
Chapter 5: Controlling Network Communications
The SELinux mandatory access controls go much beyond its file and process access controls. One of the features provided by SELinux is its ability to control network communications. By default, general network access controls use the socket-based access control mechanism, but more detailed approaches are also possible.
In this chapter, we will learn how network access controls are governed by SELinux, cover what administrators can do to further strengthen network communications using iptables, and describe how SELinux policies can be used for cross-system security through labeled IPsec. We'll finish the chapter with an introduction to CIPSO labeling and its integration with SELinux.
We cover the following topics in this chapter:
- Controlling process communications
- Linux firewalling and SECMARK support
- Securing high-speed InfiniBand networks
- Understanding labeled networking
- Using labeled IPsec with SELinux
- Supporting CIPSO with NetLabel and SELinux
Technical requirements
Not all sections in this chapter apply to all environments. For InfiniBand support, for instance, InfiniBand hardware is needed, whereas for NetLabel/CIPSO support, the network in its entirety needs to support the CIPSO (or CALIPSO in the case of IPv6) protocol for the hosts to be able to communicate with each other.
Check out the following video to see the Code in Action: https://bit.ly/34bVDdm
Controlling process communications
Linux applications communicate with each other either directly or over a network. But the difference between direct communication and networked communication, from an application programmer's point of view, is not always that big. Let's look at the various communication methods that Linux supports and how SELinux aligns with them.
Using shared memory
The least network-like method is the use of shared memory. Applications can share certain parts of the memory with each other and use those shared segments to communicate between two (or more) processes. To govern access to the shared memory, application programmers can use mutual exclusions (mutexes) or semaphores. A semaphore is an atomically incremented or decremented integer (ensuring that two applications do not overwrite each other's values without knowing about the value change), whereas a mutex can be interpreted as a special semaphore that only takes the values 0 or 1.
On Linux, two implementations exist for shared memory access and control: SysV-style and POSIX-style. We will not dwell on the advantages and disadvantages of each, but rather look at how SELinux governs access to these implementations.
SELinux controls the SysV-style primitives through specific classes: sem for semaphores and shm for shared memory. The semaphores, mutexes, and shared memory segments inherit the context of the first process that creates them.
Administrators who want to control the SysV-style primitives can use the various ipc* commands: ipcs (to list), ipcrm (to remove), and ipcmk (to create).
For instance, let's first list the resources and then remove the listed shared memory:
# ipcs
...
------ Shared Memory Segments ------
key shmid owner perms bytes nattch status
0x0052e2c1 0 postgres 600 56 6
# ipcrm -m 0
When POSIX-style semaphores, mutexes, and shared memory segments are used, SELinux controls those operations through the file-based access controls. The POSIX-style approach uses regular files in /dev/shm, which is simpler for administrators to control and manage.
Communicating locally through pipes
A second large family of communication methods in operating systems is the use of pipes. As the name implies, pipes are generally one-way communication tunnels, with information flowing from one (or more) senders to one receiver (there are exceptions to this, such as Solaris pipes, which act as bidirectional channels, but those are not supported on Linux). Another name for a pipe is first-in, first-out (FIFO).
We have two types of pipes in Linux: anonymous pipes (also known as unnamed pipes) and named pipes. The difference is that a named pipe uses a file in the regular filesystem as its identification, whereas anonymous pipes are constructed through the applications with no representation in the regular filesystem.
In both cases, SELinux will see the pipes as files of the fifo_file class. Named pipes will have their path associated with the regular filesystem and are created using the mknod or mkfifo commands (or through the mkfifo() function when handled within applications). Anonymous pipes, however, will be shown as part of the pipefs filesystem. This is a pseudo filesystem, not accessible to users, but still represented as a filesystem through Linux's virtual file system (VFS) abstraction.
From an SELinux policy point of view, the FIFO file is the target for which the access controls apply: two domains that both have the correct set of privileges toward the context of the FIFO file will be able to communicate with each other.
Administrators can find out which process is communicating over FIFOs with other processes through tools such as lsof, or by querying the /proc filesystem (as part of the /proc/<pid>/fd listings). The lsof tool supports the -Z option to show the SELinux context of the process, and even supports wildcards:
# lsof -Z *:postfix_*
In this example, lsof displays information about all processes that use a postfix_* label.
Conversing over UNIX domain sockets
With pipes supporting one-way communication only, any conversation between two processes would require two pipes. Also, true client/server-like communication with pipes is challenging to implement. To accomplish the more advanced communication flows, processes will use sockets.
Most administrators are aware that TCP and UDP communication occurs over sockets. Applications can bind to a socket and listen for incoming communications or use the socket to connect to other, remote services. But even on a single Linux system, sockets can be used to facilitate the communication flows. There are two socket types that can be used for process communication: UNIX domain sockets and netlink sockets. Netlink sockets are specific to the Linux operating system and are quite low-level, resembling the ioctl() system call usage. UNIX domain sockets, on the other hand, are higher-level and more directly accessible by administrators, which is why we explain them here in more detail.
We can distinguish between two UNIX domain socket definitions, as with pipes: unnamed sockets and named sockets. And like pipes, the distinction is in the path used to identify a socket. Named sockets are created on the regular filesystem, while unnamed sockets are part of the sockfs pseudo filesystem. Similarly, sockets can be queried through utilities such as lsof or through the /proc/<pid>/fd listings.
There is another distinction regarding UNIX domain sockets though, namely, the communication format that the UNIX domain socket allows. UNIX domain sockets can be created as datagram sockets (data sent to the socket retains its chunk size and format) or streaming sockets (data sent to the socket can be read in different-sized chunks). This has some repercussions for the SELinux policy rules.
For SELinux, communicating over UNIX domain sockets requires both domains to have the proper communication privileges toward the socket file type (open, read, and write), depending on the direction of the communication.
Additionally, the sending (client) domain requires additional privileges toward the receiving (server) domain:
- The connectto privilege in the unix_stream_socket class in the case of stream sockets
- The sendto privilege in the unix_dgram_socket class in the case of datagram sockets
As you can see, the privileges depend on the communication type used across the socket.
Understanding netlink sockets
Another socket type that can be used for process communication is netlink. Netlink sockets are sockets that allow user space applications to communicate and interact with kernel processes, and, in special cases (where network management is delegated to a user space process by the Linux kernel), also communicate with another user space application. Unlike the regular UNIX domain sockets, whose target context associates with the owner of that socket, netlink sockets are always local to the SELinux context.
Put differently, when a domain such as sysadm_t wants to manipulate the kernel's routing information, it will open and communicate with the kernel through a netlink route socket, identified through the netlink_route_socket class:
$ sesearch -s sysadm_t -t sysadm_t -c netlink_route_socket -A
allow sysadm_t domain:netlink_route_socket getattr;
allow sysadm_t sysadm_t:netlink_route_socket { append bind ... };
As applications gain more features, it might be that some of these features are no longer allowed by the current SELinux policy. Administrators will then need to update the SELinux policy to allow the netlink communication.
An overview of supported netlink sockets can be devised from the netlink information on the manual page (man netlink), from which the SELinux classes can easily be derived. For instance, the NETLINK_XFRM socket is supported through the SELinux netlink_xfrm_socket class.
