
AlwaysOn Availability Groups provide a flexible option for achieving high availability, recovering from disasters, and scaling out read-only workloads. The technology synchronizes data at the database level, with health monitoring and quorum often provided by a Windows cluster, although a Windows cluster is not mandatory.
There are different variations of AlwaysOn Availability Groups. The traditional flavor sits on a Windows Failover Cluster, but if SQL Server is installed on Linux, then Pacemaker can be used. AlwaysOn Availability Groups can also be configured with no cluster at all. This is acceptable for offloading reporting but is not a valid high availability (HA) or disaster recovery (DR) configuration. When using SQL Server 2019 with Windows Server 2019, Availability Groups can even be configured for containerized SQL, with Kubernetes.
This chapter focuses on configuring Availability Groups on a Windows Failover Cluster, for the purpose of providing both HA and DR, and scaling read-only workloads. Availability Groups on Linux will be explored in Chapter 6.
For the demonstrations in this chapter, we will use the cluster built in Chapter 3, but two additional nodes have been added to the cluster: CLUSTERNODE3 and CLUSTERNODE4. We will not use the Failover Clustered Instance that we configured in Chapter 4. Instead, stand-alone instances of SQL Server have been installed on each of the nodes, with the following names: CLUSTERNODE1PROD, CLUSTERNODE2SYNCHA, CLUSTERNODE3ASYNCDR, and CLUSTERNODE4READSCALE. Cluster nodes 1 and 2 sit within a subnet called Site1 and Cluster nodes 3 and 4 sit within a different subnet, called Site2. The instances are storing the Database data and log files on the C: volume. The shared storage within the cluster is not being used for these instances.
Create Sales, Customers, Accounts, and HR Databases.
Enable Availability Groups on our instances.
Create an Availability group for the HR Database, using the New Availability Group wizard. This Availability Group will be configured for HA only.
Create an Availability Group for the Sales and Customers database using the New Availability Group dialog box. This will be configured for HA, DR, and read-scaling.
Create an Availability Group for the Accounts database using T-SQL. This Availability Group will be configured for HA and DR without any read-scaling.
We will also discuss how PowerShell can be used to create Availability Groups.
Preparing to Implement AlwaysOn Availability Groups
Creating Databases
Configuring SQL Server
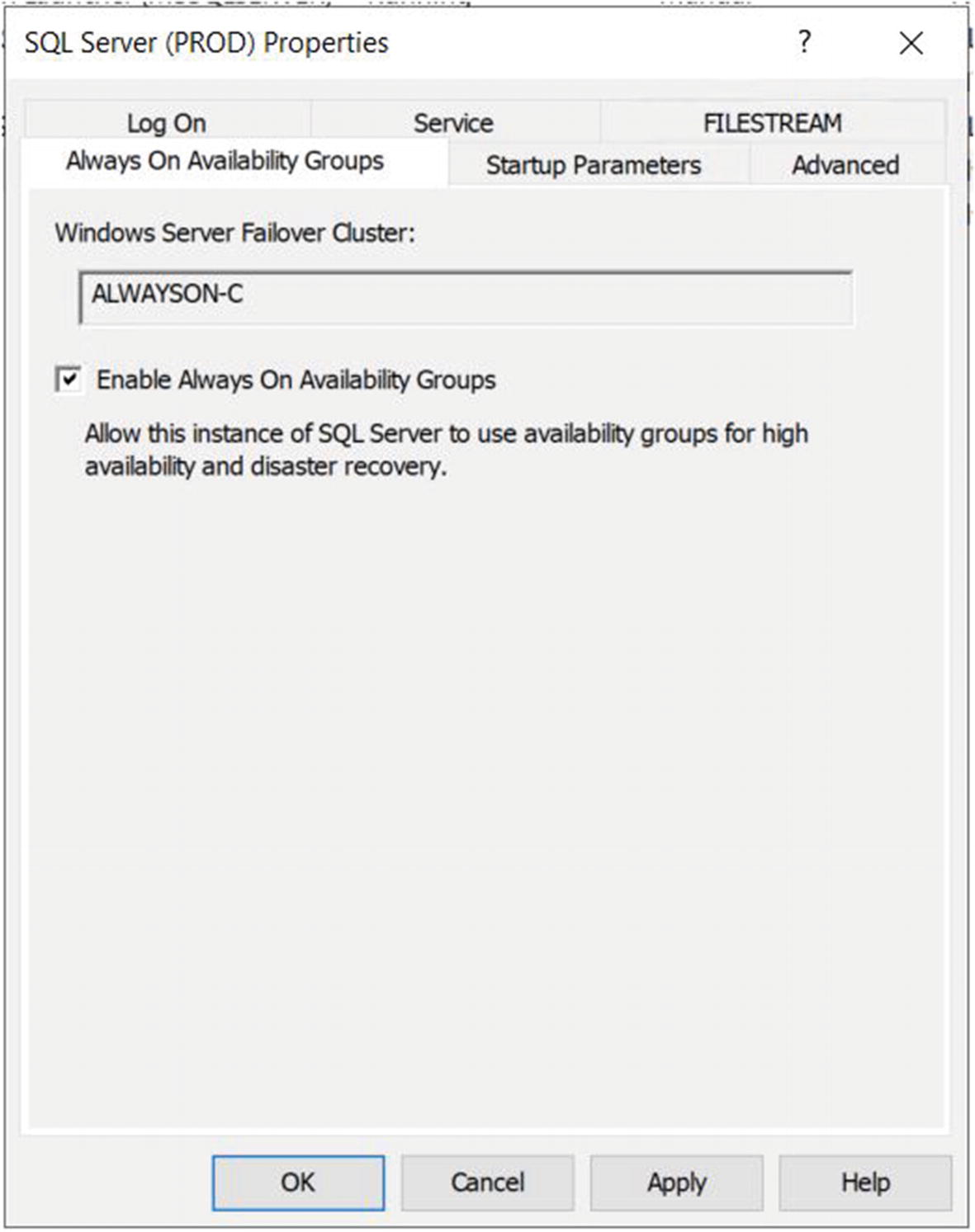
The Always On Availability Groups Tab
On this tab, we check the Enable AlwaysOn Availability Groups box and ensure that the cluster name displayed in the Windows Failover Cluster Name box is correct. We then need to restart the SQL Server service. Because AlwaysOn Availability Groups uses stand-alone instances, which are installed locally on each cluster node, as opposed to a failover clustered instance, which spans multiple nodes, we need to repeat these steps for each stand-alone instance hosted on the cluster.
