

Chapter 2
Characters and Terminology in Computing
In hindsight, what we have done is invented a computer communications Tower of Babel.
—Edwin Hart
Bits and Bytes
A Brief History of Character Encoding Standards
ASCII
ISO 8859
Other 8-Bit Encoding Schemes
Multi-octet Encoding Schemes
Problems with Encodings
Unicode
Transcoding
Chapter Summary
Bits and Bytes
In the context of computing, the terms character set, code page, and encoding are often used interchangeably or as synonyms. This is not quite correct. We need to find a better definition of all these pieces and see how they fit together.
So, how do we relate abstract characters to the bits and bytes used in the computer, and what are bits and bytes, anyway?
When text is entered via the keyboard, binary code is sent that represents the keystrokes. The code itself corresponds to the two states, on (1) and off (0), of the electronic circuits that make up a computer’s hardware. The smallest unit of information in computing is called a bit, or binary digit, which means two—because it has two states, on and off. The individual bits are usually grouped together into 8-bit bytes, or multiples of 8. Hence, characters of natural-language writing systems are eventually represented digitally as combinations of zeros and ones.
We can imagine such a system as a grid where characters from an abstract character repertoire are mapped to a set of unique numbers (nonnegative integers). The result of such a mapping is usually called a coded character set, and the numbers are called code points or code positions. For example, in ASCII, the letter A is represented as 0100 0001. Since binary numbers are difficult to read, other numbering systems are used such as the decimal notation. Hence, in a grid with the values 0 to 15 along each axis, the letter A is described by the value 04/01. More frequently used is the hexadecimal system, which replaces 10, 11, 12, 13, 14, and 15 by A, B, C, D, E, and F, respectively. It provides “a condensed way of representing large binary numbers,”1 and it allows all characters in a code to be described with the same number of digits in all cases.2 It groups 4 bits to 1 hexadecimal character. Hence, A (in ASCII) is hexadecimal 41.
Coded character sets can use the same character repertoires but assign different integers to the same characters; examples are ISO 8859-1 and the IBM EBCDIC code page 1148, which both use the Latin 1 character repertoire. The code point for Ä (Latin capital letter A with dieresis), in ISO 8859-1, for instance, is 99 in decimal and 63 in hexadecimal notation. In code page 1148, it is 196 in decimal and C4 in hexadecimal notation. Hexadecimal notation is more commonly used for identifying characters. But since knowing whether data is being represented as decimal or hexadecimal is sometimes difficult, a frequently used convention is to put “0x” in front of hexadecimal numbers. This convention will be used throughout the book. So you might see, for example, 0xc4.
In a next step, we map from the set of integers used in a coded character set to a sequence of binary codes to get a character encoding scheme (or simply called an encoding).3 These binary codes are defined as octets because they consist of 8 bits. An octet is usually equivalent to a byte, but since there used to be computers that had bytes with fewer than 8 bits, the term octet is preferred in technical contexts.
In an alternative definition, an encoding results from applying an encoding method to a (coded) character set. An encoding method is a set of rules that assign numeric representations to a set of characters. These rules govern the size of the encoding (the number of bits used to store the numeric representation of the characters) and the ranges in the encoding where characters appear.
To summarize: A coded character set assigns numbers to characters, and an encoding defines the way those numbers are stored in the computer. Hence, Unicode is not an encoding, but a (coded) character set, and UTF-8 and UTF-16 are encodings of the Unicode character set.
The term code page for a coded character set originated in the IBM world,4 but is also used by Microsoft5 and others. The term character set has a variety of meanings and uses. It can mean an abstract character repertoire, a coded character set, as well as a character encoding scheme. The IANA Charset Registry6 lists the official names for character sets that can be used by Internet protocols, in MIME headers and Java, for instance.
Often there is a one-to-one mapping between the coded character set value and the encoded value for this character. This is the case for ASCII, the ISO 8859 series, and others. But things are not so simple for multi-byte encodings and Unicode, as we shall see in the next section.
UTF-8 is an example of an encoding that is associated with only one particular (coded) character set. But there are others that can be associated with multiple character sets. EUC,7 for instance, can be used to encode characters in a variety of Asian character sets. To distinguish these, the region identifier of the character sets that EUC supports is used in the name of the encoding: EUC-JP for Japanese, EUC-KR for Korean, EUC-CN for Simplified Chinese, and EUC-TW for Traditional Chinese.
A Brief History of Character Encoding Standards
I am not going to talk about historic systems from pre-computer times such as the Morse or Baudot codes. A number of books and Web sites offer good information on these. (I will mention some of them in the References section.) Instead, I will start with “good old ASCII,” the basis of encodings used in almost all present-day computers.
ASCII
Since the early days of computing, many different encodings have been developed. One of the first standards to emerge was ASCII (American Standard Code for Information Interchange), which is a 7-bit8, 128-character code set that was adopted in the early 1960s by the American National Standards Institute (ANSI). It includes uppercase and lowercase letters A–Z, as well as digits, symbols, and control characters. Altogether, ASCII provides for 95 printable characters (including the space). Thirty-three code points are reserved for non-printing control characters (now mostly obsolete). ASCII was eventually adopted as an international standard by the International Organization for Standardization (ISO) under the name of ISO 646-IRV in 1972. (IRV stands for International Reference Version.)
ASCII/ISO-646 could not satisfy everyone’s needs because it does not contain national characters (ä, é, ñ, and so on) used by languages other than English. This is why the national variants of ISO-646 were developed. There are national-use code positions for the following 12 characters of the original ASCII set: #, $, @, [, ,], ^, `, {, |,}, and ~. The International Reference Version preserves the original ASCII code positions, whereas the national variants assign other characters to these code positions as shown in the table below.
Table 1: Examples of National-Use Code Positions in ISO-646
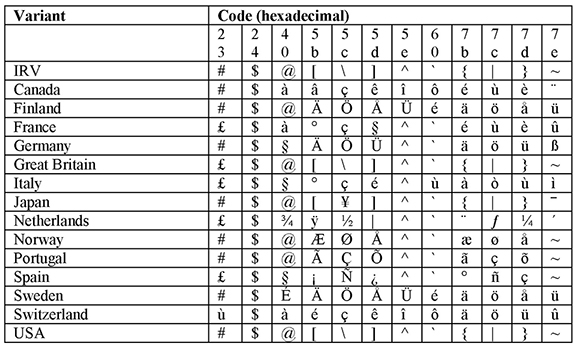
Programs written in C looked odd when using national-use code positions. For example, consider the following code snippet:
#include <stdio.h>
int main (int argc, char *argv[])
{
return 0;
}
It looked like this in the French version of ISO 646:
£include <stdio.h>
int main (int argc, char *argv°§)
é
return 0;
è
For the C compiler, this did not matter, since the compiler understood that the code value 0x7b means begin and 0x7d means end, for instance.
