
8. RPC and Query-Based API Design
Choosing the right architectural style for a network-based application requires an understanding of the problem domain and thereby the communication needs of the application, an awareness of the variety of architectural styles and the particular concerns they address.
Roy Fielding
Figure 8.1 The Design Phase offers several options for API styles. Alternatives to REST-based APIs are detailed in this chapter.
While the REST-based API style comprises most API products available in the market today, that may not always be the case. Nor is a REST-based API style always the best option for every API. As an API designer, it is important to understand the options available and the tradeoffs of each API style to determine the best fit for the target developers that will consume the API.
RPC and query-based API styles are two additional API styles beyond REST. RPC-based APIs have been available for decades but have begun to experience a resurgence through the introduction of gRPC. Query-based APIs are gaining popularity due to the introduction of GraphQL, making it the choice for many front-end developers that wish to have greater control over the shape of API responses.
With multiple API styles available, it is important to understand the advantages and challenges of each API style. For some API products and platforms, a single API style may be sufficient. For others, a mixture of intended uses and preferences for the developers tasked with integrating the API may require a mixture of API styles.
This chapter explores RPC and query-based API styles and how they may be used as an alternative or supplement to REST-based (Figure 6.1). The chapter also defines a design process for RPC and query-based API styles based on the API profiles captured during the define phase outlined in Chapter 6.
What is an RPC-based API?
A remote procedure call (RPC) is the execution of a unit of code, the procedure, over the network as if it were being executed locally. The client is given a list of available procedures that may be invoked on the server. Each procedure defines a parameter list that is both typed and ordered and the structure of a response structure.
It is important to recognize that the client is tightly coupled to the server’s procedure. If the procedure on the server is modified or removed, it then becomes the responsibility of developers to accommodate the changes. This includes modifying the client code so that the client and server are in sync and communicating properly once more. However, with this tight coupling often comes better performance.
RPC-based APIs must agree to a specification that supports the marshaling of the procedure invocation for the target programming language(s). In the early days of Java, the use of the remote method invocation (RMI) libraries supported Java-to-Java communication, with Java’s object serialization capabilities used as the binary format exchanged between Java processes. Other popular RPC standards include CORBA, XML-RPC, SOAP RPC, XML-RPC, JSON-RPC, and gRPC.
Below is an example of a JSON-RPC call over HTTP. Notice the explicit mention of the method (the procedure) and the ordered parameter list that results in a tight coupling between client and server:
POST https://rpc.example.com/calculator-service HTTP/1.1
Content-Type: application/json
Content-Length: ...Accept: application/json
{"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": 1}
Most RPC-based systems take advantage of a helper library and code generation tooling to generate the client and server stubs that are responsible for network communications. Those familiar with the fallacies of distributed computing recognize that failures can occur whenever code is executed remotely. While one of RPC’s goals is to make remote invocation behave as if it is calling a local procedure, network outages and other failure handling support is often incorporated into the client and server stubs and raised as an error.
The remote procedures are defined using an interface definition language (IDL). Code generators use the IDL to generate the client stub and a server stub skeleton that is ready for implementation. RPC-based APIs are generally faster to design and implement for this reason but are less resilient to method renaming and reordering of parameters.
The gRPC Protocol
gRPC was created by Google in 2015 to speed the development of services through the use of RPC and code generation. While initially started as an internal initiative, it has since been released and adopted by many organizations and open-source initiatives including Kubernetes.
gRPC is built upon HTTP/2 for transport and Protocol Buffers for serialization. It also leverages the bi-directional streaming offered by HTTP/2, allowing the client to stream data to the server and the server to stream data back to the client. Figure 8.2 shows how multiple programming languages communicate using generated client stubs with a gRPC server within a GoLang-based service.

Figure 8.2 An overview of how gRPC server and client stubs, generated for each programming language, work together.
