
Chapter 5. Planning
If everything is going to plan, something somewhere is going massively wrong.
—anonymous
This chapter has planning experiments related to large-scale Scrum.
Early days
Try...Kickstart large-scale Scrum with one initial Product Backlog refinement workshop
For a small group, setting up a new Product Backlog is relatively simple work—maybe a day. For a larger product—for example, a ship-control system or medical device—involving 500 people with new hardware and software, one day is not going to do.
In this case, consider holding one and only one relatively long, highly structured, and intensive initial Product Backlog refinement (or creation) workshop when an existing large product group first transitions to Scrum. This takes several days.
This activity is also known as release planning but we call it initial Product Backlog refinement[1] for three vital reasons that distinguish it from conventional release planning, to communicate that...
[1] It is not wrong to call it release planning; this is the name used in the Scrum Guide.
• Initial Product Backlog refinement has the same activities as the ongoing per-iteration Product Backlog refinement.[2]
[2] Also called Product Backlog refactoring or grooming—an evocative phrase to a native-English speaker, but we have learned (working frequently in Asia and Europe) that ‘grooming’ is an unfamiliar word, and so use the familiar ‘refinement.’
• The activity of release planning is never-ending in Scrum—it is part of ongoing Product Backlog refinement each iteration; naming it release planning suggests (strongly) to a traditional group that release planning happens only once for each release.
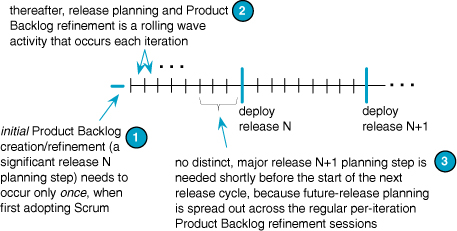
• Initial Product Backlog refinement needs to happen once and only once for the lifetime of the product when the group first adopts Scrum; thereafter, Scrum “release planning” is a rolling wave that happens every iteration.
This last point (and see Figure 5.1) is a significant change because big traditional product groups usually think (1) shortly before the next release cycle, do a major release-planning activity, (2) develop toward the release. This mindset is a variation of “order the meal, then wait for delivery of the meal”—which is associated with the traditional Contract Game, and inconsistent with the cooperative game of invention and communication in agile planning.
Try...Continuous product development rather than projects
This suggestion is emphasized in greater detail in the Organization chapter of the companion book, in Avoid...Projects in product development and other experiments.
‘Projects’ are often assumed as the best or sole way of organizing work; for instance, big product groups assume long projects (or programs) for big releases: (1) major release planning at the start, (2) a long development period, (3) release. But a project-orientation has several drawbacks, including a short-term focus in which long-term improvement and quality is sacrificed.
Projects can be reduced or eliminated in Scrum, replaced with the simpler model of continuous product development (Figure 5.2). See the Organization chapter of the companion book for more detail.
Figure 5.2. move to continuous product development rather than large projects that plan, execute, and release
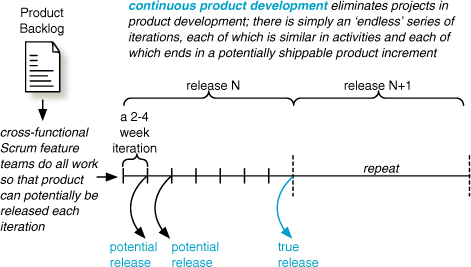
Continuous product development does not mean there is no release goal or no Release Backlog. Those still exist, but a release cycle is not treated as a special distinct project.
There are exceptions to this continuous model; for example, game development tends to be single-project oriented.[3] However, most products (including internal products) are long-lived and go through series of evolving releases; continuous product development—rather than projects—applies in these cases.
[3] There is a subset of core technology (such as a game engine) that may evolve across releases, but much is replaced and new.
Try...Initial Product Backlog refinement workshop
How to do initial Product Backlog refinement/creation? We have facilitated these events over the years, and have suggestions on participants, environment, tools, order, and activities.
Participants—Include the Product Owner Team and all team members, or representatives if too many people; workshops with more than 50 people are unwieldy—even this size is only effective with a skilled large-workshop facilitator.
Workshop facilitator—A facilitator is critical for a multi-day, intensive structured workshop with many people.
Format—Facilitated workshop (with active hands-on activities), not a meeting (where people sit and listen, or give presentations).
Environment—A big room (see the Multisite chapter for variations).
Tools—Lots of simple, tangible tools for creativity: paper, cards, whiteboards, flip charts, and so forth. Digital camera for pictures of tangible things is useful. Use a wiki to store pictures and any detailed text. Include several computer projectors so that a subgroup can easily see the wiki material or other on-line resources—but in general, avoid using computers or projectors.
Order and activities—The overall workshop will contain a series of sub-workshops, each lasting from a few hours to several days. Consider the following sub-workshops (Figure 5.3):
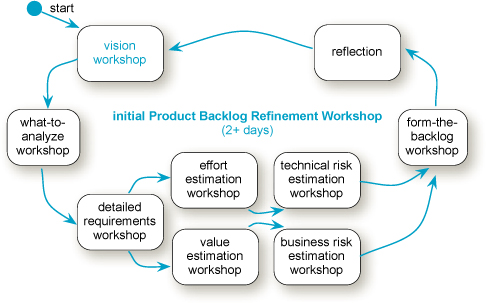

Vision Workshop: Envision business case, strategy, high-level list of features (major scope), and constraints for the release.