The national variants of ISO-646 are hardly used these days if at all, and we would not bother about them any more if national-use code positions did not haunt mainframe users even today in the form of variant characters9 that are used in many EBCDIC code pages. Another reminiscence of this practice can be found in many Japanese standards (for example, JIS X 0201) that assign the yen sign (¥) to the code value of the backslash ().
As one can easily see, this was not a satisfactory solution, not only because it was complicated to use but also because it did not provide enough space for all national characters. By using the eighth bit of an octet, 128 additional code positions became available. In the following years, a great number of new coded character sets were defined. Most of them maintained the standard US-ASCII values for the lower 128 characters (the notable exception are the EBCDIC code pages, as we shall see later). Hence, these code sets can be regarded as ASCII extensions or as extended ASCII as they are sometimes called.
Before Unicode there were dozens of different encoding systems besides ASCII. By 1989, Edwin Hart had written: “In hindsight, what we have done is invented a computer communications Tower of Babel.”10 And there were even more encodings to come.
Even within Europe, one needed several encodings in order to cater to the character sets of the different languages. Most of these systems did not contain the complete character repertoires of even one language (including common special and punctuation characters). Moreover, all these character encodings are not compatible among themselves, because they use different code positions for the same characters. Hence, a multitude of conversion programs was and is necessary.
ISO 8859
The International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC) released a series of standards for 8-bit encodings under the name of ISO/IEC 8859. The ISO 8859 standard is divided into the following parts:
- ISO 8859-1 (Latin-1) for Western European languages
- ISO 8859-2 (Latin-2) for Central and Eastern European languages
- ISO 8859-3 (Latin-3) for Southern European languages
- ISO 8859-4 (Latin-4) for Northern European languages
- ISO 8859-5 (Cyrillic) for Russian, Bulgarian, and other languages
- ISO 8859-6 for Arabic
- ISO 8859-7 for Greek
- ISO 8859-8 for Hebrew
- ISO 8859-9 (Latin-5) for Turkish (replaces Latin-3)
- ISO 8859-10 (Latin-6) for Northern European languages
- ISO 8859-11 for Thai
- ISO 8859-13 (Latin-7) for Baltic languages (replaces Latin-4)
- ISO 8859-14 (Latin-8) for Celtic languages
- ISO 8859-15 (Latin-9) for Western European languages (replaces Latin-1)
- ISO 8859-16 (Latin-10) for Eastern European languages (replaces Latin-2)
The ISO 8859 standards reserve the range 0x7f-0x9f for control characters (and for the range 0x00-0x1f that was already defined by the ASCII standard), so 96 printable characters are available in addition to the ones defined in ASCII. Now, let us have a closer look at the ISO 8859 family members.
ISO-8859-1 (Latin-1)
The following table shows the layout for ISO Latin-1. Control characters have a shaded background.
Table 2: ISO 8859-1 Code Chart
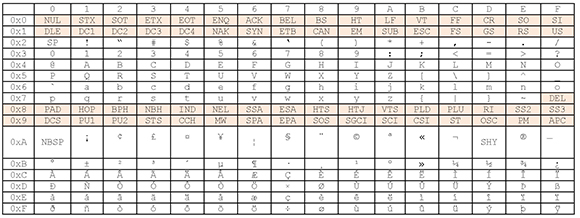
Before Unicode, ISO 8859-1 was the default encoding for HTML documents and for documents transmitted via MIME messages. Hence, most Web browsers and e-mail software used it as the default when no encoding was specified.
ISO Latin-1 was supposed to contain all the characters needed to write most Western European languages and some others: Afrikaans, Albanian, Basque, Breton, Catalan, Dutch, English, Faeroese, Finnish, French, German, Icelandic, Irish, Italian, Luxembourgish, Norwegian (Bokmål and Nynorsk), Occitan, Portuguese, Rhaeto-Romance, Scottish Gaelic, Spanish, Swahili, and Swedish. However, some characters needed for French (the ligatures œ and Œ and the uppercase letter Ÿ), Dutch (the ligature ij) and Finnish (Š, š, Ž, and ž) were missing. These design flaws were corrected with the introduction of Latin-9 (ISO 8859-15), which also brought the Euro symbol instead of the universal currency sign.
ISO-8859-2 (Latin-2)
ISO Latin-2 includes the characters needed for the languages of Central and Eastern Europe that are written with the Latin alphabet: Bosnian, Croatian, Czech, Hungarian, Polish, Romanian, Slovak, Slovenian, and Sorbian. It also contains the characters needed for German (at exactly the same code position as in Latin-1) and Albanian. Again, there are some minor flaws: for Romanian, the letters S and T should have used a “comma below” instead of the cedilla. This was corrected with the introduction of Latin-10 (ISO 8859-16), which, as did its Western counterpart Latin-9, replaced the universal currency sign with the Euro symbol.
ISO-8859-3 (Latin-3)
ISO Latin-3 was designed for Turkish, Maltese, and Esperanto. It can also be used for other southern European languages such as Italian and Spanish, as well as for German. For Turkish, it was later superseded by Latin-5 (ISO 8859-9), which differs from ISO 8859-1 in only six positions.
ISO-8859-4 (Latin-4)
ISO Latin-4 includes the characters of the Baltic languages (Estonian, Latvian, and Lithuanian) as well as the languages of Greenlandic and Lappish. It was superseded by Latin-6 (ISO 8859-10), which also includes all of the characters required to write Icelandic.
ISO 8859-5 (Cyrillic)
ISO Cyrillic covers the Slavic languages written with the Cyrillic alphabet: Bulgarian, Byelorussian, Macedonian, Russian, Serbian, and Ukrainian.
ISO 8859-6 (Arabic)
ISO Arabic covers the basic Arabic alphabet. In practice, the text is in logical order (as opposed to visual order).11 It does not reflect the fact that each Arabic letter can take any of four shapes, depending on whether it stands alone or whether it falls at the beginning, middle, or end of a word; therefore, bidirectional (BiDi) processing12 is required for display.
ISO 8859-7 (Greek)
Similar to ISO 8859-6, ISO Greek has only the plain Greek letters and only a few letters with accents (monotonic Greek).
