
Appendix A. HTTP Primer
To better understand how web APIs work, it is important to start with an understanding of HTTP, the language of the web. While the HTTP protocol can be hidden behind various libraries and frameworks, understanding the protocol provides a foundation for troubleshooting API integrations and improved API design.
This primer offers an introduction to the HTTP protocol, the elements that are involved in using HTTP for interacting with web APIs, and some advanced features that help to shape more powerful API clients and servers.
Overview of HTTP
The HTTP protocol is a client-server protocol. An HTTP client sends a request to a server. The HTTP server then determines if it can service the request with the information given. The server will then return a response that includes a code indicating success or failure, along with a response payload containing the information requested or details about the error. This request/response flow is illustrated in Figure 17A.1.

Figure 17A.1 An overview of the HTTP protocol.
HTTP is comprised of several elements:
■ The Uniform Resource Locator (URL) where the request is sent
■ The HTTP method that informs the server how the client wishes to interact with the resource
■ The request and response headers and body
■ A response code that indicates whether the request was successfully processed or whether an error was encountered
The Uniform Resource Locator (URL)
HTTP uses a uniform resource locator (URL) as a unique address where data or services are located. Requests are sent to the URL, where the server processes the request and sends a response back to the client. The URL is commonly seen in the location bar within a browser. Examples include:
■ https://launchany.com/effective-api-programs/
■ https://deckofcardsapi.com/api/deck/new/shuffle
A URL is comprised of the following items:
■ Protocol: The protocol used to connect, e.g. http (unsecure) or https (secure)
■ Hostname: The server to contact, e.g. api.example.com
■ Port number: A number ranging from 0 to 65535 that identifies the process on the server where the request is to go, e.g., 443 for https or 80 for http
■ Path: The path to the resource being requested, e.g., /projects. The default path is /, which indicates the homepage)
■ Query string: Contains data to be passed to the server. Starts with a question mark and contains name=value pairs, using an ampersand as a separator between them (e.g., ?page=1&per_page=10)
Figure 17A.2 demonstrates the elements of a URL.

Figure 17A.2 The elements of a Uniform Resource Locator (URL).
HTTP Request
An HTTP request is composed of several parts: the HTTP method, the path, the header, and the message body.
The HTTP method informs the server what kind of interaction the client would like to request. Common HTTP methods are GET, to request data, and POST to submit data. The methods commonly used for web-based APIs are detailed later in this appendix.
The path is the portion of the URL that references a resource on the server. The resource may be a static file, such as an image, or a piece of code that performs dynamic request processing.
The header tells the server about the client and specifics about the request. The header is comprised of header fields in name:value format. Common HTTP request headers used with web-based APIs include:
■ Accept: informs the server what content types the client is able to support. Examples may include image/gif and image/jpeg. If the client is willing to accept any kind of response, */* is used. This header is often used with content negotiation, detailed later
■ Content-Type: informs the server the content type of the request message body. Used when submitting data using a HTTP method that requires a message body, e.g., POST
■ User-Agent: provides a free-form string indicating the kind of HTTP client that is making the request. This may indicate a specific browser type and version or may be customized to indicate a specific helper library or command-line tool
■ Accept-Encoding: informs the server what, if any, compression support the client is able to process. This allows the server to compress the response using gzip or compress formats to reduce the byte size of the response
The message body provides details to the server when data is being submitted and may be human-readable or binary as required by the server. For a retrieval request using GET, the message body may be empty.
Figure 17A.3 shows an example of an HTTP request sent to Google to request the homepage that contains the search form, documented line-by-line.

Figure 17A.3 A line-by-line examination of an HTTP request to https://www.google.com
HTTP Response
Once the request is received by the server, the server processes the request and sends a response. The response is composed of the following parts: the response code, the response header, and the response body.
The response code is a number that corresponds to a success or error code indicating if the request could be fulfilled. The response code sent must be one of the those outlined in the HTTP specification and are detailed later. Only one response code is allowed per response.
The response header tells the client specifics about the result of the request. The header is comprised of header fields in name:value format. Common HTTP response headers used with web-based APIs include:
■ Date: the date of the response
■ Content-Location: the fully qualified URL of the response. Useful if the request resulted in redirects that may require the client to update its URL for the resource
■ Content-Length: the length, in bytes, of the response message body
■ Content-Type: informs the client of the content type of the message body
■ Server: a string that provides details about the vendor and version of the server that processed the request, e.g., nginx/1.2.3. The server may choose to provide little or no detail to avoid exposing details that might indicate a possible vulnerability exists
The response message body provides the content back to the client. It may be an HTML page, an image, or data in XML, JSON, or another format as indicated by the Content-Type response header.
