
One of the main advantages of the purity that Haskell embodies is the ability to run code in parallel easily. The absence of side effects means that all data dependencies are explicit in the code. Thus, the compiler (and you) can schedule different tasks with no dependencies between them to be performed in parallel.
The Par monad enables you to make explicit which parts of your code would benefit from being run in parallel. The model supported by Par allows you to write code using both the futures model and the dataflow parallelism approach. Then, a scheduler takes care of running your code using parallel threads. Par is a powerful abstraction because you don’t need to take care of managing the creation and destruction of threads; just let the library do what it does.
In some cases, though, several parallel tasks need to share resources in a way not expressible using Par. In the Time Machine Store, for example, several clients may be buying some items, which implies that several database updates will be happening at the same time. In those scenarios, ensuring that the resources are accessed concurrently in the right way is essential. Haskell features Software Transactional Memory as the way to control this behavior, using the idea of transactions brought from database systems.
Finally, you may want to split the computation between several nodes that are distributed across a network. One of the many ways to communicate those nodes is to use a message queue. In this chapter we look at how to use AMQP, a message queuing protocol, to exchange simple messages.
Parallelism, Concurrency, and Distribution
There’s always some confusion between the terms parallel programming, concurrent programming, and distributed programming. Concurrency is a programming model where the computation is designed as several, mostly independent, threads of control. The system may either interweave the computations or run them in parallel, but in any case the illusion is that all of them work asynchronously. One archetypal example of a concurrent application is a web server. Many clients request services at the same time, and from programmers’ point of view, each of these requests is independent and happens asynchronously.
In most cases, those threads need access to some shared resource. At this point, you must ensure that concurrent access does not leave the system in an inconsistent way. For that purpose, many programming techniques have been developed, including locks, semaphores, and channels. In the case of Haskell, a model called Software Transactional Memory (STM) brings the concept of atomic transactions from databases into your code to enable optimistic concurrency with rollback.
Parallelism refers to a way of executing code in more than one computer core at once. Concurrent tasks are often run in parallel to achieve much better performance. This increment in speed can also be applied to tasks that were not thought of as concurrent but whose data dependencies enable running parts of the algorithm independently of each other. Think of the QuickSort algorithm for sorting: at each step the list is divided in two parts, and each of them is sorted separately. In this case, the subsequent sorting of the two lists can be made in parallel.
For this second case, Haskell is the perfect field. Pure computations can’t interfere with each other, and their data dependencies are completely explicit. The Par monad , which will be introduced later, follows this line of thought and enables parallelism for tasks.
In many cases, the confusion between parallelism and concurrency comes from languages with side effects. In languages such as Java or C, any piece of code can access and change global state. For that reason, any amount of parallelism must also take care of the access to those shared resources and thus is required for concurrent programming. You cannot really separate both in that context.
Parallel programming is usually associated with running tasks in different cores (microprocessors or GPUs) on the same computer system. But the work can also be split between different computers that communicate across a network. That’s where distributed programming comes into play. Since each of the actors in the system is independent from any other, the coordination of tasks must happen in a different way from one-system parallel programming. Furthermore, communication through a network imposes constraints in case of failure or big latency. For all these reasons, distributed programming needs other techniques.
One of the biggest challenges is to ensure reliable communication: in a network messages may be lost, duplicated, or come out of order. In some cases, routing messages to different actors, or choosing an actor among an available pool is required to perform efficiently. A standard approach to this problem is to introduce an intermediate message broker. AMQP is a common protocol for dealing with message queues. There are several implementations; RabbitMQ is a widely used one. The amqp-worker package provides a simple interface for exchanging messages via this protocol and leverages several Haskell-specific techniques.
Tip
“Concurrency is about dealing with lots of things at once. Parallelism is about doing a lot of things at once.” – Rob Pike
The fields of parallel, concurrent, and distributed programming in Haskell are much wider than what will be shown in this chapter. The libraries explained here can be used in many other ways, and many other packages are available in Hackage. For parallel programming you have the parallel package, which features the strategies approach. Parallelism is not only available for processors. Accelerate builds code to be run in a GPU. Haskell’s base package features low-level functionality for concurrency in the Control.Concurrent module, including mutable memory locations (MVars) and semaphores. The distributed-process set of packages introduces Erlang-style actors which can share both code and data. The book Parallel and Concurrent Programming in Haskell by Simon Marlow describes several of these techniques in much more depth than this chapter.