ISO 8859-8 (Hebrew)
ISO Hebrew covers (modern) Hebrew. It has only the Hebrew consonants and long vowels but not the short vowels or any other diacritical marks. The text is (usually) in logical order, so bidirectional processing is required to see it displayed correctly.
ISO 8859-9 (Latin-5)
Latin-5 supersedes Latin-3 and replaces the Icelandic letters Ð, Ý, Þ, ð, ý, and þ from Latin1 with the Turkish ones: Ğ, İ, Ş, ğ, ı, and ş.
ISO 8859-10 (Latin-6)
Latin-6 supersedes Latin-4 and includes all of the characters required to write Icelandic.
ISO 8859-11 (Thai)
ISO Thai is almost identical to the Thai standard TIS 620; the only difference is that ISO 8859-11 allocates the nonbreaking space to code position 0xA0, while TIS-620 leaves it undefined.
ISO 8859-12
ISO 8859-12 was slated for Latin/Devanagari, but this was eventually abandoned in 1997. Devanagari (as other Indic scripts) is encoded in the Indian Standard Code for Information Interchange (ISCII), which is now largely superseded by Unicode (see below).
ISO 8859-13 (Latin-7)
Latin-7 covers the Baltic languages and includes added characters that were missing from the earlier ISO 8859-4 and ISO 8859-10.
ISO 8859-14 (Latin-8)
Latin-8 covers the Celtic languages: Irish, Scottish Gaelic, Manx, Welsh, and Breton.
ISO 8859-15 (Latin-9)
Latin-9 differs from Latin-1 by supporting eight new characters, most notably the Euro symbol €, but also Š, š, Ž, ž, Œ, œ, and Ÿ.
ISO 8859-16 (Latin-10)
As does Latin-9, the last member of the ISO 8859 family places the Euro sign (€) in the cell 0xA4 of the former international currency sign (¤). Otherwise, it covers the same languages as Latin-2 but now has the correct Romanian letters S and T “with comma below.”
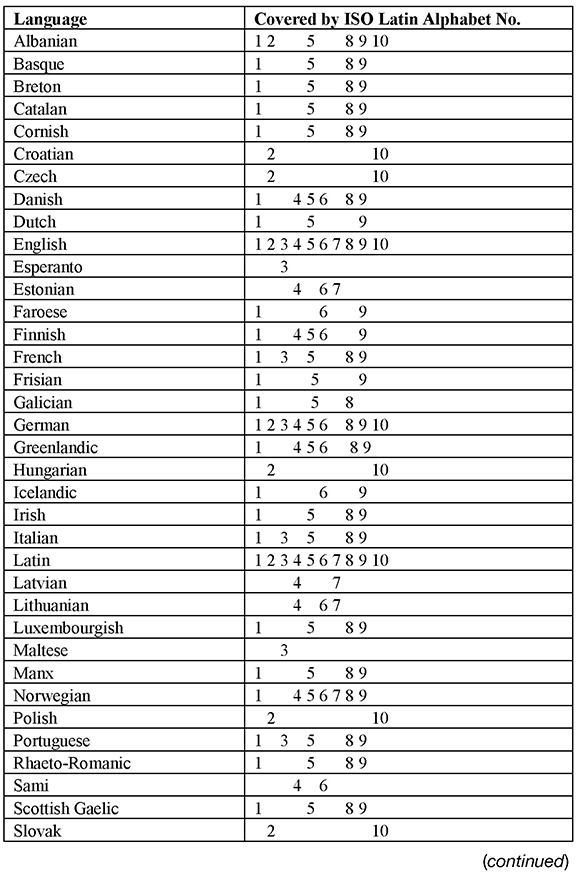
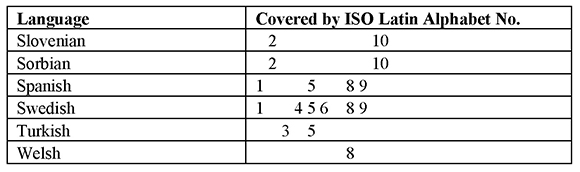
The following table lists European languages written with the Latin script and the various ISO standards that cover these.
Table 3: Coverage of Languages by ISO 8859
Other 8-Bit Encoding Schemes
Apart from the ISO 8859 standards, various proprietary ASCII extensions have emerged. Most widespread are the Microsoft Windows code pages, commonly called ANSI code pages, because 1252, the first one, was based on an American National Standards Institute (ANSI) draft.13 That draft eventually became ISO 8859-1, but Windows code page 1252 (also known as Windows Latin-1) is not exactly the same as ISO Latin-1. In fact, it is a superset of ISO Latin-1. MS-DOS and console programs continue using the so-called OEM code pages.14 Their character repertoires are similar to the ANSI code pages but at totally different code positions. Also, they contain a lot of box-drawing characters.
Windows ANSI Code Pages
The following list includes some of the Windows ANSI code pages:
- 874 for Thai
- 1250 (Latin-2) for Central and Eastern European languages
- 1251 (Cyrillic) for Russian, Bulgarian, and other languages
- 1252 (Latin-1) for Western European languages
- 1253 for Greek
- 1254 (Latin-5) for Turkish
- 1255 for Hebrew
- 1256 for Arabic
- 1257 for Baltic languages
- 1258 for Vietnamese
In contrast to the (mostly) corresponding ISO 8859 encodings, the Windows ANSI code pages do not use control characters in the 0x80–0x9F range but fill this space with additional graphic characters. Beginning with Windows 98, the Euro symbol was added at position 0x80 for 1250 Eastern European, 1252 Western, 1253 Greek, 1254 Turkish, 1257 Baltic, 1255 Hebrew, 1256 Arabic, 1258 Vietnamese, and 874 Thai; in 1251 Cyrillic, the symbol was added at position 0x88. This is again in contrast to the ISO encodings that created new encodings (for example ISO 8859-15) instead of adding the Euro sign to existing ones. Likewise, IBM created new EBCDIC code pages in support for the Euro currency symbol (see Table 8).
Code Page 1252 (Windows Latin-1)
The code range 0xA0–0xFF is identical to ISO 8859-1; also, the range between 0x80–0x9F contains the characters needed for French and Finnish that were missing in ISO Latin-1. The differences in the ISO codes are highlighted in lines 0x8 and 0x9 in Table 4.