Enabling AlwaysOn Availability Groups
Backing Up the Databases
Using the New Availability Group Wizard
When the backups complete successfully, we invoke the New Availability Group wizard by drilling through AlwaysOn High Availability in Object Explorer, within SSMS and selecting the New Availability Group wizard from the context menu of the Availability Groups folder. The Introduction page of the wizard is displayed, giving us an overview of the steps that we need to undertake.

The Specify Name Page
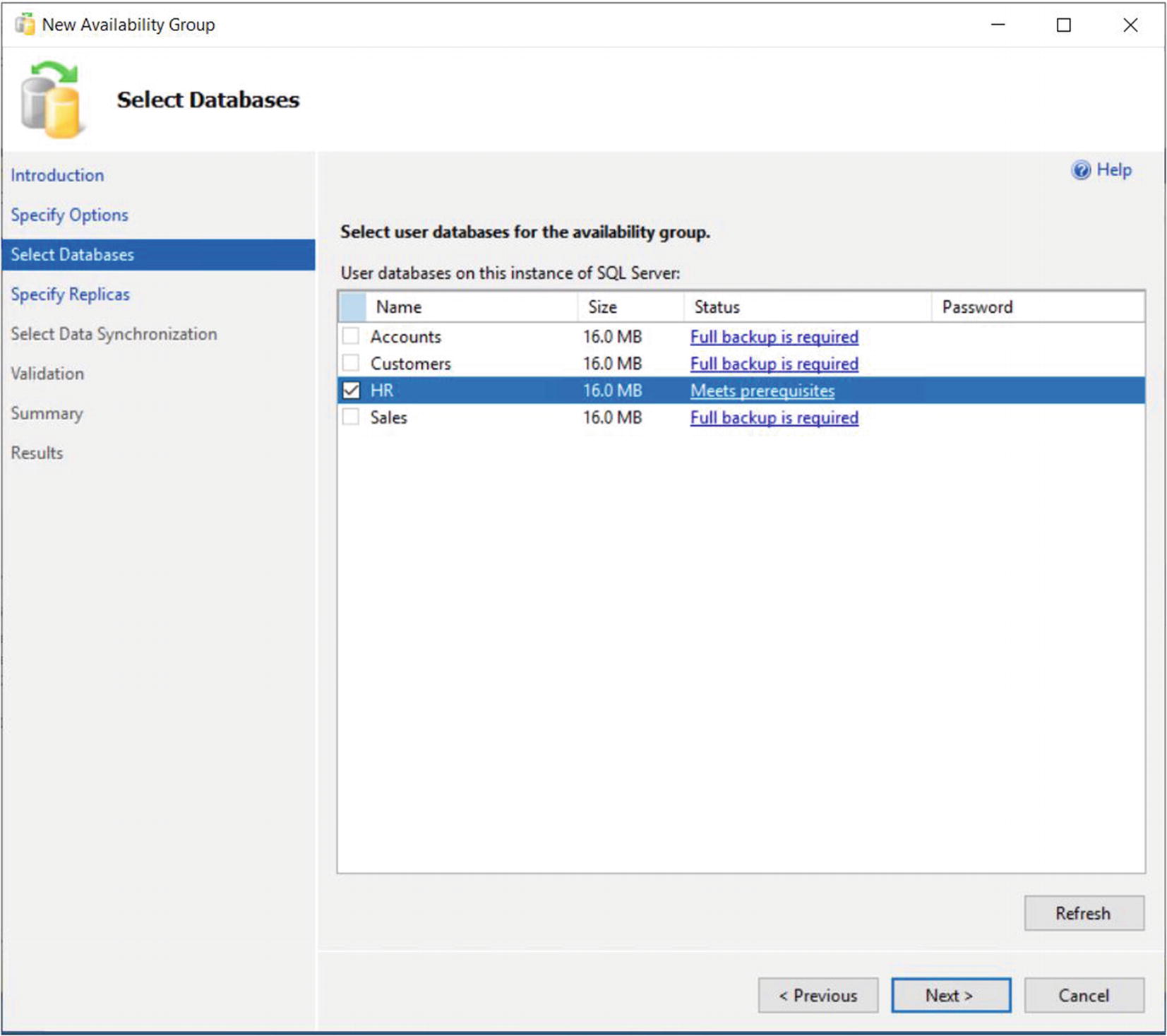
The Select Database Page
The Specify Replicas page consists of five tabs. We use the first tab, Replicas, to add the secondary replicas to the topology. Checking the Synchronous Commit option causes data to be committed on the secondary replica before it is committed on the primary replica. (This is also referred to as hardening the log on the secondary before the primary.) This means that, in the event of a failover, data loss is not possible, meaning that we can meet an SLA (service-level agreement) with an RPO (recovery point objective) of zero. It also means that there will be a performance degradation, however. If we choose Asynchronous Commit, then the replica operates in Asynchronous Commit mode. This means that data is committed on the primary replica before being committed on the secondary replica. This stops us from suffering performance degradation, but it also means that, in the event of failover, the RPO is nondeterministic.
