
Docker emerged in 2013 with their Container technology, although the term Containers can be traced back as far as 2006 with Google’s Process Containers or 2008 with LXC (Linux Containers). In reality, the idea of abstracting and isolating processes and user environments from each other can go back to the mainframe days of yore.

Containers vs. virtualization
Let’s go back to our application developer who works inside a large distributed development team and is creating components of an application that will need to be brought together to make a final working application. He’s creating his part of the application in his development environment and regularly pushes this code to his teams’ code repository which then triggers a whole automated build pipeline to deploy in a development environment for testing.
All good so far. That working application then needs to go to a user acceptance test environment and after that a pre-production environment before finally ending up in its final home, a production environment.
In the past, each of these environments was either manually built by engineers or put together with automation, but either way, they were not immutable, and changes were allowed to happen. This gives us the reason why applications can be buggy or just downright fail by the time they are run by actual users.
Containers abstract the operating system and configuration away from the application, which allows a containerized application to work in exactly the same way in each environment.
A container consists of the application, the complete runtime environment, and all of the dependencies, configurations, and libraries all bundled in one single package. In terms of scale, a container is significantly smaller than a virtual machine, and therefore a physical server host could run a lot more containers than it could virtual machines. Obviously, considering that the container contains the application and not a whole operating system, it means that containers can be started very quickly. This lets us use them only when they are needed to run their bit of code in a true “just-in-time” manner. Similar to what we just learned about AWS Lambda, once a container’s code is run, they can be terminated quickly, freeing up the Host server to run more containers.
Containers came into fashion at the perfect moment when large enterprises were redeveloping their large monolithic applications into new microservice architectures.
But let’s not forget. A container is just a way of presenting compute power to an application. If your business or customer tells you they want to use containers, that’s a good time to challenge them and ask why. What are the goals?
You find that potentially what they really want is to use microservices.
Microservices
Microservice architectures decouple, or deconstruct, application components by separating them into independent services. Each service runs in its processes and communicates externally – and with other microservice-based components in that same application – through APIs. Containers and microservices are a natural fit. Containers provide process isolation that makes it easy to break apart and run applications as independent components.
Modern applications are distributed, cloud native, and built with microservices. A modern application can scale quickly to support millions of users, provide global availability, manage petabytes and potentially exabytes of data, and respond in milliseconds. Applications built with microservices can have a faster release velocity because changes to an individual component are easier to make.
Loosely coupled
Testable and independently deployable
Structured around business capabilities
Owned and maintained by a single small team
Responsible for their own data management
As you can see, they fit very nicely to our cloud tenets and lend themselves for high velocity development and deployment which cloud is perfect for. Being loosely coupled means that we can now think about scaling and resilience. The popularity in developing microservices is directly aligned to cloud adoption. Containers are also a key construct to deliver microservices for cloud-native applications.
Practicing what they preach, or eating their own dogfood (personally, I prefer the former), Amazon switched to small DevOps teams that each own a microservice which they deploy to containers as part of a full CI/CD pipeline. As far back as 2014, it meant that they could reach over 50 million deployments per year.
Another benefit of application development using microservices is that it lends itself to polyglot programming, allowing each microservice to be developed in a programming language that is most appropriate for the task the microservice performs.
A UI or User Interface microservice could be developed in JavaScript, whereas a microservice handling application logic could be developed in C#. While that may sound inefficient from a skill’s perspective for your teams, it would actually be beneficial for the application – with the right language being used for the right task.
There are still challenges however. Moving to a microservice architecture invariably leads to a large increase in the complexity of services and APIs, often referred to as “container sprawl.” Also, we are now moving further away from traditional server technology, and how does that affect our operational processes such as monitoring for instance? Monitoring and visibility of our microservices is vital as there are now more watchpoints.
Moving to a microservice architecture approach is a significant cultural and organizational change for most businesses.
It Works on My Machine
You’ve just been given a new application to deploy into an environment, and you hit problems. The application doesn’t work. So, you go back to the development teams and get the all too familiar “Well, it works on my machine.”
