
Chapter 4: Making Sense of Master Data Management
In the last chapter, we looked at data management, its importance, and the different aspects of data management. There are many types of data and not all of them are treated the same way. This is especially true now, given that sources of data have been increasing steadily over the last few years. Earlier data was mostly structured and easily manageable, but with social data, machine-generated Internet of Things (IoT) data, sound and video data, and much more, it is becoming increasingly important to ensure that the data that is core to your business is identified and managed properly. In this chapter, we will discuss Master Data Management (MDM), different types of MDM data, its attributes, and why MDM is important.
We will also be discussing the Golden Record – the much sought-after record that accurately and comprehensively provides a single customer view. Next up will be the MDM and CRM strategy and the different ways that you can ensure that your System of Record and MDM can interface with each other. We will close the chapter by discussing Customer 360, the suite of products from Salesforce that tries to solve the MDM problem, along with other tools to deliver a complete and accurate picture of the customer.
The topics covered in this chapter include the following:
- Understanding master data
- The Golden Record
- MDM and CRM strategy
- Customer 360
By the end of this chapter, you will have a solid understanding of master data, its importance, and why the Golden Record is critical for data management and for organizations in understanding the customer's relationship with the organization. You will understand the correlation between the MDM and CRM strategy and the suite of tools that Salesforce provides to help achieve these business goals.
Understanding master data
In this section, we will first start with the definition of master data, the need to identify and manage master data, and the different types of master data. This is going to help us in our later discussion of the Golden Record and in the MDM and CRM strategy sections.
So, let's dive right in and define master data.
What is master data?
Master data can be defined as the data that describes the core entities of the business. This can include customers, suppliers, locations, leads, and so on. A good indication of whether a data element is master data is to review its use across multiple business functions, processes, or systems in the organization. For example, leads that funnel into the marketing team, once qualified, will flow down to the sales team. Once a deal has been won, the same lead, which is now a customer, will flow down to sales operations and in this instance, eventually into the ERP's contracts module as a customer. Sharing master data eliminates the need for each function to maintain its own list and facilitates uniformity across business areas.
We should note that master data is owned by the organization and not by a particular business function or department. This is important because master data requires stewardship, and this sets the context to communicate the right mindset in the organization, implying that everybody is responsible for master data. Otherwise, specific area or data specialists are left to clean up the data and ensure its accuracy, while users creating the data don't feel the same level of ownership and accountability.
The need for master data management
We established in earlier chapters that the volume of data has been growing and organizations are finding it challenging to keep pace with the volume as well as the sources of data. A typical organization will have dozens of different systems spread out and with their own proprietary data formats and ways to allow access to data. This is especially true for large organizations that are siloed and don't have effective master data management tools and processes in place. This can lead to the following challenges:
- Data governance: Mater data management and data governance go hand in hand. You cannot implement an effective data governance strategy unless you have identified and fixed any issues with master data. For example, a company has five Customer Relationship Management (CRM) systems across three regions as a result of acquisitions over the years. Some of the customers exist in multiple CRMs, with slight differences in addresses, phone numbers, and so on. Unless you can identify which is the most accurate and comprehensive record, enforcing data governance rules will not make a difference.
- Reporting: In the example stated in the previous point, how do we know who our high-value customers are if they have the same names, but with slight variations. For example, is Precision Printers LLC the same as Precision Printers Inc or PP Inc? Another example is if we have, say, five subsidiaries of a company but they are not identified as related to each other via an account hierarchy, and that knowledge sits in someone's head. Unless that person is around, we may be duplicating our marketing efforts and wasting time and money sending the same marketing brochure five times.
- Integrations: Integrations can become challenging when there is no consistent and accurately identified master data because, in a downstream system, which record are we going to send? For example, downstream call center software requires customer contact information. Based on the caller's phone number, the application matches it with the customer information sent by the upstream system and displays it to the call center agent, along with support levels and some other pertinent information. The customer contact information is held in CRM, but also manually entered in the ERP system. If we haven't defined which system is the source of truth and has the most accurate customer data, chances are we will be sending the incorrect customer contact to the call center system unless we incorporate additional logic in the interface that can send the correct information to the downstream system.
Downstream and upstream systems
In the context of integrations, downstream and upstream mean destination and source systems respectively. For example, if an ERP feeds product data into the Salesforce CRM and Salesforce has an integration with a call center system, then from the perspective of Salesforce, the ERP is regarded as an upstream system and the call center system is a downstream system.
- Customer service: In our call center example from the previous point, poor customer service could be a direct consequence of a lack of effective master data management. In this scenario, if the customer called in and the call center software matched it to the incorrect customer name or priority level, the customer experience with the call center would be less than optimal, resulting in a potentially disgruntled customer, if the SLA shown by the software is incorrect.
- Realizing revenue targets: Imagine going to a big-box store to purchase a laptop and you find the price tag at the store is different from the flyer you were mailed. Usually, the store will match the price on the flyer, but have you ever thought about why this happened in the first place? It could very well be a printing error, but could also be a master data problem. If the product pricing for the flyer was sourced from a different system than the one used by the store, a pricing discrepancy could arise. Now imagine if the price on the flyer was not intended to be 20% lower, the company just lost revenue, and for large volume stores, this can easily translate into hundreds of thousands of dollars, if not more.
- Maintaining and growing customer trust: A lack of effective master data and controls around it can lead to less customer trust. In one instance, due to a lack of effective master data management practices, branches were cannibalizing the company's own business by offering different prices for the same parts and repair services to reach their sales targets. Customers had less trust as a result and when they needed a repair, they would call three to five different branches to get the lowest possible quote. This happened because the manufacturer was continuously updating the pricing for parts and sending it over to the dealer. The dealer, in turn, was responsible for sending it to the branches, which then updated their rate sheets. Sometimes, the rate sheets were not updated for weeks, resulting in price discrepancies and, hence, revenue loss for the business.
- Regulatory compliance: Effective master data management can also lead to regulatory reporting and compliance issues. For example, how do you make sure that you have effectively removed all data for a specific person after receiving a right to be forgotten request if you don't have effective master data management processes in place to identify all possible instances of that person in the first place? Non-compliance with these regulations can be a costly business for organizations, not only in terms of bottom-line revenue but also reputation.
- Data quality: When data is stored in multiple systems with many different formats and these formats don't integrate, the usability of that data decreases. Having an effective master data management practice ensures that your data remains viable and trustworthy for users. Another aspect of data quality is duplication. Having master data in place ensures that you have taken care of the duplicates and that you are accessing the single most accurate record. For example, if a business function enters customers in the ERP after they have been vetted by the customer credit team, but the sale team is also entering the same customer in CRM, there are bound to be issues with that data. With master data management, you can rectify these types of issues and merge the records, leading to good data quality.
- Communication: Communication between departments can become challenging when there is a lack of consistency in identifying master data. This is pretty common in product-based businesses where one business department calls the product something else, while another function prefers to refer to it by yet another name.
Now that we have looked at the challenges when master data is not managed properly, let's look at the types of data that organizations have.
Categories of data
A lot of discussions are taking place regarding how many types of master data there are. Some say it's three, some five, but regardless, we have established that master data is critical for business operations and is typically found across the organization, meaning that one system may have all the customer contacts, whereas another one may have all the products that organization sells, while yet another system may have all the referential type data, including currencies and so on. Here are the five data types that a typical corporation will have:
- Transactional data: This is data generated by business activity such as sales orders, quotes, and invoices. This data is of importance to the company, either for historical reporting, analytics, legal, or regulatory compliance purposes.
- Metadata: This is data pertaining to data. In the case of Salesforce, this constitutes standard and custom fields, workflow rules, triggers, report definitions, single sign-on settings, and much more.
- Hierarchical data: This is data that stores relationships between data; for example, charts of accounts, and organizational hierarchies.
