
At this point, most of you will know enough about queries from what you have learned so far that you will likely not need any of the material from this chapter. In fact, roughly half of this chapter deals with using queries that will couple your application to a target database, so they should be used with some degree of planning and caution in any case.
We start by going through the Jakarta Persistence support for native SQL queries and show how the results can be mapped to entities, nonentities, or simple data projection results. We then move on to stored procedure queries and explain how a stored procedure can be invoked from within a Jakarta Persistence application and how the results may be returned.
The second half of the chapter deals with entity graphs and how they can be used to override the fetch type of a mapping during a query. When passed as fetch graphs or load graphs, they provide great flexibility at runtime for controlling what state should get loaded and when.
SQL Queries
With all the effort that has gone into abstracting away the physical data model, both in terms of object-relational mapping and Jakarta Persistence QL, it might be surprising to learn that SQL is alive and well in Jakarta Persistence. Although Jakarta Persistence QL is the preferred method of querying over entities, SQL cannot be overlooked as a necessary element in many enterprise applications. The sheer size and scope of the SQL features, supported by the major database vendors, means that a portable language such as Jakarta Persistence QL will never be able to fully encompass all their features.
SQL queries are also known as native queries. EntityManager methods and query annotations related to SQL queries also use this terminology. While this allows other query languages to be supported in the future, any query string in a native query operation is assumed to be SQL.
Before discussing the mechanics of SQL queries, let’s first consider some of the reasons why a developer using Jakarta Persistence QL might want to integrate SQL queries into their application.
First, Jakarta Persistence QL, despite the enhancements made over the years, still contains only a subset of the features supported by many database vendors. Inline views (subqueries in the FROM clause), hierarchical queries, and additional function expressions to manipulate date and time values are just some of the features not supported in Jakarta Persistence QL.
Second, although vendors may provide hints to assist with optimizing a Jakarta Persistence QL expression, there are cases where the only way to achieve the performance required by an application is to replace the Jakarta Persistence QL query with a hand-optimized SQL version. This may be a simple restructuring of the query that the persistence provider was generating, or it may be a vendor-specific version that leverages query hints and features specific to a particular database.
Of course, just because you can use SQL doesn’t mean you should. Persistence providers have become very skilled at generating high-performance queries, and many of the limitations of Jakarta Persistence QL can often be worked around in application code. We recommend avoiding SQL initially if possible and then introducing it only when necessary. This will enable your queries to be more portable across databases and more maintainable as your mappings change.
The following sections discuss how SQL queries are defined using Jakarta Persistence and how their result sets can be mapped back to entities. One of the major benefits of SQL query support is that it uses the same Query interface used for Jakarta Persistence QL queries. With some small exceptions that are described later, all the Query interface operations discussed in previous chapters apply equally to both Jakarta Persistence QL and SQL queries.
Native Queries vs. JDBC
A perfectly valid question for anyone investigating SQL support in Jakarta Persistence is whether it is needed at all. JDBC has been in use for years, provides a broad feature set, and works well. It’s one thing to introduce a persistence API that works on entities, but another thing entirely to introduce a new API for issuing SQL queries.
Querying Entities Using SQL and JDBC
Querying Entities Using SQL and the Query Interface
Not only is the code much easier to read but it also uses the same Query interface that can be used for Jakarta Persistence QL queries. This helps to keep application code consistent because it needs to concern itself only with the EntityManager and Query interfaces.
An unfortunate result of gradual evolution of Persistence APIs is that when the TypedQuery interface was added, the createNativeQuery() method accepting a SQL string and a result class and returning an untyped Query interface was already defined. Now there is no backward compatible way to return a TypedQuery instead of a Query. The regrettable consequence is that when the createNativeQuery() method is called with a result class argument, one might mistakenly think it will produce a TypedQuery, like createQuery() and createNamedQuery() do when a result class is passed in.
Defining and Executing SQL Queries
SQL queries may be defined dynamically at runtime or named in persistence unit metadata, similar to the Jakarta Persistence QL query definitions discussed in Chapter 7. The key difference between defining Jakarta Persistence QL and SQL queries lies in the understanding that the query engine should not parse and interpret vendor-specific SQL. In order to execute a SQL query and get entity instances in return, additional mapping information about the query result is required.
The first and simplest form of dynamically defining a SQL query that returns an entity result is to use the createNativeQuery() method of the EntityManager interface, passing in the query string and the entity type that will be returned. Listing 11-2 in the previous section demonstrated this approach to map the results of an Oracle hierarchical query to the Employee entity. The query engine uses the object-relational mapping of the entity to figure out which result column aliases map to which entity properties. As each row is processed, the query engine instantiates a new entity instance and sets the available data into it.
