
Chapter 1
Workings of the Web
What You’ll Learn in This Chapter:
![]() A Short History of the Internet
A Short History of the Internet
![]() The World Wide Web
The World Wide Web
![]() Introducing HTTP
Introducing HTTP
![]() The HTTP Request and Response
The HTTP Request and Response
![]() HTML Forms
HTML Forms
We have a lot of ground to cover in this book, so let’s get to it. We’ll begin by reviewing in this chapter what the World Wide Web is and where it came from. Afterward we’ll take a look at some of the major components that make it work, especially the HTTP protocol used to request and deliver web pages.
A Short History of the Internet
In the late 1950s, the U.S. government formed the Advanced Research Projects Agency (ARPA). This was largely a response to the Russian success in launching the Sputnik satellite and employed some of the country’s top scientific intellects in research work with U.S. military applications.
During the 1960s, the agency created a decentralized computer network known as ARPAnet. This embryonic network initially linked four computers located at the University of California at Los Angeles, Stanford Research Institute, the University of California at Santa Barbara, and the University of Utah, with more nodes added in the early 1970s.
The network had initially been designed using the then-new technology of packet switching and was intended as a communication system that would remain functional even if some nodes should be destroyed by a nuclear attack.
Email was implemented in 1972, closely followed by the telnet protocol for logging on to remote computers and the File Transfer Protocol (FTP), enabling file transfer between computers.
This developing network was enhanced further in subsequent years with improvements to many facets of its protocols and tools. However, it was not until 1989 when Tim Berners-Lee and his colleagues at the European particle physics laboratory CERN (Conseil Europeen pour le Recherche Nucleaire) proposed the concept of linking documents with hypertext that the now familiar World Wide Web began to take shape. The year 1993 saw the introduction of Mosaic, the first graphical web browser and forerunner of the famous Netscape Navigator.
The use of hypertext pages and hyperlinks helped to define the page-based interface model that we still regard as the norm for web applications today.
The World Wide Web
The World Wide Web operates using a client/server networking principle. When you enter the URL (the web address) of a web page into your browser and click on “Go,” you ask the browser to make an HTTP request of the particular computer having that address. On receiving this request, that computer returns (“serves”) the required page to you in a form that your browser can interpret and display. Figure 1.1 illustrates this relationship. In the case of the Internet, of course, the server and client computers may be located anywhere in the world.
Figure 1.1 How web servers and clients (browsers) interact.
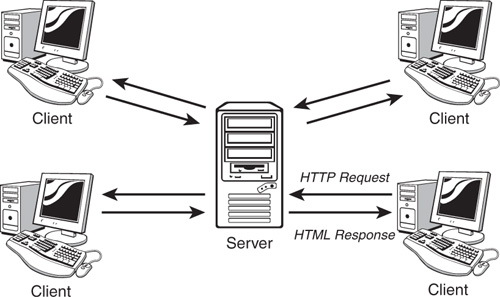
Later we’ll discuss the nlisitty-gritty of HTTP requests in more detail. For now, suffice it to say that your HTTP request contains several pieces of information needed so that your page may be correctly identified and served to you, including the following:
![]() The domain at which the page is stored (for example, mydomain.com)
The domain at which the page is stored (for example, mydomain.com)
![]() The name of the page (This is the name of a file in the web server’s file system—for example, mypage.html.)
The name of the page (This is the name of a file in the web server’s file system—for example, mypage.html.)
![]() The names and values of any parameters that you want to send with your request
The names and values of any parameters that you want to send with your request
What Is a Web Page?
Anyone with some experience using the World Wide Web will be familiar with the term web page. The traditional user interface for websites involves the visitor navigating among a series of connected pages each containing text, images, and so forth, much like the pages of a magazine.
Generally speaking, each web page is actually a separate file on the server. The collection of individual pages constituting a website is managed by a program called a web server.
Web Servers
A web server is a program that interprets HTTP requests and delivers the appropriate web page in a form that your browser can understand. Many examples are available, most running under either UNIX/Linux operating systems or under some version of Microsoft Windows.
