
Chapter 1. Internet of Things (IoT)
This chapter provides a general overview of the Internet of Things (IoT). We will cover the data-driven computing paradigm and associated architectures, desired quality attributes of an IoT platform, and evaluation criteria for IoT platforms. In addition, we’ll examine a comparative case study showing the transformative power of the IoT (in this case, in the smart grid domain).
Introduction to IoT
What does it mean to be driven by data? Data-driven business and engineering solutions are becoming the norm in our modern society. Only a couple of centuries ago, counting and calculation (a synonym for computing at that time) were done manually, just as data-gathering efforts were. This manual labor had obvious scalability issues. The appearance of a difference engine (an automatic mechanical calculator) in the 19th century heralded a new age from the point of view of computing.1 The early attempts to build viable mechanical automata ran into serious problems, and the mechanical approach was abandoned in the favor of an electrical variant. In both cases the principal goal was to boost the computing power. Computing is meaningless without data; thus, data must be somehow coupled with computing nodes. The recent advancements in communication technologies, especially the emergence of the internet, enabled data to emanate from everywhere. This significantly pushed our attention toward distributed solutions for reasons of performance, scalability, dependability, and data storage capacity.2 Nevertheless, the confinement of computing power inside large data centers cannot alone handle ever-increasing data volume. The network would become a clear bottleneck for data movement scenarios of such magnitude. Pervasive computing (a.k.a. ubiquitous computing) tries to disseminate computational capability into end devices, which are frequently sources of data, too. The notion of performing computation everywhere, preferably near data (this is also related to edge computing), opens novel data-processing possibilities. The desire to encompass as much data as possible drives our thinking toward ingenious scalable solutions.
It is easy to apprehend the truism that more data means bigger potential to discover new facts and expand knowledge. Naturally, the abundance of data demands more complex and performant computations. The overarching goal is to gain a competitive advantage either in research or business. Figure 1-1 shows an indefinite data-driven computing cycle, where data denotes raw ingredients, and computation represents a goal-oriented activity to synthetize higher level inferences.
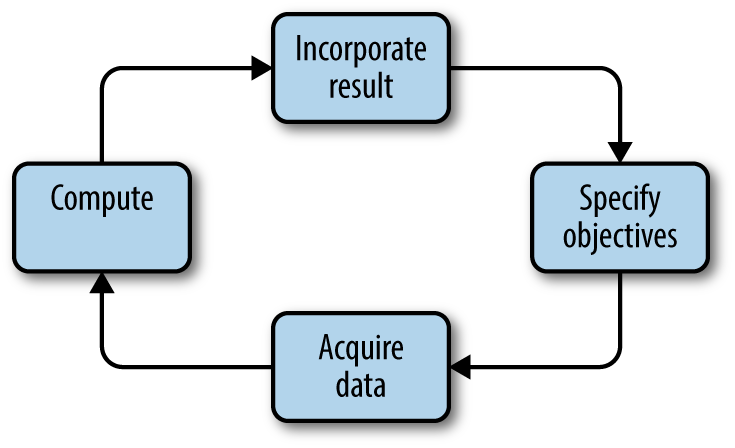
Figure 1-1. Data-driven inference cycle
Let’s review each phase of the cycle shown in Figure 1-1:
- Specify objectives
-
Data collection and handling must be based on use cases. It cannot happen by chance just by listening on any conceivable data source, and piling up records. The data should have a clear purpose that gives meaning to the associated computation. This planning phase can be carried out either by a human, or a machine governed by artificial intelligence.
- Acquire data
-
Data gathering shall be economical from the viewpoint of both resources and time. Moreover, it must be technically feasible, resulting in data of proper quality. The data acquisition endeavor must also include an analysis of required data transformations, propose a viable data serialization format, and specify the necessary communication channels/protocols. Many of these aspects should be considered during the previous planning phase, as a kind of feasibility study.
- Compute
-
This is the data-crunching activity, where various programs are run against the collected data. The set of programs may include reporting tools, machine learning facilities, data transformation pipelines, and the like. The outcome is usually a new set of data that properly encodes the synthetized knowledge.
- Incorporate result
-
The new knowledge, gained by doing the previous computation, should trigger appropriate actions, and give rise to plans with possibly elevated expectations. This is the final phase before a new cycle begins, bootstrapped by the results of the one before it.
The following well-known axioms are fundamental in every data mining work:
-
With great power comes great responsibility.
-
Correlation does not mean causation.
