
10
Inside the Real-Time Garbage Collector
“Much may be done in those little shreds and patches of time which every day produces...”
—Charles Caleb Colton
THE real-time garbage collector (RTGC) that comes as part of Sun’s Java Real-Time System is a non-blocking, non-generational, fully concurrent mark and sweep collector with no stop-world pauses. It’s also an extremely low-latency collector that operates in bounded time for all operations, and operates within a set range of priorities to help achieve predictable behavior. Not only does it work concurrently with mutator (application) threads during all GC phases, it performs its work using parallel collector threads. This classifies it as a fully concurrent, non-blocking, non-moving parallel mark and sweep real-time collector. This is not an easy accomplishment, and in this chapter we’ll outline the specific algorithms involved in its implementation.
Being based on Roger Henriksson’s thesis on real-time dynamic memory management, the Java RTS RTGC runs at lower priority than Schedulable objects. Due to the priority-based scheduling in Java RTS, RTTs are always dispatched in preference to the RTGC threads. Further, because NHRTs cannot access the heap, they experience no interference from the RTGC at all.
It’s also important to note that the RTGC, as we’ll refer to it in the remainder of this chapter, is extremely flexible in its runtime characteristics. Its tuning options allow you to control many facets of its operation. Although it’s based very much on the Henriksson real-time GC algorithm discussed in Chapter 2, through tuning you can alter its behavior to best suit your application’s requirements. We’ll refer to these alterations as “policies,” and we’ll describe some sample policies at the end of this chapter.
RTGC Theory of Operation
To achieve the most deterministic behavior, Java RTS attempts to keep the entire Java heap in physical memory. This eliminates any potential jitter from page faults in the heap. This means that the RTGC doesn’t need to consider the affects of virtual memory as it operates. Here is a list of characteristics of the Java RTS RTGC:
• It’s a mark and sweep collector.
• It’s fully concurrent with mutator threads.
• It’s a parallel collector, meaning it will perform its work in multiple threads, when applicable. Therefore, it automatically scales according to the number of processors available to it.
• It’s non-generational; there is only one main heap region.
• It’s a non-moving, non-compacting collector. This fits with the fact that there are no generations, or separate heap regions such as toSpace and fromSpace (see Chapter 2 for an explanation of these regions). Objects are not moved, and the heap is not compacted in the traditional sense. Although this can lead to fragmentation, strategies are implemented to address it. We’ll examine this later in the chapter.
• Concurrent marking uses a snapshot-at-the-beginning (SATB) approach. This will be examined in detail in the next section of this chapter.
• It uses a tri-color marking scheme (white, grey, and black—see sidebar).
• It imposes a write barrier, only activated when the GC is running. In between GC cycles—when the GC threads are idle—this write barrier is removed.
• Because it’s a non-moving collector, there is no read barrier.
• It uses fixed-sized memory blocks for object allocation, and will split large objects across memory blocks when required.
• GC threads run at a low real-time priority, above non-real-time java.lang.Threads (JLTs), but lower than application RealtimeThreads (RTTs) when running in normal mode. As discussed in Chapter 4, the RTGC may run with boosted priority if free heap space drops below a specified threshold, but this is meant to be an exceptional case.
• It implements ergonomics, and self-tunes according to mutator allocation rates and overall application behavior.
• It implements occasional handshaking with running mutator threads, which acts like GC safepoints, but without stop-world pauses.
Like most collectors, the RTGC operates in phases. There is a mark phase, a sweep phase that follows, and a third phase called zeroing. In summary, this phase prepares key global structures for the next GC cycle by emptying values within GC and per-mutator-thread data structures. Let’s begin with a detailed look at the marking phase now.
Concurrent Marking
The RTGC doesn’t begin a garbage collection cycle until the amount of free memory goes below the initial threshold, called the startup memory threshold (discussed in Chapter 4). By default, this occurs when there is almost no free memory left. When it does begin, the marking phase runs concurrently with mutator threads with no stop-world pauses, and virtually no interference with mutator thread progress. With the RTGC, this applies to RealtimeThread objects, of course, but there is an attempt to limit the impact on the lower-priority Thread objects as well. Since NoHeapRealtimeThreads don’t use the heap, and are hence subject to no GC-related jitter, we’ll omit them from this discussion.
Marking involves the following steps and activities on each mutator thread’s stack:
1. Mark all white (unmarked) objects as grey. This indicates that the object is reachable, but objects it references are not yet marked as reachable.
2. Mark white objects that were missed because the mutator thread changed an object reference while in the marking phase. We’ll examine this more closely later.
3. Recursively walk object reference graphs and mark all reachable objects (also known as blackening). When a grey root object and all of its referenced objects are marked, they are considered black. When all objects are either white (a dead object) or black (a live object), the marking phase is complete.