By default, gRPC uses the proto file format used by Protocol Buffers to define each service, the service methods offered, and the messages exchanged. Listing 8.1 shows an example IDL file for a calculate service that offers a subtract operation.
Listing 8.1 An example gRPC-based IDL that defines a Subtract operation
// calculator-service.proto3
service Calculator {
// Subtracts two integers
rpc Subtract(SubtractRequest) returns (CalcResult) {}
}
// The request message containing the values to subtract
message SubtractRequest {
// number being subtracted from
int64 minuend = 1;
// number being subtracted
int64 subtrahend = 2;
}
// The response message containing the calculation result
message CalcResult {
int64 result = 1;
}
Factors When Considering RPC
RPC-based APIs often trade performance for tighter coupling. Code generation offered by many RPC protocols, such as gRPC, speed the development process by auto-generating client stubs and producing skeleton code for server implementation purposes. These factors result in teams selecting RPC-based APIs when they own both API client and server sides, allowing for development-time and run-time performance improvements.
However, there are several disadvantages to using an RPC-based API style that should be considering before proceeding:
■ The integration between client and server are tightly coupled. Once in production, the order of the fields cannot be changed without breaking API clients
■ The serialization format for marshaling and unmarshaling of procedure calls is fixed. Unlike REST-based APIs, multiple media types cannot be used, and HTTP-based content negotiation is therefore not possible
■ Some RPC protocols, such as gRPC, require custom middleware to work with browsers and to enforce authorization and role-based access when operations are tunneled through a single URL
Finally, keep in mind that gRPC depends upon HTTP/2 and require overriding default security restrictions to perform considerable customization of HTTP request headers, browsers cannot support gRPC natively. Instead, projects such as grpc-web offer a library and gateway to transform HTTP/1 requests into gRPC-based procedure calls.
In summary, RPC-based APIs are best used when the organization owns both the API client and server. The API team exposes an RPC-based service or API for other teams within the organization to consume as needed but must strive to keep their client code up to date with the latest changes.
RPC API Design Process
The RPC design process leverages the API profiles created during API modeling, as described in Chapter 6. Since the API profiles already identified operations and basic input/output details, the RPC API design process is a rapid three-step process. While the examples provided use gRPC and Protocol Buffers 3, the process may be adapted with little or no modification for other RPC-based protocols.
Step 1: Identify RPC Operations
First, migrate the list of operations, including their descriptions and request/response details, into a new tabular format designed to capture the high-level design. This is shown in Figure 8.3.
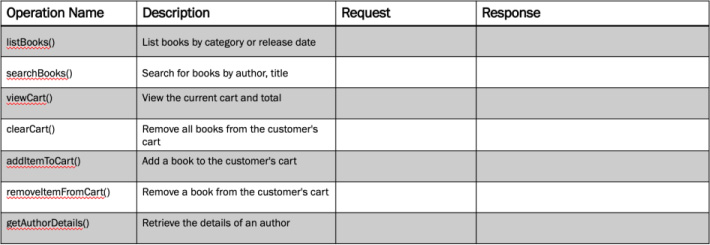
Figure 8.3 A table that captures the initial RPC operations based on the previous API profile examples from Chapter 6.
Though not necessary, following a verb-resource operation naming pattern, such as listBooks(), helps the RPC-based API to be more resource-centric and therefore more familiar to those who have used REST-based APIs.
Step 2: Detail RPC Operations
Next, expand each operation’s request and response details using the resource definitions and fields captured during API modeling. Most RPC protocols support a parameter list of fields, much like a local method invocation. In this case, list the input parameters that will be part of the request and the value(s) that will be returned in the response.
gRPC-based APIs that use Protocol Buffers, the parameter list must be wrapped within the definition of a message. Ensure each request has an associated message type defined that includes each input parameter. Likewise, each response will return a message, an array of messages, or an error status response. Figure 8.4 shows the Shopping Cart API design for a gRPC-based API.