![]()
The term web server is often used in popular speech to refer to both the web server program—such as Apache—and the computer on which it runs.
Perhaps the best-known server application is the Apache Web Server from the Apache Software Foundation (http://www.apache.org), an open source project used to serve millions of websites around the world (see Figure 1.2).
Another example is Microsoft’s IIS (Internet Information Services), often used on host computers running the Microsoft Windows operating system.
![]()
Not all Windows-based web hosts use IIS. Various other web servers are available for Windows, including a version of the popular Apache Web Server.
Figure 1.2 The Apache Software Foundation home page at http://www.apache.org/ displayed in Internet Explorer.

Server-Side Programming
Server-side programs, scripts, or languages, refer to programs that run on the server computer. Many languages and tools are available for server-side programming, including PHP, Java, and ASP (the latter being available only on servers running the Microsoft Windows operating system). Sophisticated server setups often also include databases of information that can be addressed by server-side scripts.
![]()
Server-side programming in this book is carried out using the popular PHP scripting language, which is flexible, is easy to use, and can be run on nearly all servers. Ajax, however, can function equally well with any server-side scripting language.
The purposes of such scripts are many and various. In general, however, they all are designed to preprocess a web page before it is returned to you. By this we mean that some or all of the page content will have been modified to suit the context of your request—perhaps to display train times to a particular destination and on a specific date, or to show only those products from a catalog that match your stated hobbies and interests.
In this way server-side scripting allows web pages to be served with rich and varied content that would be beyond the scope of any design using only static pages—that is, pages with fixed content.
Web Browsers
A web browser is a program on a web surfer’s computer that is used to interpret and display web pages. The first graphical web browser, Mosaic, eventually developed into the famous range of browsers produced by Netscape.
![]()
By graphical web browser we mean one that can display not only the text elements of an HTML document but also images and colors. Typically, such browsers have a point-and-click interface using a mouse or similar pointing device. |
There also exist text-based web browsers, the best known of which is Lynx (http://lynx.browser.org/), which display HTML pages on character-based displays such as terminals, terminal emulators, and operating systems with command-line interfaces such as DOS. |
The Netscape series of browsers, once the most successful available, were eventually joined by Microsoft’s Internet Explorer offering, which subsequently went on to dominate the market.
Recent competitive efforts, though, have introduced a wide range of competing browser products including Opera, Safari, Konqueror, and especially Mozilla’s Firefox, an open source web browser that has recently gained an enthusiastic following (see Figure 1.3).
Browsers are readily available for many computer operating systems, including the various versions of Microsoft Windows, UNIX/Linux, and Macintosh, as well as for other computing devices ranging from mobile telephones to PDAs (Personal Digital Assistants) and pocket computers.
Figure 1.3 The Firefox browser from Mozilla.org browsing the Firefox Project home page.

Client-Side Programming
We have already discussed how server scripts can improve your web experience by offering pages that contain rich and varied content created at the server and inserted into the page before it is sent to you.
Client-side programming, on the other hand, happens not at the server but right inside the user’s browser after the page has been received. Such scripts allow you to carry out many tasks relating to the data in the received page, including performing calculations, changing display colors and styles, checking the validity of user input, and much more.
Nearly all browsers support some version or other of a client-side scripting language called JavaScript, which is an integral part of Ajax and is the language we’ll be using in this book for client-side programming.
DNS—The Domain Name Service
Every computer connected to the Internet has a unique numerical address (called an IP address) assigned to it. However, when you want to view a particular website in your browser, you don’t generally want to type in a series of numbers—you want to use the domain name of the site in question. After all, it’s much easier to remember www.somedomain.com than something like 198.105.232.4.
When you request a web page by its domain name, your Internet service provider submits that domain name to a DNS server, which tries to look up the database entry associated with the name and obtain the corresponding IP address. If it’s successful, you are connected to the site; otherwise, you receive an error.
The many DNS servers around the Internet are connected together into a network that constantly updates itself as changes are made. When DNS information for a website changes, the revised address information is propagated throughout the DNS servers of the entire Internet, typically within about 24 hours.