There are many reasons why an application can work in one environment and not in another. Typically, it’s due to the configuration of a system or some underlying dependency that one system has and the other does not. The challenge of making environments the same is as old as when we first started using these systems themselves. Firstly, if you’ve ever tried to manually build more than a couple of servers, you’ll invariably find that one system will give you an issue causing you to provide a workaround that the other systems don’t have. Or you’re tasked with updating systems with security patches or application updates, and for one reason or another, you’ll get an error on an individual system, whereas the same process worked fine on the rest of the server farm. You’ll have configuration drift which is a term used to describe the differences between one system and another. It’s a challenge that has provided us with tools like DSC (Desired State Configuration) and system imaging and naturally leads us to where we are today with CI/CD pipelines and immutable workloads.
Containers are designed to solve the problem of “It worked on my machine” at scale, by isolating software from its environment and ensuring that it works uniformly, despite any differences in deployment locations.
A container image is a super lightweight executable package of software which will include everything required to run an application. This will include the application code, any runtimes required, any libraries, and also system tools and configuration settings. A container is created by running a container image. Once built, the container image is immutable; therefore, we see containers as the target for application deployments via CI/CD pipelines. Portability ensures that a container image can be run on many hosts. We can therefore have different container images with different versions of our application all happily running on the same host and allowing true Blue/Green deployments of our apps.
Speed is also a key characteristic of using containers. The ability to start a container within seconds provides huge benefit when it comes to application deployments.
This leads us to a question. How do containers work in our Microsoft landscape? We will be discussing this, but first let’s look at the AWS container services.
Amazon Elastic Container Service (ECS)
AWS launched their first container service, Amazon Elastic Container Service (ECS), in November 2014, providing Docker containers on AWS as part of a fully managed service. AWS ECS is a container orchestration service that handles the Docker cluster management, allowing users to focus instead on building and running your container resources.
Amazon Elastic Container Service is a fully managed container orchestration service that supports container workloads at production scale with a high level of automation that can handle thousands of hosts running millions of containers.
Amazon ECS gives you the option of running containers on Amazon EC2 which offers you more flexibility or using Amazon Fargate which completely manages your container infrastructure.

Amazon ECS objects and how they relate
Starting with the ECS cluster which is a logical grouping consisting of services and tasks which once configured and deployed allows us to run containers using task definitions. Generally, it’s best practice to have different clusters for different environments, so test, development, production, and so on. You can scale the clusters up and down via the Amazon ECS console.
Next comes the service layer which allows you to run and maintain a specified number of simultaneous instances of a task definition. If any tasks were to stop or fail, the service scheduler launches a fresh Instance to replace them.
Then the task definition defines which image to use for a container and how much memory, CPU, networking including subnet placement and security groups to attach. Also, it includes any commands to run and what storage should be allocated. Task definitions can be affected by constraints and strategies which can be added when a task is run.
