
Chapter 4. Drafting a Plan
One day, I plan to complete the 4,500 kilometer drive between Montreal to Vancouver. The drive takes about forty-eight hours from start to finish with the fastest route covering most of the length of the border between Canada and the United States. The fastest route isn’t necessarily the most rewarding route, however, and if I add a stop to see Parliament Hill in Ottawa, the iconic CN Tower in Toronto, and the Sleeping Giant Provincial Park, I lengthen my trip by a few hours and about six hundred kilometers.
Now anyone setting out on this journey knows driving it non-stop from start to finish is both impractical and dangerous. So, before I head out, I should map out a rough outline for the road trip. I should figure out how much time I’m comfortable driving on the road-heavy days, and which cities I might want to pop in to do some sightseeing. In total, I estimate the trip might take anywhere between seven to ten days depending on how long I spend sightseeing. The flexibility allows for a few unexpected twists, whether I decide to sightsee an extra day, or get stranded on the side of the road and need to call for assistance.
How do you know if you’ve had a successful roadtrip beyond actually reaching your final destination? If you set a budget for your trip, you might have achieved your goal if your next credit card bill falls within range. Maybe you wanted to eat a burger at every stop along the way. Probably, you just wanted to see something new, spend some quality time with friends or family, and make a few new memories. As tacky as it might sound, the roadtrip is just as much about the journey as it is about the destination.
Any large software endeavor can look quite a bit like a roadtrip across the country. As developers, we decide on a set of milestones we want to accomplish, a rough set of tasks we want to complete in between each of these milestones, and an estimate for when we think we might reach our destination. We keep track of our progress along the way, ensuring we stay on task and within the time we’ve alloted ourselves. By the end, we want to see a measurable, positive impact, achieved in a sustainable way.
We’ve taken the time to understand our code’s past, first by identifying how our code has degraded, then by characterizing that degradation. Now, we’re ready to map out its future. We’ll learn to how split up a large refactoring effort into its most important pieces, crafting a plan that is both thorough and precise in scope. We’ll highlight when and how to reference the metrics we carefully gathered to characterize the current problem state in Chapter 3. We’ll discuss the importance of shopping your plan around to other teams and wrap things up by emphasizing the value in continuously updating it throughout the whole process.
Everyone takes a different approach to building out an execution plan. Whether your team calls them technical specs, or product briefs, or RFCs (Request for Comment), they all serve the same purpose: documenting what you intend to do and how you intend to do it. Having a clear, concise plan is key to ensuring the success of any software project, regardless of whether it involves refactoring or building out a new feature; it keeps everyone focused on the important tasks at hand, and enforces accountability for their progress throughout the endeavor.
Defining Your End State
Our first step is to define our end state. We should already have a strong understanding of where we currently are; we’ve spent considerable time measuring and defining the problem we want to solve in Chapter 3. Now that we’ve grounded ourselves, we need to identify where we want to land.
On the Road
We’re kicking off our roadtrip in Montreal, where we currently live. Of the hundreds of towns and cities speckled along that shore, we have to pick just one to aim for. So, after a bit of research, we decide to aim for Vancouver.
Next, we need to familiarize ourselves with the highways leading directly into the city, and decide where we might want to stay upon arrival. We reach out to friends who’ve either lived in Vancouver or travel there frequently for recommendations. We land on Yaletown, a neighborhood known for its old warehouse buildings by the water. Now that your trip has a well-defined destination, we can start figuring out precisely how to get there.
At Work
To illustrate the many important concepts in this chapter, we’ll be using an example of a large-scale refactor at a fifteen-year-old biotechnology company we’ll call Smart DNA, Inc. Most of their employees are research scientists, contributing to a complex data pipeline cromprised of hundreds of Python scripts across a few repositories. The scripts are deployed to and executed on five distinct environments. All of these environments rely on a version of Python 2.6. Unfortunately, Python 2.6 has long since been deprecated, leaving the company susceptible to security vulnerabilities and preventing them from updating important dependencies. While relying on outdated software is inconvenient, the company has not prioritized upgrading to a newer Python version. It’s a massive, risky undertaking given the very limited testing in place. Simply put, this was the biggest piece of technical debt at the company for many years.
The research team has recently grown concerned about their inability to use newer versions of core libraries. Given that the upgrade is now important to the business, we’ve been tasked with figuring out how to migrate each of the repositories and environments to use Python 2.7.
The research team manages their dependencies using pip. Each repository has its own list of dependencies encoded in a requirements.txt. Having these distinct requirements.txt files has made it difficult for the team to remember which dependencies are installed on a given project when switching between projects. It also would require the software team to audit each file and upgrade them to be compatible with Python 2.7 independently. As a result, the software team decided that while it was not necessary, it would make the Python 2.7 upgrade easier for them (and simplify the researchers’ development process) to unify the repositories and thus unify the dependencies.
Our execution plan should clearly outline all starting metrics, target end metrics, with an optional, albeit helpful additional column to record the actual, observed end state. For the Python migration, the starting set of metrics was clear: each repository had a distinct list of dependencies, with each environment running Python 2.6. The desired set of metrics was equally simple: have each of the business’s environments running Python 2.7, with a clear, succinct set of required libraries managed in a single place. Table 4-1 shows an example where we’ve listed Smart DNA’s metrics.
| Metric description | Start | Goal | Observed |
|---|---|---|---|
Environment 1 |
Python 2.6.5 |
Python 2.7.1 |
- |
Environment 2 |
Python 2.6.1 |
Python 2.7.1 |
- |
Environment 3 |
Python 2.6.5 |
Python 2.7.1 |
- |
Environment 4 |
Python 2.6.6 |
Python 2.7.1 |
- |
Environment 5 |
Python 2.6.6 |
Python 2.7.1 |
- |
Number of distinct lists of dependencies |
3 |
1 |
- |
Tip
Feel free to provide both an ideal end state and an “acceptable” end state. Sometimes, getting 80% of the way there gives you 99% of the benefit of the refactor and the additional amount of work required to get to 100% simply isn’t worthwhile.