Introducing HTTP
Various protocols are used for communication over the World Wide Web, perhaps the most important being HTTP, the protocol that is also fundamental to Ajax applications.
When you request a web page by typing its address into your web browser, that request is sent using HTTP. The browser is an HTTP client, and the web page server is (unsurprisingly) an HTTP server.
In essence, HTTP defines a set of rules regarding how messages and other data should be formatted and exchanged between servers and browsers.
![]()
For a detailed account of HTTP, Sams Publishing offers the HTTP Developer’s Handbook by Chris Shiflett.
The HTTP Request and Response
The HTTP protocol can be likened to a conversation based on a series of questions and answers, which we refer to respectively as HTTP requests and HTTP responses.
The contents of HTTP requests and responses are easy to read and understand, being near to plain English in their syntax.
This section examines the structure of these requests and responses, along with a few examples of the sorts of data they may contain.
The HTTP Request
After opening a connection to the intended server, the HTTP client transmits a request in the following format:
![]() An opening line
An opening line
![]() Optionally, a number of header lines
Optionally, a number of header lines
![]() A blank line
A blank line
![]() Optionally, a message body
Optionally, a message body
The opening line is generally split into three parts; the name of the method, the path to the required server resource, and the HTTP version being used. A typical opening line might read:
GET /sams/testpage.html HTTP/1.0
In this line we are telling the server that we are sending an HTTP request of type GET (explained more fully in the next section), we are sending this using HTTP version 1.0, and the server resource we require (including its local path) is
/sams/testpage.html.
![]()
In this example the server resource we seek is on our own server, so we have quoted a relative path. It could of course be on another server elsewhere, in which case the server resource would include the full URL.
Header lines are used to send information about the request, or about the data being sent in the message body. One parameter and value pair is sent per line, the parameter and value being separated by a colon. Here’s an example:
User-Agent: [name of program sending request]
For instance, Internet Explorer v5.5 offers something like the following:
User-agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)
A further example of a common request header is the Accept: header, which states what sort(s) of information will be found acceptable as a response from the server:
Accept: text/plain, text/html
By issuing the header in the preceding example, the request is informing the server that the sending application can accept either plain text or HTML responses (that is, it is not equipped to deal with, say, an audio or video file) .
![]()
HTTP request methods include POST, GET, PUT, DELETE, and HEAD. By far the most interesting for the purposes of this book are the GET and POST requests. The PUT, DELETE, and HEAD requests are not covered here.
The HTTP Response
In answer to such a request, the server typically issues an HTTP response, the first line of which is often referred to as the status line. In that line the server echoes the HTTP version and gives a response status code (which is a three-digit integer) and a short message known as a reason phrase. Here’s an example HTTP response:
HTTP/1.0 200 OK
The response status code and reason phrase are essentially intended as machine-and human-readable versions of the same message, though the reason phrase may actually vary a little from server to server. Table 1.1 lists some examples of common status codes and reason phrases. The first digit of the status code usually gives some clue about the nature of the message:
![]() 1**—Information
1**—Information
![]() 2**—Success
2**—Success
![]() 3**—Redirected
3**—Redirected
![]() 4**—Client error
4**—Client error
![]() 5**—Server error
5**—Server error
Table 1.1 Some Commonly Encountered HTTP Response Status Codes

![]()
A detailed list of status codes is maintained by the World Wide Web Consortium, W3C, and is available at http://www.w3.org/Protocols/rfc2616/ rfc2616-sec10.html.
The response may also contain header lines each containing a header and value pair similar to those of the HTTP request but generally containing information about the server and/or the resource being returned:
Server: Apache/1.3.22
Last-Modified: Fri, 24 Dec 1999 13:33:59 GMT
HTML Forms
Web pages often contain fields where you can enter information. Examples include select boxes, check boxes, and fields where you can type information. Table 1.2 lists some popular HTML form tags.
Table 1.2 Some Common HTML Form Tags

After you have completed the form you are usually invited to submit it, using an appropriately labeled button or other page element.