Last is the container definition which is the container image and the application that you want to use.
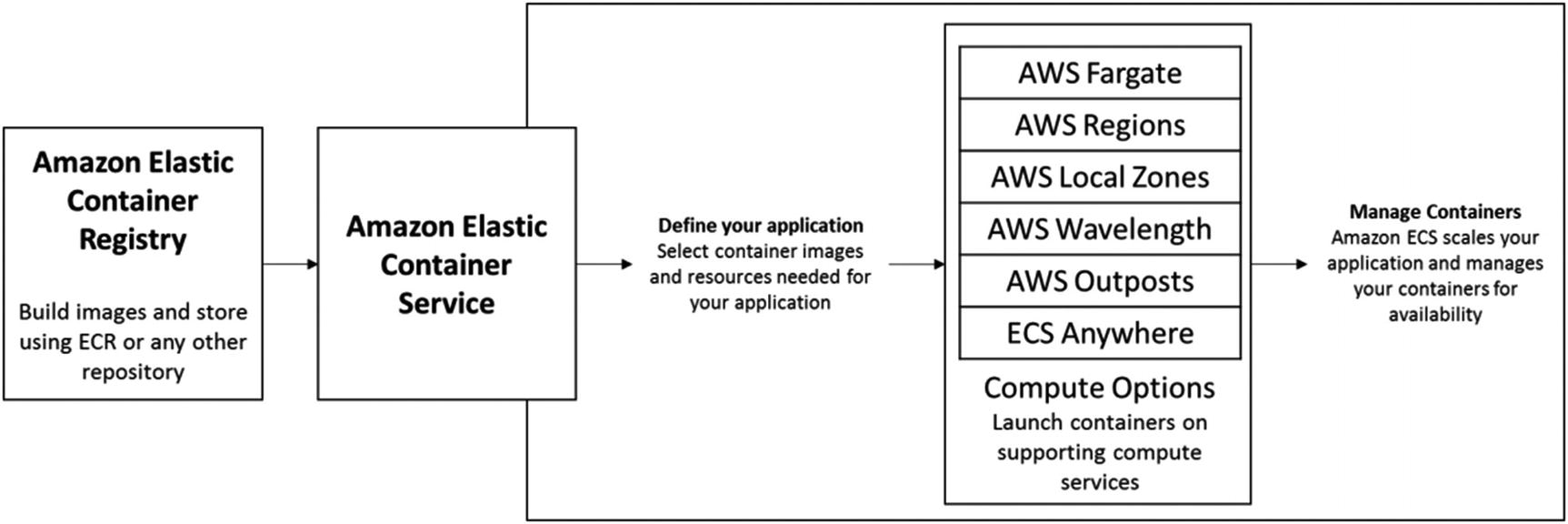
Amazon Elastic Container Service
One of the side effect benefits of Amazon Auto Scaling Groups (ASGs) is their ability to ensure that the number of instances running in an Auto Scaling Group matches the minimum number we configure when they are created. Sounds logical so far, but the effect of this logic is that should an Amazon EC2 Instance fail or terminate for some reason, the Auto Scaling Group will automatically provision a replacement, effectively giving us a self-healing container cluster.
What if you want to run specific containers on specific Instances? For example, if you have containers that require specialized hardware such as graphic processors or maybe you are placing container hosts across multiple Availability Zones, the placement engine handles all these requests for you.
A daemon called the Amazon ECS Container Agent runs on each Amazon EC2 host in a cluster. This agent enforces resource allocation at an EC2 level and provides monitoring metrics.
AWS Elastic Container Registry

Amazon Elastic Container Registry (Amazon ECR)
Adding images to Amazon ECR doesn’t mean I have to use them with Amazon ECS or EKS (Amazon Elastic Kubernetes Service). I can actually call on the container images from multiple sources including bare metal EC2 or even on-premises.
Amazon Elastic Container Registry isn’t the only register of container images. There are also public registries such as the official Microsoft Container Registry (MCR) on dockerhub (https://hub.docker.com/publishers/microsoftowner).
Amazon ECR, on the other hand, is a completely private container registry fully controlled via Amazon IAM which encrypts all images automatically.
As is normal with AWS Services, Amazon ECR is fully managed and highly available by default. A great feature is something called Amazon ECR lifecycle policies which allow you to define a set of rules that remove and retire older container images automatically. You can create rules based on tags, so you can pinpoint different environments or different versions of an image. This saves a huge amount of housekeeping when you have a large number of images.
AWS Fargate
You’ll often hear reference to AWS Fargate as “a serverless container service.” The key reason it’s earned that title isn’t due to its fully managed nature or the abstraction of hosts or even its ability to scale on demand with built-in high availability. The reason why AWS describes AWS Fargate as serverless is that it scales by unit of consumption rather than by a per-server unit, aligning it far closer to AWS Lambda than to Amazon EC2.
Why do we need another container service? Well, running Amazon ECS in EC2 mode still means we have to manage a few things such as the operating system of the host, the Docker, and Amazon ECS agents. AWS Fargate allows the user to manage only their containers. AWS Fargate handles all of the underlying infrastructure in a complete pay-as-you-go model.

AWS Fargate
AWS Fargate provides ephemeral storage for each running container based on Amazon EBS. Each task is allocated approx. 10GB and also a special 4GB volume of scratch space to share data between containers. AWS Fargate also integrates heavily with AWS IAM to provide fine-grained access permissions at the cluster, application, and housekeeping level.
More information on this can be found here: https://docs.aws.amazon.com/AmazonECS/latest/userguide/security-iam.html.
AWS Elastic Kubernetes Service (EKS)
Kubernetes is an open source platform for managing containers, created by Google and now managed by the Cloud Native Computing Foundation (CNCF). Created to allow containers to run at significant scale and developed using a software development lifecycle in mind, Kubernetes handles how your applications work inside the container cluster, which we call container orchestration.