Mapping the Shortest Distance
Next, we want to map the most direct path between our start and end states. This should give us a good lower-bound estimate on the amount of time required to execute our project. Building on a minimal path ensures that your plan stays truer to its course as you introduce intermediate steps along the way.
On the Road
So, for our roadtrip, we do a quick search to see what the most direct route between Montreal and Vancouver looks like. Taking into account minimal traffic, it appears to take 47 hours if we were to leave Montreal and drive non-stop westward.
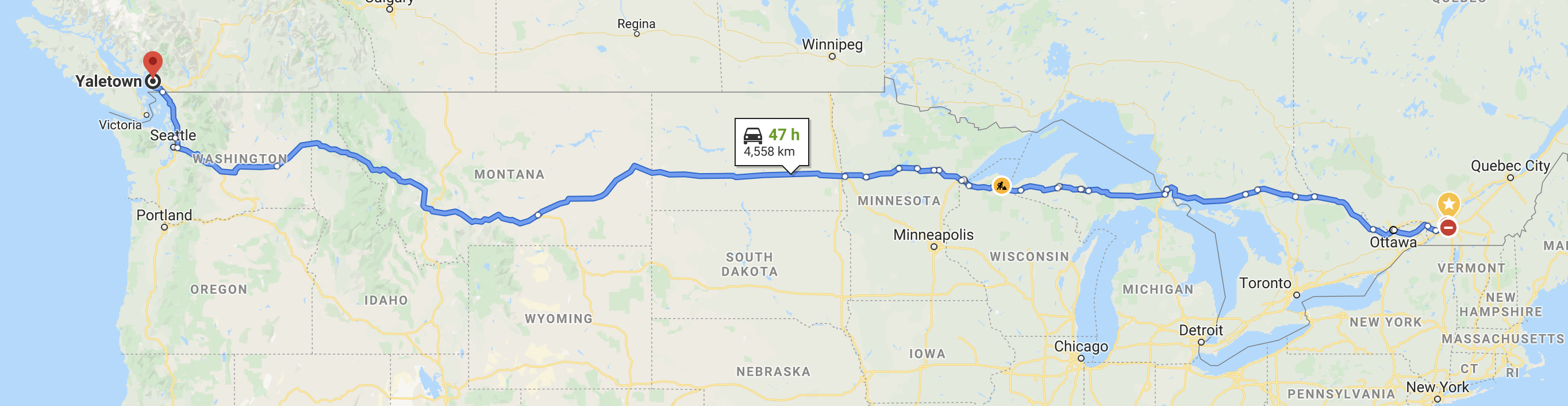
Figure 4-1. The most direct route between our address in Montreal and the Yaletown neighborhoood in Vancouver
We can determine a more reasonable lower bound for our trip by deciding how many hours we’re comfortable driving per day, and splitting that up evenly over the approximate 47 hours. If we want to commit to 8 hours of driving, it’ll take us just about 6 days.
Now that we’ve mapped the shortest possible path between the two points, we can start to pick out any major complications or over-arching strategies we want to change. One peculiarity with the drive in Figure 4-1 is that the vast majority of it travels across the United States, not Canada. If we want to restrict our drive to the area north of the 49th parallel, we’d be adding an extra hour or two to the trip. However, because it does reduce overall complexity of the trip (no need to carry around passport or worry about time wasted at a border crossing), we’ll opt to stay in Canada.
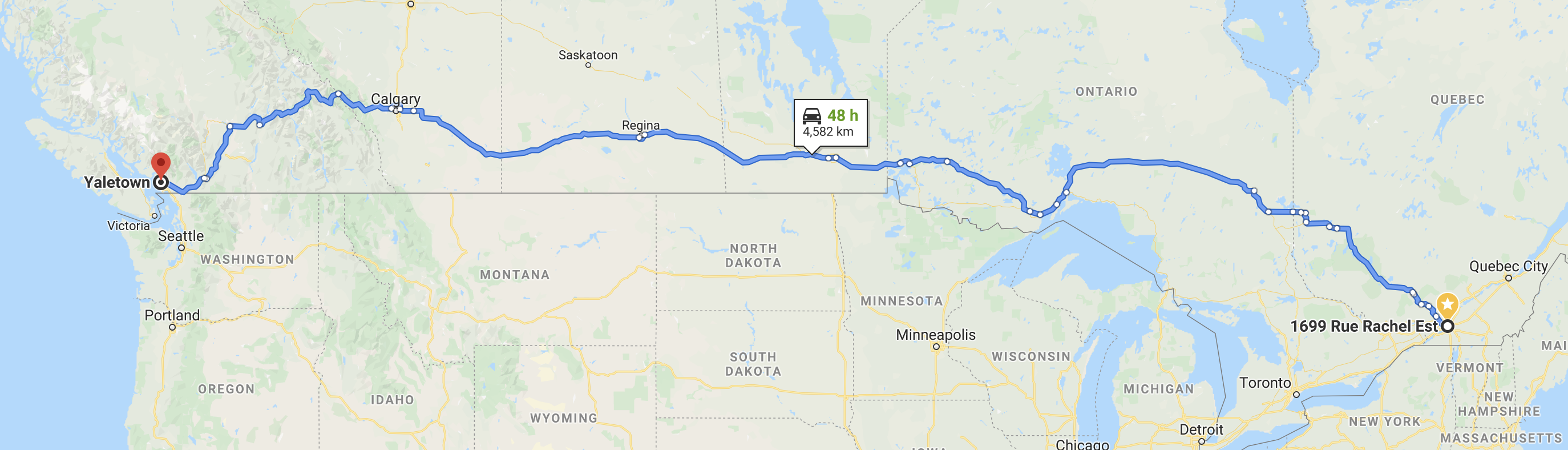
Figure 4-2. A slightly slower route restricted through Canada
At Work
Unfortunately, Google Maps for software projects doesn’t exist quite yet. So how do we determine the shortest path from now to project completion? We can do this a few different ways:
-
Open up a blank document and for 15 to 20 minutes (or until you’ve run out of ideas), write down every step you can come up with. Set the document aside for at the very least a few hours (ideally a day or two), then open it up again and try to order each step in chronological order. As you begin to order the steps, continue to ask yourself whether it is absolutely required in order to reach the final goal. If not, remove it. Once you have an ordered set of steps, reread the procedure. Fill in any glaring gaps as they arise. Don’t worry if there are any steps that are terribly ill-defined, the goal is only to produce the minimum set of steps required to complete your project. This won’t be the final product.