Dealing with TCP, UDP, and SCTP sockets
When we go further up the chain, we look at socket communication over the network. In this case, rather than communicating directly between processes (and thus in Linux terminology between SELinux domains), the flows are from, and to, TCP, UDP, and Stream Control Transmission Protocol (SCTP) sockets.
SELinux will assign types to these ports as well, and these types are then the types to use for socket communication. For SELinux, a client application connecting to the DNS port (TCP port 53, which receives the dns_port_t type in most SELinux policies) uses the name_connect permission within the tcp_socket class toward the port type. The SCTP protocol (with the sctp_socket class) uses the same permission. For UDP services (and thus the udp_socket class), name_connect is not used. Daemon applications use the name_bind privileges to bind themselves to their associated port.
Important note
Support for SCTP has only been recently introduced in SELinux, and not all Linux distributions have updated their policies accordingly. To see whether SCTP support is active, check the value of the /sys/fs/selinux/policy_capabilities/extended_socket_class file. A value of 1 means that the policy has SCTP support included, whereas a value of 0 (or an absent file) means that the system does not yet support SCTP.
Administrators can fine-tune which label to assign to which TCP, UDP, or SCTP port. For this, the semanage port command can be used. For instance, to list the current port definitions, you'd use this command:
# semanage port -l
SELinux Port Type Proto Port Number
afs3_callback_port_t tcp 7001
...
http_port_t tcp 80, 81, 443, 488, 8008, 8009, ...
In this example, we see that the http_port_t label is assigned to a set of TCP ports. Web server domains that can bind to http_port_t are, as such, allowed to bind to any of the mentioned ports.
To allow a daemon, such as an SSH server, to bind to other (or additional) ports, we need to tell SELinux to map this port to the appropriate label. For instance, to allow the SSH server to bind to port 10122, we first check whether this port already holds a dedicated label. This can be accomplished using the sepolicy command:
$ sepolicy network -p 10122
10122: udp unreserved_port_t 1024-32767
10122: tcp unreserved_port_t 1024-32767
10122: sctp unreserved_port_t 1024-32767
The unreserved_port_t label is not a dedicated one, so we can assign the ssh_port_t label to it:
# semanage port -a -t ssh_port_t -p tcp 10122
Removing a port definition works similarly:
# semanage port -d -t ssh_port_t -p tcp 10122
When a specific port type is already assigned, then the utility will give the following error:
# semanage port -a -t ssh_port_t -p tcp 80
ValueError: Port tcp/80 already defined
If this is the case and another port cannot be used, then no option exists other than to modify the SELinux policy.
Listing connection contexts
Many of the tools in an administrator's arsenal can display security context information. As with the core utilities, most of these tools use the -Z option for this. For instance, to list the running network-bound services, netstat can be used:
# netstat -naptZ | grep ':80'
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 17655/nginx: master system_u:system_r:httpd_t:s0
Even lsof displays the context when asked to:
# lsof -i :80 -Z
COMMAND PID SECURITY-CONTEXT USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 17655 system_u:system_r:httpd_t:s0 root 8u IPv4 31230 0t0 *:http (LISTEN)
Another advanced command for querying connections is the ss command. Just calling ss will display all the connections of the current system. When adding -Z, it adds the context information as well.
For instance, the following command queries for listening TCP services:
# ss -ltnZ
More advanced queries can be called as well — consult the ss manual page for more information.
Note
The use of the -Z option to show SELinux context information or consider SELinux context information in the activity that is requested by the user is a general but not mandatory practice amongst application developers. It is recommended to check the manual page of the application to confirm whether, and how, SELinux is supported by a tool. For instance, to get the ss manual page, run man ss.
All these interactions are still quite primitive in nature, with the last set (which focuses on sockets) being more network-related than the others. Once we look into interaction between systems, we might not have enough control through just the sockets though. To enable more fine-grained control, we'll look at firewall capabilities and their SECMARK support next.
Linux firewalling and SECMARK support
The approach with TCP, UDP, and SCTP ports has a few downsides. One of them is that SELinux has no knowledge of the target host, so cannot reason about its security properties. This method also offers no way of limiting daemons from binding on any interface: in a multi-homed situation, we might want to make sure that a daemon only binds on the interface facing the internal network and not the internet-facing one, or vice versa.
In the past, SELinux allowed support for this binding issue through the interface and node labels: a domain could be configured to only bind to one interface and not to any other, or even on a specific address (referred to as the node). This support had its flaws though, and has been largely deprecated in favor of SECMARK filtering.
Before explaining SECMARK and how administrators can control it, let's first take a quick look at Linux's netfilter subsystem, the de facto standard for local firewall capabilities on Linux systems.
Introducing netfilter
Like LSM, the Linux netfilter subsystem provides hooks in various stages of its networking stack processing framework, which can then be implemented by one or more modules. For instance, ip_tables (which uses the iptables command as its control application) is one of those modules, while ip6_tables and ebtables are other examples of netfilter modules. Modules implementing a netfilter hook must inform the netfilter framework of that hook's priority. This enables controllable ordering in the execution of modules (as multiple calls for the same hook can and will be used together).
The ip_tables framework is the one we will be looking at in more detail because it supports the SECMARK approach. This framework is commonly referred to as just iptables, which is the name of its control application. We will be using this term for the remainder of this book.
iptables offers several tables, functionally-oriented classifications for network processing. The common ones are as follows:
- The filter table enables the standard network-filtering capabilities.
- The nat table is intended to modify routing-related information from packets, such as the source and/or destination address.
- The mangle table is used to modify most of a packet's fields.
- The raw table is enabled when administrators want to opt out certain packets/flows from the connection-tracking capabilities of netfilter.
- The security table is offered to allow administrators to label packets once regular processing is complete.
Within each table, iptables offers a default set of chains. These default chains specify where in the processing flow (and thus which hook in the netfilter framework) rules are to be processed. Each chain has a default policy – the default return value if none of the rules in a chain match. Within the chain, administrators can add several rules to process sequentially. When a rule matches, the configured action applies. This action can be to allow the packet to flow through this hook in the netfilter framework, be denied, or perform additional processing.
Commonly provided chains (not all chains are offered for all tables) include the following:
- The PREROUTING chain, which is the first packet-processing step once a packet is received
- The INPUT chain, which is for processing packets meant for the local system
- The FORWARD chain, which is for processing packets meant to be forwarded to another remote system
- The OUTPUT chain, which is for processing packets originating from the local system
- The POSTROUTING chain, which is the last packet-processing step before a packet is sent
Overly simplified, the implementation of these tables and their chains roughly associates with the priority of the calls within the netfilter framework. The chains are easily associated with the hooks provided by the netfilter framework, whereas the table tells netfilter which chain implementations are to be executed first.
Implementing security markings
With packet labeling, we can use the filtering capabilities of iptables (and ip6tables) to assign labels to packets and connections. The idea is that the local firewall tags packets and connections and then the kernel uses SELinux to grant (or deny) application domains the right to use those tagged packets and connections.
