
Even with all of the advantages of reactive development and R2DBC we’ve dug through in this book, the fundamental process of opening a database is an expensive operation, especially if the target database is remote. The process of connecting to a database is expensive, in terms of resource utilization, because of the overhead of establishing a network connection and initializing the database connection. In turn, connection session initialization often requires time-consuming processing to perform user authentication and establish transactional contexts and other aspects of the session that are required for subsequent database usage.
So, in this chapter, we’re going to take a look at the idea of connection pools. You’ll gain an understanding of not only what connection pools are and why they can be necessary but also how they can be used within an R2DBC-based application to help improve application performance and efficiency.
Connection Pool Fundamentals

A simple connection pool workflow
Benefits of Connection Pooling
Reducing the number of times new Connection objects are created
Promoting Connection object reuse
Speeding up the process of obtaining a connection
Reducing the amount of effort required to manage Connection objects
Minimizing the number of stale connections
Controlling the amount of resources spent on maintaining connections
Ultimately, the more database intensive an application is, the more it benefits from the use of connection pools.
How to Get Started
We’ve learned that a key advantage of R2DBC is its extensibility, which is made possible through the specification’s simplicity. In fact, it’s so simple that you might have noticed that the idea of a connection pool hasn’t been mentioned until this chapter. Out of the box, R2DBC does not provide support for connection pooling.
Roll Your Own Connection Pool
R2DBC was built with extensibility in mind. With the specification mostly containing interfaces that require implementation, those implementations can be supplemented to include support for connection pooling. Basically, that means that R2DBC objects like ConnectionFactory and Connection can be created in such a way that, by default, includes support for connection pooling.
Of course, that’s something that could be accomplished at the driver level, but, ideally, because of the generalized nature of the connection pooling concept, it might make more sense to support it as an independent, self-contained library.
Ultimately, it’s out of the scope of this book to dive into the details on how connection pools can be created and maintained using a custom R2DBC implementation that has yet to be created. The real takeaway here is that it can be accomplished by creating an implementation from the R2DBC specification, located at https://github.com/r2dbc/r2dbc-spi, other libraries to help with the Reactive Streams implementation, and so on.
Introducing R2DBC Pool
However, from a pragmatic perspective, developing support for connection pools from the ground up isn’t trivial. For that reason, among others, it may be helpful to, instead of creating a custom solution, utilize an existing library for creating and managing connection pools. Luckily, such a library exists as a GitHub repository within the R2DBC account.
The r2dbc-pool project is a library that supports reactive connection pooling. Located at https://github.com/r2dbc/r2dbc-pool, the open source project uses the reactor-pool project, which provides functionality to support generic object pooling, as the foundation for fully non-blocking connection pooling.
The object pool pattern is a software design pattern that uses a set, or a pool, of initialized objects kept ready to use rather than allocating and destroying them on command.
Exposes a reactive API (Publisher input types, Mono return types)
Is non-blocking (never blocking a user who makes an attempt to acquire a resource)
Has lazy acquisition behavior
Lazy loading, or acquisition, is a design pattern that focuses on deferring initialization of an object until the point at which it is needed.
The reactor-pool project is completely open source and can be found on GitHub at https://github.com/reactor/reactor-pool.
Going forward, we’ll be using the r2dbc-pool project to examine how connection pools can be used to manage connections within an R2DBC-enabled application. Continuing with the trend that’s been set in previous chapters, I’ll be using the MariaDB R2DBC driver, in combination with r2dbc-pool, for all subsequent examples.
R2DBC Pool
In this section, we’re going to take a look at how the r2dbc-pool project can be used within an application to manage R2DBC connections.
Adding a New Dependency
Adding the dependency for r2dbc-pool
You also have the option of using the latest version of r2dbc-pool by building directly from the source code. For more information, see the documentation at https://github.com/r2dbc/r2dbc-pool.