The Par Monad
This section will focus on the parallel programming package called monad-par. The functions in that library revolve around the Par monad and the use of IVars for communication results. As you will see, computation can be modeled in two ways with this package: as futures or as dataflow programs.
Futures
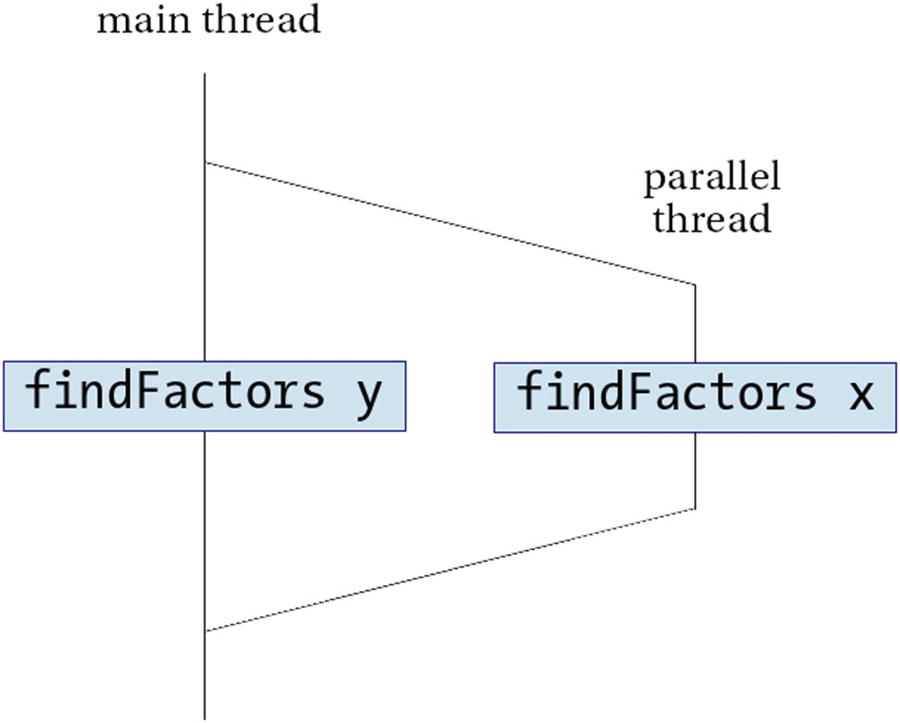
Parallel computation of two prime factorizations
The purpose of spawnP is just running a computation in parallel with the rest of the program. However, there are three things to notice from that signature. First, it requires the computation to be run to have a type supporting the NFData type class. If you remember, this is a type found in the deepseq package, which ensures that the computation is fully evaluated. spawnP imposes this constraint because it’s the only way to ensure that the code will actually run in parallel. If that constraint wasn’t there, the lazy evaluation model may make it run at any other time, losing the benefit of parallelism. Since the use of spawnP fully determines when some computation will be executed, the parallel model of monad-par is called deterministic .
The second thing you may notice is that the result is wrapped inside Par. This type is the monad in which parallelism is run. Finally, instead of just a value, the result of spawnP is an IVar. An IVar is a future, a promise that the result of the computation will be available when requested. To get the result of the computation inside an IVar, you must call the get function. This function returns immediately if the computation has finished or blocks execution until the result is available. This is the same model used in Scala or in the Task Parallel Library in C#.
Notice the call to rnf from the deepseq library to fully evaluate the factorization of y.
The +RTS option indicates the start of the options given to the Haskell runtime. In particular, -N2 indicates that two processors should be used. You can indicate at most the number of processors in your system. If you like, you can specify –N by itself, without a number, and allow the Haskell runtime to make the decision on the number of processors to use.
Dataflow Parallelism with IVars
The monad-par package not only provides futures but also a wider model of declaring parallel computations. Instead of just spawning parallel computations, you specify several steps of computation, which share intermediate results via IVars. These variables are created via new. Tasks can write to an IVar via the put function and obtain a result via get. Notice that an IVar is a write-once variable.
