
6. Buffer Overflow
And you may ask yourself: Well, how did I get here? And you may tell yourself My god! What have I done?
–TALKING HEADS
Nearly everyone who uses computers regularly recognizes the name buffer overflow. Many in the software industry understand that the vulnerability involves cramming too much data into too small of a buffer. For many cases, that’s a pretty accurate understanding. A buffer overflow occurs when a program writes data outside the bounds of allocated memory. Buffer overflow vulnerabilities are usually exploited to overwrite values in memory to the advantage of the attacker. Buffer overflow mistakes are plentiful, and they often give an attacker a great deal of control over the vulnerable code. It’s little wonder that they are such a common target of attacks.
In this chapter, we explain how a simple buffer overflow exploit works, show real-world examples that demonstrate many common coding errors that lead to buffer overflow vulnerabilities, and give advice for building software that is less likely to allow a buffer overflow. Through most of the chapter, our advice is tactical: We look at typical coding problems, their ramifications, and their solutions. Much of this chapter is focused on buffer overflow vulnerabilities related to string manipulation. The next chapter tackles integer operations that often cause buffer overflows in a similar manner and then concludes by looking at some strategic approaches to solving the buffer overflow problem.
The chapter breaks down like this:
• Introduction to buffer overflow—We show how buffer overflows work and detail the risks they introduce. We cover some common code patterns that lead to buffer overflow.
• Strings—Many buffer overflow vulnerabilities are related to string manipulation. We look at common string handling mistakes and best practices to get strings right.
We spend only a few words justifying the importance of preventing buffer overflow. Consider the following facts. Since the highly publicized Morris Worm first used a buffer overflow exploit against fingerd to aid its spread across the fledgling Internet in 1988, buffer overflow has become the single best-known software security vulnerability. With almost 20 years of high-profile exposure, you might expect that buffer overflow would no longer pose a significant threat. You would be wrong. In 2000, David Wagner found that nearly 50% of CERT warnings for that year were caused by buffer overflow vulnerabilities [Wagner et al., 2000]. What about today? Buffer overflow contributed to 14 of the top 20 vulnerabilities in 2006 [SANS 20, 2006], and data collected by MITRE as part of the Common Vulnerabilities and Exposures (CVE) project show that the overall number of buffer overflow vulnerabilities being reported has not decreased meaningfully in this decade [Christy, 2006]. If that isn’t enough evidence of their ongoing impact, buffer overflow vulnerabilities were behind some of the most devastating worms and viruses in recent memory, including Zotob, Sasser, Blaster, Slammer, Nimda, and Code Red.
6.1 Introduction to Buffer Overflow
The best way to prevent buffer overflow vulnerabilities is to use a programming language that enforces memory safety and type safety. In unsafe languages, of which C and C++ are the most widely used, the programmer is responsible for preventing operations from making undesirable changes to memory. Any operation that manipulates memory can result in a buffer overflow, but in practice, the mistakes that most often lead to buffer overflow are clustered around a limited set of operations. Before going into the variety of ways buffer overflows can occur, we look at a classic buffer overflow exploit.
Exploiting Buffer Overflow Vulnerabilities
To understand the risk that buffer overflow vulnerabilities introduce, you need to understand how buffer overflow vulnerabilities are exploited. Here we outline a canonical buffer overflow exploit. We refer readers interested in more in-depth coverage of buffer overflow exploits to Exploiting Software [Hogland and McGraw, 2004] and The Shellcoder’s Handbook [Koziol et al., 2004].
In a classic stack smashing attack, the attacker sends data that contain a segment of malicious code to a program that is vulnerable to a stack-based buffer overflow. In addition to the malicious code, the attacker includes the memory address of the beginning of the code. When the buffer overflow occurs, the program writes the attacker’s data into the buffer and continues beyond the buffer’s bounds until it eventually overwrites the function’s return address with the address of the beginning of the malicious code. When the function returns, it jumps to the value stored in its return address. Normally, this would return it to the context of the calling function, but because the return address has been overwritten, control jumps to the buffer instead and begins executing the attacker’s malicious code. To increase the likelihood of guessing the correct address of the malicious code, attackers typically pad the beginning of their input with a “sled” of NOP (no operation) instructions.