The aim of empowering the data-driven inference cycle is to reap benefits by discovering patterns in data. These patterns usually indicate some significant relationships between entities/events represented by data. Executing extensive data analysis operations without being aware of the dangers of early conclusions may induce more harm than advantages. There are ample examples on the internet of how things may go wrong (some of the most embarrassing mistakes were even made by data scientists). For example, if you find a correlation between shoe sizes and intelligence, then it doesn’t imply that a person with bigger feet is smarter than a person with smaller ones. In this case, age as a latent variable is missing from the model. You can find more information in Practical Statistics for Data Scientists by Andrew Bruce and Peter Bruce (O’Reilly).
The Architecture of a Data-Driven Solution
The architecture plays a central role in any data-driven software system. The architecture bundles together pertinent quality attributes of the system,3 and allows reasoning about the system before building it. As data-driven computing tackles innovative technologies it is important to bring in technological considerations early in the architecture. One viable approach to craft a proper architecture of this type may revolve around Architecture Tradeoff Analysis Method (ATAM) 3.0. ATAM 3.0 combines an analysis of both quality characteristics and technology. This is explained in detail in Designing Software Architectures: A Practical Approach by Rick Kazman and Humberto Cervantes (Addison-Wesley).
The IoT embraces devices, connectivity, data acquisition/processing platforms, and custom applications to realize the data-driven computing paradigm. Edge computing is a strategy that delivers computing near data instead of moving everything into a central location (usually a cloud-based data center). Figure 1-2 depicts the module decomposition view of a typical data-driven solution. For a good introduction into IoT, with many examples of vertical segments benefitting from IoT, consult IoT Fundamentals: Networking Technologies, Protocols, and Use Cases for the Internet of Things by David Hanes et al. (Cisco Press).
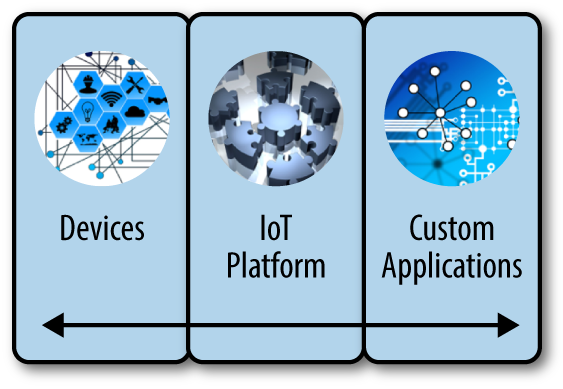
Figure 1-2. The three-tiered conceptual model of a data-driven system. This nicely illustrates the device handling (left side) and service enablement (right side) functions of an IoT platform.
The bidirectional arrow in Figure 1-2 signifies the communication paths between tiers and marks the level of achieved computational distribution. If the edge is on the far left, then it entails autonomous, smart devices (like smartphones) with decent computing power to run complex applications. In converse, the devices are dumb data sources with intermediary hubs passing data in both directions to/from applications. This situation is reminiscent of a desktop database application (for example, implemented in Microsoft Access) with a remote database file lurking on a file server. A regular query would instigate needless data transfers over the network; this approach cannot scale.
A device may take the following three roles in a combined fashion: data source, data processor, and data sink. Devices could run in an isolated fashion, or connect with peers forming a dynamic mesh network. A group of devices can constitute a swarm, where each member acts according to both the global objective, and the action/state of its neighbors.4
An IoT platform is primarily responsible for composing the data segment, and computing that segment into a unified element. The IoT platform may execute on-premises, and/or in the cloud. The principal responsibilities of the platform are as follows:
-
Provides communication bindings with devices
-
Implements the rules engine for data segmentation and response processing
-
Stores temporary and permanent data
-
Executes various analytics, and generates reports
-
Exposes service APIs for management, supervision, interoperability, and custom application development
The rules engine may employ a domain-specific language to express condition→action relations. The rules may be predefined, or self-managed through machine learning mechanisms. Rules may also govern input data classification and routing; events (messages) arriving on various communication channels may have different priorities, meaning, and response timeliness.
Multiple IoT platforms could be interlinked for data sharing purposes. Applications built on top of such interconnected IoT platforms may combine data from different domains, and leverage data affinities. The case study we’ll examine at the end of this chapter exemplifies the benefits of interoperation of IoT platforms.