What-to-Analyze Workshop: Identify ten or twenty percent of the features (for example, 20 of 200 items) that deserve deep analysis immediately.[4] Choose a subset that will yield broad and deep information about the overall release work. There are always some key features that, if deeply analyzed, give you overarching information about the big picture. These may be the most complex, the most architecturally influential, the highest-priority features, or features with the most obscurity. From the viewpoint of information theory, they represent a subset that, if analyzed, is most likely to have lots of surprising information—the most valuable kind [Reinertsen97].
[4] If development is for a fixed-price fixed-scope project, then this may need to be much larger than 20%. See the Contracts chapter.
Detailed Requirements Workshop: Hold a “deep dive” requirements workshop on the ten or twenty percent identified in the what-to-analyze workshop. This may be a relatively long workshop. It also includes splitting coarse-grained requirements into smaller ones. Myriad analysis techniques are applicable. At the end of this workshop, ten percent (for example) of influential requirements are well-refined—better understood in detail and split into smaller subitems—and ninety percent less refined.
For very large groups, requirement areas are identified during the vision workshop or near the start of this workshop. These areas can be used to concurrently analyze requirements in several sub-groups.
Parallel Effort- and Value-Estimation Workshops: In the Product Backlog, all items have both effort and ‘value’ estimates.
Team members head for one end of the room and initiate effort estimation of items identified in the Vision and Detailed Requirements workshops. Typically done with planning poker (see Figure 5.5). These workshops usually take a half- to full-day for a big release.

In parallel, the Product Owner Team heads for the other end of the room and initiates estimation (perhaps with planning poker) of the ‘value’ for items identified in the Vision and Requirements workshops. See “Try...Value” on p. 139. As explored the Product Management chapter, ‘value’ is not one simple attribute.

Parallel Technical- and Business-Risk Estimation Workshops: Risks can be grouped into those related to the development teams or the Product Owner Team:
• technical risks—uncertainty (of outcomes or events) regarding development, technologies or their performance [Reinertsen97]
– development teams have something to say—about identifying, estimating, and mitigating these
• business risks—uncertainty regarding the business case, strategy, market, economy
– Product Owner Team has something to say
Technical and business risks are inputs into the prioritization of the backlog. Why? Because to either fail fast or mitigate risk, work on items that attack probable and costly risks in early iterations.
Form-the-Backlog Workshop: At this point, the group has several hundred cards with item summaries, each of which has effort estimates, and a set of ‘value’ and risk attributes.

Separate the Release Backlog[5] and future backlog subsets—The first step in forming the Product Backlog is to create two groups on the floor: (1) items for the Release Backlog and (2) items for future releases. How to identify items for the Release Backlog? In short, the choices are influenced by a date-driven or content-driven release goal, and the small-scale agile techniques for either case also apply to larger systems; see Agile Estimating and Planning [Cohn05] and It’s All in How You Slice It [Patton05] for examples, and the “Try...Prioritize with multiple weighted factors” section on page 141.
[5] The Release Backlog is not a separate artifact; it is the part of the Product Backlog for the next release.
Some scaling-specific suggestions for the initial Release Backlog:
• Parallelize the initial Product Backlog creation if there are requirement areas and Area Product Owners. The cards are separated into different areas of the room, by requirement area. Each subgroup works in parallel. The overall Product Owner visits each group, and team members visit other areas.
• Large product groups are especially accustomed to playing the traditional development game with The Content Milestone. Old habits die hard, so we see workshop participants over-process the Release Backlog creation, concerned it must be ‘correct.’ The facilitator needs to emphasize that people can relax—it is just a rough approximation.
Separate the clear-fine and vague-course subsets—Once items have been separated into the Release Backlog and future backlog sets, the next step is to further separate the Release Backlog items (on the floor) into two sub-groups: (1) clearly analyzed fine-grained items that are small enough to be done by one team in much less than one iteration, and (2) the remaining vaguely analyzed coarse-grained items.
Prioritization of the clear-fine subset—The Product Owner can do the fiddly work of prioritizing the Product Backlog after the workshops are finished. Only items in the clear-fine set need prioritization since they are the only candidates for implementation. An exception to delaying the prioritization is if the iteration starts the following day.
Type it in? A single-site product group can experiment with using only visual management (such as cards on the wall) to record the Product Backlog. A multisite group probably needs a spreadsheet, for easy sharing. In that case...many hands make light work: Ask everyone to type in a few cards.
Reflection: End with a short retrospective on the workshop process itself, to learn and improve.
Many of these activities repeat each iteration: A non-trivial initial workshop is needed to kickstart adoption of Scrum with a well-formed Product Backlog. As a big event, that happens only once, but some or all of these activities repeat each iteration in smaller, ongoing refinement workshops.
Iteration (Sprint) planning
Try...Scaling Sprint Planning Part One
We and our clients have experimented with several approaches to scaling Sprint Planning. First, note that there are two distinct steps in Sprint Planning: Part One (SP1) that focuses on what, and...wait for it...Part Two (SP2) that focuses on how.