If the column aliases of the query do not match up exactly with the object-relational mappings for the entity, or if the results contain both entity and nonentity results, SQL result set mapping metadata is required. SQL result set mappings are defined as persistence unit metadata and are referenced by name. When the createNativeQuery() method is invoked with a SQL query string and a result set mapping name, the query engine uses this mapping to build the result set. SQL result set mappings are discussed in the next section.
Using an Annotation to Define a Named Native Query
One advantage of using named SQL queries is that the application can use the createNamedQuery() method on the EntityManager interface to create and execute the query. The fact that the named query was defined using SQL instead of Jakarta Persistence QL is not important to the caller. A further benefit is that createNamedQuery() can return a TypedQuery whereas the createNativeQuery() method returns an untyped Query.
Executing a Named SQL Query
One thing to be careful of with SQL queries that return entities is that the resulting entity instances become managed by the persistence context, just like the results of a Jakarta Persistence QL query. If you modify one of the returned entities, it will be written to the database when the persistence context becomes associated with a transaction. This is normally what you want, but it requires that any time you select data that corresponds to existing entity instances, it is important to ensure that all the necessary data required to fully construct the entity is part of the query. If you leave out a field from the query, or default it to some value and then modify the resulting entity, there is a possibility that you will overwrite the correct version already stored in the database. This is because the missing state will be null (or some default value according to the type) in the entity. When the transaction commits, the persistence context does not know that the state was not properly read in from the query and might just attempt to write out null or the default value.
There are two benefits to getting managed entities back from a SQL query. The first is that a SQL query can replace an existing Jakarta Persistence QL query and that application code should still work without changes. The second benefit is that it allows the developer to use SQL queries as a method of constructing new entity instances from tables that may not have any object-relational mapping. For example, in many database architectures, there is a staging area to hold data that has not yet been verified or requires some kind of transformation before it can be moved to its final location. Using Jakarta Persistence, a developer could start a transaction, query the staged data to construct entities, perform any required changes, and then commit. The newly created entities will get written to the tables mapped by the entity, not the staging tables used in the SQL query. This is more appealing than the alternative of having a second set of mappings that maps the same entities (or even worse, a second parallel set of entities) to the staging tables and then writing some code that reads, copies, and rewrites the entities.
Using SQL INSERT and DELETE Statements
Executing SQL statements that make changes to data in tables mapped by entities is generally discouraged. Doing so may cause cached entities to be inconsistent with the database because the provider cannot track changes made to entity state that has been modified by data-manipulation statements.
SQL Result Set Mapping
In the SQL query examples shown so far, the result mapping was straightforward. The column aliases in the SQL string matched up directly with the object-relational column mapping for a single entity. It is not always the case that the names match up, nor is it always the case that only a single entity type is returned. Jakarta Persistence provides SQL result set mappings to handle these scenarios.
Here we have defined a SQL result set mapping called EmployeeResult that may be referenced by any query returning Employee entity instances. The mapping consists of a single entity result, specified by the @EntityResult annotation, which references the Employee entity class. The query must supply values for all columns mapped by the entity, including foreign keys. It is vendor-specific whether the entity is partially constructed or whether an error occurs if any required entity state is missing.
Mapping Foreign Keys
The MANAGER_ID, DEPT_ID, and ADDRESS_ID columns all map to the join columns of associations on the Employee entity. An Employee instance returned from this query can use the methods getManager(), getDepartment(), and getAddress(), and the results will be as expected. The persistence provider will retrieve the associated entity based on the foreign key value read in from the query. There is no way to populate collection associations from a SQL query. Entity instances constructed from this example are effectively the same as they would have been had they been returned from a Jakarta Persistence QL query.
Multiple Result Mappings
Mapping a SQL Query That Returns Two Entity Types
Mapping Column Aliases
Mapping a SQL Query with Unknown Column Aliases
Mapping Scalar Result Columns
Scalar Column Mappings
Scalar results may also be mixed with entities. In this case, the scalar results are typically providing additional information about the entity.
This query is particularly challenging because there is no direct relationship from Department to the Employee who is the manager of the department. Therefore, the employees relationship must be joined twice: once for the employees assigned to the department and once for the employee in that group who is also the manager. This is possible because the subquery reduces the second join of the employees relationship to a single result. We also need to accommodate the fact that there might not be any employees currently assigned to the department and further that a department might not have a manager assigned. This means that each of the joins must be an outer join and that we further have to use an OR condition to allow for the missing manager in the WHERE clause.
