
Chapter 5. Administration
Whereas the last chapter covered working with MongoDB from an application developer’s standpoint, this chapter covers some more operational aspects of running a cluster. Once you have a cluster up and running, how do you know what’s going on?
Using the Shell
As with a single instance of MongoDB, most administration on a cluster can be done through the mongo shell.
Getting a Summary
db.printShardingStatus() is
your executive summary. It gathers all the important information about
your cluster and presents it nicely for you.
> db.printShardingStatus()
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shard0000", "host" : "ubuntu:27017" }
{ "_id" : "shard0001", "host" : "ubuntu:27018" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test", "partitioned" : true, "primary" : "shard0000" }
test.foo chunks:
shard0001 15
shard0000 16
{ "_id" : { $minKey : 1 } } -->> { "_id" : 0 } on : shard1 { "t" : 2, "i" : 0 }
{ "_id" : 0 } -->> { "_id" : 15074 } on : shard1 { "t" : 3, "i" : 0 }
{ "_id" : 15074 } -->> { "_id" : 30282 } on : shard1 { "t" : 4, "i" : 0 }
{ "_id" : 30282 } -->> { "_id" : 44946 } on : shard1 { "t" : 5, "i" : 0 }
{ "_id" : 44946 } -->> { "_id" : 59467 } on : shard1 { "t" : 7, "i" : 0 }
{ "_id" : 59467 } -->> { "_id" : 73838 } on : shard1 { "t" : 8, "i" : 0 }
... some lines omitted ...
{ "_id" : 412949 } -->> { "_id" : 426349 } on : shard1 { "t" : 6, "i" : 4 }
{ "_id" : 426349 } -->> { "_id" : 457636 } on : shard1 { "t" : 7, "i" : 2 }
37
{ "_id" : 457636 } -->> { "_id" : 471683 } on : shard1 { "t" : 7, "i" : 4 }
{ "_id" : 471683 } -->> { "_id" : 486547 } on : shard1 { "t" : 7, "i" : 6 }
{ "_id" : 486547 } -->> { "_id" : { $maxKey : 1 } } on : shard1 { "t" : 7, "i" : 7 }db.printShardingStatus() prints
a list of all of your shards and databases. Each sharded collection has
an entry (there’s only one sharded collection here, test.foo). It shows you how chunks are
distributed (15 chunks on shard0001
and 16 chunks on shard0000). Then it
gives detailed information about each chunk: its range—e.g., { "_id" : 115882 } -->> { "_id" : 130403
} corresponding to _ids in
[115882, 130403)—and what shard it’s on. It also
gives the major and minor version of the chunk, which you don’t have to
worry about.
Each database created has a primary shard that is its “home base.” In this case, the test database was randomly assigned shard0000 as its home. This doesn’t really mean anything—shard0001 ended up with more chunks than shard0000! This field should never matter to you, so you can ignore it. If you remove a shard and some database has its “home” there, that database’s home will automatically be moved to a shard that’s still in the cluster.
db.printShardingStatus() can
get really long when you have a big collection, as it lists every chunk
on every shard. If you have a large cluster, you can dive in and get
more precise information, but this is a good, simple overview when
you’re starting out.
The config Collections
mongos forward your requests to the appropriate shard—except for when you query the config database. Accessing the config database patches you through to the config servers, and it is where you can find all the cluster’s configuration information. If you do have a collection with hundreds or thousands of chunks, it’s worth it to learn about the contents of the config database so you can query for specific info, instead of getting a summary of your entire setup.
Let’s take a look at the config database. Assuming you have a cluster set up, you should see these collections:
> use config switched to db config > show collections changelog chunks collections databases lockpings locks mongos settings shards system.indexes version
Many of the collections are just accounting for what’s in the cluster:
- config.mongos
A list of all mongos processes, past and present
> db.mongos.find() { "_id" : "ubuntu:10000", "ping" : ISODate("2011-01-08T10:11:23"), "up" : 0 } { "_id" : "ubuntu:10000", "ping" : ISODate("2011-01-08T10:11:23"), "up" : 20 } { "_id" : "ubuntu:10000", "ping" : ISODate("2011-01-08T10:11:23"), "up" : 1 }_id is the hostname of the mongos. ping is the last time the config server pinged it. up is whether it thinks the mongos is up or not. If you bring up a mongos, even if it’s just for a few seconds, it will be added to this list and will never disappear. It doesn’t really matter, it’s not like you’re going to be bringing up millions of mongos servers, but it’s something to be aware of so you don’t get confused if you look at the list.
