
C H A P T E R 8
Database Integration II
In this chapter, we will see how to work with a fully-fledged RDBMS system, MySQL. Then, we will examine two database abstraction layers, PDO and ADOdb. At the end of the chapter, we will show you how to utilize the Sphinx text search engine.
With MySQL database, there are several PHP extensions from which to choose. The most frequently used is the MySQL extension. This extension is quite old and has no object orientation because it has existed since PHP4 and MySQL 4. It also lacks some important features, such as bind variables. There is a much newer extension, MySQLi, which will be covered in this chapter. It is worth mentioning that the old, procedural MySQL extension is still the most frequently used.
Introduction to MySQLi Extension
The MySQLi extension is, in many respects, similar to the SQLite3 extension discussed in the previous chapter. It is also object oriented, not procedural like the old MySQL extension, and doesn't throw exceptions, just like SQLite3. The components are the same except for the database, which in this case is much more powerful than SQLite and supports the full set of ANSI standard database features. For the purposes of this chapter, MySQL version 5.1 is running on the local machine:
mysql -u scott --password=tiger scott
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 50
Server version: 5.1.37-1ubuntu5.5 (Ubuntu)
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> select version();
+-------------------+
| version() |
+-------------------+
| 5.1.37-1ubuntu5.5 |
+-------------------+
1 row in set (0.00 sec)
The user name is “scott,” the password is “tiger,” and the database name is “scott.” The database structure will be the same as it was in the SQLite3 example: we will have the same “emp” and “dept” tables. We will also use the same two scripts: one to load CSV files into the database, and another to run queries. Rewriting the same scripts establishes the base for comparison and makes the purpose of the different MySQLi methods very clear. Here are the table descriptions, MySQL style:
mysql> describe emp;
+----------+-------------+------+-----+-------------------+---------------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+-------------------+---------------------+
| empno | int(4) | NO | PRI | NULL | |
| ename | varchar(10) | YES | | NULL | |
| job | varchar(9) | YES | | NULL | |
| mgr | int(4) | YES | | NULL | |
| hiredate| timestamp | NO | | CURRENT_TIMESTAMP |
| sal | double | YES | | NULL | |
| comm | double | YES | | NULL | |
| deptno | int(4) | YES | MUL | NULL | |
+----------+-------------+------+-----+-----------------------+-----------------+
8 rows in set (0.00 sec)
mysql> describe dept;
+----------+-----------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra|
+----------+-----------------+------+-----+---------+--------+
| deptno | int(4) | NO | PRI | NULL | |
| dname | varchar(14) | YES | | NULL | |
| loc | varchar(13) | YES | | NULL | |
+----------+-----------------+------+-----+----------+-------+
3 rows in set (0.00 sec)
Tables are empty and there are also two CSV files to load into the database. CSV stands for “comma-separated values,” and is a standard tabular file format, recognized by SQL databases and spreadsheet programs such as Microsoft Excel. In fact, most databases have special provisions that allow easier loading of CSV files. That applies to MySQL, which has the LOAD DATA command, shown in the following example. Our script, however, is still a good exercise. Here is the syntax description of the LOAD DATA MySQL command:
mysql> help load data
Name: 'LOAD DATA'
Description:
Syntax:
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...]
The files to load will be called emp.csv and dept.csv. The emp file is slightly different than the version from Chapter 7. That's because SQLite, in contrast to MySQL, doesn't support date types. MySQL supports the full ANSI standard variety of data types and data arithmetic. In order to load the data of the TIMESTAMP type, we have to use the proper date format, namely YYYY-MM-DD HH24:MI-SS. The YYYY part signifies the four-digit year, MM is the month, DD is the day of the month, HH24 is hour in the 24-hour format, and MI and SS are minutes and seconds. Here are the files:
emp.csv
7369,SMITH,CLERK,7902,"1980-12-17 00:00:00",800,,20
7499,ALLEN,SALESMAN,7698,"1981-02-20 00:00:00",1600,300,30
7521,WARD,SALESMAN,7698,"1981-02-22 00:00:00",1250,500,30
7566,JONES,MANAGER,7839,"1981-04-02 00:00:00",2975,,20
7654,MARTIN,SALESMAN,7698,"1981-09-28 00:00:00",1250,1400,30
7698,BLAKE,MANAGER,7839,"1981-05-01 00:00:00",2850,,30
7782,CLARK,MANAGER,7839,"1981-06-09 00:00:00",2450,,10
7788,SCOTT,ANALYST,7566,"1987-04-19 00:00:00",3000,,20
7839,KING,PRESIDENT,,"1981-11-17 00:00:00",5000,,10
7844,TURNER,SALESMAN,7698,"1981-09-08 00:00:00",1500,0,30
7876,ADAMS,CLERK,7788,"1987-05-23 00:00:00",1100,,20
7900,JAMES,CLERK,7698,"1981-12-03 00:00:00",950,,30
7902,FORD,ANALYST,7566,"1981-12-03 00:00:00",3000,,20
7934,MILLER,CLERK,7782,"1982-01-23 00:00:00",1300,,10
The “dept” file is the same as the version in Chapter 7:
dept.csv
10,ACCOUNTING,"NEW YORK"
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON
The script to create tables doesn't have any interesting elements. All the calls that would be used to execute “create table” commands are contained in the scripts to load and query the data. Listing 8-1 shows the script to load both CSV files into their respective MySQL tables.
Listing 8-1. Loading Both CSV Files into their Respective MySQL Tables
<?php
if ($argc != 3) {
die("USAGE:script8.1 <table_name> <file name>
");
}
$tname = $argv[1];
$fname = $argv[2];
$rownum = 0;
function create_insert_stmt($table, $ncols) {
$stmt = "insert into $table values(";
foreach (range(1, $ncols) as $i) {
$stmt.= "?,";
}
$stmt = preg_replace("/,$/", ')', $stmt);
return ($stmt);
}
try {
$db = new mysqli("localhost", "scott", "tiger", "scott");
$db->autocommit(FALSE);
$res = $db->prepare("select * from $tname");
if ($db->errno != 0) {
throw new Exception($db->error);
}
$ncols = $res->field_count;
$res->free_result();
$ins = create_insert_stmt($tname, $ncols);
$fmt = str_repeat("s", $ncols);
$res = $db->prepare($ins);
if ($db->errno != 0) {
throw new Exception($db->error);
}
$fp = new SplFileObject($fname, "r");
while ($row = $fp->fgetcsv()) {
if (strlen(implode('', $row)) == 0) continue;
array_unshift($row, $fmt);
foreach(range(1,$ncols) as $i) {
$row[$i]=&$row[$i];
}
call_user_func_array(array(&$res, "bind_param"), &$row);
$res->execute();
if ($res->errno != 0) {
print_r($row);
throw new Exception($res->error);
}
$rownum++;
}
$db->commit();
if ($db->errno != 0) {
throw new Exception($db->error);
}
print "$rownum rows inserted into $tname.