Table 4: Windows 1252 Code Chart
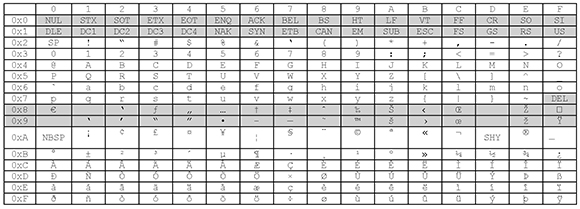
Code Page 1250 (Windows Latin-2)
Windows Latin-2 supports the same languages as ISO Latin-2, but differs from it in several code positions.
Code Page 1254 (Windows Latin-5)
For Turkish, there is no Windows Latin-3 or Windows Latin-4, but there is a Windows Latin-5. It differs from Windows Latin-1in the same way that ISO Latin-1 does from ISO Latin-5, which is in only six positions.
Code Page 1251 (Windows Cyrillic)
Windows Cyrillic is not compatible with ISO 8859-5 (Cyrillic) nor with KOI-8, which is another encoding standard that was widely used for Cyrillic in the past.
Code Page 1253 (Windows Greek)
Windows Greek differs from ISO 8859-7 (Greek) not only in the 0x80–0x9F range (as all Windows code pages do) but also in seven code positions; the most important one is probably the one for the Greek Capital Letter Alpha with Tonos.
Code Page 1255 (Windows Hebrew)
Windows Hebrew is letter-compatible with ISO 8859-8 (Hebrew); that is, the letters are in the same positions (except for 0xa4 where Windows Hebrew has the new shekel sign and ISO 8859-8 has the international currency sign). Also, Windows Hebrew has points and punctuation marks to represent vowels or distinguish between alternative pronunciations of letters of the Hebrew alphabet. Moreover, Windows Hebrew is always in logical order, which makes it the Hebrew encoding that can be found most frequently on the Web.
Code Page 1256 (Windows Arabic)
Windows Arabic is used to write Arabic and other languages that use the Arabic script. It is not compatible with ISO 8859-6.
Code Page 1257 (Windows Baltic)
Windows for the Baltic languages is neither compatible with ISO 8559-4 nor with ISO 8559-10.
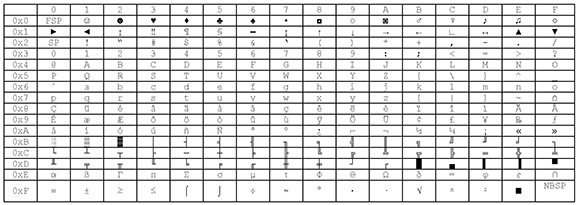
The OEM code pages that are used by Windows console applications, and by virtual DOS, can be considered a holdover from DOS and the original IBM PC architecture. These code pages were designed so that text-mode PCs could display and print line-drawing characters. The following table shows code page 437.
Table 5: OEM Code Page 437
Suppose that you open a text file that contains the following:
Test: un élève s’en va à l’école sur son âne
With the MS-DOS Editor, it displays as follows:
Figure 1: ANSI Characters in MS-DOS Editor
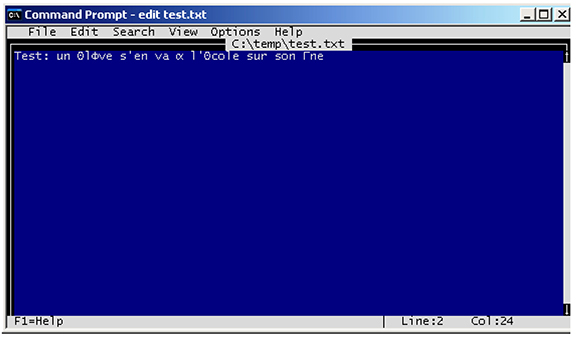
This is because the Windows ANSI characters are now displayed with their OEM counterparts. On the other hand, the same text entered via the MS-DOS Editor displays in Notepad as follows.
Figure 2: OEM Characters in Notepad
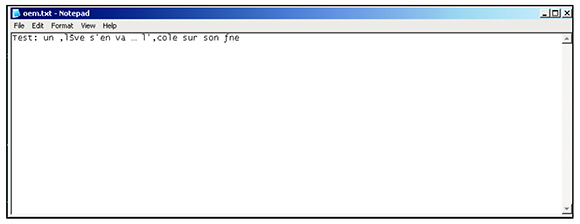
OEM Code Pages
Currently, OEM code pages are relevant only for console applications, and they could still be around in the non-extended filenames in the FAT12, FAT16, and FAT32 file systems.
The following table shows OEM code pages and their ANSI counterparts.
Table 6: OEM and ANSI Code Pages
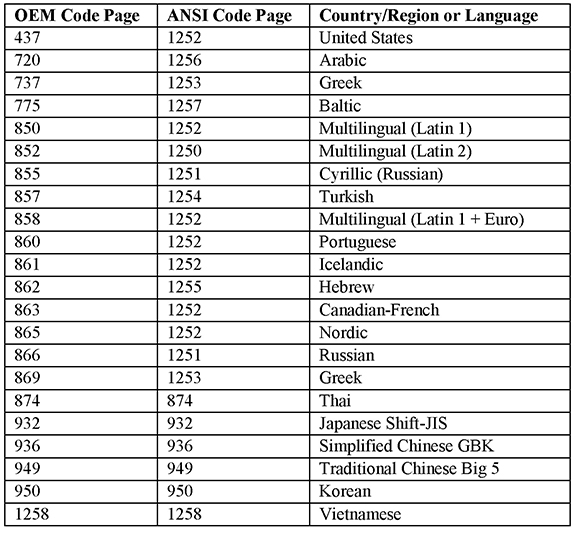
There are several single-byte OEM code pages corresponding to the same ANSI code page (1252), and there are two single-byte code pages (874 and 1258) and four multi-byte code pages (932, 936, 949, and 950) that are used as both OEM and ANSI code pages.
Other Vendor-specific Encodings
The Apple Macintosh initially used its own encoding, Mac OS Roman. It encoded almost the same characters as ISO 8859-1, but in a very different arrangement. It also added many technical and mathematical characters. Beginning with the release of Mac OS X, Mac OS Roman (as well as all other Mac OS encodings) was replaced by UTF-8 as the default encoding for the Macintosh operating system.
Roman8 is a character encoding that is mainly used on HP-UX and some Hewlett-Packard printers. As does Mac OS Roman, it uses almost the same character repertoire as ISO 8859-1 but again in very different code positions.
The DEC Multinational Character Set (MCS) was an encoding created by Digital Equipment Corporation to be used on the standard DEC VT220 terminals. It bore many similarities to ISO 8859-1; in fact, it was a precursor of ISO Latin-1 and Unicode.