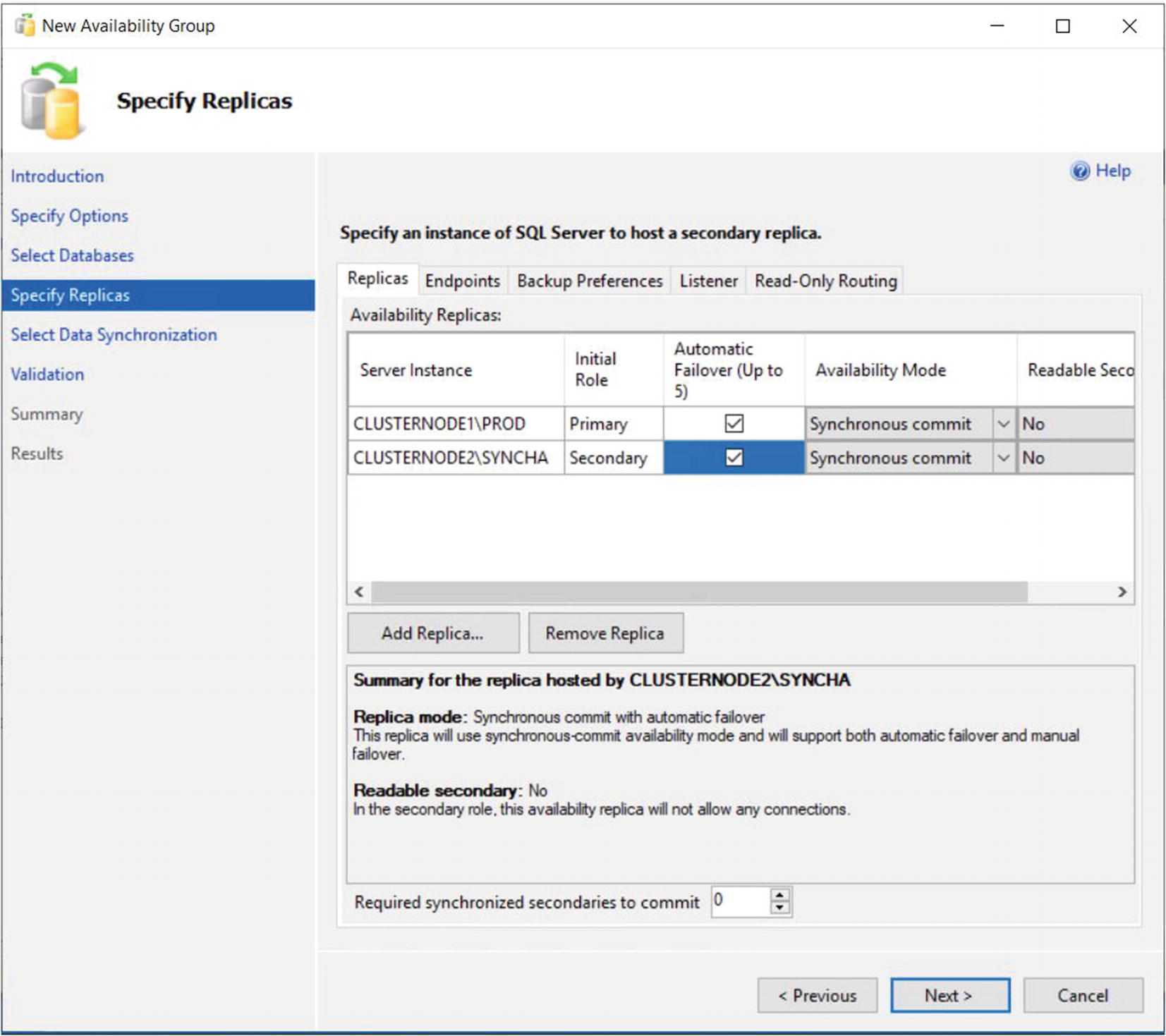
The Replicas Tab
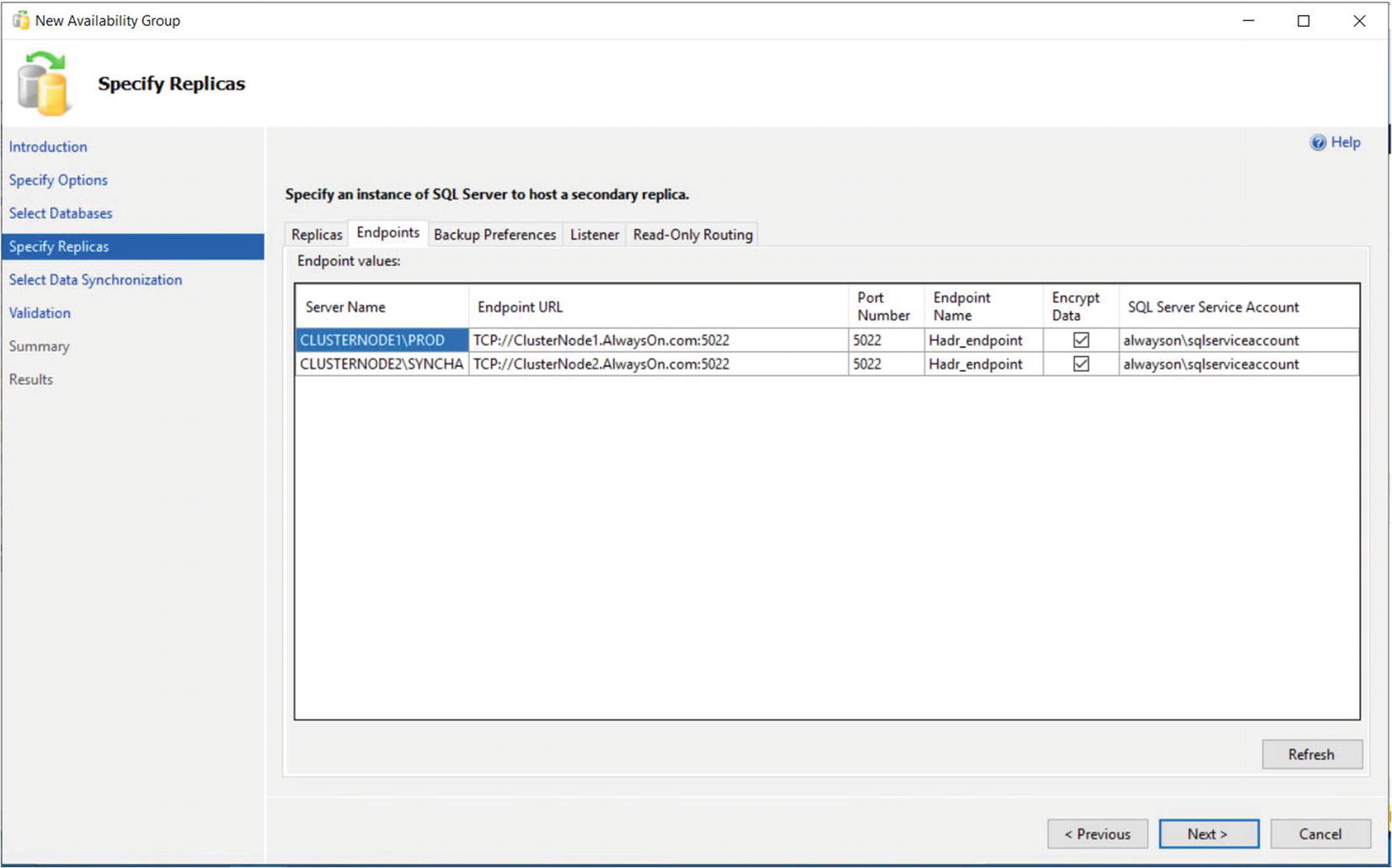
The Endpoints Tab
Optionally, you can also change the name of the endpoint that is created. Because only one database mirroring endpoint is allowed per instance, however, and because the default name is fairly descriptive, there is not always a reason to change it. Some DBAs choose to rename it to include the name of the instance, since this can simplify the management of multiple servers. This is a good idea if your enterprise has multiple availability groups, split across multiple instances on the same cluster.
The service account each instance uses is displayed for informational purposes. It simplifies security administration if you ensure that the same service account is used by both instances. If you fail to do this, you will need to grant each instance permissions to each service account. This means that instead of reducing the security footprint of each service account by using it for one instance only, you simply push the footprint up to the SQL Server level instead of the operating system level.