";
}
catch(Exception $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
There are quite a few interesting elements in this script. Connecting to the database is not one of them. The arguments for creating a new MySQLi instance are hostname, user name, password, and the database to connect to. This statement will turn autocommit mode off:
$db->autocommit(FALSE);
MySQL is a full relational database that supports transactions and ACID requirements, as explained in Chapter 7. The COMMIT statement is an ANSI SQL one that makes the effects of the current transaction permanent. The opposite command is ROLLBACK, which will annul the effects of the current transaction. In autocommit mode, the database will issue COMMIT after every SQL statement, such as insert. The COMMIT statement is extremely expensive, because the session must wait until the required information is physically written to disk before it can proceed, as mandated by the ACID requirements. Not only is that statement extremely expensive and time consuming, having COMMIT turned on automatically may result in partial loads, which are usually undesirable. Good programmers want to correct the problem and restart the load.
![]() Note Turning autocommit off is a frequent practice with all relational databases. It is used when the script includes
Note Turning autocommit off is a frequent practice with all relational databases. It is used when the script includes INSERT, UPDATE, or DELETE statements. Autocommit is a very expensive operation.
As was the case with SQLite, we will use a select * from table SQL statement to find out how many columns there are. The first call to execute is prepare:
$res = $db->prepare("select * from $tname");
This will parse the SQL statement and turn it into an object of the class MYSQLI_STMT, a parsed statement. One of the MYSQLI_STMT properties is the number of included fields:
$ncols = $res->field_count;
When the number of columns is known, it is possible to close this result set using the free_result call and constructing the insert statement. The function used to do that is very similar to the function with the same name used in Listing 7-9, but it is not the same. The difference is that the insert now looks like this:
insert into dept values(?,?,?)
It has question marks, instead of the placeholder names :1, :2 and :3, as was the case in the Listing 7-9. The reason for that is the MySQLi interface doesn't support named binds, only positional binds. All binds must be done at once, binding an array of values to the parsed statement. The statement bind method has the following format:
$res->bind_param("fmt",$var1,$var2,$var3,...,$varN);
The first parameter is a format string, which is a string consisting of one character for every bind variable. The format character tells MySQLi about the type of variable that is being bound to the same position as it has in the parameter array. This means that $var1 is being bound to the first position in the insert, marked by the first question mark, $var2 to the second question mark, and so on. The format strings are “i” for integer, “d” for double, “s” for string, and “b” for blob. Blobs are binary data collections, like images.
We now have a programming problem: we must bind variables to the insert statement in a single PHP statement, without knowing how many variables we have to bind. The format string is easy—we simply construct one consisting of all strings. One of the nice things about weakly typed scripting languages such as PHP is that types are usually not a big problem; almost everything can be converted to a string. For the bind_param method, we have to use some trickery. Fortunately, PHP is very accommodating when it comes to the tricks. There is a PHP function called call_user_func_array, which calls the user function named in the first argument, with array from the second argument as the argument array. If we had a function F(), which takes three arguments ($a1,$a and $a3), then the expression F($a1,$a2,$a3) would be completely equivalent to the this expression: call_user_func_array("F",array($a1,$a2,$a3)). If the function F() was a method of an object $obj, the first argument would be array($obj,"F") instead of just “F.” This would have solved the problem in any PHP version, up to 5.3. Unfortunately, in version PHP 5.3, MySQLi expects references for bind variables and will not accept values. That is the reason for having the following snippet in the script:
array_unshift($row, $fmt);
foreach(range(1,$ncols) as $i) {
$row[$i]=&$row[$i];
}
We make sure that each bind variable contains a reference to the actual value. This doesn't refer to the format string. The range in the loop starts with 1 and, after the unshift, the format is at the beginning of the array. PHP arrays begin with index=0, not 1 as our “range” function in the previous code snippet, which means that we're skipping the format, leaving it as a value. After having prepared our argument array properly, the “magical” binding is done like this:
call_user_func_array(array(&$res, "bind_param"), &$row);
After that, the parsed statement $res is executed. This is repeated for every row returned from the CSV file by the SplFileObject. When all rows are read, the loop is finished and the commit is executed. This is the logical place for the commit. Of course, as was said in the beginning of this chapter, MySQLi does not throw exceptions; the programmers using it are responsible for the error checking after each critical step. MySQLi, however, is well equipped for that. Every object of all MySQLi classes has errno and error properties. The errno property is the error code, and the error property contains the textual description of the error. There are three different classes in the MySQLi system: MYSQLi itself, which describes the database connection; MYSQLi_STMT, which describes parsed statements; and MYSQLI_RESULT, which describes result sets, returned by the database to the script. Listing 8-1 used the connection and the statement class. To see the result class, we must retrieve some data (see Listing 8-2).
Listing 8-2. Writing a Report Identical to That Written in Listing 7-10
<?php
$QRY = "select e.ename,e.job,d.dname,d.loc
from emp e join dept d on(d.deptno=e.deptno)";
$ncols = 0;
$colnames = array();
try {
$db = new mysqli("localhost", "scott", "tiger", "scott");
$res = $db->query($QRY);
print "
";
if ($db->errno != 0) {
throw new Exception($db->error);
}
// Get the number of columns
$ncols = $res->field_count;
// Get the column names
while ($info = $res->fetch_field()) {
$colnames[] = strtoupper($info->name);
}
// Print the column titles
foreach ($colnames as $c) {
printf("%-12s", $c);
}
// Print the border
printf("
%s
", str_repeat("-", 12 * $ncols));
// Print rows
while ($row = $res->fetch_row()) {
foreach (range(0, $ncols - 1) as $i) {
printf("%-12s", $row[$i]);
}
print "
";
}
}
catch(Exception $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
This script will write a report identical to that written by the script in Listing 7-10. The script structure is identical to Listing 7-10. Note that there is no need to turn autocommit off here; there are no transactions in this script.