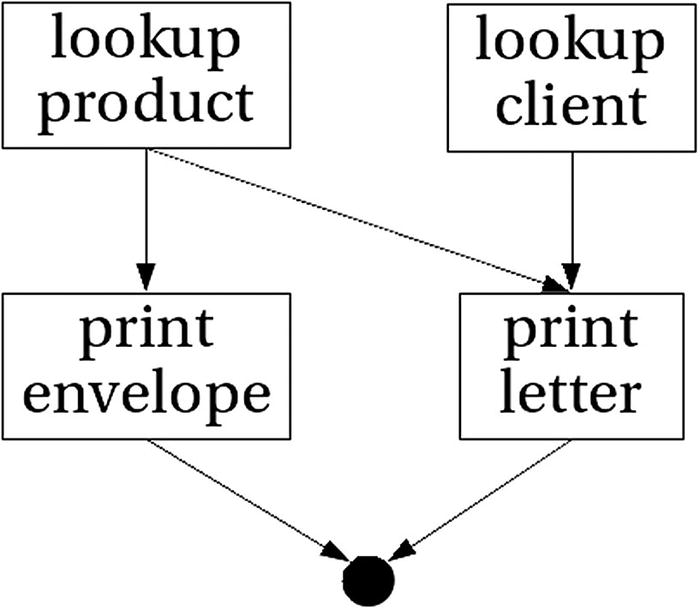
Dataflow graph of letter building
Computations built in this way always follow the shape of a graph of tasks joined by IVars to communicate. For that reason, the model is called dataflow programming. The main benefit of this approach is that all data dependencies are explicit; they are exactly those specified by the IVars. The monad-par library takes advantage of that information for scheduling the tasks in a parallel way.
One interesting benefit of separating the dataflow dependencies from the actual parallel execution is that several strategies for scheduling the tasks can be used. By default, monad-par uses the so-called Direct scheduler. Two others are available; just import Control.Monad.Par.Scheds.Spark or Control.Monad.Par.Scheds.Trace instead of Control.Monad.Par, and the corresponding scheduler will be used.
Parallelizing the Apriori Algorithm
Let’s finish this section by looking at how the Apriori algorithm could be enhanced to perform in parallel. The code will be based on the implementation in Chapter 7.
Note
Remember that to use monad-par, your data types must instantiate NFData.
As you can see, the monad-par library makes it easy to add parallelism to your current code. The focus of this library is futures and dataflow programming. There are other approaches, though. The parallel library, for example, uses another monad called Eval that helps to define how a specific data structure can be traversed in parallel. You can find more information about this and other packages on the Haskell wiki.1
Parallelizing Tasks with Side Effects
Computation with arbitrary side effects hasn’t been introduced yet. However, as a reference, it’s interesting to know that the monad-par package provides another monad for parallelism, called ParIO and available in the Control.Monad.Par.IO module, in which side effects are allowed. The interface is the same as pure Par, except for running the computation, which is achieved via the runParIO function.
Note that the implementation does not guarantee any ordering on the execution of the tasks, and thus the outcome will show nondeterministic ordering of the side effects.
Many algorithms that work on lists or have a divide-and-conquer skeleton can be easily turned into parallel algorithms via the monad-par library. In Exercise 8-1 you’re asked to do this with the other data-mining algorithm introduced in this book: K-means.
Exercise 8-1. Parallel K-means
Write a parallel version of the K-means algorithm developed in Chapter 6. To make the task a bit easier, you may look at the first implementation, which didn’t use monads. Remember, when using functions such as parMap, think about when the overhead of creating parallel tasks will exceed the benefits.
Software Transactional Memory
In this section you will look at problems where several threads of execution interact with each other and share resources; that is, concurrency comes into play. Haskell allows you to design concurrent tools in the classical way, using locks, semaphores, and so on, but in this section you will see how the functional style of programming enables you to use a much more powerful abstraction called Software Transactional Memory.
Before starting, you should be aware that code using concurrency is considered side-effect code. When several threads are executing asynchronously and sharing resources, the order in which they do this affects the observable outcome. In contrast, in pure code the order in which functions are evaluated is irrelevant because the result will be the same.