The endpoint URL specifies the URL of the endpoint that availability groups will use to communicate. The format of the URL is [Transport Protocol]://[Path]:[Port]. The transport protocol for a database mirroring endpoint is always TCP (Transmission Control Protocol). The path can either be the fully qualified domain name (FQDN) of the server, the server name on its own, or an IP address, which is unique across the network. I recommend using the FQDN of the server, because this is always guaranteed to work. It is also the default value populated. The port should match the port number that you specify for the endpoint.
Availability groups communicate with a database mirroring endpoint. Although database mirroring is deprecated, the endpoints are not.

The Backup Preferences Tab
Although the advantages of reducing IO on the primary replica are obvious, I, somewhat controversially, recommend against scaling automated backups to secondary replicas in many cases. This is especially the case when RTO (recovery time objective) is a priority for the application because of operational supportability issues. Imagine a scenario in which backups are being taken against a secondary replica and a user calls to say that they have accidently deleted all data from a critical table. You now need to restore a copy of the database and repopulate the table. The backup files, however, sit on the secondary replica. As a result, you need to copy the backup files over to the primary replica before you can begin to restore the database (or perform the restore over the network). This instantly increases your RTO.
Also, when configured to allow backups against multiple servers, SQL Server still only maintains the backup history on the instance where the backup was taken. This means that you may be scrambling between servers, trying to retrieve all of your backup files, not knowing where each one resides. This becomes even worse if one of the servers has a complete system outage. You can find yourself in a scenario in which you have a broken log chain.
The workaround for most of the issues that I just mentioned is to use a share on a file server and configure each instance to back up to the same share. This can have neutral, positive, or negative consequences. The negative consequence of this is where you have locally attached storage. By setting backups up in this manner, you are now sending all of your backups across the network rather than backing them up locally. This can increase the duration of your backups as well as increase network traffic. The positive consequence is if you are a cloud IaaS (Infrastructure as a Service) environment. It is likely that the storage attached to your VM will be more expensive than the storage used to create the file share. In many modern, on-premise scenarios, however, the consequences are neutral. This is because it is likely that both the file share and your server’s storage reside on the same SAN or NAS device. This means that there is no difference in network traffic or latency if you configure backups in this way.
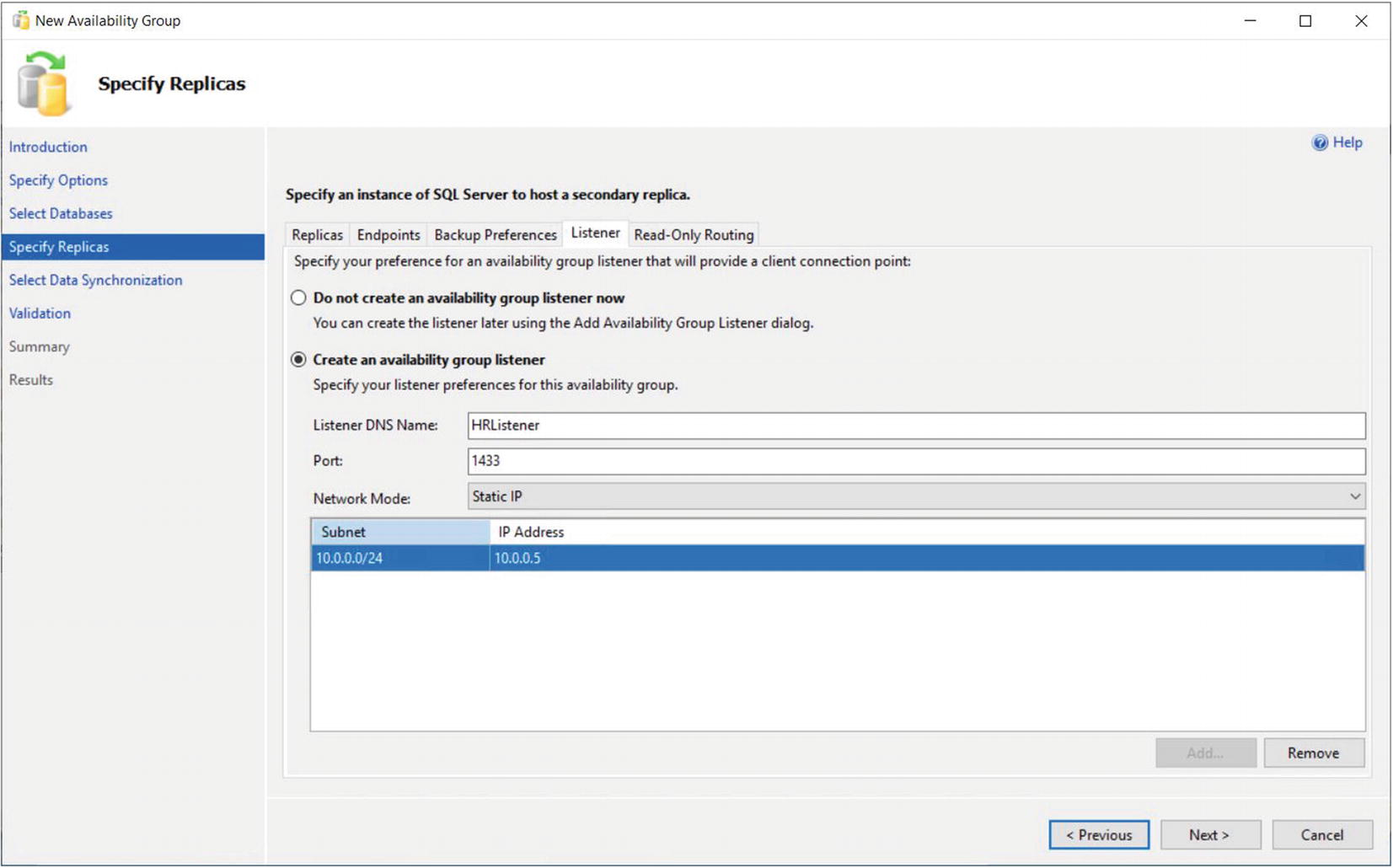
The Listener Tab
A subnet is a segment of a network containing a partition of IP Addresses from a larger network.
Because our HR Availability Group does not span multiple subnets, then our Listener will only have a single IP Address.
If you do not have Create Computer Objects permission within the organizational unit (OU), then the listener’s VCO (virtual computer object) must be present in AD and you must be assigned Full Control permissions on the object.
Tip Because the HR Availability Group will not be configured with readable secondaries, we do not need to configure the Read-Only Routing tab; however, we will explore read-only routing in the “Using the New Availability Group Dialog Box” section of this chapter.
