
2.8 Syntactic Ambiguity
The following parse, although different from that in Section 2.7, proves precisely the same result—that the string is a sentence.
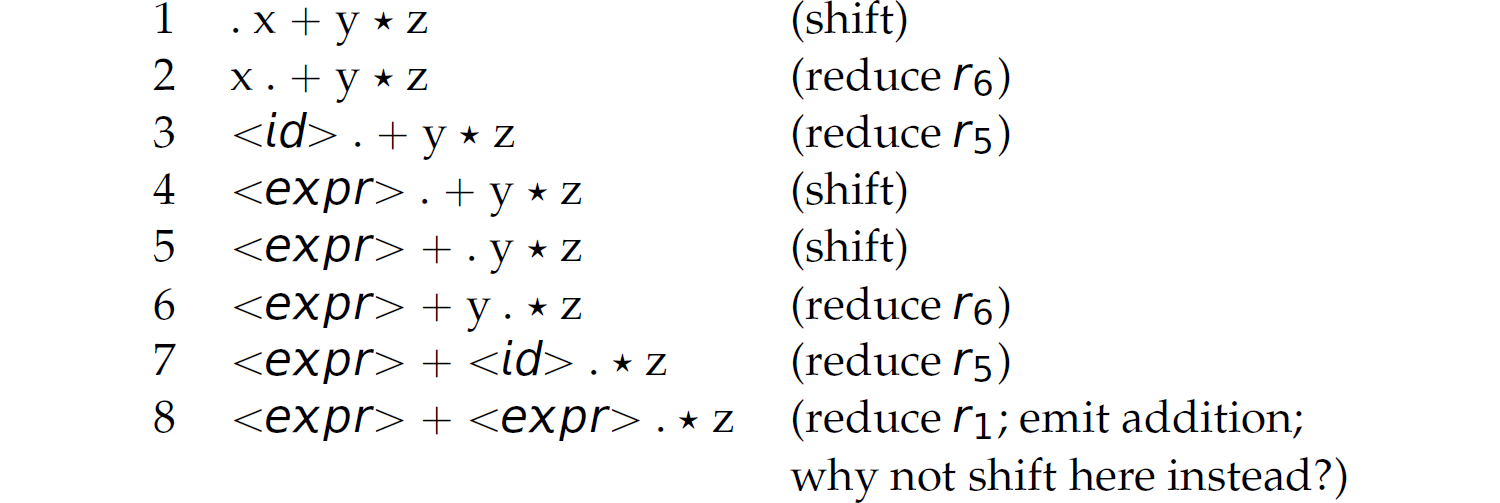

Which of these two parses is preferred? How can we evaluate which is preferred? On what criteria should we evaluate them? The short answer to these questions is: It does not matter. The objective of language recognition and parsing is to determine if the input string is a sentence (i.e., does its structure conform to the grammar). Both of these parses meet that objective; thus, with respect to syntax, they both equally meet the objective. Here, we are only concerned with the syntactic validity of the string, not whether it makes sense (i.e., semantic validity). Parsing deals with syntax rather than semantics.
However, parsers often address issues of semantics with techniques originally intended only for addressing syntactic validity. One reason for this is that, unfortunately, unlike for syntax, we do not have formal models of semantics that are easily implemented in a computer system. Another reason is that addressing semantics while parsing can obviate the need to make multiple passes through the input string. While formal systems help us reason about concepts such as syntax and semantics, programming language systems implemented based on these formalisms must address practical issues such as efficiency. (Certain types of parsers require the production rules of the grammar of the language of the sentences they parse to be in a particular form, even though the same language can be defined using production rules in multiple forms. We discuss this concept in Chapter 3.) Therefore, although this approach is considered impure from a formal perspective, sometimes we address syntax and semantics at the same time (Table 2.6).
Table 2.6 Formal Grammars Vis-à-Vis BNF Grammars
|
A formal grammar defines only the syntax of a formal language. A BNF grammar defines the syntax of a programming language, and some of its semantics as well. |
2.8.1 Modeling Some Semantics in Syntax
One way to gently introduce semantics into syntax is to think of syntax implying semantics as a desideratum. In other words, the form of an expression or command (i.e., its syntax) should provide some clue as to its meaning (i.e., semantics). A complaint against UNIX systems vis-à-vis systems with graphical user interfaces is that the form (i.e., syntax) of a UNIX command does not imply the meaning (i.e., semantics) of the command (e.g.,  ). The idea of integrating semantics into syntax may not seem so foreign a concept. For instance, we are taught in introductory computer programming courses to use identifier names that imply the meaning of the variable to which they refer (e.g.,
). The idea of integrating semantics into syntax may not seem so foreign a concept. For instance, we are taught in introductory computer programming courses to use identifier names that imply the meaning of the variable to which they refer (e.g.,  ).
).