4. Invoke a write barrier to place newly created objects on a special list. We’ll examine this later, as well.
Parallel GC threads, called the RTGC gang worker threads, perform most of the marking. The mutator threads perform some of the marking themselves during steps 1, 2, and 3 above, if they happen to be running while a GC cycle is in progress. Step 3 is performed solely by RTGC worker threads without any synchronization with mutator threads. To be thorough, the following three conditions must be accounted for during the marking phase, for each mutator thread:
• When a GC cycle begins, some (if not all) of the mutator threads may be suspended. For each mutator thread that is suspended, one of the GC gang worker threads performs the marking of its live objects. In this case, the marking can be performed without any potential latency, and without the mutator thread ever knowing it happened. The only exception is if the mutator thread wakes up during the operation.
• When a GC cycle begins, one or more of the mutator threads may be running. If this is the case, the mutator thread itself performs the marking operation by scanning its own live objects. This is done through a handshake, where the RTGC main thread inserts calls to the marking code into the mutator’s stack. The latency (due to the extra processing of marking) involved with the handshake is bounded, and very small.
• For a mutator thread that is released (become eligible for execution) while a GC thread is actively scanning its stack for live objects, there is a small amount of latency incurred while the GC worker thread finishes stack scanning that mutator thread’s stack. The mutator will be blocked until this operation is complete.
By default, the number of gang worker threads started by the RTGC is equal to the number of processors/cores available on the server. However, this may be overridden by a command-line parameter setting, or constrained by the number of processors in a processor set assigned to execute the Java RTS VM process.
To accommodate changes for the RTGC in Java RTS, the base Java SE object data structure is extended by two 32-bit words; the first word is the marking chain pointer, used as part of a linked list of marked objects; the second word is used for object splitting on allocation (discussed later in this chapter)—see Figure 10-1. The marking word is the next pointer itself (part of the header), and by nature of it holding a non-null value, the object is considered marked.
Figure 10-1 The two new header fields for a Java RTS Object.

Marking is performed on a single list of global objects (for global variables) as well as on a list per mutator thread used to store marked objects for the associated thread (see Figure 10-2). As the roots are traced for each thread via stack scanning, objects marked as live are placed on the applicable thread’s marked list. Because these lists are maintained per thread, there is no need to synchronize access, as there would be if a single list were used. Additionally, atomic compare-and-swap (CAS) operations are performed where possible to avoid locking that would otherwise be required when testing and updating pointer values. We’ll discuss CAS operations as appropriate in this discussion.
Figure 10-2 Per-mutator lists of marked objects are maintained.
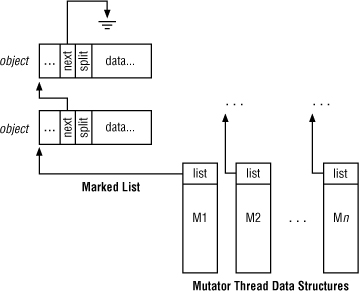
As mentioned above, a non-null value in the next header field indicates the object is marked. The next field for the last object in the list is set to a special end-of-list value (not null). Note that since this value is non-null, the object is appropriately considered marked.
Snapshot at the Beginning
The RTGC uses a snapshot at the beginning (SATB) technique, as opposed to continuous update marking, for its concurrent marking phase. With SATB, only objects that are unreachable at the beginning of the cycle are collected; objects that become free during a cycle will not. This is done to eliminate much of the rescanning performed when an object reference is updated during a cycle.
Note: RTGC Bounded Operations
![]()
Although it’s based on the Henriksson real-time collection algorithm, the Java RTS RTGC goes one step further. It tries to limit its disruption of standard threads, as well as real-time threads. Therefore, theoretically, non-real-time threads will benefit from the design and operation of the RTGC. But for true real-time behavior guarantees, your code must execute within a RealtimeThread object.
With SATB, there is potential for additional floating garbage (as opposed to continuous update marking), but on the positive side, there is an upper bound to both the total marking time, and the latency involved with mutator thread stack scanning. Remember, floating garbage consists of dead objects that are missed (and not collected) by the current GC cycle. Both floating garbage and latency issues are important to a real-time collector, as you want to free as much memory as possible at each GC cycle, and to do so with limited impact on running mutator threads. With a continuous-update marking algorithm, stack scanning needs to be repeated to ensure references aren’t missed, and live objects aren’t mistakenly collected. To explain this, let’s look at an example.
Figure 10-3 illustrates an object reference graph as viewed by a GC’s marking thread. Here, root objects (i.e., from the mutator thread’s stack) are shown above the dotted line. All of the objects that the roots refer to are live, and must be marked as such. Starting from each root, the GC marker thread walks the tree and marks each referenced object as live. At the end of the marking cycle, sweeping begins and all unmarked objects are considered garbage and reclaimed.