Figure 17A.4 shows an example of a HTTP response sent back from Google based on our earlier request for the homepage.

Figure 17A.4 A line-by-line examination of an HTTP response to a request sent to https://www.google.com
It is important to note that the response in Figure 17A.4 only includes the HTML in the response and not additional images, stylesheets, JavaScript, etc. The HTTP client is responsible for parsing the HTML, identifying the tags that reference these additional assets, and sending subsequent HTTP requests for each one. For a web page with 20 images, 21 separate HTTP requests are required to gather all of the files necessary to render the web page – 1 request for the HTML page, along with the 20 requests necessary to retrieve each image.
Common HTTP Methods
HTTP methods inform the server what kind of operation or interaction that the client would like to perform. Common interactions include retrieving a resource, creating a new resource, performing a calculation, and deleting a resource.
The following HTTP methods are commonly encountered when using web-based APIs:
■ GET: retrieve a resource from the server – response may be cached
■ HEAD: requests only the response headers but not the actual response body
■ POST: submit data to the server, often for storage or for calculations – response not cacheable
■ PUT: submit data to the server, often as a replacement of existing data – response not cacheable
■ PATCH: submits data to the server, often as a partial update of existing data – response not cacheable
■ DELETE: delete an existing resource on the server - response not cacheable
HTTP methods have additional semantics that are important for clients to take into consideration: safety and idempotence.
Safety indicates that the HTTP method used will not generate side-effects, such as altering data. This is common for GET and HEAD methods as they are intended for resource retrieval and do not alter data. APIs that implement data altering operations using safe HTTP methods risk generating unpredictable results, especially when middleware servers, such as caching servers, are involved.
Idempotent methods ensure that the same side effects are produced when identical requests are submitted. This is true for GET and HEAD retrieval methods since no data is altered. PUT and DELETE are guaranteed by the HTTP specification to be idempotent as PUT replaces the resource with a completely new representation and DELETE removes the resource from the server.
POST is not guaranteed to be idempotent as they may create new resources on each subsequent request or alter data in some way that is not guaranteed to produce the same results, e.g., incrementing a value. Likeway, PATCH is not idempotent as only a subset of fields, rather than the entire representation, are altered.
Figure 17A.5 summarizes the semantics of the common HTTP methods used for web-based APIs.
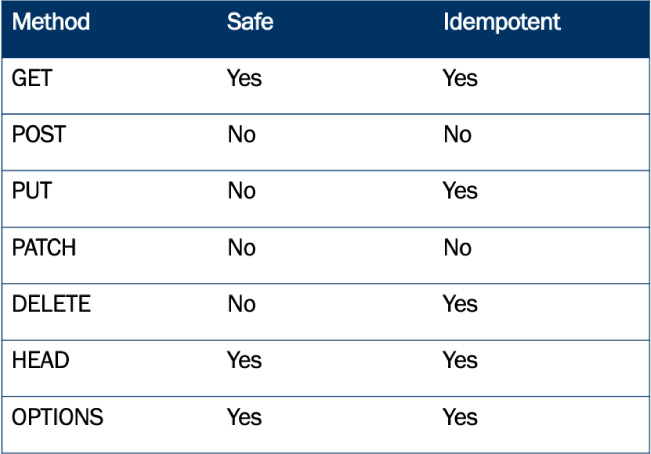
Figure 17A.5 Common HTTP methods used with APIs, including safety and idempotency traits that help to guide the client on how to recover from errors.
HTTP Response Codes
HTTP responses include a response code that indicates to the API consumer if the request succeeded or failed. HTTP provides a series of response codes that the API server can send back to the client to indicate the result.
HTTP response status codes belong to three primary response code families:
■ 200 codes indicate that the request was processed successfully
■ 300 codes indicate that the client may need to take additional action(s) to complete the request, such as follow a redirect
■ 400 codes indicate a failure in the request that the client may wish to fix and re-submit
■ 500 codes indicate a failure on the server that is not the fault of the client. The client may attempt a retry at a future time, if appropriate
Table 17A.1 offers a list of the common response codes from the HTTP specification that are used by REST-based APIs.
Table 17A.1 Common HTTP response codes used in API design

Content Negotiation
Content negotiation allows clients to request one or more preferred media type(s) for the server. With content negotiation, a single operation may support different resource representations, including CSV, PDF, PNG, JPG, SVG, etc.