Here we would like to infuse semantics into parsing in an identifiable way. Specifically, we would like to evaluate the expression while parsing it. This helps us avoid making unnecessary passes over the string if it is a sentence. Again, it is important to realize we are shifting from the realm of syntactic validity into interpretation. The two should not be confused, as they serve different purposes. Determining if a string is a sentence is completely independent of evaluating it for a return value. We often subconsciously impart semantics onto an expression such as 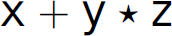 because without any mention of meaning we presume it is a mathematical expression. However, it is simply a string conforming to a syntax (i.e., form) and can have any interpretation or meaning we impart to it. Indeed, the meaning of the expression
because without any mention of meaning we presume it is a mathematical expression. However, it is simply a string conforming to a syntax (i.e., form) and can have any interpretation or meaning we impart to it. Indeed, the meaning of the expression 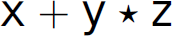 could be a list of five elements.
could be a list of five elements.
Thus, in evaluating an expression while parsing it, we are imparting knowledge of how to interpret the expression (i.e., semantics). Here, we interpret these sentences as standard mathematical expressions. However, to evaluate these mathematical expressions, we must adopt even more semantics beyond the simple interpretation of them as mathematical expressions. If they are mathematical expressions, to evaluate them we must determine which operators have precedence over each other [i.e., is 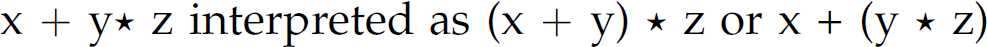 ] as well as the order in which each operator associates [i.e., is
] as well as the order in which each operator associates [i.e., is 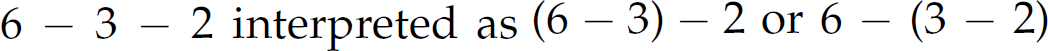 ?]. Precedence deals with the order of distinct operators (e.g., * computes before +), while associativity deals with the order of operators with the same precedence (e.g., – associates left-to-right).
?]. Precedence deals with the order of distinct operators (e.g., * computes before +), while associativity deals with the order of operators with the same precedence (e.g., – associates left-to-right).
Formally, a binary operator ⊕ on a set S is associative if 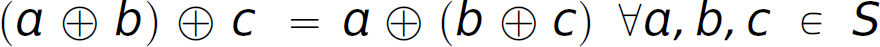 . Intuitively, associativity means that the value of an expression containing more than one instance of a single binary associative operator is independent of evaluation order as long as the sequence of the operands is unchanged. In other words, parentheses are unnecessary and rearranging the parentheses in such an expression does not change its value.
. Intuitively, associativity means that the value of an expression containing more than one instance of a single binary associative operator is independent of evaluation order as long as the sequence of the operands is unchanged. In other words, parentheses are unnecessary and rearranging the parentheses in such an expression does not change its value.
Notice that both parses of the expression 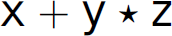 are the same until line 8, where a decision must be made to shift or reduce. The first parse shifts while the second reduces. Both lead to successful parses. However, if we evaluate the expression while parsing it, each parse leads to different results. One way to evaluate a mathematical expression while parsing it is to emit the mathematical operation when reducing. For instance, in step 12 of the first parse, when we reduce
are the same until line 8, where a decision must be made to shift or reduce. The first parse shifts while the second reduces. Both lead to successful parses. However, if we evaluate the expression while parsing it, each parse leads to different results. One way to evaluate a mathematical expression while parsing it is to emit the mathematical operation when reducing. For instance, in step 12 of the first parse, when we reduce 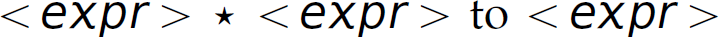 , we can compute
, we can compute ![]() . Similarly, in step 13 of that same parse, when we reduce
. Similarly, in step 13 of that same parse, when we reduce 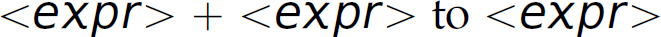 , we can compute
, we can compute 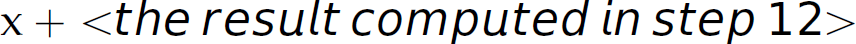 . This interpretation [i.e.,
. This interpretation [i.e., 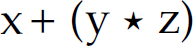 ] is desired because in mathematics multiplication has higher precedence than addition. Now consider the second parse. In step 8 of that parse, when we (prematurely) reduce
] is desired because in mathematics multiplication has higher precedence than addition. Now consider the second parse. In step 8 of that parse, when we (prematurely) reduce 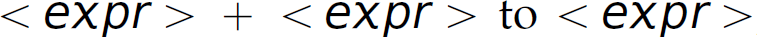 , we compute
, we compute 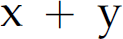 . Then in step 13, when we reduce
. Then in step 13, when we reduce 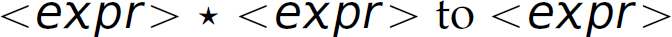 , we compute
, we compute 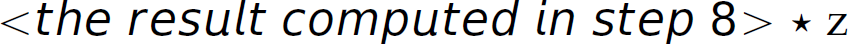 . This interpretation [i.e.,
. This interpretation [i.e., 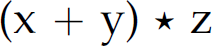 ] is obviously not desired. If we shift at step 8, multiplication has higher precedence than addition (desired). If we reduce at step 8, addition has higher precedence than multiplication (undesired). Therefore, we prefer the first parse. These two parses exhibit a shift-reduce conflict. If we shift at step 8, then multiplication has higher precedence than addition (which is the desired semantics). If we reduce at step 8, then addition has higher precedence (which is the undesired semantics).