A custom IoT application that uses the publicized services of an IoT platform may focus on business use cases instead of dealing with device management and raw data handling. Applications are segregated into verticals, each concerned with the matching domain (smart grid, healthcare, autonomous vehicles, agriculture, etc.). It is important to remember that the same data channel could participate in multiple verticals at the same time. For example, weather forecast data is useful in many realms. Furthermore, the same device can deliver different data for a multitude of verticals. A smartphone can be a data source for many healthcare functions5 while executing other disparate IoT-related applications in parallel.
Figure 1-2 is a logical view of a data-driven system, since multiple deployments are possible. For example, a powerful device may host an IoT platform to perform locally as much data processing as possible. It is also conceivable to bundle together an IoT platform with applications on the same computer. However, the crucial point is pertaining to efficient interconnectedness of components both logically and physically. The deployment scenario must support this ambition. The merit is perhaps best codified in a variant of Metcalfe’s law, which states that the value of such a networked solution is proportional to the square of its connected elements.
Currently, there are two IoT-specific formal development methods, both of which stress the importance of architecture: Ignite and IoT Methodology. You may read more about Ignite in Enterprise IoT: Strategies and Best Practices for Connected Products and Services by Dirk Slama et al. (O’Reilly). The IoT Methodology introduces the IoT OSI reference model. It is comprised of five layers (the IP hourglass model has only four6). These layers are device, connectivity, middleware, services, and applications. The three middle layers are mainly embodied by the IoT platform (see Figure 1-2). For a description of how to reuse practices from various methods through essentialization, refer to Is There a Single Method for the Internet of Things? by Ivar Jacobson et al. (Communications of the ACM).
Desired Quality Attributes of an IoT Platform
To avoid confusion regarding the word quality, we will use Steve McConnell’s practical and succinct definition: “Conformance to requirements, stated and implied.” The second part of the definition addresses potential requirements errors; thus, quality isn’t only about adhering to specified stuff, nor is a narrow view toward functional requirements. The focus here is on important product7 non-functional requirements embodied by an architecture of the data-driven system. These quality characteristics are known as -illities, although there are exceptions, like performance.
The quality model cannot be expressed by simply including all non-functional requirements. Some quality attributes support each other, and others are in opposition. A canonical example for the latter is security and usability. Table 1-1 gives a sample of the trade-off matrix for some common quality attributes relevant for IoT platforms. The double-sided arrow designates a typically supporting pair, while the cross sign marks a typically conflicting combination (empty cells mean indifference). Adaptability and usability are user visible; the rest are internally visible. Efficiency belongs to both categories.
Adaptability |
|||||
Portability |
↔ |
Portability. |
|||
Usability |
↔ |
Usability |
|||
Security |
❌ |
❌ |
❌ |
Security |
|
Safety |
↔ |
Safety |
|||
Efficiency |
❌ |
❌ |
❌ |
❌ |
Instead of just declaring the significant attributes of an IoT platform, it is important to study the reasons behind the selection. Our starting point is performance as a function of throughput and latency. Throughput is a generic indicator pertaining to the amount of data handled per unit of time. Eliminating redundant data movements surely benefits throughput; the same is true for data processing speed. Latency becomes critical in real-time IoT systems, where the law of physics (speed of light) also kick in. This parameter dictates the responsiveness of the data-driven architecture, and can be related to the length of a feedback loop (i.e., the round-trip time between the device and application). For a good overview, consult Responsive Data Architecture for the Internet of Things by David Linthicum (IEEE Computer).
Figure 1-3 shows how applying the principles of edge computing reduces data response times (the segments referred to on the picture are data and compute). As the computation moves toward the source of data, there is less latency between event (message) generation and handling. This reaction time is especially crucial in real-time systems, where late responses are useless (for the sake of simplicity, further classification into hard and soft real-time systems is skipped).

Figure 1-3. The liaison between the distance of segments, and latency
The computation in this case is represented by facilities offered by an IoT platform. The intelligence built into the device complements the features available in the IoT platform. The following list shows those high-priority quality attributes that buttress the deployment of an IoT platform in multiple places:
- Portability
-
The IoT platform must be portable if it is destined to heterogeneous nodes. This may be achieved by leveraging virtualization technologies (for example, by using the Java Virtual Machine), or packing the deliverable into host operating system oblivious form (like the Docker image).
- Adaptability
-
To support an extensive list of devices, and provide more service APIs for integration purposes, it is mandatory to have an adaptable IoT platform. The possible usage scenarios are vast, and cannot be predetermined in advance.
- Usability
-
To reduce the deployment hassle, and quickly get users up and running with an IoT platform, it must be in a user-friendly form in multiple aspects. This includes the management, supervision, and reporting facilities.
