
Chapter 2
Principles in Refactoring
The example in the previous chapter should have given you a decent feel of what refactoring is. Now you have that, it’s a good time to step back and talk about some of the broader principles in refactoring.
Defining Refactoring
Like many terms in software development, “refactoring” is often used very loosely by practitioners. I use the term more precisely, and find it useful to use it in that more precise form. (These definitions are the same as those I gave in the first edition of this book.) The term “refactoring” can be used either as a noun or a verb. The noun’s definition is:
Refactoring (noun): a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior.
This definition corresponds to the named refactorings I’ve mentioned in the earlier examples, such as Extract Function (106) and Replace Conditional with Polymorphism (272).
The verb’s definition is:
Refactoring (verb): to restructure software by applying a series of refactorings without changing its observable behavior.
So I might spend a couple of hours refactoring, during which I would apply a few dozen individual refactorings.
Over the years, many people in the industry have taken to use “refactoring” to mean any kind of code cleanup—but the definitions above point to a particular approach to cleaning up code. Refactoring is all about applying small behavior-preserving steps and making a big change by stringing together a sequence of these behavior-preserving steps. Each individual refactoring is either pretty small itself or a combination of small steps. As a result, when I’m refactoring, my code doesn’t spend much time in a broken state, allowing me to stop at any moment even if I haven’t finished.
 If someone says their code was broken for a couple of days while they are refactoring, you can be pretty sure they were not refactoring.
If someone says their code was broken for a couple of days while they are refactoring, you can be pretty sure they were not refactoring.
I use “restructuring” as a general term to mean any kind of reorganizing or cleaning up of a code base, and see refactoring as a particular kind of restructuring. Refactoring may seem inefficient to people who first come across it and watch me making lots of tiny steps, when a single bigger step would do. But the tiny steps allow me to go faster because they compose so well—and, crucially, because I don’t spend any time debugging.
In my definitions, I use the phrase “observable behavior.” This is a deliberately loose term, indicating that the code should, overall, do just the same things it did before I started. It doesn’t mean it will work exactly the same—for example, Extract Function (106) will alter the call stack, so performance characteristics might change—but nothing should change that the user should care about. In particular, interfaces to modules often change due to such refactorings as Change Function Declaration (124) and Move Function (198). Any bugs that I notice during refactoring should still be present after refactoring (though I can fix latent bugs that nobody has observed yet).
Refactoring is very similar to performance optimization, as both involve carrying out code manipulations that don’t change the overall functionality of the program. The difference is the purpose: Refactoring is always done to make the code “easier to understand and cheaper to modify.” This might speed things up or slow things down. With performance optimization, I only care about speeding up the program, and am prepared to end up with code that is harder to work with if I really need that improved performance.
The Two Hats
Kent Beck came up with a metaphor of the two hats. When I use refactoring to develop software, I divide my time between two distinct activities: adding functionality and refactoring. When I add functionality, I shouldn’t be changing existing code; I’m just adding new capabilities. I measure my progress by adding tests and getting the tests to work. When I refactor, I make a point of not adding functionality; I only restructure the code. I don’t add any tests (unless I find a case I missed earlier); I only change tests when I have to accommodate a change in an interface.
As I develop software, I find myself swapping hats frequently. I start by trying to add a new capability, then I realize this would be much easier if the code were structured differently. So I swap hats and refactor for a while. Once the code is better structured, I swap hats back and add the new capability. Once I get the new capability working, I realize I coded it in a way that’s awkward to understand, so I swap hats again and refactor. All this might take only ten minutes, but during this time I’m always aware of which hat I’m wearing and the subtle difference that makes to how I program.
Why Should We Refactor?
I don’t want to claim refactoring is the cure for all software ills. It is no “silver bullet.” Yet it is a valuable tool—a pair of silver pliers that helps you keep a good grip on your code. Refactoring is a tool that can—and should—be used for several purposes.
Refactoring Improves the Design of Software
Without refactoring, the internal design—the architecture—of software tends to decay. As people change code to achieve short-term goals, often without a full comprehension of the architecture, the code loses its structure. It becomes harder for me to see the design by reading the code. Loss of the structure of code has a cumulative effect. The harder it is to see the design in the code, the harder it is for me to preserve it, and the more rapidly it decays. Regular refactoring helps keep the code in shape.
Poorly designed code usually takes more code to do the same things, often because the code quite literally does the same thing in several places. Thus an important aspect of improving design is to eliminate duplicated code. It’s not that reducing the amount of code will make the system run any faster—the effect on the footprint of the programs rarely is significant. Reducing the amount of code does, however, make a big difference in modification of the code. The more code there is, the harder it is to modify correctly. There’s more code for me to understand. I change this bit of code here, but the system doesn’t do what I expect because I didn’t change that bit over there that does much the same thing in a slightly different context. By eliminating duplication, I ensure that the code says everything once and only once, which is the essence of good design.
Refactoring Makes Software Easier to Understand
Programming is in many ways a conversation with a computer. I write code that tells the computer what to do, and it responds by doing exactly what I tell it. In time, I close the gap between what I want it to do and what I tell it to do. Programming is all about saying exactly what I want. But there are likely to be other users of my source code. In a few months, a human will try to read my code to make some changes. That user, who we often forget, is actually the most important. Who cares if the computer takes a few more cycles to compile something? Yet it does matter if it takes a programmer a week to make a change that would have taken only an hour with proper understanding of my code.
The trouble is that when I’m trying to get the program to work, I’m not thinking about that future developer. It takes a change of rhythm to make the code easier to understand. Refactoring helps me make my code more readable. Before refactoring, I have code that works but is not ideally structured. A little time spent on refactoring can make the code better communicate its purpose—say more clearly what I want.
I’m not necessarily being altruistic about this. Often, this future developer is myself. This makes refactoring even more important. I’m a very lazy programmer. One of my forms of laziness is that I never remember things about the code I write. Indeed, I deliberately try not remember anything I can look up, because I’m afraid my brain will get full. I make a point of trying to put everything I should remember into the code so I don’t have to remember it. That way I’m less worried about Maudite [maudite] killing off my brain cells.
Refactoring Helps Me Find Bugs
Help in understanding the code also means help in spotting bugs. I admit I’m not terribly good at finding bugs. Some people can read a lump of code and see bugs; I cannot. However, I find that if I refactor code, I work deeply on understanding what the code does, and I put that new understanding right back into the code. By clarifying the structure of the program, I clarify certain assumptions I’ve made—to a point where even I can’t avoid spotting the bugs.