The client requests the preferred media type using the Accept header. The example below demonstrates an API client requesting a JSON-based response:
GET https://api.example.com/projects HTTP/1.1 Accept: application/json
More than one supported media type may be included in the header as shown in the example below:
GET https://api.example.com/projects HTTP/1.1 Accept: application/json,application/xml
The asterisk may be used as a wildcard when selecting media types. A text/* indicates that any subtype of the text media type is acceptable. Specifying a value of */* indicates that the client will accept any media type in the response. This is a common scenario for browsers, which will prompt the user whether to save the file or launch a chosen application when encountering an unknown media type. However, for clients working with an API, it is important to be explicit to avoid runtime errors that could occur when encountering an unknown or unsupported content type.
Requests may specify preference for specific media types supported within the Accept header through the use of quality factors. Quality factors are expressed as a qvalue between 0 and 1 that helps to assign a preferred order of media types. The API server will review the header values and return te response using the content type that matches both what the server supports and what the client requested. If the server cannot respond with an accepted content type, it will return a 415 Unsupported Media Type response code.
Below is an example of using qvalues to specify a preference for XML, with JSON also supported if XML is unavailable:
GET https://api.example.com/projects HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0
The use of qvalues allows API client code to support a specific type, perhaps XML for improved transformation capabilities and JSON as a fallback.
Since API clients may specify more than one media type, they must pay special attention to the Content-Type response header to determine which parser is appropriate. The following is a response that provides XML based on the previous example request:
HTTP/1.1 200 OK Date: Tue, 16 June 2015 06:57:43 GMT Content-Type: application/xml <project>...</project>
Content negotiation extends the media type support of an API beyond a single type, such as JSON or XML. It allows some or all operations of an API to respond with the content type that best meets the needs of the API client.
Likewise, language negotiation allows APIs to support multiple languages in a response. The approach is similar as content negotiation using the Accept-Language request header and Content-Language response header.
Cache Control
The fastest network request is the one that doesn’t need to be made. A cache is a local store of data to prevent re-retrieval of the data in the future, thereby optimizing network communications. Developers familiar with the term have likely used server-side caching use tools such as memcached to keep data in memory and reduce the need to fetch unchanged data from a database to improve application performance.
HTTP cache control allows for cacheable responses to be stored locally by API clients or intermediary cache servers. This moves the cache closer to the API client and reduces or removes the need to traverse the network all to the way to the backend API server. Users experience better performance and reduced network dependence.
HTTP makes available several caching options through the Cache-Control response header. This header declares whether the response is cacheable and, if so, for how long it should be cached.
Below is an example response from an API operation that returns a list of projects:
HTTP/1.1 200 OK Date: Tue, 22 December 2020 06:57:43 GMT Content-Type: application/xml Cache-Control: max-age=240 <project>...</project>
In this example, the max age indicates that the data may be cached for up to 240 seconds (4 minutes) before the client should consider the data stale.
APIs may also explicitly mark a response as not cacheable, requiring a new request each time the response is required:
HTTP/1.1 200 OK Date: Tue, 22 December 2020 06:57:43 GMT Content-Type: application/xml Cache-Control: no-cache <project>...</project>
Applying thoughtful use of the cache control header to APIs will reduce network traffic and speed up web and mobile applications. It also is the building block for conditional requests.
Conditional Requests
Conditional requests are a lesser known but powerful capability offered by HTTP. Conditional requests allow clients to request an updated resource representation only if something has changed. Clients that send a conditional request will either receive a 304 Not Modified if the content has not changed, or 200 OK along with the changed content.
There are two precondition types for informing the server about the client’s local cached copy for comparison: time-based and entity tag-based.
Time-based preconditions require that the client store the Last-Modified response header for later requests. The If-Modified-Since request header is then be used to specify the last modified timestamp that the server will use to compare against the last known modified timestamp to determine if the resource has changed.
Below is an example of a client/server interaction that uses the last modified date in a subsequent request to determine if the resource has changed on the server:
GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 HTTP/1.1 200 OK Date: Tue, 22 December 2020 06:57:43 GMT Content-Type: application/xml Cache-Control: max-age=240 Location: /projects/12345 Last-Modified: Tue, 22 December 2020 05:29:03 GMT <project>...</project> GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 If-Modified-Since: Tue, 22 December 2020 05:29:03 GMT HTTP/1.1 304 Not Modified Date: Tue, 22 December 2020 07:03:43 GMT GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 If-Modified-Since: Tue, 22 December 2020 07:33:03 GMT Date: Tue, 22 December 2020 07:33:04 GMT Content-Type: application/xml Cache-Control: max-age=240 Location: /projects/12345 Last-Modified: Tue, 22 December 2020 07:12:01 GMT <project>...</project>
The entity tag, or “eTag”, is an opaque value that represents the current resource state. The client may store the eTag after a GET, POST, or PUT request, using the value to check for changes via a HEAD or GET request.
