
Chapter 3. Understanding the MapR Distribution for Apache Hadoop
The Hadoop distribution provided by MapR Technologies contains Apache Hadoop and more. We’re not just talking about the Hadoop ecosystem tools that ship with MapR—there are many, including almost all of those described in Chapter 2—but rather some special capabilities of MapR itself. These MapR-specific characteristics are the topic of this chapter because the real-world stories in this book are based on how MapR customers are using Apache Hadoop and the MapR NoSQL database, MapR-DB, to meet their large-scale computing needs in a variety of projects. The goal is to show you the benefits of Hadoop when used for the right jobs.
To make sure that you get the most out of this book, regardless of what kind of Hadoop distribution you use, we alert you to any aspects of the use cases we describe here that are not directly generalizable because of extra features of MapR not included in other distributions. For example, MapR is API-compatible with Hadoop, so applications written to run on Hadoop will run on MapR, but, in addition, non-Hadoop applications will also run on MapR, and that’s unusual. We will describe how you might work around these issues if you are not using MapR.
Use of Existing Non-Hadoop Applications
One of the key distinctions with MapR is that it has a realtime, fully read-write filesystem. This means that you not only can interact with data stored on the cluster via Hadoop commands and applications, but you also can access data via traditional routes. Any program in any language that can access files on a Linux or Windows system can also access files in the MapR cluster using the same traditional mechanisms. This compatibility is made possible primarily because the MapR file system (MapR-FS) allows access to files via NFS. This is very different from HDFS, the file system that other major Hadoop distributions use for distributed data storage.
What are the implications of MapR-FS being a read/write POSIX file system accessible via NFS or Hadoop commands? One effect is that existing applications can be used directly, without needing to rewrite them as Hadoop applications. In contrast, when using with other Hadoop distributions, the workflow generally includes steps in which data is copied out of the Hadoop file system to local files to be available for traditional tools and applications. The output of these applications is then copied back into the HDFS cluster. This doesn’t mean the use cases described in this book are only for MapR, but some of the details of the workflow may be somewhat different with other Hadoop distributions. For instance the workflow would need to include time to write Hadoop-specific code to access data and run applications, and the team doing so would need to be well versed in how HDFS file APIs differ from more traditional file APIs.
In case you are curious about the reason for this difference in MapR’s ability to use traditional code, as well as some of MapR’s other specific capabilities, here’s a brief technical explanation. One key difference lies in the size of the units used to manipulate and track files in a MapR cluster as compared with HDFS. As illustrated in Figure 3-1, files in HDFS files are broken into blocks of a fixed size. The default value for these blocks is 128 megabytes. The value can be changed, but it still applies across all files in the cluster. The block size is fundamental to how HDFS tracks files in a central system called the name node. Every change in the size or other properties of the file aside from the content of the file itself must be sent to the name node in order to keep track of all pieces of all the files in the cluster. HDFS blocks are the unit of allocation, and once written, they are never updated. This has several logical consequences, including:
- Realtime use of HDFS is difficult or impossible. This happens because every write to a file extends the length of the file when the write is committed. That means every such change requires talking to the name node, so programs try to avoid committing writes too often. In fact, it is common for multiple blocks to be flushed at once.
- The consistency model of HDFS is such that readers cannot be allowed to read files while a writer still has them open for writing.
- Out-of-order writes cannot be allowed because they would constitute updates to the file.
- A name node has to keep track of all of the blocks of all of the files, and because this information can churn rapidly while programs are running, this information has to be kept in memory. This means the name node’s memory size is proportional to the number of blocks that can be tracked. That number times the block size is the scalability limit of an HDFS file system.
These consequences made HDFS much easier to implement originally, but they make it much harder for it to work in real time (which implies readers can see data instantly and writers can flush often), to scale to very large sizes (because of the limited number of blocks), or to support first-class access via NFS (because NFS inherently reorders writes and has no concept of an open file).
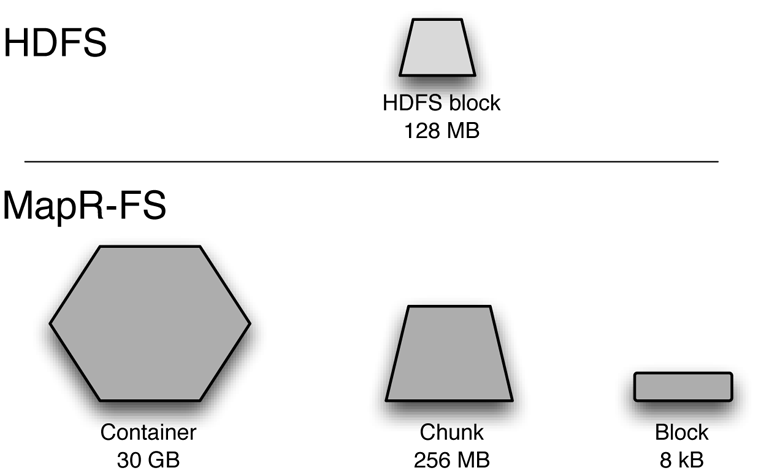
In contrast, MapR has no name node at all. Metadata for files and directories is spread across the entire cluster. MapR also has several kinds of data structures that operate at different sizes, with the largest unit being a huge data structure known as a container (30 GB), as depicted in Figure 3-1. There is no equivalent to the container in HDFS. In MapR-FS, the fundamental unit in which files are striped across the cluster is a chunk of configurable size, set by default at 256 MB. The smallest size that can be changed is quite small, 8 kB. The design decision to make blocks small not only enables MapR-FS to allow random updates to files, it also allows MapR-FS to function as a realtime file system, as we discuss in the next section.
