
Chapter 7. Gradual Process Improvement as an Antidote for Overcommitment
Imagine that you are a consultant that specializes in helping early-stage product companies overcome their growing pains.
Your newest client is a few months into a transition from a web development agency to a product-based business. Their core focus is on a product called TagSail, a mobile-friendly web application that helps people find nearby yard sales.
The business model for TagSail is straightforward: the site is free to use for anyone looking for yard sales to visit, but a fee is charged to anyone who posts a listing on the site. There are also premium features available to paying customers, but like many early-stage products, TagSail’s offering is a bit scattershot.
For months it looked like the product wasn’t going anywhere, but in recent weeks it has started to gain traction. This spike in activity has caused major strains at both the technical and human level, and the team is now at the point where they’re willing to try anything to prevent themselves from being swept out to sea.
Your mission is to help the TagSail team minimize waste while still delivering a steady stream of value to their customers. To make this happen, you’ll apply Lean-inspired process improvements—but custom-fit to the needs of the situation on the ground.
In this chapter…
You will learn some common anti-patterns that lead to struggles in software project management, and how incremental process improvements at all levels can alleviate some of those pains.
Respond to unexpected failures with swiftness and safety
It’s your first day on site and there is already a minor emergency underway. A reverse geocoding API is failing, causing all requests for TagSail’s home page to fail with a generic internal server error.
You ask Erica (the company’s lead developer) to fill you in on the details:
You: I know that this isn’t the time for a long conversation, but can you take just a minute to get me up to speed on what’s happening here?
Erica: Sure. We had a huge traffic spike this morning because our site was mentioned in some popular newsletter, and that caused a major slowdown in page load times. We increased the number of server instances to try to keep up with demand, which helped for a little while. But then a few minutes ago our reverse geocoding service started rejecting all requests, completely breaking our home page.
You: So as of right now, no one is able to use the application at all?
Erica: That’s correct. They’ll see a generic “We’re sorry, something went wrong” message that gets served up whenever an internal server error happens. That’s pretty terrible, because this is by far the most visitors we’ve ever seen in a day.
You: Any idea how much longer it will take to get the site back up and running again?
Erica: I’m not sure yet. We’re still trying to figure out exactly what went wrong with the reverse geocoding API, and how to get it working again. We think it’s probably some sort of rate limiting issue.
You continue to observe for a few minutes, and suggest that the team might be focusing on the wrong question. Rather than looking into fixing the broken API, they should focus on getting the home page up and running again—even if it means degrading functionality slightly.
After a brief discussion, the developers come to realize the reverse geocoding is not essential, anyway. A separate set of APIs detect the visitor’s geographical coordinates and center the map on their location; the reverse geocoding service is only needed to turn those coordinates into a meaningful place name that gets shown in the search box above the map.
Temporarily disabling the reverse geocoding API calls would leave the location search box blank. This could cause a minor usability headache in situations where the detected location was inaccurate, because the first thing the visitor would see would be a map centered on a specific location that wasn’t their own. But even in that scenario, the visitor could still manually enter their location into the search box, and everything would work as expected from there.
Although most of the team seems comfortable with this idea, Sam (the team’s most experienced frontend developer) pushes back a bit. He suggests the root cause of the problem could be properly fixed by moving the server-side reverse geocoding API calls to the client side, eliminating the rate limiting issues and also fully restoring site functionality. You briefly discuss the tradeoffs with Sam and Erica:
You: Have you already built the client-side implementation, or are you planning on writing the code for that right now?
Sam: Well, when we first built this feature I’d suggested doing it that way, and I did a quick spike to prove the concept. I’m not sure if I still have that code laying around, but the documentation was easy enough to follow.
You: How long do you think it’d take you to make that change, if we went that route?
Sam: It’d be a quick fix, I think. Half an hour of work at the most.
You: When you did your proof of concept, how realistic of an environment did you test the work in? Did you simulate lots of simultaneous requests? Did you try it in all the browsers that the product needs to support? Did you actually expose it to live production traffic?
Sam: Um, no. But this API is provided by FancyMappingService. I’d assume that it’s pretty solid given how common of a use case this is, and how popular their service is.
You: You know what, I think you’re probably right. But I also worry that experimentation under pressure tends to go poorly. If we disable the feature that’ll take the pressure off, and allow everyone to think more clearly.
Erica: How about a compromise? Sam can begin working on a patch that will move the reverse geocoding to the client side, and I’ll buy us some time by disabling the feature for now. That should only take a few minutes, and in the worst case I can revert and we’d be back to where we are now.
You: That sounds fine, as long as you wait until after the system has returned to a stable state to begin experimenting with Sam’s patch.
Erica gets to work on disabling the reverse geocoding feature, which goes smoothly. She asks you whether or not it’d be a good idea to deploy her fix right away, but you point out that even in chaotic situations like this, it is better to ask for a quick review than to rush work out the door that might make a bad situation worse.