EBCDIC
Extended Binary Coded Decimal Interchange Code (EBCDIC) was initially released by IBM with the IBM System/360 line of mainframe computers. It is a family of related encodings. Unlike most 8-bit encodings, it is not compatible with ASCII. Rather, characters are coded according to the historical needs of punch card machines. Each EBCDIC variation, known as a code page, is identified by a Coded Character Set Identifier, or CCSID. The characters in the basic set (a–z, A–Z, 0–9, and so on) are mapped to the same code points on all EBCDIC code pages (these are called invariant characters). The rest of the code points can be used for different national and special characters (these are called variant characters), depending on which country and language for which a code page was developed.
Here are some EBCDIC code pages:
- 838 (Thailand)
- 870 (Central Europe)
- 1025 (Russia)
- 1047 (United States)
- 1141 (Austria and Germany)
- 1142 (Denmark and Norway)
- 1143/1122 (Finland and Sweden)
- 1144 (Italy)
- 1145 (Spain)
- 1146 (United Kingdom)
- 1147 (France)
- 1148/1130 (International)
What Are Variant Characters?
The following characters are considered variant because they can have different code positions in various EBCDIC variations:
! # $ @ [ ] ^ `{ } | ~
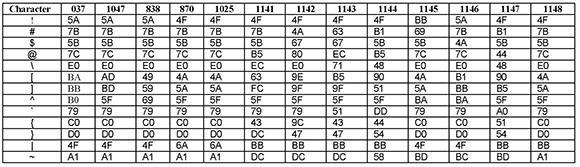
These characters exist in every encoding, but their hexadecimal values might change from one encoding to another, as shown in the following table.
Table 7: Variant Characters in EBCDIC
Although the designers of EBCDIC considered it to be “helpful in the long run if EBCDIC provided the same set of graphics as ASCII” and that “EBCDIC should not have graphics that were not in ASCII,”15 there are several major differences between ASCII and EBCDIC. In EBCDIC, lowercase characters precede uppercase characters and numbers. In ASCII, it is the other way round. Moreover, the EBCDIC code points that are used to map lowercase and uppercase characters are not contiguous (as they are in ASCII). There are three characters in U.S. EBCDIC that do not exist in ASCII:
- cent (“¢” 0x4a)
- not (“¬” 0x5f)
- split bar (“¦” 0x6a)
On the other hand, there were three characters in ASCII that did not exist in EBCDIC:
- left bracket (“[” 0x5b)
- right bracket (“]” 0x5d)
- circumflex (“^” 0x5e)
This made ASCII-to-EBCDIC conversions difficult.
The original EBCDIC specification did not have code points for the left bracket ([) and right bracket (]), and the circumflex (^).16a The brackets were later added to code page 1047 according to the TN/T11 print train17 code points of 0xad and 0xbd. The circumflex was put in the code point of the NOT sign (0x5f) while the NOT was moved to 0xb0. However, the code points of EBCDIC code page 03718 (also used in the U.S.) are different (0xba and 0xbb for the brackets and 0x5f for the NOT and 0xb0 for the circumflex).
In IBM mainframe computer languages (PL/I, REXX) ¬ represents “logical NOT.” In ASCII, the ASCII circumflex (^) is the “logical NOT.” The tilde (~) is recognized as a NOT symbol on all platforms. The U.S. EBCDIC split bar (¦) at 0x6a and the vertical bar (|) at 0x4f are homographs of the (7-bit) ASCII vertical bar (|) at 0x7c19. In SAS, the ASCII vertical bar is transcoded to U.S. EBCDIC as the vertical bar (code point 0x4f), and its interpretation as the OR operator is universal.20
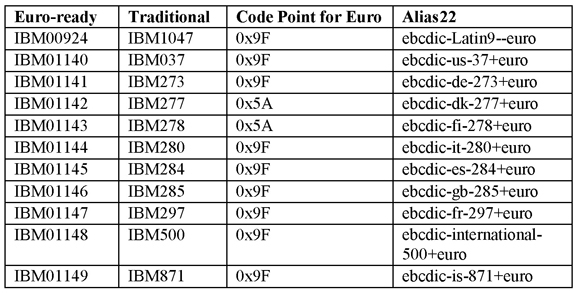
With the advent of the Euro, IBM created updates of several code pages. EBCDIC encodings that support the Euro symbol and those that do not usually differ by only one character.21 The following table shows the Euro-ready code pages along with the corresponding traditional code pages.
Table 8: New Code Pages with the Euro
Multi-octet Encoding Schemes
Not all languages in the world use alphabets (as we have seen previously) and most alphabets, as such, use a relatively small number of different characters. Logographic writing systems usually contain many thousands of characters. An encoding for such a system needs at least two octets (16 bits) per character, which permits a total of 216b = 65,536 characters. Because two octets or, for the sake of simplicity, two bytes are required to represent each character, these encodings are referred to as double-byte character sets (DBCS). Strictly speaking, this is not correct, not only because the term character set is used inappropriately—but more importantly because two bytes are not always used to encode one character. In fact, they are variable-width or multi-byte encodings. This is why they are called multi-byte character sets (MBCS).
There are two kinds of MBCS encodings: modal and non-modal.
- In a modal encoding, escape codes called Shift Out/Shift In (or SO/SI) surround double-byte characters, thus distinguishing them from the single-byte characters. Examples are IBM mainframe encodings such as IBM-939, and the family of ISO 2022 encodings.
- In non-modal encodings, single-byte and double-byte characters occupy different code ranges. In these encodings, the original ASCII characters usually keep their code positions. If a byte is in the range 0x81-0x9f or 0xe0-0xfc, it is usually the first byte of a double-byte character. Examples are Shift-JIS (SJIS) or EUC-JP.
The following diagram illustrates how a modal encoding works.
Figure 3: Modal Encoding

In the diagram that follows, the same text string as processed in a non-modal encoding.
Figure 4: Non-modal Encoding

National standard bodies have defined various coded character sets (so-called) for the Chinese, Japanese, and Korean (CJK) languages: JIS stands for Japanese Industrial Standard, KS for Korean Standard, GB for Guojia Biaozhun (“National Standard” in Chinese) (PRC), and CNS for Chinese National Standard (Taiwan).
The first Japanese encoding that became widely used was JIS C 6220 (later called JIS X 0201-1976). It is an 8-bit extension of the Japanese national variant of ISO-646 (also known as JIS-Roman), where the backslash () and tilde (~) have been replaced by yen (¥) and overline (‾). The second half consists of half-width katakana characters23 and a few ideographic punctuation marks. It does not encode hiragana or any kanji characters.