Related to large-scale Scrum framework-1 and framework-2, a tipping point in the SP1 scaling-approaches happens at around ten teams (for the total group). Ten is not a magic number; it is related to the upper bound of people that can effectively meet together in one common SP1 meeting, and the ability of the Product Owner to focus on the big picture. At some point, the size is unwieldy—although that point is context sensitive. For example, larger groups remain effective with good facilitation, practice, clear requirements, or long-term stable teams.
Suggestions...
Around Ten or Fewer Teams
In this case, do SP1 for the entire product group in one meeting (unless there are time zone constraints involving multisite development). If there are only a few teams, it is possible for the entire group (such as 14 people) to come. Otherwise, send one or two representatives from each team; sending two representatives has the advantage of providing multiple perspectives for each team. As discussed in the Coordination chapter, avoid the ScrumMaster as a team representative—at this and most other meetings.
Start SP1 by viewing the existing baseline product-level Definition of Done, to ensure that this key point is clear.
The Product Owner spreads out wish-list cards that summarize backlog items (and their priority), probably grouped into epics or themes. She invites teams to volunteer for items. A creative period ensues in which the teams make tentative decisions on the items they will take forward to SP2. Each team physically moves and groups cards they will take forward. If there are grouped items, it is normal for one team to take the group (or manageable subset), so that there is increased consistency and cohesion. Furthermore, it normal for one team to take new items related—by epic or theme—to old items they did previously, for the same reasons.
At the end of this period, the floor will have groups of cards for each team, and perhaps leftover cards that no team has chosen.
Offerings directed to individual teams?—To encourage self-organization, experiment with teams deciding among themselves—by interest, negotiation, or skill—which teams will pick up which items. This also reduces decision-making effort by the Product Owner. However, the Product Owner has the final decision on which items are matched with teams, so if there is a problem, she decides the distribution. Also, if a high-priority item is not picked up by any team, or high-priority items are not spread across teams (see next point), then the Product Owner can decide to change the distribution.
Spread high-priority items across teams—Potential problem: Assume two teams. During SP1 Team-1 takes items with priority [1, 2, 3, 4] and Team-2 takes [5, 6, 7, 8]. Later, during SP2 or the iteration, Team-1 descopes item-4. Result? A relatively high-priority item (item-4) has been descoped, even though (perhaps) Team-2 could have done it. Solution? Spread high-priority items across teams; for example, Team-1 takes [1, 3, 5, 6] and Team-2 takes [2, 4, 7, 8]; this is not always appropriate due to relatedness or dependency of items.
This seems too easy—If Scrum feature teams are in place, and the Product Owner and teams are applying Scrum with skill, then even with multiple teams SP1 should be simple, quick, and without many questions. The items being offered should already—before this meeting—be small, clear, estimated. The Product Owner should already know the priority. And a team should be able to independently do an end-to-end item by itself. If SP1 is complicated and filled with questions (or silent confusion), that signals lack of preparation in the previous iteration. If SP1 raises many cross-team coordination problems, that signals lack of true feature teams.
More than around ten teams
This is more-or-less the tipping point where it is useful to introduce requirement areas and Area Product Owners (APOs)—each APO served by a maximum of around ten teams. We have seen this scale to groups of about one thousand people.
Pre-Sprint Planning—Before SP1, in the previous iteration, the APOs and overall PO (if there is one) need to coordinate so that the different Area Backlog priorities reflect product-level themes or other coordination agreements.[6] For instance, if the theme of the next iteration is touch interface, the APOs coordinate so that related items rise in priority in all Area Backlogs.
[6] For example, one APO taking on a common infrastructure goal.
SP1—Area-level Sprint Planning Part One—Simply, in parallel meetings on the first day of the iteration, each APO and their requirement area teams (or team representatives) meet and hold SP1 exactly as described in the previous section.
Multisite Issues
There are several multisite issues, including (1) the participants in SP1 not working at the same site, and (related) (2) no common time.
For a multisite SP1 meeting, one approach is to organize the display and choosing of items with a software tool, such as Google Spreadsheet, combined with video (such as Skype video) or audio conferencing. Caution: If the overall Product Owner or an APO is physically in the room with a subset of teams of one site, there is tendency (due to communication ease) for the APO to favor the local teams in some way—in terms of information, clarification, and so forth. Pay attention to that. We have seen an APO travel to different sites over time for Sprint Planning and Sprint Review—this supports balance and building relationships between the APO and teams.
No common time window—For example, some teams are in New York and in Singapore—about 12 time zones apart. Experiment with the Product Owner deciding which set of items to offer to each site and holding separate SP1 meetings—one of which will be in the evening for the Product Owner.
Try...Simple Sprint Planning Part Two
If the scaling practices for SP1 have been applied and the organization has created feature teams, then SP2 is simple: Each separate team individually doing—more-or-less in parallel—their own individual SP2 meeting.
A variation is asynchronous SP2 meetings so that some people can observe other meetings, when there is a coordination interest.
Try...Asynchronous or joint Product Backlog refinement
If a team wants to coordinate with another, or learn from another:
• Hold Product Backlog refinement workshops at different times.
– a few people from other teams can observe or participate
• Hold a joint workshop.
Try...Plan bounded research or learning items
Large product groups, especially those for embedded-software products, frequently have genuine and complex research work. What new color models can be used in printing? What is IEEE 802.11ad? As discussed in the “Try...Genuine research work as PBIs” section on page 227, genuine research work can and should be identified and planned in Scrum, similarly to regular feature items.