Figure 10-3 With concurrent marking, the mutator thread can change the live object set during marking.
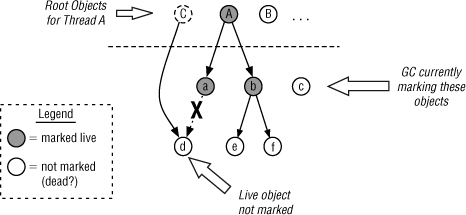
In this example, roots A and B (and possibly more) existed when marking began, but not C. Remember, with the Java RTS RTGC, marking will occur concurrently with mutator threads, so changes to the object graph may occur while the GC marker thread is scanning it. Here, after the marker thread has scanned root A and some of its first level references (a and b), the following occurs:
1. Root A, and child objects a and b, are marked as live by the GC marker thread.
2. Concurrently, the mutator thread does the following:
a. Creates a new root object, C
b. Creates a reference from C to d
c. Breaks a reference from a to d
The RTGC worker thread will continue graying, and will mark objects e, and f as live. However, because the reference from a to d has been broken, the marker thread doesn’t find object d, and leaves it unmarked. If nothing else were to happen, the marker thread might finish without ever marking d, and the sweep phase would collect it as garbage, which is clearly incorrect.
One solution, called continuous update marking, is to activate a write barrier when marking begins that sets a flag when updates occur to a thread’s root object set. At the end of the marking cycle, the marker thread would check this flag and restart the marking phase if it’s set. The result is positive, in that it avoids the error of collecting a live object, but negative in that it requires an entire marking phase to occur again. What’s worse, if mutator activity continues to change the root object set, marking may be repeated again, and again, without limit. This delays the sweep phase, which makes free memory available to the running mutator threads. As a result, mutator threads—even critical real-time threads—may experience failure or delay due to a low-memory condition.
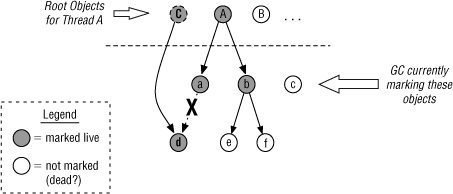
The goal is to ensure that the delay of the sweeping phase is bounded. However, since an equally important goal is to have no stop-world pauses, the mutator thread must not be blocked in any way. The SATB marking algorithm accomplishes this by activating a write barrier that automatically marks object references on updates, for both the new and old object references. In this case, for example, object d would be marked when the reference to it is broken, and root object C would be marked upon creation. The result, shown in Figure 10-4, is that objects C and d are marked as live even though the marker thread never scanned them. Note that this write-barrier is only needed (and hence only activated) when the RTGC is currently in the marking phase.
Figure 10-4 A write barrier marks new objects, and old object references to avoid rescanning.
This approach has one drawback: there exists a potential to mark objects as live when they truly are garbage, thus creating floating garbage. For example, given the previous scenario, if the reference from object a to object d were broken, but root object C was never created with a reference to it, object d would have still been marked as live even though there are no references to it—see Figure 10-5.
Figure 10-5 SATB-based marking can result in dead objects marked as live.
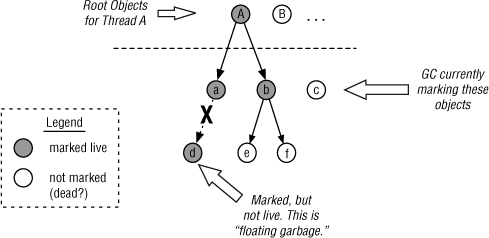
Floating garbage objects end up getting collected in the next GC cycle. However, in low-memory conditions, this delay can negatively impact the application. This is a tradeoff that the Java RTS design team deemed necessary in a real-time application, as the unbounded delay of the sweep cycle could have the same, if not a more widespread, result.
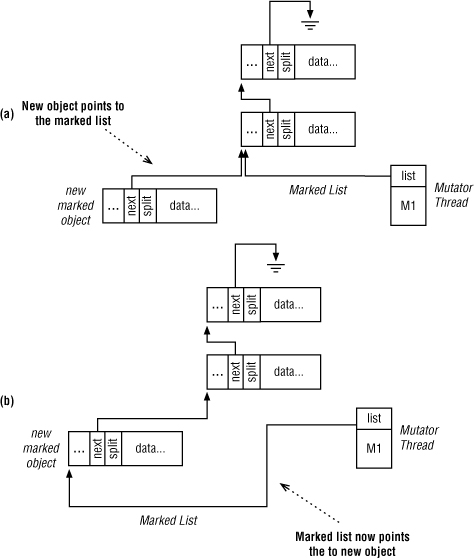
Objects are added to the head of the marked list. Because of this, there is no walking of the list required, and object insertion is performed in a small, bounded, amount of time. Additionally, by using a CAS operation, this requires no locking of the list. The new marked object has its next pointer set to the head of the thread’s marked list, and then the thread’s marked list pointer is set to this new object (see Figure 10-6).
