
2.7 Language Recognition: Parsing
In the prior subsection we used context-free grammars as language generation devices to construct derivations. We can also implement a computer program to construct derivations; that is, to randomly choose the rules used to substitute non-terminals. That sentence-generator program takes a grammar as input and outputs a random sentence in the language defined by that grammar (see the left side of Figure 2.2). One of the seminal discoveries in computer science is that grammars can (like finite-state automata) also be used for language recognition— the reverse of generation. Thus, we can implement a computer program to accept a candidate string as input and construct a rightmost derivation in reverse to determine whether the input string is a sentence in the language defined by the grammar (see the right side of Figure 2.2). That computer program is called a parser and the process of constructing the derivation is called parsing—the topic of Chapter 3. If in constructing the rightmost derivation in reverse we return to the start symbol when the input string is expired, then the string is a sentence; otherwise, it is not.
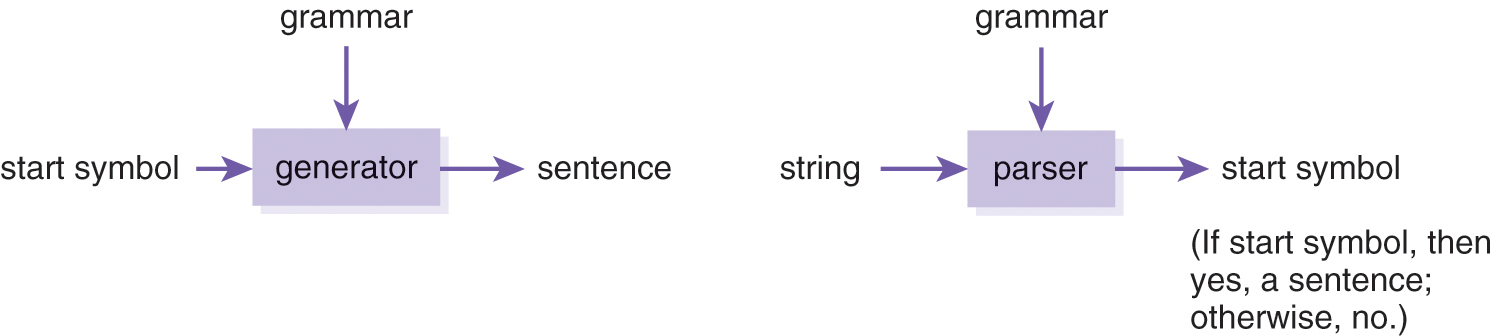
Figure 2.2 The dual nature of grammars as generative and recognition devices. (left) A language generator that accepts a grammar and a start symbol and generates a sentence from the language defined by the grammar. (right) A language parser that accepts a grammar and a string and determines if the string is in the language.
Description
A generator applies the production rules of a grammar forward. A parser applies the rules backward.5
Consider parsing the string 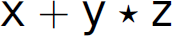 . In the following parse, . denotes “top of the stack”:
. In the following parse, . denotes “top of the stack”:
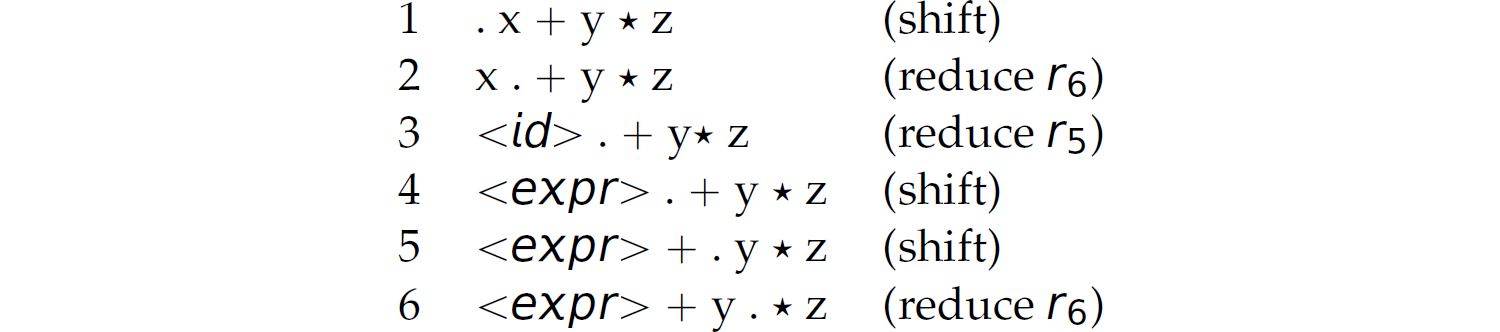

The left-hand side of the . represents a stack and the right-hand side of the . (i.e., the top of the stack) represents the remainder of the string to be parsed, called the handle. At each step, either shift or reduce. To determine which to do, examine the stack. If the items at the top of the stack match the right-hand side of any production rule, replace those items with the non-terminal on the left-hand side of that rule. This is known as reducing. If the items at the top of the stack do not match the right-hand side of any production rule, shift the next lexeme on the right-hand side of the . to the stack. If the stack contains only the start symbol when the input string is entirely consumed (i.e., shifted), then the string is a sentence; otherwise, it is not.
This process is called shift-reduce or bottom-up parsing because it starts with the string or, in other words, the terminals, and works back through the nonterminals to the start symbol. A bottom-up parse of an input string constructs a rightmost derivation of the string in reverse (i.e., bottom-up). For instance, notice that reading the lines of the rightmost derivation in Section 2.6 in reverse (i.e., from the bottom line up to the top line) corresponds to the shift-reduce parsing method discussed here. In particular, the production rules in the preceding shift-reduce parse of the string 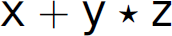 are applied in reverse order as those in the rightmost derivation of the same string in Section 2.6. Later, in Chapter 3, we contrast this method of parsing with top-down or recursive-descent parsing. The preceding parse proves that
are applied in reverse order as those in the rightmost derivation of the same string in Section 2.6. Later, in Chapter 3, we contrast this method of parsing with top-down or recursive-descent parsing. The preceding parse proves that 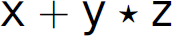 is a sentence.
is a sentence.
5. Another class of parsers applies production rules in a top-down fashion (Section 3.4).