The first multi-byte encoding standard for Japanese was established by the Japanese Standards Association (JSA) in 1978 as JIS C 6226 (later renamed to JIS X 0208). Strictly speaking, JIS X 0208 is a character set standard and not a character encoding standard; therefore, there are several implementations of this standard. One implementation uses the ISO/IEC 2022 mechanisms. ISO 2022 defines a way to switch between multiple character sets by including escape codes (SO/SI) in the text (that is, special codes that indicate a switch between character sets). ISO-2022-JP recognizes a subset of these escape codes relevant to Japanese. Shift-JIS, mainly developed by Microsoft, is also based on JIS X 0208; but instead of using escape codes, it specifies different code ranges for single-byte and double-byte characters. If the numeric value of a character falls between 0x81-0x9F and 0xE0-0xEF, then it is treated as the first octet, and the next character is treated as the second octet of a double-byte character. EUC-JP (used by UNIX and UNIX-like operating systems) resembles Shift-JIS in its internal representation. That is, multi-byte sequences are marked by having the most significant bit set, which is in the range 0x80-0xFF, while the single-byte sequences are in the range 0x00-0x7F alone.
A supplemental Japanese character set standard was defined in 1990 as JIS X 0212. JIS X 0208 and JIS X 0212 include numbers, Latin, hiragana and katakana characters, kanji, as well as Cyrillic and Greek characters.
The Japanese standards triggered the development of national standards for China, Korea, and Taiwan. These standards share some of the characteristics of the JIS coded character sets. For example, they extend the local variant of ISO 646 that includes the local currency sign instead of the backslash. They are known as GB-Roman (from GB 1988-89), CNS-Roman (from CNS 5205-1989), and KS-Roman (from KS X 1003:1993).
The multi-byte encoding standards also include characters from other scripts (Cyrillic, Greek, Japanese syllabaries, and so on). The most current standard in the People’s Republic of China is GB 18030-2005. It was preceded by GB 2312-80. GB2312 has the following encoding forms: EUC-CN (default), HZ (HZ-GB-2312), and ISO-2022-CN.
The two major Taiwanese character set standards are Big Five and CNS 11643. Big Five (or Big5) is not a national standard but was developed by five of Taiwan’s largest IT companies; hence the name. Big5 has become the de facto standard and shares many qualities with CNS 11643. The most important characters of Big Five and CNS 11643 are included in Unicode.24 Traditional Chinese uses the following encoding methods: ISO-2022-CN, EUC-TW, and Big5. Microsoft created its own extension of Big5 as Code page 950. The authoritative standard for Korean is KS X 1001 (previously known as KS C 5601). It uses the following encoding methods: ISO-2022-KR, EUC-KR, and Johab.
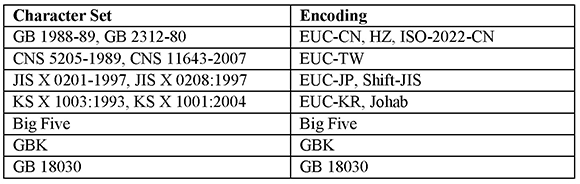
Just to re-emphasize: A coded character set (especially one for CJK languages) can be encoded in many different ways. Some character sets are supported by a single encoding, others by several encodings. The following table gives an overview.25
Table 9: CJK Character Sets and Encodings
Problems with Encodings
Coded character sets and encodings were now available for almost any language; however, the basic problems persisted:
- Each language or group of languages has several, often incompatible, encodings. Therefore, encodings can use different positions for the same character, or they can use the same code position for different characters.
- Any given computer and software needs to support many different encodings.
- One cannot easily mix languages in a document or system.
- Data transfer across platforms always runs the risk of data loss or corruption.
Unicode changed all that since “it provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language.”26
Unicode
After some preliminary work in the late 1980s, two committees—the Unicode Consortium (founded in 1991 by some major software companies) and a working group of the International Organization for Standardization (ISO)—have been jointly developing a truly universal (coded) character set: Unicode and ISO 10646.27 Both standards are compatible, and there is always a direct mapping from a particular version of one standard to a particular version of the other. For example, Unicode 5.028 has the same character repertoire as ISO/IEC 10646:2003.29
In Unicode, characters from almost all the world’s writing systems are assigned unique codes. The first 128 codes of Unicode are identical to 7-bit ASCII, and the first 256 codes are identical to ISO 8859-1. The most current version as of 2012 (Unicode 6.130) defines 110,116 character codes.31
Unicode codes can be logically divided into 17 planes (plane 0–16), each with a range of 65,536 (= 216c) code points, although currently only a few planes are used. The most commonly used characters have been placed in the first plane (0x0000 to 0xFFFD), which is called the Basic Multilingual Plane (BMP) or Plane 0.
The original Unicode standard provided for 65,536 characters. Since 16 bits were not enough, Unicode 2.0 added the surrogate mechanism (now known as UTF-16) to address more than 1,000,000 possible values. This means that pairs of Unicode values called surrogates are used to represent characters outside the BMP.
The Unicode standard follows 10 fundamental principles:32
- Universality: There is a single character repertoire for universal use.
- Efficiency: Text is simple to process and parse.
- Characters, not glyphs: The standard encodes characters, not glyphs.
- Semantics: Characters have well-defined properties.
- Plain text: Characters represent plain text without formatting.
- Logical order: The default for memory representation is logical order.
- Unification: The standard unifies duplicate characters within scripts across languages.
- Dynamic composition: Characters with diacritical marks can be dynamically composed.
- Equivalent sequences: Static pre-composed characters have an equivalent, dynamically composed sequence of characters.
- Convertibility: Accurate convertibility between the Unicode Standard and other widely accepted standards is guaranteed.
It should not be surprising that several compromises with reality had to be made, though. For example, Unicode decided to unify characters of Chinese origin (the so-called CJK Unified Ideographs) that are used in mainland China (written with the simplified Chinese script), in Taiwan (written with the traditional Chinese script), in Japan, and in Korea.33 On the other hand, it did not unify characters common to the Latin, Greek, and Cyrillic scripts. The Angstrom sign (U+212B) “Å” was encoded as a distinct character from the Latin capital letter A with ring above (U+00C5) because the two were distinguished in some source standard.
Both Unicode and ISO 10646 now define three encoding forms: UTF-8, UTF-16, and UTF-32. UTF-16 superseded the older UCS-2 (2-byte Universal Character Set) encoding, which has a fixed length and always encodes characters into a single 16-bit code unit.34 Depending on the encoding form, each character is represented either as a sequence of one to four octets, one or two 16-bit code units, or a single 32-bit code unit.