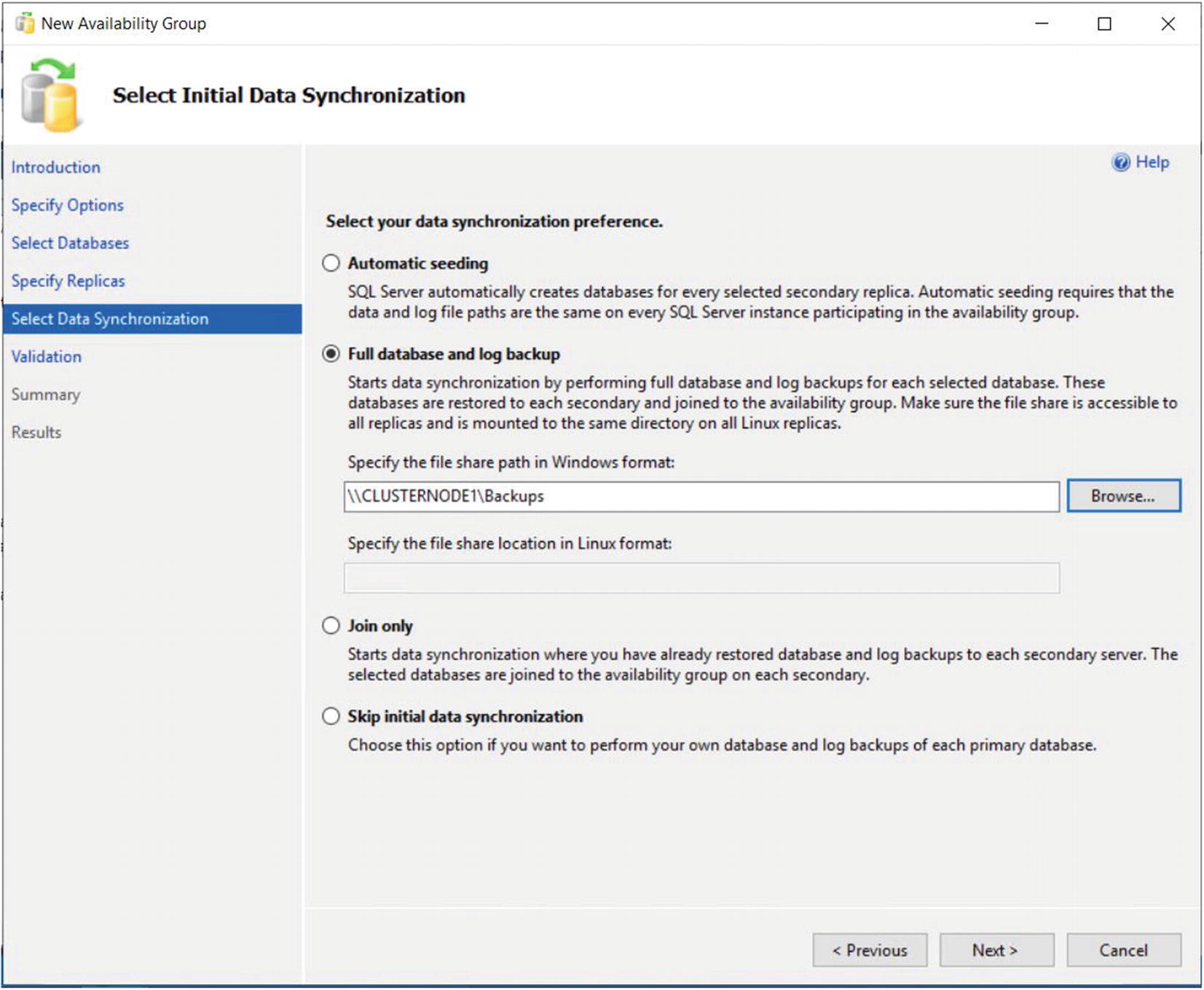
The Select Data Synchronization Page
If you have already backed up your databases and restored them onto the secondaries, then you can select the Join Only option. This starts the data synchronization, via log stream, on the databases within the availability group. Selecting Skip Initial Data Synchronization allows you to back up and restore the databases yourself after you complete the setup.
If you select the Automatic Seeding option, then an empty database is initially created on each Replica. The data is then seeding using VDI (Virtual Device Interface) over the log stream transport. This option is slower than initializing with a backup but avoid transferring large backup files between shares.
If your availability group will contain many databases, then it may be best to perform the backup/restore yourself. This is because the inbuilt utility will perform the actions sequentially, and therefore, it may take a long time to complete.
On the Validation page, rules that may cause the setup to fail are checked. If any of the results come back as Failed, then you need to resolve them before you attempt to continue.
A common gotcha is discovered during the validation process, when you are using named instances. A requirement of availability groups is that the databases must reside in the same file path on all replicas. The default file location for SQL Server data files includes the name of the instance, however. This does not matter for default instances, because the instance name within the file path is always MSSQLSERVER. For named instances, however, ensure that the database files are stored in a file path that exists on all servers.
Once validation tests are complete and we move to the Summary page, we are presented with a list of the tasks that are to be carried out during the setup.
As setup progresses, the results of each configuration task display on the Results page . If any errors occur on this page, be sure to investigate them, but this does not necessarily mean that the entire availability group needs to be reconfigured. For example, if the creation of the availability group listener fails because the VCO had not been presented in AD, then you can re-create the listener without needing to re-create the entire availability group.
As an alternative to using the New Availability Group wizard, you can perform the configuration of the availability group using the New Availability Group dialog box, followed by the Add Listener dialog box. This method of creating an availability group is examined in the next section.
Using the New Availability Group Dialog Box
Now that we have successfully created our first availability group, let’s create a second availability group for Sales. This availability group will contain the Sales and Customer databases. This time, we use the New Availability Group and Add Listener dialog boxes. We begin this process by backing up the two databases. Just like when we created the HR availability group, the databases are not selectable until we perform the backup. Unlike when we used the wizard, however, we have no way to make SQL Server perform the initial database synchronization using a backup/restore option. Therefore, we must either back up the database to the share that we created during the previous demonstration and then restore the backup, along with a transaction log backup, to the secondary instance, or use Automatic Seeding. In this example, we will use Automatic Seeding, so there is no need to restore the databases to the secondary Replicas in advance. The script in Listing 5-4 will perform the Full backup of the databases.
For Automatic Seeding to work, the Availability Group must be granted the CREATE ANY DATABASE permission on the secondary servers.
Backing Up and Restoring the Database
If we had not already created an availability group, then our next job would be to create a TCP endpoint so the instances could communicate. We would then need to create a login for the service account on each instance and grant it the connect permissions on the endpoints. Because we can only ever have one database mirroring endpoint per instance, however, we are not required to create a new one, and obviously we have no reason to grant the service account additional privileges. Therefore, we continue by creating the availability group. To do this, we drill through AlwaysOn High Availability in Object Explorer and select New Availability Group from the context menu of availability groups.