-
Gather a few coworkers who are either interested in the project or you know will be contributing. Set aside an hour or so. Grab a pack of sticky notes and a pen for each of you. For anywhere between 15 to 20 minutes (or until everyone’s pens are down), write down every step you think is required, each on individual sticky notes. Then, have a first person lay out their steps in chronological order. Subsequent teammates go through each of their own sticky notes and either pair them up with their duplicates, or insert them into the appropriate spot within the timeline. Once everyone’s organized all of their notes, go through each individual step and ask the room whether they believe that the the step is absolutely required in order to reach the goal. If not, discard it. The final product should be a reasonable set of minimal steps. (You can easily adapt this method for distributed teams by combining all ideas individually brainstormed steps into a joint shared document. Either way, the final output of the exercise should be a written document that is easy to distribute and collaboratively improve.)
If neither of these options work for you, that’s alright! Use whatever method you find most effective. So long as you are able to produce a list of steps you believe model a direct path to achieving your goal, no matter how ill-defined they might be, then you’ve successfully completed this critical step.
Our team at Smart DNA gathered into a conference room for a few hours to brainstorm all of the steps required to get everything running a newer version of Python. On a whiteboard, we started out by drawing a timeline. On the far left was their starting point, and on the far right their goal. Teammates alternated listing important steps along the way, slotting them in along the line. A subset of the brainstormed steps are as follow:
-
Build a single list of all of the packages across each of the repositories manually.
-
Narrow-down the list to just the necessary packages.
-
Identify which version each package should be upgraded to in Python 2.7.
-
Build a Docker container with all of the required packages.
-
Test the Docker container on each of the environments.
-
Locate tests for each repository; determine which tests are reliable.
-
Merge all of the repositories into a single repository.
-
Choose a linter and corresponding configuration.
-
Integrate linter into continuous integration.
-
Use linter to identify problems in the code (undefined variables, syntax errors, etc.)
-
Fix problems identified by the linter.
-
Install Python 2.7.1 on all environments and test.
-
Use Python 2.7 on a subset of low-risk scripts.
-
Roll out Python 2.7 to all scripts.
We can see from our subset that some can be parallelized, or reordered, and others should be broken down into further detail. At this point in the process, our focus is on getting a rough sense of the steps involved; we’ll refine the process throughout the chapter.
Identifying Strategic Intermediate Milestones
We’ll next use the procedure we derived to come up with an ordered list of intermediate milestones. These milestones do not need to be of similar size or evenly-distributed, so long as they are achievable within a timescale that feels comfortable. We should focus on finding milestones that are meaningful in and of themselves. That is, either reaching the milestone is a win on its own, or it defines a step we could comfortably stop at if necessary (or both). If you’re able to identify milestones that are both meaningful and showcase the potential impact of your refactoring effort early, then you’re doing great!
On the Road
For the stretch of the trip between Winnipeg and Vancouver, we ask some friends and family for recommendations of sights to see and things to do. After weighing their suggestions with our own interests, we come up with a rough itinerary which includes everything from camping, museum visits, tasty pitstops, and a few visits to extended family. But at no point do any of these points of interest take us radically off-course.

Figure 4-3. Our rough itinerary
At Work
We can apply similar tactics to narrow-in on our milestones for our refactoring effort. For each of the steps we brainstormed previously, we can ask ourselves these questions:
1. Does this step feel attainable in a reasonable period of time?
Let’s refer back to our previous example, outlined in “At Work”. A logical, feasible milestone might be to combine each of the distinct repositories into a single repository for convenience. The software team at Smart DNA anticipate it’ll take six weeks to properly merge the repositories without disrupting the research team’s development process. Given the software team is accustomed to shipping at a quicker pace, and they’re concerned about morale if they set out to merge the repositories too early-on in the migration, they decide on a simpler initial milestone: generating a single requirements.txt file to encompass all package dependencies for each of the repositories. By taking the time to reduce the set of dependencies early, they are simplifying the development process for the research team, taking a substantial step towards enabling the merging of the repositories, and all of that well before the migration to Python 2.7 is complete.
2. Is this step valuable on its own?
When choosing major milestones, we should optimize for steps that demonstrate the benefits of the refactor early and often. One way to do that is to focus on steps that, upon completion, derive immediate value for other engineers. This should hopefully increase the morale of both your team and other engineers impacted by your changes.
When scoping out the Python migration, we noticed that none of the repositories used any continuous integration to lint for common problems in proposed code changes. We know that linting the existing code could help us pinpoint problems we risk encountering when executing it in Python 2.7. We also know that enabling a simple, automatic linting step could promote better programming practices for the entire research team for years to come. In fact, it seems so valuable that under different circumstances, instituting an automatic linting step might’ve been a project all on its own. This indicated to us that it was a meaningful, significant intermediate step.
3. If something comes up, could we stop at this step and pick it back up easily later?
In a perfect world, we wouldn’t have to account for shifts in business priorities, incidents, or re-orgs. Unfortunately, these are all a reality of working, regardless of the industry. This is why the best plans account for the unexpected. One way of accounting for disruptive changes is by dividing our project into distinct pieces that can stand alone in the unlikely event we need to pause development.