- config.shards
All the shards in the cluster
- config.databases
All the databases, sharded and non-sharded
- config.collections
All the sharded collections
- config.chunks
All the chunks in the cluster
config.settings contains (theoretically) tweakable settings that depend on the database version. Currently, config.settings allows you to change the chunk size (but don’t!) and turn off the balancer, which you usually shouldn’t need to do. You can change these settings by running an update. For example, to turn off the balancer:
> db.settings.update({"_id" : "balancer"}, {"$set" : {"stopped" : true }}, true)If it’s in the middle of a balancing round, it won’t turn off until the current balancing has finished.
The only other collection that might be of interest is the config.changelog collection. It is a very detailed log of every split and migrate that happens. You can use it to retrace the steps that got your cluster to whatever its current configuration is. Usually it is more detail than you need, though.
“I Want to Do X, Who Do I Connect To?”
If you want to do any sort of normal reads, writes, or administration, the answer is always “a mongos.” It can be any mongos (remember that they’re stateless), but it’s always a mongos—not a shard, not a config server.
You might connect to a config server or a shard if you’re trying to do something unusual. This might be looking at a shard’s data directly or manually editing a messed up configuration. For example, you’ll have to connect directly to a shard to change a replica set configuration.
Remember that config servers and shards are just normal mongods; anything you know how to do on a mongod you can do on a config server or shard. However, in the normal course of operation, you should almost never have to connect to them. All normal operations should go through mongos.
Monitoring
Monitoring is crucially important when you have a cluster. All of the advice for monitoring a single node applies when monitoring many nodes, so make sure you have read the documentation on monitoring.
Don’t forget that your network becomes more of a factor when you have multiple machines. If a server says that it can’t reach another server, investigate the possibility that the network between two has gone down.
If possible, leave a shell connected to your cluster. Making a connection requires MongoDB to briefly give the connection a lock, which can be a problem for debugging. Say a server is acting funny, so you fire up a shell to look at it. Unfortunately, the mongod is stuck in a write lock, so the shell will sit there forever trying to acquire the lock and never finish connecting. To be on the safe side, leave a shell open.
mongostat
mongostat is the most comprehensive monitoring available. It gives you tons of information about what’s going on with a server, from load to page faulting to number of connections open.
If you’re running a cluster, you can start up a separate mongostat for every server, but you can also run mongostat --discover on a mongos and it will figure out every member of the cluster and display their stats.
For example, if we start up a cluster using the simple-setup.py script described in Chapter 4, it will find all the mongos processes and all of the shards:
$ mongostat --discover
mapped vsize res faults locked % idx miss % conn time repl
localhost:27017 0m 105m 3m 0 0 0 2 22:59:50 RTR
localhost:30001 80m 175m 5m 0 0 0 3 22:59:50
localhost:30002 0m 95m 5m 0 0 0 3 22:59:50
localhost:30003 0m 95m 5m 0 0 0 3 22:59:50
localhost:27017 0m 105m 3m 0 0 0 2 22:59:51 RTR
localhost:30001 80m 175m 5m 0 0 0 3 22:59:51
localhost:30002 0m 95m 5m 0 0 0 3 22:59:51
localhost:30003 0m 95m 5m 0 0 0 3 22:59:51 I’ve simplified the output and removed a number of columns because I’m limited to 80 characters per line and mongostat goes a good 166 characters wide. Also, the spacing is a little funky because the tool starts with “normal” mongostat spacing, figures out what the rest of the cluster is, and adds a couple more fields: qr|qw and ar|aw. These fields show how many connections are queued for reads and writes and how many are actively reading and writing.
The Web Admin Interface
If you’re using replica sets for shards, make sure you start them
with the --rest option. The web admin interface for
replica sets (http://localhost:28017/_replSet, if
mongod is running on port 27017)
gives you loads of information.
Backups
Taking backups on a running cluster turns out to be a difficult problem. Data is constantly being added and removed by the application, as usual, but it’s also being moved around by the balancer. If you take a dump of a shard today and restore it tomorrow, you may have the same documents in two places or end up missing some documents altogether (see Figure 5-1).