This packet labeling is known as SECurity MARKings (SECMARK). Although we use the term SECMARK, the framework consists of two markings: one for packets (SECMARK) and one for connections, that is, CONNection MARKings (CONNMARK). The SECMARK capabilities are offered through two tables, mangle and security. Only these tables currently have the action of tagging packets and connections available in their rule set:
- The mangle table has a higher execution priority than most other tables. Implementing SECMARK rules on this level is generally done when all packets need to be labeled, even when many of these packets will eventually be dropped.
- The security table is next in execution priority after the filter table. This allows the regular firewall rules to be executed first, and only tag those packets allowed by the regular firewall. Using the security table allows the filter table to implement the discretionary access control rules first and have SELinux execute its mandatory access control logic only if the DAC rules are executed successfully.
Once a SECMARK action triggers, it will assign a packet type to the packet or communication. SELinux policy rules will then validate whether a domain is allowed to receive (recv) or send packets of a given type. For instance, the Firefox application (running in the mozilla_t domain) will be allowed to send and receive HTTP client packets:
allow mozilla_t http_client_packet_t : packet { send recv };
Another supported permission set for SECMARK-related packets is forward_in and forward_out. These permissions are checked when using forwarding in netfilter.
One important thing to be aware of is that once a SECMARK action is defined, then all the packets that eventually reach the operating system's applications will have a label associated with them — even if no SECMARK rule exists for the packet or connection that the kernel is inspecting. If that occurs, then the kernel applies the default unlabeled_t label. The default SELinux policy implemented in some distributions (such as CentOS) allows all domains to send and receive unlabeled_t packets, but this is not true for all Linux distributions.
Assigning labels to packets
When no SECMARK-related rules are loaded in the netfilter subsystem, then SECMARK is not enabled and none of the SELinux rules related to SECMARK permissions are checked. The network packets are not labeled, so no enforcement can be applied to them. Of course, the regular socket-related access controls still apply — SECMARK is just an additional control measure.
Once a single SECMARK rule is active, SELinux starts enforcing the packet-label mechanism on all packets. This means that all the network packets now need a label on them (as SELinux can only deal with labeled resources). The default label (the initial security context) for packets is unlabeled_t, which means that no marking rule matches this network packet.
Because SECMARK rules are now enforced, SELinux checks all domains that interact with network packets to see whether they are authorized to send or receive these packets. To simplify management, some distributions enable send and receive rights against the unlabeled_t packets for all domains. Without these rules, all network services would stop functioning properly the moment a single SECMARK rule becomes active.
To assign a label to a packet, we need to define a set of rules that match a particular network flow, and then call the SECMARK logic (to tag the packet or communication with a label). Most rules will immediately match the ACCEPT target as well, to allow this particular communication to reach the system.
- The first is to allow communication toward websites (port 80) and tag the related network packets with the http_client_packet_t type (so that web browsers are allowed to send and receive these packets).
- The second is to allow communication toward the locally running web server (port 80 as well) and tag its related network packets with the http_server_packet_t type (so that web servers are allowed to send and receive these packets).
For each rule set, we also enable connection tracking so that related packets are automatically labeled correctly and passed.
Use the following commands for the web server traffic:
# iptables -t filter -A INPUT -m conntrack --ctstate
ESTABLISHED,RELATED -j ACCEPT
# iptables -t filter -A INPUT -p tcp -d 192.168.100.15 --dport
80 -j ACCEPT
# iptables -t security -A INPUT -p tcp --dport 80 -j SECMARK
--selctx "system_u:object_r:http_server_packet_t:s0"
# iptables -t security -A INPUT -p tcp --dport 80 -j
CONNSECMARK --save
Use these commands for the browser traffic:
# iptables -t filter -A OUTPUT -m conntrack --ctstate
ESTABLISHED -j ACCEPT
# iptables -t filter -A OUTPUT -p tcp --dport 80 -j ACCEPT
# iptables -t security -A OUTPUT -p tcp --dport 80 -j SECMARK
--selctx "system_u:object_r:http_client_packet_t:s0"
# iptables -t security -A OUTPUT -p tcp --dport 80 -j
CONNSECMARK --save
Finally, to copy connection labels to the established and related packets, use the following commands:
# iptables -t security -A INPUT -m state --state
ESTABLISHED,RELATED -j CONNSECMARK --restore
# iptables -t security -A OUTPUT -m state --state
ESTABLISHED,RELATED -j CONNSECMARK --restore
Even this simple example shows that firewall rule definitions are an art by themselves, and that the SECMARK labeling is just a small part of it. However, using the SECMARK rules makes it possible to allow certain traffic while still ensuring that only well-defined domains can interact with that traffic. For instance, it can be implemented on kiosk systems to only allow one browser to communicate with the internet while all other browsers and commands aren't. Tag all browsing-related traffic with a specific label, and only allow that browser domain the send and recv permissions on that label.
Transitioning to nftables
While iptables is still one of the most widely used firewall technologies on Linux, two other contenders (nftables and bpfilter) are rising rapidly in terms of popularity. The first of these, nftables, has a few operational benefits over iptables, while retaining focus on the netfilter support in the Linux kernel:
- The code base for nftables and its Linux kernel support is much more streamlined.
- Error reporting is much better.
- Filtering rules can be incrementally changed rather than requiring a full reload of all rules.
The nftables framework has recently received support for SECMARK, so let's see how to apply the http_server_packet_t and http_client_packet_t labels to the appropriate traffic.
The most common approach for applying somewhat larger nftables rules is to use a configuration file with the nft interpreter set:
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
secmark http_server {
"system_u:object_r:http_server_packet_t:s0"
}
secmark http_client {
"system_u:object_r:http_client_packet_t:s0"
}
map secmapping_in {
type inet_service : secmark
elements = { 80 : "http_server" }
}
map secmapping_out {
type inet_service : secmark
elements = { 80 : "http_client" }
}
chain input {
type filter hook input priority 0;
ct state new meta secmark set tcp dport map @secmapping_in
ct state new ct secmark set meta secmark
ct state established,related meta secmark set ct secmark
}
chain output {
type filter hook output priority 0;
ct state new meta secmark set tcp dport map @secmapping_out
ct state new ct secmark set meta secmark
ct state established,related meta secmark set ct secmark
}
}
The syntax that nftables uses is recognizable when we compare it with iptables. The script starts with defining the SECMARK values. After that, we create a mapping between a port (80 in the example) and the value used for the SECMARK support. Of course, already established sessions also receive the appropriate SECMARK labeling.
If we define multiple entries, the elements variable uses commas to separate the various values:
elements = { 53 : "dns_client" , 80 : "http_client" , 443 : "http_client" }
Next to nftables. A second firewall solution that is gaining traction is eBPF, which we cover next.
Assessing eBPF
eBPF (and the bpfilter command) is completely different in nature compared to iptables and nftables, so let's first see how eBPF functions before we cover the SELinux support details for it.
Understanding how eBPF works
The extended Berkeley Packet Filter (eBPF) is a framework that uses an in-kernel virtual machine that interprets and executes eBPF code, rather low-level instructions comparable to processor instruction set operations. Because of its very low-level, yet processor-agnostic language, it can be used to create very fast, highly optimized rules.