You will learn more about how to deal with arbitrary side effects in the next chapter. For the time being, you just need to know that Haskell uses a special monad called IO, in which you can use side effects. In the code, the only difference you will see between programming with and without side effects is that do notation is used.
Concurrent Use of Resources
The first thing you need to know is how to create a new thread of execution. You achieve this via the forkIO function in the Control.Concurrent module. This function takes as an argument an action of type IO () and starts executing that code in parallel.
Note
forkIO returns a thread identifier that allows you to pause and stop the thread that was just created. However, the functionality of the Control.Concurrent module won’t be covered in this book.
As you can see, the main function creates three threads running the same code. The next question is how to make those threads cooperate and share resources because by default they cannot communicate between them. The answer is via an MVar , a box that can hold a mutable variable, which can be read or updated. One of those boxes is created before forking the threads using the newMVar function and is given as an argument to each of them. Thus, the threads have access to a shared resource in the form of a mutable variable.
Each thread can read the value of the MVar using takeMVar and to write a new one using putMVar. What makes this type useful for concurrency is the special behavior that it shows in the presence of multiple threads. You should think of an MVar as a box that either is holding some element or is empty. When you use takeMVar, you either read the value being held and make the box empty or block until some element is put in there. Conversely, putMVar either writes a new value if the box is empty or waits. Furthermore, those functions guarantee that only one thread will be woken up if it is blocked and that threads will be served in a first-in, first-out order, which means that no thread can swallow the events of all the rest.
Notice that the code includes a call to getLine at the end. The purpose of this function is to wait for some user input. The reason you need it is because when the main thread ends its computation, any other thread created by forkIO dies with it. Thus, if you want to see the effect of the other threads, you need to add a way to make the main thread continue execution. Waiting for user input is one way to do this.
Note
None of the MVar-related functions forces the evaluation of the data inserted in them. This may cause problems because the price of executing some code may be paid much later, in the context of another computation. You may want to look at the strict-concurrency package to obtain a strict version of MVar.
Atomic Transactions
Your first impression may be that the code is quite complex. However, you want to update the stock and the price only when there are enough items to sell. And if you cannot perform the purchase, you wouldn’t want to block the access to the money shared variable. Thus, you need to plan for both possibilities and restore the initial stock if the transaction is not successful.

Example of deadlock
Another problem may occur in the following case of two updater threads, U1 and U2, and one reader thread that I’ll call R. It is possible that U1 updates the money variable and immediately afterward R reads that variable, obtaining the money after selling the item in U1. However, afterwards U1 can proceed, and the whole U2 is executed as well. By that time, the stock variable will contain the changes of both U1 and U2, and R will get stock information that is not consistent with the value it got from money. In this case, the problem is that a thread can get an inconsistent view of the world.
Both problems are common in systems where many agents update and query some data in a concurrent way. The best example of this pertains to database systems. The solution comes in the form of transactions. A transaction is a computation guaranteed to be run reliably independent from other transactions, and it always has a coherent view of the data. Transactions provide the illusion that a whole computation runs as an atomic block inside the database and ensure that data maintains its integrity.2
When using stm, instead of MVars you should use TVars . In contrast to the former, TVars can be read and written as many times as you want. Thus, you don’t need to write back the stock if the purchase could not be done.
The great advantage of having a function such as atomically is that you can delimit which parts of your code need to be run as a transaction and which don’t. This is important for performance. Keeping the guarantees of transactionality is expensive, and you should make minimal use of it.
Rolling Back Transactions
When working with databases, you often find scenarios in which your current transaction cannot be performed. Usually, this comes into play when considering the constraints that your data should maintain. For example, selling an item from the Store stock can be done only when the corresponding number of items of that product is larger than zero. When you abort a transaction, you want the state of the world to return to the previous moment in time, as if no computation has happened at all. This operation is called a rollback.
Code using retry has special behavior. As a first description, the transaction is executed repeatedly until it finally finds a scenario in which it succeeds. Of course, such an approach would be overkill. Internally, stm keeps track of which TVars influence the transaction and executes the code again only if any of them change. Not having to implement that functionality by hand makes your code much more modular and maintainable.