- Efficiency
-
The IoT platform should ideally have a small footprint, employ advanced data storage technologies, and require adequate hardware resources to be usable in both real time and regular contexts. To move the computation near devices it should run on less capable hardware (for example, inside a smart meter or smartphone).
- Safety
-
The IoT platform should never do something it isn’t supposed to do. The principal game changer regarding software in the domain of IoT is safety coupled with accountability and responsibility. Any applied automation through an IoT solution means that we have faith in the system and trust that it will never do harm in the environment.
- Security
-
The IoT platform must ensure proper device management (via authentication and authorization mechanisms), data privacy, integrity, and confidentiality via secure communication and encryption of data. Security is especially crucial for an IoT platform, as it will rely more on automated security.
Additionally, an IoT platform must be highly available, and maintainable (includes the testability property). All these attributes should be balanced against the intended usage, and incorporated into the architecture. The chapters that follow describe some concrete IoT platforms that balance these quality characteristics in different ways.
Universal Device Communication Protocols
IoT is predominantly about devices and their data. This section gives a briefing about some wide-ranging device communication protocols (peculiar edge protocols—such as BACnet, DLMS/COSEM, OSLP, Modbus, etc.—are omitted):
- HTTP
-
The protocol of the web. Many devices are directly or indirectly accessible via SOAP or REST; indirection relies on intermediaries, like the Echelon SmartServer.
- WebSocket
-
Enables bidirectional communication between parties over a single TCP connection. The primary objective is to eliminate the client’s need to open multiple HTTP connections toward the server.
- Message Queuing Telemetry Transport (MQTT)
-
This is a lightweight publish/subscribe messaging protocol.
- Constrained Application Protocol (CoAP)
-
A specialized web transfer protocol for use with constrained nodes and unreliable networks. It mimics the REST API for small devices.
It is also possible to extend the set of fieldbus protocols to include non-IP variants. Such extension is plausible in supporting legacy devices, and for those that cannot afford to implement a full-blown IP stack. You may read about an interesting proposal, based upon the chirp device data stream format, in Rethinking the Internet of Things: A Scalable Approach to Connecting Everything by Francis daCosta (Apress). Another possibility is to leverage IoT-customized IP variants, like IPv6 with the LoWPAN adaptation layer.
Key communication patterns
Most machine-to-machine (M2M) protocols support request/response and publish/subscribe communication modes. Knowing when to use them is essential to achieve proper reaction times, increase dependability, and improve performance.
The request/response mechanism requires an established channel between parties. It may be used for individualized information exchanges (such as asking the central node for a security key, or retrieving “personalized” schedules from the coordinator node). The request/response mode isn’t plausible when some condition (event) must trigger dozens of devices to execute an action. In this case, there are two general choices (both suffer from scalability issues, and introduce a single point of failure):
-
Let the initiating device loop over its device list, and send the matching command to each device.
-
Send the event to the central node, and let it notify relevant devices in sequence.
The publish/subscribe pattern is inherently decentralized. Figure 1-4 shows a sequence of actions that accompany this mechanism. The publish/subscribe mode creates fast, local action loops that don’t swamp the central node. Moreover, a triggering device doesn’t need to maintain a separate device list for each event. The protocol layer is optimized to manage the device network; thus it can efficiently handle registrations and notifications.