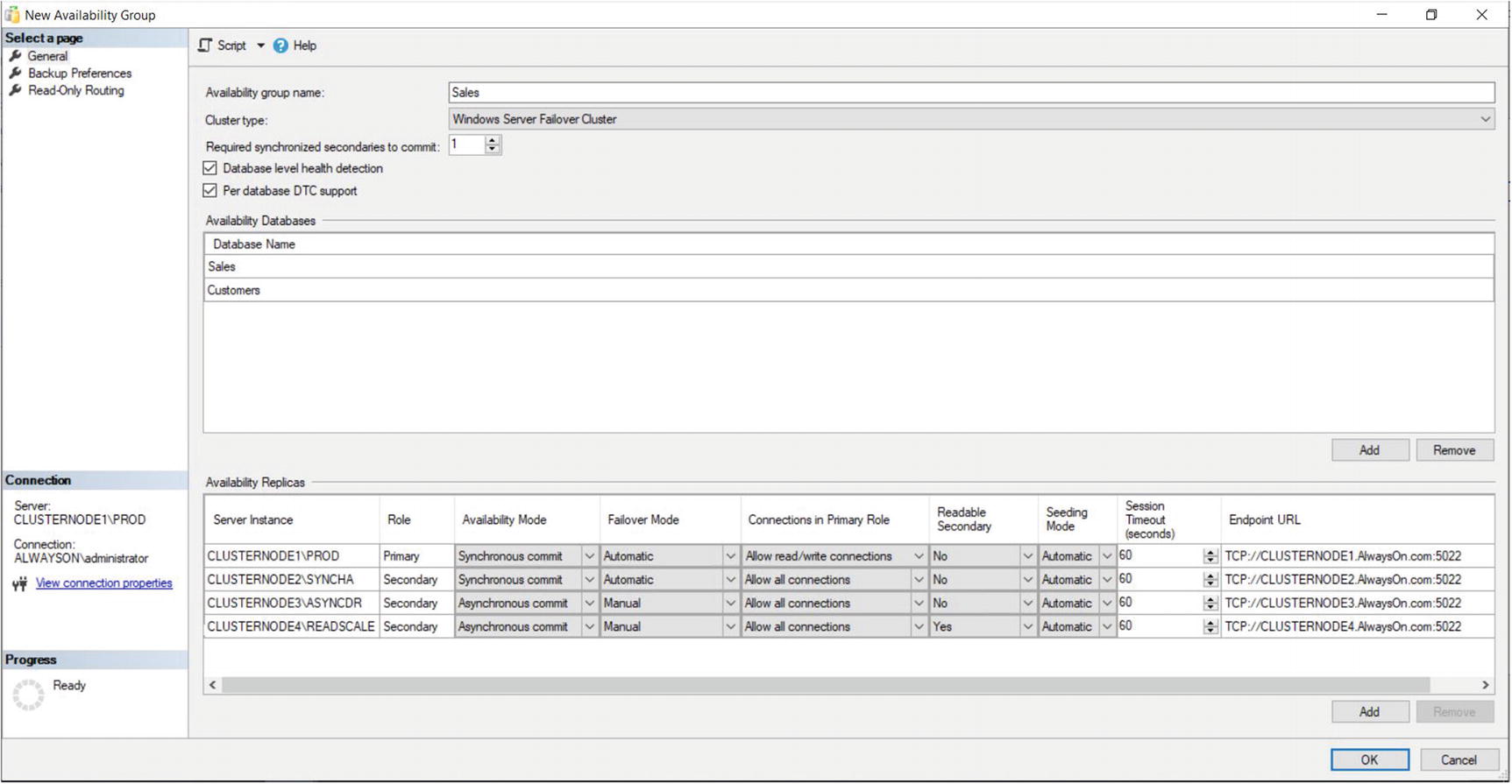
The New Availability Group Dialog Box
Now we can begin to set the replica properties. We discussed the Role, Availability Mode, Failover Mode, Readable Secondary, and Endpoint URL properties when we created the HR availability group. The Connection in Primary Role property defines what connections can be made to the replica if the replica is in the primary role. You can configure this as either Allow All Connections or Allow Read/Write connections. When Read/Write is specified, applications using the Application Intent = Read only parameter in their connection string will not be able to connect to the replica.
The Session Timeout property sets how long the replicas can go without receiving a ping from one another before they enter the DISCONNECTED state and the session ends. Although it is possible to set this value to as low as 5 seconds, it is usually a good idea to keep the setting at 60 seconds; otherwise, you run the risk of a false-positive response, resulting in unnecessary failover. If a replica times out, it needs to be resynchronized, since transactions on the primary will no longer wait for the secondary, even if the secondary is running in Synchronous Commit mode.