The “query” method of the connection class returns an object of the MYSQLI_RESULT class, in this case the aptly named $res. One of the properties of this object is the number of columns:
$ncols = $res->field_count;
For every column, there is a description—an object of an ancillary class stdClass. That object is retrieved by using the fetch_field method of the $res object. Here is the relevant snippet:
while ($info = $res->fetch_field()) {
$colnames[] = strtoupper($info->name);
}
This script is only using the “name” property, but the entire description, contained in the $info object, looks like this:
stdClass Object
(
[name] => empno
[orgname] => empno
[table] => emp
[orgtable] => emp
[def] =>
[max_length] => 4
[length] => 4
[charsetnr] => 63
[flags] => 53251
[type] => 3
[decimals] => 0
)
The “name” property obviously refers to column name. The orgname and orgtable are important when dealing with views. SQL standard describes objects called “views” that are essentially named queries. Queries are allowed to rename columns, so the new name will be in the “name” property, while the original name and table will be in the orgname and orgtable properties. The most important column, besides the name and length columns, is the type column. Unfortunately, the meaning of these types is not documented in the MySQLi documentation. However, from experience we know that 3 is the integer, 5 is double, 253 is the variable character, and 7 is the timestamp data type.
Just as with all other databases, there is a “fetch” call to fetch the results from the databases. In this case, the method is called fetch_row. The loop to fetch the data is literally the same as with the SQLite example in Listing 7-10:
while ($row = $res->fetch_row()) {
foreach (range(0, $ncols - 1) as $i) {
printf("%-12s", $row[$i]);
}
print "
";
}
The output of this script looks exactly like the output from Listing 7-10:
./script8.2.php
ENAME JOB DNAME LOC
--------------------------------------------------- -----------------
CLARK MANAGER ACCOUNTING NEW YORK
KING PRESIDENT ACCOUNTING NEW YORK
MILLER CLERK ACCOUNTING NEW YORK
SMITH CLERK RESEARCH DALLAS
JONES MANAGER RESEARCH DALLAS
SCOTT ANALYST RESEARCH DALLAS
ADAMS CLERK RESEARCH DALLAS
FORD ANALYST RESEARCH DALLAS
ALLEN SALESMAN SALES CHICAGO
WARD SALESMAN SALES CHICAGO
MARTIN SALESMAN SALES CHICAGO
BLAKE MANAGER SALES CHICAGO
TURNER SALESMAN SALES CHICAGO
JAMES CLERK SALES CHICAGO
Conclusion of the MySQLi Extension
MySQLi is much more modern and powerful than the original MySQL extension, but it lacks some important features, such as named binds and exception handling. Many hosting companies allow only the original MySQL extension, which is superseded by the bigger, better, faster MySQLi. Fortunately, this is not the only choice. There is also the PDO family of extensions, which resolves the problems with the named binds and exceptions. We will discuss PDO extensions next.
Introduction to PDO
PDO is an abbreviation that stands for PHP data objects. It is an attempt at unifying the extensions for all databases into a single programming application program interface (API), which would simplify the programming and decrease the amount of knowledge needed for writing applications that interact with the database. This effort has been successful for some databases, but less so for others. When everything is reduced to the same common denominator, some special features are lost—such as “copy” commands in PostgreSQL or array interface and session pooling for Oracle RDBMS. These features are designed to significantly speed up data processing, but they are not available through PDO. Also, database vendors are primarily maintaining the database specific extensions, leaving PDO somewhat neglected.
PDO has two layers. First, there is a general PDO interface, and then there is a database-specific driver that, in cooperation with the PDO layer, does the actual interfacing with the database. PDO is enabled by default, but the database drivers need to be installed separately. One of the databases for which PDO interface is actually better than the native interfaces is MySQL. So let's see the CSV loading script written using PDO (see Listing 8-3).
Listing 8-3. The CSV Loading script Written Using PDO
<?php
if ($argc != 3) {
die("USAGE:script8.3 <table_name> <file name>
");
}
$tname = $argv[1];
$fname = $argv[2];
$rownum = 0;
function create_insert_stmt($table, $ncols) {
$stmt = "insert into $table values(";
foreach (range(1, $ncols) as $i) {
$stmt.= "?,";
}
$stmt = preg_replace("/,$/", ')', $stmt);
return ($stmt);
}
try {
$db = new PDO('mysql:host=localhost;dbname=scott', 'scott', 'tiger'),
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$res = $db->prepare("select * from $tname");
$res->execute();
$ncols = $res->columnCount();
$ins = create_insert_stmt($tname, $ncols);
$res = $db->prepare($ins);
$fp = new SplFileObject($fname, "r");
$db->beginTransaction();
while ($row = $fp->fgetcsv()) {
if (strlen(implode('', $row)) == 0) continue;
$res->execute($row);
$rownum++;
}
$db->commit();
print "$rownum rows inserted into $tname.
";
}
catch(PDOException $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
This is the shortest version so far, yet it is fully functional. The majority of the missing code is the error-handling code. This code is conspicuously absent from this version of the script. The reason is the setAttribute call immediately following the database connection. In that setAttribute call, PDO is instructed to throw an object of the class PDOException should any database error occur. That exception contains the error code and message, which can be used for handling errors. That rendered all of our custom-made, error-handling code unnecessary, so it was removed from the script.
The code that binds variables to placeholders or statements is also completely absent. PDO can perform a bind at execution time, a characteristic that it shares with our next portable database interface, ADOdb. The execute method takes the array of the bind values as an argument and binds the array to the parsed statements immediately before the execution. Compare that to the horrible call_user_func_array magic necessary to bind variables in Listing 8-1. PDO does support the bindValue method for named placeholders, but it is not frequently needed.