Using the container building blocks provided by Docker, Kubernetes uses a master/worker architecture where the master coordinates the cluster and the workers are the nodes that run applications.
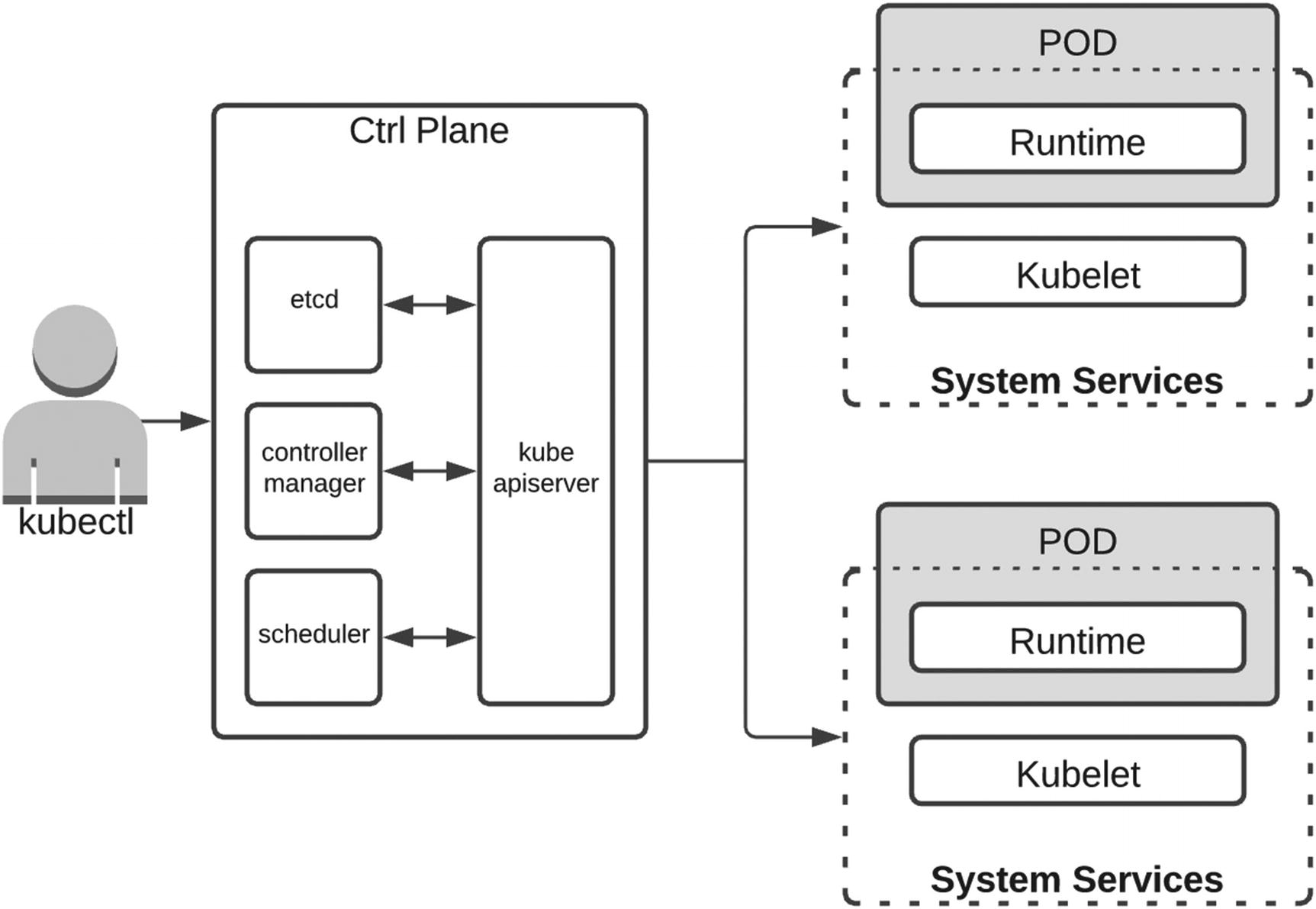
The Kubernetes architecture
Amazon EKS creates your Kubernetes clusters and manages the availability and scalability of the control plane across three Availability Zones, allowing users to focus entirely on building applications.