For example, we were once consulting at a site in Budapest; the group wanted to provide “push to talk over cellular.” The international standards document for this is thousands of pages. Just to vaguely grasp the topic is a formidable effort.
One approach is to ask a team to “study the subject.” Yet, that is fuzzy unbounded work, so it leads to more variability and a big batch of analysis—not all of it necessarily useful.
An alternative approach—this suggestion—is to plan an effort-bounded goal to learn within the iteration. For example, maximum 30 person-hours on “push to talk” in the next iteration. This item and its limit is clear in SP1; the team knows how much this otherwise unbounded work will impact their SP2 planning, and the Product Owner is making a bounded investment in this research.
Suggestions:
• This research item should not consume all the time of the team for the iteration; balance it with development work.
• Focus research work on useful output for the Product Owner, especially identifying new Product Backlog items (PBIs); limit study; quickly prototype and implement.
• Focus research work on tangible output for the Product Owner, such as a research report presented at Sprint Review—ranging from an oral presentation to wiki pages. Include advice to the Product Owner on how much to invest in future research.
• Avoid giving research items to special ‘research’ teams; research is done by normal Scrum teams, not separate groups.
– this reduces the waste of handoff, and increases learning by the teams doing the real development work
To repeat an example from the Requirements chapter: Rather than studying in depth a 500-page document of the next PDF specification,[7] people can
[7] Printer-product companies write software to interpret PDF.
- skim over the document and identify large sections that can be studied in detail later[8]
- study only a smaller subset in detail
- create new customer-centric PBIs; prototype; ...
- start implementation
After the iteration, the Product Owner knows more and can decide to invest more bounded effort in another cycle of research, and can perhaps start implementation of some concrete PBIs to incrementally build up the functionality.
Try...Plan infrastructure items by regular teams
This is a variation of the “Try...Add and do a cross-product common goal” section on page 128 in the Product Management chapter. Review that section for issues that apply to this case; consequently, this section is terser than it would be otherwise.
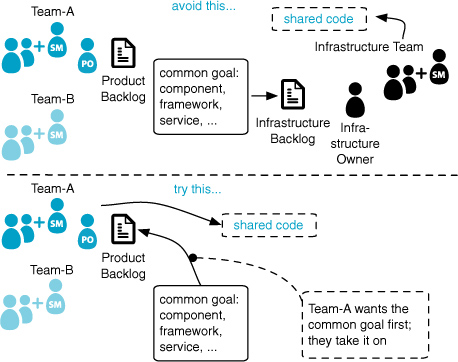
When we start coaching a big group, we often find the Infrastructure Team (a smaller variation of a Platform group that serves multiple products). The conventional idea is to collect requests[9] for shared components or services from across several teams in the product group, which are then implemented by the Infrastructure Team “for efficiency.” And sometimes there is an Infrastructure Backlog, separate from the Product Backlog, perhaps even with an Infrastructure Owner.
[9] Often called “technical requirements”—which are in fact not requirements, but design solutions.
In contrast, this suggestion is to put shared goals for common infrastructure on the Product Backlog, done by regular Scrum feature teams, temporarily playing an infrastructure role (Figure 5.7). The motivation is analyzed in the related Product Management chapter and the Feature Teams chapter of the companion book.
Try...Avoid... Fixing defects
One of our clients builds ship-control systems; they have a category of defect called ‘sinking.’ Those don’t wait. How to plan for these surprises? One approach is for teams to include some bug slack in their Sprint Planning; in the best case they can use the slack time towards new-feature work rather than for ‘predictable’ surprises.
Another approach: Large, old systems invariably have a long list of known defects. How to plan? Some of our clients have <N> feature teams move into the role of bug teams for one or two iterations. All defects are handled by these teams, even if they are not the fastest experts—and in this way the teams learn. Component guardians may also be involved in helping or review. Team members only interrupt an über-expert (in this example, not currently in the bug teams) if the problem is extremely time- or expertise sensitive. Bug teams eventually move back to the role of regular feature teams, and fresh feature teams become bug teams. During the transition back to feature team, people carry work-in-progress defects into their ‘feature’ iteration, wrapping them up before starting their first feature.
Avoid—As a perfection challenge, there should not be any defects, and so planning for them should not be necessary. Although this is tough in the old systems we work with, we encourage agile coaches to help create the culture and engineering practices for zero tolerance on open defects.
Also: See “Avoid...Using defect tracking systems during the iteration” on p. 39.
Done
Try...Product-level Definition of Done
Definition of Done
“We are done!” said the team. But what does that mean?
The Definition of Done (DoD) is an agreement between the Product Owner and teams about what ‘done’ means. When team states ‘done,’ what will that mean? Does it mean that all testing has been done? How about the customer documentation?