It reminds me of a statement Kent Beck often makes about himself: “I’m not a great programmer; I’m just a good programmer with great habits.” Refactoring helps me be much more effective at writing robust code.
Refactoring Helps Me Program Faster
In the end, all the earlier points come down to this: Refactoring helps me develop code more quickly.
This sounds counterintuitive. When I talk about refactoring, people can easily see that it improves quality. Better internal design, readability, reducing bugs—all these improve quality. But doesn’t the time I spend on refactoring reduce the speed of development?
When I talk to software developers who have been working on a system for a while, I often hear that they were able to make progress rapidly at first, but now it takes much longer to add new features. Every new feature requires more and more time to understand how to fit it into the existing code base, and once it’s added, bugs often crop up that take even longer to fix. The code base starts looking like a series of patches covering patches, and it takes an exercise in archaeology to figure out how things work. This burden slows down adding new features—to the point that developers wish they could start again from a blank slate.
I can visualize this state of affairs with the following pseudograph:
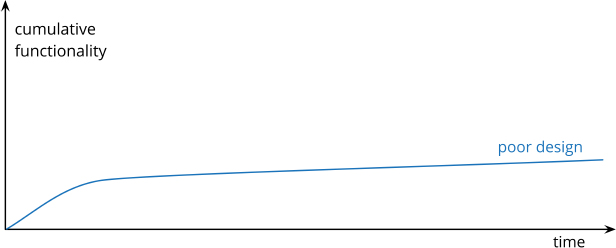
But some teams report a different experience. They find they can add new features faster because they can leverage the existing things by quickly building on what’s already there.

The difference between these two is the internal quality of the software. Software with a good internal design allows me to easily find how and where I need to make changes to add a new feature. Good modularity allows me to only have to understand a small subset of the code base to make a change. If the code is clear, I’m less likely to introduce a bug, and if I do, the debugging effort is much easier. Done well, my code base turns into a platform for building new features for its domain.
I refer to this effect as the Design Stamina Hypothesis [mf-dsh]: By putting our effort into a good internal design, we increase the stamina of the software effort, allowing us to go faster for longer. I can’t prove that this is the case, which is why I refer to it as a hypothesis. But it explains my experience, together with the experience of hundreds of great programmers that I’ve got to know over my career.
Twenty years ago, the conventional wisdom was that to get this kind of good design, it had to be completed before starting to program—because once we wrote the code, we could only face decay. Refactoring changes this picture. We now know we can improve the design of existing code—so we can form and improve a design over time, even as the needs of the program change. Since it is very difficult to do a good design up front, refactoring becomes vital to achieving that virtuous path of rapid functionality.
When Should We Refactor?
Refactoring is something I do every hour I program. I have noticed a number of ways it fits into my workflow.
Preparatory Refactoring—Making It Easier to Add a Feature
The best time to refactor is just before I need to add a new feature to the code base. As I do this, I look at the existing code and, often, see that if it were structured a little differently, my work would be much easier. Perhaps there’s function that does almost all that I need, but has some literal values that conflict with my needs. Without refactoring I might copy the function and change those values. But that leads to duplicated code—if I need to change it in the future, I’ll have to change both spots (and, worse, find them). And copy-paste won’t help me if I need to make a similar variation for a new feature in the future. So with my refactoring hat on, I use Parameterize Function (310). Once I’ve done that, all I have to do is call the function with the parameters I need.
“It’s like I want to go 100 miles east but instead of just traipsing through the woods, I’m going to drive 20 miles north to the highway and then I’m going to go 100 miles east at three times the speed I could have if I just went straight there. When people are pushing you to just go straight there, sometimes you need to say, ‘Wait, I need to check the map and find the quickest route.’ The preparatory refactoring does that for me.”
— Jessica Kerr,https://martinfowler.com/articles/preparatory-refactoring-example.html
The same happens when fixing a bug. Once I’ve found the cause of the problem, I see that it would be much easier to fix should I unify the three bits of copied code causing the error into one. Or perhaps separating some update logic from queries will make it easier to avoid the tangling that’s causing the error. By refactoring to improve the situation, I also increase the chances that the bug will stay fixed, and reduce the chances that others will appear in the same crevices of the code.
Comprehension Refactoring: Making Code Easier to Understand
Before I can change some code, I need to understand what it does. This code may have been written by me or by someone else. Whenever I have to think to understand what the code is doing, I ask myself if I can refactor the code to make that understanding more immediately apparent. I may be looking at some conditional logic that’s structured awkwardly. I may have wanted to use some existing functions but spent several minutes figuring out what they did because they were named badly.
At that point I have some understanding in my head, but my head isn’t a very good record of such details. As Ward Cunningham puts it, by refactoring I move the understanding from my head into the code itself. I then test that understanding by running the software to see if it still works. If I move my understanding into the code, it will be preserved longer and be visible to my colleagues.
That doesn’t just help me in the future—it often helps me right now. Early on, I do comprehension refactoring on little details. I rename a couple variables now that I understand what they are, or I chop a long function into smaller parts. Then, as the code gets clearer, I find I can see things about the design that I could not see before. Had I not changed the code, I probably never would have seen these things, because I’m just not clever enough to visualize all these changes in my head. Ralph Johnson describes these early refactorings as wiping the dirt off a window so you can see beyond. When I’m studying code, refactoring leads me to higher levels of understanding that I would otherwise miss. Those who dismiss comprehension refactoring as useless fiddling with the code don’t realize that by foregoing it they never see the opportunities hidden behind the confusion.
Litter-Pickup Refactoring
A variation of comprehension refactoring is when I understand what the code is doing, but realize that it’s doing it badly. The logic is unnecessarily convoluted, or I see functions that are nearly identical and can be replaced by a single parameterized function. There’s a bit of a tradeoff here. I don’t want to spend a lot of time distracted from the task I’m currently doing, but I also don’t want to leave the trash lying around and getting in the way of future changes. If it’s easy to change, I’ll do it right away. If it’s a bit more effort to fix, I might make a note of it and fix it when I’m done with my immediate task.