] is obviously not desired. If we shift at step 8, multiplication has higher precedence than addition (desired). If we reduce at step 8, addition has higher precedence than multiplication (undesired). Therefore, we prefer the first parse. These two parses exhibit a shift-reduce conflict. If we shift at step 8, then multiplication has higher precedence than addition (which is the desired semantics). If we reduce at step 8, then addition has higher precedence (which is the undesired semantics).
The possibility of a reduce-reduce conflict also exists. Consider the following grammar:
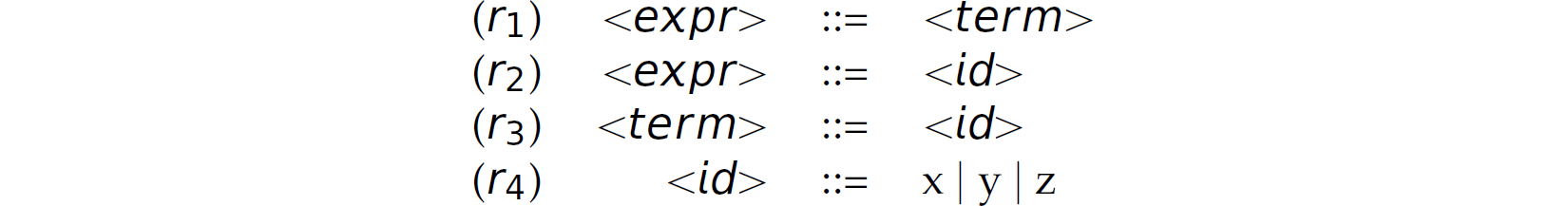
and a bottom-up parse of the expression x:
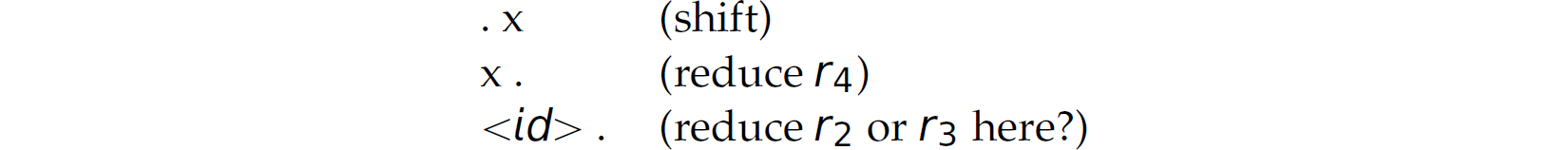
2.8.2 Parse Trees
The underlying source of shift-reduce and reduce-reduce conflicts is an ambiguous grammar. A grammar is ambiguous if there exists a sentence that can be parsed in more than one way. A parse of a sentence can be graphically represented using a parse tree. A parse tree is a tree whose root is the start symbol of the grammar, non-leaf vertices are non-terminals, and leaves are terminals, where the structure of the tree represents the conformity of the sentence to the grammar. A parse tree is fully expanded. Specifically, it has no leaves that are non-terminals and all of its leaves are terminals that, when collected from left to right, constitute the expression whose parse it represents. Thus, a grammar is ambiguous if we can construct more than one parse tree for the same sentence from the language defined by the grammar. Figure 2.3 gives parse trees for the expression 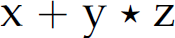 derived from the four-function calculator grammar in Section 2.6. The left tree represents the first parse and the right tree represents the second parse. The existence of these trees proves that the grammar is ambiguous. The last grammar in Section 2.8.1 is also ambiguous; a proof of ambiguity exists in Figure 2.4, which contains two parse trees for the expression x.
derived from the four-function calculator grammar in Section 2.6. The left tree represents the first parse and the right tree represents the second parse. The existence of these trees proves that the grammar is ambiguous. The last grammar in Section 2.8.1 is also ambiguous; a proof of ambiguity exists in Figure 2.4, which contains two parse trees for the expression x.