Department Summary Query
Mapping for the Department Query
Mapping Compound Keys
SQL Query Returning Employee and Manager
Mapping for Employee Query Using id Class
Mapping for Employee Query Using Embedded id Class
Mapping Inheritance
In many respects , polymorphic queries in SQL are no different from regular queries returning a single entity type. All columns must be accounted for, including foreign keys and the discriminator column for single-table and joined inheritance strategies. The key thing to remember is that if the results include more than one entity type, each of the columns for all the possible entity types must be represented in the query. The field result mapping techniques demonstrated earlier may be used to customize columns that use unknown aliases. These columns may be at any level in the inheritance tree. The only special element in the @EntityResult annotation for use with inheritance is the discriminatorColumn element. This element allows the name of the discriminator column to be specified in the unlikely event that it is different from the mapped version.
Mapping to Nonentity Types
Constructor expressions in native queries, much like the constructor expressions from Jakarta Persistence QL, result in the instantiation of user-specified types by using the row data of the underlying result set to invoke the constructor. All of the data required to construct the object must be represented as arguments to the constructor.
As with other examples that use ColumnResult, the name field refers to the column alias as defined in the SQL statement. The column results are applied to the constructor of the user-specified type in the order in which the column result mappings are defined. In cases where there are multiple constructors that may be ambiguous based on position only, the column result type may also be specified in order to ensure the correct match.
It is worth noting that should an entity type be specified as the target class of a ConstructorResult mapping , any resulting entity instances would be considered unmanaged by the current persistence context. Entity mappings on user-specified types are ignored when processed as part of a native query using constructor expressions.
Parameter Binding
SQL queries have traditionally supported only positional parameter binding. The JDBC specification itself supports only named parameters on CallableStatement objects, not PreparedStatement, and not all database vendors even support this syntax. As a result, Jakarta Persistence guarantees only the use of positional parameter binding for SQL queries. Check with your vendor to see whether the named parameter methods of the Query interface are supported, but understand that using them may make your application nonportable between persistence providers.
Another limitation of parameter support for SQL queries is that entity parameters cannot be used. The specification does not define how these parameter types should be treated. Be careful when converting or overriding a named Jakarta Persistence QL query with a native SQL query that the parameter values are still interpreted correctly.
Stored Procedures
Jakarta Persistence provides the ability to map and invoke stored procedures from a database. Jakarta Persistence has first-class support for stored procedure queries on the EntityManager and defines a query type, StoredProcedureQuery, which extends Query and better handles the range of options open to developers who leverage stored procedures in their applications.
The following sections describe how to map and invoke stored procedure queries using Jakarta Persistence. Note that the implementation of stored procedures is highly database dependent and is therefore outside the scope of this book. Unlike Jakarta Persistence QL and other types of native queries, the body of a stored procedure is never defined in Jakarta Persistence and is instead only ever referenced by name in the application.
Defining and Executing Stored Procedure Queries
Like other types of Jakarta Persistence queries, stored procedure queries may be created programmatically from the EntityManager interface, or they may be defined using annotation metadata and later referenced by name. In order to define a stored procedure mapping, the name of the stored procedure must be provided as well as the name and type of all parameters to that stored procedure.
Jakarta Persistence stored procedure definitions support the main parameter types defined for JDBC stored procedures: IN, OUT, INOUT, and REF_CURSOR. As their name suggests, the IN and OUT parameter types pass data to the stored procedure or return it to the caller, respectively. INOUT parameter types combine IN and OUT behavior into a single type that can both accept and return a value to the caller. REF_CURSOR parameter types are used to return result sets to the caller. Each of these types has a corresponding enum value defined on the ParameterMode type.
Stored procedures are assumed to return all values through parameters except in the case where the database supports returning a result set (or multiple result sets) from a stored procedure. Databases that support this method of returning result sets usually do so as an alternative to the use of REF_CURSOR parameter types. Unfortunately, stored procedure behavior is very vendor-specific, and this is an example where writing to a particular feature of a database is unavoidable in application code.
Scalar Parameter Types
After the query has been executed via the execute() method, any IN or INOUT parameter values returned to the caller may be accessed using one of the getOutputParameterValue() methods, specifying either the name of the parameter or its position. As with native queries, parameter positions are numbered beginning with one. Therefore, if an OUT parameter is registered in the second position for a query, then the number two would be used to access that value, even if the first parameter is of IN type and does not return any value.
Note that calling the getSingleResult(), getResultList(), or getResultStream() methods of the inherited Query interface will result in an exception if the stored procedure only returns scalar values through parameters.