Figure 10-6 In (a), the new object’s next field points to the marked list. In (b), the thread’s marked list points to the new object; the insert is complete.
When marking is complete (all root objects have been scanned, and their references recursively scanned as well), all live objects are marked as black and the marking phase is terminated for this mutator thread. To do this, another handshake is invoked, where the mutator thread copies the head of its marked list to another mutator field, and sets the marked list pointer to a special end-of-list value.
Parallel Marking
GC work during the marking phase per mutator thread is naturally parallelized; it’s either performed by the individual mutator threads themselves (if running), or available gang worker threads inside the RTGC for mutator threads that are suspended during this phase. Root graying, the recursive blackening of live object graphs, and additional marking due to mutator changes to the object graph, all occur in parallel and currently to mutator threads. For global data (which includes application global data, static and class data, and internal VM data), the gang workers need to divide the work to help the Java RTS VM scale on multiprocessor servers.
The RTGC uses a row-and-column, grid-based, structure to help parallelize the RTGC marking work on global data. This is structured as an n-by-n grid of rows and columns, where n is equal to the number of GC worker threads. By default, this number is equal to the number of processors/cores available to the Java RTS VM process, unless changed via command-line arguments. Each row is serviced by only one RTGC thread, and is implemented as a circular linked-list—the last entry (column) points back to the first. Each cell in each row points to a linked-list of objects to be recursively marked, hence creating a three-dimensional data structure (see Figure 10-7).
Figure 10-7 Each row is serviced by one thread, making work available to other threads (per column).
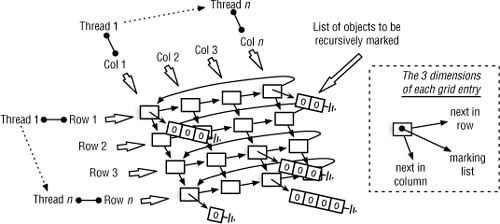
In this grid, the columns are also connected as lists, but they’re not circular in this case. As with rows, each column is serviced by only one RTGC worker thread. The list of objects in each cell contains a head pointer (points to first item in the list) and a last-scanned pointer, which points to the last object in the list that was recursively scanned and marked. New objects to be scanned are inserted at the head of the list, and the last-scanned pointer works from the end towards the head of the list.
Because one assigned thread feeds each row, and one assigned thread services each column, this arrangement helps to limit synchronization issues. However, there is potential that some threads will remain idle (because their respective column is empty) while others are busy servicing their assigned columns. To help balance the load, when a thread discovers it has no work left on its column, it will attempt to steal work from another column, or from another mutator’s marking list.
The RTGC knows that there is no more marking to be done when all the objects in the grid have been recursively marked, and all of the per-mutator marking lists are empty. The lists are retrieved via a handshake. This indicates that there are no additional objects left to mark. At this point, the thread enters the termination protocol—see Figure 10-8.
Figure 10-8 The termination handshake is like a gate at the start of the horse race, and gathers threads for the next phase.
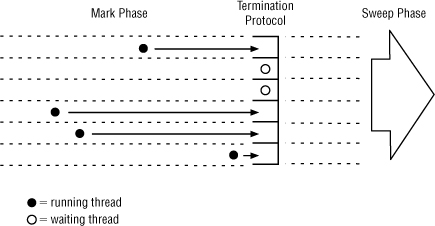
Once the handshake is complete, with no more marking work left on the grid or any mutator lists, this is the indication that the marking phase can terminate, as there is no marking left to do. If the handshake reveals more marking work is to be done, the RTGC will exit the termination protocol safely and re-enter later. Otherwise, this signals the end of the marking phase, and the beginning of the RTGC sweep phase.
Concurrent Sweeping
The point of the sweep phase is to collect all objects in the heap not marked as live during the mark phase. The memory space occupied by these objects is then made available for the allocation of new objects. Put another way, the RTGC threads produce free memory for the mutator threads to consume. Since the RTGC is a non-generational, non-compacting collector, the objects are considered free in place, leading to potential gaps of free space of varying size in the heap. This is an issue that must be addressed during allocation, which we’ll examine later in this chapter.
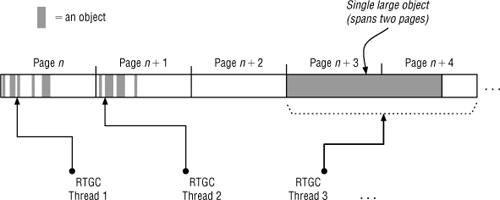
Parallelism during the sweep phase (performed by the RTGC gang worker threads only) is accomplished by dividing the heap into equally sized pages, where each page is processed by a single thread. The only exception is when a single object is larger than one page. Note that the page size is set such that the likelihood of this occurring is small. However, if it does occur, the large object is aligned on the page boundary, and all of the pages the object occupies are given to a single worker thread to process as a unit (see Figure 10-9).