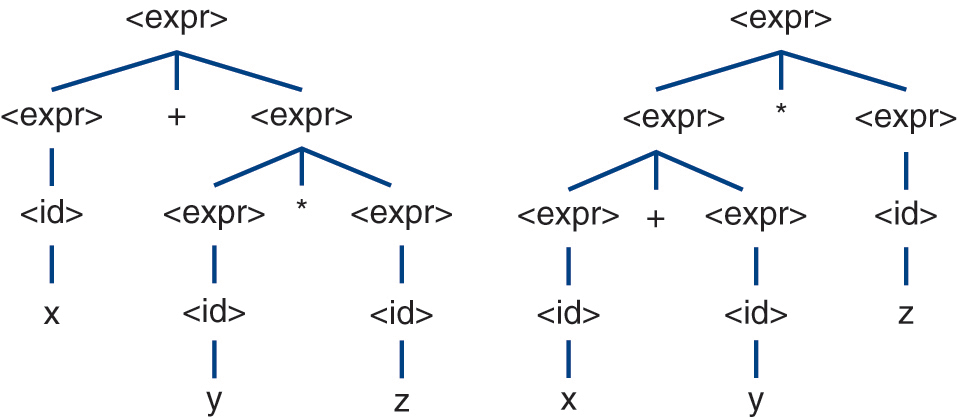
Figure 2.3 Two parse trees for the expression x + y * z.
Description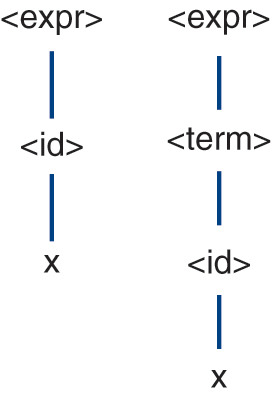
Figure 2.4 Parse trees for the expression x.
DescriptionAmbiguity is a term used to describe a grammar, whereas a shift-reduce conflict and a reduce-reduce conflict are phrases used to describe a particular parse. However, each concept is a different side of the same coin. If a grammar is ambiguous, a bottom-up parse of a sentence in the language the grammar defines will exhibit either a shift-reduce or reduce-reduce conflict, and vice versa.
Thus, proving a grammar is ambiguous is a straightforward process. All we need to do is build two parse trees for the same expression. Much more difficult, by comparison, is proving that a grammar is unambiguous.
It is important to note that a parse tree is not a derivation, or vice versa. A derivation illustrates how to generate a sentence. A parse tree illustrates the opposite—how to recognize a sentence. However, both prove a sentence is in a language (Table 2.7). Moreover, while multiple derivations of a sentence (as illustrated in Section 2.6) are not a problem, having multiple parse trees for a sentence is a problem—not from a recognition standpoint, but rather from an interpretation (i.e., meaning) perspective. Consider Table 2.8, which contains four sentences from the four-function calculator grammar in Section 2.6. While the first sentence 132 has multiple derivations, it has only one parse tree (Figure 2.5) and, therefore, only one meaning. The second expression, 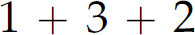 , in contrast, has multiple derivations and multiple parse trees. However, those parse trees (Figure 2.6) all convey the same meaning (i.e., 6). The third expression,
, in contrast, has multiple derivations and multiple parse trees. However, those parse trees (Figure 2.6) all convey the same meaning (i.e., 6). The third expression, 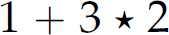 , also has multiple derivations and parse trees (Figure 2.7). However, its parse trees each convey a different meaning (i.e., 7 or 8). Similarly, the fourth expression,
, also has multiple derivations and parse trees (Figure 2.7). However, its parse trees each convey a different meaning (i.e., 7 or 8). Similarly, the fourth expression, 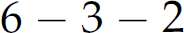 , has multiple derivations and parse trees (Figure 2.8), and those parse trees each have different interpretations (i.e., 1 or 5). The last three rows of Table 2.8 show the grammar to be ambiguous even though the ambiguity manifested in the expression
, has multiple derivations and parse trees (Figure 2.8), and those parse trees each have different interpretations (i.e., 1 or 5). The last three rows of Table 2.8 show the grammar to be ambiguous even though the ambiguity manifested in the expression 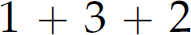 is of no consequence to interpretation. The third expression demonstrates the need for rules establishing precedence among operators, and the fourth expression illustrates the need for rules establishing how each operator associates (left-to-right or right-to-left).
is of no consequence to interpretation. The third expression demonstrates the need for rules establishing precedence among operators, and the fourth expression illustrates the need for rules establishing how each operator associates (left-to-right or right-to-left).