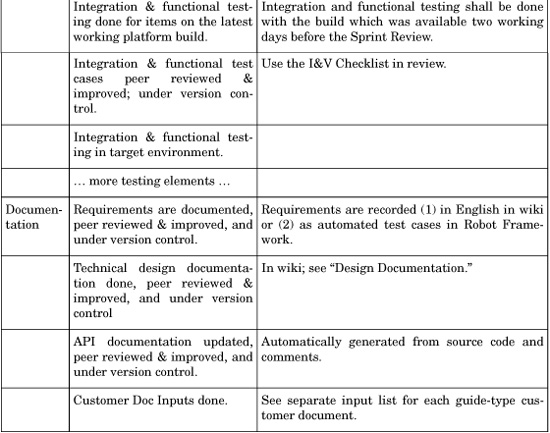
The perfection-challenge output of an iteration in Scrum is called a Potentially Shippable Product Increment [Schwaber04], that is “[done] in the sense that it could be sent out to the marketplace” [Schwaber06]. But for a product—the kind we commonly work with—that has a background of five-year release cycles, 100 component teams spread across 13 sites worldwide, and many single-function departments...that is an unimaginable step.
Therefore, a big group defines their DoD as their current technical and organizational ability—typically starting below the perfection challenge. What are they capable of doing each iteration when starting Scrum? For any group, this includes at least programming and some kind of testing. Over time, as the group improves, their DoD expands until it is equal to truly potentially shippable.
Do not confuse the DoD with criteria of satisfaction or acceptance criteria. The first are valid for all items in the Product Backlog, whereas the latter are item-specific criteria that evolve in acceptance tests, probably during a requirement workshop with A-TDD.
Here is an example (imperfect) DoD from one of our clients building a large product:
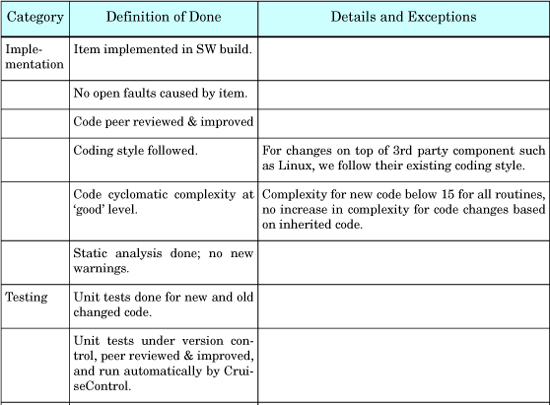
Product-level baseline
For meaningful tracking of overall progress, there needs to be a common product baseline DoD that all teams conform to. Our clients usually record this common definition in a wiki page.
In some cases, there is also an intermediate requirement area baseline that extends the product baseline.
When to first define it? In a special workshop that must include involvement by the hands-on teams. If there is contention about the original definition, the Product Owner has the final say.
When to evolve it? During Joint Retrospectives.
Why bother? Without a product-level definition, there is
• reduced visibility into the state of the overall product—it is not possible to track meaningful system-level progress
• less focus on the overall system—there is less discussion and attention to the state of whole product
• increased variability—different features can and will have different degrees of Undone Work
• reduced ability to deliver a potentially shippable product increment each iteration—some features can and will have more Undone Work than others
Avoid...Definition of Done defined by quality group
We coached a group in India that included a quality manager who wrote checklists and wanted teams to follow those. His focus was on centralized defined processes and top-down conformance. When this group started to adopt Scrum, he injected his checklists and centralized conformance into Scrum by defining the DoD. Avoid that—the DoD is an agreement between the Product Owner and teams. It is not an agreement with a quality group.
Avoid...Undone Work
When the DoD does not yet include all the work needed to ship the product to the customer—common in big groups first adopting Scrum—then work is left before the product can ship. This is the Undone Work,[10] and it increases each iteration.
[10] Not to be confused with unfinished work from the iteration. The Undone Work exists by intention or plan.
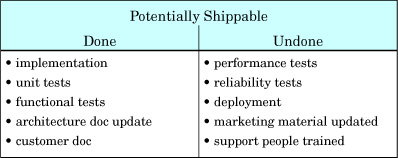
For instance, if the group cannot (yet) do performance testing each iteration (perhaps it is not automated and is outsourced to Vietnam), then this is Undone Work and the amount of performance testing increases over time, building up (implicitly) as a big batch of work in a queue to be done before release (Figure 5.8).
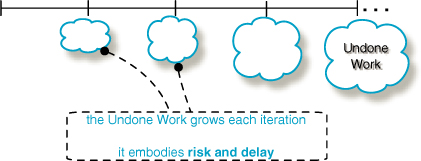
Risk and delay—Since the Undone Work has to be done before shipping, it represents delay for the Product Owner—and therefore also responsiveness. Undone Work also represents risks—performance testing being an excellent example. When it is delayed until near the end of the release and the group discovers performance problems late in the game...bleh!
Also: See “Avoid...Try...Separate “Undone Work” from the Product Backlog” on p. 226.
Hardening—When we first visit a client new to lean or agile development, a word we frequently hear is...hardening. Such as, “We are planning to do three iterations, and then do a hardening iteration.” ‘Hardening’—an aspect of Undone Work—is so common that some do not see it for what it is: a failure, not a solution. In lean thinking, defects and then all that follows (test and fix at the end of a cycle) is considered waste. The lean perfection challenge is to build quality in—through changing the system to address the root cause problems—so that hardening and similar superficial quick fix reactions are no longer needed.
But, sometimes there still is Undone Work. Then, how to do it?