Another feature that the previous example demonstrates is the compositionality of transactions. Since a transaction is just a value of the STM monad , you can put several of them together to create a larger transaction. In the example, the check for the card system and the money and stock update are defined separately and then joined to make the larger payByCard transaction.
While retry is a powerful tool, in some cases you may want to follow a path different from waiting until the variables change and the invariants are satisfied. For those occasions, stm provides the orElse combinatory. In general, t1 `orElse` t2 behaves as t1. However, in the case in which t1 calls retry, the effects of t1 are rolled back, and t2 is run. If t2 ends successfully, no more work is done. If t2 also calls retry, the whole t1 `orElse` t2 transaction is restarted.
In Exercise 8-2 you can use your knowledge of transactions to build a Time Machine system.
Exercise 8-2. Traveling Through Time
The Time Machine Store also provides the service of time traveling. However, there are some restrictions that customers must abide by: at most n people can be traveling at the same moment (because the company owns only n time machines), and by no means should two people be on the same year at the same time.
Develop a small application where customers are simulated by different threads and the restrictions are always satisfied via a careful use of the stm library. Hint: use a shared TVar for saving the years that people are traveling to, and use retry to block customers from traveling without satisfying the rules.
Producer-Consumer Queues
Up to this point, the focus has been on threads that communicate using shared variables. But in the world of concurrency, there are many other ways in which two threads can share some data. Even more, data can be shared not only among threads, but also across different processes or different parts of the network. In this section you’ll see how to use a queue to implement a producer-consumer model.
One way to architect the Store, for example, is to have multiple front-end threads or processes and just one back end. The front ends are responsible for asking all the information that may be needed to perform a transaction. However, they are not responsible for processing the orders. That responsibility belongs to the back end.
Single-Process Queues
If you want to keep all your computation within a single process, you may think of using STM to handle concurrent access to the data. If you could use only TVars to implement this solution, you would have a tough time. You would need a concrete amount of possible front ends that may communicate, and the back end should always be on the lookout to see whether some of those variables have new information. The better solution is to stop using a TVar and instead use a queue.
The stm package provides several kinds of queues. The easiest one is called TQueue. You can put a new element on the queue using writeTQueue. This queue does not impose any limit on the number of elements that may be waiting in the queue (apart from the obvious constraints on memory available in the system), so the writeTQueue function will never block a thread. The converse operation, getting the first element from the queue, is done via readTQueue. If the queue is empty, the thread will be blocked.
Whether a queue has a bounded size or is unbounded. In the case of bounded queues, the creation of such a queue needs the maximum number of elements as a parameter. When calling the corresponding write function, if the queue is full, the thread is blocked until more space becomes available.
Whether a queue is closable. A queue that is closed cannot receive any more items. When this happens, every call to the write function is effectively discarded, and every read returns Nothing. Note that the behavior when the queue is closed and when it’s empty is completely different.
Types of STM Queues
Unbounded | Bounded | |
|---|---|---|
Not closable | TQueue (package stm) | TBQueue (package stm) |
Closable | TMQueue (package stm-chans) | TBMQueue (package stm-chans) |
Using queues can help in the design of the system from Exercise 8-2. Indeed, Exercise 8-3 asks you to use queues to make the management of clients in the store fairer.
Exercise 8-3. Queuing Travelers
In the previous exercise, all customers were trying to access the finite number of time machines at the same time. This may pose a problem of fairness because stm does not guarantee which thread will be woken up from retry if several are waiting.
An alternative solution involves using a queue where customers put their requests and where a master thread assigns time machines when they are free. Implement this solution using TBQueue.
Message Queues Using AMQP
The main caveat of the previous solution is that the queue can only be used by threads coming from the same process. But in many cases, you would like the front end and the back end to be different, isolated programs, maybe even running on different machines in the network. The main problem in that case is communication and sharing of resources: how to ensure that messages are transported correctly between processes, and how to ensure that all of them have a consistent view of the message queue.
There are many libraries available in Haskell to communicate through the network, starting with the network package. Alas, rolling your own messaging protocol does not seem like a good idea. Communication is known to be a tricky area of computer science, since many things can go wrong: messages can be lost, duplicated, or arrive out of order or simply very late. Fortunately, we do not need to write any of that code if we introduce a message broker to the mix.