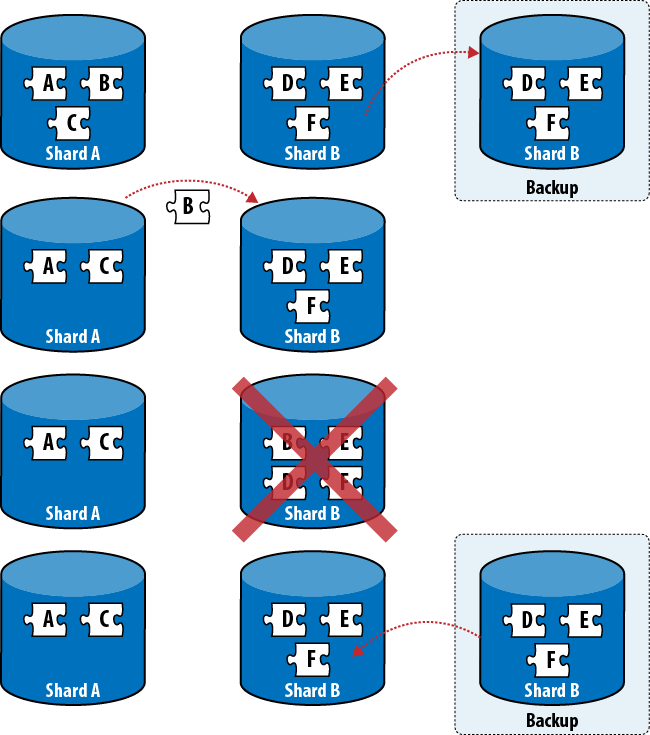
The problem with taking backups is that you usually only want to restore parts of your cluster (you don’t want to restore the entire cluster from yesterday’s backup, just the node that went down). If you restore data from a backup, you have to be careful. Look at the config servers and see which chunks are supposed to be on the shard you’re restoring. Then only restore data from those chunks using your backups (and mongorestore).
If you want a snapshot of the whole cluster, you would have to turn off the balancer, fsync and lock the slaves in the cluster, take dumps from them, then unlock them and restart the balancer. Typically people just take backups from individual shards.
Config Server Backups
If you have three config servers, shut one of them down and copy its files to a backup location. As two config servers are still running, your cluster configuration will be read-only, but everything else should operate normally. Backing up data from a config server should only take a few minutes: even the largest installs generate less than a gigabyte of config data.
If you have a single config server and you’re using that single config server in production, it becomes a little trickier (please don’t use a single config server in production). You should do a targetted query through each of the mongos processes running to ensure that they all have up-to-date versions of the configuration. Once you’ve done that, bring down the config server and make a backup of its files.
Suggestions on Architecture
You can create a sharded cluster and leave it at that, but what happens when you want to do routine maintenance? There are a few extra pieces you can add that will make your setup easier to manage.
Create an Emergency Site
The name implies that you’re running a website, but this applies to most types of application. If you need to bring your application down occasionally (e.g., to do maintenance, roll out changes, or in an emergency), it’s very handy to have an emergency site that you can switch over to.
The emergency site should not use your cluster at all. If it uses a database, it should be completely disconnected from your main database. You could also have it serve data from a cache or be a completely static site, depending on your application. It’s a good idea to set up something for users to look at, though, other than an Apache error page.
Create a Moat
A excellent way to prevent or minimize all sorts of problems is to create a virtual moat around your machines and control access to the cluster via a queue.
A queue can allow your application to continue handling writes in a planned outage, or at least prevent any writes that didn’t quite make it before the outage from getting lost. You can keep them on the queue until MongoDB is up again and then send them to the mongos.
A queue isn’t only useful for disasters—it can also be helpful in regulating bursty traffic. A queue can hold the burst and release a nice, constant stream of requests, instead of allowing a sudden flood to swamp the cluster. You can also use a queue going the other way: to cache results coming out of MongoDB.
There are lots of different queues you could use: Amazon’s SQS, RabbitMQ, or even a MongoDB capped collection (although make sure it’s on a separate server than the cluster it’s protecting). Use whatever queue you’re comfortable with.
Queues won’t work for all applications. For example, they don’t work with applications that need real-time data. However, if you have an application that can stand small delays, a queue can be useful intermediary between the world and your database.