BPF was originally used for analyzing and filtering network traffic (for example, within tcpdump). Because of its high efficiency, it was soon found in other tools as well, growing beyond the plain network filtering and analysis capabilities. As BPF expanded toward other use cases, it became extended BPF, or eBPF.
The eBPF framework in the Linux kernel has been successfully used for performance monitoring, where eBPF applications hook into runtime processes and kernel subsystems to measure performance and feed back the metrics to user-space applications. It, of course, also supports filtering on (network) sockets, cgroups, process scheduling, and many more — and the list is growing rapidly.
As with the LSM framework, which uses hooks into the system calls and other security-sensitive operations in the Linux kernel, eBPF hooks into the Linux kernel as well. Occasionally it can use existing hooks (as with the Linux kernel probes or kprobes framework) and thus benefit from the stability of these interfaces. We can thus expect eBPF to grow its support further in other areas of the Linux kernel as well.
eBPF applications (eBPF programs) are defined in user space, and then submitted to the Linux kernel. The kernel verifies the security and consistency of the code to ensure that the virtual machine will not attempt to break out of the boundaries it works in. If approved (possibly after the code is slightly altered, as the Linux kernel has some operations that modify eBPF code to suit the environment or security rules), the eBPF program runs in the Linux kernel (within its virtual machine) and executes its purpose.
Note
The Linux kernel can compile the eBPF instructions into native, processor-specific instructions, rather than having the virtual machine interpret them. However, as this leads to a higher security risk, this Just-In-Time (JIT) eBPF support is sometimes disabled by Linux distributions in their Linux kernels. It can be enabled by setting /proc/sys/net/core/bpf_jit_enable to 1.
These programs can load and save information in memory, called maps. These eBPF maps can be read or written to by user-space applications, and thus offer the main interface to interact with running eBPF programs. These maps are accessed through file descriptors, allowing processes to pass along and clone these file descriptors as needed.
Various products and projects are using eBPF to create high-performance network capabilities, such as software-defined network configurations, DDoS mitigation rules, load balancers, and more. Unlike the netfilter-based firewalls, which rely on a massive code base within the kernel tuned through configuration, eBPF programs are built specifically for their purpose and nothing more, and only that code is actively running.
Securing eBPF programs and maps
The default security measures in place for eBPF programs and maps are very limited, partly because lots of trust is put in the Linux kernel verifier (which verifies the eBPF code before it passes the code on to the virtual machine), and partly because the eBPF code was only allowed to be loaded when the process involved has the CAP_SYS_ADMIN capability. And as this capability basically means full system access, additional security controls were not deemed necessary.
Since Linux kernel 4.4, some types of eBPF programs (such as socket filtering) can be loaded even by unprivileged processes (but, of course, only toward the sockets these processes have access to). The system allows loading programs to work on cgroups socket buffers (skb) if the process has the CAP_NET_ADMIN capability. Recently, the permission to load eBPF programs has been added to the CAP_BPF and CAP_TRACING capabilities, although not all Linux distributions offer a Linux kernel that supports these capabilities already. But Linux administrators that want more fine-grained control over eBPF can use SELinux to tune and tweak eBPF handling.
SELinux has a bpf class, which governs the basic eBPF operations: prog_load, prog_run, map_create, map_read, and map_write. Whenever a process creates a program or map, this program or map inherits the SELinux label of this process. If the file descriptors regarding these maps or programs are leaked, the malicious application still requires the necessary privileges toward this label before it can exploit it.
User-space operations can interact with the eBPF framework through the /sys/fs/bpf virtual filesystem, so some Linux distributions associate a specific SELinux label (bpf_t) with this location as well. This allows administrators to manage access through SELinux policy rules in relation to this type.
While eBPF is extremely extensible, the number of simplified frameworks surrounding it is small given its very early phase. We can, however, expect that more elaborate support will come soon, as a new tool called bpfilter is showing off the capabilities of eBPF-based firewalling on Linux systems.
Filtering traffic with bpfilter
The bpfilter application is an application that builds a new eBPF program to filter and process traffic. It allows administrators to build firewall capabilities without understanding the low-level eBPF instructions, and has recently started supporting iptables: administrators create rules with iptables, and bpfilter translates and converts these into eBPF programs.
Important note
While bpfilter is part of the Linux kernel tree, it should be considered a proof-of-value currently, rather than a production-ready firewall capability.
bpfilter creates eBPF programs that hook inside the Linux kernel between the network device driver and the TCP/IP stack in a layer called the eXpress Data Path (XDP). At this level, the eBPF programs have access to the full network packet information (including link layer protocols such as Ethernet).
To use bpfilter, the Linux kernel needs to be built with the appropriate settings, including CONFIG_BPFILTER and CONFIG_BPFILTER_UMH. The latter is the bpfilter user mode helper that will capture iptables-generated firewall rules, and translate those into eBPF applications.
Before we load the bpfilter user mode helper, we need to allow execmem permission in SELinux:
# setsebool allow_execmem on
Next, load the bpfilter module, which will have the user mode helper active on the system:
# modprobe bpfilter
# dmesg | tail
...
bpfilter: Loaded bpfilter_umh pid 2109
Now, load the iptables firewall using the commands listed previously. The instructions are translated into eBPF programs, as shown with bpftool:
# bpftool p
1: xdp tag 8ec94a061de28c09 dev ens3
loaded_at Apr 25/23:19 uid:0
xlated 533B jited 943B memlock 4096B
The eBPF code itself can be displayed as well, but is hardly readable at this point for administrators.
All of the aforementioned firewall capabilities interact with the TCP/IP stack supported within the Linux kernel. There are, however, networks that do not rely on TCP/IP, such as InfiniBand. Luckily, even on those more specialized network environments, SELinux can be used to control communication flows.
Securing high-speed InfiniBand networks
The InfiniBand standard is a relatively recent (in network history) technology that enables very high throughput and very low latency. It accomplishes this by having a very low overhead on the network layer (protocol) and direct access from user applications to the network level. This direct access also has implications for SELinux, as the Linux kernel is no longer actively involved in the transport of data across an InfiniBand link.
Let's first look at what InfiniBand looks like, after which we can see how to still apply SELinux controls to its communication flows.
Directly accessing memory
One of the main premises of InfiniBand is to allow user applications to have direct access to the network. By itself, InfiniBand is a popular Remote Direct Memory Access (RDMA) implementation, which has received significant support from vendors. We find RDMA actively used in high-performance clusters.
Because of the direct access, controls are only possible while setting up the access approach. Without SELinux, all that is needed to set up and manage InfiniBand communications is to have access to the device file itself. If a process can write to the InfiniBand device, then it can use InfiniBand. By default, these devices are only accessible by the root user.
The InfiniBand devices are the network cards or Host Channel Adapters (HCA) and can have multiple ports. An InfiniBand port is the link or interface that connects to an InfiniBand subnet. The subnet is the high-speed network on which multiple machines (ports) are connected. As with regular networks, InfiniBand switches are used to facilitate communication across a subnet, and routers can be used to connect different subnets with each other.