Figure 10-9 Parallel RTGC threads sweep the heap in pages to avoid synchronization issues.
Although this figure shows three or more RTGC threads working in parallel, the rules that dictate how many actual RTGC threads operate in the sweep phase are the same as in the mark phase. In fact, the number of gang worker threads available for all phases of garbage collection is equal (ignoring the differences between normal and boosted mode). The same threads simply perform different work based on the phase the collector is in. As a review, by default the actual number of RTGC threads running depends on the number of processor cores available to the Java RTS VM, unless changed via command-line arguments.
Additionally, there is no hard-coded assignment of pages to RTGC threads. Instead, the threads use a concept called work stealing to determine which page, if any, they should sweep next. Again, a CAS operation is used by each thread to claim a page to avoid expensive locking. If the CAS operation succeeds, the thread sweeps the page; if the CAS fails, it means another thread has claimed that page. The thread will repeatedly attempt to claim another page, unless there are no more pages to claim (and sweep).
During the sweep phase, each dead (unmarked) object’s data is cleared, but its header values are untouched. As a result, each object remains within its respective list (i.e., the global list, or a mutator thread’s marked list). The header portion of each dead object is cleared during the next and last collection phase. The only objects whose data is not cleared, and temporarily not made available for future allocation, are those that are deemed too small. This is what the RTGC calls dark matter.
By tracking dark matter within the heap and not making it available for immediate allocation, the RTGC can better fight against fragmentation. This is an important strategy, as the RTGC does not move objects or compact memory in any way. Instead, the RTGC tracks dark matter and waits for adjacent objects to also become free, at which point their blocks will be coalesced into a single, larger, block. To be precise, to fight against memory fragmentation, the RTGC will do the following:
• Combine two groups of contiguous dark matter blocks into one usable block
• Combine a dark matter block with a free block adjacent to it
• For a new dead object that is adjacent (between) two blocks of dark matter (too small to be placed on the free list), combine all three blocks into one
When a thread finishes sweeping its page, it attempts to claim another. If repeated attempts fail, the thread will enter the termination protocol for the sweep phase. Once all of the RTGC gang worker threads enter the termination protocol, this signals the end of the sweep phase, and the beginning of the zeroing phase, which we’ll examine in detail now.
Concurrent Zeroing
At this point in the collection cycle, the RTGC has completed both the marking and sweeping phases. All live objects have been marked and preserved, and all unmarked objects have been cleared and placed on the free list or considered dark matter. However, the live marked objects still reside within the grid, the global black list, or a mutator “new object” list (the per-mutator marking lists are all empty at this point). These objects must have their marked indicators cleared in preparation for the next cycle. Since each object’s next field is used for marking and placing it within a list, clearing this value simultaneously un-marks it, and un-links it from a list.
As with marking, zeroing is performed by entering a handshake, which stops mutator threads from chaining newly created objects. At this point, the RTGC gang worker threads parse all of the lists without concern of interference from mutator threads. For global data (not on a mutator list), the n-by-n grid described earlier is used. Parallelism is accomplished in a similar manner, where assigned threads zero the objects within each list, per row. As they traverse the rows and columns, and walk the lists, clearing each object’s next field effectively prepares them for the next GC cycle and removes them from the list, all in one efficient operation.
Once all mutator lists and the global grid are empty (containing nothing but the special end-of-list marker), the GC cycle is complete and the RTGC will suspend all gang worker threads. This constitutes the end of the GC cycle, and the RTGC will remain suspended for a set period of time, even if free memory is still at or below the threshold to begin GC again. This is to ensure that even low-priority, non-real-time threads can execute. The minimum time period between GC cycles can be configured through a command-line parameter, as described in Chapter 4.
RTGC Memory Allocation
Although a garbage collector’s main goal is to produce enough free memory for running applications, its secondary goal is to support the application’s consumption of that memory. The RTGC manages the entire Java heap, and sets appropriate values within each new object’s header fields. Namely, each object’s marking field—the next pointer we discussed throughout this chapter—is set differently according to the active GC phase. To accurately track new objects during these phases, the tri-color marking scheme described earlier is used.
As discussed earlier, a write barrier is activated during a GC cycle to properly set an object’s header fields accordingly. However, in between cycles, this write barrier is removed, and allocation occurs more quickly. Although it’s unfortunate that the allocating mutator threads must pay this penalty, it’s a relatively small price to pay for concurrent garbage collection. The alternative, implemented by many non-real-time collectors, is to stop all mutator threads during a GC cycle. Let’s examine the heap layout in general, and the strategies implemented to make object allocation as efficient as possible.