With our Python example, we could comfortably pause the project after fixing all errors and warnings highlighted by the linter, but before beginning to run a subset of scripts using the new version. Depending on how we tackled the refactor, pausing half-way through could risk confusing the researchers actively working in the repository. If the refactor needed to be paused for whatever reason, pausing immediately before we started running a subset of scripts using to Python 2.7 would be safe; we would still have made considerable progress towards our overall goal and have a clean, easy place to pick things back up when we are next able to.
After taking the time to highlight strategic milestones, we reorganized our execution plan to highlight these steps and grouped subtasks accordingly. The more refined plan is as follows:
-
Create a single
requirements.txtfile.-
Enumerate all packages used across each of the repositories.
-
Audit all packages and narrow-down list to only required packages with corresponding versions.
-
Identify which version each package should be upgraded to in Python 2.7.
-
-
Merge all of the repositories into a single repository.
-
Create a new repository.
-
For each repository, add to the new repository using git submodules.
-
-
Build a Docker image with all of the required packages.
-
Test the Docker image on each of the environments.
-
-
Enable linting through continuous integration for the mono-repo.
-
Choose a linter and corresponding configuration.
-
Integrate linter into continuous integration.
-
Use linter to identify logical problems in the code (undefined variables, syntax errors, etc.)
-
-
Install and roll out Python 2.7.1 on all environments.
-
Locate tests for each repository; determine which tests are reliable.
-
Use Python 2.7 on a subset of low-risk scripts.
-
Roll out Python 2.7 to all scripts.
-
Hopefully after you’ve identified key milestones, you have a procedure that feels balanced, achievable, and rewarding. It’s important to note, however, that this isn’t a perfect science. It can be quite difficult to weigh required steps against one another according to the effort they involve and their relative impact. We’ll see an example of how we decided to weigh each of these considerations when strategically planning a large-scale refactor in both of our case study chapters, Chapter 10 and Chapter 11.
Finally, once we have our end state and our key milestones, we want to interpolate our way through the intermediate steps between our end state and each of our strategic intermediary milestones. This way, we maintain focus on the most critical pieces, all the while building out a detailed plan.
This is where we can spend some time figuring out whether certain portions of the refactor are order-agnostic; that is, they can be completed at any point, with very few to no prerequisites. For example, let’s say you’ve identified a few key milestones for your project; we’ll call them A, B, C, and D. You notice that you need to complete A before tackling B or C, and B needs to be completed before you tackle D. You have three options with regards to C: you could parallelize development on C at the same time as D, complete C then D, or complete D followed by C.
If you have a hunch that B is going to be a difficult, lengthy milestone and D looks just as challenging, you might want to break things up by putting milestone C between B and D. This should help boost morale and add some pep to the team’s momentum as you work through a long refactor. On the other hand, if you think that you can comfortably parallelize work on milestone C and D, and wrap up the project a little bit sooner, then that might be worthwhile option as well.
It all comes down to balance: balancing time and effort associated with each requisite step, all the while considering their impact on your codebase and the well-being of your team.
Choosing a Rollout Strategy
Having a thoughtful rollout strategy for your refactoring effort can make the difference between great success and utter failure. Therefore, it is absolutely critical to include as part of your execution plan. If your refactor involves multiple distinct phases, each with its own rollout strategy, be certain to outline each of these among the concluding steps of each phase. While there is a great variety of deployment practices used by teams of all kinds, in this section, we’ll only discuss rollout strategies specific to teams that do continuous deployment.
Typically, product engineering teams that do continuous deployment will begin development on a new feature, testing it both manually and in an automated fashion it out throughout the process. When all the boxes have been checked, the feature is carefully, incrementally rolled-out to live users. Before the final rollout phase, many teams will deploy the feature to an internal build of their product, giving themselves yet another opportunity to weed out problems before kicking off deployment to users. Measuring success in this case is easy; if the feature works as expected, great! If we find any bugs, we devise a fix, and depending on the implications of that fix, either repeat the incremental rollout process, or push it out to all users immediately.
Note
It’s common practice in continuous deployment environments to use feature flags to conditionally hide, enable, or disable specific features or code paths at runtime. Good feature flag solutions allow development teams the flexibility to assign groups of users to specific features (sometimes according to a number of different attributes). If you work on a social media application, for instance, you might want to release a feature to all users within a single geographic area, a random 1% of users globally, or all users who are over the age of 40.
With refactoring projects, while we most certainly want to test our changes early and frequently, and very carefully roll it out to users, it’s quite a bit trickier to determine whether everything is working as intended. After all, one of the key success metrics is that no behavior has changed. It is much more difficult to ascertain a lack of change than even the smallest change. So, one of the easiest ways we can ascertain that the refactor hasn’t introduced any new bugs is by programmatically comparing pre-refactor behavior with post-refactor behavior.
Dark Mode/Light Mode
We can compare pre-refactor and post-refactor behavior by employing what we’ve coined at Slack as the light/dark technique. Here’s how it works.
First, implement the refactored logic separately from the current logic, with the goal being to remove the current logic altogether. Example 4-1 depicts this step on a small scale.
Example 4-1. New and old implementations; perhaps in different files
// Linear search; this is the old implementationfunctionsearch(name,alphabeticalNames){for(leti=0;i<alphabeticalNames.length;i++){if(alphabeticalNames[i]==name)returni;}return-1;}// Binary search; this is the new implementationfunctionsearchFaster(name,alphabeticalNames){letstartIndex=0;letendIndex=alphabeticalNames.length-1;while(startIndex<=endIndex){letmiddleIndex=Math.floor((startIndex+endIndex)/2);if(alphabeticalNames[middleIndex]==name)returnmiddleIndex;if(alphabeticalNames[middleIndex]>name){endIndex=middleIndex-1;}elseif(alphabeticalNames[middleIndex]<name){startIndex=middleIndex+1;}}return-1;}
Then, as shown in Example 4-2, relocate the logic from the current implementation into a separate function.