Result Set Parameter Types
The first point to note about this example is that we are not specifying a parameter class type for the empList parameter. Whenever REF_CURSOR is specified as the parameter type, the class type argument to registerStoredProcedureParameter() is ignored. The second point to note is that we are checking the return value of execute() to see any result sets were returned during the execution of the query. If no result sets are returned (or the query only returns scalar values), execute() will return false. In the event that no records were returned and we did not check the result of execute(), then the parameter value would be null.
As a shortcut for executing queries, both getResultList() and getSingleResult() implicitly invoke execute(). In the case where the stored procedure returns more than one result set, each call to getResultList() will return the next result set in the sequence.
Stored Procedure Mapping
Stored procedure queries may be declared using the @NamedStoredProcedureQuery annotation and then referred to by name using the createNamedStoredProcedureQuery() method on EntityManager. This simplifies the code required to invoke the query and allows for more complex mappings than are possible using the StoredProcedureQuery interface. Like other Jakarta Persistence query types, names for stored procedure queries must be unique within the scope of a persistence unit.
Here we can see that the native procedure name must be specified in addition to the name of the stored procedure query. It is not defaulted as it is when using the createStoredProcedureQuery() method . As with the programmatic example, all parameters must be specified using the same arguments as would be used with registerStoredProcedureParameter().
The list of classes provided to the resultClasses field is a list of entity types. In the version of this example where REF_CURSOR is not used and the results are returned directly from the stored procedure, the empList parameter would simply be omitted. The resultClasses field would be sufficient. It is important to note that the entities referenced in resultClasses must match the order in which result set parameters are declared for the stored procedure. For example, if there are two REF_CURSOR parameters—empList and deptList—then the resultClasses field must contain Employee and Department in that order.
As with resultClasses, multiple result set mappings may also be specified if the stored procedure returns multiple result sets. It should be noted, however, that combining resultClasses and resultSetMappings is undefined. Support for result set mappings in the NamedStoredProcedureQuery annotation ensures that even the most complex stored procedure definitions can likely be mapped by Jakarta Persistence, simplifying access and centralizing metadata in a manageable way.
Entity Graphs
Unlike what its name implies, an entity graph is not really a graph of entities but rather a template for specifying entity and embeddable attributes. It serves as a pattern that can be passed into a find method or query to specify which entity and embeddable attributes should be fetched in the query result. In more concrete terms, entity graphs are used to override at runtime the fetch settings of attribute mappings. For example, if an attribute is mapped to be eagerly fetched (set to FetchType.EAGER), it can set to be lazily fetched for a single execution of a query. This feature is similar to what has been referred to by some as the ability to set a fetch plan, load plan, or fetch group.
Although entity graphs are currently being used for overriding attribute fetch state in queries, they are just structures that define attribute inclusion. There are no inherent semantics stored in them. They could just as easily be used as an input to any operation that might benefit from an entity attribute template, and in the future they might be used with other operations as well. However, we focus on what exists right now and discuss entity graphs in the context of defining fetch plans.
Entity graph nodes : There is exactly one entity graph node for every entity graph. It is the root of the entity graph and represents the root entity type. It contains all of the attribute nodes for that type, plus all of the subgraph nodes for types associated with the root entity type1.
Attribute nodes : Each attribute node represents an attribute in an entity or embeddable type. If it is for a basic attribute, then there will be no subgraph associated with it, but if it is for a relationship attribute, embeddable attribute, or element collection of embeddables, then it may refer to a named subgraph.
Subgraph nodes: A subgraph node is the equivalent of an entity graph node in that it contains attribute nodes and subgraph nodes, but represents a graph of attributes for an entity or embeddable type that is not the root type2.
To help illustrate the structure, let’s assume that we have the domain model described in Figure 8-1 and want an entity graph representation that specifies a subset of those attributes and entities, as shown in Figure 11-1.