Heap Layout
The heap in Java RTS is one large space composed of an array of lists that contain free objects, with no separate to or from spaces, or generations. (See the discussion of GC algorithms in Chapter 2 for more details on spaces and generations.) The free lists are composed of individual blocks of free memory sized increasingly large, by powers of two. For instance, there are lists of blocks sized at 512 bytes, at 1024 bytes, and so on. The maximum size of blocks kept on the lists is dependent upon the total size the heap is set to at VM startup.
As with the marking and sweeping phases of the GC cycle, objects are inserted into and removed from the free lists via atomic, lock-free, compare-and-swap (CAS) operations. This removes the need for expensive locking and synchronization amongst the GC and mutator threads.
Thread-Local Allocation Buffers
Java RTS makes use of thread-local allocation buffers (TLABs), per mutator thread, to avoid contention between mutator threads when new objects are created. To review from Chapter 2, a TLAB is a portion of the free heap that’s reserved for one thread to allocate from (see Figure 10-10). This figure is slightly different from when it was first presented in Chapter 2, as the Java RTS heap does not contain a global first-free-byte pointer; since it doesn’t move live objects and compact the heap, it cannot.
Figure 10-10 TLABs avoid lock contention on concurrent allocations.
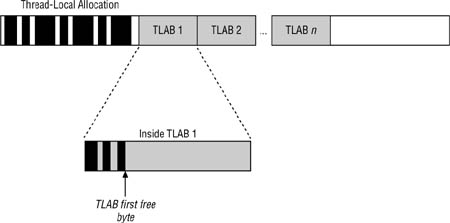
All TLABs are 4K bytes in size by default. However, if the heap becomes fragmented, the VM will return TLABs of smaller size, as needed. When a mutator thread creates a new object, the memory is taken from the thread’s active TLAB. If the object is smaller than the free space within the active TLAB, the allocation is very fast and efficient. In fact, the allocation code is inlined with the thread’s compiled Java code, producing the fastest possible allocation performance. The only exceptions are when the current TLAB becomes filled, or the object is too large to fit into even an empty TLAB.
In the first case, the VM will request a new TLAB from the RTGC. This is a more expensive, but bounded, scenario. In the second case, where the object size is relatively large, the RTGC may decide to place the object outside of the mutator’s TLAB. This operation is less expensive than allocating a new TLAB, as it uses atomic operations and hence requires no locking. Although the RTGC is not generational, this is analogous to Java SE’s immediate promotion of large objects to the heap’s old generation.
Object Splitting
As mentioned above, TLAB sizes may fall below the normal 4K if the heap becomes fragmented. This isn’t necessarily a problem, unless the size of any one free block is too small to accommodate the next new object to be created. If contiguous free blocks cannot be located to fit it, the object will be split across free blocks outside of a TLAB (see Figure 10-11).
Figure 10-11 New objects may be split across multiple (smaller) free heap blocks.
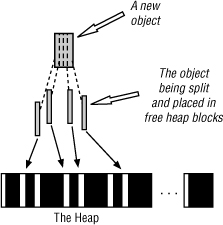
Although this isn’t something exposed to you (as a Java developer), it does require extra accounting and processing within the VM when the object is accessed. As a result, this can affect latency, performance, and throughput overall. Therefore, all effort is made to avoid splitting entirely, but when it does occur, objects are split using the largest free blocks available. In practice, for most objects split across the heap versus those that are placed within one free block, the access time difference is minimal. For arrays, however, performance quickly becomes a concern, but Java RTS has considered this case.
Array Splitting and Caching
Arrays tend to be the largest objects in the heap, and are therefore more than likely to be split across non-contiguous free blocks. Therefore, array access is optimized through the use of an internal index. The best performance is achieved when the array index is contained within a single block. However, through the use of an internal VM array index cache, performance is still good even when the array is split. In the case of a cache miss (an array index that’s not in the cache), Java RTS uses a tree structure to locate the array block, within a bounded time frame. Therefore, in the worst-case, the time is O(log(n)) for array access on a block cache miss; however, this is relatively rare.
In the end, the important fact to remember regarding array object splitting, is that all effort is made to ensure bounded, relatively quick access to array indexes even when the array spans non-contiguous heap regions.
RTGC Policies
With its default settings, the Java RTS RTGC appears to operate differently to different application threads. For instance, to non-real-time threads (JLTs), it appears as a partially concurrent collector with stop-the-world pauses during its phases, where each phase runs to completion. To mid-range real-time threads, the RTGC appears as a fully concurrent collector that interferes with application progress very little during its phases. To critical real-time threads, the RTGC doesn’t even appear to exist. In fact, NoHeapRealtimeThreads will experience no delays from the RTGC regardless of the state of the VM or the heap.