A message broker is simply a program whose only role is to manage communication between nodes and processes. Their most basic functionality is to connect endpoints, sometimes by forwarding a message to more than one recipient. Many brokers also introduce a notion of message queue, where messages are saved until they are handled somehow. Most deployed message brokers with support for queues use the Advanced Message Queuing Protocol, or AMQP, which is the focus of this section.
Installing Rabbitmq
In order to run the code in this section, you need to have an AMQP-compatible broker in your machine. My suggestion is to use RabbitMQ, available at https://www.rabbitmq.com . The server runs in Linux, Windows, and MacOS X, and you can also get it as a Docker image. In the code below, I assume that you have RabbitMQ running in the default port, 5672, with the default security configuration, so we can access it as guests.
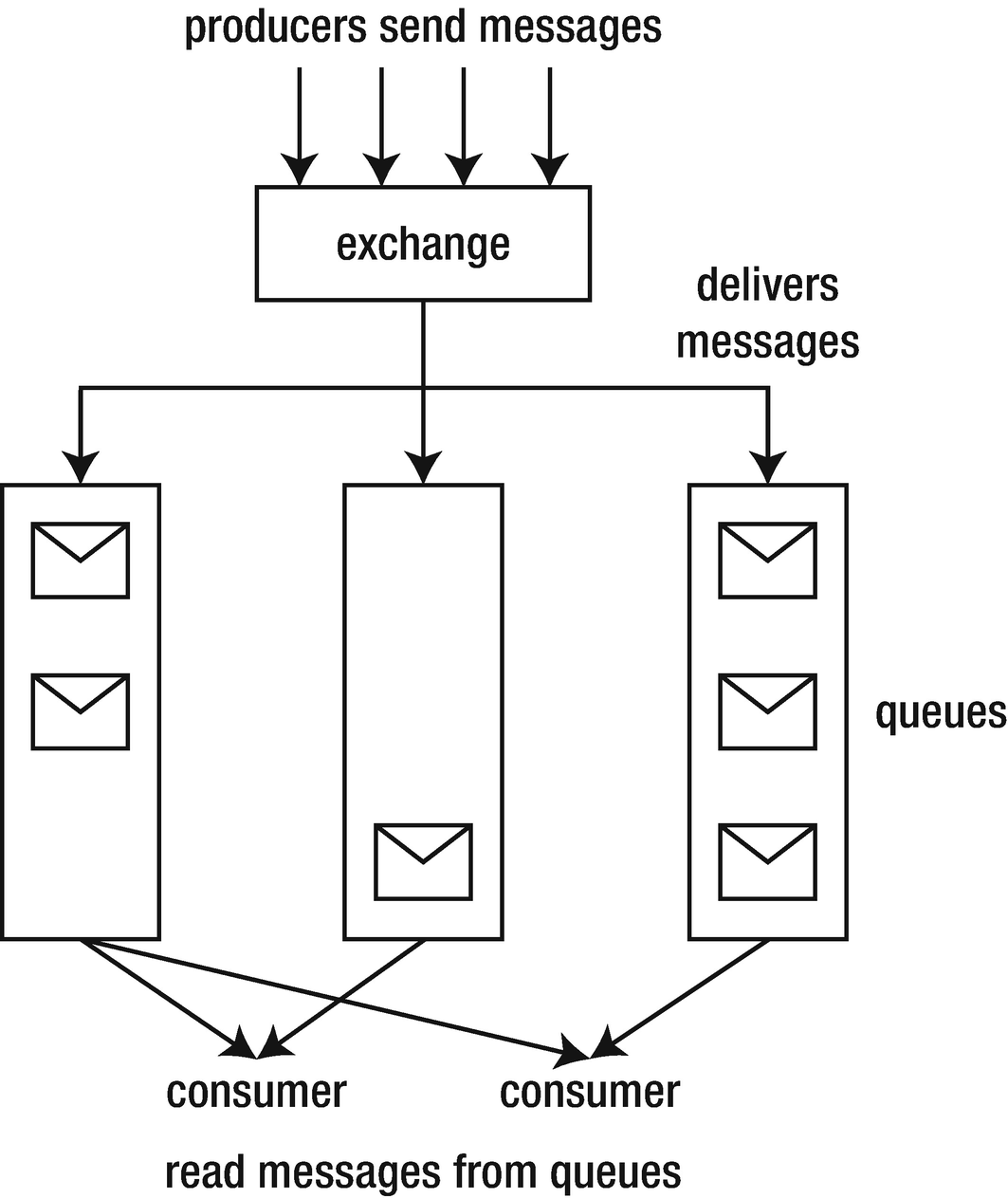
High-level view of the AMQP messaging model
On top of those, AMQP defines the concept of exchange. An exchange is an intermediary between producers and queues. In this messaging model, producers never write directly to queues. Instead, each message is sent to an exchange which decides in which queue or queues the message should be delivered. Take for example a logging message: different processes may want to listen to only specific severity levels. We can model each of them as a queue. The exchange in this case distributes the messages according to our specific logging policy.