Domain model subset
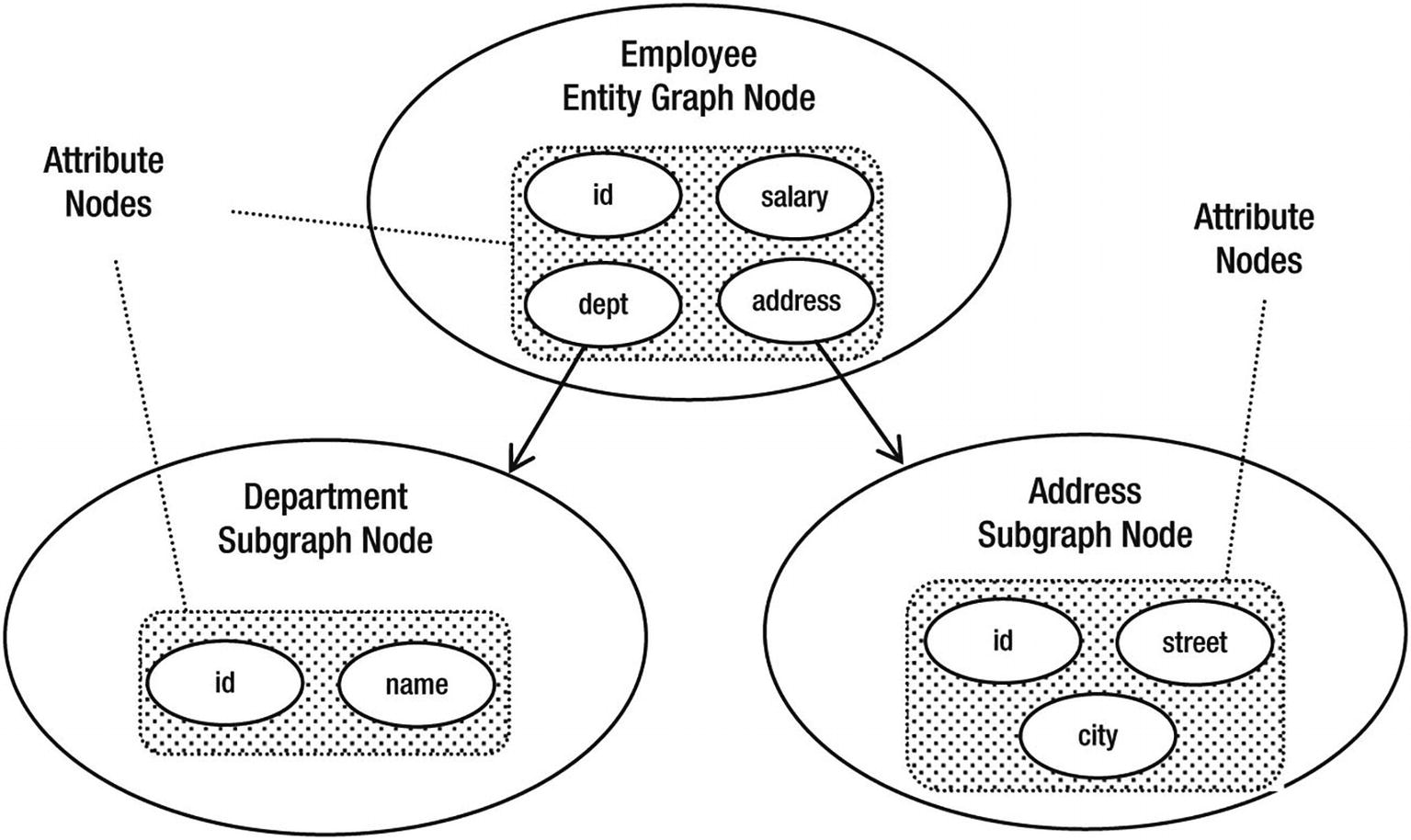
Entity graph state
A key point to mention is that identifier and version attributes (see Chapter 12 for a complete description about version attributes) will always be included in both the entity graph node and each of the subgraph nodes. They do not need to be explicitly included when creating an entity graph, although if either of them is included, it is not an error, just a redundancy.
Every entity and embeddable class has a default fetch graph that is composed of the transitive closure of all of the attributes that are either explicitly defined as or, defaulted to be, eagerly fetched. The transitive closure part means that the rule is recursively applied, so the default fetch graph of an entity includes not only all of the eager attributes defined on it but also all of the eager attributes of the entities that are related to it, and so on until the relationship graph has been exhausted. The default fetch graph will save us a lot of effort when it comes time to define more expansive entity graphs.
Entity Graph Annotations
Defining an entity graph statically in an annotation is useful when you know ahead of time that an attribute access fetch pattern needs to be different than what has been configured in the mappings. You can define any number of entity graphs for the same entity, each depicting a different attribute fetch plan.
The parent annotation to define an entity graph is @NamedEntityGraph. It must be defined on the root entity of the entity graph. All of its components are nested within the one annotation, so this means two things. First, if you are defining a large and involved entity graph, then your annotation is going to also be large and involved (and not likely very pretty). Second, if you are defining multiple entity graphs, you cannot share any of the constituent subgraph parts of one with another3. They are completely encapsulated within the enclosing named entity graph.