- Reference data: This is data that defines a collection of valid values and is referenced by other data, for example, a countries list, currencies, payment terms, and so on. This could also be data defined by international, regional, or industry standards and used in the organization.
- Master data: This is the core data that, within the enterprise, describes business entities around which business operations are conducted. This data is relatively static and not transactional in nature. Typically, the critical areas that master data encompasses are products, customers, locations, and a fourth area that consists of contracts and entitlements.
Understanding reference data and master data
Reference data is the data that is used to set the context for other data in the organization. For example, the Stage field on the opportunity object is used in conjunction with the transactional data (the opportunity itself) or different currencies that the opportunity can be in. Currencies, stages, statuses, and countries are all examples of reference data. Reference data not only provides context to the transactional data (stages on the opportunity object) but also to master data; by way of an example, on products, a picklist value that identifies whether the product is active or not or the Salutation field on the contact object.
A key difference between reference and master data is that in an ideal world, the former doesn't require record linkages, meaning that multiple instances of a similar record don't need to be resolved, unlike in maser data. In reality, there may be multiple sources of reference data; however, every effort should be made to identify a single source of truth to avoid confusion and the proliferation of bad data. For example, an account name (master data) may be coming in from three different systems and needs to be linked together to provide a clearer picture of the data. This is usually not needed for reference data, since it is more stable and changes less often. This doesn't mean that there are no challenges associated with reference data. Reference data can originate outside of the organization and therefore the consuming organization cannot exert any influence over it. For example, Dun & Bradstreet (D&B) provides data enrichment services.
It maintains up-to-date data, and once integrated, it can push automatic updates into Salesforce. For example, if an organization has the Industry field on the account object synced with D&B and the latter decides to make changes to a specific industry, that could potentially have a downstream impact within the organization.
Solving problems via master data management
Earlier, we reviewed challenges that organizations face when master data is not properly managed. In this section, we will review some examples to gain clarity in terms of where master data management adds a lot of value. Keep in mind that a small business with 50 customers that operates on repeat business will not require an extensive master data management solution. This is because, as you will see in the next section, they will not face the problems that comparatively larger organizations or businesses that have growing data face. However, this should not be misunderstood as smaller organizations not needing to manage their master data, rather that they may not need the extensive tools and processes that larger organizations need. In the examples coming up in the following sections, we will look specifically at customer data, but similar issues exist for other master data, such as products.
Duplicate data
This is a common problem and usually arises in a Merger and Acquisitions (M and A) scenario. When a company acquires another company, unless the acquired company is in another continent or in a different line of business, the majority of the time, customers between the companies will be shared. For example, an auto dealership acquired another dealer's three branches that are in the same territory. Both dealerships use the same CRM, but suddenly, the company now has to deal with redundant data and decide what to do with it. Implementing robust master data practices and tools can help alleviate these types of problems.
Source of truth record
This can easily happen in Salesforce when the sharing model has not been well thought out and is locked to such an extent that a sales representative cannot search for an account that may already exist within the database before creating a new account. As a result, you may see accounts created in CRM, such as IBM, IBM Ltd., IBM USA (Consulting), IBM USA (Health), and IBM Healthcare Management Solutions.
Data standardization
This is common in situations where there are multiple CRMs and, let's say, the Industry field has different values in each CRM, or the Customer Priority field on an Account object has High, Normal, or Low in one CRM, but Platinum, Gold, and Silver in another CRM.
Hierarchies
This is a problem when data has been entered in the CRM or multiple CRMs and adequate attention has not been given to defining a hierarchy for customer accounts. For example, a large global company can have hundreds of subsidiaries in different lines of business. How can an organization that is a major supplier to this global brand, including its subsidiaries, determine how much total revenue the account is generating? How much revenue is generated from a region, a line of business, or a sales territory? Unless there is some sort of hierarchy defined that properly links the subsidiaries with the parent company, it will require a lot of manual work to arrive at the numbers. Apart from this, hierarchies offer some further benefits, including the following:
- Revenue opportunities: In Salesforce, we know about the account hierarchy, but I want to drill down on the concept of hierarchies and why they are important. Earlier, we looked at how hierarchies can help us answer questions such as who our top customers are. Who are the top customers in a region or a territory? However, the benefits of hierarchies are not limited to this.
When having a comprehensive view, we can look for opportunities as well as any credit risk that a customer and its subsidiaries may carry. For example, Precision Printers, a global provider of printers and photocopiers in 150+ countries, has 47 subsidiaries. You are in negotiations with the company to renew the contract for another 10 years and you notice that one of the subsidiaries has consistently ordered large quantities of photocopiers in the last few years. You recommend including in the contract a special deal for that subsidiary at a discounted price if they order a minimum number of photocopiers every year. This type of insight would not have been possible in the absence of account hierarchies.
- Product insights: Given that you can have many different types of hierarchies, including product, supplier, and location hierarchies, forming hierarchies for these entities can reap benefits for the business. For example, a product hierarchy could help identify insights that could not have been achieved by using the product itself. For example, for a dealer selling heavy-duty construction machines and providing parts and maintenance services, a bucket attachment for a machine is a product that rolls up into a wheel loader (another product), which then rolls up into the construction machines category. Immediately, you can see how the bucket is related to the loader and the construction machines category.
This information can provide us with critical questions, such as should we be selling the bucket as part of the loader, or is there an opportunity for more revenue by selling it as a separate add-on? How does our loader compare to the loader from a competitor? Have they included the bucket in the base price of the machine?
- Accurate reporting: Another benefit is that hierarchies can provide a baseline for comparison between systems. For example, in the ERP, you may have the bucket attachment and the loader as two different products, but in the quoting system, you have them as one product, with the prices added up to come up with a list price. In your Business Intelligence (BI) tool, you add the prices of all machines sold in two territories minus the average national cost of the machine to come up with the final profit for each territory. What you didn't account for was the added surcharge that the manufacturer is adding to deliver the buckets to one of the territories that is in a remote location. This can give you skewed numbers, thereby impacting your sales and marketing efforts.
To be clear, this work of creating and maintaining hierarchies can also be done manually, and some companies do that, but it is tedious and error-prone. Consider, for example, your data team bringing in data from the ERP, CRM, and other systems, and then transforming the data so a valid comparison can be made. With MDM, the process, once it is set up, is automatic and the MDM tool does the heavy lifting that otherwise would be done by the data team. It is important to note though that having an MDM will not completely absolve the organization from any human intervention because there are going to be scenarios where a data steward will need to make a decision to confirm the matching and merging of records, but the overall process will be much more efficient.
In the next section, we will review the factors that can help us to identify whether a data element should be considered master data.
Deciding what data is master data
Companies should pay a lot of attention to identifying what master data truly is, as a loosely defined criterion can lead to managing data that is not that valuable and this can result in wasted effort and time. Some types of data can be clearly defined as master data, such as accounts and contacts, but other types of data may not be that clear. The criteria defined here would help in those situations and should be used as a guide in deciding what is and isn't master data within your organization:
- Behavior data: This is when a subset of data is analyzed to observe how it interacts with other data. For example, in transactional systems, master data interacts with transactional data. As an example, consider that a customer buys a product (master data), or a partner requests a new location (master data) to be added. The relationship between the master and transactional data can be viewed in a verb/noun construct where the transactional data constitutes a verb and a noun captures the master data. In our previous examples, the act of buying a product or tracking the partner's request to add a new location would constitute transactional data and the records associated with that would be transactional data. Master data would be the product being purchased or the location being added to the system.
- Life cycle: Master data can also be described by CRUD (Create, Read, Update, Delete) operations on it. For example, due to the need to ensure that master data is created accurately and completely, some companies will put in stringent processes to create customer accounts. Reviewing business processes that emphasize the creation of certain types of data can help in identifying master data.