Example 4-2. Old implementation moved to a separate function
// Existing function now calls into relocated implementationfunctionsearch(name,alphabeticalNames){returnsearchOld(name,alphabeticalNames);}// Linear search logic moved to a new function.functionsearchOld(name,alphabeticalNames){for(leti=0;i<alphabeticalNames.length;i++){if(alphabeticalNames[i]==name)returni;}return-1;}// Binary search; this is the new implementationfunctionsearchFaster(name,alphabeticalNames){letstartIndex=0;letendIndex=alphabeticalNames.length-1;while(startIndex<=endIndex){letmiddleIndex=Math.floor((startIndex+endIndex)/2);if(alphabeticalNames[middleIndex]==name)returnmiddleIndex;if(alphabeticalNames[middleIndex]>name){endIndex=middleIndex-1;}elseif(alphabeticalNames[middleIndex]<name){startIndex=middleIndex+1;}}return-1;}
Then, transform the previous function into an abstraction conditionally calling either implementation. During dark mode, both implementations are called, the results are compared, and the results from the old implementation are returned. During light mode, both implementations are called, the results are compared, and the results from the new implementation are returned. As can be seen in Example 4-3, repurposing the existing function definition allows us to modify as little code as possible. (Though not depicted in our example, to prevent performance degradations as part of the light/dark process, both the old and new implementations should be executed concurrently.)
Example 4-3. Existing interface used as an abstraction for calling both new and old implementations
// Existing function now an abstraction for calling into either implementationfunctionsearch(name,alphabeticalNames){// If we're in dark mode, return the old result.if(darkMode){constoldResult=searchOld(name,alphabeticalNames);constnewResult=searchFaster(name,alphabeticalNames);compareAndLog(oldResult,newResult);returnoldResult;}// If we're in light mode, return the new result.if(lightMode){constoldResult=searchOld(name,alphabeticalNames);constnewResult=searchFaster(name,alphabeticalNames);compareAndLog(oldResult,newResult);returnnewResult;}returnsearch(name,alphabeticalNames);}// Linear search logic moved to a new function.functionsearchOld(name,alphabeticalNames){for(leti=0;i<alphabeticalNames.length;i++){if(alphabeticalNames[i]==name)returni;}return-1;}// Binary search; this is the new implementationfunctionsearchFaster(name,alphabeticalNames){letstartIndex=0;letendIndex=alphabeticalNames.length-1;while(startIndex<=endIndex){letmiddleIndex=Math.floor((startIndex+endIndex)/2);if(alphabeticalNames[middleIndex]==name)returnmiddleIndex;if(alphabeticalNames[middleIndex]>name){endIndex=middleIndex-1;}elseif(alphabeticalNames[middleIndex]<name){startIndex=middleIndex+1;}}return-1;}functioncompareAndLog(oldResult,newResult){if(oldResult!=newResult){console.log(`Diff found; old result:${oldResult}, new result:${newResult}`);}}
Once the abstraction has been properly put in place, start enabling dark mode, (i.e. dual code path execution, returning the results of the old code). Monitor any differences being logged between the two result sets. Track down and fix any potential bugs in the new implementation causing those discrepancies. Repeat this process until you’ve properly handled all discrepancies, enabling dark mode to broader groups of users.
Once all users have been opted into dark mode, starting with the lowest-risk environments first, begin enabling light mode to small subsets of users (i.e. start returning data from the new code path). Continue logging any differences in the result sets; this can be useful if other developers are actively working on related code and risk introducing a change to the old implementation that is not reflected in the new implementation. Continue to opt braoder groups of users into light mode, until everyone is successfully processing results from the new implementation.
Finally, disable executing both code paths, continuing to monitor for any reported bugs, and remove the abstraction, feature flags, conditional execution logic, and, once the refactor has been live to users for an adequate period of time (whatever that might be for your use case), remove the old logic altogether. Only the new implementation should remain where the old implementation once was. See Example 4-4 for an example.
Example 4-4. New implementation inside the old function definition
// Binary search; this is the new implementationfunctionsearch(name,alphabeticalNames){letstartIndex=0;letendIndex=alphabeticalNames.length-1;while(startIndex<=endIndex){letmiddleIndex=Math.floor((startIndex+endIndex)/2);if(alphabeticalNames[middleIndex]==name)returnmiddleIndex;if(alphabeticalNames[middleIndex]>name){endIndex=middleIndex-1;}elseif(alphabeticalNames[middleIndex]<name){startIndex=middleIndex+1;}}return-1;}
Drawbacks
As with any approach, there are some downsides to be mindful of. If the code you are refactoring is performance-sensitive, and you’re operating in an environment that does not enable true multi-threading (e.g. PHP, Python, or Node) then running two versions of the same logic side by side might not be a great option. Say you’re refactoring code that involves making one or more network requests; assuming those dependencies do not change with the refactor, you’ll be executing double the number of network requests, serially. You must weigh the ability to audit your changes at a high fidelity against a corresponding increase in latency. One trade-off might be to run the dual code paths and subsequent comparison at a sampled rate; if this path is hit very frequently, running a comparison just 5% of the time might get you ample data about whether your solution is working as expected without compromising too heavily on performance.
We also have to be mindful of any additional load we’ll be subjecting to downstream resources. This can include anything from a database, to a message queue, to the very systems we are using to log differences across the codepaths we’re comparing. If we are refactoring a high-traffic path, and we want to run the comparison often, we need to certain that we won’t accidentally over-burden our underlying infrastructure. In my experience, comparisons can unearth a swarm of unexpected differences (particularly when refactoring old, complex code). It’s safer to take a slow, incremental approach to ramping up dual execution and comparison than risk overloading your logging system. Set a small initial sample rate, address any high-frequency differences as they creep up, and repeat, increasing the sample rate step by step until you either reach 100% or a stable state at which you are confident no more discrepancies should arise.