Erica opens a pull request for Sam to review before the two of you take a quick walk around the office just to see how everyone else is holding up.
After waiting for what feels like too long, Sam finally sends Erica an update via chat; he’s still working on his own patch, which he thinks will be ready to ship in another 15–20 minutes. He also wants to skip the temporary workaround and go straight to deploying his own fix.
You don’t say anything, but the look on your face makes it clear that you’re not happy with this response. You walk across the hall to Sam’s office and close the door.
Five minutes later, Erica receives a notification that her branch has been deployed. Immediately after that, you return to her workspace with Sam in tow. Erica pulls up the server logs and the three of you monitor the system together.
As the request logs tick away on the screen, they clearly show that people are successfully loading the home page again. There is a big spike in the number of manual lookups of locations, as expected.
Convinced the site is stable again, Erica asks Sam to resume work on the client-side patch. With the immediate pressure relieved, there is no rush to get that fix out the door—so it can be properly reviewed and tested before it is rolled out.
Identify and analyze operational bottlenecks
It’s been a week since your last visit, and the first thing you ask Erica is what new features have shipped in the last few days.
When she tells you, “Nothing, unless you count bug fixes,” it is impossible to miss the faint look of disappointment in her eyes. You waste no time and get straight to work:
You: So if no new improvements have been rolled out in the last week, what has each person on your team been up to?
Erica: Let’s see…I’ve started to integrate a few new classified ad networks with our application.
Sam has been working on a new version of an internal library we’ve built, in preparation for some new features we plan to implement next month.
And finally, Sangeeta and David started on an improvement that we planned to ship this week, but then there were some urgent support requests that needed attention. They had to put their feature work on pause in order to take care of those issues.
You: What were the urgent support requests?
Erica: They were also related to our classified ad integrations. A few weeks ago we added support for an ad network that is pretty popular, and it seemed to work well at first. But it turns out that the new version of their API only supports certain regions, and for other regions you need to use their old API.
The differences between the two APIs are small enough that we thought we could share a common client between them as long as we didn’t use any newer features, but that turned out to be a mistaken assumption.
You: So how did you find out about this problem?
Erica: Through bug reports from users. We don’t have a very good monitoring mechanism in place for the integrations at this point, so we rely on our support team to be our eyes and ears.
When something comes up only once or twice, we assume it’s an isolated issue and then review and prioritize the bug reports weekly. When three or more reports show up for the same issue, it gets escalated and someone looks into it immediately. That’s what happened in this case, and it ate up the second half of David and Sangeeta’s week.
You: But the issue they investigated is sorted out now?
Erica: Well, we think so. We don’t have direct access to several of the systems we integrate with, and in particular, don’t have staging environments set up for every possible version of every system we support. Their fixes seem to have sorted out the issue for the people who filed the bug reports, but it’s a little hard to tell if we’ve managed to fully fix the compatibility issues or not.
You: This sounds like kind of a nightmare, in general.
Erica: It is! I think we spend at least half of our time in a given week on these integrations, and I have my doubts that they’ll ever pay off enough to be worth the time we’re putting into them.
You ask Erica how requests for new integrations are being processed, and she shows you a tiny form on the customer dashboard that says, “Don’t see your local classified ad provider? Let us know and we’ll try to support it soon!”
Erica explains that this form generates many requests, but the team is struggling to fulfill them because the effort to integrate each service is highly variable. Sometimes there are web-based APIs that are easy to work with, and other times an “integration” can be made up of an ad hoc email report, a spreadsheet uploaded to an ancient FTP server, or even a text document delivered to a fax machine.
The word fragile does not even begin to describe TagSail’s classified ad network support, but the sales team is (somehow?) convinced that taking on that pain so customers don’t have to will pay off in the end. Suspecting that there is something not quite right here, you start to dig a bit deeper.
Pay attention to the economic tradeoffs of your work
For many phenomena, 20% of invested input is responsible for 80% of the results obtained.
Pareto Principle
You spend a few minutes reviewing the project’s issue tracker. It turns out that new requests for integrations are flowing in five times faster than the existing requests are being closed. When you add in bug reports, the ratio is actually closer to 8:1.
These are bad numbers because it means most requests sit indefinitely in limbo and the backlog keeps growing and growing. Left unchecked, this will become an even greater maintenance headache than it already is.
There is a clear process problem with how classified ad integrations are being handled, but its relative severity depends on how much the work is (or isn’t) paying off for the company. You ask a few more questions to get a more complete picture:
You: What is the business model for ad network integrations?
Erica: We bill the customer for whatever the external costs of running the ad are, in addition to the base cost for listing their yard sale on our own website.
You: So in other words, these integrations don’t provide direct revenue themselves; they are just one of the benefits offered to customers?
Erica: That’s correct. And honestly, we didn’t originally plan to roll this out nation-wide. We initially integrated with a single major provider in New England. We were hoping that might get us some publicity and attract new paying customers, and it managed to do both. But we didn’t have much of a plan for where to take things next, and the requests started flowing in.