Kubernetes has grown from almost a decade of development, and there are lots of features to understand. The best place to start is the official documentation at https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/.
The 6-Gigabyte Elephant in the Room
Now that we understand what AWS Services are available for us to use, where does this leave those of us wanting to run Microsoft workloads on containers?
Let’s go back to the launch of Windows Server 2016 when Windows containers were first introduced. Microsoft had to reach out and partner with Docker to make this happen. That’s a full 2 years since AWS launched Amazon ECS and 3 years after Docker exploded into our IT universe. It’s fair to say that, once again, Microsoft was playing catch-up.
Windows containers are just not the same as traditional Linux containers; since the internal OS architecture is significantly different, there has had to be a lot of effort from both Docker and Microsoft to make Windows containers a possibility.
To make containers lightweight, interoperable, and fast, they use a shared kernel. This also poses a slight security risk when running on Windows Server because of the tight coupling between APIs contained in DLLs and the underlying OS services. So, if a shared Windows kernel is hacked in some way, then all the containers using it are exposed. This is the reason why Microsoft has two versions of its container technology.

Windows Server Container architecture
There’s also the question of compatibility with containers running on different versions of Windows and also what the different editions that are available are capable of. As you can see, containers on Windows can be complex!
If you want to run a Windows Server container on Server 2016, then that container must be built from a Server 2016 base. Running the same container on the 2016 Semi-Annual Channel releases like version 1709 or 1803 will mean the container will not work. It means you must only run containers on the same OS version as the host.
Even with all this complexity around versions and isolation, the reason that stops companies considering running Windows containers is the size of the image. When it was launched, Windows Server 2016 was a whooping 6GB in size. Compare that to a standard Linux image of between 2MB and 200MB, and you’ll see some obvious shortcomings in terms of being able to run Windows containers that start and terminate quickly in order to run a task.
Microsoft is working hard to reduce this footprint. After Windows Server 2016, it released the first version of Windows Nano Server, a container-focused image with a much smaller footprint and a subset of the full functionality of standard Windows Server.
But it’s not only footprint alone that Microsoft has to work out a solution for, because the real issue here is not one of image size, and any associated storage that requires, but rather the large size causing delays in both container creation and startup. It makes sense that the larger the container, the longer it takes to run your application.
Windows Nano Server
Microsoft Windows Nano Server was an option during a Windows Server 2016 deployment. It’s a 64-bit-only edition with a cut-down amount of functionality but also a number of welcome benefits.
The upside of being able to support a minimal amount of server roles is that only a small subset of security patches need to be applied; this also has a knock-on effect in the amount of reboots required and therefore the amount of uptime you should expect.
The biggest benefit that Windows Nano Server has to offer is in its footprint. The image size of Windows Nano Server was a mere 400MB, which is still double what an average Linux image is but on the other hand is a gigantic 15 times smaller than Windows Server 2016. Smaller footprint means faster setup time, and in comparison to Windows Server 2016, Nano Server is nearly eight times faster during setup.
Managing Windows Nano Servers cannot be done via Remote Desktop Protocol (RDP), SSH, or an actual login to the server. Access is via the Nano Server Recovery Console, Windows Remote Management (WINRM), or PowerShell Remoting.
Apart from having to manage Windows Nano Server differently than the rest of your Windows Server estate, all seem good right? Small, fast, perfect!
Well, that really depends on what you plan to do with your Windows Nano Server once it’s running. Windows Nano Server does not support MSI Windows installations, so getting your apps installed is going to require a different approach. Also, there are no GUI features at all, so getting your apps configured and running is also going to require some thought.
Windows Nano Server is also not able to run full .NET applications. But you can run .NET Core.
This really begs the question: if I can only run .NET Core applications, then surely I’d be better off doing that with a more streamlined Linux distro than using Windows 2016 Nano Server?
As we’ve learned, Windows Nano Server is really a mixed bag of potentials and constraints. But Microsoft has learned lessons, and things do get better with Windows Server 2019.
Windows Server 2019
Microsoft Windows Server 2019 has embraced containers. Certainly, more than its predecessor did. It still gives you the options of Windows Containers or Hyper-V Containers, but Docker now becomes integrated much tighter with the ability to install the containers feature.