Table 2.7 The Dual Use of Grammars: For Generation (Constructing a Derivation) and Recognition (Constructing a Parse Tree)
|
A derivation |
generates |
a sentence in a formal language. |
|
A parse tree |
recognizes |
a sentence in a formal language. |
|
Both |
prove |
a sentence is in a formal language. |
Table 2.8 Effect of Ambiguity on Semantics
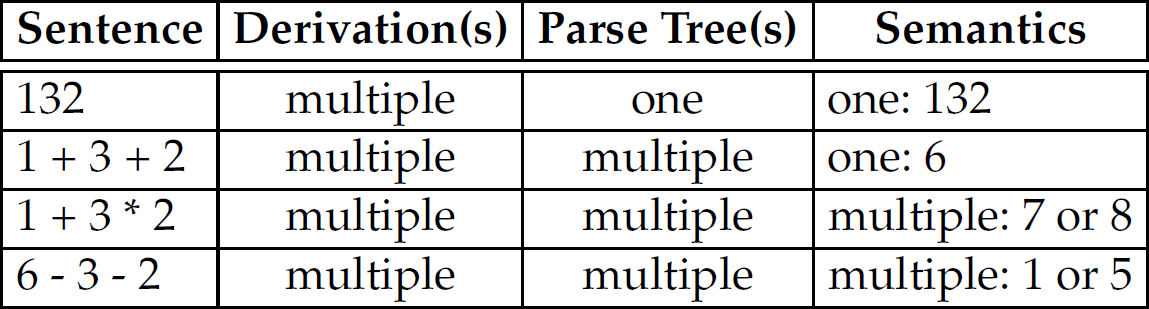
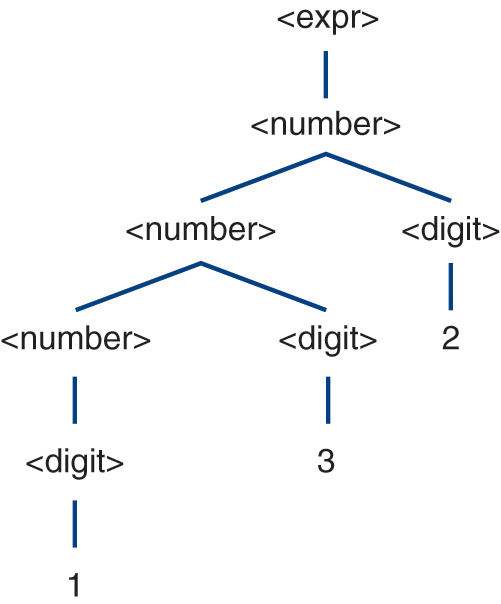
Figure 2.5 Parse tree for the expression 132.
Description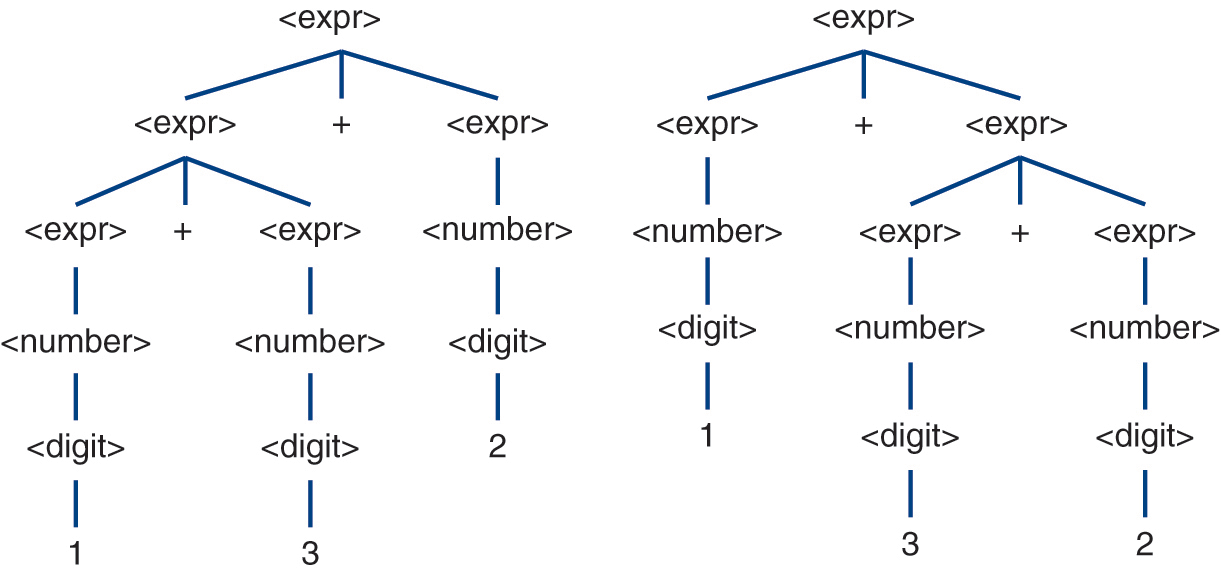
Figure 2.6 Parse trees for the expression 1 + 3 + 2.