You likely noticed that the annotation begins with the Named prefix. This is a clear giveaway that entity graphs are named, and like other types of named objects in Jakarta Persistence, the names must be unique within the scope of the persistence unit. If not specified, the name of an entity graph will default to be the entity name (which, as you will recall from Chapter 2, is the unqualified name of the entity class). We will see later how a name is used to refer to a given entity graph when obtaining it from the entity manager.
Note that the subgraphs within an entity graph are also named, but those names are only valid within the scope of the entity graph and, as you will see in the next section, are used to connect the subgraphs.
Basic Attribute Graphs
Named Entity Graph with Basic Attributes
Annotating the class without listing any attributes is a shorthand for defining a named entity graph that is composed of the default fetch graph for that entity. Putting the annotation on the class causes the named entity graph to be created and referenceable by name in a query.
Using Subgraphs
Named Entity Graph with Subgraphs
For every Employee attribute that we want fetched, there is a @NamedAttributeNode listing the name of the attribute. The address attribute is a relationship, though, so listing it means that the address will be fetched, but what state will be fetched in the Address instance? This is where the default fetch group comes in. When a relationship attribute is listed in the graph but does not have any accompanying subgraph, then the default fetch group of the related class will be assumed. In fact, the general rule is that for any embeddable or entity type that has been specified to be fetched, but for which there is no subgraph, the default fetch graph for that class will be used. This is as you might expect since the default fetch graph specifies the behavior you get when you don’t use an entity graph at all, so the absence of specifying one should be equivalent. For our address example, you saw that the default fetch graph of Address is all of its (basic) attributes.
For the other relationship attributes, the @NamedAttributeNode additionally includes a subgraph element, which references the name of a @NamedSubgraph. The named subgraph defines the attribute list for that related entity type, so the subgraph we named dept defines the attributes of the Department entity related via the department attribute of Employee.
Named Entity Graph with Multiple Type Definitions
This named entity graph contains two major changes from the previous one. The first change is that we have added the manager attribute to be fetched. Since the manager is an Employee entity, you might be surprised that the namedEmp subgraph is specified, thinking that the manager Employee would just get loaded according to the fetch plan described by the named entity graph that we are defining (it is an Employee entity graph, after all). This is not what the rule states, however. The rule is that unless a subgraph is specified for a relationship attribute type, the default fetch graph for that type will be used as the fetch plan. For Employee, that would mean the manager would have all of its eager relationships loaded, and all of the eager relationships of its related entities, and so on. This could cause much more data to be loaded than we expected. The solution is to do as shown in Listing 11-16 and specify a minimal subgraph for the manager Employee.
The second change to this entity graph is that the phone subgraph includes the employee attribute. Once again, we are referencing the namedEmp subgraph to specify that the employee not be loaded according to the default fetch graph. The first thing of note is that we can reuse the same named subgraph in multiple places in the entity graph. After that you should notice that the employee attribute is really a back pointer to an employee in the result set of the named entity graph. We just want to make sure that referencing it from the phone does not cause more to be fetched than what is already defined by the employee named entity graph, itself.
Entity Graphs with Inheritance
Named Entity Graph with Inheritance
The attribute fetch state for the projects attribute is defined in a subgraph called project, but as you can see, there are two subgraphs named project. Each of the possible classes/subclasses that could be in that relationship has a subgraph named project and includes its defined state that should be fetched, plus a type element to identify which subclass it is. However, since DesignProject does not introduce any new state, we don’t need to include a subgraph named project for that class.
Named Entity Graph with Root Inheritance
A minor issue in the annotation definition is that the subclassSubgraphs element is of type NamedSubgraph[], meaning that a name is required to be specified even though in this case it is not used anywhere. We have labeled it notUsed to show that it is extraneous.
Map Key Subgraphs
Named Entity Graph with Map Key Subgraph
At this point you have just about as much expertise on named entity graphs as almost any developer out there, so after seeing all of the annotation examples, you might have noticed that they were more complicated than they needed to be. In many cases they listed attributes that could have been easily defaulted by using the default fetch graph rule. This was to try to keep the model as simple as possible but still be correct and able to demonstrate the concepts. Now that you have the rules straight in your mind, you should go back through each of the named entity graphs and as an exercise see how they could be shortened using the default fetch graph rule.
Entity Graph API
The API is useful for creating, modifying, and adding entity graphs dynamically in code. The entity graphs can be used to generate fetch plans based on program parameters, user input, or in some cases even static data when programmatic creation is preferred. In this section, we describe the classes and most of the methods of the API. We apply them in examples showing how to create dynamic equivalents of the named entity graphs in the previous annotation section.