All changes to files are reported back to containers, not a name node, and there are containers all over the cluster. This means that meta-data updates are fast, and consequently writers can commit file writes very often and readers can see these updates almost instantly. By splitting the single HDFS design parameter of block size into three different design parameters of container, chunk, and block sizes that range over nine orders of magnitude, MapR-FS is able to do different things than HDFS can do.
Making Use of a Realtime Distributed File System
Among the prototypical use cases in Chapter 5, we discuss the need for realtime analytics running in a Hadoop-based system. Historically, Hadoop supported parallel computation via a batch compute model known as MapReduce. HDFS, the original Hadoop file system, is well suited to the loads that MapReduce imposes. HDFS, however, is not particularly well suited to direct use by realtime operations. To get around this, data is often stored in memory until a large amount can be flushed at once. This is how HBase works, for instance. Such applications must checkpoint their work rather often, however, to make sure that they can be restarted without data loss.
The point to be made here is that the realtime nature of the MapR file system with its NoSQL database, MapR-DB, changes the response-time parameters that are reasonable goals for projects employing realtime processing applications. As with any Hadoop distribution, it’s important to use Hadoop or NoSQL for the right jobs, but with MapR, subsecond response times without complex workarounds are very much within reach.
Meeting SLAs
When you make guarantees in the form of SLAs for uninterrupted performance, high availability, or fast response times, it is important to make sure that your Hadoop system is well suited for the requirements of the jobs for which you plan to use it. In other words, make sure you are planning to use it for jobs it can do well.
As an example, some MapR customers such as the Aadhaar project mentioned in Chapter 1 are using MapR-DB to store and access data in delay-critical applications. The applications involved often have stringent response time limits. MapR-DB has very tightly constrained response times with no compaction delays. These characteristics make meeting response time SLAs much easier. Systems like HBase are much more difficult to use in these situations because HBase has had to be designed with HDFS limitations in mind and therefore does things like write data in large increments. This can occasionally lead to very long response times. In such situations, the use cases are to some extent MapR specific, not because of any specific feature, but due to predictability. Whatever Hadoop system you are running, you should match its capabilities well to requirements of the particular job of interest in a realistic way in order to be successful.
Deploying Data at Scale to Remote Locations
There are two major reasons to deploy data to remote sites in large-scale systems. One is to make identical data available at multiple processing centers or divisions of a company in different locales. Another purpose is to provide a secondary data center that serves as an off-site duplication of critical data in case of disaster. Both of these needs can be met using MapR’s mirroring feature, unique among Hadoop distributions. MapR mirrors are fully consistent incremental copies of data that appear at remote locations atomically. During mirroring, the changes in the data are sent from a source cluster to mirror volumes on the destination cluster. As they arrive, the changes are applied to a snapshot copy of the destination, and when they complete, the snapshot is exposed.
Use cases that depend on mirroring may be possible to implement with HDFS-based Hadoop distributions by simply copying all of the data to the destination machines. If new data can be segregated from old data in specific directories, then this copying can sometimes be set up to avoid excessive data motion. Application cooperation can make sure that partial copies are not processed before they have safely arrived. If this level of management and careful design is an option, then you may be able to achieve similar results without mirroring.
Consistent Data Versioning
MapR’s fully consistent snapshots are a specialized feature that makes it possible to have an accurate view of data from an exact point in time. Not only can they be used as a protection against data loss from human error (fat finger syndrome) or software bugs, but consistent snapshots also serve as a means for data versioning. The latter can be particularly useful for preserving an unchanging version of training data for machine learning models or for forensic analysis, in which it is important to be able to demonstrate exactly what was known and when.
HDFS supports a feature called snapshots, but these snapshots are not consistent, nor are they precise. Files that are being updated when a snapshot is made can continue to change after the snapshot is completed. If, however, you arrange to only snapshot directories that have no files being actively changed, then you may be able to use HDFS snapshots (sometimes called fuzzy snapshots) for the same purposes as the atomic and consistent snapshots such as those available with MapR.
Finding the Keys to Success
Now that you have a grounding in how Hadoop works and in the special additional options you may encounter in MapR use cases, let’s address the question, “What decisions drive successful Hadoop projects?” In the next chapter we provide a collection of tips drawn from the decisions that have helped to drive success in existing Hadoop and NoSQL projects. Whether you are new to Hadoop or one of the Hadoop pioneers yourself, you may find the advice offered in Chapter 4 is helpful in planning your next step with Hadoop.