
INTRODUCTION

When I was in high school, I wanted to write a tic-tac-toe program that the user would play against a computer. At the time, I was blissfully unaware of how real computer scientists approached such a problem. I had only my own thoughts, and those were to implement a lot of rules using the crude if-then statements and gotos supported by unstructured Applesoft BASIC. It was a lot of rules—a few hundred lines’ worth.
In the end, the program worked well enough, until I found the sequence of moves that my rules didn’t cover and was able to win every time. I felt certain that there must be a way to teach a computer how to do things by showing it examples instead of brute-force code and rules—a way to make the computer learn on its own.
As an undergraduate student in the later 1980s, I was excited to sign up for a course in artificial intelligence. The course finally answered my question about how to write a tic-tac-toe playing program, but the computer wasn’t learning; it was still just using a clever algorithm. Incidentally, the same course assured us that while it was expected that someday a computer would beat the world’s best chess player, which happened in 1997, it was impossible for a computer to beat the best human at a game like Go. In March 2016, the AlphaGo deep learning program did just that.
In 2003, while working as a consultant for a scientific computing company, I was assigned to a project with a major medical device manufacturer. The goal was to classify, in real time, intravascular ultrasound images of coronary arteries by using machine learning: a subfield of artificial intelligence that learns from data on its own, developing models that were not explicitly programmed by a human. This was what I was waiting for!
I was vaguely aware of machine learning and that there were strange beasts called neural networks that could do some interesting things, but for the most part, machine learning was simply a small research area and not something the average computer science person paid much attention to. However, during the project, I fell in love with the idea of training a machine to do something useful without explicitly writing a lot of code. I kept learning on my own, even after the project ended.
Circa 2010, I was involved with another machine learning project, and the timing was perfect. People were just beginning to discuss a new approach to machine learning called deep learning, which revived the old neural networks. When 2012 rolled around, the flood-gates opened. I was fortunate enough to be in the room at the ICML 2012 conference in Edinburgh, Scotland when Google presented its initial breakthrough deep learning results that responded to cats in YouTube videos. The room was crowded. After all, there were a whopping 800 people at the conference.
It’s now 2020, and the machine learning conference I recently went to had over 13,000 attendees. Machine learning has exploded: it’s not a fad that will disappear. Machine learning has profoundly affected our lives and will continue to do so. It would be nice to know something about it, to get past the oftentimes hyped-up presentations down to the essential core, which is interesting enough, no hype needed. That is why this book exists, to help you learn the essentials of machine learning. Specifically, we’ll be focusing on the approach known as deep learning.
Who Is This Book For?
I wrote this book for readers who have no background in machine learning, but who are curious and willing to experiment with things. I’ve kept the math to a minimum. My goal is to help you understand core concepts and build intuition you can use going forward.
At the same time, I didn’t want to write a book that simply instructed you on how to use existing toolkits but was devoid of any real substance as to the why of things. It’s true that if all you care about is the how, you can build useful models. But without the why, you’ll only be parroting, not understanding, let alone eventually moving the field forward with your own contributions.
As far as assumptions on my part, I assume you have some familiarity with computer programming, in any language. The language of choice for machine learning, whether you are a student or a major corporation, is Python, so that’s the language we’ll use. I’ll also assume you’re familiar with high school math but not calculus. A little calculus will creep in anyway, but you should be able to follow the ideas, even if the technique is unfamiliar. I’ll also assume you know a bit of statistics and basic probability. If you’ve forgotten those topics since high school, don’t worry—you’ll find relevant sections in Chapter 1 that give you enough of a background to follow the narrative.
What Can You Expect to Learn?
If you work through this book in its entirety, you can expect to learn about the following:
- How to build a good training dataset. This is a dataset that will let your model be successful when used “in the wild.”
- How to work with two of the leading machine learning toolkits: scikit-learn and Keras.
- How to evaluate the performance of a model once you’ve trained and tested it.
- How to use several classical machine learning models like k-Nearest Neighbors, Random Forests, or Support Vector Machines.
- How neural networks work and are trained.
- How to develop models using convolutional neural networks.
- How to start with a given set of data and develop a successful model from scratch.
About This Book
This book is about machine learning. Machine learning is about building models that take input data and arrive at some conclusion from that data. That conclusion might be a label placing the object into a particular class of objects, like a certain kind of dog, or a continuous output value, say the price one should ask for a house with the given set of amenities. The key here is that the model learns from the data on its own. In effect, the model learns by example.
You can think of the model as a mathematical function, y = f (x), where y is the output, the class label, or the continuous value, and x is the set of features representing the unknown input. Features are measurements or information about the input that the model can use to learn what output to generate. For example, x might be a vector representing the length, width, and weight of a fish, where each of those measurements is a feature. Our goal is to find f, a mapping between x and y that we’ll be able to use on new instances of x, for which we do not know y.
The standard way to learn f is to give our model (or algorithm) known data, and have the model learn the parameters it needs to make f a useful mapping. This is why it’s called machine learning: the machine is learning the parameters of the model. We’re not thinking of the rules ourselves and cementing them in code. Indeed, for some model types like neural networks, it’s not even clear what the model has learned, only that the model is now performing at a useful level.
There are three main branches to machine learning: supervised learning, unsupervised learning, and reinforcement learning. The process we just described falls under supervised learning. We supervised the training of the model with a set of known x and y values, the training set. We call a dataset like this a labeled dataset because we know the y that goes with each x. Unsupervised learning attempts to learn the parameters used by the model using only x. We won’t discuss unsupervised learning here, but you can transfer a lot of our discussion of supervised learning if you want to explore that area on your own later.