Try...Include Scrum teams in a Release Sprint
In small-scale Scrum, the standard solution to do the Undone Work is to hold a Release Sprint in which the regular Scrum team does all this work—they do not work on new features—and then releases the product (Figure 5.9). Good idea[11]—especially because it educates the team through painful experience about this Undone Work. Since they are “eating their own dog food,” the team is increasingly likely to think of ways to reduce it in the future—to improve the DoD and reduce the Undone Work.
[11] The need for a Release Sprint is not good. Rather, if needed, including the teams is good.
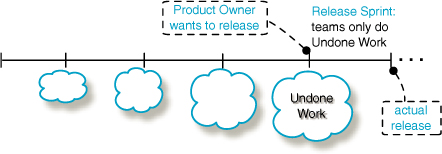
As a rule, big groups moving from sequential development have a dedicated “Undone Unit”—the group that handles all the Undone Work such as documentation for field engineers, acquisition of part numbers, system testing, fulfillment of legal or government regulations, and so forth. When there already exists a big institutionalized Undone Unit that has done this end-of-release work before, it is mighty tempting to fall back on old habits and simply, once again, hand over the Undone Work to them. And we have seen ‘Undone’ management groups with a stake in keeping the Undone Unit alive—they press the Product Owner (or someone) to give them all the Undone Work.
Resist that temptation.
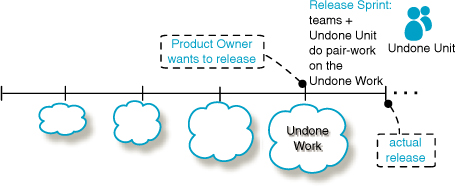
Rather, (1) hold one Release Sprint with some or all of the regular Scrum feature teams. For exactly the same reasons as above—learning through eating their own dog food. Also, (2) mix Scrum team members with the Undone-Unit experts, to reduce handoff problems and improve two-way learning (Figure 5.10). Examples:
• One of our clients is a bank. They have a production operations group that, before adopting Scrum, received a candidate release and tested it in a sandbox. After adopting Scrum, regular Scrum team members physically join with (pair-work with) product operation people during a Release Sprint to do this testing in a sandbox.
– This is a temporary phase. The longer-term change is for the production operations group to diminish, and some members join regular development Scrum teams. Then, regular Scrum teams will have development knowledge to help with operations.
• One of our clients builds ship-control systems. They have a ship-installation group that installs a control system (wires, hardware, software, ...) in a ship. They are exploring including regular software-development team members on the ship during installation, to help. (This change is complicated by safety and insurance issues).
This is a good step, but there is a mountain of Undone Work in large embedded-software products new to Scrum. One Release Sprint may not be sufficient to level it and to release. Therefore...
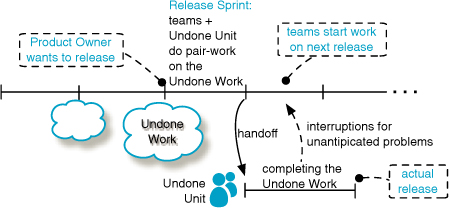
Try...After one Release Sprint, hand off remaining Undone Work to the Undone Unit
After one Release Sprint with the teams and Undone Unit working together, if Undone Work remains, then experiment with the Undone Unit taking over the remaining pile. Fortunately, since the teams and Undone Unit have done pair-work in the Release Sprint, the handoff waste will be lower than otherwise. For example, in the prior ship-control system example, after a few weeks, most Scrum team members leave the ship and the expert installation crews remain behind.
Bring teams back to the rhythm of working on new features—at this point, for the next release cycle (Figure 5.11).
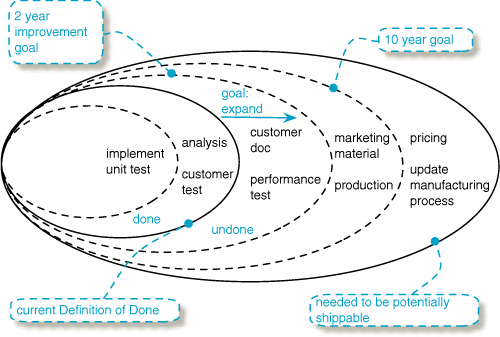
Try...Expand the Definition of Done
Never lose sight of the perfection challenge: to have the potential to release, completely done, at the end of any iteration. That capability extends beyond just the R&D department—it includes product management, marketing, delivery, field support, and more.
Over time, (1) expand the DoD (Figure 5.12), which implies (2) shifting Undone Unit experts into regular Scrum teams so that the regular teams can truly wrap up by themselves in one Release Sprint; this implies an increase in multi-skilling. It also implies the end or a diminished role for a smaller Undone Unit.
In general these are the ways of expanding the DoD:
• automate—for example, performance testing is automated
• expand team cross-functionality—for example, a person with technical-writing skills joins the team
In big complex products, this is a long-term journey; see the “Try...Lower the waters in the lake” section on page 407 for a sense of perspective in this continuous improvement.
Try...Expand team-level Definition of Done
No team should be unable to conform to the product-level baseline DoD, but each is encouraged to expand beyond it, according to their capabilities. This is discussed in team-level Sprint Retrospectives and agreed to with the Product Owner in Sprint Planning.
Try...Avoid...Early and incremental handoff of Undone Work
The previous tips on Release Sprints posit a false dichotomy: the only two choices for the Undone Work are (1) do it during a Release Sprint, or (2) get rid of it by expanding the Definition of Done. But there are gradual-improvement alternatives...