Description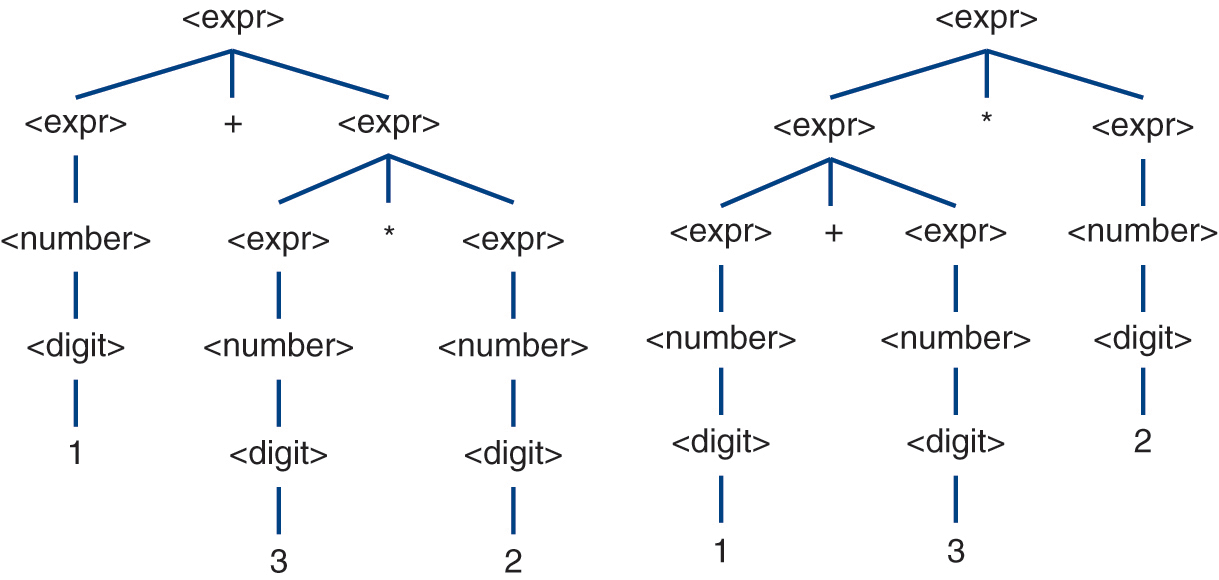
Figure 2.7 Parse trees for the expression 1 + 3 * 2.
Description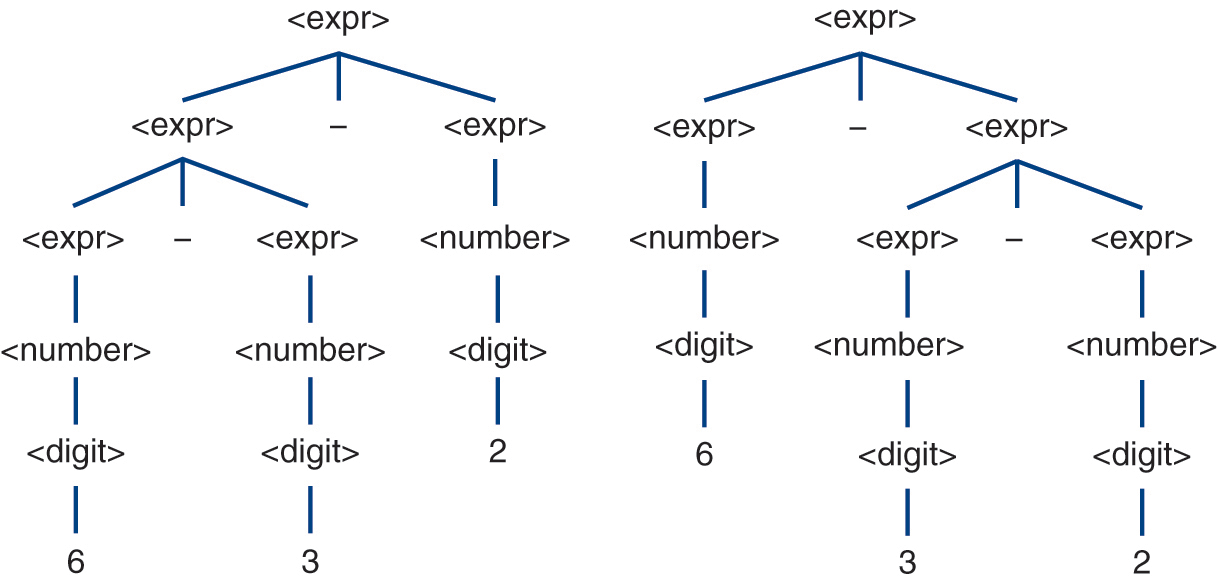
Figure 2.8 Parse trees for the expression 6 – 3 – 2.
