
3.5 Bottom-up, Shift-Reduce Parsing and Parser Generators
We engage in bottom-up parsing when we parse a string using the shift-reduce method (as we demonstrated in Section 2.7). The bottom-up nature refers to starting the parse with the terminals of the string and working backward (or bottom-up) toward the start symbol of the grammar. In other words, a bottom-up parse of a string attempts to construct a rightmost derivation of the string in reverse (i.e., bottom-up). While parsing a string in this bottom-up fashion, we can also construct a parse tree for the sentence, if desired, by allocating nodes of the tree as we shift and setting pointers to pre-allocated nodes in the newly created internal nodes as we reduce. (We need not always build a parse tree; sometimes a traversal is enough, especially if semantic analysis or code generation phases will not follow the syntactic phase.)
Shift-reduce parsers, unlike recursive-descent parsers, are typically not written by hand. Like the construction of a scanner, the implementation of a shift-reduce parser is well grounded in theoretical formalisms and, therefore, can be automated. A parser generator is a program that accepts a syntactic specification of a language in the form of a grammar and automatically generates a parser from it. Parser generators are available for a wide variety of programming languages, including Python (PLY) and Scheme (SLLGEN). ANTLR (ANother Tool for Language Recognition) is a parser generator for a variety of target languages, including Java. Scanner and parser generators are typically used in concert with each other to automatically generate a front end for a language implementation (i.e., a scanner and parser).
The field of parser generation has its genesis in the classical UNIX tool yacc (yet another compiler compiler). The yacc parser generator accepts a context-free grammar in EBNF (in a .y file) as input and generates a shift-reduce parser in C for the language defined by the input grammar. At any point in a parse, the parsers generated by yacc always take the action (i.e., a shift or reduce) that leads to a successful parse, if one exists. To determine which action to take when more than one action will lead to a successful parse, yacc follows its default actions. (When yacc encounters a shift-reduce conflict, it shifts by default; when yacc encounters a reduce-reduce conflict, it reduces based on the first rule in lexicographic order in the .y grammar file.) The tools lex and yacc together constitute a scanner/parser generator system.3
The yacc language describes the rules of a context-free grammar and the actions to take when reducing based on those rules, rather than describing computation explicitly. Very high-level languages such as yacc are referred to as fourth-generation languages because three levels of language abstraction precede them: machine code, assembly language, and high-level language.
Recall (as we noted in Chapter 2) that while semantics can sometimes be reasonably modeled using a context-free grammar, which is a device for modeling the syntactic structure of language, a context-free grammar can always be used to model the lexical structure of language, since any regular language can be modeled by a context-free grammar. Thus, where scanning (i.e., lexical analysis) ends and parsing (i.e., syntactic analysis) begins is often blurred from both language design and implementation perspectives. Addressing semantics while parsing can obviate the need to make multiple passes through the input string. Likewise,4 addressing lexics while parsing can obviate the need to make multiple passes through the input string.
3.5.1 A Complete Example in lex and yacc
The following are lex and yacc specifications that generate a shift-reduce, bottom-up parser for the symbolic expression language presented previously in this chapter.

The pattern-action rules for the relevant lexemes are defined using UNIX-style regular expressions on lines 10–16. A pattern with outer square brackets matches exactly one of any of the characters within the brackets (lines 10 and 12) and . (line 13) matches any single character except a newline, which is matched on line 11.