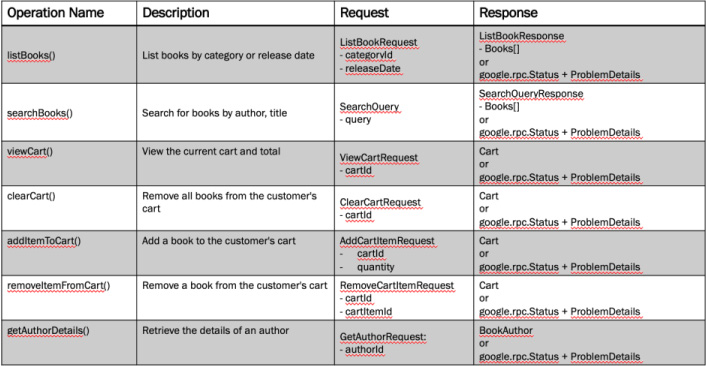
Figure 8.4 The gRPC design complete with request and response basic message details.
It is important to standardize on an error response type so that clients are able to process server-side errors consistently. For gRPC, it is recommended to use the google.rpc.Status message type, which supports an embedded details object with any additional details that the client may need to process.
Step 3: Document the API Design
Finally, use the design details from the previous two steps to compose the IDL file for the RPC-based API. In the case of gRPC, the IDL file is in the Protocol Buffers format. Listing 8.2 provides a skeleton of a gRPC-based Shopping Cart API to demonstrate the documentation process.
Listing 8.2 An example IDL file for the gRPC version of the Shopping Cart API
// Shopping-Cart-API.proto3
service ShoppingCart {
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse) {}
rpc SearchBooks(SearchBooksRequest) returns (SearchBooksResponse) {}
rpc ViewCart(ViewCartRequest) returns (Cart) {}
rpc ClearCart(ClearCartRequest) returns (Cart) {}
rpc AddItemToCart(AddCartItemRequest) returns (Cart) {}
rpc RemoveItemFromCart(RemoveCartItemRequest) returns (Cart) {}
rpc GetAuthorDetails() returns (Author) {}
}
message ListBooksRequest {
string category_id = 1;
string release_date = 2;
}
message SearchBooksRequest {
string query = 1;
}
message SearchBooksResponse {
int32 page_number = 1;
int32 result_per_page = 2 [default = 10];
repeated Book books = 3;
}
message ViewCartRequest {
string cart_id = 1;
}
message ClearCartRequest {
string cart_id = 1;
}
message AddCartItemRequest {
string cart_id = 1;
string book_id = 2;
int32 quantity = 3;
}
message RemoveCartItemRequest {
string cart_id = 1;
string cart_item_id = 2;
}
message CartItem {
string cart_item_id = 1;
Book book = 2;
int32 quantity = 3;
}
message Cart {
string cart_id = 1;
repeated CartItem cart_items = 2;
}
That’s it! The RPC-based API now has a high-level design. Details can now be added to complete the API and code generators used to jumpstart the development and integration work. Generating human-readable documentation is also recommended using a tool such as protoc-gen-doc.
Keep in mind that due to RPC’s tight coupling with code, many code changes will have a direct impact on the design of an RPC-based API. Put another way, RPC-based API designs are replaced, not modified, when code changes are applied.
Notice how most of the effort took place in the API modeling step. By using the API modeling technique as the foundation of the design effort, the work of bridging the desired outcomes of the customer is easily mapped into an RPC-based design. Should additional API styles be required, such as REST, the same API modeling work can be re-applied to the design effort for the API style of choice.
What is a Query-Based API?
Query-based APIs offer robust query capabilities and response shaping. They support fetching a complete resource representation by identifier, paginated listing of resource collections, and resource collection filtering using simple and advanced filter expressions. Most query-based styles support mutating data as well, supporting a full CRUD-based lifecycle along with custom actions.