Table 10: Examples of Characters in Different Unicode Encodings
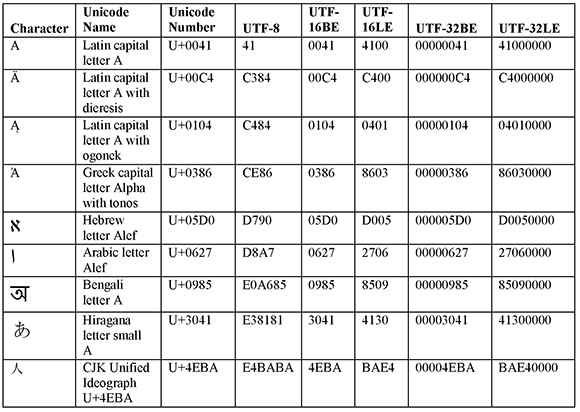
The previous table shows why it was important to make the distinction between a coded character set and a character encoding scheme. Unicode character number U+00C4, for example, can be encoded as 0xC384 in UTF-8, as 0x00C4 in big-endian UTF-16, as 0xC400 in little-endian UTF-16, as 0x000000C4 in big-endian UTF-32, and as 0xC4000000 in little-endian UTF-32.
Endianness depends on the processor. Big-endian machines (like most RISC processors) store multi-byte values with the most significant byte value first. On the little-endian systems (particularly Microsoft Windows platforms), multi-byte values are stored with the least significant byte value first. In order to denote whether a text uses big-endian or little-endian format, Unicode designated the character U+FEFF as the Byte-Order Mark (BOM): 35 U+FEFF means big-endianness and U+FFFE means little-endianness.
Transcoding
Transcoding is the process of converting character data from one encoding to another encoding. Transcoding is necessary when the encoding of data in the original location is different from the encoding of the data’s destination.
Take, for example, a file created under a UNIX operating environment that uses the ISO 8859-1 (Latin-1) encoding, which is then moved to an IBM mainframe that uses the 1147 (French) EBCDIC encoding. When the file is processed on the IBM mainframe, the data is remapped from the Latin-1 encoding to the French EBCDIC encoding. If the data contains a lowercase letter é, the hexadecimal number is converted from 0xE9 to 0xC0.
Transcoding should not be confused with translation. Transcoding does not translate between languages; transcoding changes the encoding of data—in other words, the internal representation of characters. Nevertheless, transcoding is sometimes referred to as character translation because data can be converted from one encoding to another by means of a simple matrix or translation table. Ideally, transcoding should be lossless and provide round-trip fidelity; this means all characters in one encoding can be mapped to the other encoding and back again.
Example 1: Here we are transcoding between a PC and a mainframe encoding. Both encodings (basically) share the same character repertoire, but the code positions are all different. Nevertheless, the transcoding is successful, and it works in both directions.

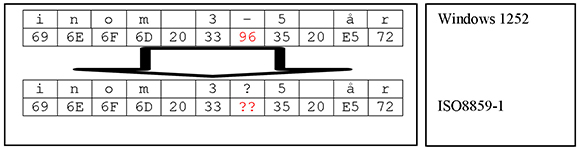
Example 2: Here we are transcoding between a Microsoft Windows PC and a UNIX encoding. Again, both encodings share the same character repertoire. The code positions of the characters are almost identical, but there are a few differences. Hence, transcoding is necessary, and is successful.
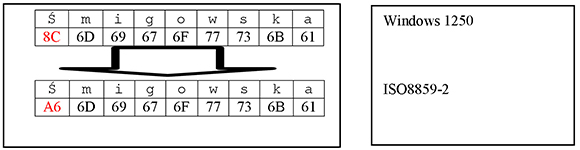
Example 3: In the following example, we are transcoding between a Microsoft Windows PC and a UNIX encoding. Again, both encodings (seem to) share the same character repertoire. And the code positions of the characters are almost identical or seem to be identical. Nevertheless, the transcoding fails. It is not easy to see why. However, the character in code position 0x96 is the EN DASH. This character that looks (almost) like the hyphen (0x2d) exists in Windows 1252 (Windows Latin-1), but it does not exist in ISO 8859-1 (ISO Latin-1). This is why the transcoding fails.
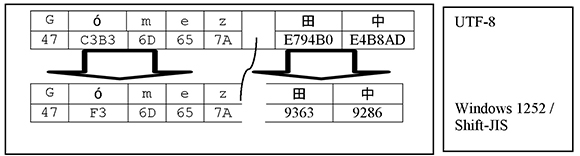
Example 4: Here we are transcoding between UTF-8 and Microsoft Windows Latin-1. The transcoding works for the characters of the Latin1 character repertoire but it does not work for the Japanese characters, of course, because they have no representation in Latin1.

So what we need to do is to transcode the Japanese and the Western values separately.
There are a couple of transcoding (conversion) tools out there. For example, probably the most well-known is iconv which is available on most UNIX systems. It is quite simple to use; basically you need to specify the source and target encodings. Here is an example:
iconv -f 1141 -t 1047 test1 > test2
This code converts the contents of file test1 from EBCDIC 1141 to EBCDIC 1047 and stores the output in file test2.
The names of the encodings are system dependent; you can list the names of the supported encodings with this command:
iconv -l
Needless to say, you can easily transcode data with SAS by a variety of means. I will explain this in detail in the next chapter.
Chapter Summary
Since the early days of computing, many different encodings have been developed.
ASCII, one of the first standards to emerge, is a 7-bit, 128-character code set that was adopted in the early 1960s by the American National Standards Institute (ANSI). It includes uppercase and lowercase letters A–Z, as well as digits, symbols, and control characters.
By using the eighth bit of an octet, 128 additional code positions became available. In the following years, a great number of new coded character sets were defined: the ISO 8859 standard; the Microsoft Windows code pages; EBCDIC (Extended Binary Coded Decimal Interchange Code), which was released by IBM with the System/360 line of mainframe computers; and many other vendor-specific encodings.
For CJK languages with their thousands of characters, two bytes are required to represent each character; these encodings are referred to as double-byte character sets (DBCS).
Coded character sets and encodings are available for almost any language. However, the basic problems persist: languages use several often incompatible encodings; software needs to support many different encodings; and data transfer across platforms always runs the risk of data loss or corruption.