DescriptionBear in mind, that we are addressing semantics using a formalism intended for syntax. We are addressing semantics using formalisms and techniques reserved for syntax primarily because we do not have easily implementable methods for dealing with context, which is necessary to effectively address semantics, in computer systems. By definition, context-free grammars are not intended to model context. However, the semantics we address through syntactic means—namely, precedence and associativity—are not dependent on context. In other words, multiplication does not have higher precedence than addition in some contexts and vice versa in others (though it could, since we are defining the language6). Similarly, subtraction does not associate left-to-right in some contexts and right-to-left in others. Therefore, all we need to do is make a decision for each and implement the decision.
Typically semantic rules such as precedence and associativity are specified in English (in the absence of formalisms to encode semantics easily and succinctly) in the programming manual of a particular programming language (e.g., * has higher precedence than + and – associates left-to-right). Thus, English is one way to specify semantic rules. However, English itself is ambiguous. Therefore, when the ambiguity—in the formal language, not English—is not dependent on context, as in the case here with precedence and associativity, we can modify the grammar so that the ambiguity is removed, making the meaning (or semantics) determinable from the grammar (syntax). When ambiguity is dependent on context, grammar disambiguation to force one interpretation is not possible because you actually want more than one interpretation, though only one per context. For instance, the English sentence “Time flies like an arrow” can be parsed multiple ways. It can be parsed to indicate that there are creatures called “time flies,” which really like arrows (i.e., 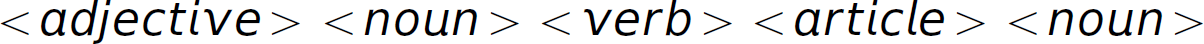 ), or metaphorically (i.e.,
), or metaphorically (i.e., 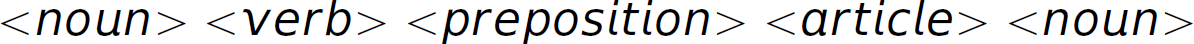 ). English is a language with an ambiguous grammar. How can we determine intended meaning? We need the surrounding context provided by the sentences before and after this sentence. Consider parsing the sentence “Mary saw the man on the mountain with a telescope.”, which also has multiple interpretations corresponding to the different parses of it. This sentence has syntactic ambiguity, meaning that the same sentence can be diagrammed (or parsed) in multiple ways (i.e., it has multiple syntactic structures). “They are moving pictures.” and “The duke yet lives that Henry shall depose.”7 are other examples of sentences with multiple interpretations.
). English is a language with an ambiguous grammar. How can we determine intended meaning? We need the surrounding context provided by the sentences before and after this sentence. Consider parsing the sentence “Mary saw the man on the mountain with a telescope.”, which also has multiple interpretations corresponding to the different parses of it. This sentence has syntactic ambiguity, meaning that the same sentence can be diagrammed (or parsed) in multiple ways (i.e., it has multiple syntactic structures). “They are moving pictures.” and “The duke yet lives that Henry shall depose.”7 are other examples of sentences with multiple interpretations.
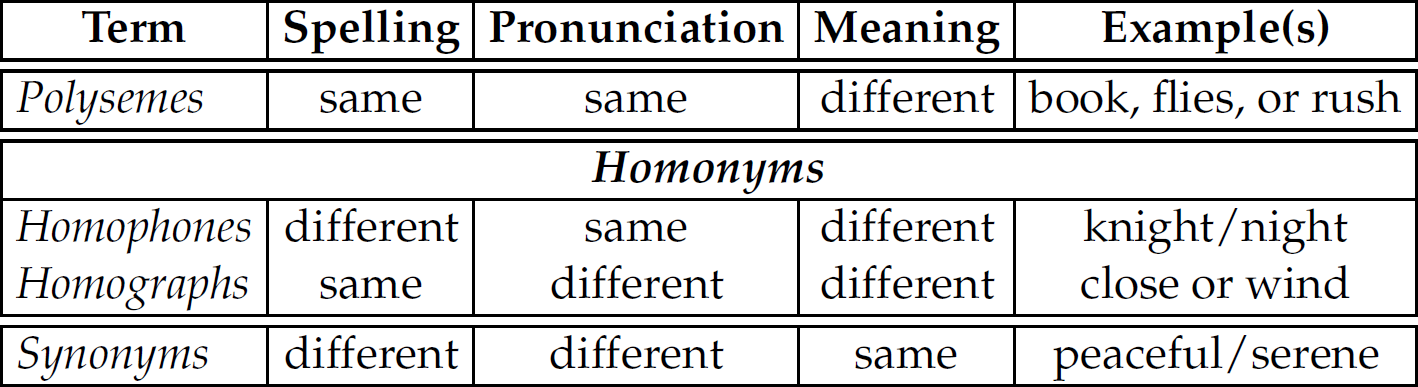
English sentences can also exhibit semantic ambiguity, where there is only one syntactic structure (i.e., parse), but the individual words can be interpreted differently. An underlying source of these ambiguities is the presence of polysemes—a word with one spelling and pronunciation, but different meanings (e.g., book, flies, or rush). Polysemes are the opposite of synonyms—different words with one meaning (e.g., peaceful and serene). Polysemes that are different parts of speech (e.g., book, flies, or rush) can cause syntactic ambiguity, whereas polysemes that are the same part of speech (e.g., mouse) can cause semantic ambiguity. Note that not all sentences with syntactic ambiguity contain a polyseme (e.g., “They are moving pictures.”). For summaries of these concepts, see Tables 2.9 and 2.10.