Smart DNA’s Rollout
With the refactor at Smart DNA, the greater risk was in migrating each of the repositories’ many dependencies to versions compatible with Python 2.7, not with running the existing code itself using the newer Python version. The software team decided that they would first a few preliminary tests, setting up a subset of the data pipeline in an isolated environment, installing both versions of Python, and running a few jobs using the new dependency file in the 2.7 environment. When they were confident with the results of their preliminary tests, they would slowly, carefully introduce usage of the new set of dependencies in production.
To limit the risk involved, the team audited each of the jobs that make up the researchers’ data pipeline and grouped them according to their importance. Then the engineers chose a low-risk job with the fewest downstream dependencies to migrate first. They worked with the research team to identify a good time to swap the configuration to point to the new requirements.txt file and new Python version. Once the change had been made, the team planned to monitor logs generated by the job to catch any strange behavior early. If any problems crept up, the configuration would be swapped back to its original version while the software team worked on a fix. When the fix was ready, the team would repeat the experiment. As part of their rollout plan, the team required that the configuration change sit in production for a few days, allowing for the job to run successfully on a dozen different occasions before moving onto a second job.
After the second job was successfully migrated, the software team would opt-in all low-risk jobs into the new configuration. They would then repeat the process for the medium-risk jobs. Finally, for the most critical jobs, the team decided to migrate each of these individually due to their importance. Again they would wait a few days before repeating the process for the next job, and so on. In all, the team determined it would take nearly two months to migrate the entire data pipeline to the new environment. While this might sound like a grueling process, both the software and research teams agree that it is necessary so as to sufficiently reduce risk. It gives everyone adequate opportunity weed out problems at small increments early, ensuring that the pipeline remains as healthy as possible throughout the entire process.
Cleaning Up Artifacts
In Chapter 1, I mentioned that you shouldn’t embark on a refactor unless you have the time to execute to completion. No refactor is complete unless all remaining transitional artifacts are properly cleaned up. Below is a short, non-exhausting list of the kinds artifacts we generate during the refactoring process.
-
Feature flags: Most of us are guilty of leaving one or two feature flags behind. It’s not so bad to forget to remove a flag for a few days (or even a few weeks), but there’s a tangible risk associated with failing to clean these up. First, verifying whether a feature flag is enabled adds complexity. Engineers reading code gated by a feature flag need to reason about the behavior if the flag is enabled and the flag is disabled. This is a necessary overhead for feature development in a continuous deployment environment, but we should prioritize removing it soon after we are able to do so. Second, stale feature flags can pile up. A single flag won’t weigh down your application, but hundreds of stale flags certainly might. Practice good feature flag etiquette; add authors and expiration dates, and follow-up with those engineers once those dates have passed.
-
Abstractions: We can attempt to shield our refactor from other developers by building abstractions to hide the transition. In fact, we might have written one to use the “Dark Mode/Light Mode” deployment method outlined in the previous section. Once we’ve finished refactoring, however, these abstractions are generally no longer meaningful, and can further confuse developers. In cases where our abstractions still contain some meaningful logic, we should strive to simplify them such that engineers reading them in the future have no reason to suspect that they were written for the purpose of smoothly refactoring something.
-
Dead code: When we’re refactoring something, particularly when we’re refactoring something at large scale, we typically end up with a sizable amount of dead code following rollout. Although dead code isn’t dangerous on its own, it can be frustrating for engineers down the line trying to determine whether it is still being used. Recall “Unused Code” where we discussed the downsides of keeping unused code in the codebase.
-
Comments: We leave a variety of different comments when executing on a refactor. We warn other developers of code in flux, maybe leave a handful of TODOs, or make note of dead code to remove once the refactor is finished. These comments should be deleted so as not to mislead anyone. On the off chance we come across any stray, unfinished TODOs, we’ll be even more gratified that we took the time to tidy up our work.
-
Unit tests: Depending on how we’re executing the refactor, we may have written duplicative unit tests alongside existing ones to verify the correctness of our changes. We need to clean up any newly superfluous tests so that we don’t confuse any developers referencing them later. (Redundant unit tests also aren’t great if your team wants to maintain speedy unit testing suite.)
Tip
A few years ago, a teammate of mine ran an experiment to determine how much time we were spending calculating feature flags. For the average request to our backend systems, it amounted to nearly 5% of execution time. Unfortunately, a great deal of the feature flags for which we were spending time calculating had already been enabled to all production workspaces and could have been removed entirely. We built some tooling to urge developers to clean up their expired flags and within just a few weeks had dramatically reduced the time spent processing them. Feature flags really do add up!
If there’s a common thread for why we should clean up each of the kinds of transitional artifacts we produce, it’s to to minimize developer confusion and frustration. Each of these lead to additional complexity, and engineers encountering them risk wasting a considerable amount of time understanding their purpose. We can save everyone ample frustration by cleaning them up!
Tip
As you execute on your refactoring effort, choose a tag that your team can use to label any artifacts you’ll need to clean up. It can be something as simple as leaving an inline comment like TODO: project-name, clean-up post release. Whatever it is, make it easy to search for so that once you’re in the final stages of the project, you can quickly locate all of the places that could use a final polish.
Referencing Metrics in Your Plan
In Chapter 3, we discussed a wide variety of ways we could characterize the state of the world before we began forming a plan of action. We talked about how these metrics should make a compelling case in support of your project to your teammates and management alike. We also described the importance of using these metrics to define an end state at the start of this chapter (see “Defining Your End State”). Now, we need to complement the intermediate steps we identified earlier (see “Identifying Strategic Intermediate Milestones”), with their own metrics. These be useful for you and your team to determine whether you’re making the progress you expected to see, and course-correct early if your trajectory appears off.
Execution plans are also one of the first glimpses management (whether that’s your team’s product manager, your skip-level, or your CTO) will have of a project. For them to support the initiative, not only does your problem statement need to be convincing with clear success criteria, your proposal also needs to include definitive progress metrics. Showing you have a strong direction should ease any concerns they might have about giving the go-ahead on a lengthy refactor.