The Unicode Consortium and a working group of the International Organization for Standardization have been jointly developing a truly universal (coded) character set. In Unicode, characters from almost all the world’s writing systems are assigned unique codes. Unicode defines three encoding forms: UTF-8, UTF-16, and UTF-32.
Transcoding is the process of converting character data from one encoding to another encoding. Transcoding is necessary when the encoding of data in the original location is different from the encoding of the data’s destination.
Ideally, transcoding should be lossless and provide round-trip fidelity; this means all characters in one encoding should be mapped to the other encoding and back again.
( Endnotes)
1 Anil K. Maini. 2007. Digital Electronics: Principles, Devices and Applications, Hoboken, NJ: John Wiley & Sons Inc., p. 4.
2 Clews, 1988, p. 4.
3 This is a somewhat simplified explanation. The Unicode Character Encoding Model defines four levels: Abstract Character Repertoire (ACR), Coded Character Set (CCS), Character Encoding Form (CEF), and Character Encoding Scheme (CES). A CEF maps the code points in a CCS to sequences of code units. These are octets (eight-, sixteen-, and thirty-two-bit values) that are either all of the same length (fixed width) or of different lengths (variable width). A CES maps each code unit of a CEF into a unique serialized byte sequence in order. There are two possibilities for the order: little-5ndian, meaning the least significant byte comes first; and big-endian, meaning the most significant byte comes first. See “Unicode Technical Report #17” at http://unicode.org/reports/tr17/.
4 See “IBM Code Pages” at http://www-03.ibm.com/systems/i/software/globalization/codepages.html.
5 See “Code Pages Supported by Windows” at http://msdn.microsoft.com/en-us/goglobal/bb964654.aspx.
6 See “IANA Charset Registry” at http://www.iana.org/assignments/character-sets.
7 EUC, Extended UNIX Code, is a multi-byte encoding used primarily for Japanese, Korean, and Chinese.
8 ASCII actually uses octets of 8 bits per character, but it leaves the first (the most significant) bit in each octet unused (it must be always zero).
9 Variant characters are comprehensively discussed in “TS-758: Ensuring Compatibility of Encoding across Different Releases of the SAS System in the z/OS Environment,” which can be found at http://support.sas.com/techsup/technote/ts758.pdf.
10 Hart, 1989, p. 24.
11 Storing Arabic or Hebrew text in visual order means the text is stored in memory in the same order you would expect to see it displayed. Logical ordering means the text is stored in memory in the order in which it would normally be typed, and the software makes sure it is rendered in the correct visual display.
12 BiDi (bidirectional) text is a mixture of Arabic or Hebrew text with Latin text or numbers. Arabic and Hebrew strings of text are read from right to left, but numbers and embedded Latin text strings are read from left to right. BiDi processing means the ability of the software to display bidirectional text correctly.
13 See Code Pages at http://msdn.microsoft.com/en-us/library/dd317752%28VS.85%29.aspx.
14 See Code Pages at http://msdn.microsoft.com/en-us/library/dd317752%28VS.85%29.aspx.
15 Mackenzie (1980) p. 152.
16a Cf. Mackenzie (1980) p. 154: Figure 9.2 shows the final assignment of specials into EBCDIC in 1970.
16b Cf. Mackenzie (1980) p. 154: Figure 9.2 shows the final assignment of specials into EBCDIC in 1970.
16c Cf. Mackenzie (1980) p. 154: Figure 9.2 shows the final assignment of specials into EBCDIC in 1970.
17 Line printers from the 1970s had print chains. Before laser printers, this is what people used on the IBM mainframes. The TN/T11 print train provided uppercase and lowercase Latin characters, including the brackets. Moreover, the codes for the print train were on the green IBM/360 and yellow IBM/370 System Reference Summary cards and later booklets (GX20-1850). Thus, people knew about using printers with the TN/T11 print train. (Communicated by Edwin Hart via e-mail on September 17, 2010.) Mackenzie (1980) has a schematic illustration of a chain/train printer on p. 168.
18 The characters defined in EBCDIC code page 037 make up the standard assembler language character set. See International Business Machines Corporation. 2008. High Level Assembler for z/OS & z/ampVM & z/VSE Language Reference Release 6, Sixth Edition (July 2008), SC26-4940-05.
19 Hart, 1989, p. 9.
20 Robert A. Cruz. 2009. “Portable SAS: Language and Platform Considerations.” Proceedings of the Western Users of SAS Software (WUSS) Conference. Available at http://www.wuss.org/proceedings09/09WUSSProceedings/papers/app/APP-Cruz.pdf, p.10.
21 Code page 924 is an exception. It had eight characters that have been replaced, and three characters that have been moved from their code points in code page 1047.
22 From IANA Charset Registry.
23 Half-width means that the characters are compressed and visually occupy a space half that of normal Japanese characters. There used to be a clear relationship between the display width and the number of bytes used to encode the character; i.e., half-width characters used to be encoded in one byte. This is no longer true. Cf. Lunde, 2009, p. 26.
24 Lunde, 2009, p. 124.
25 Adapted from Lunde, 2009, p. 275f.
26 See “What is Unicode?” at http://unicode.org/standard/WhatIsUnicode.html.
27 The connection between the names ISO 646 and ISO 10646 is not coincidental because ISO 10646 is an extension of ISO 646.
28 SAS 9.3 supports Unicode 5.0.
29 See “Unicode and ISO 10646” at http://unicode.org/faq/unicode_iso.html.
30 Version 6.0 was the first major version of the Unicode Standard to be published solely in online format.
31 The Unicode Consortium. The Unicode Standard, Version 6.1.0, Mountain View, CA: The Unicode Consortium, 2012, http://www.unicode.org/versions/Unicode6.1.0/
32 See “The Unicode Standard: A Technical Introduction” at http://unicode.org/faq/unicode_iso.html.
33 There has been a lot of controversy about this Han unification. See “The Secret Life of Unicode” at http://www.ibm.com/developerworks/library/u-secret.html. The basic CJK Unified Ideographs block, also known as the Unified Repertoire and Ordering (URO) contains 20,902 characters. The Unicode designers followed several rules to determine which characters could be unified. In particular, characters were not unified when they looked similar but had different meanings and etymologies. They also were not unified if they used the same components but arranged them differently, and so on. Altogether, Unicode 6.0 provides for 74,616 CJK characters.
34 Cf. “What is the difference between UCS-2 and UTF-16?” See http://www.unicode.org/faq/basic_q.html#14.
35 See “Byte Order Mark (BOM) FAQ” at http://unicode.org/faq/utf_bom.html#BOM