In this script, we also see a deficiency of the “common denominator” approach: PDO cannot turn off autocommit mode for the session. It can explicitly start transaction, which will, of course, turn off autocommit mode for the duration of the transaction, not for the duration of the session.
Also, PDO has to initially execute a prepared statement to be able to describe it. The native MYSQLi driver doesn't have to execute the statement; we were able to execute field_count on the statement that was prepared but not executed in Listing 8-1. Executing a long-running SQL statement can potentially cause a large delay. If the table to be loaded contains hundreds of millions of records, an execution of our initial SQL statement “select * from $table” can potentially take hours to complete. The reason for that lies in the ACID requirements. ACID requirements guarantee the user that he will only see changes committed to the database before the query starts. The database has to reconstruct the rows modified after the query has started and present the user the version of the row from the time just before the query has started. That can be a very lengthy process, if the underlying table is large and frequently modified. An alternative would be to lock the table and block anybody else from modifying it for the duration of the query. Needless to say, that strategy wouldn't get a passing grade if the concurrency of access is a business requirement.
One would have to resort to non-portable tricks to address that. One way would be to rewrite that SQL like this: “select * from $table limit 1”. That would return only a single row from the database and therefore execute much faster, regardless of the table size. Unfortunately, that wouldn't fly with Oracle RDBMS, which doesn't support the LIMIT option, but uses its own ROWNUM construct instead. There is no portable solution to that problem. That is the risk of using PDO. The majority of users, however, employ only one or two types of database engines (MySQL and PostgreSQL only, for example) so that this is usually not a big problem.
Now, let's see the second script, the little report produced by running a fixed query (see Listing 8-4).
Listing 8-4. The Report Produced by Running a Fixed Query
<?php
$QRY = "select e.ename,e.job,d.dname,d.loc
from emp e join dept d on(d.deptno=e.deptno)";
$colnames = array();
$ncols = 0;
try {
$db = new PDO('mysql:host=localhost;dbname=scott', 'scott', 'tiger'),
$db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$res = $db->prepare($QRY);
$res->execute();
// Get the number of columns
$ncols = $res->columnCount();
// For every column, define format, based on the type
foreach (range(0, $ncols - 1) as $i) {
$info = $res->getColumnMeta($i);
$colnames[] = $info['name'];
}
// Print column titles, converted to uppercase.
foreach ($colnames as $c) {
printf("%-12s", strtoupper($c));
}
// Print the boundary
printf("
%s
", str_repeat("-", 12 * $ncols));
// Print row data
while ($row = $res->fetch(PDO::FETCH_NUM)) {
foreach ($row as $r) {
printf("%-12s", $r);
}
print "
";
}
}
catch(PDOException $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
This is completely standard—there's not much to see here. However, it is interesting that the getColumnMeta method, used to describe the cursor, is still marked as experimental and tagged as “use at your own risk” in the manual. This method is absolutely crucial; its absence would severely limit the usefulness of PDO. However, this method doesn't work on all databases. It doesn't work on Oracle, for example. The column description produced by this method looks like this:
Array
(
[native_type] => VAR_STRING
[flags] => Array
(
)
[table] => d
[name] => loc
[len] => 13
[precision] => 0
[pdo_type] => 2
)
The table name is “d,” because the method picked the table alias from our SQL. The query being executed is the following:
$QRY = "select e.ename,e.job,d.dname,d.loc
from emp e join dept d on(d.deptno=e.deptno)";
In this query, we used the alias “e” for the emp table and the alias “d” for the dept table, in order to be able to shorten the join condition from (emp.deptno=dept.deptno) to the much shorter and equally understandable (by the DB server) form (e.deptno = d.deptno). The getColumnMeta method returned this alias instead of the full table name. This is not necessarily a bug, but renders the “table” field much less useful. Also, fetch contains the PDO::FETCH_NUM option, similar to what we have seen with the SQLite example in Listing 7-10. Just as was the case there, fetch can return row as an array indexed by numbers, column names, or as an object with column names as properties. The default is FETCH_BOTH, which will fetch both associative and number indexed arrays.
Having mentioned SQLite, there is a PDO driver for SQLite3, too. Even more, getColumnMeta works perfectly and returns the full table name, not the SQL alias, as is the case with MySQL. Both of our PDO scripts would work perfectly if we replaced the connection line with $db = new PDO(‘sqlite:scott.sqlite’). Of course, the commands to begin and commit the transaction would not be needed, but nor would they do any harm.
Conclusion of the PDO
PDO is off to a good start, but it is still in development. It will be the only database extension in PHP 6, but that will not happen soon. It is completely sufficient for utilizing the standard database features, but it still cannot utilize the proprietary database extensions built into almost all databases, mainly for performance reasons. Combined with the fact that it is not fully functional, I would advise the reader to treat PDO extension as beta software.
Introduction to ADOdb
The last of the database extensions covered in this book will be ADOdb. It is a third-party extension, available free under the BSD license terms. Most Linux distributions have made it available as a software package and, for the rest, it can be downloaded from here:
http://adodb.sourceforge.net
The installation consists of unpacking the source in a file system directory. The directory where the source is unpacked should be included in the include_path PHP.ini parameter for that installation.
![]() Note The directory where ADOdb is unpacked needs to be added to the
Note The directory where ADOdb is unpacked needs to be added to the include_path PHP parameter in the php.ini file, if it isn't already there.
ADOdb is modeled after the Microsoft's popular ActiveX data object (ADO) framework. It supports exceptions, iterating through database cursors and both positional and named binds. It also supports many databases, just like the original ADO framework. MySQL, PostgreSQL, SQLite, Firebird, Oracle SQL Server, DB2, and Sybase are all supported, among others. It uses the original database extensions, linked into the PHP interpreter. If MySQL is supported by the PHP interpreter, it is possible to use ADOdb. In other words, ADOdb is just a class structure on top of the original driver. ADOdb sets the driver option, depending on its own options, but the original driver for the databases is not provided by John Lim, the author of ADOdb.
ADOdb comes in two varieties: one, older, which supports both PHP4 and PHP5 and the newer one, which supports only PHP5. The examples in this book have been tested with the latter version. At a glance, these two versions look exactly the same, if the version that supports PHP4 is needed, it has to be downloaded separately. Of course, PHP4 does not support exceptions, so this part will not work with PHP4.