The Backup Preferences Tab
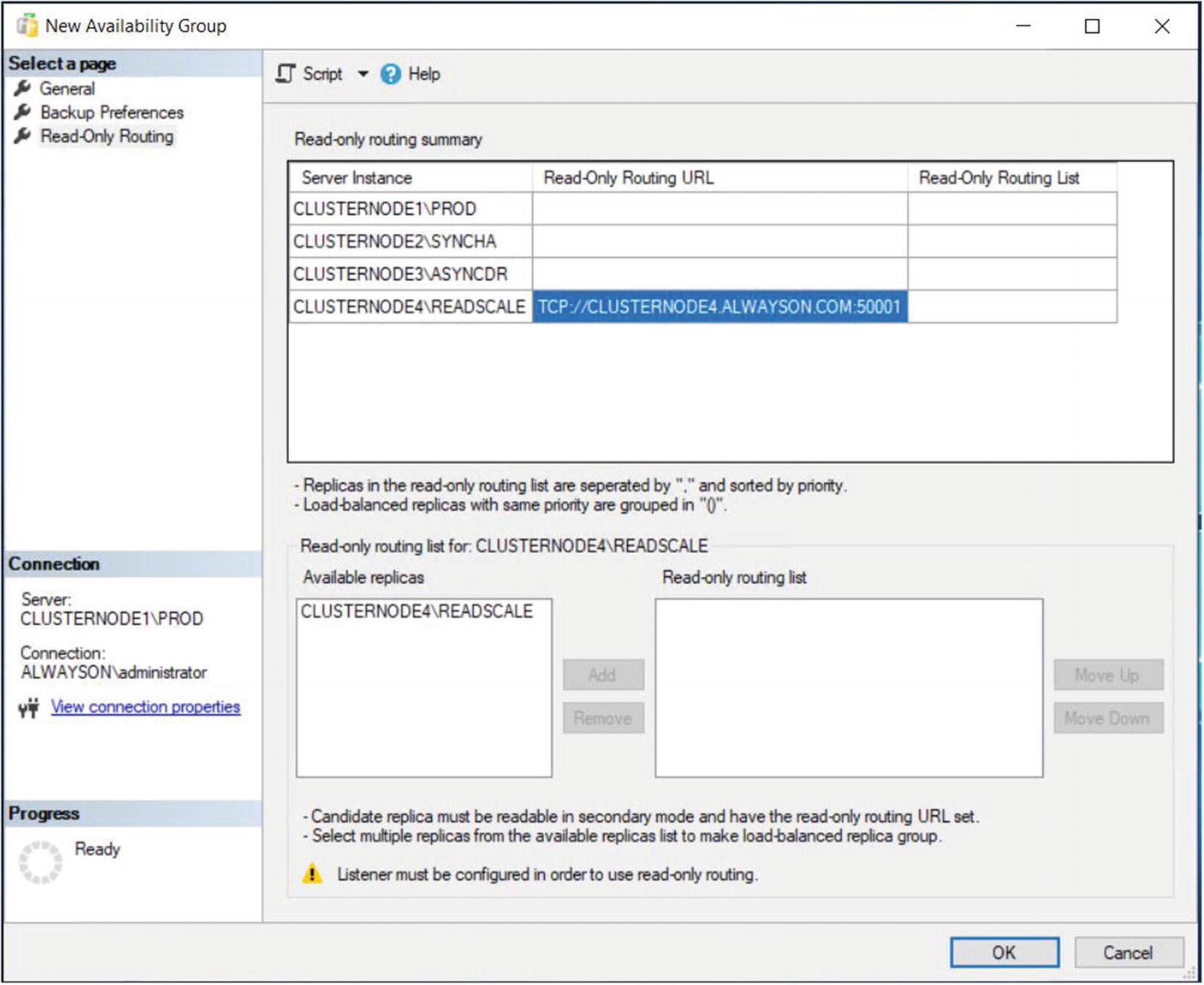
Read-Only Routing Tab – Configure the Read-Only Routing URL

Read-Only Routing Tab – Configure the Read-Only Routing List
This example shows a simple configuration, where all nodes (when they are hosting the primary replica) can offload read requests to a single readable secondary. More complex permutations are also possible, however. For example, you could configure each node to route to an individual readable secondary. This could prove useful if your Availability Group is split between multiple sites and you want to ensure that each node will route read-only requests to a replica in the same site, improving redundancy for the read scale-out.
Alternatively, you could allow each node to route read-only requests to multiple readable secondaries. In this scenario, you have two options. The default implementation will always send read request to the first available replica, so you are simply adding redundancy for your readable secondaries. If this is the intention, then each readable secondary in the routing list will be separated by a comma. A more advanced implementation is to configure readable secondaries to load balance read-only requests. In this scenario, read-only requests will be routed across the load balanced set, using a round-robin approach. Nodes within the load balanced set will be separated with a comma and the set will be enclosed in parenthesis.
You can also configure multiple load balanced sets within the same routing list. Here, requests will be routed round-robin around the first load balanced set, unless the nodes within that set become unavailable, in which case, requests will be routed round-robin around the next set.
For example, imagine that you wanted read-only requests to be load balanced between ServerA and ServerB, but if those servers became unavailable, you wanted requests to be load balanced between ServerC and ServerD. Your read-only routing list would take the form: ((ServerA,ServerB),(ServerC,ServerD)).
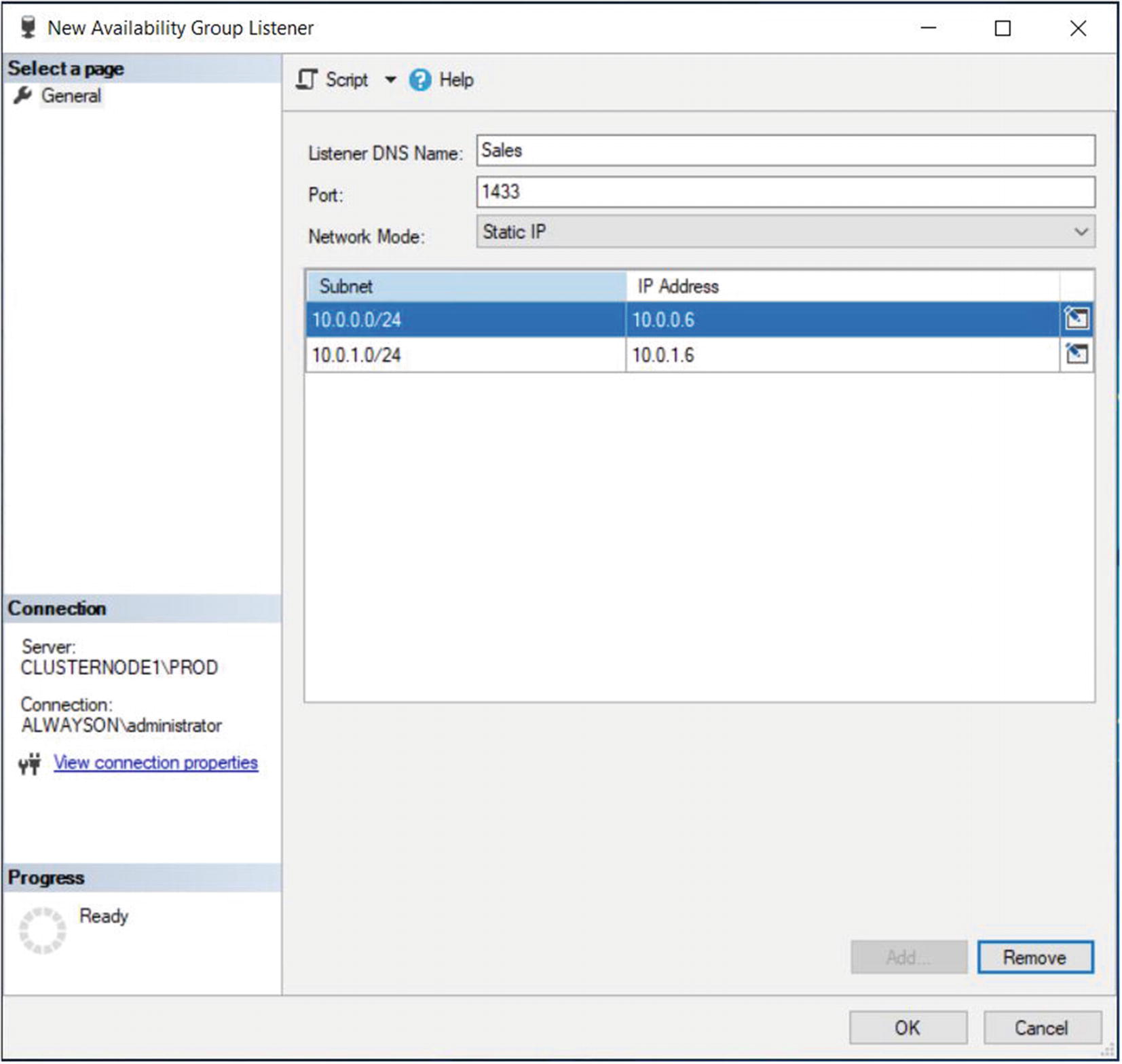
The New Availability Group Listener Dialog Box
In this dialog box, we start by entering the virtual name for the listener. We then define the port that it will listen on and the IP address that will be assigned to it.