Interpolating Goal Metrics to Intermediate Milestones
Recall our Table 4-1 where we showed our starting metrics alongside our final goal metrics. For each of our milestones, if the start and end metrics are applicable to our intermediate stages, we can add an entry highlighting which metrics we expect to change and by how much if our metrics lend themselves well to intermediate measurements during the refactor.
End goal metrics that might lend themselves better to intermediate measurements include complexity metrics, timings data, test coverage measurements, and lines of code. Be warned, however, that your measurements might trend worse before they trend better again! Consider the “Dark Mode/Light Mode” approach, for instance; having two code paths, both of which do the same thing, will definitely lead to a tangible uptick in complexity and lines code.
Unfortunately, with our Python migration example, the language version remains the same throughout most of the project. Only once the team has reached the stage of rolling out the new version to each of the company’s environments we start to see our metrics change. To measure progress, we will need to come up with a different set of metrics to track throughout development.
Distinct Milestone Metrics
As the previous section showed, not all end goal metrics will lend themselves well showing intermediate progress. If that happens to be the case, we’ll still need at least one helpful metric to indicate momentum. The metrics we choose might not directly correlate to our final goal, but they’re important guideposts along the way.
There are a number of simple options. Say at Smart DNA we’ve set up continuous integration and enabled the linter to warn on undefined variables. We can use the number of warnings remaining as a metric to measure their progress within the scope of that step. Table 4-2 shows each of the major milestones we brainstormed in ??? with their corresponding metric. (Note that the starting value for the linting milestone is an approximation. The team provided an estimate here by running pylint with the default configuration across the three repositories and summing up the number of warnings generated.)
| Milestone description | Metric description | Start | Goal | Observed |
|---|---|---|---|---|
Create a single |
Number of distinct lists of dependencies |
3 |
1 |
- |
Merge all of the repositories into a single repository |
Number of distinct repositories |
3 |
1 |
- |
Build a Docker image with all of the required packages |
Number of environments using new Docker image |
0 |
5 |
- |
Enable linting through continuous integration for the mono-repo. |
Number of linter warnings |
approx. 15,000 |
0 |
- |
Install and roll out Python 2.7.1 on all environments |
Number of jobs running on Python 2.7.1 with new |
0 |
158 |
- |
Estimating
After taking the time to associate metrics with our most important milestones, I recommend starting to make estimates. Our plan isn’t in its final stages quite yet, so our estimates should not be terribly specific (e.g. on the order of weeks or months rather than days) and, most importantly, generous.
Going back to our cross-Canada raodtrip, we’ve set some general guidelines for when and where we want to stop for food and a good night’s sleep along our trip from Montreal to Vancouver. The longest drive we plan to do is the stretch between Regina, SK and Calgary, AB; just under 800km of highway for roughly a 7.5 hr drive. By making sure that we’re never driving more than 8 hours per day, we’re giving ourselves plenty of time to pack up in the morning from our starting point and decide how to distribute our day. What’s important is that we’ve given ourselves enough time to enjoy the journey; we still intend to make some serious strides every day, but not so serious that we’ll leave burnt out by the time we reach Vancouver.
Most teams have their own guidelines and processes around deriving estimates, but if you don’t have one already (or don’t quite know how to go about estimating a particularly large software project), here’s a simple technique. Go through each of the milestones and assign a number from 1 to 10, where 1 denotes a relatively short task and 10 denotes a lengthy task. Take your lengthiest milestone and estimate how long you think it might take. Now imagine what is most likely to go wrong during that milestone and update your estimate to account for it. (Don’t overdo it! It’s important to be reasonable with the amount of buffer we add to our estimates, otherwise leadership might ultimately decide our refactor is not a worthwhile endeavor.) Now, measure each shorter milestone against this lengthier one. If you anticipate that your longest milestone will take 10 weeks to complete, and your second-longest milestone should take almost just as much time, then maybe 9 weeks is a good estimate. Keep going down the list until you’ve given everything a rough estimate.
From a refactoring perspective, setting generous estimates is important for two main reasons. First, it gives your team wiggle room for when you run into the inevitable roadblock or two. The larger the software project, the greater the chance something won’t go quite to plan, and refactoring is no exception to that rule. Building a reasonable buffer into your estimates will give your team a chance at hitting important deadlines, while accounting for a few pesky bugs and incidents along the way.
Large-scale refactoring efforts tend to impact multiple teams, so there’s a reasonable chance that your project ends up unexpectedly butting heads with another team’s project. Setting generous estimates allows you to navigate those situations more smoothly; you’ll be more level-headed going into negotiations with the other team knowing you have sufficient time to hit your next milestone. You’re more likely to come up with creative solutions to the impasse. If your team needs to pause work on the current milestone, maybe you’re able to quickly pivot, shifting your focus to a different portion of the refactor, and come back to the current work later.
Second, these estimates will help us set expectations with stakeholders (product managers, directors, CTOs) and teams that risk being impacted by our refactor. We’ll ask them for their perspective on our plan next, and if we’re careful to build ample buffer into the estimates we provide, we’ll have some room to negotiate. The next section deals more closely with how best navigate
Remember that you can give the overall project a greater estimate than the sum of each of its parts. Unless your organization is stringent about how to estimate software projects, there is no rule that states that the anticipated project completion date should precisely line up with the completion of its individual components.
Sharing Your Plan with Other Teams
Large refactoring project typically impact a large number of engineering groups of all disciplines. You can determine just how many (and which ones) by stepping through your execution plan and identifying any teams think might be most closely impacted by your refactor at each stage. Brainstorm with your team (or a small group of trusted colleagues) to make sure you’ve covered a variety of disciplines and departments. If your company is small enough, consider going through a list of all engineering departments and for each group decide whether they might appreciate the opportunity to provide input on your plan. Many companies put together technical design committees, where you can submit a project proposal to be critiqued by engineers of different disciplines from across the company. Take advantage of these committees if you can; you’re likely to learn a great deal of useful information well before your kick-off meeting.