An InfiniBand subnet is managed by a Subnet Manager (SM). This is a process that coordinates the management of the different ports within the subnet, as well as the partitions. Partitions in InfiniBand are a way to differentiate between different communications within a subnet, like Virtual Local Area Networks (VLANs) in more regular networks. With partitioned communication, it is the subnet manager that tells which ports can be used for which partitions of the communication.
Protecting InfiniBand networks
Unlike regular networks, where firewalls and switch-level access controls are the norm for preventing unauthorized access, InfiniBand has few protection measures in place. InfiniBand largely assumes that the network is within a trusted environment. However, that does not exclude us from applying more rigid controls over which process can access the InfiniBand network in SELinux.
As the communication flow itself is directly mapped in-memory toward the devices, the Linux kernel does not have any hooks available to do packet-level controls like it can with regular TCP/UDP traffic (using the SECMARK capabilities), or even session-level controls with sockets. Instead, SELinux focuses on two main controls, as visualized in the following diagram:
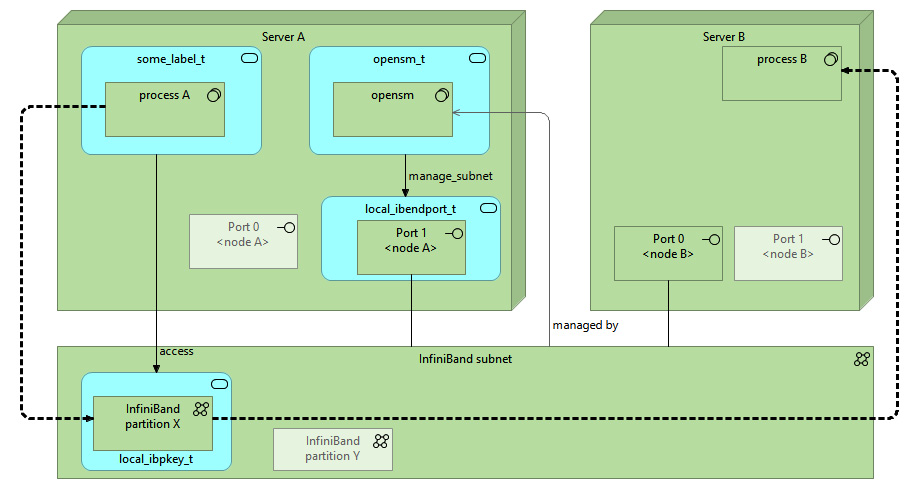
Figure 5.1 – SELinux InfiniBand controls
These two main controls are as follows:
- Controlling who can manage the InfiniBand subnet
- Controlling who can access an InfiniBand partition
To properly govern these controls, the semanage application assigns the right type to the appropriate InfiniBand resource. However, not all SELinux policies already contain the appropriate types, so we need to add those in as well.
Managing the InfiniBand subnet
Let's start with managing the InfiniBand network. With InfiniBand on Linux, this is most often accomplished using the opensm application. Many InfiniBand adapters have multiple ports, allowing a server to participate in multiple InfiniBand subnets. With SELinux, we can control which domain can manage a subnet by controlling access to the InfiniBand port on a device.
First, we need to assign a label to the InfiniBand port associated with a subnet. To accomplish that, we first need to obtain the right InfiniBand device, create the appropriate label (type), and then assign it to the port.
Let's start by querying the available InfiniBand-capable devices on the system using ibv_devinfo:
# ibv_devinfo
hca_id: rxe0
transport: InfiniBand (0)
fw_ver: 0.0.0
...
phys_port_cnt:
port: 1
state: PORT_ACTIVE (4)
...
Next, we create a type (label) to assign to the port. This type is only used to validate the access from the opensm application to this port. We use the CIL language for this (which we will elaborate upon in Chapter 16, Developing Policies with SELinux CIL). Create a file with the following content (let's call it infiniband_subnet.cil):
(typeattribute ibendport_type)
(type local_ibendport_t)
(typeattributeset ibendport_type local_ibendport_t)
(allow opensm_t local_ibendport_t (infiniband_endport (manage_subnet)))
In the previous code, we enhance the SELinux policy with a new type called local_ibendport_t, assign it the ibendport_type attribute, and then grant the opensm_t domain the manage_subnet privilege within the infiniband_endport class.
Let's load this policy enhancement:
# semodule -i infiniband_subnet.cil
Finally, we assign this newly created type to the InfiniBand port:
# semanage ibendport -a -t local_ibendport_t -z rxe0 1
This command assigns the local_ibendport_t type to port number 1 of the rxe0 device (as obtained from ibv_devinfo). Once this mapping is in place, we can query it using semanage as well:
# semanage ibendport -l
SELinux IB End Port Type IB Device Name Port Number
local_ibendport_t rxe0 0x1
Without any mappings, the command does not display any output.
Important note
Currently, most Linux distributions have not incorporated InfiniBand support within the SELinux policy, requiring us to create our own custom labels. We can expect that distributions will add in default types for InfiniBand resources, and that SELinux support for InfiniBand will be extended with sane defaults.
If we use InfiniBand on an SELinux-enabled system without any port mappings, the initial security context for unlabeled classes will be used as the label for this port, namely, unlabeled_t. It is, however, not recommended to stick to this label, as it is more widely used for unlabeled resources. Granting any privilege to the unlabeled_t type should be limited to highly privileged processes, and its use should be carefully considered to ensure that logging interpretation and SELinux policy rules vis-à-vis InfiniBand resources are clear (through well-documented types).
Controlling access to InfiniBand partitions
While the previous section focused on allowing the management application opensm to manage a subnet, this section will focus on restricting access to the InfiniBand network to the right domains. As mentioned before, an InfiniBand subnet can be divided further into separate networks using InfiniBand partitions.
Originally, these partitions are used to allow Quality of Service (QoS) or specific bandwidth and performance requirements on flows. The SM defines the partitions and its attributes, and applications use a Partition Key (P_Key) to inform the InfiniBand network as regards to which partition certain communications must be done.
SELinux can govern these partitions by creating a mapping between the InfiniBand subnet plus P_Key and an SELinux type. However, as with the subnet management, we need to find the appropriate details first and create an appropriate SELinux type before we can define the mapping.
Let's start by figuring out the subnet and partition details. Both are managed by opensm. If you do not have access to the opensm configuration, then you need to ascertain these details from the (InfiniBand) network administrator.
Within the opensm partition configuration (/etc/rdma/partitions.conf), the subnet and prefix can be found as follows:
# grep '=0x' /etc/rdma/partitions.conf
Default=0x7fff, rate=3, mtu=4, scope=2, defmember=full;
Default=0x7fff, ipoib, rate=3, mtu=4, scope=2;
rxe0_1=0x0610, rate=7, mtu=4, scope=2, defmember=full;
rxe0_1=0x0610, ipoib, rate=7, mtu=4, scope=2;
In this example, two partitions are defined. The first one is the default partition, which needs to remain (0x7fff). The second partition with key 0x0610 is active on the rxe0 device and port 1. It is this second partition that we will protect with SELinux.