You: Then let me guess: the sales team got excited by the early results and made a push toward supporting as many integrations as possible?
Erica: Yep, and without really talking with us about it. The first integration was built in a single day and was able to serve dozens of cities; it didn’t occur to them that future integrations may take a lot longer than that to serve a much smaller market.
You: I think I’m beginning to see the problem here.
With Erica’s help, you do a tiny bit of market research. You dig up a statistical report,1 which claims that the average number of yard sales in the United States per week is around 165,000 and that the leading online classified site posts around 95,000 listings per week for the whole country.
Erica runs a quick query against TagSail’s data to find that they’re posting roughly 15,000 listings per week, which is just shy of 10% of the nationwide average.
Of the customers posting those listings, about half of them have access to at least one classified integration. In that group, about one in eight opt into paying the extra fees associated with getting their ads listed in their local newspaper and online news sites. That breaks down to an average of roughly 1,000 total listings per week that make use of the classified integrations feature.
You then ask Erica to break down the average number of listings per integration. From the raw data she comes up with, you produce the following graph:
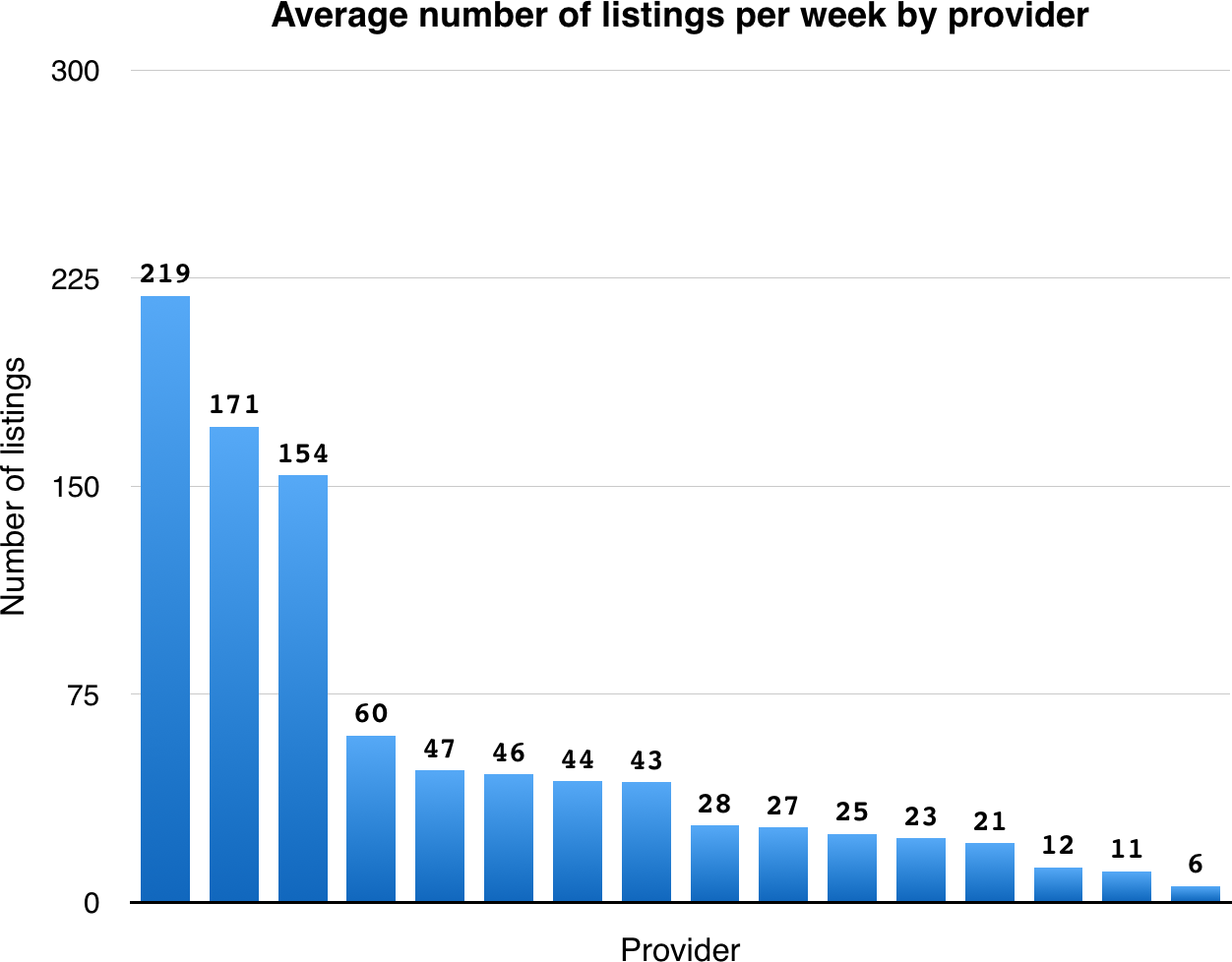
The story makes sense in hindsight, but it’s an uncomfortable thing to think about: almost three in five classified ads are handled by the top three integrations, and the bottom 50% of the integrations handle only a little more than 15% of the listings. With relatively few customers using the integrations to begin with, supporting these less popular services is effectively a total waste of time for the development team.