The code in Example 6.1 defines the simple function trouble(), which allocates a char buffer and an int on the stack and reads a line of text into the buffer from stdin with gets(). Because gets() continues to read input until it finds an end-of-line character, an attacker can overflow the line buffer with malicious data.
Example 6.1. This simple function declares two local variables and uses gets() to read a line of text into the 128-byte stack buffer line.
![]()
void trouble() {
int a = 32; /*integer*/
char line[128]; /*character array*/
gets(line); /*read a line from stdin*/
}
In today’s security climate, the code in Example 6.1 would be quickly labeled unsafe because gets() is almost universally understood to be dangerous. This basic variety of exploit still works on older platforms, but because buffer overflows offer attackers the ability to write arbitrary data to memory, the range of possible attacks is not limited to targeting the return address of a function.
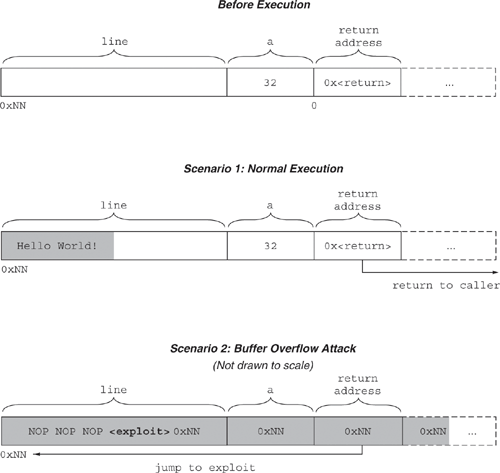
To better understand what happens in a classic buffer overflow exploit, consider Figure 6.1, which shows three different versions of a simplified stack frame for trouble(). The first stack frame depicts the contents of memory after trouble() is called but before it is executed. The local variable line is allocated on the stack beginning at address 0xNN. The local variable a is just above it in memory; the return address (0x<return>) is just above that. Assume that 0x<return> points into the function that called trouble(). The second stack frame illustrates a scenario in which trouble() behaves normally. It reads the input Hello World! and returns. You can see that line is now partially filled with the input string and that the other values stored on the stack are unchanged. The third stack frame illustrates a scenario in which an attacker exploits the buffer overflow vulnerability in trouble() and causes it to execute malicious code instead of returning normally. In this case, line has been filled with a series of NOPs, the exploit code, and the address of the beginning of the buffer, 0xNN.
Figure 6.1. Three different versions of a simplified stack frame for trouble(): one before execution, one after normal execution, and one after a buffer overflow exploit.
One of the most common misconceptions about buffer overflow vulnerabilities is that they are exploitable only when the buffer is on the stack. Heap-based buffer overflow exploits can overwrite important data values stored on the heap, and attackers have also found ways to change the control flow of the program. For example, they might overwrite the value of a function pointer so that when the program invokes the function referenced by the function pointer, it will execute malicious code. Finally, even if an attacker cannot inject malicious code onto a system, an exploit technique known as arc injection or return-into-libc (because of its dependency on standard library functions) might allow a buffer overflow to alter the control flow of the program. Arc injection attacks use a buffer overflow to overwrite either a return address or the value of a function pointer with the address of a function already defined on the system, which could allow an attacker to set up a call to an arbitrary system library, such as system("/bin/sh") [Pincus and Baker, 2004].
Enough is enough. Buffer overflow vulnerabilities give an attacker a lot of latitude. Writing just a single byte past the end of an array can result in system compromise. In the rest of this chapter, we spend very little energy discussing exploitability. Instead, we talk about common mistakes and how to identify them, remediate them, and hopefully avoid them altogether.