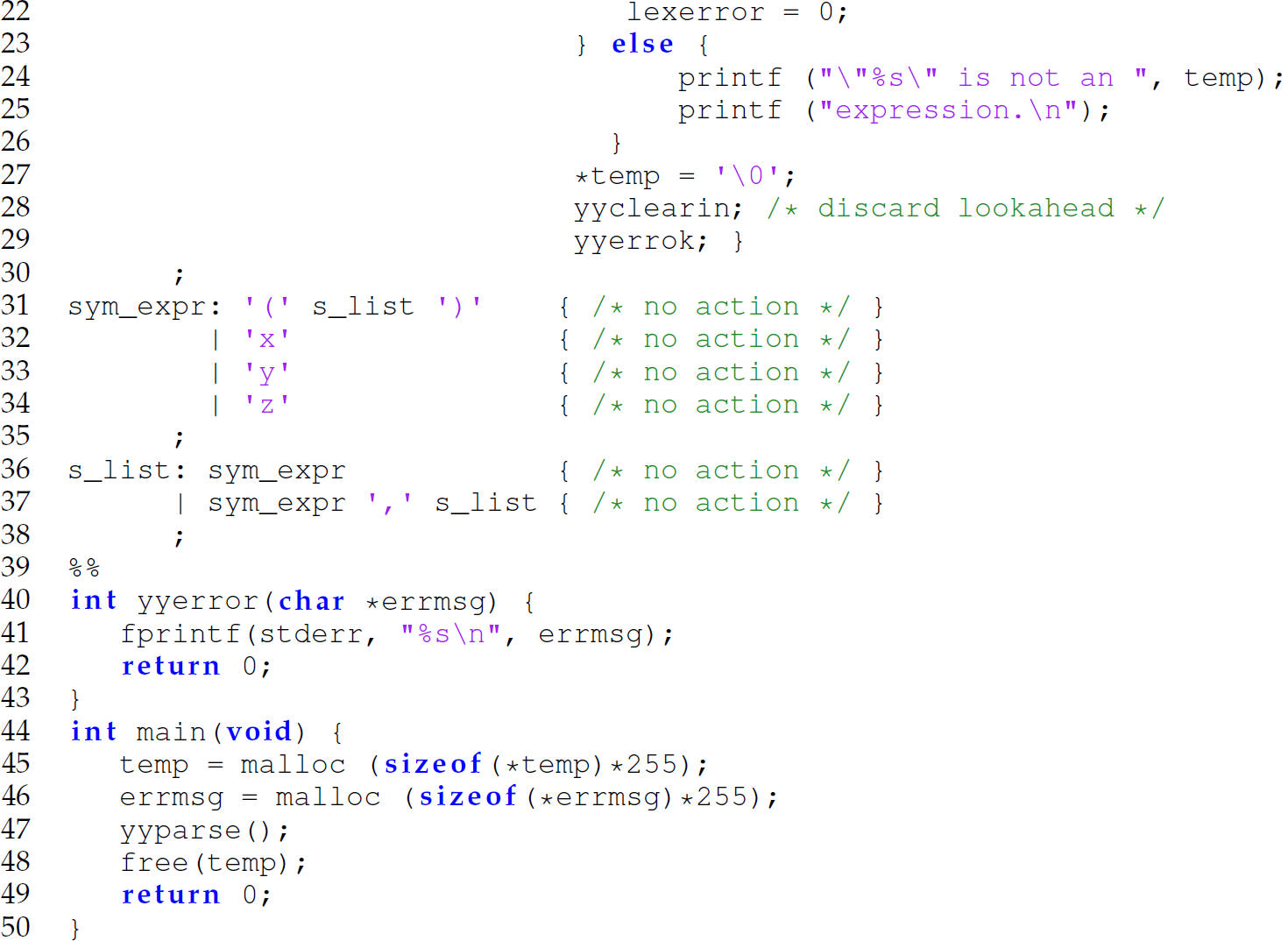
The shift-reduce pattern-action rules for the symbolic expression language are defined on lines 14–38. The patterns are the production rules of the grammar and are given to the left of the opening curly brace. Each action associated with a production rule is given between the opening and closing curly braces to the right of the rule and represented as C code. The action associated with a production rule takes place when the parser uses that rule to reduce the symbols on the top of the stack as demonstrated in Section 2.7.
Note that the actions in the second and third pattern-action rules (lines 31–38) are empty. In other words, there are no actions associated with the sym_expr and s_list production rules. (If we were building a parse or abstract-syntax tree, the C code to allocate the nodes of the tree would be included in the actions blocks of the second and third rules.) The first rule (lines 14–30) has associated actions and is used to accept one or more lines of input. If a line of input is a sym_expr, then the parser prints a message indicating that the string is a sentence. If the line of input does not parse as a sym_expr, it contains an error and the parser prints a message indicating that the string is not a sentence. The parser is invoked on line 47.
These scanner and parser specification files are compiled into an executable parser as follows:


Table 3.5 later in this chapter compares the top-down and bottom-up methods of parsing.
3. The GNU implementations of lex and yacc, which are commonly used in Linux, are named flex and bison, respectively.
4. Though in the other direction along the expressivity scale.