- Cardinality: Cardinality is the number of elements in a set and if there are a few elements in a set, then the probability of the element being master data is low. For example, if an organization only has three customers, then in the context of needing an MDM solution, this would not be considered master data. This does not diminish the value of the customers, as they are essential in order for any business to survive, but it helps in deciding what data to consider as master data. In contrast, an organization with thousands of customers and multiple source systems could definitely make use of an MDM solution.
- Lifetime: Master data is more stable and less volatile compared to transactional data; for example, contracts are typically categorized as transactional data. An HVAC (Heating, Ventilation, Air Conditioning) company doing plumbing work for 2 weeks may just treat their contracts as transactional data, whereas when working with a large commercial client, they may decide to consider it master data. The company may decide to consider the 2-week long job as master data, too, just because it is easier to deal with it in the day-to-day business rather than separating it out. Similarly, work order estimates may be considered master data because they provide valuable historical intelligence when dealing with repeat customers.
- Complexity: This is another factor that helps to determine whether an element should be considered master data. The less complex an element, the less likely it is to be considered master data; for example, a manufacturer that makes one type of generic school bags and supplies large retailers such as Walmart or Target would be interested in knowing the count of the bags on hand rather than the type and other details. Because there is only one type and color, there is not much to manage in terms of master data.
- Value: This category is slightly subjective and leaves the consideration of a dataset to be recognized as master data to the entity owning it. For example, if the company considers all contracts regardless of duration and value as important and places high importance on all of them, then most likely, contracts will be managed as master data.
- Reuse: Reusability of data is usually a driver behind managing a set of elements as master data. A very common example of this is customer data since companies strive to have a consistent definition of customer data and make it available for widespread use within the organization.
Now that we have looked at some of the factors that can help us to identify whether a data element is master data, in the next section, we will review a common scenario that Salesforce data architects face, which is to design solutions to manage master and transactional data when there are multiple Salesforce orgs in an organization.
Multi-org scenario
A common scenario that is played out in organizations using Salesforce is the use of multiple Salesforce orgs, which can contribute to an incomplete view of the customer and other data. Multi-org scenarios can be the result of mergers and acquisitions, or with very large organizations that have many sales and marketing teams, and it makes sense to have distinct Salesforce orgs. This is not the place to discuss when a multi-org strategy makes sense, but the decision to go with multiple orgs shouldn't be taken lightly. Please refer to a blog post from Salesforce that goes into more detail on this topic: https://developer.salesforce.com/blogs/developer-relations/2014/10/enterprise-architecture-multi-org-strategy.html.
As seen earlier, not having optimal visibility of customer data results in missed opportunities, both in terms of sales and service. In terms of sales, it could be customer contact by different sales reps in the organization that are using the disconnected orgs and, similarly, when providing services, the disparate orgs don't facilitate a full view of the customer, oftentimes leading to the customer receiving conflicting information from service agents.
In an MDM scenario, multiple orgs can be piped into the MDM system, so it can handle the records from different systems, clean them, and push them back into the source systems if it's a co-existence-type MDM implementation, which we will look at later. It goes without saying that in the absence of MDM, processes and tools must still be implemented to ensure that data is not just moved from one org to the next, but it is ensured that it is clean data.
However, in cases where there is no MDM in the system landscape, the issues we discussed in this section materialize, and a solution is required for smooth business operations. In the next few sections, we will review some strategies on how this challenge stemming from a multi-org scenario can be managed while delivering consolidated data that's required for reporting and analytics. It must, however, be understood that although this discussion is taking place in the context of master data management, it must not be seen as tied to master data only. In a multi-org scenario, you would still want to ensure that not only your master data but also transactional data is properly managed.
The main reporting org
This approach requires designating a Salesforce org as the main reporting org, where data from source orgs is rolled up for analytical purposes. Figure 4.1 depicts this approach diagrammatically:

Figure 4.1 – Main reporting org
This master org doesn't send data back into the source orgs and reporting and is used to get that single customer record view. The benefits of this approach are as follows:
- It requires minimal changes to source orgs, as all the work is done in the master org.
- It results in an exclusive org that has clean and consolidated data for analytical purposes.
Some of the disadvantages of this approach are as follows:
- Manual and automated processes are still run from source orgs and do not benefit from the quality data that exists in the reporting org.
- Purchasing and maintaining another Salesforce org entails additional costs.
- The middleware that is needed to integrate the orgs entails additional costs.
As seen, this can be costly because of the need to maintain an additional org, but it has advantages over other models. Next, we will look at the parent org model.
The parent org
In this arrangement, an org is designated as the master org and is used for business processes and reporting. The child orgs report to the master org and data is synced between the orgs. The premise is that at any given time, data in all the orgs is synced. Some of the pros of this approach include the following:
- A single org for all business processing.
- Cleansed data exists in child orgs as well, leading to consistent data in MDM and source systems.
Some cons of this approach are as follows:
- This involves simple syncing, which can result in bad-quality data getting circulated in the systems.
- Additional costs in terms of integration processes and tools to keep the orgs in sync.
- It may require that multiple business processes are still maintained for each org.
As shown in the diagram, data is synced between parent and child orgs:

Figure 4.2 – Parent org model
The big benefit of this approach is the ability to keep all orgs in sync, but it requires fine-tuning and analysis to ensure that automation processes are run across the orgs.
The consolidation org
This approach requires that all Salesforce orgs except one are retired and data is consolidated into the main org. Some of the advantages of this include the following:
- Provides a single view of the customer
- Ease of maintenance
- Cost efficiencies via the consolidation of various orgs
- Effective central control of the main org
Some cons of this approach include the following:
- It could hit the org limits sooner.
- There is a potential for disruption to business users when they are moved to the consolidated org, especially given that Salesforce usernames are unique.
- It requires the recreation of business processes in the consolidated org.
- Massive volumes of data require multiple rounds of testing to ensure that data can be validated for accuracy and completeness.
- Consolidation-type projects are risky and costly in the short term.
As seen in Figure 4.3, one org is designated as the parent org and others are merged into it:
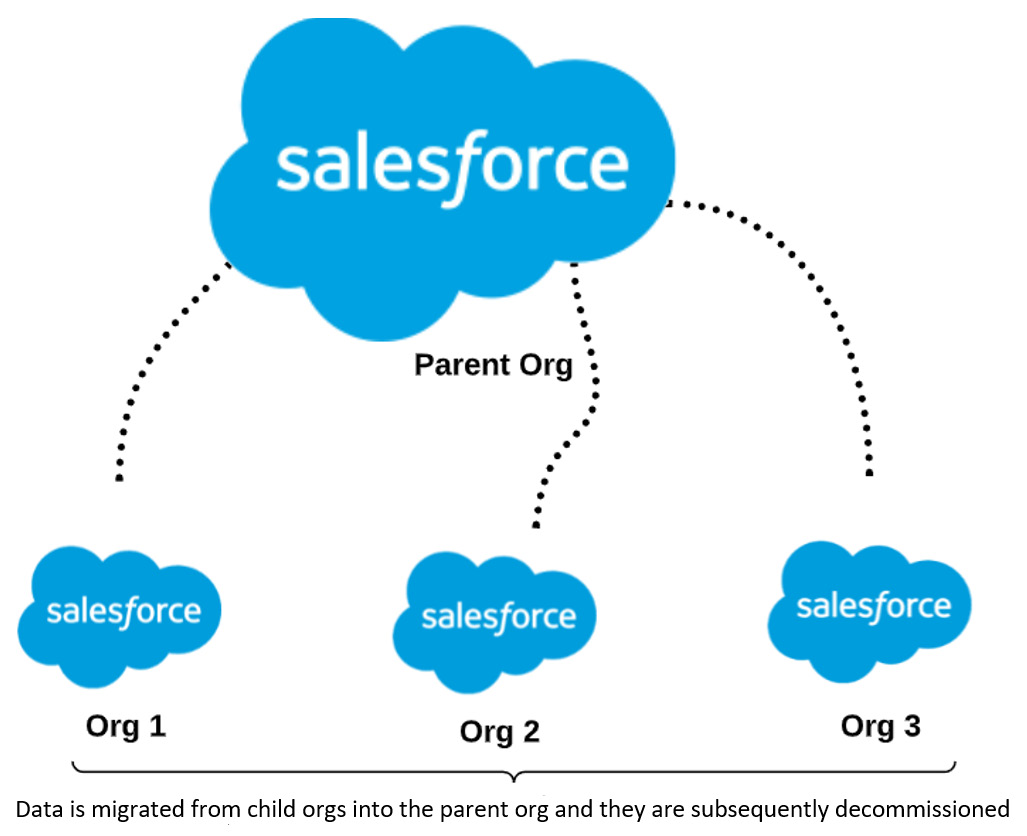
Figure 4.3 – Child orgs are migrated into the parent org and then decommissioned
Whichever approach is chosen, make sure that you have considered the advantages and disadvantages of each approach within the context of your technical systems' landscape and business priorities. If reporting and analytics are key, then the main reporting org model may be more suitable, whereas if business processes are a priority, then the single consolidated org model could yield the most value.