This alone is an achievement, but its benefits don’t end there. Every effort has been made to build as much flexibility into the RTGC as possible. Through a multitude of command-line parameters (examined in Chapter 4), the behavior of the RTGC can be tuned, and its behavior modified, to best fit your application’s requirements. We’ll refer to the resulting modes of operation that can be attained through tuning as policies, and we’ll explore four sample policies now.
Full-Time RTGC Policy
By setting the proper command-line parameter values, you can configure the Java RTS RTGC to run almost continuously. This may not be something you wish to do on a uniprocessor server, as all lower-priority threads may suffer near-complete starvation. However, on a server with multiple processors and/or cores, this may be an ideal configuration, especially if your application has a high memory allocation rate.
By default, the RTGC will not start until free memory is nearly exhausted. For the most part, this is safe for two reasons:
• Once the RTGC does start, free memory will be produced concurrently without pausing application threads.
• A portion of the heap is reserved for critical real-time threads to further ensure there is free memory available to them.
However, in extreme cases, such as allocation bursts, or bursts of activity, even high-priority real-time threads may be blocked on allocation if the collector cannot keep up. Therefore, you may need to instruct the RTGC to begin each GC cycle sooner—before free memory is exhausted. Remember, though, that this may cause the RTGC to run more often, and hence will reduce application throughput. There’s no magic here; with more processor time dedicated to GC, less processor time is available to application threads. However, on a server with enough processor cores, there may be enough processing time available to both your application and RTGC to run together all the time. The configuration for this policy involves setting one additional command-line parameter: NormalMinFreeBytes.
The following example Java RTS command-line sets the total heap size to 1GB, and instructs the RTGC to begin a cycle when the amount of free memory drops below 1GB:
![]()
This command virtually guarantees that there will always be a need to start collecting. However, to further ensure that the RTGC runs continuously, you need to reduce the minimum amount of time it waits to start a new cycle when the previous one ends. You can do this by adding -XX:RTGCWaitDuration=0 to the above command.
Of course, any of these numbers can be configured differently. You can choose to start a GC cycle when 50% of the heap is exhausted, or 75%, and so on. Also, you can modify the pause time between cycles to be larger than zero, but smaller than the default of ten milliseconds. Finally, you may decide you want to run the RTGC continuously, but only on a subset of available processor cores. You can do this by combining the settings above with the segregated RTGC policy, defined in the next section.
Segregated RTGC Policy
Again, with only the proper command-line parameters, you can configure Java RTS to run only within a subset of available processors/cores (from this point onward, we will simply refer to both as cores). By default, the Java RTS RTGC will scale up its parallel processing according to the total number of cores available on the host server. With the segregated RTGC policy, you can’t bind RTGC threads to particular cores, but you can limit the number of threads it will run in parallel. This leaves other cores available to execute application threads.
To achieve this, recall the discussion on tuning the RTGC from Chapter 4. The RTGC will run in one of three modes: normal mode, boosted mode, and critical mode. The collector starts in normal mode (where RTGC threads run at lower priority), and progresses to boosted mode (where RTGC threads run at higher priority) if it cannot keep up with the application’s allocation rate. The RTGC will potentially enter critical mode (where all RTTs are blocked on allocation) if multiple cycles fail to free enough memory for the running application. Java RTS command-line parameters allow you to set the maximum number of worker threads that the RTGC will create while in normal and boosted modes.
A careful review of the GC logs (see Chapter 4 for details) will inform you of the amount of processor time (and hence cores) that the RTGC requires to produce enough free memory for your application. You should be able to determine the requirements for both normal mode, and boosted mode, if the RTGC had the need to run in that mode. Using this, you can safely confine the RTGC to a subset of cores accordingly, via the -XX:RTGCNormalWorkers and -XX:RTGCBoostedWorkers command-line settings. For example, the following command-line sets the maximum number of RTGC threads to two during normal mode, and four during boosted mode (assuming this is run on a server with at least four cores):
![]()
You can combine this policy with the full-time RTGC policy to instruct the RTGC to run continuously, but only on a subset of server cores. This combines the benefits of both policies, while ensuring that a predetermined number of cores are always available to your application (outside of other system activity). The combined command will look similar to the following example:
![]()
These numbers are for illustration only. You need to work with your application’s allocation needs, the target server capabilities, and the RTGC’s activity logs to determine what’s best for your specific deployment.
Note that you’re not restricted to command-line parameters only to alter the RTGC characteristics. Sun’s Java RTS provides an extension API, as part of the com.sun.rtsjx package, to allow you to monitor and alter the RTGC operation at runtime, through Java code within your application. As an example of how to use this API, let’s examine the time-based RTGC policy implementation now.