Reinforcement learning trains models to perform tasks, like playing chess or Go. The model learns a set of actions to take given the current state of its world. This is an important area of machine learning, and it has recently achieved a high level of success on tasks previously thought to be solely the domain of humans. Sadly, compromises had to be made to make this book manageable, so we’ll ignore reinforcement learning altogether.
One quick note on terminology. In the media, a lot of what we’re talking about in this book is referred to as artificial intelligence, or AI. While this is not wrong, it’s somewhat misleading: machine learning is one subfield of the broader field of artificial intelligence. Another term you’ll often hear is deep learning. This term is a bit nebulous, but for our purposes, we’ll use it to mean machine learning with neural networks, in particular, neural networks with many layers (hence deep). Figure 1 shows the relationship between these terms.
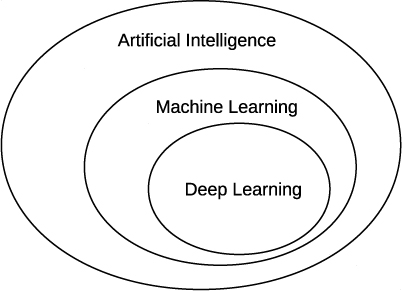
Figure 1: The relationship between artificial intelligence, machine learning, and deep learning
Of course, within the fields of machine learning and deep learning, there’s considerable variety. We’ll encounter a number of models throughout this book. We could arrange them in what we’ll call “the tree of machine learning,” pictured in Figure 2.
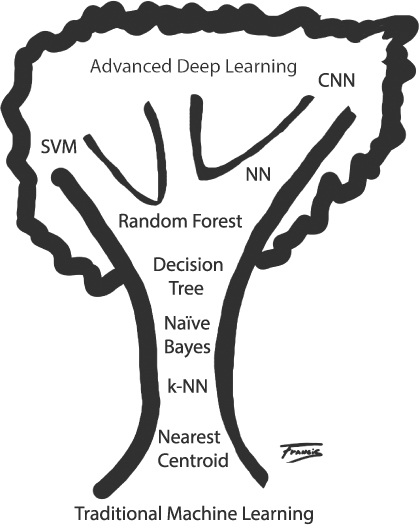
Figure 2: The tree of machine learning
The tree shows the growth from traditional machine learning at the root to modern deep learning at the top of the tree. Consider this a preview of what’s to come: we’ll look at each of these models in this book.
Along those same lines, we’ll end this introduction with a quick synopsis of each chapter.
Chapter 1: Getting Started This chapter tells you how to set up our assumed working environment. It also includes sections about vectors, matrices, probability, and statistics that you can use as refreshers or for background.
Chapter 2: Using Python This chapter will get you started on Python.
Chapter 3: Using NumPy NumPy is an extension to Python. It’s what makes Python useful for machine learning. If you are not familiar with it, peruse this chapter.
Chapter 4: Working with Data Bad datasets lead to bad models; we’ll teach you what makes a good one.
Chapter 5: Building Datasets We’ll build the datasets used throughout the book. You’ll also learn how to augment datasets.
Chapter 6: Classical Machine Learning To understand where you are going, sometimes it’s good to know where you came from. Here we’ll cover some of the original machine learning models.
Chapter 7: Experiments with Classical Models This chapter shows the strengths and weaknesses of the old-school approach to machine learning. We’ll refer to these results for comparison purposes throughout the book.
Chapter 8: Introduction to Neural Networks Modern deep learning is all about neural networks; we’ll introduce them here.
Chapter 9: Training a Neural Network This challenging chapter gives you the knowledge you need to understand how neural networks are trained. Some basic calculus slipped into this chapter, but don’t panic—it’s discussed at a high level to give you intuition, and the notation isn’t as frightening as it might seem at first.
Chapter 10: Experiments with Neural Networks Here we run experiments to build intuition and get a feel for actually working with data.
Chapter 11: Evaluating Models To understand the results presented in machine learning papers, talks, and lectures, we need to understand how to evaluate models. This chapter will take you through the process.
Chapter 12: Introduction to Convolutional Neural Networks The deep learning we will focus on in this book is embodied in the idea of a convolutional neural network, or CNN. This chapter discusses the basic building blocks of these networks.
Chapter 13: Experiments with Keras and MNIST Here we’ll explore how CNNs work by experimenting with the MNIST dataset, the workhorse of deep learning.
Chapter 14: Experiments with CIFAR-10 The MNIST dataset, useful as it is, is a simple one for CNNs to master. Here we explore another workhorse dataset, CIFAR-10, which consists of actual images and will challenge our models.
Chapter 15: A Case Study: Classifying Audio Samples We’ll conclude with a case study. We start with a new dataset, one not in widespread use, and work through the process of building a good model for it. This chapter uses everything we studied in the book, from building and augmenting data to classical models, traditional neural networks, CNNs, and ensembles of models.
Chapter 16: Going Further No book is complete. This one won’t even try to be. This chapter points out some of what we’ve neglected and helps you sift through the mountains of resources around you related to machine learning so you can focus on what you should study next.
All the code in the book, organized by chapter, can be found here: https://nostarch.com/practical-deep-learning-python/. Let’s now take a look at setting up our operating environment.