Defining Master Data Management (MDM)
MDM is the technology, tools, and processes that ensure that master data is coordinated across the enterprise. It provides a consistent, accurate, and complete view of the data available to the organization and business partners.
In the next section, we will review basic concepts that can be helpful to communicate internally and externally when working on an MDM project. Having a clear understanding of these concepts will allow you to define your business requirements more precisely and provide a foundation that can be used to select the optimal solution for your organization.
Reviewing the basics of data quality
What comes to your mind when thinking about bad data? Is it that values in a Phone field are formatted the same way, or that a picklist is restricted so additional values cannot be entered? You may answer yes to all or most of these questions; these practices of ensuring that data is consistent and formatted properly are generally referred to as standardization and formatting. These form an integral part of a modern MDM system. An MDM system will allow you to define standards based on industry and business practices for each of your source systems. Let's review these practices in more detail:
- Prevention: The adage that prevention is better than cure applies to master data as well and we should be mindful of opportunities to prevent bad data entry in the first place. These are usually easier to implement and can be used to enforce certain data standards. For example, validation rules in Salesforce can be used to enforce good data entry practices, such as ensuring that a custom Loss Reason field is filled out if the opportunity is set to Closed Lost. In this example, if the loss reason is not entered and a sales representative tries to save the opportunity after setting it to Closed Lost, they will get an error. Similarly, a very common prevention method on the Salesforce Platform is the use of picklists. When you have checked the Restrict picklist to the values defined in the value set checkbox, users cannot add new values either through the User Interface (UI) or through the APIs. A third example of this is defaulting values in fields so that in the case where a user has not entered a value in the field, a default value exists.
- Audit: Another way in which data can be managed is by way of audits. Audits are often used to frequently assess and improve the quality of data and are an effective form of managing your master data. The downside is that audits are done after the data has already been saved in the database and may have been used elsewhere for reporting or integration purposes. However, this should not stop us from auditing our data frequently and there are out-of-the-box tools that can be used for this, or AppExchange apps to help with the audits. For example, after you have set up duplicate rules in Salesforce, you can run reports to detect any duplicates with your data and take appropriate action.
- Correction: Another approach commonly used during data entry is that of correction, but this is less used than prevention, mainly because of the rules that need to be defined and applied consistently. For example, a custom field on a lead object is used to capture the sales engineer working on the lead and, at the time of conversion, it gets read and entered into the Opportunity Team Members related list on the opportunity. A simple trigger, or preferably a Process Builder flow, can be used to accomplish this. Another example is updating the Type field from Prospect to Customer on the account object once an opportunity has been set to Closed Won. As you may notice, rules would need to be defined for each of these situations and at least in these examples, they are dependent on a value being present somewhere else before a correct value can be entered.
- Deduplication: This is a commonly faced business problem within organizations using Salesforce. This is because the nature of the CRM system is such that it has to have multiple data entry points into the system. Consider, for example, web-to-lead, marketing tools, and sales representatives uploading spreadsheets into the system, and the manual creation of records. All of these are distinct data channels into the system. Sometimes, even a single channel can cause duplication; for example, when a lead submits a web-to-lead form multiple times, this can create duplicate records in Salesforce. We mentioned earlier that if Salesforce record-level access security is not set up properly and the org is overly restricted, and a rep searches for an account and cannot find it in the system, they will create a new one, thereby establishing a duplicate. This is assuming that a record already exists in the system.
A key challenge with duplicated records is the numerous permutations that duplicate records could have, making it so much more difficult to correctly identify duplicates. For example, consider a contact record for John Smith with the address 123 Main St, Detroit MI, a second record for J Smith with the address Number 123 main street, Detroit Michigan, and a third one for John S with the address 123 Main st, unit 7, Michigan. Are these duplicates or different records? Reviewing the records carefully, we could safely conclude that these are duplicates, but how would you define rules so that when computer software reviews these records, it will correctly identify the duplicates? As this example shows, it can be quite challenging to correctly identify duplicate records, especially when the volume is in the hundreds of thousands of records.
One of the key functions of an MDM solution is to identify and resolve duplicate data as this is a critical step toward achieving a clean and trustworthy state for master records. This key function kicks in as soon as the data from different sources is consolidated in the MDM.
The first step in this process is to identify the duplicates, also referred to as matching. Typically, there are two ways in which this is done – a deterministic approach and a probabilistic approach:
a) Deterministic approach: In this approach, an exact match between data elements is sought and a score is assigned. This approach usually results in fewer matches. This is the ideal choice if unique values, such as Social Security number and social insurance number, are captured, but considering this is confidential data, customers are not willing to share them unless required. Therefore, the most commonly used fields include phone numbers, addresses, email addresses, and so on. This approach also introduces complexity as the number of data elements to match increases because that means requiring more matching rules. Excessive matching rules could result in performance degradation and a costly continuous cycle of maintenance.
b) Probabilistic approach: In this approach, matches are based on multiple criteria, such as phonetics, the likelihood of occurrence, and nuances. This approach uses weights to calculate the match score and employs thresholds to determine a match. This approach is more accurate in matching records. It is more suitable with a wider set of data elements that can be used for matching.
Once the record has been identified as a duplicate, the next step is to merge the duplicates to create the golden source, the single source of truth. The key challenge at this stage is which data elements from multiple records need to survive to form the Golden Record. This requires building some intelligence in the MDM tool to determine which elements should survive.
Key elements of an MDM program
It is crucial to understand that MDM is not a technological solution to a business problem. Although it will help, it won't solve all problems. This is a mindset that, if not recognized, can cause MDM projects to fail. The thinking that once we implement an MDM tool, all data problems will sort themselves out is just not realistic. A strong MDM program has key elements that must be implemented and adhered to, so the MDM investment of the organization continues to bear fruit and provide a high ROI.
The key elements of your MDM strategy should be the following:
- Governance: This is a set of directives that guide the organizational body, policies, principles, and qualities to promote access to accurate and consistent master data.
- Measurement: This involves setting key performance indicators (KPIs) to measure and continuously improve data.
- Organization: This defines the people and teams that will form data stewards, data owners, and those on governance committees.
- Policy: Requirements, policies, and procedures that the MDM program should adhere to.
- Technology: Selection, implementation, and management of the technology component of the MDM program.
Once an organization has defined what is considered master data, the next steps are to put an MDM program in place. The key steps in implementing an MDM program include the following:
- Identifying sources of master data: This step involves identifying all sources of master data. This is a critical step and should be thorough as, unsurprisingly, there may be multiple sources of master data, including in privately stored Excel spreadsheets, Word documents, and suchlike.