Before proceeding to the next section, it’s important to reemphasize that the r2dbc-pool project does not provide any mechanisms for actually connecting to an underlying database. It needs to be used in combination with an existing driver to work. Going forward, I’ll be providing examples that assume use of the MariaDB R2DBC driver that we’ve used in previous chapters.
Connection Pool Configuration
You’ve learned that the ConnectionFactoryOptions object, which was first mentioned in Chapter 4 and then later in Chapter 12, exists to hold the configuration options used to, ultimately, create ConnectionFactory objects. The R2DBC Pool project extends the options available through ConnectionFactoryOptions to include discovery settings to support connection pools.
Supported ConnectionFactory discovery options
Option | Description |
|---|---|
driver | Must be pool. |
protocol | Driver identifier. The value is propagated by the pool to the driver property. |
acquireRetry | Number of retries if the first connection acquisition attempt fails. Defaults to 1. |
initialSize | Initial number of Connection objects contained within a pool. Defaults to 10. |
maxSize | Maximum number Connection objects contained within a pool. Defaults to 10. |
maxLifeTime | Maximum lifetime of a connection within a pool. |
maxIdleTime | Maximum idle time of a connection within a pool. |
maxAcquireTime | Maximum allowed time to acquire a connection from a pool. |
maxCreationConnectionTime | Maximum allowed time to create a new connection. |
poolName | Name of the connection pool. |
registerJMX | Whether to register the pool to JMX. |
validationDepth | Validation depth used to validate an R2DBC connection. Defaults to LOCAL. |
validationQuery | Query that will be executed just before a connection is received from the pool. Query execution is used to validate that a connection to the database is still alive. |
Java Management Extensions (JMX) is a Java technology that supplies tools for managing and monitoring applications, system objects, devices, and service-oriented networks. Those resources are represented by objects called MBeans. In the API, classes can be dynamically loaded and instantiated.
Connection Factory Discovery
Ultimately, in order to be able to manage connections using a connection pool, you must have access to a ConnectionPool object . However, acquiring a ConnectionPool object starts by obtaining a ConnectionPool-compatible ConnectionFactory object. Creating a ConnectionPool-compatible ConnectionFactory object can be done in two ways.
Using an R2DBC URL to discover a pool-capable ConnectionFactory
Other, optional, discovery options can be added after the question mark (?) in a R2DBC URL.
Programmatically discovering a pool-capable ConnectionFactory
ConnectionPoolConfiguration
Building a ConnectionPoolConfiguration object using ConnectionFactory
Creating a ConnectionPool
Creating a new connection pool
Class implementation of ConnectionPool
Managing Connections
We’ve learned that the R2DBC Connection object is the foundation that reactive interactions are built on and that in order to obtain a Connection object we have to go through a ConnectionFactory object .
In the previous section, we also learned that the R2DBC Pool project’s ConnectionPool object is an implementation of the ConnectionFactory object.
Obtaining a Connection
To take advantage of the connection pool management provided by the R2DBC Pool project, you’ll need to acquire Connection objects through a PooledConnection object.
A high-level class implementation view of PooledConnection
Obtaining a PooledConnection object
Then, as expected, we can use the PooledConnection object to be able to communicate with the database to execute statements, manage transactions, and so on.