Sometimes, of course, it’s going to take a few hours to fix, and I have more urgent things to do. Even then, however, it’s usually worthwhile to make it a little bit better. As the old camping adage says, always leave the camp site cleaner than when you found it. If I make it a little better each time I pass through the code, over time it will get fixed. The nice thing about refactoring is that I don’t break the code with each small step—so, sometimes, it takes months to complete the job but the code is never broken even when I’m part way through it.
Planned and Opportunistic Refactoring
The examples above—preparatory, comprehension, litter-pickup refactoring—are all opportunistic. I don’t set aside time at the beginning to spend on refactoring—instead, I do refactoring as part of adding a feature or fixing a bug. It’s part of my natural flow of programming. Whether I’m adding a feature or fixing a bug, refactoring helps me do the immediate task and also sets me up to make future work easier. This is an important point that’s frequently missed. Refactoring isn’t an activity that’s separated from programming—any more than you set aside time to write if statements. I don’t put time on my plans to do refactoring; most refactoring happens while I’m doing other things.
You have to refactor when you run into ugly code—but excellent code needs plenty of refactoring too.
It’s also a common error to see refactoring as something people do to fix past mistakes or clean up ugly code. Certainly you have to refactor when you run into ugly code, but excellent code needs plenty of refactoring too. Whenever I write code, I’m making tradeoffs—how much do I need to parameterize, where to draw the lines between functions? The tradeoffs I made correctly for yesterday’s feature set may no longer be the right ones for the new features I’m adding today. The advantage is that clean code is easier to refactor when I need to change those tradeoffs to reflect the new reality.
“for each desired change, make the change easy (warning: this may be hard), then make the easy change”
— Kent Beck,https://twitter.com/kentbeck/status/250733358307500032
For a long time, people thought of writing software as a process of accretion: To add new features, we should be mostly adding new code. But good developers know that, often, the fastest way to add a new feature is to change the code to make it easy to add. Software should thus be never thought of as “done.” As new capabilities are needed, the software changes to reflect that. Those changes can often be greater in the existing code than in the new code.
All this doesn’t mean that planned refactoring is always wrong. If a team has neglected refactoring, it often needs dedicated time to get their code base into a better state for new features, and a week spent refactoring now can repay itself over the next couple of months. Sometimes, even with regular refactoring I’ll see a problem area grow to the point when it needs some concerted effort to fix. But such planned refactoring episodes should be rare. Most refactoring effort should be the unremarkable, opportunistic kind.
One bit of advice I’ve heard is to separate refactoring work and new feature additions into different version-control commits. The big advantage of this is that they can be reviewed and approved independently. I’m not convinced of this, however. Too often, the refactorings are closely interwoven with adding new features, and it’s not worth the time to separate them out. This can also remove the context for the refactoring, making the refactoring commits hard to justify. Each team should experiment to find what works for them; just remember that separating refactoring commits is not a self-evident principle—it’s only worthwhile if it makes life easier.
Long-Term Refactoring
Most refactoring can be completed within a few minutes—hours at most. But there are some larger refactoring efforts that can take a team weeks to complete. Perhaps they need to replace an existing library with a new one. Or pull some section of code out into a component that they can share with another team. Or fix some nasty mess of dependencies that they had allowed to build up.
Even in such cases, I’m reluctant to have a team do dedicated refactoring. Often, a useful strategy is to agree to gradually work on the problem over the course of the next few weeks. Whenever anyone goes near any code that’s in the refactoring zone, they move it a little way in the direction they want to improve. This takes advantage of the fact that refactoring doesn’t break the code—each small change leaves everything in a still-working state. To change from one library to another, start by introducing a new abstraction that can act as an interface to either library. Once the calling code uses this abstraction, it’s much easier to switch one library for another. (This tactic is called Branch By Abstraction [mf-bba].)
Refactoring in a Code Review
Some organizations do regular code reviews; those that don’t would do better if they did. Code reviews help spread knowledge through a development team. Reviews help more experienced developers pass knowledge to those less experienced. They help more people understand more aspects of a large software system. They are also very important in writing clear code. My code may look clear to me but not to my team. That’s inevitable—it’s hard for people to put themselves in the shoes of someone unfamiliar with whatever they are working on. Reviews also give the opportunity for more people to suggest useful ideas. I can only think of so many good ideas in a week. Having other people contribute makes my life easier, so I always look for reviews.
I’ve found that refactoring helps me review someone else’s code. Before I started using refactoring, I could read the code, understand it to some degree, and make suggestions. Now, when I come up with ideas, I consider whether they can be easily implemented then and there with refactoring. If so, I refactor. When I do it a few times, I can see more clearly what the code looks like with the suggestions in place. I don’t have to imagine what it would be like—I can see it. As a result, I can come up with a second level of ideas that I would never have realized had I not refactored.
Refactoring also helps get more concrete results from the code review. Not only are there suggestions; many suggestions are implemented there and then. You end up with much more of a sense of accomplishment from the exercise.
How I’d embed refactoring into a code review depends on the nature of the review. The common pull request model, where a reviewer looks at code without the original author, doesn’t work too well. It’s better to have the original author of the code present because the author can provide context on the code and fully appreciate the reviewers’ intentions for their changes. I’ve had my best experiences with this by sitting one-on-one with the original author, going through the code and refactoring as we go. The logical conclusion of this style is pair programming: continuous code review embedded within the process of programming.
What Do I Tell My Manager?
One of the most common questions I’ve been asked is, “How to tell a manager about refactoring?” I’ve certainly seen places were refactoring has become a dirty word—with managers (and customers) believing that refactoring is either correcting errors made earlier, or work that doesn’t yield valuable features. This is exacerbated by teams scheduling weeks of pure refactoring—especially if what they are really doing is not refactoring but less careful restructuring that causes breakages in the code base.
To a manager who is genuinely savvy about technology and understands the design stamina hypothesis, refactoring isn’t hard to justify. Such managers should be encouraging refactoring on a regular basis and be looking for signs that indicate a team isn’t doing enough. While it does happen that teams do too much refactoring, it’s much rarer than teams not doing enough.
Of course, many managers and customer don’t have the technical awareness to know how code base health impacts productivity. In these cases I give my more controversial advice: Don’t tell!