- Identifying producers and consumers of master data: This step involves understanding who produces the data and who its consumers are. Producers and consumers can be IT systems or humans.
- Analyzing metadata regarding your data: This step involves determining the attributes associated with the master data and what they mean. This can be an extensive step, especially if dispersed regions or business areas have different definitions of the data; for example, what defines a customer in the organization, or when does a new customer become an existing customer, because there could be processes associated with whether a customer is new or existing. Some of the attributes of master data that can be analyzed could include the following:
- Attribute name
- Data type
- Allowed values
- Constraints
- Default values
- Dependencies
- Data owner
- Appointing data stewards: These are people who ideally have a well-grounded understanding of the data and can assist in maintaining master data going forward.
- Implementing a data governance council: This group has the authority to make decisions on how the master data is maintained, what it contains, how long it is kept for, and how changes are authorized.
- Developing a master data model: This includes deciding on what the master data looks like, including its attributes, size, and data type, what values are allowed, and so on; for example, in a large heavy equipment dealership, the parts department preferred to use the part number to look up parts, whereas technicians preferred to use the old part number because they had it memorized even when a new part number had been issued that superseded the old one.
- Selecting the tool: This is where you would select a tool for data cleansing, transforming, and merging data. The tools will have support for finding data quality issues, such as duplicates and missing or incomplete data. Typically, these tools will have a versioning mechanism, too, to track the history of the changes on the master data.
- Creating and testing master data: Once you have selected a tool, the next step is to create the master data and test it. You want to start with a small subset of data and ensure that your rules are properly configured and that the resulting master dataset is indeed what is desired. Once you have established that the rules are configured properly and generating the desired data, you can start loading in the rest of the data.
Creating master data
There are two basic steps involved in creating master data:
- Cleaning and standardizing data: Before starting and cleansing data, you must understand the data model. You will have mapped each attribute from the master data to the source system. Some of the data cleansing functions include the following:
- Normalize data functions: Make sure that fields have the same data and consistent formatting; for example, a phone number has numbers only and no text.
- Replace missing values: Insert missing values, default values, and make use of services such as Dun & Bradstreet to fill in the gaps in your data.
- Standardize values: Convert measurements to an agreed-upon system, convert prices to a common corporate currency, and so on.
- Map attributes: Parse contact names into first and last names and move part # and part no to a Part Number field.
- Matching data: In this step, you match the data records to eliminate duplicates. This step requires a lot of analysis and consideration since you can inadvertently lose data; for example, John C King and John King, entirely different contacts in a person account setup, are considered to be the same and important historical data is lost.
The key is to match on more than one attribute and have an algorithm in place that calculates the likelihood of a record being the same as another record. When the match score is high and meets or exceeds the threshold, you can confidently say that the record is indeed a match.
In the next section, we will look at the different types of MDM implementation patterns, as well as their advantages and disadvantages.
Implementing MDM
In this section, we will look at how MDM can be implemented and the considerations for the different styles of MDM. Four implementation styles are used with MDM, mainly driven by whether the data is controlled from a central hub or the hub is synchronized from data sources. The reason this is important is that organizations need to have that single version of the truth. In an MDM implementation, the focus is on improving data quality, establishing data governance rules, and ensuring that data is easily managed and is available across businesses. The style you choose depends on the nature of your organization, business processes, and company goals:
- The registry style: This style assigns global unique identifiers to records in multiple systems that can then be used to define a single version of the truth. This system doesn't send data back to the source systems, so master data continues to be made through source systems. It matches and cleans the identifying cross-referenced data and relies on the source systems maintaining their own quality of the data. When a single version of the truth is needed, it uses a reference system to build a complete picture of the record. This style is useful when you have a large number of source systems and want to minimize disruption and significant changes in source systems. It is useful for situations where a read-only copy of the record is needed without the risk of overwriting any information in the source systems and avoids duplication of data in the MDM hub and source systems. It provides an efficient method to remove data duplicates and get a consistent view of your data.
Its low cost and relatively quick implementation, along with minimal changes to source systems, make it an attractive option. Here is a registry-style MDM depicted in a diagram:
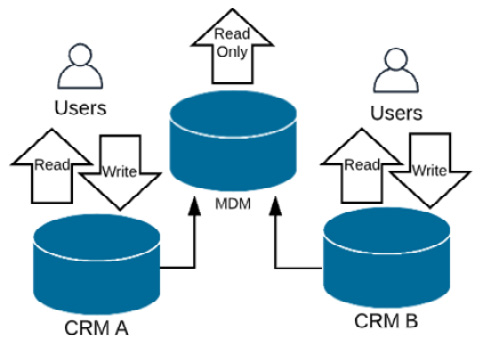
Figure 4.4 – Registry-style MDM implementation
Figure 4.4 shows data being read and written to each of the CRM by the users. The narrow arrows from the MDM into the CRMs depict the read operations that the MDM has to perform when a query is received.
The biggest benefit of this style is that minimal changes are required in source systems and therefore, it can be implemented in a relatively short timeframe.
- The consolidation style: In this style, data is consolidated from multiple systems into the central MDM hub. It is then transformed, cleansed, and matched, resulting in the single source of truth (Golden Record) that is then made available to downstream systems for use by other systems. This style is typically used for reporting and analytics. Here is what a consolidation-style implementation looks like:
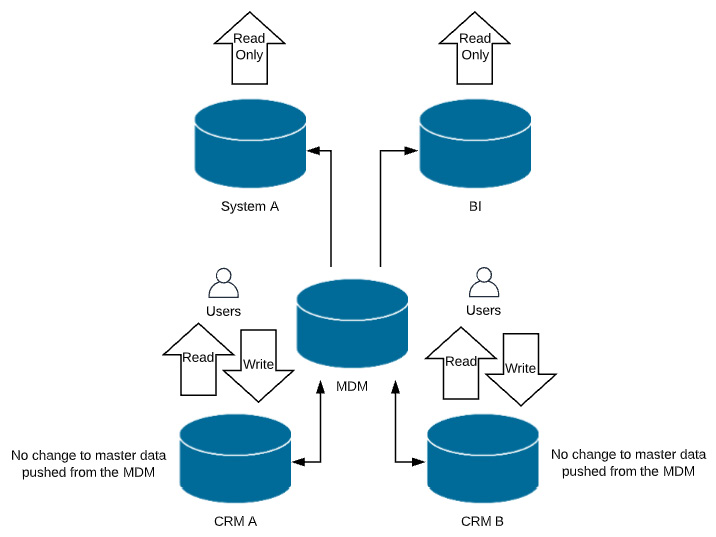
Figure 4.5 – Consolidation-style model
As seen in Figure 4.5, the MDM hub becomes the single source of truth for downstream systems. Any updates to the golden record are also written back to the source systems. However, source systems are not to manipulate that master data.
As the name suggests, this is a very involved process and requires data transformation, cleansing, and matching that requires extensive testing.
- The coexistence style: This implementation style is very similar to the consolidation style, but source systems are permitted to make changes to the master data. This means sending back the Golden Record to each source system, thereby enabling real-time synchronization between the MDM and source systems. The coexistence style is depicted in the following diagram:
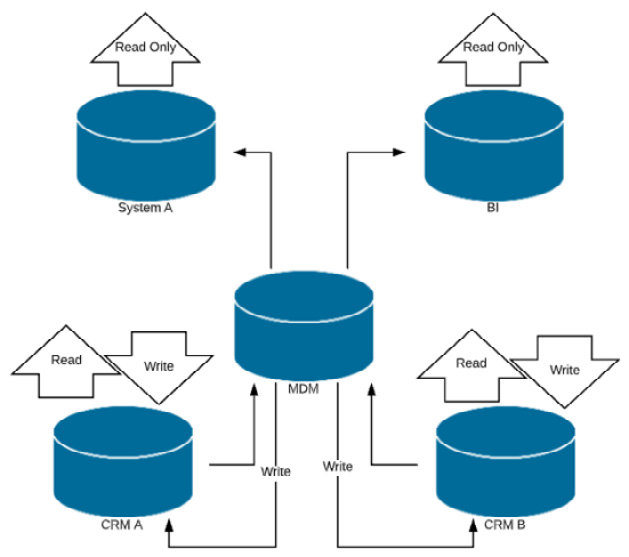
Figure 4.6 – Coexistence-style MDM implementation
As per Figure 4.6, this style is very similar to the consolidation-style implementation but this style allows the flexibility of making changes directly in the source systems.