By default, only Windows Containers are allowed; an upgrade to Docker Enterprise Edition is needed to also run Linux containers natively from the OS. It’s also good practice to keep your Windows and Linux containers on separate clusters.
Another welcome enhancement has been the image size which is 1.5GB for Server 2019 and just 98MB for Nano Server 2019.
AWS’s support for Windows Server 2019 containers began in June 2019 with the ability for customers to run 2019 containers on Amazon ECS. This was followed up with Kubernetes support using Amazon EKS in October 2019.
Containers will continue to play a significant role in Microsoft’s strategy moving forward. It really has no choice since enterprises have really embraced containers as part of their digital transformations, and Microsoft already faces a very real threat to its enterprise dominance from Linux.
Supporting Containers
Now that we have our Docker and Kubernetes clusters up and running with hundreds of Windows containers, our thoughts turn to exactly how are we going to support these containers operationally? Fortunately, AWS has some great services that can help here.

Kubernetes Web UI Dashboard running on Amazon EKS
A full tutorial on how to set up this dashboard to run on your Amazon EKS cluster can be found here: https://docs.aws.amazon.com/eks/latest/userguide/dashboard-tutorial.html.
Docker has Prometheus which can be run as a ready-built appliance via the AWS Marketplace and also integrated with the monitoring service, AWS CloudWatch (https://aws.amazon.com/blogs/containers/using-prometheus-metrics-in-amazon-cloudwatch/).
It’s worth reminding ourselves that there are also multiple third-party container monitoring solutions available.
Using AWS CloudWatch allows us to monitor the whole container cluster holistically. We can monitor the EKS worker nodes and Docker hosts, whether they are Linux or Windows, that make up our environment. Pulling metrics from the hypervisor and container level, we can create dashboards focused on our container health as well as our entire AWS estate.

AWS CloudWatch Container Insights
An often-requested feature from the Windows container community is the ability to join containers to an Active Directory domain. This can be useful in terms of container security and administration or have their container application authenticate to another service.
A school of thought exists that dismisses the requirement of using AD with containers. Containers should be short-lived immutable places to run your microservices, whereas adding them to an Active Directory domain suggests that they will be stateful and long-lived. However, a use case exists where a container might need to be domain joined for authentication or security reasons.
AWS launched this update during AWS re:Invent 2019 using an Active Directory feature called Windows Group Managed Service Accounts (gMSA). This is available for both Amazon ECS and EKS and is implemented by the use of a credential spec file via a task definition.
AWS App Mesh
Let’s step back for a second and think about our new way of developing applications using multiple microservices rather than one huge monolith. You can see there are lots of benefits to this approach, particularly in terms of supportability, agility in getting out new features, and ownership from small two-pizza teams who are now responsible for individual microservices rather than a whole department reasonable for the entire monolith.
We mentioned at the start of this chapter there are also disadvantages in terms of complexity. Each microservice needs to be aware of the microservices it needs to communicate with and also understand where those microservices live after being updated since they may well have different IP addresses or DNS names.
This is the problem that AWS App Mesh solves.
AWS App Mesh provides uniformity when it comes to inter-service communication, and this becomes very important if you consider who will use microservices and how you’ll deploy your application updates to them via rolling or Blue-Green deployments. AWS App Mesh provides a proxy which sits alongside all microservices, whereas the AWS App Mesh control plane manages all the proxies.