We are able to use the same port for both of the listeners, as well as the SQL Server instance, because all three use different IP addresses.
Using T-SQL
Backup the Accounts Database
CREATE AVAILABILITY GROUP with Options
Option | Description |
|---|---|
AUTOMATED_BACKUP_PREFERENCE | Specifies which replica should be used for backups. Possible options are PRIMARY, meaning the Primary Replica will always be used; SECONDARY_ONLY, meaning that backup should never be performed on the Primary Replica; SECONDARY, meaning backups should not be taken on the Primary Replica, unless the Primary Replica is the only Replica online; and NONE, meaning that the role of each Replica will be ignored, when selecting which Replica to take the backup from. |
FAILURE_CONDITION_LEVEL | Specifies the events that should cause an Availability Group to automatically fail over. Acceptable levels are 1–5*. |
HEALTH_CHECK_TIMEOUT | Specified in milliseconds, the duration the cluster will wait for a response from the health check procedure, before assuming that the node is unresponsive and fails over. |
DB_FAILOVER | When an Availability Group has multiple databases, determines if a single database within the Availability Group moving out of the ONLINE state triggers a failover. |
DTC_SUPPORT | Specifies if cross-database transactions are supported within the Availability Group, using DTC (Distributed Transaction Coordinator). Acceptable values are PER_DB or NONE. |
BASIC | Used to create a basic Availability Group. Basic Availability Groups are discussed in Chapter 7. |
DISTRIBUTED | Used to create a Distributed Availability Group. This is discussed in Chapter 7. |
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT | Can be used to ensure a zero RPO, by enforcing a commit on secondary Replica(s) before proceeding. 0 indicates that transactions will be marked as NOT SYNCHRONIZED, but the Replica will continue to process transactions. |
CLUSTER_TYPE | Specifies the type of cluster that the Availability Group resides on. Possible values are WSFC, indicating a Windows Failover cluster; EXTERNAL, indicating a non-Windows cluster, such as Linux Pacemaker; or NONE, indicating clusterless Availability Groups. |
Failure Condition Levels
Level | Events That Trigger Failover |
|---|---|
1 | • The SQL Server service is stopped. • The SQL Server instance’s lease in the cluster has expired, because no acknowledgment has been received. |
2 | • Any Level 1 condition. • The SQL instance is not connected to the cluster and the health check threshold is exceeded. • The availability replica is in a FAILED state. |
3 (Default) | • Any Level 1–2 condition. • Critical internal errors within the SQL Server instance. |
4 | • Any Level 1–3 condition. • Moderate internal errors within the SQL Server instance. |
5 | • Any Level 1–4 condition. • Any internal failure within the SQL Server instance. |
ON REPLICA WITH Options
Option | Description |
|---|---|
ENDPOINT_URL | The URL of the endpoint on the SQL Server instance that hosts the Replica. |
FAILOVER_MODE | Specifies if the Replica should support automatic or manual failover. |
AVAILABILITY_MODE | Specifies if transactions on the Replica should be committed synchronously or asynchronously. The availability mode can also be set to CONFIGURATION_ONLY mode, to support external cluster mode. This will be discussed in Chapter 6. |
SESSION_TIMEOUT | Specifies the session timeout period in seconds. |
BACKUP_PRIORITY | Provides a weighting for the Replica, which will be used to decide which Replica backups should be taken from. 0 indicates backups cannot be taken from the replica. |
SEEDING_MODE | Specifies how the Replica is seeded. Acceptable values are AUTOMATIC and MANUAL. |
PRIMARY_ROLE | Used to specify the ALLOW_CONNECTIONS setting and pass a READ_ONLY_ROUTING_LIST. |
SECONDARY_ROLE | Used to specify a value for ALLOW_CONNECTIONS and pass a READ_ONLY_ROUTING_URL. |
Create the Accounts Availability Group
ADD LISTERNER WITH Options
Option | Description |
|---|---|
IP | Specify the IP Address(s) that the Listener will listen on, along with the subnet masks of the network relating to each IP address |
PORT | The Port that the Listener will listen on |
Create an Availability Group Listener
Implementing Availability Groups with PowerShell
As you might expect, Microsoft offers PowerShell cmdlets that can be used to create and manage SQL Server Availability Groups and Availability Group Listeners. This is becoming increasingly important, as the world moves toward a DevOps culture, with PowerShell being the language of choice for many organizations looking to implement build automation.
Install the sqlserver PowerShell Module
If this is the first time you have installed a PowerShell module on the server, then you will be prompted to install the NuGet provider.
Once the sqlserver module is installed, you will have access to cmdlets which allow you to create and manage Availability Groups via PowerShell. The New-AvailabilityReplica cmdlet allows you to create an object which specifies the properties for each Replica. These objects can then be passed to the New-SqlAvailabilityGroup cmdlet , which will create the Availability Group.
Create to Foo Availability Group
Create an Availability Group Listener
Summary
AlwaysOn Availability Groups can be implemented with up to eight secondary replicas, combining both Synchronous and Asynchronous Commit modes. When implementing high availability with availability groups, you always use Synchronous Commit mode, because Asynchronous Commit mode does not support automatic failover. When implementing Synchronous Commit mode, however, you must be aware of the associated performance penalty caused by committing the transaction on the secondary replica before it is committed on the primary replica. For disaster recovery, you will normally choose to implement Asynchronous Commit mode.
The availability group can be created via the New Availability Group wizard, through dialog boxes, through T-SQL, or even through PowerShell. If you create an availability group using dialog boxes, then some aspects, such as the endpoint and associated permissions, must be scripted using T-SQL or PowerShell.
If you implement disaster recovery with availability groups, then you need to configure a multi-subnet cluster. This does not mean that you must have SAN replication between the sites, however, since availability groups do not rely on shared storage. What you do need to do is add additional IP addresses for the administrative cluster access point and also for the Availability Group Listener. You also need to pay attention to the properties of the cluster that support client reconnection to ensure that clients do not experience a high number of timeouts.