While the entity graphs resulting from annotations are the same as those created using the API, there are some minor differences between the models they each employ. This is primarily because of the inherent differences between annotations and a code API, but is also somewhat by style choice.
This will create an AttributeNode object for each of the named attribute parameters and add it to the entity graph. There is unfortunately no method equivalent to the includeAllAttributes element in the @NamedEntityGraph annotation.
Dynamic Entity Graph with Subgraphs
The API-based entity graph is clearly shorter and neater than the annotation-based one. This is one of those cases when methods are not only more expressive than annotations but also easier to read. Of course, the variable argument methods don’t hurt either.
Dynamic Entity Graph with Multiple Type Definitions
Dynamic Entity Graph with Inheritance
Dynamic Entity Graph with Root Inheritance
Note that in Listing 11-23, we use the fact that no further subgraphs are being added to the subgraphs connected to the entity graph node, so neither of the created subgraphs are saved in stack variables. Rather, the addAttributeNodes() method is invoked directly on each of the Subgraph results of the addSubgraph() and addSubclassSubgraph() methods.
Dynamic Entity Graph with Map Key Subgraph
In this example, the addKeySubgraph() method was invoked on the root entity graph node, but the same method also exists on Subgraph, so a key subgraph can be added at any level where a Map occurs.
Managing Entity Graphs
The previous sections taught you how to create named and dynamic entity graphs, so the next logical step is to see how they can be managed. For the purposes of this section, managing entity graphs means accessing them, saving them, changing them, and creating new ones using an existing one as a starting point.
Accessing Named Entity Graphs
Note that the type parameter is wildcarded because the type of the entity graph is not known by the entity manager. Later, when we show ways to use an entity graph, you will see that it is not necessary to strongly type it in order to use it.
In this case, the EntityGraph parameter type is lower bounded to be Employee, but may also be some superclass of Employee as well. If, for example, Person was a superclass entity of Employee, then we would also get the Person entity graphs included in the output.
Adding Named Entity Graphs
The Entity Graph API allows dynamic creation of entity graphs, but you can go even further by taking those entity graphs and saving them as named entity graphs. Once they are named, they can be used just like a named entity graph that was statically defined in an annotation.
Note that the name we choose for the entity graph is up to us, just as it was when we defined it in annotation form, except that in this case there is no default name. We must supply a name as a parameter.
If a named entity graph with the same name already existed in the named entity graph namespace, it will be overridden by the one we are supplying in the addNamedEntityGraph() call, since there can only be one entity graph of a given name in a persistence unit.
Creating New Entity Graphs from Named Ones
In some cases you may find that you have an existing entity graph but want to create a new one that is very similar to the existing one, but differs by some small factor. This may be especially true due to the fact that subgraphs cannot be shared across entity graphs. The best way to do this is to use the createEntityGraph() method . By using an existing graph, you can modify just the parts that you want changed and then resave the modified one under a different name.
Creating an Entity Graph from an Existing Graph
The change that we made to the entity graph in Listing 11-25 was actually fairly trivial on purpose because it turns out that you may be somewhat limited in what you can do when it comes to making changes to an existing entity graph. The reason is that the Javadoc for the Entity Graph API does not specify whether you can mutate the collection accessors. For example, EntityGraph has a getAttributeNodes() method, but the method does not specify whether the List<AttributeNode<?>> returned by it is the actual List referred to by the EntityGraph instance. If it is a copy, then if it is modified, it will have no effect on the EntityGraph instance it was obtained from. This would make it impossible to remove an attribute from the graph since there is no alternative API to modify the collections other than to add to them.
Using Entity Graphs
The hardest part of entity graphs is creating them to be correct and to produce the result that you are expecting. Once you have created the right entity graphs, using them is fairly simple. They are passed as the values of one of two standard properties. These properties can either be passed into a find() method or set as a query hint on any named or dynamic query. Depending on which property is used, the entity graph will take on the role of either a fetch graph or a load graph. The following sections explain the semantics of the two types of graphs and show some examples of how and when they can be used.
Fetch Graphs
When an entity graph is passed into a find() method or a query as the value to the jakarta.persistence.fetchgraph property, the entity graph will be treated as a fetch graph. The semantics of a fetch graph are that all attributes included in the graph are to be treated as having a fetch type of EAGER, as if the mapping had been specified as fetch=FetchType.EAGER, regardless of what the static mapping actually specifies. Attributes that are not included in the graph are to be treated as LAZY. As described earlier, all identifier or version attributes will be treated as EAGER and loaded, regardless of whether they are included in the graph. Also, as we explained, if a relationship or embedded attribute is included in the graph but no subgraph is specified for it, then the default fetch graph for that type will be used.