Buffer Allocation Strategies
Most tactics for preventing buffer overflows focus on how and when to check for a condition that will lead to an overflow. Before we discuss these tactics, we consider what should happen when such a check fails. At its core, this is a question of memory allocation. There are only two alternatives; when an operation requires a larger buffer than is currently allocated, the program can do one of two things:
• Retain the current size of the buffer and either prevent the operation from executing (perhaps by doing something as extreme as terminating program execution) or carry out only part of the operation (thereby truncating the data).
• Dynamically resize the buffer so that it can accommodate the results of the operation.
Big programs invariably use static allocation in some cases and dynamic allocation in others. Programmers choose between them based on the task at hand. Regardless of the approach being used for a particular piece of code, a systematic and explicit method for memory allocation makes it easier for a human or a tool to inspect the code and quickly verify its safety. Be consistent with the solution you choose for specific types of operations. Make the accepted mechanism for allocating memory in a given context clear so that programmers, auditors, and tools understand the expected behavior and are better able to identify unintentional deviations. Consistency makes errors easier to spot.
Example 6.2 shows a buffer overflow found in RSA’s reference implementation of the RSA cryptographic algorithm. When this bug was found in 1999, it affected a number of security-related programs, including PGP, OpenSSH, and Apache’s ModSSL [Solino, 1999]. The problem is that the function shown (and others like it) did not check to make sure that the dynamically sized function parameter input was smaller than the statically sized stack buffer pkcsBlock.
Example 6.2. This buffer overflow in RSAREF is caused by mixing static and dynamic approaches to memory allocation.
![]()
int RSAPublicEncrypt (output, outputLen, input,
inputLen, publicKey, randomStruct)
unsigned char *output; /* output block */
unsigned int *outputLen; /* length of output block */
unsigned char *input; /* input block */
unsigned int inputLen; /* length of input block */
R_RSA_PUBLIC_KEY *publicKey; /* RSA public key */
R_RANDOM_STRUCT *randomStruct; /* random structure */
{
int status;
unsigned char byte, pkcsBlock[MAX_RSA_MODULUS_LEN];
unsigned int i, modulusLen;
...
R_memcpy ((POINTER)&pkcsBlock[i], (POINTER)input, inputLen);
...
}
Static Buffer Allocation
Under a static buffer allocation scheme, memory for a buffer is allocated once and the buffer retains its initial size for the duration of its existence. The biggest advantage of this approach is simplicity. Because a buffer remains the same size throughout its lifetime, it is easier for programmers to keep track of the size of the buffer and ensure that operations performed on it are safe. Along these same lines, allocating memory for a buffer only once results in simpler code surrounding buffer operations, which facilitates both manual and automated code review.
The code in Example 6.3 shows a simple program that uses snprintf() to copy the number of command-line arguments and the name of the binary that was invoked into the stack buffer str. The buffer is statically allocated on the stack with a constant size of 16 bytes, and the call to snprintf() is used properly to determine whether the amount of data available to be copied would result in a string larger than str can accommodate. If too much data is provided, the program prints a simple error message indicating that the formatted print operation was truncated.
Example 6.3. A simple program uses a static memory allocation strategy.
![]()
int main(int argc, char **argv) {
char str[BUFSIZE];
int len;
len = snprintf(str, BUFSIZE, "%s(%d)", argv[0], argc);
printf("%s
", str);
if (len >= BUFSIZE) {
printf("length truncated (from %d)
", len);
}
return SUCCESS;
}
Despite its simplicity, the static allocation approach does have disadvantages. Because the programmer must select the maximum size for each buffer before the program is compiled, programs that allocate buffers statically are inherently less flexible in the conditions they can handle without fault. Under a static allocation scheme, the only choices available when a buffer is too small are to refuse to perform the operation or to truncate the data and return an error. Depending on the context in which it occurs, data truncation can introduce a variety of logic and representation errors that can be nasty to track down. Another side effect of statically sized buffers is the potential for wasted resources when the maximum capacity required for a buffer is much larger than the average capacity used. For example, a program that processes e-mail addresses needs to allocate buffers large enough to hold the longest valid e-mail address, even though most addresses will be much shorter. This waste of resources can add up in large programs where many buffers are only partially filled.