You encourage Erica to report these findings to Jen, the head of the product team. She hesitates, doubting that her concerns will be considered because they go against a priority of the sales team. But when you point out that neither the product team nor the sales team has access to the data that was used to generate this new report, Erica warms up to the idea that she might be taken seriously this time around.
Jen and Erica get together to discuss the problem while you listen in and act as a moderator. Once there is some basic agreement that a huge portion of the integrations work is mostly going to waste, you lay out some concrete suggestions on how to bring things back into balance:
-
Focus support efforts on the eight most popular integrations, which cover 83.6% of all listings per week on average.
-
Set a fixed limit on capacity (say 20% to start with) that can be allocated to work on integrations each month. If the team goes over this limit, report back to the product team so they can revise their plans accordingly.
-
Audit the eight less popular integrations and decide what level of support to offer for them, if any. Those that are working with very low maintenance overhead could possibly be kept around, but the high-cost integrations could be gradually phased out.
-
Work with the product team to evaluate potential market sizes and cost of implementing and maintaining integrations before adding more ad networks. Make sure that it’s clear that any time spent on integrations is time not spent on other potentially valuable work.
-
Make it clear to customers that there is no guarantee that new classified ad providers will be supported, and consider removing the request form entirely.
-
As the integrations workload stabilizes, invest in proactive maintenance measures like better monitoring, logging, analytics, and testing. Prioritize work on these preventative measures based on experienced pain points rather than theoretical future needs.
The purpose of this plan is to put an upper limit on the amount of effort that can be invested in developing an area of the application that’s producing diminishing returns. Although often overlooked, simple time budgeting is a powerful tool for limiting the impact of the high-risk areas of a project, and also encourages more careful prioritization and cost-benefit analysis.
If even some of these changes materialize, life should get a whole lot easier for the development team while also freeing up a large amount of time to focus on more productive work.
Reduce waste by limiting work in progress
Four weeks pass, and then you join the TagSail team again to see how things are going. Your first question is whether or not they’ve managed to get the issues around classified ad integrations under control, and Erica is happy to report that they seem to have gotten that area of the product to finally settle down.
You then ask what new improvements they’ve shipped since your last visit, and Erica lamentingly tells you: not much, unless you count bug fixes, chores, and internal code cleanup. You pull yourself together after a moment of uncomfortable silence and start to dig in:
You: I don’t understand. Didn’t you free up about 30% of the team’s capacity and also radically reduce unplanned urgent work since the last time we talked?
Erica: Yes, but as soon as the product team saw that we were no longer putting out fires every day, they began to pile on new work to make use of our newfound capacity.
They seem obsessed with the idea of “catching up” with the roadmap we created before we ran into growing pains, and that has us back in a tough spot again.
You: So what’s happening? Is work being rushed out the door before it’s ready just to make room for the next set of tasks?
Erica: Nope, that’s not it. What’s happening is new work is being planned and assigned every week, but the product team is very slow to respond to our questions and sign off on finished work so we can ship it. We’re also running behind on our own internal code reviews and QA testing, because the whole team is opening pull requests much faster than we can close them.
You: Believe it or not, this is a sign of progress. Removing one bottleneck in a process will naturally cause another one to become visible,2 and it seems like the new constraint is how fast work can be reviewed and approved before it is released. Finding the right cadence and sticking to it will take some effort, but once that’s taken care of, you should start to see some real forward momentum.
Erica: If you mean asking the product team to reduce the amount of new work they assign per week, that’s going to be a non-starter. They have commitments to uphold the hectic schedule they’d put in place when we were trying to go for a new funding round, and so there is a ton of pressure all around to deliver new work quickly.
You: But work that is stuck in code review isn’t delivered yet, and neither is work that sits around in a queue for days or weeks waiting to be approved by a product manager before it can be shipped. You can have a hundred improvements in a work-in-progress state, but the only thing generating value is the stuff that ships.
Erica: I agree, but how can we get the product team to change their approach?
You: It’s simple if not easy: we need them to establish the mindset that unshipped code is not an asset, it’s inventory. Moreover, it’s perishable inventory with a cost of carry.
Erica had explained this problem to the product team before, but she approached it from a different angle. She emphasized the harmful costs of context switching, and the stressful feeling of starting new things before finishing existing tasks.