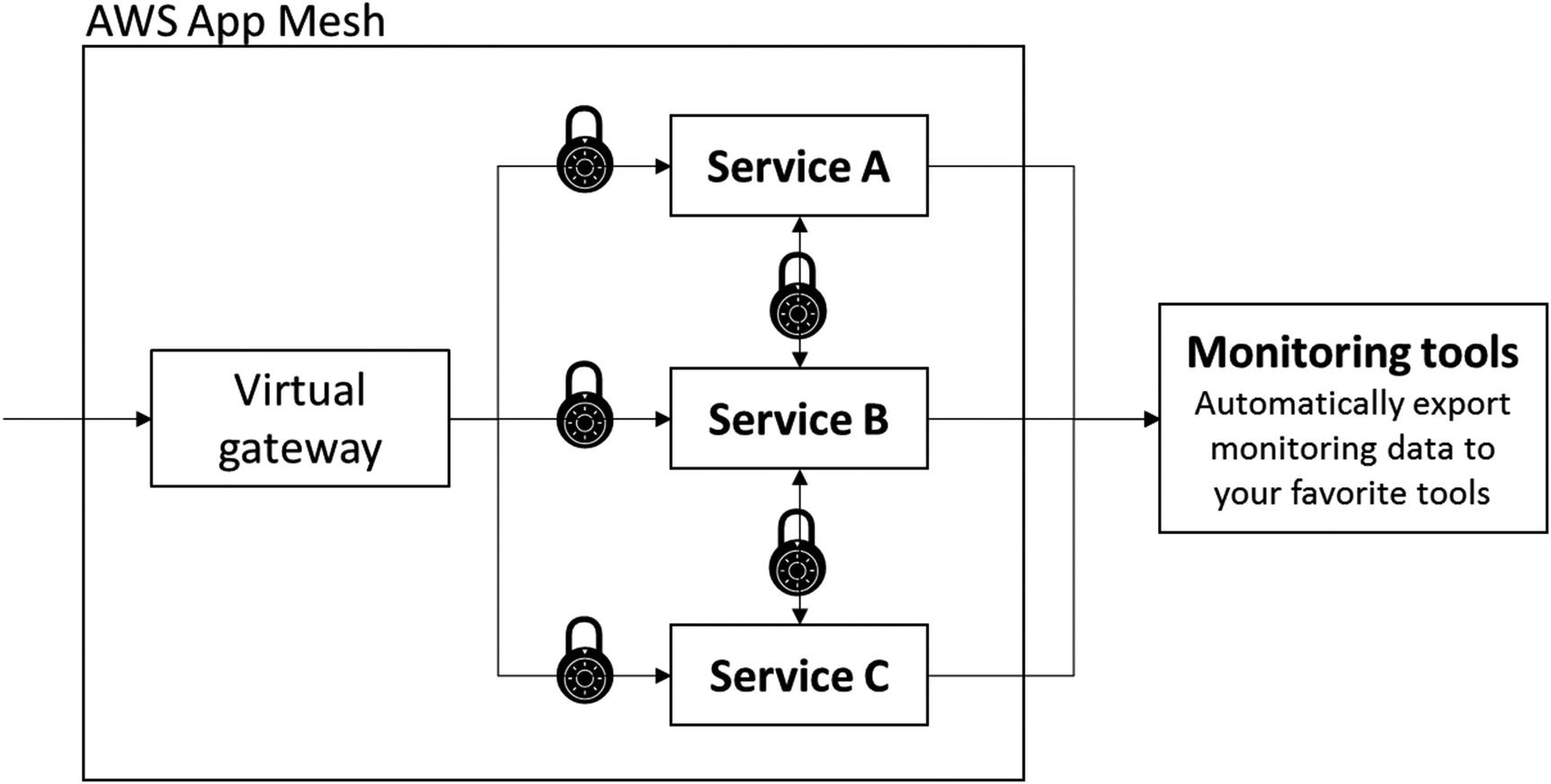
AWS App Mesh
AWS App Mesh (Figure 7-10) also provides network traffic shaping and routing capabilities between microservices while also integrating closely with another service, AWS Cloud Map.
AWS Cloud Map
One final piece in the container puzzle is the ability to discover new microservices when they are constantly being updated or new functionality introduces them.

AWS Cloud Map overview
You start by creating a namespace and then decide how your applications can be found via their endpoints. AWS Cloud Map also integrates with Route 53 and will monitor the health of your services and mark them as unhealthy in the registry if they do not respond.
Summary
We’ve covered a lot of different technologies during this chapter, and this is very much a high-level view of the world of Windows containers on AWS. There is an awful lot of information to dive deep into if this is an area you’d like to pursue.
Microservices are very much the current phase of application development, and you may already be running containers in your own AWS accounts. We’ve found the journey to understand Microsoft Windows containers to be confusing at times with lots of options and advantages/disadvantages we need to process to understand what works for us.
It’s also very welcome that AWS seems to be leading the way in the field of containers and pouring significant effort into developing services and features to help with this new deployment paradigm – not only improving their Docker and Kubernetes services but also developing a mature ecosystem of services that support us.
A statistic that sums this up and reinforces why we use AWS in the first place is this: 80% of containers running in the cloud run on AWS.