Let's create a new type to assign to this partition. We use the CIL format again to define the policy enhancement, and store these rules in a file called infiniband_pkey.cil:
(typeattribute ibpkey_type)
(type local_ibpkey_t)
(typeattributeset ibpkey_type local_ibpkey_t)
(allow unconfined_t local_ibpkey_t (infiniband_pkey (access)))
Within this example, we've created the local_ibpkey_t type, assigned it to the ibpkey_type attribute, and granted unconfined_t access privilege within the infiniband_pkey class.
Let's load the policy:
# semodule -i infiniband_pkey.cil
We can now create an appropriate mapping to this partition, and limit it to the ff12:: subnet prefix:
# semanage ibpkey -a -t local_ibpkey_t -x ff12:: 0x0610
# semanage ibpkey -l
SELinux IB PKey Type Subnet_Prefix Pkey Number
local_ibpkey_t ff12:: 0x610
While we can create separate types for each partition, we can also use an SELinux range to use SELinux category support:
# semanage ibpkey -a -t local_ibpkey_t -r s0-s0:c0.c4 -x ff12:: 0x0610
With categories, we can grant access based on the source domain category, something we benefit from with other network protection measures such as labeled networking, which we tackle next.
Understanding labeled networking
Another approach to further fine-tune access controls on the network level is to introduce labeled networking. With labeled networking, security information passes on between hosts (unlike SECMARK, which only starts when the netfilter subsystem receives the packet, and whose marking never leaves the host). This is also known as peer labeling, as the security information passes on between hosts (peers).
The advantage of labeled networking is that security information remains across the network, allowing end-to-end enforcement on mandatory access-control settings between systems as well as retaining the sensitivity level of communication flows between systems. The major downside, however, is that this requires an additional network technology (protocol) that can manage labels on network packets or flows.
SELinux currently supports two implementations as part of the labeled networking approach: NetLabel and labeled IPsec. With NetLabel, two implementations exist: fallback labeling and CIPSO. In both cases, only the sensitivity of the source domain is retained across the communication. Labeled IPsec supports transporting the entire security context with it.
Note
NetLabel actually supports loopback-enabled, full-label support. In that case, the full label (and not only the sensitivity and categories) is passed on. However, this only works for communications that go through the loopback interface and, as such, do not leave the current host.
Quite some time ago, support for NetLabel/CIPSO and labeled IPsec merged into a common framework, which introduces three additional privilege checks in SELinux: interface checking, node checking, and peer checking. These privilege checks are only active when labeled traffic is used; without labeled traffic, these checks are simply ignored.
Fallback labeling with NetLabel
The NetLabel project supports fallback labeling, where administrators can assign labels to traffic from or to network locations that don't use labeled networking. By using fallback labeling, the peer controls mentioned in the next few sections can be applied even without labeled IPsec or NetLabel/CIPSO being in place.
The netlabelctl command controls the NetLabel configurations. Let's create a fallback label assignment for all traffic originating from the 192.168.100.1 address:
# netlabelctl unlbl add interface:eth0 address:192.168.100.1 label:system_u:object_r:netlabel_peer_t:s0
To list the current definitions, use the following command:
# netlabelctl -p unlbl list
Accept unlabeled packets : on
Configured NetLabel address mappings (1)
interface: eth0
address: 192.168.100.1/32
label: "system_u:object_r:netlabel_peer_t:s0"
With this rule in place, labeled networking is active. Any traffic originating from the 192.168.100.1 address will be labeled with the netlabel_peer_t:s0 label, while all other traffic will be labeled with the (default) unlabeled_t:s0 label. Of course, the SELinux policy must allow all domains to have the recv permission from either the unlabeled_t peers or the netlabel_peer_t peers.
Fallback labeling is useful for supporting a mix of labeled networking environments and non-labeled networks, which is why we list it here before documenting the various labeled networking technologies.
Limiting flows based on the network interface
The idea involving interface checking is that each packet that comes into a system passes an ingress check on an interface, whereas a packet that goes out of a system passes an egress check. ingress and egress are the SELinux permissions involved, whereas interfaces are given a security context.
Interface labels can be granted using the semanage tool and are especially useful for assigning sensitivity levels to interfaces in case of MLS, although assigning different labels to the interface is also possible (but requires more adjustments to the running SELinux policy to return with a working system):
# semanage interface -a -t netif_t -r s1-s1:c0.c128 eth0
Like the other semanage commands, we can view the current mappings as follows:
# semanage interface -l
SELinux Interface Context
eth0 system_u:object_r:netif_t:s1-s1:c0.c128
Keep in mind that for inbound communications, the acting domain is the peer. With labeled IPsec, this would be the client domain initiating the connection, whereas in NetLabel/CIPSO, this is the associated peer label (such as netlabel_peer_t).
By default, the interface is labeled with netif_t and without sensitivity constraints. This will, however, not be shown in the semanage interface -l output as its default output is empty.
Accepting peer communication from selected hosts
SELinux nodes represent specific hosts (or a network of hosts) that data is sent to (sendto) or received from (recvfrom) and are handled through the SELinux node class. Just like interfaces, these can be listed and defined by the semanage tool. In the following example, we mark the 10.0.0.0/8 network with the node_t type and associate a set of categories with it:
# semanage node -a -t node_t -p ipv4 -M 255.255.255.255 -r s0-s0:c0.c128 192.168.100.1
Again, we can list the current definitions, too:
# semanage node -l
Like the network interface flow, the acting domain for incoming communications is the peer label.
By default, nodes are labeled with node_t and without category constraints. This will, however, not be shown in the semanage node -l output as its default output is empty.
Verifying peer-to-peer flow
The final check is a peer class check. For labeled IPsec, this is the label of the socket sending out the data (such as mozilla_t). For NetLabel/CIPSO, however, the peer will be static, based on the source, as CIPSO is only able to pass on sensitivity levels. A common label seen for NetLabel is netlabel_peer_t.
Unlike the interface and node checks, peer checks have the peer domain as the target rather than the source.
Important note
In all the labeled networking use cases, the process listed in a denial has nothing to do with the denial shown in the audit logs. This is because the denial triggers from within a kernel subsystem rather than through a call made by a user process. As a result, the kernel interrupts an unrelated process to prepare and log the denial, and this process name is used in the denial event.
To finish up, look at the following diagram, which provides an overview of these various controls and the level to which they apply:

Figure 5.2 – Schematic overview of the various network-related SELinux controls
The top-level controls are handled on the domain level (such as httpd_t), whereas the bottom-level controls are on the peer level (such as netlabel_peer_t).
Using old-style controls
Most Linux distributions enable the network_peer_control capability. This is an enhancement within the SELinux subsystem that uses the previously mentioned peer class for verifying peer-to-peer flow.
However, SELinux policies can opt to return to the previous approach, where peer-to-peer flow is no longer controlled over the peer class, but uses the tcp_socket class for communication. In that case, the tcp_socket class will be used against the peer domain, and it will also use the recvfrom permission (on top of the existing tcp_socket permissions).
The current value of the network_peer_control capability can be queried through the SELinux filesystem:
# cat /sys/fs/selinux/policy_capabilities/network_peer_controls
1
If the value is 0, then the previously mentioned peer controls will be handled through the tcp_socket class instead of the peer class.