At this point, the HTML form constructs and sends an HTTP request from the user-entered data. The form can use either the GET or POST request type, as specified in the method attribute of the <form> tag.
GET and POST Requests
Occasionally you may hear it said that the difference between GET and POST requests is that GET requests are just for GETting (that is, retrieving) data, whereas POST requests can have many uses, such as uploading data, sending mail, and so on.
Although there may be some merit in this rule of thumb, it’s instructive to consider the differences between these two HTTP requests in terms of how they are constructed.
A GET request encodes the message it sends into a query string, which is appended to the URL of the server resource. A POST request, on the other hand, sends its message in the message body of the request. What actually happens at this point is that the entered data is encoded and sent, via an HTTP request, to the URL declared in the action attribute of the form, where the submitted data will be processed in some way.
Whether the HTTP request is of type GET or POST and the URL to which the form is sent are both determined in the HTML markup of the form. Let’s look at the HTML code of a typical form:
<form action=”http://www.sometargetdomain.com/somepage.htm” method=”post”>
Your Surname: <input type=”text” size=”50” name=”surname” />
<br />
<input type=”submit” value=”Send” />
</form>
This snippet of code, when embedded in a web page, produces the simple form shown in Figure 1.4.
Let’s take a look at the code, line by line. First, we begin the form by using the <form> tag, and in this example we give the tag two attributes. The action attribute determines the URL to which the submitted form will be sent. This may be to another page on the same server and described by a relative path, or to a remote domain, as in the code behind the form in Figure 1.4.
Next we find the attribute method, which determines whether we want the data to be submitted with a GET or a POST request.
Figure 1.4 A simple HTML form.

Now suppose that we completed the form by entering the value Ballard into the surname field. On submitting the form by clicking the Send button, we are taken to http://www.sometargetdomain.com/somepage.htm, where the submitted data will be processed—perhaps adding the surname to a database, for example.
The variable surname (the name attribute given to the Your Surname input field) and its value (the data we entered in that field) will also have been sent to this destination page, encoded into the body of the POST request and invisible to users.
Now suppose that the first line of the form code reads as follows:
<form action=”http://www.sometargetdomain.com/somepage.htm” method=”get”>
On using the form, we would still be taken to the same destination, and the same variable and its value would also be transmitted. This time, however, the form would construct and send a GET request containing the data from the form. Looking at the address bar of the browser, after successfully submitting the form, we would find that it now contains:
http://www.example.com/page.htm?surname=Ballard
Here we can see how the parameter and its value have been appended to the URL. If the form had contained further input fields, the values entered in those fields would also have been appended to the URL as parameter=value pairs, with each pair separated by an & character. Here’s an example in which we assume that the form has a further text input field called firstname:
http://www.example.com/page.htm?surname=Ballard&firstname=Phil
Some characters, such as spaces and various punctuation marks, are not allowed to be transmitted in their original form. The HTML form encodes these characters into a form that can be transmitted correctly. An equivalent process decodes these values at the receiving page before processing them, thus making the encoding/decoding operation essentially invisible to the user. We can, however, see what this encoding looks like by making a GET request and examining the URL constructed in doing so.
Suppose that instead of the surname field in our form we have a fullname field that asks for the full name of the user and encodes that information into a GET request. Then, after submitting the form, we might see the following URL in the browser:
http://www.example.com/page.htm?fullname=Phil+Ballard
Here the space in the name has been replaced by the + character; the decoding process at the receiving end removes this character and replaces the space.
![]()
In many cases, you may use either the POST or GET method for your form submissions and achieve essentially identical results. The difference becomes important, however, when you learn how to construct server calls in Ajax applications.
The XMLHTTPRequest object at the heart of all Ajax applications uses HTTP to make requests of the server and receive responses. The content of these HTTP requests are essentially identical to those generated when an HTML form is submitted.
Summary
This chapter reviewed the history and architecture of the World Wide Web, and covered some basics of server requests and responses using the HTTP protocol.
In particular, we discussed how GET and POST requests are constructed, and how they are used in HTML forms. Additionally, we saw some examples of responses to these requests that we might receive from the server.