You point out that while those are completely valid concerns, it’s better to frame the conversation in terms of the negative impact on the team’s ability to deliver new valuable work to customers. To find evidence to support this point, you ask Erica to show you the team’s Kanban board:
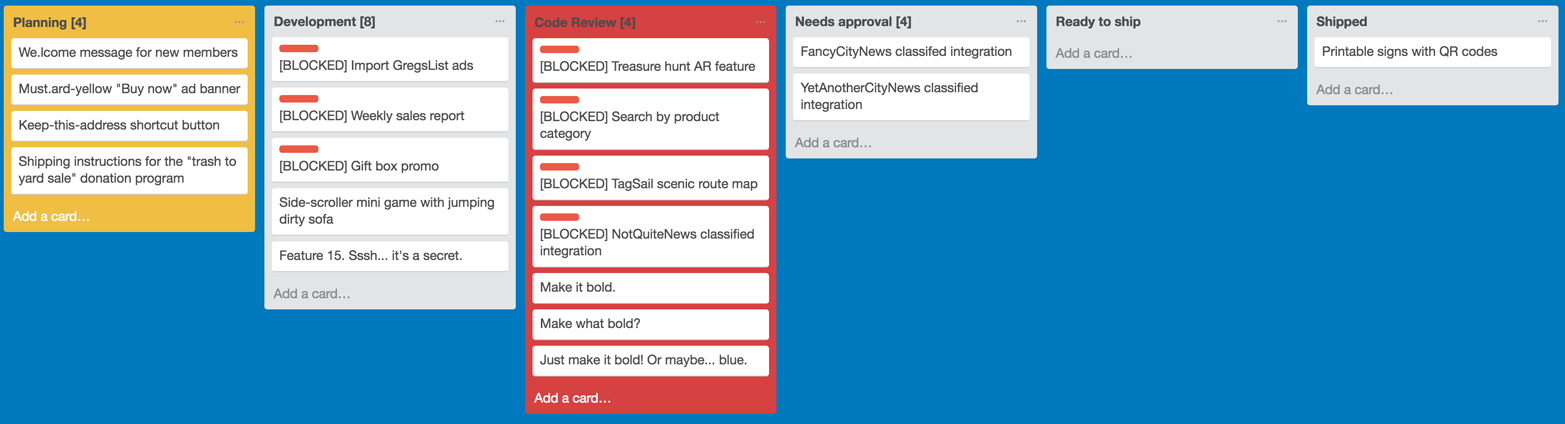
Almost immediately, you notice the right side (which represents deliverable and delivered work) is nearly empty, while the left and center sections (which represent planned work and work in progress) are richly populated. There are also many blocked tasks, which—if unblocked all at once—would cause severe overload.
To solve this problem, you will need to talk to Jen, who is responsible for deciding what gets worked on each week. Erica gets her on the phone and listens in as you try to talk through the critical disconnect between the planning rate and delivery rate on the project:
You: A few weeks ago we made some changes that I hoped would have sped up progress, but from what Erica tells me things still aren’t moving all that smoothly. How does it look from your perspective?
Jen: Good in some ways and bad in others. A good thing is that the developers seem to be less overwhelmed with urgent bug fixes lately, so they’re focused on productive work now. But there is still a ton of pressure from the CEO and our investors to rapidly grow the product, and many of our partnerships are hanging in the balance right now.
You: The main problem for the development team is that new work is being piled on before they have a chance to ship or even finish their current tasks, and from what I can tell, they seem to be making a reasonable complaint.
The last significant customer-facing improvement was completed six weeks ago, and currently there are two new features waiting to be signed off on. But there are twelve features in a work-in-progress state, and four more are being planned!
Jen: I know, it’s a big mess. What can we do about it?
You: Well, how many new pieces of functionality can you realistically release per week?
Jen: Our original roadmap called for one major improvement along with 2–3 minor improvements per week. The plan was to send out an email newsletter every Tuesday to announce the changes and show people how to use them.
You: That seems reasonable on paper, but new work is being planned much faster than it is getting shipped. As a result, you’re accumulating work in progress, and much of it is blocked on feedback. The overall flow rate is what matters, and when you have much more flowing into the system than out of it, that’s how things get overloaded.
Jen: I see what you’re getting at. Part of the problem is that we’re expected to keep the developers busy. That means that whenever there’s an open slot on the Kanban board, it’s a signal to us to sit down with a developer and plan a new feature. Now that they’re moving a little bit faster, this is actually taking up a fair amount of our time.
You: Why not use that time to help unblock the developers who have questions or need approval? Wouldn’t that help make sure they stay productive and also lead to more work getting shipped, sooner?
Jen: If I could make those decisions on my own, I absolutely would. But few questions the developers ask are ones that I can answer directly; some require conversations with the sales team, others involve customer research, others require talking to vendors and partners, and for some I even need to sit down with the CEO and talk them through.
Unfortunately, sometimes a question that only takes ten minutes for the right person to answer can take a week or more to get a response.
You: OK, I understand the problem now. You’re trying to stick to a development pace that is faster than your feedback bottleneck.