In this style, the source systems are also updated alongside the MDM hub, which makes for consistent data across the systems. The downside is that any data errors will also get propagated throughout the system.
- The transactional/centralized hub implementation style: This is where the master data hub becomes the single source of truth and system of record and any system that needs access to the data must subscribe to the hub for up-to-date data. Systems other than the hub are not allowed to create or modify data. Rather, they get their up-to-date data from a single source, which is the hub. Implementing this style requires resources and time in order to be implemented because removing functionality so master data cannot be created in source systems can be costly and requires extensive testing:

Figure 4.7 – Centralized hub-style MDM implementation
This type of style provides more control and cleaner data since there is only one point of data entry, but it is costly to implement and reduces the benefits from other systems that could have been realized if data was directly entered into the respective system.
Whichever MDM implementation you choose, one of the most important things you can do is to thoroughly understand and define the business challenges you wish to solve with an MDM implementation. It's important to have a clear understanding of the end goal of where you want to be with MDM, as implementing the wrong style and backing out can be expensive and a frustrating experience.
Now that we have reviewed the different MDM implementation styles along with the advantages and disadvantages of each style, next, we will look at the considerations for selecting an MDM solution.
Considerations for selecting an MDM solution
There are so many MDM tools out there and selecting the best fit for your organization can seem like a daunting task. One of the key steps that I recommend is to spend the time and define in reasonable detail what the objectives are that you wish to achieve by implementing an MDM solution. A common problem is that companies will jump right into selecting an MDM solution while not truly understanding what business problem(s) they are trying to solve, how it fits with the organization's short- and long-term vision, and what the other projects on the roadmap are that could have a significant impact on the implementation of your MDM solution.
Make sure that you have your business requirements defined and prioritized, which will help you to evaluate a solution later on. This can really help you cut through the fluff of vendor demos and sales pitches and prevent what I call the bells and whistles pitfall, in which the solution selection committee gets sold on the nice-to-haves rather than the core functionality that will add real value to the business.
This pitfall is easily avoided by having a solution selection scorecard that has scores for each of the key functionalities required based on the prioritized business requirements. For example, an important criterion in the scorecard should be ease of maintenance, as well as supportability. You don't want a solution that takes extensive effort and a specialized skill set for seemingly small problems and, at the same time, consider the type of support that the vendor provides for the solution.
Here are some key functional and technical capabilities that I recommend when choosing an MDM solution:
- Integration connectors: It is very important that the solution supports out-of-the-box connectors to interface with different applications, including Salesforce, otherwise you may find yourself spending time building MDM interfaces. For example, does the solution have a connector to use with SAP using, in Salesforce terms, clicks, or does it require one to be coded from scratch?
- Deployment options: Some MDM solutions offer on-premises or cloud-based solutions only. Look for a vendor that can support both and that has them integrated. The reason is because of the nature of master data, companies are still reluctant to move their master data completely into the cloud and a hybrid approach may work well.
- Multiple domains: The solution should support multiple domains rather than just one or a few domains; for example, ascertain that the solution can support products, customers, locations, and other domains that have been identified as master data.
- Scalable solution: Understand how well the solution can scale both horizontally, meaning in terms of the nature of master data that can be supported, and vertically, and the volumes of data that the solution can support.
- Total Cost of Ownership (TCO): Drill down on what it would take to implement a select few use cases and then incrementally build the solution over time. Your objective should be to prove the value of MDM, which will help create buy-in and willingness on the part of stakeholders to see more use cases implemented. What sort of skills would be required to enhance the MDM implementation? Are these skills easy to find, or are they highly specialized and therefore costly?
- Licensing model: I cannot stress enough that this should be very well understood because some vendors charge more as your data grows, so ensure that you go through a sizing exercise before selecting a solution to understand what type of storage requirements you have. As your MDM footprint grows, how will your licensing be impacted, and are there any technical or contractual limitations that you need to be aware of?
- Technology roadmap: Understand the roadmap of the solution and where it is going in the next few years. Ensure that it aligns with your MDM strategy and your existing and future-state system landscape.
- Architectural model: As seen earlier, there are multiple topologies (co-existence, consolidation, registry, and so on) in which an MDM solution can be implemented. You want to ensure that your chosen solution can support different topologies rather than locking you into a specific topology. This gives your more maneuvering room to properly assess and select the topology that makes the most sense for your business. It also gives you the ability to leverage the tool in a new acquisition that may have similar complexity to your system's landscape.
- Supportability: Understand how the vendor supports its product. Given that MDMs form the backbone of business due to the critical services they provide, ask questions about Service-Level Agreements (SLAs) and details on past planned and unplanned downtimes for maintenance and patching. Check references from existing customers if possible and ask questions about what works and what's not working for them.
Now that we have looked at some of the criteria for choosing an MDM solution, in the next section, we will look at the Golden Record, why it's important, and some of its use cases.
The Golden Record
The Golden Record, sometimes referred to as the single customer view, is defined as that single data point that captures all the necessary information that we need to know regarding a data element. It is the most accurate source of truth that the organization has. For example, a customer record for Acme Inc. (a hypothetical company) may exist in multiple databases, and having that one record that is the most accurate and complete is what is sought after and desired in MDM.
A matching methodology based on business rules determines which record to keep and which ones to discard. Usually, three types of determining methods are used:
- Most recent: In this method, the record with the most recent date stamp is considered the most accurate and considered the Golden Record.
- Most frequent: This method defines that if the same information exists in more than one record, then that can be considered eligible as the survivor record.
- Most complete: This method considers field completeness as a criterion for the most viable record.
The problem with using these survivorship methodologies is that they are more reliant on superficial attributes of data rather than a solid understanding of the data.
For example, you could have two similar customer contact records and one is more recent than the other, but it has an invalid phone number. In this case, going with the most recent record will cause the Golden Record to have an invalid data element.
Another example is when, let's say, three customer contacts exist for the same contact and two are considered the most frequent because they have the same data elements. Assuming both have invalid phone numbers and the third record, which is considered infrequent but has a valid phone number, will cause the Golden Record to have an invalid phone number. These examples illustrate the importance of also using trusted, third-party data sources to validate and enrich your data.
Why is the Golden Record important?
Although we have looked at some examples earlier in the context of master data management, I want to look at another example here so we can understand the importance of the Golden Record. Suppose a customer, Tony Alex, went into an electronic store and purchased a gaming console. When paying for the device, they provided their name as T Alex, along with their address. Upon reaching home, they create an account on the store's website and register with their full name to receive updates and special offers from the store. Later, the store decides to mail a special holiday offer to Tony and because the store doesn't have the Golden Record, Tony receives two special holiday offers, one addressed to T Alex and the other to Tony Alex. Tony can only use one because the store policy requires the ID to be presented and only vouchers with names matching with the ID are accepted.
This is a simple example with only two input points that resulted in this discrepancy. What if Tony had also visited the website to access gated content and provided Tony A as their name? Then there would be three records in different databases, and what would we use to get to the single version of the truth? In this simplified example, we have a one-person record, but in a real-world scenario, we could be dealing with hundreds of thousands or millions of records. In this example, the business lost time and valuable resources that could have been put to good use somewhere else simply because the master data was not reliable.