What to Do When Things Go Wrong
As mentioned in the first chapter, network partitions, server crashes, and other problems can cause a whole variety of issues. MongoDB can “self-heal,” at least temporarily, from many of these issues. This section covers which outages you can sleep through and which ones you can’t, as well as preparing your application to deal with outages.
A Shard Goes Down
If an entire shard goes down, reads and writes that would have hit that shard will return errors. Your application should handle those errors (it’ll be whatever your language’s equivalent of an exception is, thrown as you iterated through a cursor). For example, if the first three results for some query were on the shard that is up and the next shard containing useful chunks is down, you’d get something like:
> db.foo.find()
{ "_id" : 1 }
{ "_id" : 2 }
{ "_id" : 3 }
error: mongos connectionpool:
connect failed ny-01:10000 : couldn't connect to server ny-01:10000Be prepared to handle this error and keep going gracefully. Depending on your application, you could also do exclusively targeted queries until the shard comes back online.
In 1.7.5 and later, you can set a “partial results” flag when you send a query to mongos. If this flag is set (it defaults to unset), mongos will only return results from shards that are up and not return any errors.
Most of a Shard Is Down
If you are using replica sets for shards, hopefully an entire
shard won’t go down, but merely a server or two in the set. If the set
loses a majority of its members, no one will be able to become master
(without manual rejiggering), and so the set will be read-only. If a set
becomes read-only, make sure your application is only sending it reads
and using slaveOkay.
If you’re using replica sets, hopefully a single server (or even a few servers) failing won’t affect your application at all. The other servers in the set will pick up the slack and your application won’t even notice the change.
Tip
In 1.6, if a replica set configuration changes, there may be a zillion identical messages printed to the log. Every connection between mongos and the shard prints a message when it notices that its replica set connection is out-of-date and updates it. However, it shouldn’t have an impact on what’s actually happening—it’s just a lot of sound and fury. This has been fixed for 1.8; mongos is much smarter about updating replica set configurations.
Config Servers Going Down
If a config server goes down, there will be no immediate impact on cluster performance, but no configuration changes can be made. All the config servers work in concert, so none of the other config servers can make any changes while even a single of their brethren have fallen. The thing to note about config servers is that no configuration can change while a config server is down—you can’t add mongos servers, you can’t migrate data, you can’t add or remove databases or collections, and you can’t change replica set configurations.
If a config server crashes, do get it back up so that your config can change when it needs to, but it shouldn’t affect the immediate operation of your cluster at all. Make sure you monitor config servers and, if one fails, get it right back up.
Having a config server go down can put some pressure on your servers if there is a migrate in progress. One of the last steps of the migrate is to update the config servers. Because one server is down, they can’t be updated, so the shards will have to back out the migration and delete all the data they just painstakingly copied. If your shards aren’t overloaded, this shouldn’t be too painful, but it is a bit of a waste.
Mongos Processes Going Down
As you can always have extra mongos processes and they have no state, it’s not too big a deal if one goes down. The recommended setup is to run one mongos on each appserver and have each appserver talk to its local mongos (Figure 5-2). Then, if the whole machine goes down, no one is trying to talk to a mongos that isn’t there.
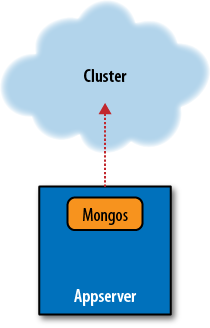
Have a couple extra mongos servers out there that you can fail over to if one mongos process crashes while the application server is still okay. Most drivers let you specify a list of servers to connect to and will try them in order. So, you could specify your preferred mongos first, then your backup mongos. If one goes down, your application can handle the exception (in whatever language you’re using) and the driver will automatically shunt the application over to your backup mongos for the next request.
You can also just try restarting a crashed mongos if the machine is okay, as they are stateless and store no data.
Other Considerations
Each of the points above is handled in isolation from anything else that could go wrong. Sometimes, if you have a network partition, you might lose entire shards, parts of other shards, config servers, and mongos processes. You should think carefully about how to handle various scenarios from both user-facing (will users still be able to do anything?) and application-design (will the application still do something sensible?) perspectives.
Finally, MongoDB tries to let a lot go wrong before exposing a loss of functionality. If you have the perfect storm (and you will), you’ll lose functionality, but day-to-day server crashes, power outages, and network partitions shouldn’t cause huge problems. Keep an eye on your monitoring and don’t panic.