This never works, so we either need to slow down the release cadence, reduce the batch sizes of the work being done, or speed up the feedback loops. I’d recommend some combination of all three for best results.3
There is some initial resistance to the idea, but after a lengthy meeting with the CEO, you and Jen come out with a plan that seems almost too good to be true:
-
Put a hold on planning new major features for four weeks to allow some of the current work in progress to be wrapped up and delivered.
-
Change to a release cycle of one new major feature every two weeks, with the first new release planned for four weeks from now.
-
Release minor improvements on a rolling basis, rather than allowing them to block or be blocked by the newsletter announcements.
-
Gradually build up a backlog of up to five release-ready features to serve as a buffer for when a current major work in progress is blocked.
-
Once that buffer is built up, synchronize planning with the release schedule so that a newly released (or canceled) feature is what triggers the planning of a new major improvement, rather than trying to max out available developer capacity.
-
Review the product roadmap and cut it in half. Involve both the sales team and the developers in this process to know the costs and benefits of the revised plan.
-
Block off four hours company-wide on Monday mornings for coordination time. During this time, no one will be expected to do heads-down work or attend formal meetings; instead, the entire time period will be used for helping anyone who is blocked get unblocked.
The overall goal is to give the entire organization a bit of room to breathe. By letting backed-up work make its way out the door before cramming in just one more thing, a more natural and stable rhythm of work will hopefully emerge.
That said, this plan is just a starting point, and you make it clear that Jen and Erica can expect it to be challenging at times to keep the whole company committed to it. For that reason, you’ve suggested running it as a twelve-week experiment to start with, and seeing how things go from there.
Make the whole greater than the sum of its parts
Three months go by like a flash. As you predicted, it hasn’t been easy for everyone to stick to the plan, and there have been times where some team members have been tempted to go back to their old way of doing things. But they’ve reluctantly stayed on course, and some of your ideas have definitely paid off.
To help you get a sense of how things went over the last twelve weeks, the CEO requested that each department come up with “a rose, a bud, and a thorn” to sum up the last few months of work.
The roses represents good things that have happened, the buds reflects things that look promising, and the thorns are pain points:
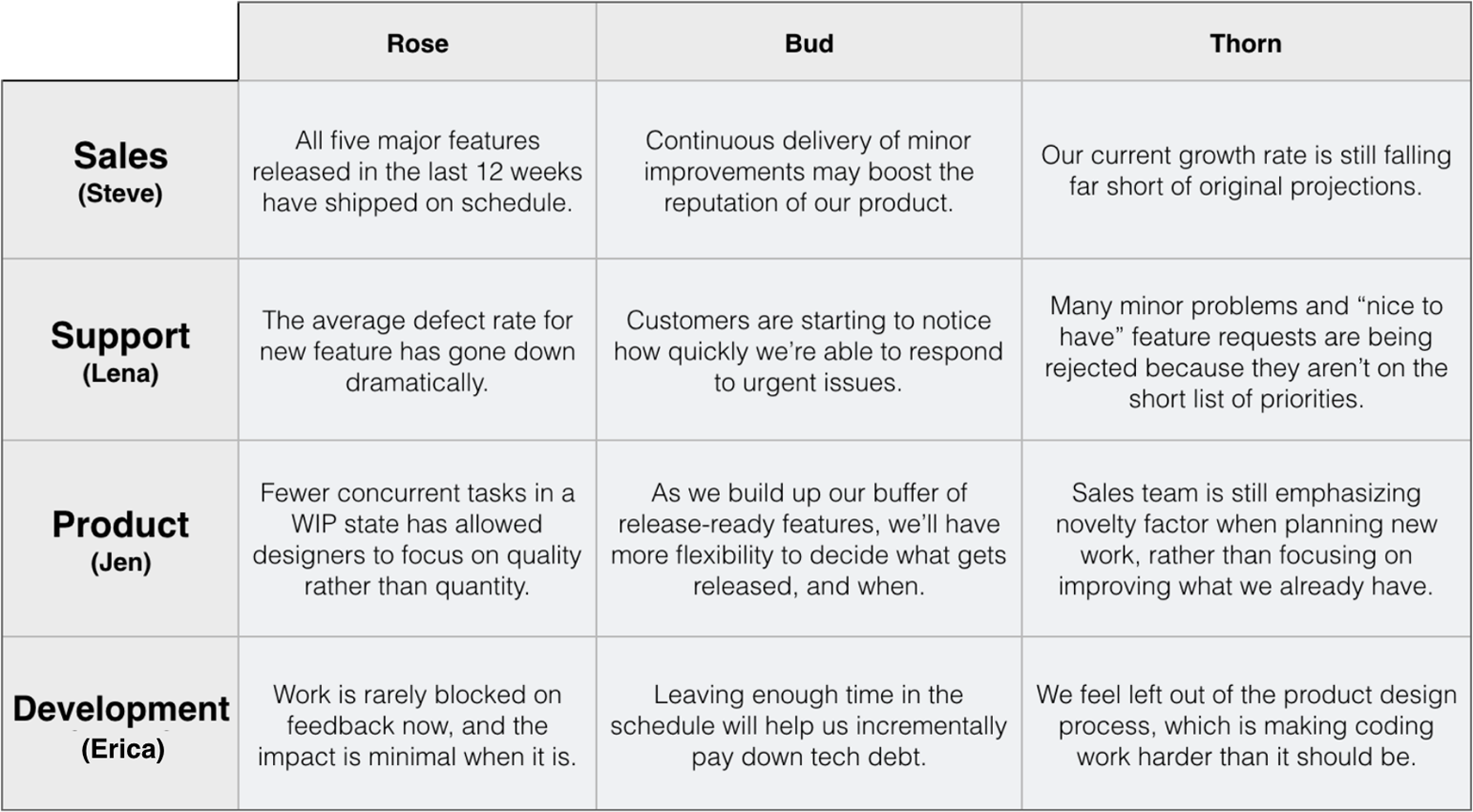
This may be the first time the organization has created a high-level view of how decisions affect everyone as a whole in spite of frequently holding inter-departmental meetings in the past. The fact that they’re doing this exercise at all is a sign of better collaboration within the company, even if there are many problems still left to be resolved.