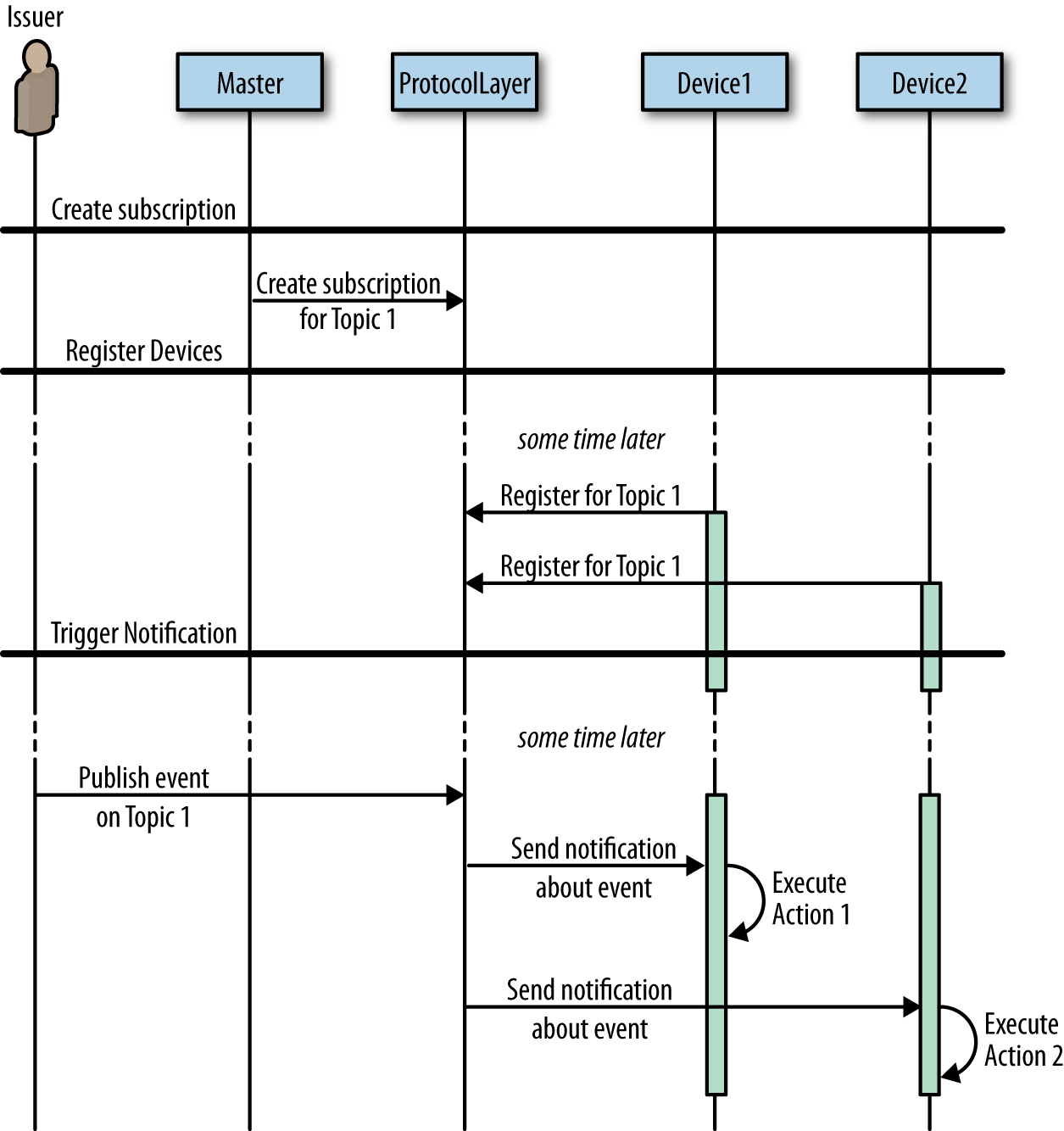
Figure 1-4. UML sequence diagram illustrating the pub/sub pattern
Evaluation Criteria for IoT Platforms
Besides the previously enumerated quality attributes, there should be well-defined IoT platform evaluation criteria for comparison purposes. The next set of traits include both functional and non-functional aspects. Security is separately emphasized, because of its importance (it is a subcategory of dependability). Each subsequent chapter concludes with concrete values for these properties, in relation to the corresponding IoT platform:
- Device bindings
-
This specifies the supported communication protocols of an IoT platform regarding devices (for example, HTTP, MQTT, etc.).
- Analytics
-
The type of technology used to perform analytical calculations. Analytics is the mechanism to synthetize higher-level knowledge from raw data. Rules may be associated with such derived values. For more information, you may read Internet of Things and Data Analytics Handbook by Hwaiyu Geng (Wiley).
- Visualization
-
This defines the offered technologies for data visualization (for example, an HTML5-based UI dashboard).
- Rules engine and alarming
-
Elaborates how rules and alarms are defined on top of accumulated data. The ability to easily customize conditions to trigger alarms, and rules to associate actions with events, is of utmost significance. Hardcoding these (or using similarly rigid constructs) isn’t an option. Domain-specific languages are an attractive choice here.
- Security
-
The set of supported security technologies by an IoT platform. This covers securing device–platform, platform–platform, and platform–application communication channels, controlling access to data via authentication/authorization, and so on. For an excellent treatment of IoT security, consult Abusing the Internet of Things by Nitesh Dhanjani (O’Reilly), as well as The Internet of Risky Things by Sean Smith (O’Reilly).
- License
-
This defines the type of license attached to the IoT platform (like Apache 2.0), and whether an IoT platform is freely available or not.
