UNIX.
The start Command
The Perl system function is used by both Windows and UNIX to start an operating system command. The system function executes a program and doesn’t return until that program finishes. If the Windows start command is given as an argument to the Perl system function, a new application will run, and your script will also continue to run.
The Win32::Spawn Function
The Win32::Spawn function behaves like the system function and the Windows Start command.
The Win32::Process Module
Another extension you can use to launch Windows applications is the object-oriented Win32::Process module. It provides a number of methods to create and manage processes. You can suspend, resume, and kill processes with this module. See Table 16.12.

16.3 Other Ways to Interface with the Operating System
If the system functions are still not enough, Perl offers a number of alternative ways to deal with the operating system. You can use the syscall function, command substitution, the system function, and the here document to get system information.
16.3.1 The syscall Function and the h2ph Script
The syscall function calls a specified system call with its arguments. If the C system call is not implemented, a fatal error is returned. The first argument is the name of the system call, preceded by &SYS_. The remaining arguments are the actual parameters that are required by the real system call. If the argument is numeric, it is passed as a C integer. If not, the pointer to the string value is passed. You may have to coerce a number to an integer by adding 0 to it if it is not a literal and cannot be interpreted by context.
Before using the syscall function, you should run a script called h2ph (h2ph.bat on Windows) that comes with the Perl distribution (http://perldoc.perl.org/h2ph.html). At the bottom of the h2ph script (after _ _END_ _) are the manual pages for h2ph, including an explanation on how to run the script. This script converts the proper C header files to the corresponding Perl header files. You must add these files to the Perl library if you are using functions that require them. All the files created have the .ph extension. After running the h2ph script, make sure that the @INC array in your program includes the path to these library functions.12
12. See also the h2xs script that comes with the Perl 5 distribution, for building a Perl extension from any C header file.
16.3.2 Command Substitution—The Backquotes
Although we have already discussed command substitution and backquotes in Chapter 5, “What’s in a Name?” a quick review might be in order here because command substitution is yet another way for Perl to interface with operating system commands.
Backquotes are used by the UNIX/Linux shells (not Windows) to perform command substitution and are implemented in Perl scripts pretty much the same way. For example, the command line echo The present working directory is `pwd` will cause the command in backquotes to be executed and its results substituted into the string. Like the UNIX/Linux shell, enclosing a command in backquotes causes it to execute. Unlike the shell, if double quotes surround the backquoted string, command substitution will not occur. The output resulting from executing the command is saved in a scalar variable.
16.3.3 The Shell.pm Module
This module lets you use UNIX commands that you normally type at the shell prompt in a Perl script. The commands are treated like Perl subroutines. Arguments and options are passed to the commands as a list of strings. As of Perl 5.16, this core module has been removed and can be found at CPAN.
16.3.4 The system Function
Like its C counterpart, the system function takes a system command as its argument, sends the command to the system shell for interpretation, and returns control back to the calling program, your script. This is just like the exec functions, except that a fork is done first, so that control is returned to the Perl script. Because it does not flush the output buffer, the special Perl variable $| is set to 1 to force the buffer to flush after print or write statements.13
13. A fork is done, the script waits for the command to be executed, and control is then returned to the script.
16.3.5 Globbing (Filename Expansion and Wildcards)
If you have worked at the UNIX or MS-DOS command line, you have been introduced to the shell metacharacters used to expand filenames. The asterisk (*) is used to match all characters in a filename, the question mark (?) to match one character in a filename, and brackets ([ ]) to match one of a set of characters in a filename. The process of expanding these shell metacharacters to a filename is called globbing.
Perl supports globbing if the filenames are placed within angle brackets, the read operators. However, today you should use the built-in glob function, shown next. The following example is here so that if you encounter older code, you will understand what is going on.
The glob Function
The builtin glob function does the same thing as the <*> operator and is the function you should use when globbing filenames. It expands the filename metacharacters just as the shell does and returns the expanded filenames.
16.4 Error Handling
There are a number of occasions when a system call can fail; for example, when you try to open a file that doesn’t exist or remove a directory when it still contains files or when you try to read from a file for which you do not have read permission. Although we have used the die function in earlier examples, now we will go into more detail about error handling and functions you can use to handle errors. The functions are the die function, the warn function, and the eval function.
• Use the die function to quit the Perl script if a command or filehandle fails.
• The warn function is like the die function, but it does not exit the script.
• The eval function has multiple uses, but it is used primarily for exception handling.
You may remember that the short-circuit operators, && and ||, evaluate the operands on the left and then evaluate the operands on the right. If the operand to the left of the && is true, the right-hand side is evaluated. If the operand to the left of the || is false, the right-hand side is evaluated.
16.4.1 The Carp Module
There are many ways to die. Perl 5’s Carp module extends the functionality of die and warn.
The die Function
If a system call fails, the die function prints a string to STDERR and exits with the current value of $!. The $! variable yields the current value of errno, the UNIX global variable containing a number indicating a system error. The only time that errno is updated is when a system call fails. When a system call fails, a code number is assigned to errno to indicate the type of error. If the newline is omitted in the string, the message is printed with its line number. (See /usr/include/sys for a complete list.)
Here is an example from /usr/include/sys/errno.h:
#define EPERM 1 /* Not owner */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
...