So far, we have talked about the value of the Golden Record from a revenue perspective, but achieving that state and maintaining it where you have the single source of truth record is also important from a regulatory point of view. Policies such as the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) have some aspect of consumer access requests – it is the right of a consumer to request and receive full disclosure of all the data that the organization has pertaining to the consumer. This is simply not possible without having good master data management practices that lead to the Golden Record. Non-compliance with these regulations can result in heavy fines and penalties, thereby impacting the company's bottom line.
Detractors of the Golden Record
Although the Golden Record philosophy is widely accepted and implemented, the discussion around it wouldn't be complete if we didn't talk about an opposing view, which is that the pursuit of the Golden Record is not needed and that it's a flawed concept that needs to be revised. This is a theoretical discussion, but nonetheless valuable for consideration purposes. The premise of this argument is based on the foundation that there are closed and open Information Systems (ISes). Closed ISes are systems that organizations develop themselves or are responsible for maintaining, whereas open ISes are systems that are developed and maintained by independent vendors. Organizations today are moving from using closed systems to open systems, which means that data federation becomes challenging because the format, structure, and other characteristics of data are different. In addition to that, additional sources of unstructured data are emerging, such as digital sensors, social media, and IoT devices.
In a closed IS, the organization knows the data precisely, including the meaning of data entities, attributes, and their dependencies between different systems. Integrations are relatively easy to build because so much is known via the data model of each system. In other words, data can easily be interfaced and federated by leveraging the data model of integrating systems. Data federation refers to bringing data from diverse and distributed systems to a single data store while implementing a common data model.
Many organizations today rely on a combination of on-premises and cloud systems and have various types of master data, such as that pertaining to customers, vendors, and products, in various systems, leading to fragmented data stores. Of course, MDM tries to solve this problem by combining all this data in one place, de-duplicating, and removing any inconsistencies, but the issue of the growing number of systems that may be partially Systems of Record (SORs) also complicates these efforts. Furthermore, data federation also becomes challenging due to synchronous and asynchronous systems in the mix, or automated processes that run at different times, and may have an impact on data federation processes.
The other flaw pointed out with the Golden Record approach is that it assumes a single version of the truth for the record and leaves out the contextual information or the metadata of the record. This is because getting to the Golden Record involves matching and merging data records that may be essential to retaining the context of that data.
The argument is that the context is important and applicable for the business areas where the data was produced, but in an attempt to get to the Golden Record, which can then be used organization-wide, we are sacrificing that important context that was useful to those business silos in the organization. The other assumption of the Golden Record is that even though various systems may have different data models, it is possible to develop a single data model for sharing data. This idea of harmonizing data forms the backbone of the Golden Record philosophy.
The contrary view claims that the meaning of data is contextual and subject to changes over time. For example, a Golden Record for a customer in the MDM system exists, but does a customer refer to the person who made the purchase, the user of the product where the delivery was made, or who paid the bill? Because these could be three different persons. This context would exist in CRM and the Accounts Receivable (AR) system.
If the person who made the purchase and had it delivered to their address is the same, but the product user is different, in MDM you will see two records – one for the person who made the purchase or had it delivered to their address, because they would get matched and merged, and the other perhaps for the person who is the user but without any context in MDM.
Another example to clarify this is the use of medical data for patient diagnosis. Suppose patient data, including prescriptions, hospitalization records, vaccinations, allergies, and other self-reported data, such as physical exercise and temperature, is stored in a data store. It is then federated using the Golden Record philosophy to a downstream diagnostic assistance system that is used by medical providers to view past data and assist with diagnoses.
We can see that this could lead to a seriously flawed diagnosis because the doctor may see an average number for temperature readings without knowing what time the reading was taken, the condition of the patient when the reading was taken, and any activity performed before taking the reading, while other relevant contextual details may also be missing.
An important reality to always keep in mind is that customer interactions usually involve more than one domain. For example, when a business sells a product and signs a contract, the customer master data, along with the product as well as contracts (if considered master data) will be impacted. If it's a commission-based sale, employee (also master data) will be impacted as well because commissions need to be paid.
According to the detractors of the Golden Record, organizations have been attempting, with varying degrees of success, to implement MDM and get to the Golden Record and have had mixed success. This may be because of the desire to get to that one organizational view of the record rather than leverage data while keeping it within the context.
Fixing the flaws
The detractors of the Golden Record philosophy recommend considering all master data of a process or activity, rather than just the single domain, as in the customer record in the example in the Detractors of the Golden Record section. The proponents of this new framework advocate understanding the various meanings and links between data attributes. As a result, multiple interpretations/contexts of data are allowed and considered part of the global master data.
In this model, each system has its own master data registry, which preserves the context of the data within the application. A central MDM system has interoperable attributes with their corresponding metadata descriptions and when a change is detected in the master data of any federated system, the MDM populates the data using the known metadata and attributes.
Keep in mind that the foundation for this approach is still rooted in MDM, but improves on the current Golden Record philosophy that is in widespread use today. Its claim that data may have several different contextually dependent meanings rather than one metadata description at any given time (which is what the Golden Record is based on) has weight and can open up doors to view and report on data through various contexts. Here is a depiction of what this would look like in a practical setting:

Figure 4.8 – Fixing the flaws in traditional MDM architecture
In the next section, we will look at the linkage between MDM and CRM, the challenges with CRMs, and how some of these challenges can be mitigated using MDM. We will also briefly touch on the challenges that organizations face when implementing MDM solutions in the cloud.
MDM and CRM strategy
The MDM and CRM strategy should be considered hand in hand because CRM is typically the entry point for customer data. Large companies also have multiple CRMs and there is usually an overlap of customer data within these systems. There is also the need to manage customer hierarchies and typical CRMs are not optimized to manage hierarchies.
Some of the specific challenges include the following:
- Multiple versions of the truth with no rules for matching and merging. As mentioned, CRMs are not optimized for hierarchy management and multiple records for a customer in a CRM system with no standardized hierarchies makes reporting a challenge.
- With mergers and acquisitions (M&A), multiple copies of customer records can exist in many CRMs, resulting in multiple versions of the truth with no rules for matching and merging, nor a clear identification of the source of specific data elements.
- Multiple systems of record also result in the duplication of data without identifying the correct version, and when this data flows down to downstream systems, it can impact business decision making, customer engagement, and retention.
- Incorrect data also results in non-standardized data where a customer may be identified with an industry, let's say manufacturing, in one system, and because a small portion of their business is retail, retail in another system.
Having an MDM implemented can address some of these deficiencies in CRM by providing consolidated and trusted customer data, the much sought-after Golden Record. It can improve the overall data quality and provide an easy mechanism to manage customer hierarchies.
We should acknowledge that due to the nature of master data and how it forms the backbone of a business, some organizations are reluctant to implement cloud-based MDM solutions due to data privacy concerns, the perceived lack of control of data, and concerns regarding the security of cloud-based solutions. Salesforce Customer 360 addresses some of these concerns, which we will review in the next section.
Customer 360
You may have noticed that the organizational structure of enterprises is often reflected in the way digital transformation is talked about and implemented. Everyone realizes the need to keep pace with the changing business and regulatory environment and transform their business to stay competitive. However, at the time of implementation, for example, a division selling large mining trucks will implement its own quoting solution when there was already a solution that was used by the construction division. The rationale may be that the construction business is so different from the mining business that it requires its own quoting solution. With more and more organizations realizing the importance of business and enterprise architecture, we may see fewer of these types of scenarios playing out, but nonetheless, they remain a reality and present good examples of how silos are formed and ultimately reflected in digital products that a company creates.