Subversive? I don’t think so. Software developers are professionals. Our job is to build effective software as rapidly as we can. My experience is that refactoring is a big aid to building software quickly. If I need to add a new function and the design does not suit the change, I find it’s quicker to refactor first and then add the function. If I need to fix a bug, I need to understand how the software works—and I find refactoring is the fastest way to do this. A schedule-driven manager wants me to do things the fastest way I can; how I do it is my responsibility. I’m being paid for my expertise in programming new capabilities fast, and the fastest way is by refactoring—therefore I refactor.
When Should I Not Refactor?
It may sound like I always recommend refactoring—but there are cases when it’s not worthwhile.
If I run across code that is a mess, but I don’t need to modify it, then I don’t need to refactor it. Some ugly code that I can treat as an API may remain ugly. It’s only when I need to understand how it works that refactoring gives me any benefit.
Another case is when it’s easier to rewrite it than to refactor it. This is a tricky decision. Often, I can’t tell how easy it is to refactor some code unless I spend some time trying and thus get a sense of how difficult it is. The decision to refactor or rewrite requires good judgment and experience, and I can’t really boil it down into a piece of simple advice.
Problems with Refactoring
Whenever anyone advocates for some technique, tool, or architecture, I always look for problems. Few things in life are all sunshine and clear skies. You need to understand the tradeoffs to decide when and where to apply something. I do think refactoring is a valuable technique—one that should be used more by most teams. But there are problems associated with it, and it’s important to understand how they manifest themselves and how we can react to them.
Slowing Down New Features
If you read the previous section, you should already know my response. Although many people see time spent refactoring as slowing down the development of new features, the whole purpose of refactoring is to speed things up. But while this is true, it’s also true that the perception of refactoring as slowing things down is still common—and perhaps the biggest barrier to people doing enough refactoring.
The whole purpose of refactoring is to make us program faster, producing more value with less effort.
There is a genuine tradeoff here. I do run into situations where I see a (large-scale) refactoring that really needs to be done, but the new feature I want to add is so small that I prefer to add it and leave the larger refactoring alone. That’s a judgment call—part of my professional skills as a programmer. I can’t easily describe, let alone quantify, how I make that tradeoff.
I’m very conscious that preparatory refactoring often makes a change easier, so I certainly will do it if I see that it makes my new feature easier to implement. I’m also more inclined to refactor if this is a problem I’ve seen before—sometimes it takes me a couple of times seeing some particular ugliness before I decide to refactor it away. Conversely, I’m more likely to not refactor if it’s part of the code I rarely touch and the cost of the inconvenience isn’t something I feel very often. Sometimes, I delay a refactoring because I’m not sure what improvement to do, although at other times I’ll try something as an experiment to see if it makes things better.
Still, the evidence I hear from my colleagues in the industry is that too little refactoring is far more prevalent than too much. In other words, most people should try to refactor more often. You may have trouble telling the difference in productivity between a healthy and a sickly code base because you haven’t had enough experience of a healthy code base—of the power that comes from easily combining existing parts into new configurations to quickly enable complicated new features.
Although it’s often managers that are criticized for the counter-productive habit of squelching refactoring in the name of speed, I’ve often seen developers do it to themselves. Sometimes, they think they shouldn’t be refactoring even though their leadership is actually in favor. If you’re a tech lead in a team, it’s important to show team members that you value improving the health of a code base. That judgment I mentioned earlier on whether to refactor or not is something that takes years of experience to build up. Those with less experience in refactoring need lots of mentoring to accelerate them through the process.
But I think the most dangerous way that people get trapped is when they try to justify refactoring in terms of “clean code,” “good engineering practice,” or similar moral reasons. The point of refactoring isn’t to show how sparkly a code base is—it is purely economic. We refactor because it makes us faster—faster to add features, faster to fix bugs. It’s important to keep that in front of your mind and in front of communication with others. The economic benefits of refactoring should always be the driving factor, and the more that is understood by developers, managers, and customers, the more of the “good design” curve we’ll see.
Code Ownership
Many refactorings involve making changes that affect not just the internals of a module but its relationships with other parts of a system. If I want to rename a function, and I can find all the callers to a function, I simply apply Change Function Declaration (124) and change the declaration and the callers in one change. But sometimes this simple refactoring isn’t possible. Perhaps the calling code is owned by a different team and I don’t have write access to their repository. Perhaps the function is a declared API used by my customers—so I can’t even tell if it’s being used, let alone by who and how much. Such functions are part of a published interface—an interface that is used by clients independent of those who declare the interface.
Code ownership boundaries get in the way of refactoring because I cannot make the kinds of changes I want without breaking my clients. This doesn’t prevent refactoring—I can still do a great deal—but it does impose limitations. When renaming a function, I need to use Rename Function (124) and to retain the old declaration as a pass-through to the new one. This complicates the interface—but it is the price I must pay to avoid breaking my clients. I may be able to mark the old interface as deprecated and, in time, retire it, but sometimes I have to retain that interface forever.
Due to these complexities, I recommend against fine-grained strong code ownership. Some organizations like any piece of code to have a single programmer as an owner, and only allow that programmer to change it. I’ve seen a team of three people operate in such a way that each one published interfaces to the other two. This led to all sorts of gyrations to maintain interfaces when it would have been much easier to go into the code base and make the edits. My preference is to allow team ownership of code—so that anyone in the same team can modify the team’s code, even if originally written by someone else. Programmers may have individual responsibility for areas of a system, but that should imply that they monitor changes to their area of responsibility, not block them by default.
Such a more permissive ownership scheme can even exist across teams. Some teams encourage an open-source-like model where people from other teams can change a branch of their code and send the commit in to be approved. This allows one team to change the clients of their functions—they can delete the old declarations once their commits to their clients have been accepted. This can often be a good compromise between strong code ownership and chaotic changes in large systems.
Branches
As I write this, a common approach in teams is for each team member to work on a branch of the code base using a version control system, and do considerable work on that branch before integrating with a mainline (often called master or trunk) shared across the team. Often, this involves building a whole feature on a branch, not integrating into the mainline until the feature is ready to be released into production. Fans of this approach claim that it keeps the mainline clear of any in-process code, provides a clear version history of feature additions, and allows features to be reverted easily should they cause problems.