Releasing a Connection

All of the connections within a connection pool being used by clients
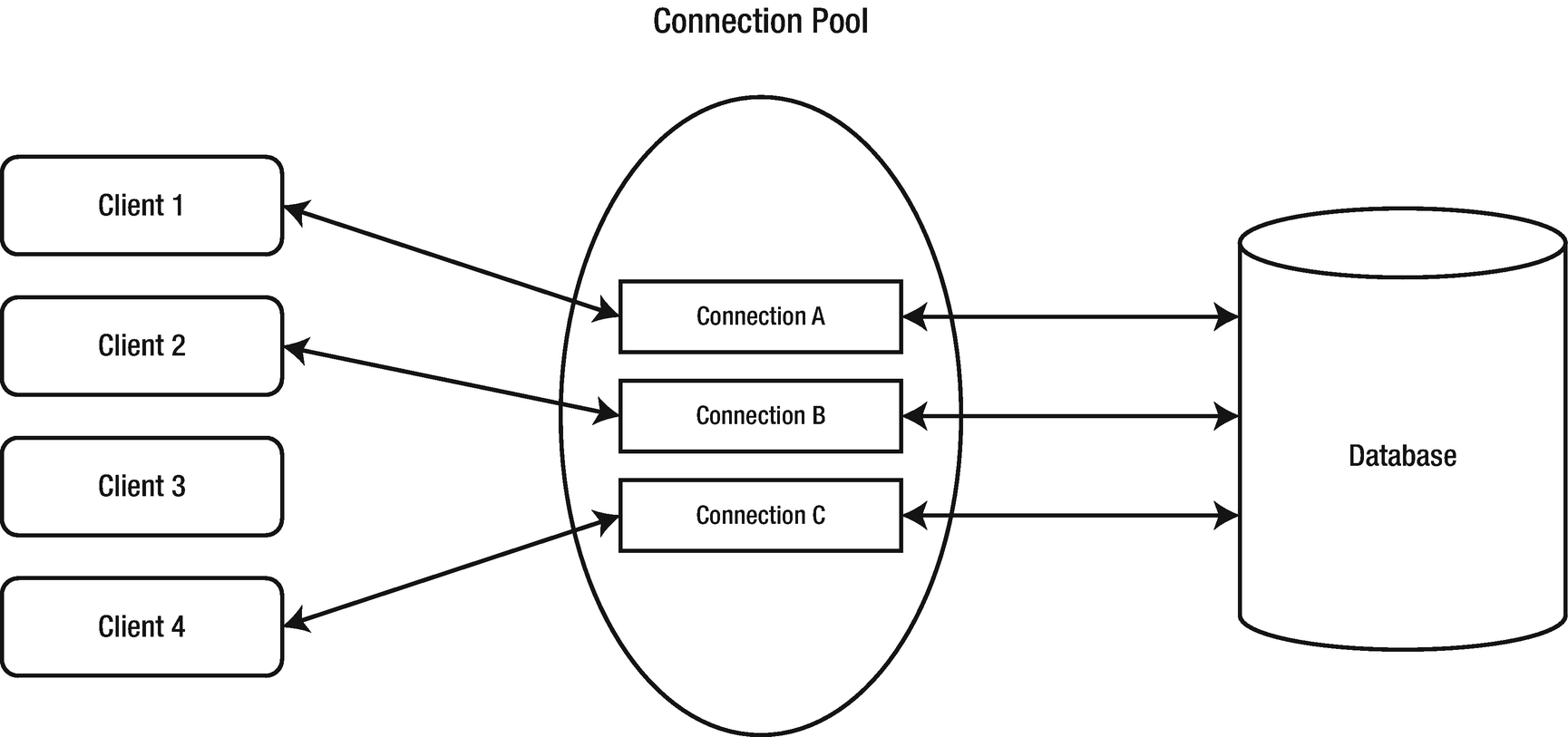
After being released back into the connection pool, Connection C is available for Client 4 to use
Releasing a connection back into the connection pool
Cleaning Up
Disposing a connection pool
Closing a connection pool
Underneath the hood, the close method simply calls the dispose method.
Show Me the Code
You can find a complete, fully compilable sample application in the GitHub repository dedicated to this book. If you haven’t already done so, simply navigate to https://github.com/apress/r2dbc-revealed to either git clone or directly download the contents of the repository. From there you can find a sample application dedicated to this chapter in the ch15 folder.
Summary
Connection pools are essentially a cache of database connections maintained in the database's memory so that the connections can be reused when the database receives future requests for data. Ultimately connection pools are used to enhance the performance of executing commands on a database.
In this chapter, you gained a fundamental understanding of what connection pools are and how they can be extremely beneficial to use within applications, especially those with a large number of database-intensive operations. You learned about the R2DBC Pool project and gained first-hand knowledge of how to utilize it within an application.