Most query-based API styles also offer response shaping, allowing API clients to specify the fields to include in the response. Response shaping also supports deep and shallow fetches of resource graphs. Deep fetches allow nested resources to be retrieved at the same time as the parent, avoiding multiple API calls to recreate a large graph on the client. Shallow fetches prevent this from happening to avoid sending unnecessary data in the response. Response shaping is often used for mobile apps, when a smaller amount of data is required compared to a web application that can render more information in a single screen.
Understanding OData
Two of the most popular query-based API styles are OData and GraphQL. OData is a query-based API protocol that is standardized and managed by OASIS. It is built upon HTTP and JSON and uses a resource-based approach familiar to those already familiar with REST.
OData queries are made through specific resource-based URLs via GET. It also supports hypermedia controls for following related resources and data linking for expressing resource relationships using hypermedia links rather than identifiers during a create or update operation. OData supports custom actions, which may mutate data in ways beyond the standard CRUD pattern. Functions are also supported to support calculations. Listing 8.3 demonstrates the use of a filtered GET to retrieve any airports located in San Francisco, CA using an OData query.
Listing 8.3 An example OData using a filter to find airports in San Francisco, CA.
GET /OData/Airports?$filter=contains(Location/Address, 'San Francisco')
{
"@odata.context": "/OData/$metadata#Airports",
"value": [
{
"@odata.id": "/OData/Airports('KSFO')",
"@odata.editLink": "/OData/Airports('KSFO')",
"IcaoCode": "KSFO",
"Name": "San Francisco International Airport",
"IataCode": "SFO",
"Location": {
"Address": "South McDonnell Road, San Francisco, CA 94128",
"City": {
"CountryRegion": "United States",
"Name": "San Francisco",
"Region": "California"
},
"Loc": {
"type": "Point",
"coordinates": [
-122.374722222222,
37.6188888888889
],
"crs": {
"type": "name",
"properties": {
"name": "EPSG:4326"
}
}
}
}
}
]
}
Some developers find the complexity of adopting the OData specification too much for simple APIs. However, the mixture of REST-based API design with robust query options makes OData a popular choice for larger API products and platforms.
OData has considerable support and investment from companies such as Microsoft, SAP, and Dell. The Microsoft Graph API, which unifies the Office 365 platform under a single API, is built upon OData and is an excellent example of constructing data-centric REST-based APIs with advanced query support.
Exploring GraphQL
GraphQL is an RPC-based API style that supports the querying and mutation of data. It is a specification that was developed internally by Facebook in 2012 before being publicly released in 2015. It was originally designed to overcome the challenges of supporting web and mobile clients that need to obtain data via APIs at different levels of granularity and with the option of retrieving deeply nested graph structures. Over time, it has become a popular choice by front-end developers that need to bridge backend data stores with single-page applications (SPAs) and mobile apps.
All GraphQL operations are tunneled through a single HTTP POST or GET-based URL. Requests use the GraphQL query language to shape the response of desired fields and any nested resources in a single request. Mutations support modifying data or performing calculation logic and use a similar language as queries to express the data input for a modification or calculation request. All resource structures are defined in one or more schema files, ensuring that clients may introspect resources at design-time or run time. Listing 8.4 provides an example of a GraphQL query.
Listing 8.4 An example GraphQL query to fetch the San Francisco Airport by IATA code.
POST /graphql
{
airports(iataCode : "SFO")
}
{
"data" : {
{
"Name": "San Francisco International Airport",
"iataCode": "SFO",
"Location": {
"Address": "South McDonnell Road, San Francisco, CA 94128",
"City": {
"CountryRegion": "United States",
"Name": "San Francisco",
"Region": "California"
},
"Loc": {
"type": "Point",
"coordinates": [
-122.374722222222,
37.6188888888889
]
}
}
}
}
}
While GraphQL is popular with front-end developers, it has also gained significant traction across enterprises as a means to stitch multiple REST APIs together into a single query-based API. It is also useful for producing query-only reporting APIs alongside existing REST-based APIs, offering a best-of-breed approach to API platforms.