- Deployment technology
-
Describes the applied deployment technology (for example, Web archive, Docker image, operating system dependent package manager file, etc.).
- Auto-scaling
-
Enrolls the set of technologies and techniques that allows scaling of an IoT platform. This aspect is tightly related to availability. If an internal service or component becomes unresponsive, then such a condition must be auto-detected and acted upon (typically by summoning a new instance to preserve the desired capacity). Obviously, keeping the determined number of services up also improves availability.
- Device data persistence
-
Defines what database technologies (or other data storage mechanisms) are used by an IoT platform to store raw device data.
- Management database
-
Defines what database technologies (or other data storage mechanisms) are used by an IoT platform to store management-related data, including derived values.
- Implementation language
-
Specifies the main implementation programming language for an IoT platform (for example, Go, Java, etc.).
- Data model
-
Describes the event (message) format for communicating with devices (like Sensor Markup Language).
Active Load Control Case Study
The smart grid (one of the research areas of the authors) is an undoubted vertical domain that benefits from IoT. This case study gives a compelling insight into how IoT may transform the electrical power system. More specifically, the following topics are exemplified:
-
The centralized, top-down, and rigid non-IoT solution, and the problems engendered by following this approach
-
The tiered, bottom-up, and flexible IoT solution, and the associated benefits
-
The idea behind IoT distributed intelligence, and hierarchical control loops
-
The power behind efficient IoT analytics
-
IoT’s stratified architectural style, and the potential extensions enabled by such design
-
Multidomain applications that leverage IoT interoperability
Warning
Due to space limitations, the text here contains gross simplifications; the goal is to err on the side of accuracy to bring forward the essential points in a straightforward manner. For a broader overview of IoT case studies and protocols (including an extensive treatment of the smart grid), refer to The Internet of Things: Key Applications and Protocols by Olivier Hersent et al. (Wiley).
Electricity consumption is represented by a load profile (LP). It is a pattern of electricity usage for a customer, or a group of customers, over some period. Usually LPs are created daily with 15-minute resolution (mirroring the consumption measurement sampling period). Each LP is tightly linked to its context (a.k.a. as the load condition), which characterizes the matching period (for example, price of electricity, power network condition, season, etc.). Individual LPs may be aggregated; this is how a region’s behavior is estimated. The accrued historical power usage data, in the form of LPs, is used for short-term and long-term planning purposes. The aim is to keep production in sync with demand. Any serious disbalance may endanger the stability of the power grid.
Balancing production with demand is a function of available power generator types. For example, it is quite expensive to follow huge variations in demand with thermal power stations. On the other hand, renewable energy sources (like wind and solar) are of lower capability and volatile. Therefore, it is desirable to smooth out fluctuations in load by influencing the consumption. This can be done by switching on/off the appliances according to some logic. Figure 1-5 shows a good (conceived) and bad LP from the viewpoint of harmonizing production with demand. It also illustrates an allowable range of alterations of the actual LP from the devised one. Peaks are especially troublesome; thus, most control actions target them first.

Figure 1-5. Load control and planning based upon LPs
Non-IoT Traditional Grid
In a traditional power grid, the basic idea is to drive only the most influential appliances (water heater, electric heater with thermal accumulation, air conditioning unit, etc.) via predefined schedules. A schedule contains instructions on when to turn on/off the specific sort of appliance throughout a day. Appliances cannot be individually modeled (for reasons that will become apparent from the equations we’ll look at momentarily), hence they are grouped by type. The aspiration is to shape the actual LPs to conform with the planned ones.
An effectual load management initiative must include flexible pricing, too. Balancing the power grid alone cannot justify the required investments, as the profit margins would be negligible for most stakeholders. Nonetheless, extending the model to discuss dynamic pricing would make it overly complex.
The management of the power grid is organized in a federated fashion, as depicted in Figure 1-6; there are multiple levels of planning and control. The global load control management (LMC) is dealing with countrywide strategic activities. The distribution LMC is handling state (region)-wide tasks. Finally, the local LMC is covering some municipal area. Each level coordinates the execution of its subordinate entities. The control flow is from top to bottom, while status feedback flows upward. Each level does possess some autonomy, but pricing and generation facilities are treated on the top. Moreover, below LLMC everything runs in passive mode (we disregard any local controller inside an appliance, like a thermostat).