The four department leads begin an uneasy conversation about each other’s thorns, but it soon begins to feel like they’re talking past each other. You calmly suggest that they take a short break before continuing the discussion.
When they return, you ask each person to write down a brief explanation of “why it hurts” for each of their pain points. You then present all of their responses side by side, so that they can see their own concerns in the context of the bigger picture:
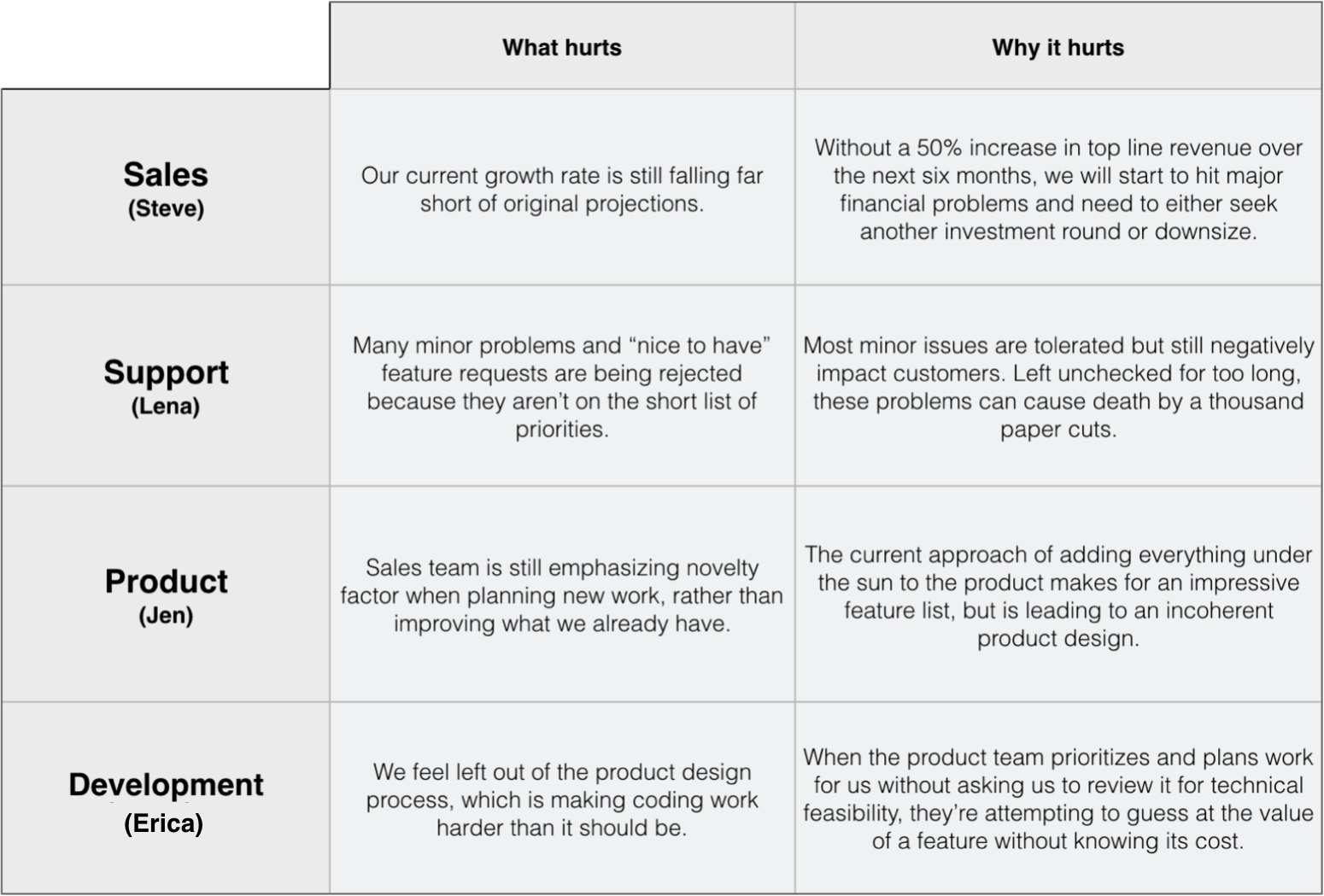
The discussion picks back up again, but this time around you volunteer to moderate things to make sure that the group stays focused:
You: I’d like to start with Steve’s concern, because it’s the elephant in the room. The product is making money, but it’s not cashflow positive—let alone profitable. With over 20 people on staff here, that’s a scary problem and one that needs to be on the top of everyone’s minds.