Many of the challenges around GraphQL are centered on its choice to tunnel through a single endpoint, rather than take advantage of the full capabilities of HTTP. This prevents the use of HTTP content negotiation support multiple media types beyond JSON. It also prevents the use of concurrency controls and optimistic locking offered by HTTP conditional headers. Similar challenges were experienced with SOAP-based services, which was designed to work across multiple protocols including HTTP, SMTP, and JMS-based message brokers.
Enforcing authorization is also a challenge, since traditional API gateways that expect to enforce access control by URL are limited to the single GraphQL operation. However, some API gateways are extending their capabilities to include authorization enforcement around GraphQL-based queries and mutations. Likewise, rate limiting, often associated to a combination of path and HTTP method, must be rethought to accommodate this new interaction style.
Query-Based API Design Process
The process used to design a query-based API is similar to other API design styles, such as RPC and REST. The primary difference is that the steps require the creation of a resource graph prior to designing the operations. To demonstrate the process, a GraphQL-based API will be designed based upon the API modeling effort shown in Chapter 6.
Step 1: Designing Resource and Graph Structures
The first and most important step for query-based APIs is to design the graph structure of all resources. If the API modeling work outlined in Chapter 6 has been done, then this step is already complete. If the API modeling work hasn’t been completed, go back to Chapter 6 and complete those steps before proceeding. Figures 8.5 and 8.6 revisit the resources and relationships identified in Chapter 6 for the bookstore example.
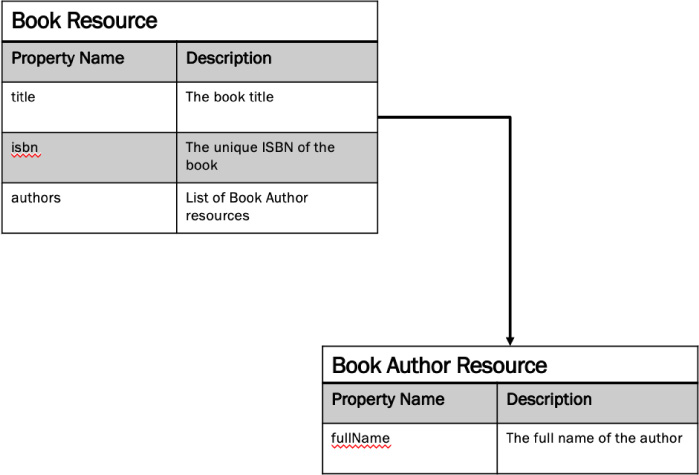
Figure 8.5 The Book resource is the first top-level resource that needs to be supported for the Shopping Cart API modeled in Chapter 6.

Figure 8.6 The Cart resource is the second top-level resource that needs to be supported for the Shopping Cart API modeled in Chapter 6.
Once all top-level resources, along with related resources have been identified, proceed to the next step to design the query and mutation operations.
Step 2: Design Query and Mutation Operations
The next step is to migrate all operations captured in the API profile during API modeling in Chapter 6. The API profiles captured each operation and included a safety classification of ‘safe’, ‘idempotent’, or ‘unsafe’. Classify each operation marked as ‘safe’ as a query. Operations marked as ‘idempotent’ or ‘unsafe’ will be mutations. For the Shopping Cart API, there are both query and mutation operations, as shown in Figure 8.7.
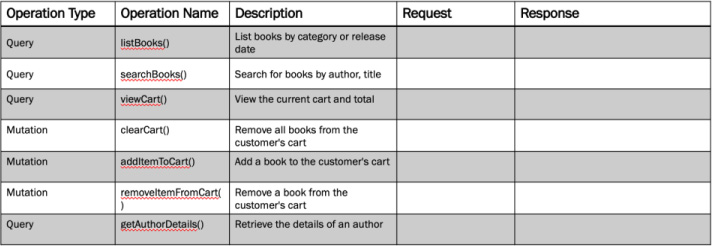
Figure 8.7 The Shopping Cart API profile, modeled in Chapter 6, is migrated to a tabular format that helps with query-based API design.