The usefulness of a fetch graph is primarily to enable attributes to be fetched lazily when they were configured or defaulted to be eagerly fetched in the mapping. The thing to remember is that the same semantics of LAZY apply here as those that were described in Chapter 4. That is, when an attribute is marked as LAZY, there is no guarantee that the attribute will remain unloaded until the first time it is accessed. If an attribute is LAZY, it only means that the provider can optimize by not fetching the state of the attribute until it is accessed. The provider always has a right to load LAZY attributes eagerly if it wants to.
Load Graphs
A load graph is an entity graph that is supplied as the value to the jakarta.persistence.loadgraph property. The main difference between a fetch graph and a load graph is how the missing attributes are treated. While in a fetch graph an excluded attribute is to be treated as LAZY, in a load graph all missing attributes are to be treated as they are defined in the mappings. Expressing it in terms of the default fetch graph that we discussed in the previous sections, an empty load graph with no attributes included is the same as the default fetch graph for that type. The value of using a load graph is in the ability to cause one or more attributes to be treated as EAGER even though they were statically defined to be LAZY.
Triggering a Lazy Relationship
As you can see, the graph creation is quite simple since we are only adding one attribute and no subgraphs. The department attribute is a relationship, and we did not include a subgraph for it so the default fetch graph for Department will be used.
The difficulty with using a fetch graph is that it is a complete specification for the type. To make a single attribute be lazy, you need to specify all of the eager attributes. In other words, you cannot just override the fetch mode for a single attribute; when you create a fetch graph for an entity or embeddable type, you are effectively overriding all of the attributes of the type, either by including them or excluding them from the fetch graph. What the spec really needs is an additional property, jakarta.persistence.lazygraph, that would specify that all of the attributes included in the graph are to be lazy and all of the excluded attributes revert to what they are defined to be in their mappings. This would allow selective inclusion of lazy attributes.
Best Practices for Fetch and Load Graphs
When and how to use a fetch graph or a load graph will become obvious as you try to use one or the other; it won’t take long to discover which one fits your attribute loading needs. However, we offer a few tips to get you going and perhaps save you a little bit of time at the outset.
Learn what your target provider supports in terms of laziness. If your provider loads every lazy attribute eagerly and you are planning to create a series of fetch graphs for your queries to make attributes be lazy, then it might not be worth going through the effort at all. You can test the loading behavior of your provider by using the PersistenceUnitUtil.isLoaded() method on a lazy attribute before it is accessed. Try it out on the different types of attributes that you are planning to set to LAZY.
If your entity graphs are not acting the way that you think they should be, then look for attributes that do not have subgraphs. Remember that the default fetch graph will be used when no subgraph is specified. This is relevant for all bidirectional relationships (remember to set a subgraph for the relationship back to the original object type), but especially those that navigate back to the root entity type. Your intuition may tell you that the root entity graph specification will be used, but it is the default fetch graph that will be used instead.
If you end up using a fetch or load graph to change the fetch type of an attribute more times than not, you may want to consider changing how the fetch type is defined in the mapping. The mapping should define the most commonly used fetch mode, with the fetch or load graphs overriding it in the exceptional cases.
Using named entity graphs provides reusability of the entity graph and is a convenient way to create a slightly different graph for one-off modifications. While declaring them in code is a neater and preferred way to define entity graphs, you should go on to register them as named entity graphs to achieve the reusability. You will also want to define them in code that you are sure will be executed before any of the queries that use them get executed.
Summary
We began the chapter with a look at SQL queries. We looked at the role of SQL in applications that also use Jakarta Persistence QL and the specialized situations where only SQL can be used. To bridge the gap between native SQL and entities, we described the result set mapping process in detail, showing a wide range of queries and how they translate back into the application domain model.
We then showed how stored procedures can be invoked through a Jakarta Persistence query and how the results can be obtained through output parameters, ref cursors, and result sets. Stored procedures are always going to be somewhat database-specific, so care must be taken when using them.
We finished off by talking about entity graphs, what they are, and how they are constructed. We showed how named entity graphs can be defined in annotation form and went on to describe the API for creating dynamic entity graphs in code. The entity manager methods for obtaining named or modifiable entity graphs were discussed, including an example that took an existing named entity graph, made a change to it, and then added the changed graph as a separate named entity graph. Lastly, we showed how entity graphs are used. You saw how they take on the semantics of fetch graphs or load graphs when they are passed as property values to find() methods or queries.
In the next chapter, we look at more advanced topics, primarily in the areas of lifecycle callbacks, entity listeners, validation, concurrency, locking, and caching.