Figure 1-6. Hierarchical load control management
The active load control job can be formulated as a linear programming problem using the following set of expressions:8

The meaning of the variables are as follows:
- Pp
-
The unknown peak load after applying control actions
- u
-
The index of the appliance type (there are n different types of appliances)
- j(u)
-
The index of the schedule type for the kind of appliance denoted by u
- k(u)
-
The total number of control schemes for appliances of type u
- A
-
The effect of applying control on appliances of type u at interval i using scheme j(u)
- x
-
The variable number of appliances of type u that should be controlled by scheme j(u)
- di
-
The load at interval i after applying control actions
- di*
-
The desired load at interval i
- ?
-
The uniformly allowed distance between achieved and planned load
- i
-
Index of the interval (there are 96 15-minute intervals per day)
- M(u)
-
The number of appliances of type u
An additional concern is how to model each appliance type. Appliances capable of accumulating energy tend to consume a lot of power (for a short period) after being switched on again. This must be considered to avoid excessive peaks. This phenomenon is illustrated in Figure 1-7. All in all, averaging the behavior of all appliances of a given type, under some generic scheme, introduces additional inaccuracy in the planning process.

Figure 1-7. The outcome of turning on an appliance that stores energy
We can formulate the following conclusions about this non-IoT scenario:
-
Control is unidirectional (from a utility company toward customers), although it may leverage some mechanism to remotely command appliances.
-
Appliances are modeled using crude approximations.
-
It is hard to optimally cope with unpredictable production that is introduced by alternative energy sources.
-
The method has serious scalability deficiencies, as the sheer number of appliances may easily render the linear programming approach inapt.9
-
Integration with other vertical domains can only occur at the nearest LMCs, which are far away from end users.
-
There is no way to establish autonomous, local electricity markets with real-time pricing.
-
Planning and control must involve humans; it isn’t possible to have entirely machine-to-machine (M2M) use cases.
IoT-Enabled Smart Grid
Perhaps the best way to highlight the crucial differences is to reformulate the previous list in light of an IoT-driven grid:
-
Planning and control is obeying the context; it is based on actual power usage data fully considering current load conditions.
-
The behavior of appliances is inferred, rather than modeled beforehand, using local historical data via the analytics module of an IoT platform.
-
It is manageable to optimally cope with irregular production; for example, a smart house may administer its generation capabilities autonomously, and align it with local consumption.
-
The method has no inherent scalability deficiencies, as the processing is distributed, and happens near data.
-
Integration with other vertical domains can occur at any level.
-
It is possible to establish autonomous, local electricity markets with real-time pricing.
-
Planning and control don’t solely rely on humans; it is possible to have M2M use cases.
The feedback control loops are hierarchically arranged, and resemble the tree structure shown in Figure 1-6; the boxes there should be substituted in the following manner: LLMC→smart house, DLMC→microgrid, and GLMS→smart grid. The main point is that the intelligence is distributed, and upper layers send hints to subordinate elements regarding how to behave. But the lower layers don’t passively wait for commands. They act according to the local conditions. In some way, the IoT decommissions the command-and-control management of the power grid in favor of a more cooperative and flexible style.
A smart house may store excessive energy (usually gained through solar panels) in electric vehicles. This accumulated power can be utilized when prices are high, or to compensate for a sudden increase in load without pulling power from the neighborhood. It is also possible to establish dynamic energy markets inside a microgrid. The smart meters may negotiate the energy exchange circumstances alone. There is an interesting initiative to leverage blockchain technology to record such transactions. For more information, refer to Energy Trading for Fun and Profit by Morgen E. Peck and David Wagman (IEEE Spectrum).
It is also possible to coordinate electricity and gas consumptions by establishing data exchanges between vertical domains. The electricity and gas smart meters may communicate price information to evaluate and control the spending of various energy types to reduce expenses. The weather forecast data (another domain) may help in predicting future energy demands; a smart meter may decide that it is now better to keep the stored energy instead of pumping it back into the grid.
An excellent example of a completely integrated multidomain IoT solution is known as the smart city. It is oriented toward tracking and coordinating consumption of various resources (like electricity, gas, water, etc.), monitoring traffic conditions, alerting about environmental hazards, and more. The goal is to use disparate sources of information to align individual behavior with the interests of all benefactors. It is a well-known fact from the tragedy of the commons economic theory that purely local optimizations may negatively impact the group.
Open Smart Grid Plaform
The Open Smart Grid Platform (OSGP) is a freely available Java-based IoT platform for the smart grid. It provides a set of SOAP-based web services (each service’s API is specified in WSDL), that cover the major business areas of a smart grid. These APIs are leveraged by custom applications, shielding them from device handling responsibilities. The following domains are exposed by the platform:
- Admin
-
The platform’s core and admin functions for device management (includes the device authorization facility).