Table 2.9 Syntactic Ambiguity Vis-à-Vis Semantic Ambiguity

Table 2.10 Polysemes, Homonyms, and Synonyms
Similarly, in programming languages, the source of a semantic ambiguity is not always a syntactic ambiguity. For instance, consider the expression (Integer)-a on line 5 of the following Java program:

The expression 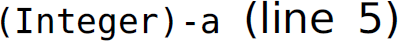 has only one parse tree given the grammar of a four-function calculator presented this section (assuming Integer is an
has only one parse tree given the grammar of a four-function calculator presented this section (assuming Integer is an 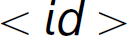 ) and, therefore, is syntactically unambiguous. However, that expression has multiple interpretations in Java: (1) as a subtraction—the variable Integer minus the variable a, which is 4, and (2) as a type cast—type casting the value -a (or -1) to a value of type Integer, which is -1. Table 2.11 contains sentences from both natural and programming languages with various types of ambiguity, and demonstrates the interplay between those types. For example, a sentence without syntactic ambiguity can have semantic ambiguity; and a sentence without semantic ambiguity can have syntactic ambiguity.
) and, therefore, is syntactically unambiguous. However, that expression has multiple interpretations in Java: (1) as a subtraction—the variable Integer minus the variable a, which is 4, and (2) as a type cast—type casting the value -a (or -1) to a value of type Integer, which is -1. Table 2.11 contains sentences from both natural and programming languages with various types of ambiguity, and demonstrates the interplay between those types. For example, a sentence without syntactic ambiguity can have semantic ambiguity; and a sentence without semantic ambiguity can have syntactic ambiguity.
Table 2.11 Interplay Between and Interdependence of Types of Ambiguity
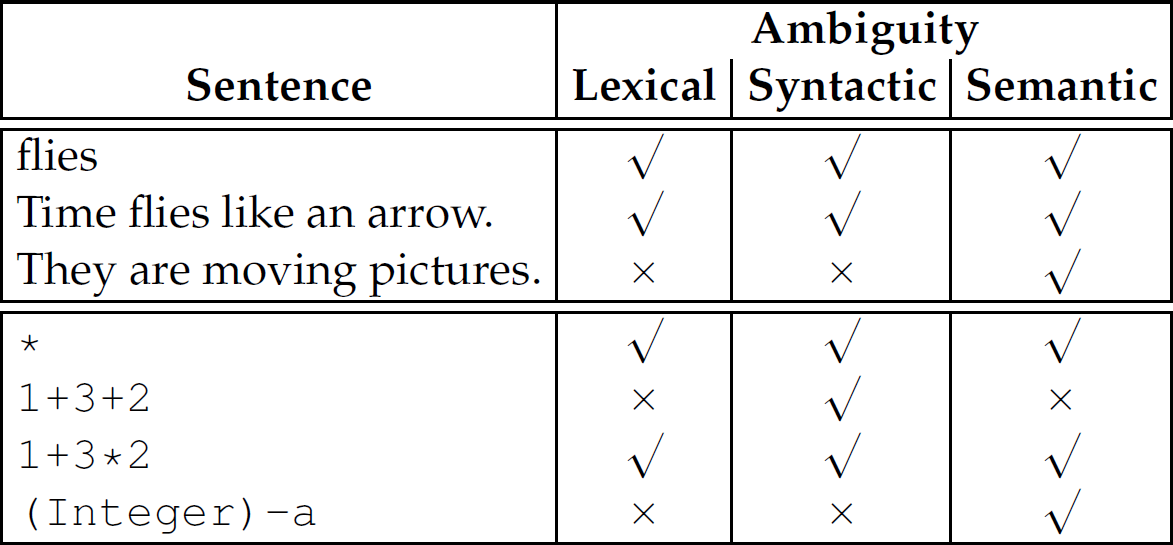
We have two options for dealing with an ambiguous grammar, but both have disadvantages. First, we can state disambiguation rules in English (i.e., attach notes to the grammar), which means we do not have to alter (i.e., lengthen) the grammar, but this comes at the expense of being less formal (by the use of English). Alternatively, we can disambiguate the grammar by revising it, which is a more formal approach than the use of English, but this inflates the number of production rules in the grammar. Disambiguating a grammar is not always possible. The existence of context-free languages for which no unambiguous context-free grammar exists has been proven (in 1961 with Parikh’s theorem). These languages are called inherently ambiguous languages.
6. In the programming language APL, addition has higher precedence than multiplication.
7. Henry VI by William Shakespeare.