ADOdb contains two main classes: the connection class and the result class, or set or record set class, as it is called in the ADOdb documentation.
To better explain things, let's see the first of our two scripts, the script to load a CSV file into database (see Listing 8-5).
Listing 8-5. Loading a CSV File into a Database
<?php
require_once ('adodb5/adodb.inc.php'),
require_once ('adodb5/adodb-exceptions.inc.php'),
if ($argc != 3) {
die("USAGE:script8.5 <table_name> <file name>
");
}
$tname = $argv[1];
$fname = $argv[2];
$rownum = 0;
function create_insert_stmt($table, $ncols) {
$stmt = "insert into $table values(";
foreach (range(1, $ncols) as $i) {
$stmt.= "?,";
}
$stmt = preg_replace("/,$/", ')', $stmt);
return ($stmt);
}
try {
$db = NewADOConnection("mysql");
$db->Connect("localhost", "scott", "tiger", "scott");
$db->autoCommit = 0;
$res = $db->Execute("select * from $tname");
$ncols = $res->FieldCount();
$ins = create_insert_stmt($tname, $ncols);
$res = $db->Prepare($ins);
$fp = new SplFileObject($fname, "r");
$db->BeginTrans();
while ($row = $fp->fgetcsv()) {
if (strlen(implode('', $row)) == 0) continue;
$db->Execute($res, $row);
$rownum++;
}
$db->CompleteTrans();
print "$rownum rows inserted into $tname.
";
}
catch(Exception $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
The following two lines will load all the basic classes into our script. There are some other classes that will be mentioned later:
require_once ('adodb5/adodb.inc.php'),
require_once ('adodb5/adodb-exceptions.inc.php'),
The exact location for include will depend on the ADOdb installation. The ADODB distribution can be unpacked anywhere on the system and will work the same, as long as it is properly specified by the include_path PHP directive. The new ADOdb connection is created by using the NewADOConnection function. It is not a classic PHP class constructor; it is simply a function that returns an object of the connection class. Once the connection object is created, it is possible to connect to the database, using the Connect method. ADOdb also contains the call to turn off autocommit, once the connection is established. It is unnecessary in this script, because it controls its transaction—but turning autocommit off doesn't do any harm, and is considered a good programming practice, as explained earlier.
Note that the “Execute” method belongs to the connection class, not to the record set class. ADOdb also has to execute the statement, to be able to describe the data set, determine the number of fields, and their names, types, and lengths. The number of fields is determined by using the FieldCount method shown previously. Binds are not necessary; it is possible to hand the bind array to the execute call, just as was the case with PDO. Once again, it is worth noticing that the execute method is in the connection class, not in the result set class. Execute method is actually very powerful and supports array execution. Array execution is something that is not frequently done with MySQL, but is very frequently done with Oracle or PostgreSQL, which have special optimizations for just such a method. What is this all about? If we had to execute the following insert statement: $INS="insert into tab values(?,?)" and an array of rows looking like this:
$rowbatch = array(
array($a1,$a2),
array($b1,$b2),
array($c1,$c2));
The following call would actually insert all three rows, with a single execution:
$db->Execute($INS,$rowbatch);
What is gained by inserting batches of records like this? First, it minimizes the network communication, which is still the slowest part of the application. If there are 100 rows to insert, then inserting every row by itself would require 100 roundtrips across the network. If the rows are inserted in groups of 20, just five roundtrips are needed. Also, inter-process communication is drastically reduced, and the database is far less busy as a result. This bulk binding feature is deactivated by default and must be activated by setting the “bulkBind” connection attribute, like this: $db->bulkBind=true. Once again, this doesn't make much sense for MySQL or SQLite, but can be pretty handy with some other databases.
Everything else is completely standard, with the exception of the CompleteTrans method, which is smart and knows that it has to roll the transaction back should any error occur. There are also classic methods for commit and rollback, but they need additional logic to check for database errors. This is redundant, because ADOdb would throw an exception in case of error and the transaction would die before it reached the commit point. Also, we did have problems with CompleteTrans against PostgreSQL 9.0 database, which performed rollback when we expected the transaction to commit. We eventually opted for the CommitTrans() method instead. With MySQL, there are no such issues.
Now, let's see our report. The SQL is well known by now; the only interesting tricks in the report are describing columns and fetching rows (see Listing 8-6).
Listing 8-6. Insert Listing Caption Here.
<?php
require_once ('adodb5/adodb.inc.php'),
require_once ('adodb5/adodb-exceptions.inc.php'),
$ADODB_FETCH_MODE = ADODB_FETCH_NUM;
$QRY = "select e.ename,e.job,d.dname,d.loc
from emp e join dept d on(d.deptno=e.deptno)";
$colnames = array();
$ncols = 0;
try {
$db = NewADOConnection("mysql");
$db->Connect("localhost", "scott", "tiger", "scott");
$res = $db->Execute($QRY);
// Get the number of columns
$ncols = $res->FieldCount();
// Get the column names.
foreach (range(0, $ncols - 1) as $i) {
$info = $res->FetchField($i);
$colnames[] = $info->name;
}
// Print column titles, converted to uppercase.
foreach ($colnames as $c) {
printf("%-12s", strtoupper($c));
}
// Print the boundary
printf("
%s
", str_repeat("-", 12 * $ncols));
// Print row data
while ($row = $res->FetchRow()) {
foreach ($row as $r) {
printf("%-12s", $r);
}
print "
";
}
}
catch(Exception $e) {
print "Exception:
";
die($e->getMessage() . "
");
}
?>
At the very beginning of Listing 8-6, there is the line that sets $ADODB_FETCH_MODE variable to the constant ADODB_FETCH_NUM. This is another version of the same mechanism that we have seen before. Instead of passing the desired form of the returned value as a parameter, like PDO does, ADOdb sets a special global variable, which is in turn consulted by the FetchRow method. Just as was the case with PDO, ADOdb can return an associative array, an array indexed by numbers, or both. The default is to return both.
The method to describe columns is the FetchField. It takes the column number as an argument and returns object with the following properties: name, type, and max_length. Here is an example of the returned object:
ADOFieldObject Object
(
[name] => ename
[max_length] => -1
[type] => varchar
)
As visible from this example, the max_length field is not too accurate and shouldn't be relied upon. Fortunately, as we know by now, PHP is a weakly typed scripting language, so this is not a big problem.