There are two primary reasons for sharing your execution plan with other teams. The first, and perhaps most important reason, is to provide transparency. The second is to gather perspective on your plan so as to further strengthen it before seeking buy-in from management.
Transparency
Transparency helps build trust across teams. If you’re up front with other engineers at the company, then they’re more likely to be engaged and invested in your effort. It should go without saying, but if your team drafts up a plan and starts executing on a refactor that impacts a number of groups without warning, you risk dangerously eroding that relationship.
You must be mindful of the fact that your proposed changes could drastically change code that they own, or affect important processes they maintain. With Smart DNA’s Python migration, we’re combining three different repositories into one. This is a significant change for any developers or researchers working in any of these repositories. The teams impacted should be adequately forewarned that their development process is going to change.
The refactor also risks impacting other teams’ productivity. For instance, if we’re proposing to combine all required packages into a single, global requirements.txt file, we may need other teams’ help getting their changes reviewed and approved. We might even inquire about borrowing engineers from other teams to help out with the refactor (see Chapter 6 for a more in-depth look at how to recruit teammates).
Similarly, you have to make sure that your plans align with impacted teams. If you’re planning to modify code owned by another team just as they are planning to kick off development on a major feature (or perhaps their own hefty refactor), you will need to coordinate to make sure you aren’t stepping on each others’ toes.
Perspective
The second reason to share your plan with other teams is to get their perspective. You’ve done the research to define the problem and draft a comprehensive plan, but are the teams that risk being impacted by your proposed changes supportive of your effort? If they do not believe that the benefits of your refactor outweigh the risks and inconvenience to their team, then you may need to reconsider your approach. Perhaps you could convey the benefits in a more convincing manner, or find a way to reduce the level of risk associated with the current plan. Work with the team to figure out what would make them more comfortable with your plan. (You can use some of the techniques outlined in the next chapter to help out.)
If you’re working to refactor a complex product, there are likely a number of edge cases you haven’t considered. Just getting that second (and third and fourth) set of eyes can make a huge difference. Let’s say that while auditing the packages used by the research team at Smart DNA, we fail to notice that some researchers have been manually updating a requirements.txt file on one of the machines directly, rather than making their changes in version history and deploying the new the code. When we share our plan with the researchers, they’ll point out that they typically update their dependencies on the machine itself and that the software team should verify the version there rather than the one checking into their repository. That insight would have saved our software team a great deal of pain and embarrassment had we started executing on the project without consulting the researchers first.
Remember that while it’s important to get stakeholders’ opinions about your plan before kicking off execution, nothing is set in stone at this stage. Your plan will likely change throughout the duration of the refactor; you’ll run into an unexpected edge case or two, maybe spend more time than anticipated solving a pesky bug, or realize part of your initial approach simply won’t work. At this stage, we are seeking out others’ perspectives mostly as a means of ensuring transparency with others and weeding out the blatantly obvious problems early. We’ll discuss how to keep these stakeholders engaged and informed as your plan evolves in Chapter 7.
Refined Plan
At Smart DNA, the software team worked diligently to build a comprehensive execution plan for their migration from Python 2.6 to 2.7. After stepping through each of the steps we’ve outlined, defining a goal state, identifying important milestones, choosing on a rollout srategy, etc., the team’s had a plan they were confident about, as follows:
-
Create a single
requirements.txtfile.-
Metric: Number of distinct lists of dependencies; Start: 3; Goal: 1
-
Estimate: 2-3 weeks
-
Subtasks:
-
Enumerate all packages used across each of the repositories.
-
Audit all packages and narrow-down list to only required packages with corresponding versions.
-
Identify which version each package should be upgraded to in Python 2.7.
-
-
-
Merge all of the repositories into a single repository.
-
Metric: Number of distinct repositories; Start: 3; Goal: 1
-
Estimate: 2-3 weeks
-
Subtasks:
-
Create a new repository.
-
For each repository, add to the new repository using git submodules.
-
-
-
Build a Docker image with all of the required packages.
-
Metric: Number of environments using new Docker image; Start: 0; Goal: 5
-
Estimate: 1-2 weeks
-
Subtasks:
-
Test the Docker image on each of the environments.
-
-
-
Enable linting through continuous integration for the mono-repo.
-
Metric: Number of linter warnings; Start: approx. 15,000; Goal: 0
-
Estimate: 1-1.5 months
-
Subtasks:
-
Choose a linter and corresponding configuration.
-
Integrate linter into continuous integration.
-
Use linter to identify logical problems in the code (undefined variables, syntax errors, etc.)
-
-
-
Install and roll out Python 2.7.1 on all environments.
-
Metric: Number of jobs running on Python 2.7.1 with new
requirements.txtfile; Start: 0; Goal: 158 -
Estimate: 2-2.5 months
-
Subtasks:
-
Locate tests for each repository; determine which tests are reliable.
-
Use Python 2.7 on a subset of low-risk scripts.
-
Roll out Python 2.7 to all scripts.
-
-
Tip
If you use project management software (like Trello or JIRA) to keep track of your team’s projects, I recommend creating some top-level entries for the large milestones. While some of the nitty-gritty details of the refactor might change throughout development, the strategic milestones you defined in this chapter are less likely to shift dramatically.
For the individual subtasks, you should consider creating entries for the first one or two milestones you’re planning to undertake. You can figure out smaller tasks your team needs to tackle at a more regular cadence throughout the development process. Later milestones are more likely to be impacted by earlier work, and the specifics of their individual subtasks risk changing. Create entries for the subtasks of subsequent milestones only as you kick them off.
We’ve done the preliminary work required to understand and comprehensively characterize the work involved with our large-scale refactor, and successfully crafted an execution plan we’re confident will lead us to the finish line smoothly. Now, we need to get the necessary buy-in from our manager (and other important stakeholders) to support the refactor before we can confidently forge ahead.