- Smart lighting
-
Controls, monitors, and manages street lights. It integrates light sensor data with scheduling policies, and monitors power consumption.
- Tariff switching
-
Allows tariff switching.
- Microgrids
-
Monitors and controls microgrids.
- Distribution automation
-
Controls and monitors substations (health status, power quality data, etc.).
- Smart metering
-
Reads and manages smart meters (smart meter installation, firmware updates, smart meter removal, read smart meter values, time synchronization, etc.).
OSGP is comprised of the following layers:
-
Web service
-
Business logic
-
Core
-
Protocol
-
Device
The protocol layer implements device bindings; the following communication protocols are supported: OSLP, DLMS/COSEM, and IEC 61850. The device layer isn’t part of the OSGP per se; any node with an IP connection may connect to the platform as a device.
Summary
The IoT revolves around structured and mesh device and IoT platform networks to deliver functions that are greater in scope than the sum of its parts (reflecting each element’s capability separately). The constituent technologies cannot be admired as sensational or revolutionary. Most of them have existed for quite a long time. Nonetheless, their judicious assembly into a unified whole radiates with supremacy. The vast possibilities offered by the IoT are still only beginning to be exploited.
This chapter barely scratches the surface of this topic, and instead offers easily digestible learning material about the IoT. It is sprinkled with references for your own continuous study. The power grid comparative case study illuminates how IoT profoundly changes the scene; it realizes concepts and ideas that were inconceivable in the past. The following chapters briefly introduce some popular IoT platforms to make the IoT exposition even more pragmatic and comprehensible.
There are many further variations on the theme of the IoT. For example, the application of advanced web technologies (such as linked data and the semantic web) on top of the IoT is called the WoT. It additionally boosts the IoT’s integrability and interoperability possibilities by letting the machines themselves figure out the meaning of events (messages). You can read more about WoT in Building the Web of Things with Examples in Node.js and Raspberry Pi by Dominique D. Guinard and Vlad M. Trifa (Manning).
A related development in enhancing M2M interoperations is the semantic sensor network. It benefits devices by increasing their ability to create ad hoc mesh networks. For more information, you should read the Internet of Things: From Internet-Scale Sensing to Smart Services by Dimitrios Georgakopoulos and Prem Prakash Jayaraman (Computing, Springer).
In the following chapters of this report, you will find descriptions of concrete IoT platforms that will make this general introduction more tangible. We will elaborate on two commercial cloud-centric products (with proprietary edge extensions), an open source sustainable and unified IoT platform (it can execute on the edge, on premises, and in the cloud), and a special edge component (which aims to standardize the edge of the network). Each of the subsequent chapters will include practical instructions to become productive with the corresponding IoT product.
1 Let us disregard some ancient calculators, like abacuses, to make the discussion more focused.
2 Moore’s law isn’t sustainable anymore, because of physical limitations of electronic circuits. The industry solution is provided in the form of parallelism revolving around multiple processing units (multicore CPUs, GPUs, computing clusters, etc.) that obey Amdahl’s law.
3 For an overview, consult the ISO/IEC 25010 standard quality model.
4 A swarm may be controlled via the swarm programming technique. You can try out the freely available Buzz programming language designed for robot swarms. It supports both bottom-up and top-down approaches of swarm programming, depending on whether the focus is on individual robots, or on the group.
5 An interesting IoT use case from the healthcare sector is published in A Software Shrink: Apps and Wearables Could Usher in an Era of Digital Psychiatry by John Torous (IEEE Spectrum). The idea is to use an IoT platform inside a smart house to control the inner environment, depending on the patient’s physical condition. The input is provided by a smartphone. For example, ambient light may turn off during periods of sleep, or an emergency call could be initiated in case of a serious health situation requiring immediate treatment.
6 In this model, the IP sits in the middle, with a multitude of link layer protocols below it, and different transport and application protocols above it. Such an arrangement is visually evocative of an hourglass.
7 There are also project characteristics (such as predictability, repeatability, visibility), but these are not relevant when analyzing the development processes of data-driven solutions.
8 There is a substantial nerd factor in this section, but you surely don’t need to understand the equations to comprehend the material. These are put here only for illustration purposes, to signify the amount of hassle associated with fixed, centralized load control management.
9 It is possible to leverage an iterative interior point primal-dual algorithm (like Karmarkar’s), but this may only shift the limits by some modest amount.