There are downsides to feature branches like this. The longer I work on an isolated branch, the harder the job of integrating my work with mainline is going to be when I’m done. Most people reduce this pain by frequently merging or re-basing from mainline to my branch. But this doesn’t really solve the problem when several people are working on individual feature branches. I distinguish between merging and integration. If I merge mainline into my code, this is a oneway movement—my branch changes but the mainline doesn’t. I use “integrate” to mean a two-way process that pulls changes from mainline into my branch and then pushes the result back into mainline, changing both. If Rachel is working on her branch I don’t see her changes until she integrates with mainline; at that point, I have to merge her changes into my feature branch, which may mean considerable work. The hard part of this work is dealing with semantic changes. Modern version control systems can do wonders with merging complex changes to the program text, but they are blind to the semantics of the code. If I’ve changed the name of a function, my version control tool may easily integrate my changes with Rachel’s. But if, in her branch, she added a call to a function that I’ve renamed in mine, the code will fail.
The problem of complicated merges gets exponentially worse as the length of feature branches increases. Integrating branches that are four weeks old is more than twice as hard as those that are a couple of weeks old. Many people, therefore, argue for keeping feature branches short—perhaps just a couple of days. Others, such as me, want them even shorter than that. This is an approach called Continuous Integration (CI), also known as Trunk-Based Development. With CI, each team member integrates with mainline at least once per day. This prevents any branches diverting too far from each other and thus greatly reduces the complexity of merges. CI doesn’t come for free: It means you use practices to ensure the mainline is healthy, learn to break large features into smaller chunks, and use feature toggles (aka feature flags) to switch off any in-process features that can’t be broken down.
Fans of CI like it partly because it reduces the complexity of merges, but the dominant reason to favor CI is that it’s far more compatible with refactoring. Refactorings often involve making lots of little changes all over the code base—which are particularly prone to semantic merge conflicts (such as renaming a widely used function). Many of us have seen feature-branching teams that find refactorings so exacerbate merge problems that they stop refactoring. CI and re-factoring work well together, which is why Kent Beck combined them in Extreme Programming.
I’m not saying that you should never use feature branches. If they are sufficiently short, their problems are much reduced. (Indeed, users of CI usually also use branches, but integrate them with mainline each day.) Feature branches may be the right technique for open source projects where you have infrequent commits from programmers who you don’t know well (and thus don’t trust). But in a full-time development team, the cost that feature branches impose on refactoring is excessive. Even if you don’t go to full CI, I certainly urge you to integrate as frequently as possible. You should also consider the objective evidence [Forsgren et al.] that teams that use CI are more effective in software delivery.
Testing
One of the key characteristics of refactoring is that it doesn’t change the observable behavior of the program. If I follow the refactorings carefully, I shouldn’t break anything—but what if I make a mistake? (Or, knowing me, s/if/when.) Mistakes happen, but they aren’t a problem provided I catch them quickly. Since each refactoring is a small change, if I break anything, I only have a small change to look at to find the fault—and if I still can’t spot it, I can revert my version control to the last working version.
The key here is being able to catch an error quickly. To do this, realistically, I need to be able to run a comprehensive test suite on the code—and run it quickly, so that I’m not deterred from running it frequently. This means that in most cases, if I want to refactor, I need to have self-testing code [mf-stc].
To some readers, self-testing code sounds like a requirement so steep as to be unrealizable. But over the last couple of decades, I’ve seen many teams build software this way. It takes attention and dedication to testing, but the benefits make it really worthwhile. Self-testing code not only enables refactoring—it also makes it much safer to add new features, since I can quickly find and kill any bugs I introduce. The key point here is that when a test fails, I can look at the change I’ve made between when the tests were last running correctly and the current code. With frequent test runs, that will be only a few lines of code. By knowing it was those few lines that caused the failure, I can much more easily find the bug.
This also answers those who are concerned that refactoring carries too much risk of introducing bugs. Without self-testing code, that’s a reasonable worry—which is why I put so much emphasis on having solid tests.
There is another way to deal with the testing problem. If I use an environment that has good automated refactorings, I can trust those refactorings even without running tests. I can then refactor, providing I only use those refactorings that are safely automated. This removes a lot of nice refactorings from my menu, but still leaves me enough to deliver some useful benefits. I’d still rather have self-testing code, but it’s an option that is useful to have in the toolkit.
This also inspires a style of refactoring that only uses a limited set of refactorings that can be proven safe. Such refactorings require carefully following the steps, and are language-specific. But teams using them have found they can do useful refactoring on large code bases with poor test coverage. I don’t focus on that in this book, as it’s a newer, less described and understood technique that involves detailed, language-specific activity. (It is, however, something I hope talk about more on my web site in the future. For a taste of it, see Jay Bazuzi’s description [Bazuzi] of a safer way to do Extract Method (106) in C++.)
Self-testing code is, unsurprisingly, closely associated with Continuous Integration—it is the mechanism that we use to catch semantic integration conflicts. Such testing practices are another component of Extreme Programming and a key part of Continuous Delivery.
Legacy Code
Most people would regard a big legacy as a Good Thing—but that’s one of the cases where programmers’ view is different. Legacy code is often complex, frequently comes with poor tests, and, above all, is written by Someone Else (shudder).
Refactoring can be a fantastic tool to help understand a legacy system. Functions with misleading names can be renamed so they make sense, awkward programming constructs smoothed out, and the program turned from a rough rock to a polished gem. But the dragon guarding this happy tale is the common lack of tests. If you have a big legacy system with no tests, you can’t safely refactor it into clarity.
The obvious answer to this problem is that you add tests. But while this sounds a simple, if laborious, procedure, it’s often much more tricky in practice. Usually, a system is only easy to put under test if it was designed with testing in mind—in which case it would have the tests and I wouldn’t be worrying about it.
There’s no simple route to dealing with this. The best advice I can give is to get a copy of Working Effectively with Legacy Code [Feathers] and follow its guidance. Don’t be worried by the age of the book—its advice is just as true more than a decade later. To summarize crudely, it advises you to get the system under test by finding seams in the program where you can insert tests. Creating these seams involves refactoring—which is much more dangerous since it’s done without tests, but is a necessary risk to make progress. This is a situation where safe, automated refactorings can be a godsend. If all this sounds difficult, that’s because it is. Sadly, there’s no shortcut to getting out of a hole this deep—which is why I’m such a strong proponent of writing self-testing code from the start.
Even when I do have tests, I don’t advocate trying to refactor a complicated legacy mess into beautiful code all at once. What I prefer to do is tackle it in relevant pieces. Each time I pass through a section of the code, I try to make it a little bit better—again, like leaving a camp site cleaner than when I found it. If this is a large system, I’ll do more refactoring in areas I visit frequently—which is the right thing to do because, if I need to visit code frequently, I’ll get a bigger payoff by making it easier to understand.