AMQP handles many more communication needs. For example, you can use a message queue as a work queue: in that case many processes may consume messages, but each message should only be consumed once. As a result, consumers must acknowledge that they have handled a message to get it removed from the work queue. The notion of exchange is also greatly generalized: you can have queues with different topics, to which consumers may subscribe. If you are interested on the possibilities, I strongly suggest looking at RabbitMQ tutorials.
AMQP in Haskell
There are several libraries in Hackage for communication using AMQP. The amqp package gives access to the full set of features of the protocol, at the expense of a more complicated interface. On top of this we have amqp-conduit, which exposes the messages queues as streams (the conduit streaming library is discussed in the next chapter). In this section we look at amqp-worker, which exposes a simple functional interface.
The queue function receives two arguments. The second one is the name of the message queue to connect to, which will be created if it does not exist yet. As we have discussed above, each queue is associated with an exchange, so we also need to declare it beforehand by giving it a name. Any client connecting to the same exchange and the same queue will be able to send and receive messages. Something which is only explicit in the type signature is that ordersQueue deals with messages of type Order. In this case our data is expressed using a simple tuple, but amqp-worker can deal also with programmer-defined types.
Overloadedstrings
You may have noticed that we need to enable the OverloadedString extension to compile this code. This is required because the literals "test" and "orders" are not of type String (the default in Haskell) but of type Text (a different representation often used when interoperating with other languages). We discuss the differences between the two and how to convert between them in Chapter 10.
Building on the code we had before, we are still using two TVars to handle the state of the program. The money is represented by the m variable, and the current stock by the s variable. This is a very common pattern in Haskell programs: whenever you need to keep some mutable state, throw a transactional variable to ensure that your program is free from deadlocks and any kind of data race.
There might be some error when dealing with the message. Then the error handler is called, in this case onBackendError. The function is called with the description of the problem so that if can be further inspected, although in the code above we just print it.
If the message arrives successfully, the other handler is called. In the code above is called onBackendMessage. The information, of type Order in this case, is wrapped in a Message type which includes additional information about the delivery. If we are not interested in that extra information, we can just get the inner message as the value field. Note that the actual work of calling pay remains equal to our older version using TQueues.
Note
The extra getLine after calling frontend is required to give some time for amqp-worker to send the message before exiting. If the process ends right after the call to publish, the message may not be correctly delivered.
Scaling this simple example to a real network requires a bit more work in order to configure RabbitMQ correctly. If your communication patterns are simple, the amqp-worker library may cover your needs quite well. The only caveat of this library is that it fixes a simple messaging pattern; if you need something more complex you can switch to the broader amqp.
Summary
The Par monad provides simple parallelism via futures, which are computations started in parallel that you can ask for the result of at some later point.
You saw how monad allows spawning parallel computations around the concept of a dataflow graph, where dependencies are defined via IVars.
Basic concurrency can be achieved in GHC via forkIO for creating new threads and via MVars for sharing information.
In some cases you need to perform longer access to shared resources as an atomic operation. In that case you can use transactions via the stm library.
In addition to simple TVar variables, the stm library provides abstractions over several types of queues. The examples have focused on TQueue, the nonbounded nonclosable one.
Finally, you learned the basics of communication using message queues using the amqp-worker package.