Try—Hand off (to the Undone Unit), early and incrementally,[12] Undone Work that the teams cannot yet do themselves (customer documentation) or that takes too long to complete within one iteration (long-running manual stability testing). As another example, internationalization of user-interface text may be handed off early and incrementally. This reduces the wastes of delay and work-in-progress (WIP), and confronts some risks earlier.
[12] Incrementally every three iterations, for example. If, on the other hand, it was possible to hand it off each iteration, it would be time to stop handing it off and, instead, extend the Definition of Done.
Avoid—But on the other hand, this still engenders the wastes of handoff, delay, and WIP. And once there is a ‘successful’[13] handoff in place (especially once it can be done every iteration), that suggests it should soon after be possible to expand the Definition of Done and remove the handoff.
[13] A ‘successful’ early-and-incremental handoff process does not imply improvement is finished, or the process should remain.
This approach to gradual improvement is used by several of our clients in big embedded-software products, with mountains of difficult-to-remove Undone Work.
Avoid...Try...Planning an ‘agile’ release train
An “agile release train” [Leffingwell07] is an incremental release planning, integration, and system-test (‘hardening’) strategy for managing dependencies between teams—the type created by having component teams. In a release train, there are predefined periodic (such as every four iterations) internal release dates for system-level integration and testing during an ‘hardening’ iteration. The hardening iteration is a mechanism to work on the growing queue of WIP and Undone Work. The internal release dates are inviolate, but component teams have flexibility to decide their functionality and whether to “join the train” or not. And if not, they provide a simple “plan B” component version (such as an old version) to not break the new integration build.
Avoid—Release trains partially solve problems that can be solved more powerfully and fundamentally with other methods, such as adopting feature teams, doing real continuous integration with test automation, and preventing Undone Work by expanding the Definition of Done. Release trains add additional planning, coordination, and management overhead—a “release train management team.” System integration and testing is not delayed until the final end, but...there is still some delay in integration and testing, and Undone Work. By retaining component teams—that create dependency and integration problems—system-level delivery of value is still slow, and there are more queues, WIP, handoff, and multitasking. Related to the prior experiment, “Try...Avoid...Early and incremental handoff of Undone Work” section on page 179, a release train could involve some handoff to an Undone Unit, such as a separate system-level testing group.
Try—If, for some reason, the group is unable to adopt feature teams with continuous integration, then a release train approach is at least better than a classic sequential life cycle.
Estimation
Try...Estimate with Story Points
In Agile Estimating and Planning, Mike Cohn makes a good argument in favor of using story points (relative effort points) for estimation. We do not repeat the motivation, but note that this advice is even more compelling in development with many teams. Why? In this case, other—more detailed—estimation techniques (such as work-breakdown person-day estimates) are extraordinarily slow and laborious. Thus, there is disinclination to refresh the estimates—even though updated estimates are useful in planning, and are part of Product Backlog refinement each iteration.
But story points, especially when combined with techniques such as planning poker, are relatively quick and easy to refresh. Especially in large-scale development, that translates to an increased chance that re-estimation will occur each iteration.
Problem: Story points are relative—‘5’ has no absolute independent meaning. Two teams can define ‘5’ differently, which makes it difficult to estimate overall effort or track overall progress. Therefore...
Try...Avoid...Synchronize points and range
If the product group makes a common agreement on the size of story points[14]—so that a ‘5’ is the same for all teams—there are benefits:
[14] A common agreement also fosters overall product-level perspective among the teams, rather than isolated-team mindset.
• a common Release Burndown chart—better view of progress
• a product-level velocity—better prediction of future progress
• a team’s estimate of items that can be done by other teams
• the time together to create a common agreement that builds more shared understanding and cross-team relationships
How to define a common point, and a common range of points? One approach is...
Cross-team Estimation Workshops for Canonical Set—All members—or team representatives—of all teams join in a common estimation workshop and identify items for which they have common understanding. Then they estimate these, using planning poker with story points. This canonical set of items is a baseline of shared understanding and is used as the baseline of future estimation workshops, including those done separately by individual teams or larger sub-groups. This cross-team estimation workshop occurs not only before the first iteration, but repeatedly in subsequent ones to resynchronize.
There are at least two ways that the group can have common understanding of the meaning or effort in a canonical set:
• Historical set of completed items is reviewed. Likely the best choice, since the items were done and so have the clearest information.
– this gives common understanding of effort but not necessarily of meaning
• New items are first analyzed together by the estimators in a previous requirements workshop.
Issues—Synchronizing points across teams works relatively well, but requires occasionally repeating cross-team estimation workshops,[15] since they drift out of synchronization. Synchronizing also brings with it a few potential dangers:
[15] These workshops need not be cast as a problem; positively, they foster common understanding and product-level perspective.
• comparing—we have seen management groups start to compare the relative ‘performance’ of teams that use a common synchronization, even though such comparisons are in reality meaningless—and worse, harmful.
• converting—one merit to story points is that they have no absolute or independent meaning. They cannot be realistically converted into person-days, for example—and the attempt to do so by management (or others) indicates that the purpose of their use in velocity has not been understood. We have seen teams attempt to synchronize by stating, “one point means two person-days.” This is a slippery slope to a deep misunderstanding of story points and velocity.