Time-Based RTGC Policy
Again, the Java RTS RTGC is based on the Henriksson-Lund real-time collection algorithm discussed in Chapter 2. However, if you prefer, you can make the RTGC behave as a time-based collector, similar to IBM’s Metronome GC [Stoodley07]. With this policy, the RTGC will run at very high priority, at predictable points in time, and for a set amount of time. Of course, with this policy, even your real-time threads will be interrupted at regular intervals, but at least the interruptions are deterministic. Let’s explore how this is achieved.
Unlike the previous two policies, which were achieved via command-line settings, this one requires working with the RTGC in Java code. The code in Listing 10-1 contains a controller class, named TimeBasedRTGC, which manipulates the RTGC to run according to a specified schedule.
Listing 10-1 The TimeBasedRTGC controller class


The TimeBasedRTGC class constructor takes a period and duration as parameters. The period indicates how often you want the RTGC start, such as every ten milliseconds. The duration indicates how long you want it to run at high priority, such as for one millisecond. This means that the duration value must be smaller than the period. In this implementation, all values are in milliseconds, with the smallest period or duration being one millisecond.
Using the Java RTS com.sun.rtsjx package, you can gain access to the garbage collector within the VM and monitor its activity, or control portions of its operation. Within the constructor, one of the very first checks is to make sure the Java RTS VM was started with the real-time collector, as opposed to the serial collector. Next, the current settings for the RTGC’s normal mode priority, and its critical mode priority, are stored. The code will explicitly boost the RTGC to the critical mode priority for the specified duration. These values are platform-dependent, and are configurable via the command line; therefore there was no reason to hard-code them in this class.
Next, a simple listener class, PriorityHandler, is added to receive and log GC priority change events. This class is actually an RTSJ Asynchronous Event Handler (AEH) class, and is provided through the call to FullyConcurrentGarbageCollector.addPriorityHandler. There are other GC-related events that can be received via an AEH, such as GC start and end events, if your application is interested in this information. The PriorityHandler AEH is included simply for demonstration purposes, and can be removed from the actual implementation.
Finally, a periodic RealtimeThread is created, at high priority, to control the RTGC operation according to the supplied period and duration. The period of the RTT is set to the period value supplied in the TimeBasedRTGC class constructor. All of the controller code is contained in the run method, within a while loop.
Each time the periodic RTT wakes up, it starts the RTGC, boosts its priority immediately, and then waits for the duration specified using the HighResolutionTime class. This ensures that the RTGC will run at boosted priority for precisely the duration given. When the timer expires, the RTT sets the RTGC back to its normal priority, and waits for the next period.
As an example of how simple it is to activate the time-based RTGC policy with this code, simply instantiate the TimeBasedRTGC class with the period and run duration, as shown in Listing 10-2, and continue with your application processing.
Listing 10-2 Using the TimeBasedRTGC class

Of course, there is no guarantee that the RTGC will run for the full duration given, as there may not be enough work for it to perform. However, you will be guaranteed that the RTGC won’t run at boosted priority for any length of time greater than the duration you specify. Also, most importantly, it’s assumed that most people will not want to run the RTGC in this way, as any time-based collector has the following risks:
• The duration is not long enough to produce enough free memory.
• The duration represents the minimum latency that the application can guarantee.
This code serves as an exercise in understanding how you can monitor and manipulate the RTGC from your application, if needed. However, let’s examine an RTGC policy that we find works well in many cases, which you can configure for your real-time applications as well. It’s called the isolated RTGC policy.
Isolated RTGC Policy
One approach to RTGC tuning that we find applicable to many Java RTS applications is called the isolated RTGC policy. In this case, RTGC threads are isolated from the application’s time-critical real-time threads by binding RTTs and/or NHRTs to processor sets. As also covered in Chapter 4, defining processor sets in both Solaris and Linux is straightforward.
This policy may seem identical to the segregated RTGC policy discussed previously. However, while both effectively limit the RTGC to a subset of processors, the isolated policy dedicates the same subset of cores to your critical threads. This has an advantage in that it removes potential context switching and CPU cache-related issues from the latency equation. It also allows the RTGC to self-tune and run on all of the remaining processors not in the processor set.
However, the disadvantage is that while the application time-critical threads (RTTs and/or NHRTs) are otherwise idle, the processors in the processor set to which they’re bound are unavailable to execute any other code in the system. As a result, even when idle, those processors are unavailable to execute RTGC threads or any other non-real-time threads within the Java RTS VM. As with any tuning exercise, the benefits of this policy are best quantified through testing with your particular application. With careful analysis and planning, however, this configuration can help to yield the smallest latency and greatest determinism for a Java RTS application.
To configure it, you need to create a processor set (see Chapter 4 for details), and use one of the related command-line options, as in this example:
![]()
There are four total command-line options related to processor binding of threads within the Java RTS VM. There are two sets of two—one for Linux, and the other for Solaris—where each set contains an option for RTTs, and the other for NHRTs. See Chapter 4 for a complete explanation and set of examples to illustrate.