The default labeled networking controls within SELinux do not pass on any process context, and the use of fallback labeling with NetLabel is most commonly used in environments where the system participates in both labeled as well as unlabeled networks. However, there is a much more common networking implementation that not only supports labeled networking, but even passes on the domain context and does not require specialized environments: labeled IPsec.
Using labeled IPsec with SELinux
Although setting up and maintaining an IPsec setup is far beyond the scope of this book, let's look at a simple IPsec example to show how to enable labeled IPsec on a system. Remember that the labeled network controls on the interface, node, and peer levels, as mentioned earlier, are automatically enabled the moment we use labeled IPsec.
In an IPsec setup, there are three important concepts to be aware of:
- The security policy database (SPD) contains the rules and information for the kernel to know when communication should be handled by an IP policy (and, as a result, handled through a security association).
- A security association (SA) is a one-way channel between two hosts and contains all the security information about the channel. When labeled IPsec is in use, it also contains the context information of the client that caused the security association to materialize.
- The security association database (SAD) contains the individual security associations.
Security associations with a labeled IPsec setup are no longer purely indexed by the source and target address, but also the source context. As such, a Linux system that participates in a labeled IPsec setup will easily have several dozen SAs for a single communication flow between hosts, as each SA now also represents a client domain.
Labeled IPsec introduces a few additional access controls through SELinux:
- Individual entries in the SPD are given a context. Domains that want to obtain an SA need to have the polmatch privilege (part of the association class) against this context. Also, domains that initiate an SA need to have the setcontext privilege (also part of the association class) against the target domain.
- Only authorized domains can make modifications to the SPD, which is also governed through the setcontext privilege, but now also against the SPD context entries. This privilege is generally granted to IPsec tools, such as Libreswan's pluto (ipsec_t).
- Domains that participate in IPsec communication must have the sendto privilege with their own association and the recvfrom privilege with the association of the peer domain. The receiving domain also requires the recv privilege from the peer class associated with the peer domain.
So while labeled IPsec cannot govern whether mozilla_t can communicate with httpd_t (as mozilla_t only needs to be able to send to its own association), it can control whether httpd_t allows or denies incoming communication from mozilla_t (as it requires the recvfrom privilege on the mozilla_t association). The following diagram displays this complex game of privileges:
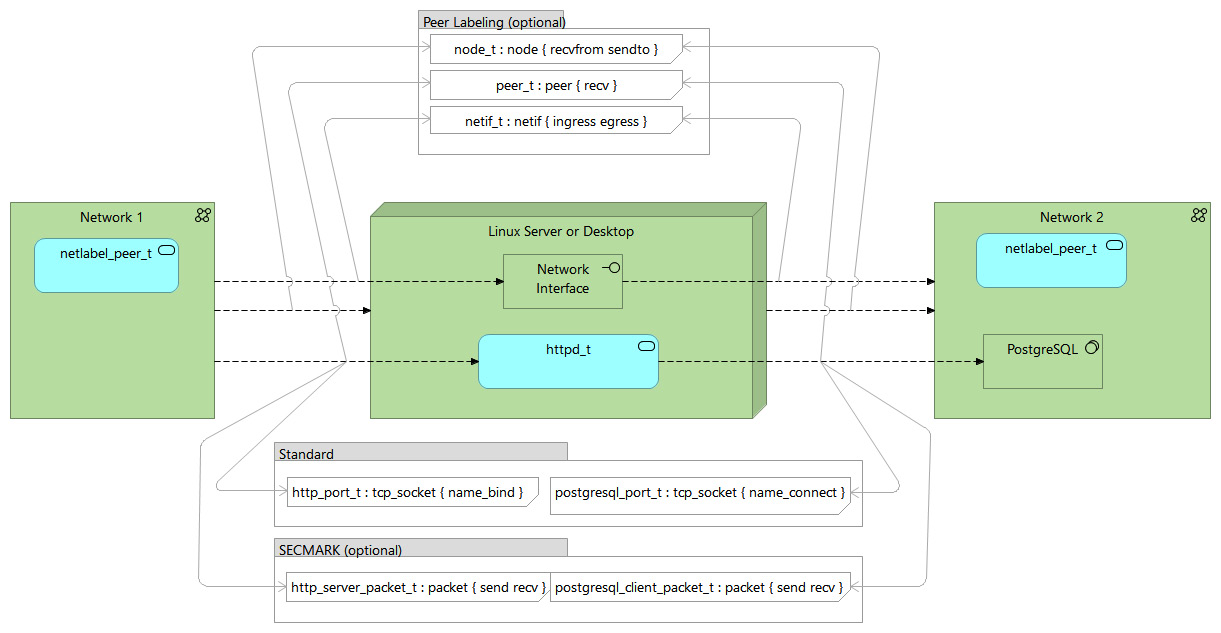
Figure 5.3 – Example SELinux controls for labeled IPsec
In the next example, we will set up a simple IPsec tunnel between two hosts using the Libreswan tool.
Setting up regular IPsec
Configuring Libreswan is a matter of configuring Libreswan's main configuration file (ipsec.conf). Most distributions will use an include directory (such as /etc/ipsec.d) where admins or applications can place connection-specific settings. Generally, this include directory is used for the actual IPsec configurations, whereas the general ipsec.conf file is for Libreswan behavior.
To create a host-to-host connection, we first define a shared secret on both hosts. Let's call the connection rem1-rem2 (as those are the hostnames used for the two hosts), so the shared secret will be stored as /etc/ipsec.d/rem1-rem2.secrets:
192.168.100.4 192.168.100.5 : PSK "somesharedkey"
Next, we define the VPN connection in /etc/ipsec.d/rem1-rem2.conf as follows:
conn rem1-rem2
left=192.168.100.4
right=192.168.100.5
auto=start
authby=secret
#labeled-ipsec=yes
#policy-label=system_u:object_r:ipsec_spd_t:s0
The settings that enable labeled IPsec are commented out for now to first test the IPsec connection without this feature.
Launch the IPsec service on both systems:
# systemctl start ipsec
Verify whether the connection works, for instance, by checking the network traffic with tcpdump, or by checking the state with ip xfrm state.
Enabling labeled IPsec
To use labeled IPsec with Libreswan, uncomment the labeled-ipsec and policy-label directives in the /etc/ipsec.d/rem1-rem2.conf IPsec definition. Restart the ipsec service, and try the connection again.
When an application tries to communicate over IPsec with remote domains, pluto (or any other Internet Key Exchange version 2 (IKEv2) client that supports labeled IPsec) will exchange the necessary information (including context) with the other side. Both sides will then update the SPD with the necessary SAs and associate the same security policy information (SPI) with it. From that point onward, the sending side will add the agreed-upon SPI information to the IPsec packets so that the remote side can immediately associate the right context with it again.
The huge advantage here is that the client and server contexts, including sensitivity and categories, are synchronized (they are not actually sent over the wire with each packet, but exchanged initially when the security associations are set up).
In certain specialized or highly secure environments, labeled networking is supported within the network itself. The most common labeling technology used is CIPSO, whose SELinux support we cover next.