Win32 error codes differ from UNIX error codes, making it impossible to rely on the value returned in $!. There are a number of Win32 extensions that provide their own error functions to give more meaningful results. See the documentation for Win32::GetLastError in the standard Perl library included with ActiveState.
The warn Function
The warn function is just like the die function except that the program continues to run. If the die function is called in an eval block, the argument string given to die will be assigned to the special variable $@. After a die, this variable can pass as an argument to warn and the output sent to STDERR. (See Section 16.4.2, “The eval Function.”)
16.4.2 The eval Function
Use the eval function for exception handling; that is, catching errors. The block following eval is treated and parsed like a separate Perl program, except that all variable settings and subroutine and format definitions remain after eval is finished.
The value returned from the eval function is that of the last expression evaluated. If there is a compile or runtime error or the die statement is executed, an undefined value is returned, and a special variable, $@, is set to the error message. If there is no error, $@ is a null string.
Example 16.65 shows an example of evaluating Perl expressions using eval.
Next, we will see how to use eval to catch errors in a program.
The next example shows how to use the eval function with a here document.
16.5 Signals and the %SIG Hash
A signal sends a message to a process and normally causes the process to terminate, usually due to some unexpected event, such as illegal division by zero, a segmentation violation, a bus error, or a power failure. The UNIX kernel also uses signals as timers; for example, to send an alarm signal to a process. The user sends signals when he hits the BREAK, DELETE, QUIT, or STOP keys.
The kernel recognizes 31 different signals, listed in /usr/include/signal.h. You can get a list of signals by simply typing kill -l at the UNIX prompt (see Table 6.13).

16.5.1 Catching Signals
Signals are asynchronous events; that is, the process doesn’t know when a signal will arrive. Programmatically, you can ignore certain signals coming into your process or set up a signal handler to execute a subroutine when the signal arrives. In Perl scripts, any signals you specifically want to handle are set in the %SIG hash. If a signal is ignored, it will be ignored after fork or exec function calls.
A signal may be ignored or handled for a segment of your program and then reset to its default behavior. See http://perldoc.perl.org/perlvar.html for more examples.
16.5.2 Sending Signals to Processes
The kill Function
If you want to send a signal to a process or list of processes, use the kill function. The first element of the list is the signal. The signal is a numeric value or a signal name if quoted. The function returns the number of processes that received the signal successfully. A process group is killed if the signal number is negative. You must own a process to kill it; that is, the effective uid and real uid must be the same for the process sending the kill signal and the process receiving the kill signal.
For complex signal handling, see the POSIX module in the Perl standard library.
The alarm Function
The alarm function tells the kernel to send a SIGALARM signal to the calling process after some number of seconds. Only one alarm can be in effect at a time. If you call alarm and an alarm is already in effect, the previous value is overwritten.
The sleep Function
The sleep function causes the process to pause for a number of seconds or forever if a number of seconds is not specified. It returns the number of seconds that the process slept. You can use the alarm function to interrupt the sleep.
16.5.3 Attention, Windows Users!
For those Win32 systems, the following functions have not been fully implemented. Primary among these is alarm(), which is used in a few Perl modules. Following is a list of unimplemented functions.
Functions for processes and process groups:
• alarm(), fork(), getpgrp(), getppid(), getpriority(), setpgrp(), setpriority()
Functions for fetching user and group info:
• endgrent(), endpwent(), getgrent(), getgrgid(), getgrnam(), getpwent(), getpwnam(), getpwuid(), setgrent(), setpwent()
System V interprocess communication functions:
• msgctl(), msgget(), msgrcv(), msgsnd(), semctl(), semget(), semop(), shmctl(), shmget(), shmread(), shmwrite()
Functions for filehandles, files, or directories:
• link(), symlink(), chroot()
Input and output functions:
• syscall()
Functions for fetching network info:
• getnetbyname(), getnetbyaddr(), getnetent(), getprotoent(), getservent(), sethostent(), setnetent(), setprotoent(), setservent(), endhostent(), endnetent(), endprotoent(), endservent(), socketpair()
See the perlport and perlwin32 documentation pages for more information on the portability of built-in functions in ActivePerl.
16.6 What You Should Know
1. What are system calls?
2. How does Perl make calls to the system?
3. What module is used to traverse a file system?
4. How are directories created and removed?
5. How do you get the date and time with Time::Piece?
6. What is meant by the environment?
7. What is a process?
8. What do fork and exec accomplish?
9. Where can you find modules for Windows processes?
10. How does the system function differ from using command substitution (backquotes) when executing system commands?
11. What is globbing?
12. How does eval work with die?
13. What are signals?
14. How does Perl deal with signals?
15. How do you rename a file with Perl?
16. How do you remove a file with Perl?
Exercise 16: Interfacing with the System
1. From a Perl script:
a. Create a directory/folder and change to that directory.
b. Print the current working directory and create a new file in the directory called testing.txt.
c. Rename the file junk.txt.
2. In a Perl script, open up your top-level directory using the opendir function. List all readable files in the directory. Clear the screen.
3. PING means Packet InterNet Groper. It is a program and command that helps testing and debugging network and/or Internet connections. Use the ping command in a Perl script to check network connectivity for your host machine. (Use ping for UNIX or ping -t for Windows.) It will continuously print output. After 20 seconds, send a signal to the program to stop pinging.
4. Use the Time::Piece module to get today’s day, week day, month day, and year.
5. Use the stat function to get the last time all files in your present working directory were modified.