If the chosen protocol only supports query operations, then mutations will need to be handled using a different API style. GraphQL supports both, so the design can include both query and mutations within the same API definition.
Once the basic operation details have been captured, expand the request and response columns with further details about the input and output values. These input and output values were already determined during the API modeling in Chapter 6. Migrate these values into the new API design table. The Shopping Cart API operations are expanded in Figure 8.8.
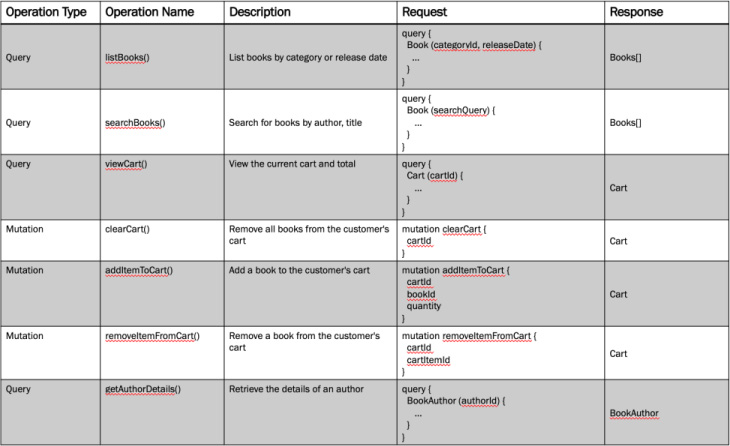
Figure 8.8 The Shopping Cart GraphQL API design is now expanded with additional details about queries and mutations.
Step 3: Document the API Design
Finally, document the resulting API using the preferred format for the chosen protocol. In the case of GraphQL, a schema is used to define the queries and mutations available, as shown in Listing 8.5.
Listing 8.5 The Shopping Cart API example captured as a GraphQL schema.
# API Name: "Bookstore Shopping API Example" # # The Bookstore Example REST-based API supports the shopping experience of
an online bookstore. The API includes the following capabilities and
operations... # type Query { listBooks(input: ListBooksInput!): BooksResponse! searchBooks(input: SearchBooksInput!): BooksResponse! getCart(input: GetCartInput!): Cart! getAuthorDetails(input: GetAuthorDetailsInput!): BookAuthor! } type Mutation { clearCart(): Cart addItemToCart(input: AddCartItemInput!): Cart removeItemFromCart(input: RemoveCartItemInput!): Cart } type BooksResponse { books: [BookSummary!] } type BookSummary { bookId: String! isbn: String! title: String! authors: [BookAuthor!] } type BookAuthor { authorId: String! fullName: String! } type Cart { cartId: String! cartItems: [CartItem!] } type CartItem { cartItemId: String! bookId: String! quantity: Int! } input ListBooksInput { offset: Int! limit: Int! } input SearchBooksInput { q: String! offset: Int! limit: Int! } input GetAuthorDetailsInput { authorId: String! } input AddCartItemInput { cartId: String! bookId: String! quantity: Int! } input RemoveCartItemInput { cartId: String! cartItemId: String! }
It is recommended to generate human-readable documentation using a tool such as graphql-docs. Be sure to offer an interactive interface using GraphQL Playground to enable developers to craft requests directly in the browser before writing their integration code.
All examples provided in this chapter are based upon the API workshop examples available on GitHub.
Summary
REST is not the only API style available. RPC and query-based APIs provide additional interaction styles that help developers integrate with an API product or platform quickly. They may also be combined with REST-based APIs to provide robust query operations for reporting and fast code generation options.
While the design process is slightly different for each API style, they all build upon the investment of aligning the needs between business, customers, and developers. The next step in the design process is to determine if one or more asynchronous APIs would benefit the API consumer. This is discussed in detail in the next chapter.