Databases
When I wrote the first edition of this book, I said that refactoring databases was a problem area. But, within a year of the book’s publication, that was no longer the case. My colleague Pramod Sadalage developed an approach to evolutionary database design [mf-evodb] and database refactoring [Ambler & Sadalage] that is now widely used. The essence of the technique is to combine the structural changes to a database’s schema and access code with data migration scripts that can easily compose to handle large changes.
Consider a simple example of renaming a field (column). As in Change Function Declaration (124), I need to find the original declaration of the structure and all the callers of this structure and change them in a single change. The complication, however, is that I also have to transform any data that uses the old field to use the new one. I write a small hunk of code that carries out this transform and store it in version control, together with the code that changes any declared structure and access routines. Then, whenever I need to migrate between two versions of the database, I run all the migration scripts that exist between my current copy of the database and my desired version.
As with regular refactoring, the key here is that each individual change is small yet captures a complete change, so the system still runs after applying the migration. Keeping them small means they are easy to write, but I can string many of them into a sequence that can make a significant change to the database’s structure and the data stored in it.
One difference from regular refactorings is that database changes often are best separated over multiple releases to production. This makes it easy to reverse any change that causes a problem in production. So, when renaming a field, my first commit would add the new database field but not use it. I may then set up the updates so they update both old and new fields at once. I can then gradually move the readers over to the new field. Only once they have all moved to the new field, and I’ve given a little time for any bugs to show themselves, would I remove the now-unused old field. This approach to database changes is an example of a general approach of parallel change [mf-pc] (also called expand-contract).
Refactoring, Architecture, and Yagni
Refactoring has profoundly changed how people think about software architecture. Early in my career, I was taught that software design and architecture was something to be worked on, and mostly completed, before anyone started writing code. Once the code was written, its architecture was fixed and could only decay due to carelessness.
Refactoring changes this perspective. It allows me to significantly alter the architecture of software that’s been running in production for years. Refactoring can improve the design of existing code, as this book’s subtitle implies. But as I indicated earlier, changing legacy code is often challenging, especially when it lacks decent tests.
The real impact of refactoring on architecture is in how it can be used to form a well-designed code base that can respond gracefully to changing needs. The biggest issue with finishing architecture before coding is that such an approach assumes the requirements for the software can be understood early on. But experience shows that this is often, even usually, an unachievable goal. Repeatedly, I saw people only understand what they really needed from software once they’d had a chance to use it, and saw the impact it made to their work.
One way of dealing with future changes is to put flexibility mechanisms into the software. As I write some function, I can see that it has a general applicability. To handle the different circumstances that I anticipate it to be used in, I can see a dozen parameters I could add to that function. These parameters are flexibility mechanisms—and, like most mechanisms, they are not a free lunch. Adding all those parameters complicates the function for the one case it’s used right now. If I miss a parameter, all the parameterization I have added makes it harder for me to add more. I find I often get my flexibility mechanisms wrong—either because the changing needs didn’t work out the way I expected or my mechanism design was faulty. Once I take all that into account, most of the time my flexibility mechanisms actually slow down my ability to react to change.
With refactoring, I can use a different strategy. Instead of speculating on what flexibility I will need in the future and what mechanisms will best enable that, I build software that solves only the currently understood needs, but I make this software excellently designed for those needs. As my understanding of the users’ needs changes, I use refactoring to adapt the architecture to those new demands. I can happily include mechanisms that don’t increase complexity (such as small, well-named functions) but any flexibility that complicates the software has to prove itself before I include it. If I don’t have different values for a parameter from the callers, I don’t add it to the parameter list. Should the time come that I need to add it, then Parameterize Function (310) is an easy refactoring to apply. I often find it useful to estimate how hard it would be to use refactoring later to support an anticipated change. Only if I can see that it would be substantially harder to refactor later do I consider adding a flexibility mechanism now.
This approach to design goes under various names: simple design, incremental design, or yagni [mf-yagni] (originally an acronym for “you aren’t going to need it”). Yagni doesn’t imply that architectural thinking disappears, although it is sometimes naively applied that way. I think of yagni as a different style of incorporating architecture and design into the development process—a style that isn’t credible without the foundation of refactoring.
Adopting yagni doesn’t mean I neglect all upfront architectural thinking. There are still cases where refactoring changes are difficult and some preparatory thinking can save time. But the balance has shifted a long way—I’m much more inclined to deal with issues later when I understand them better. All this has led to a growing discipline of evolutionary architecture [Ford et al.] where architects explore the patterns and practices that take advantage of our ability to iterate over architectural decisions.
Refactoring and the Wider Software Development Process
If you’ve read the earlier section on problems, one lesson you’ve probably drawn is that the effectiveness of refactoring is tied to other software practices that a team uses. Indeed, refactoring’s early adoption was as part of Extreme Programming [mf-xp] (XP), a process which was notable for putting together a set of relatively unusual and interdependent practices—such as continuous integration, self-testing code, and refactoring (the latter two woven into test-driven development).
Extreme Programming was one of the first agile software methods [mf-nm] and, for several years, led the rise of agile techniques. Enough projects now use agile methods that agile thinking is generally regarded as mainstream—but in reality most “agile” projects only use the name. To really operate in an agile way, a team has to be capable and enthusiastic refactorers—and for that, many aspects of their process have to align with making refactoring a regular part of their work.
The first foundation for refactoring is self-testing code. By this, I mean that there is a suite of automated tests that I can run and be confident that, if I made an error in my programming, some test will fail. This is such an important foundation for refactoring that I’ll spend a chapter talking more about this.
To refactor on a team, it’s important that each member can refactor when they need to without interfering with others’ work. This is why I encourage Continuous Integration. With CI, each member’s refactoring efforts are quickly shared with their colleagues. No one ends up building new work on interfaces that are being removed, and if the refactoring is going to cause a problem with someone else’s work, we know about this quickly. Self-testing code is also a key element of Continuous Integration, so there is a strong synergy between the three practices of self-testing code, continuous integration, and refactoring.