Dynamic Buffer Allocation
The dynamic buffer allocation approach allows for buffers to be resized according to runtime values as required by the program. By decoupling decisions about buffer sizes from the compilation of the program, a dynamic solution enables programs to function more flexibly when the data they operate on vary significantly at runtime.
The code in Example 6.4 demonstrates how the simple program from Example 6.3 could be rewritten to behave more flexibly using dynamic buffer allocation. The behavior of the program is nearly identical, except when the size of the string produced by snprintf() is larger than the initial size of str. In this case, the program attempts to dynamically resize str to the exact size required for the operation to continue safely. If the new allocation fails (which can happen under low memory conditions), the program returns an error code.
Example 6.4. Code from Example 6.3 rewritten to use dynamic memory allocation.
![]()
int main(int argc, char **argv) {
char *str;
int len;
if ((str = (char *)malloc(BUFSIZE)) == NULL) {
return FAILURE_MEMORY;
}
len = snprintf(str, BUFSIZE, "%s(%d)", argv[0], argc);
if (len >= BUFSIZE) {
free(str);
if ((str = (char *)malloc(len + 1)) == NULL) {
return FAILURE_MEMORY;
}
snprintf(str, len + 1, "%s(%d)", argv[0], argc);
}
printf("%s
", str);
free(str);
str = NULL;
return SUCCESS;
}
Compare Example 6.4 with Example 6.3. The additional complexity involved in dynamic allocation is obvious. Beyond the addition of code to determine the desired buffer size, allocate the new memory, and check to see that the allocation succeeds, the program’s correctness is harder to verify because a runtime value controls the size of the dynamically allocated buffer. The dependence on the return value of snprintf() and the size of extra add a layer of indirection to the code. Although the relationship between these values can be determined, this indirection makes the code less readable and possibly more error prone.
Dynamic allocation also brings with it another concern. Because the dynamic approach is data driven, unexpected or malicious input could cause the system to exhaust its memory resources. Under a static allocation approach, the decision of how much data to accept or operate on is made at compile time. Only if a buffer overflow occurs can these limits be exceeded, and then resource exhaustion is probably not your greatest concern. When buffers are allocated dynamically, however, specific checks are necessary to place limits on the size of data that should be accepted. Implement explicit sanity checks to ensure that you do not allocate an unreasonable amount of memory in the process of resizing a buffer.
The code in Example 6.5 demonstrates how Example 6.4 could be rewritten to include a sanity check on the size of the string generated by snprintf().
Example 6.5. Code from Example 6.4 reimplemented to include a sanity check on the maximum memory allocated.
![]()
int main(int argc, char **argv) {
char *str;
int len;
if ((str = (char *)malloc(BUFSIZE)) == NULL) {
return FAILURE_MEMORY;
}
len = snprintf(str, BUFSIZE, "%s(%d)", argv[0], argc);
if (len >= BUFSIZE) {
free(str);
if (len >= MAX_ALLOC) {
return FAILURE_TOOBIG;
}
if ((str = (char *)malloc(len + 1)) == NULL) {
return FAILURE_MEMORY;
}
snprintf(str, len + 1, "%s(%d)", argv[0], argc);
}
printf("%s
", str);
free(str);
str = NULL;
return SUCCESS;
}
• Error conditions and other exceptional circumstances
• Confusion over which part of the program is responsible for freeing the memory
Example 6.6. A use-after-free vulnerability in simple error-handling code.
![]()
char* ptr = (char*)malloc (SIZE);
...
if (tryOperation() == OPERATION_FAILED) {
free(ptr);
errors++;
}
...
if (errors > 0) {
logError("operation aborted before commit", ptr);
}
Example 6.7. A double free vulnerability in simple error-handling code.