ADOdb is a large library. It even has its own caching mechanism, which is not as efficient as the “memcached” package, but is extremely simple to set up and utilize. Caching is based on the file system cache. The results are written to the operating system files, so that the next time the query is requested, the result is simply read from the file. If the web server is on a different machine from the database, using cache to retrieve data can really save some time. Also, caching is multi-user, so if several users are executing a similar application, the result file will be cached in memory and the boost to performance will be rather significant. To define cache, one needs only to define the cache directory, by setting the corresponding global variable:
$ADODB_CACHE_DIR="/tmp/adodb_cache";
The cache directory can grow quickly and should be located at a place that is usually cleaned up by the operating system, like /tmp directory which gets completely cleaned up at system reboot, if the system is so configured. After that, the cache is used by calling the CacheExecute method instead of the Execute method:
$res = $db->CacheExecute(900,$QRY);
The first argument defines the number of seconds after which the cache will be invalidated. If the file is older than the given number of seconds, it will not be used. The second argument is the query to execute. This would create a file in the directory which looks like this:
ls -R /tmp/adodb_cache/
/tmp/adodb_cache/:
03
/tmp/adodb_cache/03:
adodb_03b6f957459e47bab0b90eb74ffaea68.cache
The sub-directory “03” is based on the hash value of the query, computed by the internal hash function. Then there is another hash function that computes the file name. If the query in the file name is the same as is the query in the script, the results will be retrieved from the file, not from the database.
Bind variables are prohibited; only the results of the queries without placeholders can be cached. That is an understandable stipulation, because the query result depends on bind variables, and those are supplied at run time, which makes caching impossible. On a frequently changing database, where business requirements mandate that the data must be completely accurate and up to date, this caching mechanism cannot be used, but it is extremely helpful for relatively static data that is frequently queried. The date, for instance is unlikely to change in less than 24 hours, which makes today's date an ideal candidate for caching.
ADOdb Conclusion
ADOdb has many other methods and tricks, but covering them all is beyond the scope of this book. We have described the most frequently used ones, but the library is very comprehensive. It is by far the largest of the libraries we've seen so far. It is also used in many open source products, is well documented, and well supported. It also supports a very wide variety of databases.
Full-Text Searches with Sphinx
Text searching is usually considered a separate topic from the database integration, but every major database has a full-text search engine. Sphinx just happens to be the default full-text search engine for the MySQL database. In this book, however, I will show how to set up and utilize Sphinx with PostgreSQL for searching text, because that's the database we have at hand.
So, what are full-text searches, and why are they needed? Most modern databases do a pretty good job with regular expressions, so one would think that there is no need for full-text searches. Unfortunately, searches by regular expressions usually cannot use indexes, so they are far too slow to be practical. That is why there is a technique for creating special text indexes that help with full-text searches. Text indexes and the accompanying software can do the following things:
- Word searches. That means searching for records which contain specific words, like “chicken” or “salad.”
- Phrase searches. This is for users looking for a phrase, such as “chicken salad,” who don't necessarily want to get back something like “chicken wings and potato salad,” which would be returned based on a search for two single words, “chicken” and “salad.”
- Proximity searches, also known as the “nearness operators,” retrieve all rows where the given text field contains, for example, the words “hello” and “world” not more than three words apart from each other.
- Quorum searches, which are the type of search in which there is a list of words and a minimal number of those words to be present in the article, to be flagged as a match.
- Logical operators: You can combine searches for words using the AND, OR, and NOT operators.
All modern search engines are capable of such feats. There is, of course, more than one text searching software, both open source and commercial. Open source text engines are Sphinx, Lucene, Xapian, and Tsearch2, and they each have strengths and weaknesses. There are also commercial products like Oracle*Text or the IDOL engine by Autonomy Corp. The rest of this chapter will be devoted to Sphinx, an open source text search engine developed by Sphinx Technologies. The company web site is: http://sphinxsearch.com
The installation is simple and the program is usually available as an operating system package. If it isn't already installed natively, Sphinx can be built on almost any operating system. PHP also needs an additional module that is installed by using the PECL utility.
Sphinx consists of two parts: indexer, which builds the desired text index; and search process, which executes the searches. Both of the components are controlled by the configuration file called sphinx.conf. The first step is to actually build an index. The Sphinx indexer reads the document source and builds an index, according to some rules. Document source can be a database or a program producing XML (“xmlpipe”). Supported databases are PostgreSQL and MySQL.
The database used for demonstrating Sphinx will be PostgreSQL, which is a very powerful open source database. The table that will be used for indexing is called food_articles, and was assembled by searching food articles on Google. There are 50 articles, with the author, URL where we found the article, the text, and the date on which the article was collected. All the articles were collected on January 30, 2011, so the column with the dates is a bit boring. It is, however, necessary for the example presented in this book.
The newline characters in the articles are replaced by <BR> the HTML tag that marks the line break. This was a necessary evil, because of the method used to load data into the database. All the information about articles was assembled into a large CSV file, by using the almighty “vi” editor. The resulting CSV file was then loaded into the database. Table 8-1 shows what the food_articles table looks like.