With this trio of practices in place, we enable the Yagni design approach that I talked about in the previous section. Refactoring and yagni positively reinforce each other: Not just is refactoring (and its prerequisites) a foundation for yagni—yagni makes it easier to do refactoring. This is because it’s easier to change a simple system than one that has lots of speculative flexibility included. Balance these practices, and you can get into a virtuous circle with a code base that responds rapidly to changing needs and is reliable.
With these core practices in place, we have the foundation to take advantage of the other elements of the agile mindset. Continuous Delivery keeps our software in an always-releasable state. This is what allows many web organizations to release updates many times a day—but even if we don’t need that, it reduces risk and allows us to schedule our releases to satisfy business needs rather than technological constraints. With a firm technical foundation, we can drastically reduce the time it takes to get a good idea into production code, allowing us to better serve our customers. Furthermore, these practices increase the reliability of our software, with less bugs to spend time fixing.
Stated like this, it all sounds rather simple—but in practice it isn’t. Software development, whatever the approach, is a tricky business, with complex interactions between people and machines. The approach I describe here is a proven way to handle this complexity, but like any approach, it requires practice and skill.
Refactoring and Performance
A common concern with refactoring is the effect it has on the performance of a program. To make the software easier to understand, I often make changes that will cause the program to run slower. This is an important issue. I don’t belong to the school of thought that ignores performance in favor of design purity or in hopes of faster hardware. Software has been rejected for being too slow, and faster machines merely move the goalposts. Refactoring can certainly make software go more slowly—but it also makes the software more amenable to performance tuning. The secret to fast software, in all but hard real-time contexts, is to write tunable software first and then tune it for sufficient speed.
I’ve seen three general approaches to writing fast software. The most serious of these is time budgeting, often used in hard real-time systems. As you decompose the design, you give each component a budget for resources—time and footprint. That component must not exceed its budget, although a mechanism for exchanging budgeted resources is allowed. Time budgeting focuses attention on hard performance times. It is essential for systems, such as heart pacemakers, in which late data is always bad data. This technique is inappropriate for other kinds of systems, such as the corporate information systems with which I usually work.
The second approach is the constant attention approach. Here, every programmer, all the time, does whatever she can to keep performance high. This is a common approach that is intuitively attractive—but it does not work very well. Changes that improve performance usually make the program harder to work with. This slows development. This would be a cost worth paying if the resulting software were quicker—but usually it is not. The performance improvements are spread all around the program; each improvement is made with a narrow perspective of the program’s behavior, and often with a misunderstanding of how a compiler, runtime, and hardware behaves.
The interesting thing about performance is that in most programs, most of their time is spent in a small fraction of the code. If I optimize all the code equally, I’ll end up with 90 percent of my work wasted because it’s optimizing code that isn’t run much. The time spent making the program fast—the time lost because of lack of clarity—is all wasted time.
The third approach to performance improvement takes advantage of this 90-percent statistic. In this approach, I build my program in a well-factored manner without paying attention to performance until I begin a deliberate performance optimization exercise. During this performance optimization, I follow a specific process to tune the program.
I begin by running the program under a profiler that monitors the program and tells me where it is consuming time and space. This way I can find that small part of the program where the performance hot spots lie. I then focus on those performance hot spots using the same optimizations I would use in the constant-attention approach. But since I’m focusing my attention on a hot spot, I’m getting much more effect with less work. Even so, I remain cautious. As in refactoring, I make the changes in small steps. After each step I compile, test, and rerun the profiler. If I haven’t improved performance, I back out the change. I continue the process of finding and removing hot spots until I get the performance that satisfies my users.
Having a well-factored program helps with this style of optimization in two ways. First, it gives me time to spend on performance tuning. With well-factored code, I can add functionality more quickly. This gives me more time to focus on performance. (Profiling ensures I spend that time on the right place.) Second, with a well-factored program I have finer granularity for my performance analysis. My profiler leads me to smaller parts of the code, which are easier to tune. With clearer code, I have a better understanding of my options and of what kind of tuning will work.
I’ve found that refactoring helps me write fast software. It slows the software in the short term while I’m refactoring, but makes it easier to tune during optimization. I end up well ahead.
Where Did Refactoring Come From?
I’ve not succeeded in pinning down the birth of the term “refactoring.” Good programmers have always spent at least some time cleaning up their code. They do this because they have learned that clean code is easier to change than complex and messy code, and good programmers know that they rarely write clean code the first time around.
Refactoring goes beyond this. In this book, I’m advocating refactoring as a key element in the whole process of software development. Two of the first people to recognize the importance of refactoring were Ward Cunningham and Kent Beck, who worked with Smalltalk from the 1980s onward. Smalltalk is an environment that even then was particularly hospitable to refactoring. It is a very dynamic environment that allows you to quickly write highly functional software. Smalltalk had a very short compile-link-execute cycle for its time, which made it easy to change things quickly at a time where overnight compile cycles were not unknown. It is also object-oriented and thus provides powerful tools for minimizing the impact of change behind well-defined interfaces. Ward and Kent explored software development approaches geared to this kind of environment, and their work developed into Extreme Programming. They realized that refactoring was important in improving their productivity and, ever since, have been working with refactoring, applying it to serious software projects and refining it.
Ward and Kent’s ideas were a strong influence on the Smalltalk community, and the notion of refactoring became an important element in the Smalltalk culture. Another leading figure in the Smalltalk community is Ralph Johnson, a professor at the University of Illinois at Urbana-Champaign, who is famous as one of the authors of the “Gang of Four” [gof] book on design patterns. One of Ralph’s biggest interests is in developing software frameworks. He explored how refactoring can help develop an efficient and flexible framework.
Bill Opdyke was one of Ralph’s doctoral students and was particularly interested in frameworks. He saw the potential value of refactoring and saw that it could be applied to much more than Smalltalk. His background was in telephone switch development, in which a great deal of complexity accrues over time and changes are difficult to make. Bill’s doctoral research looked at refactoring from a tool builder’s perspective. Bill was interested in refactorings that would be useful for C++ framework development; he researched the necessary semantics-preserving refactorings and showed how to prove they were semantics-preserving and how a tool could implement these ideas. Bill’s doctoral thesis [Opdyke] was the first substantial work on refactoring.
I remember meeting Bill at the OOPSLA conference in 1992. We sat in a café and he told me about his research. I remember thinking, “Interesting, but not really that important.” Boy, was I wrong!