Supporting CIPSO with NetLabel and SELinux
NetLabel/CIPSO labels and transmits sensitivities across the network. Unlike labeled IPsec, no other context information is sent or synchronized. So, when we consider the communication flows between two points, they will have a default, common SELinux type (rather than the SELinux type associated with the source or target) but will have sensitivity labels based on the sensitivity label of the remote side.
Part of NetLabel's configuration are mapping definitions that inform the system which communication flows (from selected interfaces, or even from configured IP addresses) are for a certain Domain of Interpretation (DOI). The CIPSO standard defines the DOI as a collection of systems that interpret the CIPSO label similarly, or, in our case, use the same SELinux policy and configuration of sensitivity labels.
Once these mappings have been established, NetLabel/CIPSO will pass on the sensitivity information (and categories) between hosts. The context we will see on the communication flows will be netlabel_peer_t, a default context assigned to NetLabel/CIPSO-originated traffic.
Through this approach, we can start daemons with a sensitivity range and thus only accept connections from users or clients that have the right security clearance, even on remote, NetLabel/CIPSO-enabled systems.
Configuring CIPSO mappings
A preliminary requirement for having a good CIPSO-enabled network is to have a common understanding of which DOI will be used and what its consequences are. Labeled networks can use different DOIs for specific purposes.
Along with the DOI, we also need to take care of how the categories and sensitivities are passed on over the CIPSO-enabled network. The CIPSO tag controls this setting, and NetLabel supports this with the following three values:
- With tags:1, the categories are provided in the CIPSO package in a bitmap approach. This is the most common approach, but limits the number of supported categories to 240 (from 0 to 239).
- With tags:2, the categories are enumerated separately. This allows a wider range of categories (up to 65,543), but only supports at most 15 enumerated categories. Try to use tags:2 when you have many categories but for each scope, only a few categories need to be supported.
- With tags:5, the categories can be mentioned in a ranged approach (lowest and highest), with at most seven such low/high pairs.
Note that the CIPSO tag results are handled under the hood: system administrators only need to configure the NetLabel mapping to use a selected tag value.
Let's assume that we have two CIPSO-enabled networks, which have 10.1.0.0/16 associated with doi:1 and 10.2.0.0/16 associated with doi:2. Both use the tag value 1. First, we enable CIPSO and allow it to pass CIPSO-labeled packages with the DOI set to either 1 or 2. We don't perform any translations (so the category and sensitivity set on the CIPSO package is the one used by SELinux):
# netlabelctl cipsov4 add pass doi:1 tags:1
# netlabelctl cipsov4 add pass doi:2 tags:1
If we need to translate (say that we use sensitivity s0-s3 while the CIPSO network uses sensitivity 100-103), a command would look like so:
# netlabelctl cipsov4 add std doi:1 tags:1
levels:0=100,1=101,2=102
Next, we implement mapping rules, telling the NetLabel configuration which network traffic is to be associated with doi:1 or doi:2:
# netlabelctl map del default
# netlabelctl map add default address:10.1.0.0/16 protocol:cipsov4,1
# netlabelctl map add default address:10.2.0.0/16 protocol:cipsov4,2
To list the current mappings, use the list option:
# netlabelctl map list -p
Configured NetLabel domain mappings (2)
domain: DEFAULT (IPv4)
address: 10.1.0.0/16
protocol: CIPSO, DOI = 1
domain: DEFAULT (IPv4)
address: 10.2.0.0/16
protocol: CIPSO, DOI = 2
That's it. We removed the initial default mapping (as that would prevent the addition of new default mappings) and then configured NetLabel to tag traffic for the given networks with the right CIPSO configuration.
Adding domain-specific mappings
NetLabel can also be configured to ensure that given SELinux domains use a well-defined DOI rather than the default one configured earlier on. For instance, to have the SSH daemon (running in the sshd_t domain) have its network traffic labeled with CIPSO doi:3, we'd use this:
# netlabelctl cipsov4 add pass doi:3 tags:1
# netlabelctl map add domain:sshd_t protocol:cipsov4,3
The mapping rules can even be more selective than that. We can tell NetLabel to use doi:2 for SSH traffic originating from one network, use doi:3 for SSH traffic originating from another network, and even use unlabeled network traffic when it comes from any other network:
# netlabelctl map del domain:sshd_t protocol:cipsov4,3
# netlabelctl map add domain:sshd_t address:10.1.0.0/16 protocol:cipsov4,1
# netlabelctl map add domain:sshd_t address:10.4.0.0/16 protocol:cipsov4,3
# netlabelctl map add domain:sshd_t address:0.0.0.0/0 protocol:unlbl
The NetLabel framework will try to match the most specific rule first, so 0.0.0.0/0 is only matched when no other rule matches.
Using local CIPSO definitions
As mentioned before, NetLabel, by default, only passes the sensitivity and categories. However, when using local (over the loopback interface) CIPSO, it is possible to use full label controls. When enabled, peer controls will not be applied against the default netlabel_peer_t type, but will use the client or server domain.
To use local CIPSO definitions, first declare the DOI for local use:
# netlabelctl cipsov4 add local doi:5
Next, have the local communication use the defined DOI (5 in our example):
# netlabelctl map add default address:127.0.0.1 protocol:cipsov4,5
With this enabled, local communication will be associated with doi:5 and use the local mapping, passing the full label to the mandatory access control system (SELinux).
Supporting IPv6 CALIPSO
CIPSO is an IPv4 protocol, but a similar framework exists for IPv6, named Common Architecture Label IPv6 Security Option (CALIPSO). As with CIPSO, CALIPSO is supported by the NetLabel project. When we need CALIPSO support, the protocol target is calipso rather than cipsov4.
CALIPSO has a few small differences compared to CIPSO in NetLabel:
- Only one tag type is supported (unlike CIPSO's three tag types). As a result, CALIPSO administrators do not need to specify tags:# anywhere.
- CALIPSO only uses pass-through mode. Translations are not supported.
- The NetLabel CALIPSO implementation currently does not support local mode, where the full label would be passed on.
Beyond these differences, the use of CALIPSO is very similar to CIPSO.
Summary
SELinux, by default, uses access controls based on the file representation of communication primitives or the sockets used. On InfiniBand networks, access controls are limited to accessing the InfiniBand port and partitions. For TCP, UDP, and SCTP ports, administrators have some leeway in handling the controls through the semanage command without resorting to SELinux policy updates. Once we go into the realms of network-based communication, more advanced communication control can be accomplished through Linux netfilter support, using SECMARK labeling, and through peer labeling.
In the case of SECMARK labeling, local firewall rules are used to map contexts to packets, which are then governed through SELinux policy. With peer labeling, either the application context itself (labeled IPsec) or its sensitivity level (netfilter/CIPSO) identify the resources the access controls apply. This allows an almost application-to-application network flow control through SELinux policies.
We learned that the most common firewall frameworks (iptables and nftables) support SECMARK already, while the more recent eBPF-based bpfilter application has yet to receive this support.
In the next chapter, we look at how we can use common infrastructure-as-code frameworks to address the various SELinux controls in a server environment.
Questions
- How do you map an SELinux type to a TCP port?
- Does SECMARK labeling change the network packets as they go over the wire?
- What semanage subcommands are used for InfiniBand support?
- Is specialized equipment needed for labeled IPsec?