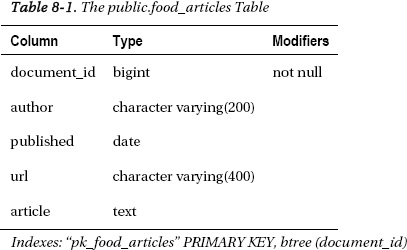
Document id is the primary key, and it is the sequence number for the article. It is of the type “bigint” which may contain 64 bit integers. Now, let's proceed with building our text index. The text index is built by the program called “indexer,” which is part of the Sphinx package. First, we need the configuration file, which is usually named sphinx.conf. The location of the file is dependent on the operating system you use. Here is our fairly typical configuration file, constructed from the example file, which comes with the software:
Listing 8-7. Insert Listing Caption Here,
###################################################
## data source definition
###################################################
source food
{
# data source type. mandatory, no default value
# known types are mysql, pgsql, mssql, xmlpipe, xmlpipe2, odbc
type = pgsql
sql_host = localhost
sql_user = mgogala
sql_pass = qwerty
sql_db = mgogala
sql_port = 5432
sql_query =
SELECT document_id,
date_part('epoch',published) as publ_date,
article
FROM food_articles;
sql_query_info =
SELECT document_id,
date_part('epoch',published) as publ_date,
article
FROM food_articles
WHERE document_id=$id;
sql_attr_timestamp = publ_date
}
index food-idx
{
source = food
path = /usr/local/var/data/food
docinfo = extern
charset_type = utf-8
preopen = 1
}
indexer
{
mem_limit = 256M
write_buffer = 8M
max_file_field_buffer = 64M
}
searchd
{
listen = 9312
log = /var/log/searchd.log
query_log = /var/log/query.log
read_timeout = 5
max_children = 30
pid_file = /var/run/searchd.pid
max_matches = 1000
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
read_buffer = 1M
read_unhinted = 256K
subtree_docs_cache = 64M
subtree_hits_cache = 64M
}
The structure of this file is rather simple. The first part defines the source of the data. Each source has its name; this example source is called “food.” It first defines the database, including the type of the database, database name, username, password and port—all the usual stuff. The second thing to define in the source section is how to get the data. There are two queries: one to get the data, the other to get information about the particular document id. Sphinx expects that the first column of the select list is the primary key. It also expects the primary key to be an integer. It can accept 64 bit integers.
![]() Note The first column in the query in the Sphinx data source must be the primary key. Primary key must also be an integer. Large 64-bit integers are supported.
Note The first column in the query in the Sphinx data source must be the primary key. Primary key must also be an integer. Large 64-bit integers are supported.
That was the reason for defining our document_id column as “bigint,” despite the fact that there are only 50 articles. Also note that there is no need to select all of the columns from the table. Selecting only the columns that need to be indexed will be instrumental in saving both time and space. After that, optional attributes can be defined. Attributes are not the index columns. Attributes cannot be used for text searches; attributes can only be used for sorting and range searches. We could ask for the data from February, not that we would get any because of the nature of our sample data. Attributes can be numbers or time stamps. Time stamp is defined as the number of seconds, since the epoch: 01/01/1970. Date fields cannot be used directly; they must be mapped into epoch format.
![]() Note Fields consisting of several lines, such as our SQL fields, must use backslash characters as in the previous example.
Note Fields consisting of several lines, such as our SQL fields, must use backslash characters as in the previous example.
The next section is the definition of the index. It must contain the name of the data source that will be used to get the data, the path where the index files will be written, and the character set type. Our index also contains the optional performance parameter “preopen,” which directs the search process to open the index when it is started, rather than wait for the first search. The first search will be done faster because of this.
After that there are memory options for the indexer, the program used for building text indexes and search process, which executes searches. The important option for the search process is the “max_matches” option. It defines the maximum number of hits that search process can return. It can find more matches than that, but it can only return “max_matches” hits. In PHP, that is the maximum size of array that can be returned by the search. Our configuration file is ready; let's build an index.
indexer food-idx
Sphinx 1.10-beta (r2420)
Copyright (c) 2001-2010, Andrew Aksyonoff
Copyright (c) 2008-2010, Sphinx Technologies Inc (http://sphinxsearch.com)
using config file '/usr/local/etc/sphinx.conf'...
indexing index 'food-idx'...
collected 50 docs, 0.2 MB
sorted 0.0 Mhits, 100.0% done
total 50 docs, 230431 bytes
total 0.038 sec, 5991134 bytes/sec, 1299.98 docs/sec
total 3 reads, 0.000 sec, 38.9 kb/call avg, 0.0 msec/call avg
total 9 writes, 0.000 sec, 31.6 kb/call avg, 0.0 msec/call avg
The program “indexer” was invoked with the name of index as an argument; it's that simple. The only non-trivial thing was writing the configuration file. Sphinx prides itself with the fastest index building program around. It really is extremely fast, and that can be important when there are many items to index. After the index is created, the search process must be started, simply executing the command searchd from the command line. In Windows, there is a menu used for starting a search process. If everything was done correctly, the process will start as shown in the following:
searchd
Sphinx 1.10-beta (r2420)
Copyright (c) 2001-2010, Andrew Aksyonoff
Copyright (c) 2008-2010, Sphinx Technologies Inc (http://sphinxsearch.com)
using config file '/usr/local/etc/sphinx.conf'...
listening on all interfaces, port=9312
precaching index 'food-idx'
precached 1 indexes in 0.001 sec
Now, we can test the index using the “search” program. The search program is a command line tool which communicates with the search process and executes the searches passed to it on the command line.
search "egg & wine"
Sphinx 1.10-beta (r2420)
Copyright (c) 2001-2010, Andrew Aksyonoff
Copyright (c) 2008-2010, Sphinx Technologies Inc (http://sphinxsearch.com)
using config file '/usr/local/etc/sphinx.conf'...
index 'food-idx': query 'egg & wine ': returned 2 matches of 2 total in 0.000 sec
displaying matches:
1. document=9, weight=1579, publ_date=Sun Jan 30 00:00:00 2011
2. document=36, weight=1573, publ_date=Sun Jan 30 00:00:00 2011
words:
1. 'egg': 8 documents, 9 hits
2. 'wine': 20 documents, 65 hits
This search looked for the documents that contain both words “egg” and “wine.”. It also gave us the detailed information about the documents it found. It's time now to learn some more details about searching:
- Searching for “egg | wine” will return all the documents that contain either of the words. The “|” character is the “or” logical operator.
- Searching for “egg & wine” will return the documents containing both words. The “&” character is the “and” logical operator.
- Searching for “!egg” will return all the documents that do not contain the word egg. The “!” character is logical negation—the “not” operator. If used to do a search from the command line, single quotes must be used around the search text, because the exclamation mark has a special meaning for the shell, and characters within the single quotes are not further interpreted by the shell. That applies only to Linux and Unix shells only—not to the Windows command line.
- Searching for “olive oil” (double quotes are a part of the expression) will return the documents containing the exact phrase “olive oil.”
- Searching for “olive oil”~5 will return documents that contain the words “olive” and “oil” separated by no more than five words.