We recommending trying cross-team synchronization on points with a canonical set. But if these dangers are manifest, there is an alternative: Each team uses its own idiosyncratic definition of points. However, this leads to problems in estimating overall effort and tracking overall progress across all teams. One partial solution is...
Try...Combine progress measures
If different teams (or larger requirement areas) use different point systems, then each has its own Release Burndown chart, and there is no common product-level Release Burndown chart and no common velocity. How to estimate progress? Some alternatives:
• The simplest approach we have used is to hang the separate Release Burndown charts on a wall, stacked directly underneath each other, and ‘eyeball’ the overall scene.
• Estimate the percentage of progress, based on points, of each group. For example, if team-1 has 100 points in their Release Backlog and have finished 20, they are “20% complete.”[16] Over all product progress can be defined with different combination methods: worst case, mean, or median, depending on context.[17]
[16] This is actually a fiction, because of variability and because it assumes the Release Backlog cannot be descoped.
[17] As an example of context and combination method: If team-1 does COBOL features in Beijing and team-2 does Java features in São Paolo and they refuse to talk to each other (and cannot, anyway)...perhaps worst-case is the combination method. This is an extreme example; in very big groups, mean suffices.
Try...Avoid...Estimate velocity before iteration-1
Real velocity is not estimated, it is measured—it is the total of all story point estimates of the work completed in the last iteration, a historical measure.[18] Yet, sometimes a group wants to estimate it before iteration-1—before it can be measured—to help predict total release duration. For instance, the group may want to estimate release cost, and use duration as one factor. Agile Estimating and Planning [Cohn05] offers techniques for its estimation in the small-scale case.
[18] Velocity is a kind of budgeted cost of work performed (BCWP) in earned value management [FK06]; as a name, ‘BCWP’ emphasizes that it is a historical measure, not an estimate.
For the multiteam case, one approach we have used is for all teams to hold a pretend (planned but not executed) Sprint Planning Part One and Part Two meeting, and assume that the items chosen for implementation were done—or that 75% (for example) were done. The total story points of all these items, across all teams, is the estimate of product-level velocity.
Avoid—If the next release of a product is going to be done anyway, rather than spending a week before iteration-1 estimating the velocity, just immediately do iteration-1, and measure real velocity.
Try...Adjust duration estimate with Monte Carlo simulation
In a tiny release with one team and four months estimated duration, plenty can go wrong to invalidate the estimate. This variability is magnified in the large scale. For some product groups we work with, that is not a problem—vague confidence in a fuzzy duration estimate is sufficient. In others—especially fixed-price, fixed-scope, fixed-duration outsourced work—it is vital to do the best one can to estimate duration.
Once when we were coaching in Bangalore, a lead developer’s father died, and he had to leave for several weeks. Once in Budapest, a lead developer’s girlfriend left him, and he was pretty useless on the team for a while—until he found a new girlfriend! These are examples of risks and sources of variability. And there are others: scope change, productivity, attrition, snowstorms, and more.
How do scientists and other estimators model stochastic (probabilistic) systems, such as development work? A standard solution is Monte Carlo simulation (MCS). With an MCS model for release duration, you can include the impact of many elements of variability or risk, including scope change, attrition—and girlfriends. MCS is especially useful in very large and long-duration development and in offshore, outsourced, fixed-price, fixed-duration projects.
And MCS fits well in the context of agile estimating because it is a simple, lightweight, fast technique to apply and adjust.
A classic book on product development risk management and MCS is Waltzing with Bears [DL03]; this explains the method of MCS for estimating a more realistic duration. The authors, DeMarco and Lister, also provide a free Excel spreadsheet called Riskology that implements an MCS model. Find Riskology on the web and try it, to improve the realism of your estimates.
Conclusion
Planning large-scale agile development is simpler than traditional approaches—or at least should be. We notice that this simplicity is disconcerting for some, because the traditional paradigm of management is that big complex work needs big complex planning and control by project managers. But there is a different way: the emergence of order from self-organizing Scrum feature teams. Top-down planning and control is not particularly effective in systems with variability and discovery—because the plans assume something relatively static or deterministic—and the approach grows even less effective as these non-linear systems grow larger.[19] Complex systems on the boundary of chaos and order (chaordic systems [Hock99])—and that includes big development groups—cannot be truly planned or controlled from above.
[19] This was explored in Queueing Theory in the companion book.
No false dichotomy regarding “no planning” versus “top-down planning”...In Scrum, the group does start by creating a Release Backlog for a future goal, identifying and estimating the product features. But after that starting point, agile planning emphasizes continual learning and adapting.
How to do that within a large chaordic system? By (1) encouraging self-organization and bottom-up emergence of order, (2) increasing transparency and feedback, and (3) making it easy to frequently inspect and adapt. This is precisely what agile approaches such as Scrum offer. Consequently—in contrast to those that assumed agile development was for small groups—agile planning is especially useful for the large scale.
Recommended Readings
• For envisioning and vision workshops, two books already recommended in the Product Management chapter are relevant: Innovation Games and Agile Product Management with Scrum.
• For planning with small or large groups, Agile Estimating and Planning by Mike Cohn is an excellent, practical resource.
• Waltzing with Bears by DeMarco and Lister is informative and entertaining; it emphasizes iterative—rather than sequential—development as a key risk-management practice, and explains how to apply Monte Carlo simulation in estimation.