John Brant and Don Roberts took the refactoring tool ideas much further to produce the Refactoring Browser, the first refactoring tool, appropriately for the Smalltalk environment.
And me? I’d always been inclined to clean code, but I’d never considered it to be that important. Then, I worked on a project with Kent and saw the way he used refactoring. I saw the difference it made in productivity and quality. That experience convinced me that refactoring was a very important technique. I was frustrated, however, because there was no book that I could give to a working programmer, and none of the experts above had any plans to write such a book. So, with their help, I did—which led to the first edition of this book.
Fortunately, the concept of refactoring caught on in the industry. The book sold well, and refactoring entered the vocabulary of most programmers. More tools appeared, especially for Java. One downside of this popularity has been people using “refactoring” loosely, to mean any kind of restructuring. Despite this, however, it has become a mainstream practice.
Automated Refactorings
Perhaps the biggest change to refactoring in the last decade or so is the availability of tools that support automated refactoring. If I want to rename a method in Java and I’m using IntelliJ IDEA [intellij] or Eclipse [eclipse] (to mention just two), I can do it by picking an item off the menu. The tool completes the refactoring for me—and I’m usually sufficiently confident in its work that I don’t bother running the test suite.
The first tool that did this was the Smalltalk Refactoring Browser, written by John Brandt and Don Roberts. The idea took off in the Java community very rapidly at the beginning of the century. When JetBrains launched their IntelliJ IDEA IDE, automated refactoring was one of the compelling features. IBM followed suit shortly afterwards with refactoring tools in Visual Age for Java. Visual Age didn’t have a big impact, but much of its capabilities were reimplemented in Eclipse, including the refactoring support.
Refactoring also came to C#, initially via JetBrains’s Resharper, a plug-in for Visual Studio. Later on, the Visual Studio team added some refactoring capabilities.
It’s now pretty common to find some kind of refactoring support in editors and tools, although the actual capabilities vary a fair bit. Some of this variation is due to the tool, some is caused by the limitations of what you can do with automated refactoring in different languages. I’m not going to analyze the capabilities of different tools here, but I think it is worth talking a bit about some of the underlying principles.
A crude way to automate a refactoring is to do text manipulation, such as a search/replace to change a name, or some simple reorganizing of code for Extract Variable (119). This is a very crude approach that certainly can’t be trusted without rerunning tests. It can, however, be a handy first step. I’ll use such macros in Emacs to speed up my refactoring work when I don’t have more sophisticated refactorings available to me.
To do refactoring properly, the tool has to operate on the syntax tree of the code, not on the text. Manipulating the syntax tree is much more reliable to preserve what the code is doing. This is why at the moment, most refactoring capabilities are part of powerful IDEs—they use the syntax tree not just for refactoring but also for code navigation, linting, and the like. This collaboration between text and syntax tree is what takes them beyond text editors.
Refactoring isn’t just understanding and updating the syntax tree. The tool also needs to figure out how to rerender the code into text back in the editor view. All in all, implementing decent refactoring is a challenging programming exercise—one that I’m mostly unaware of as I gaily use the tools.
Many refactorings are made much safer when applied in a language with static typing. Consider the simple Rename Function (124). I might have addClient methods on my Salesman class and on my Server class. I want to rename the one on my salesman, but it is different in intent from the one on my server, which I don’t want to rename. Without static typing, the tool will find it difficult to tell whether any call to addClient is intended for the salesman. In the refactoring browser, it would generate a list of call sites and I would manually decide which ones to change. This makes it a nonsafe refactoring that forces me to rerun the tests. Such a tool is still helpful—but the equivalent operation in Java can be completely safe and automatic. Since the tool can resolve the method to the correct class with static typing, I can be confident that the tool changes only the methods it ought to.
Tools often go further. If I rename a variable, I can be prompted for changes to comments that use that name. If I use Extract Function (106), the tool spots some code that duplicates the new function’s body and offers to replace it with a call. Programming with powerful refactorings like this is a compelling reason to use an IDE rather than stick with a familiar text editor. Personally I’m a big user of Emacs, but when working in Java I prefer IntelliJ IDEA or Eclipse—in large part due to the refactoring support.
While sophisticated refactoring tools are almost magical in their ability to safely refactor code, there are some edge cases where they slip up. Less mature tools struggle with reflective calls, such as Method.invoke in Java (although more mature tools handle this quite well). So even with mostly safe refactorings, it’s wise to run the test suite every so often to ensure nothing has gone pear-shaped. Usually I’m refactoring with a mix of automated and manual refactorings, so I run my tests often enough.
The power of using the syntax tree to analyze and refactor programs is a compelling advantage for IDEs over simple text editors, but many programmers prefer the flexibility of their favorite text editor and would like to have both. A technology that’s currently gaining momentum is Language Servers [langserver]: software that will form a syntax tree and present an API to text editors. Such language servers can support many text editors and provide commands to do sophisticated code analysis and refactoring operations.
Going Further
It seems a little strange to be talking about further reading in only the second chapter, but this is as good a spot as any to point out there is more material out there on refactoring that goes beyond the basics in this book.
This book has taught refactoring to many people, but I have focused more on a refactoring reference than on taking readers through the learning process. If you are looking for such a book, I suggest Bill Wake’s Refactoring Workbook [Wake] that contains many exercises to practice refactoring.
Many of those who pioneered refactoring were also active in the software patterns community. Josh Kerievsky tied these two worlds closely together with Refactoring to Patterns [Kerievsky], which looks at the most valuable patterns from the hugely influential “Gang of Four” book [gof] and shows how to use refactoring to evolve towards them.
This book concentrates on refactoring in general-purpose programming, but refactoring also applies in specialized areas. Two that have got useful attention are Refactoring Databases [Ambler & Sadalage] (by Scott Ambler and Pramod Sadalage) and Refactoring HTML [Harold] (by Elliotte Rusty Harold).
Although it doesn’t have refactoring in the title, also worth including is Michael Feathers’s Working Effectively with Legacy Code [Feathers], which is primarily a book about how to think about refactoring an older codebase with poor test coverage.
Although this book (and its predecessor) are intended for programmers with any language, there is a place for language-specific refactoring books. Two of my former colleagues, Jay Fields and Shane Harvey, did this for the Ruby programming language [Fields et al.].
For more up-to-date material, look up the web representation of this book, as well as the main refactoring web site: refactoring.com [ref.com].