An eTag is either a hashed value of the entire response. Alternatively, servers may provide a weak eTag, which is semantically equivalent but perhaps not an exact byte-for-byte equivalency.
Below is an interactive client/server interaction but using eTags rather than the last modified date:
GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 HTTP/1.1 200 OK Date: Tue, 22 December 2020 06:57:43 GMT Content-Type: application/xml Cache-Control: max-age=240 Location: /projects/12345 ETag: "17f0fff99ed5aae4edffdd6496d7131f" <project>...</project> GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 If-None-Match: "17f0fff99ed5aae4edffdd6496d7131f" HTTP/1.1 304 Not Modified Date: Tue, 22 December 2020 07:03:43 GMT GET /projects/12345 HTTP/1.1 Accept: application/json;q=0.5,application/xml;q=1.0 If-None-Match: "17f0fff99ed5aae4edffdd6496d7131f" HTTP/1.1 200 OK Date: Tue, 22 December 2020 07:33:04 GMT Content-Type: application/xml Cache-Control: max-age=240 Location: /projects/12345 ETag: "b252d66ab3ec050b5fd2c3a6263ffaf51db10fcb" <project>...</project>
Conditional requests reduce the effort required to validate and re-fetch cached resources. eTags are opaque values that represent the current internal state, while last modified timestamps may be used for time-based comparison rather than eTags. They may also be used for concurrency control when making modifications to resources.
Concurrency Control in HTTP
Concurrency control with HTTP is a challenge encountered by teams that need to support APIs that modify data by different users at the same time. Some API designers find clever ways to implement resource-level locking over HTTP. However, HTTP has built-in concurrency control that prevent teams from building it themselves.
Conditional requests are also used to support concurrency control in HTTP. By combining eTags or last modified dates with state change methods such as PUT, PATCH, or DELETE, we can ensure that data is not overwritten accidentally by another API client via a separate HTTP request.
To apply a conditional request, the API client adds a precondition to the request to prevent modification if the last modified timestamp or eTag of the resource has changed. Should the precondition fail, a 412 Precondition Failed response is sent by the server. API servers may also enforce the requirement of a precondition header to enforce concurrency control by responding with a 428 Precondition Required if neither of the conditional headers were found in the request.
Below is an example where two API clients are trying to modify a project. First, each client retrieves the client using a GET request, then each attempts a change but only the first API client is able to apply the change:
GET /projects/12345 HTTP/1.1
Accept: application/json;q=0.5,application/xml;q=1.0
HTTP/1.1 200 OK
Date: Tue, 22 December 2020 07:33:04 GMT
Content-Type: application/xml
Cache-Control: max-age=240
Location: /projects/12345
ETag: "b252d66ab3ec050b5fd2c3a6263ffaf51db10fcb"
<project>...</project>
PUT /projects/1234
If-Match: "b252d66ab3ec050b5fd2c3a6263ffaf51db10fcb"
{ "name":"Project 1234", "Description":"My project" }
HTTP/1.1 200 OK
Date: Tue, 22 December 2020 08:21:20 GMT
Content-Type: application/xml
Cache-Control: max-age=240
Location: /projects/12345
ETag: "1d7209c9d54e1a9c4cf730be411eff1424ff2fb6"
<project>...</project>
PUT /projects/1234
If-Match: "b252d66ab3ec050b5fd2c3a6263ffaf51db10fcb"
{ "name":"Project 5678", "Description":"No, it is my project" }
HTTP/1.1 412 Precondition Failed
Date: Tue, 22 December 2020 08:21:24 GMT
The second API client that received the failed precondition response must now re-fetch the current representation of the resource instance, inform the user of the changes, and request them to determine if they wish to re-submit the changes made or leave it as-is.
Concurrency control may be added to an API through HTTP preconditions in the request header. If the eTag/last modified date hasn’t changed, then the request is processed normally. If it has changed, a 412 response code is returned, preventing the client from overwriting data as a result of two separate clients modifying the same resource concurrently. This is a powerful capability built-in to HTTP, preventing the need for teams to invent their own concurrency control support.
Summary
HTTP is a powerful protocol with a robust set of capabilities with a minimal of understanding. Using content negotiation allows API clients and servers to agree on a supported media type. Cache control directives provide client-side and intermediary caching support. HTTP preconditions can be used to determine if expired caches are still valid while protecting resources from overwriting changes. By applying these techniques, teams are able to build robust APIs that drive complex applications in a resilient and evolvable way.