Jen: This is the first time I’ve seen Steve explain this in terms of runway rather than projected revenue growth. I think everyone in the company is able to understand the former, whereas the latter seems abstract.
Erica: I don’t know, I’m not sure how the developers on my team would be if I told them, “In six months some of you may be out of work if we can’t turn this thing around at a breakneck pace.”
Lena: I agree, and I’m sure that people from the support team would be first to go, should we need to downsize. This is terrible news.
Steve: Unfortunately, the sales team isn’t responsible for defining a reasonable growth rate; we’re tasked with trying to hit the numbers that the CEO and the company’s investors have laid out for us. We’re staffed for a growth curve that’s much steeper than our actual results can justify, and it’s been that way for a few months now.
You: But doesn’t that mean that the product roadmap is also tracking based on an assumed growth curve that just isn’t there? In other words, are we applying a “go big or go home” strategy when we don’t have the resources to pull that off?
Steve: Well, I guess you can say that. The reason is because 50% growth over six months is just the bare minimum we’d need to keep extending our runway rather than shrinking it. To make our investors happy, we’d need to hit something like 150% revenue growth over the next 180 days.
You: Let’s assume for the sake of argument that there’s no reasonable way to get within striking distance of that goal. If you cut those projections in half, would it allow you to shift the focus to selling what is already built for a while rather than gambling on new major features?
Steve: We’d need to get approval from the CEO, but it may be worth trying for a couple months. But we’d also need to prove that the approach is working with hard numbers.
You point out to all the non-sales people in the room that in a business that’s not profitable yet, cash is oxygen—things go bad quickly when it runs out. It’s not a pleasant thing to think about, but forgetting it is how you go out of business.
At the same time, the financial success of the product is directly tied to how well the staff as a whole can work together. Building a better, more cohesive product means balancing the needs of everyone involved in its development, without emphasizing the needs of one team over the others.
Taking into account everything that was revealed in the “roses, buds, and thorns” exercise, you help the group come up with a plan that will help them stay aligned with one another as they go through the next few months of critical work on the product:
-
Build a new dashboard that lays out the core AARRR metrics (Acquisition, Activation, Retention, Revenue, Referral) that are essential to any business. Having everyone look at the same reports, and training the entire staff on how to read them, will make it easier to get a sense of overall product health at a glimpse.
-
Figure out where the AARRR pipeline bottleneck is and then have all teams work together to try out experiments that might help move the needle in that area. Start with incremental improvements, and gradually work up to more substantial changes as needed.
-
Do an all-hands meeting to review the product onboarding process, both for visitors looking for yard sales, and customers posting listings. Have each employee take notes on any areas that can be improved.
-
Look to see if any issues noticed during the onboarding walkthrough overlap with existing support tickets or items on the product roadmap. Prioritize those for fixing in the near future, and then use the AARRR metrics to measure impact.
-
Set aside one day per week for a single developer to work on “small stuff” that the support team feels is worth fixing. Rotate this position each week so that all developers can get some experience with responding to support issues.
-
Schedule time for as much cross-training as possible. Developers and product designers should sit in on sales calls, sales people should attend some project planning meetings, and everyone in the company should spend at least an hour per month doing front-line customer support.
-
Identify three features within the next eight weeks that can either be removed from the product or significantly simplified. Specifically target the features that appear out of place in the context of the product as a whole.
The common thread that ties each of these individual actions together is a simple piece of advice: know enough about what everyone else is doing to be able to see how your own actions fit into the bigger picture.
After discussing this plan, the group expresses a fair amount of optimism about the coming months. There’s no guarantee of success, but with a common understanding of the problems at hand, they’re far more aligned than they were just days ago.
With a dramatic tone you say, “My work here is done,” and then ride off into the sunset. As for everyone else, their work has just begun.
1 In case you are curious, here is the real statistical report that forms the backdrop for this made-up story.
2 For more on this concept, research Eli Goldratt’s Theory of Constraints.
3 Donald Reinertsen’s The Principles of Product Development Flow (Celeritas Publishing, 2009) is an excellent (if abstract) read on this topic.