This siloing of IT systems leads to multiple databases and applications and the disparate use of technologies, which makes it challenging to get a single most accurate view of the customer. You may ask why this is important, especially when companies have been generating profits operating like this for so many decades. The answer is that as the marketplace becomes more competitive, it's not enough to merely sell a product/service and deliver it. Customers are demanding more, and they expect more, and world-class companies are delivering on these expectations. Customers are looking for an experience along with the product/service they are to receive. That customer experience cannot be fully provided unless companies understand the customer's journey, and the multiple touchpoints with their digital or physical assets. In summary, not having a complete view of the customer will hinder this goal.
How can this view be achieved? It requires connecting your sales, service, marketing, supply chain, commerce, and other systems, but that is easier said than done because these systems sometimes use propriety data models, which makes them hard to integrate, or use technology that is old and doesn't facilitate easy integration. The goal of building that single view of the customer has been around for a long time but has not been easy to achieve due to the reasons we discussed previously in this section. Salesforce's Customer 360 promises to achieve that goal by implementing the Cloud Information Model (CIM), but more on the model later. First, let's understand what makes up Customer 360. It is a set of tools and services that enables customers to deliver intelligent and highly personalized customer service.
Customer 360 consists of four elements:
- Customer 360 Data Manager: This is the key component that allows companies to connect and provide a single source of truth of customer records across Salesforce and other enterprise systems. It does this by creating a single universal Salesforce ID that is used to represent a customer. This allows companies to provide a personalized experience to the customer and, internally, allows companies to get that unique insight into customer behavior through Salesforce Einstein.
- Salesforce Identity for Customers: This component allows companies to provide a uniform, consistent login experience to their customers. Rather than customers requiring multiple passwords to log in and access different company assets, such as mobile apps, websites, and e-commerce sites, customers can use one login with multi-factor authentication enabled and securely access these resources.
- Customer 360 Audiences: This creates multiple customer profiles across website visits, first-party IDs, emails, and suchlike, and allows companies to create customer journeys and gain AI-driven insights. First-party IDs are IDs associated with first-party cookies. First-party cookies are cookies (small text files) that are placed on a user's device when they visit the site. First-party cookies are different to third-party cookies in that first-party cookies can only be placed by the website host you are visiting. For example, if you visit google.com, it can place cookies on your device but youtube.com cannot. First-party cookies are generally considered more privacy-safe.
- Salesforce Privacy and Data Governance: This allows companies to collect and enforce their systems' customer privacy preferences. Part of this is also the data classification label that can now be applied to fields in Salesforce. This helps companies to ensure that they are compliant with privacy laws.
Common Information Model (CIM)
CIM is an open source data model that standardizes data interoperability between systems. It is a data model that allows data sources with different formats and structures to be connected. It forms the backbone on which Customer 360 is architected. When data sources are connected to Customer 360, data, in essence, is mapped from those sources to a canonical data model.
Canonical Data Model (CDM): This is a data model that can contain all the data from different data models that source systems may have; for example, let's say we have MS Dynamics, SAP, and Salesforce in our systems landscape. All three will have their own way of storing data and in a CDM, we will be able to bring this data, translate it, store it, and easily map it back to the source systems. Therefore, in our preceding example, we will be able to bring in the data from MS Dynamics, SAP, and Salesforce, making it available for other systems to consume that data easily without having to do their own transformation or translation.
Data lakes
Typically, when you are storing data in a data store, you have to structure it in a certain format. Data lakes are data stores that don't require data to be stored in any strict format and allow users to store structure as well as unstructured data.
In Salesforce, the CIM is exposed to the platform so you can run SOQL queries against it, build triggers, or create Lightning Web Components (LWCs). The strength of Customer 360 lies in the fact that there is no need to move massive amounts of data into a data lake; rather, the use of a unique reference back to the source allows the data to remain in place. This also means that there is no need to make a change to the source systems to accommodate integrations.
Summary
We started off with the basics and reviewed master data and its importance in any organization, whether small or large. We reviewed the different types of data, especially comparing master data and reference data in the context of Salesforce. When most people talk about master data, they are usually referring to both these categories under the master data umbrella. We discussed at length what data is master data and the business problems that it helps us to solve. This should have provided you with an appreciation of why adequate resources and time should be spent in identifying master data with a solid plan to manage it properly for smooth and ongoing business operations.
We discussed Master Data Management (MDM), starting with its definition to establish a baseline understanding of the term, and then briefly discussed how an MDM program can be implemented. The discussion around different styles of implementing MDM provided a good understanding of which style would be appropriate for your organization, followed by a discussion of the criteria when choosing an MDM solution. We also discussed the Golden Record, its importance, and what the detractors of the Golden Record philosophy argue. This should have provided a balanced approach to the Golden Record when discussing it, keeping in mind its benefits and the perceived disadvantages that you can mitigate when implementing an MDM solution.
Lastly, we discussed the new offering from Salesforce called Customer 360 and its components. Customer 360 is Salesforce's attempt to provide a solution to master data issues that organizations face today, but it doesn't stop there. It takes it a step further and brings the customer into the conversation, too, by attempting to provide a unified login experience to the customer via Salesforce Identity for Customers and ensuring that customer data is properly governed and that requests from customers regarding their data that the organization possesses can be properly addressed via the Salesforce Privacy and Data Governance component of Customer 360.
In the next chapter, we will discuss data governance for enterprises and privacy acts such as the GDPR and the CCPA, along with discussing ways in which to assess our current state from a data governance perspective.
Questions
- Precision Printers (PP) has multiple CRMs in each region and has decided to implement an MDM system to consolidate records and arrive at the Golden Record. The project team has decided to use survivorship rules for selecting the record that would need to be kept during the merge operation. What do the data architect and the project team need to consider in this scenario?
a) The team must define multiple survivorship rules, one for each system, to arrive at the Golden Record.
b) Survivorship rules cannot be used for this scenario because they are not intended for duplicate management.
c) The project team needs to define the specific criteria that can be used to arrive at the Golden Record.
d) The project team needs to set up probabilistic rules to determine the Golden Record.
- Alpha Big Box Inc. has multiple systems, each of which has been determined to be the system of record, having a portion of the master data related to accounts and contacts, in other words, data is entered or updated, and for those specific data points, the system where these data points are updated is considered as the system of record. A CRM is being transitioned to Salesforce that is defined as the source of truth for accounts and contacts going forward. An MDM has also been recently implemented that is now pulling data from Salesforce.
Users are finding that some records in the MDM have blank or incorrect values, such as Test Contact. What could be the root cause of the problem? (Choose two answers):
a) Test data generated during User Acceptance Testing (UAT) in Salesforce still exists and has not been removed.
b) The project team should turn off the MDM interfaces immediately, remove all the data from the MDM, and restart the integrations all over again.
c) All the data has not yet been migrated to Salesforce and it has been prematurely defined as the system of record for accounts and contacts, causing the MDM to pull in those specific fields for some records.
d) Only one system should always be the system of record; this configuration is invalid and the source of this problem.
- Koolio Box Inc. is a consumer goods retailer that operates on a B2C model. It has 20 million person account records in Salesforce and the number is growing by 5% each year. Koolio's management is concerned that these are not unique records and, due to a number of data entry channels, such as web-to-case, web-to-lead, and outbound marketing efforts, the situation is going to get worse if nothing is done on a priority basis. They have hired a data architect to recommend a solution. What should the data architect recommend?
a) Hire several interns and have them manually sift through the records in Excel and determine duplicate records. Delete those records from the system.
b) Develop a custom solution that uses APIs and Lightning Web Components (LWCs) to assist in determining potential duplicates based on a limited number of criteria, for example, email and phone number.
c) Use an AppExchange package to clean up the existing data and leverage it to ensure data quality on an ongoing basis.
d) Use Dun & Bradstreet (D&B) services to clean up the data.