- Searching for “oil vinegar tomato lettuce salad”/3 will return the documents that contain at least three of the given words. That is known as the “quorum search.”
These are basic operations that can be combined in the complex expressions. Now it's time to write a PHP script that will search the text index. Because of the size and type of the output, this script will be used from the browser, which means that we need to build a simple HTML form and present the output as an HTML table. That will be done by using two PEAR modules: HTML_Form and HTML_Table. HTML_Form is a bit outdated but very simple and easy to use. The script is shown in Listing 8-8.
Listing 8-8. Searching the Text Index (PHP Script)
<?php
/* ADOdb includes */
require_once ('adodb5/adodb.inc.php'),
require_once ('adodb5/adodb-exceptions.inc.php'),
$ADODB_FETCH_MODE = ADODB_FETCH_NUM;
$db = ADONewConnection("postgres8");
$colheaders = array("ID", "AUTHOR", "PUBLISHED", "URL", "ARTICLE");
/* PEAR modules are used for simplicity */
require_once ('HTML/Form.php'),
require_once ('HTML/Table.php'),
$attrs = array("rules" => "rows,cols", "border" => "3", "align" => "center");
$table = new HTML_Table($attrs);
$table->setAutoGrow(true);
/* Set the output table headers */
foreach (range(0, count($colheaders) - 1) as $i) {
$table->setHeaderContents(0, $i, $colheaders[$i]);
}
/* Get the given document from the database */
$QRY = "select * from food_articles where document_id=?";
$srch = null;
if (!empty($_POST['srch'])) {
$srch = trim($_POST['srch']);
}
/* Display a simple form, consisting only of a single textarea field */
echo "<center><h2>Sphinx Search</h2></center><hr>";
$form = new HTML_Form($_SERVER['PHP_SELF'], "POST");
$form->addTextarea("srch", 'Search:', $srch, 65, 12);
$form->addSubmit("submit", "Search");
$form->display();
/* Stop if there is nothing to search */
if (empty($srch)) exit;
try {
$db->Connect("localhost", "mgogala", "qwerty", "mgogala");
$stmt = $db->Prepare($QRY);
/* Connect to Sphinx "searchd" process */
$cl = new SphinxClient();
$cl->SetServer("localhost", 9312);
/* Set the extended mode search, for the phrase searches */
$cl->SetMatchMode(SPH_MATCH_EXTENDED2);
/* Results will be ordered by date */
$cl->SetSortMode(SPH_SORT_ATTR_DESC, "publ_date");
/* Execute search and check for problems */
$result = $cl->Query($srch);
if ($result === false) {
throw new Exception($cl->GetLastError());
} else {
if ($cl->GetLastWarning()) {
echo "WARNING: " . $cl->GetLastWarning() . "<br>";
}
}
/* Get the results and use them to query the database */
foreach ($result["matches"] as $doc => $docinfo) {
$rs = $db->Execute($stmt, array($doc));
$row = $rs->FetchRow();
/* Add the result of the query to the output table */
$table->addRow($row);
}
/* Display the results */
echo $table->toHTML();
}
catch(Exception $e) {
die($e->getMessage());
}
This script is a far better approximation of the usual scripts required from the programmers than the command line snippets elsewhere in this chapter. This script combines database, using ADOdb, simple web modules, and the Sphinx search engine. The output is displayed in Figure 8-1.
Figure 8-1. The output of the script in Listing 8-7
The form is used to enter the search terms. When the terms search are entered, the script connects to the database and the Sphinx search engine and retrieves the data by issuing the following call: $result=$cl->Query($search). Sphinx will parse the query terms and return data. The result is an associative array that looks like the following:
Array
(
[error] =>
[warning] =>
[status] => 0
[fields] => Array
(
[0] => article
)
[attrs] => Array
(
[publ_date] => 2
)
[matches] => Array
(
[13] => Array
(
[weight] => 2713
[attrs] => Array
(
[publ_date] => 1296363600
)
)
)
[total] => 1
[total_found] => 1
[time] => 0
[words] => Array
(
[celery] => Array
(
[docs] => 3
[hits] => 4
)
[apple] => Array
(
[docs] => 3
[hits] => 5
)
[soup] => Array
(
[docs] => 13
[hits] => 30
)
[lentil] => Array
(
[docs] => 1
[hits] => 3
)
)
)
The match for our search terms was found in the document with the id=13. The search term was “celery & apple & soup & lentil;” we were looking for articles containing all of these words. Matches were put in the $result['matches'] array, which is also an associative array containing the document information with weight. The weight is calculated by using the statistical function known as “BM25,” which takes into account the word frequencies. The higher the document weight, the better the match. The article itself is not in shown in the visible form. To get the row with the document id=13, we need to go to the database. That may be inconvenient, but duplicating the data from the database in the index would be a waste of space. It doesn't really matter when there are only 50 records, but if there are many millions of rows, duplicating data can be prohibitively expensive. After all, the data already resides in the database, there is no need to store it into the index, too.
Sphinx is amazingly versatile software. It has real-time indexes, SQL-query-like syntax, it can do “federated indexing”—which means that one index can point to several other indexes—on different machines, it can do UTF-8, and it can access different databases. Its searching syntax is very flexible. Sphinx client is also built into the MySQL database but, as shown previously, it can actually work with other databases, too. Sphinx can also emulate MySQL and be used to connect target with MySQL PHP extension, MySQL ODBC driver and even the MySQL command line client. Additionally, the PHP client is well maintained and documented.
Summary
In this chapter, we covered the following topics:
- MySQL
- PDO
- ADOdb
- Sphinx
MySQL is a fully-fledged relational database, and there are many books about it. All the sections in this chapter, except the last one, are based on the MySQL database. For the purpose of this chapter, the database type is not particularly important. PDO, ADOdb, and Sphinx could have also been demonstrated on SQLite, PostgreSQL, Oracle, or DB2. The scripts would look just the same. Granted, for Sphinx, we would need a script that would read the database and write XML files for any database other than MySQL or PostgreSQL, but that is not a big issue. ADOdb could very well be used for that.
This chapter is not a comprehensive reference; it's intended only as an introduction. All of these libraries and software packages have options and possibilities not described in this chapter.