![]()
char* ptr = (char*)malloc (SIZE);
...
if (tryOperation() == OPERATION_FAILED) {
free(ptr);
errors++;
}
...
free(ptr);
#define FREE( ptr ) {free(ptr); ptr = NULL;}
Model checking rule
Tracking Buffer Sizes
Beyond simple string lengths and stack-allocated variables, C and C++ give programmers little help tracking the size of buffers. The sizeof operator returns the length of memory allocated for a variable if it’s allocated on the stack in the current scope, but it returns only the size of the pointer if the variable is allocated on the heap. If a buffer contains a string, the size of the memory the string occupies can be computed by counting the bytes in the buffer before a null terminator is found. The only general solution is to explicitly track the current size of each buffer as separate value. This enables you to avoid relying on assumptions to ensure that operations on the buffer are safe, but it requires that the length stored for the buffer be updated whenever an operation is performed that alters its size. This section outlines some common strategies for tracking buffer sizes and shows a piece of code that is retrofitted to include explicit size information.
The most common approach to tracking a buffer and its size is to store them together in a composite data structure (such as a struct or class). This approach is akin to a rudimentary approximation of memory safety.
Memory-safe languages track the size of every buffer and make comparisons against this size when operations are performed on them. It’s worth considering whether your program might lend itself to reimplementation in a language that abstracts the work away from the programmer.
The code in Example 6.8 demonstrates how Example 6.5 could be rewritten to use an elementary string structure that stores the length of the string along with buffer.
Example 6.8. Code from Example 6.5 rewritten to explicitly track buffer sizes.
![]()
typedef struct{
char* ptr;
int bufsize;
} buffer;
int main(int argc, char **argv) {
buffer str;
int len;
if ((str.ptr = (char *)malloc(BUFSIZE)) == NULL) {
return FAILURE_MEMORY;
}
str.bufsize = BUFSIZE;
len = snprintf(str.ptr, str.bufsize, "%s(%d)", argv[0], argc);
if (len >= BUFSIZE) {
free(str.ptr);
if (len >= MAX_ALLOC) {
return FAILURE_TOOBIG;
}
if ((str.ptr = (char *)malloc(len + 1)) == NULL) {
return FAILURE_MEMORY;
}
str.bufsize = len + 1;
snprintf(str.ptr, str.bufsize, "%s(%d)", argv[0], argc);
}
printf("%s
", str.ptr);
free(str.ptr);
str.ptr = NULL;
str.bufsize = 0;
return SUCCESS;
}
Most errors related to manually tracking buffer sizes occur when the size of a buffer is maintained incorrectly, which is usually caused by code that dynamically resizes a buffer but fails to update the associated size. A stale buffer size is more dangerous than no buffer size because later operations on the buffer might trust the stored size implicitly. Provide centralized libraries to maintain buffer sizes for commonly used structures. This allows code that updates stored sizes to be carefully audited for errors.
Example 6.9 shows the code from Example 6.8 rewritten to include a simple helper function that manipulates string structures. The function accepts a string structure, a new value, and the length of the value.
Example 6.9. Code from Example 6.8 rewritten to use a helper function to systematically update the buffer and its size together.
![]()
typedef struct{
char* ptr;
int bufsize;
} buffer;
int resize_buffer(buffer* buf, int newsize) {
char* extra;
if (newsize > MAX_ALLOC) {
return FAILURE_TOOBIG;
}
if ((extra = (char *)malloc(newsize)) == NULL) {
return FAILURE_MEMORY;
}
free(buf->ptr);
buf->ptr = extra;
buf->bufsize = newsize;
return SUCCESS;
}
int main(int argc, char **argv) {
buffer str = {NULL, 0};
int len;
int rc;
if ((rc = resize_buffer(&str, BUFSIZE)) != SUCCESS) {
return rc;
}
len = snprintf(str.ptr, str.bufsize, "%s(%d)", argv[0], argc);
if (len >= str.bufsize) {
if ((rc = resize_buffer(&str, len + 1)) != SUCCESS) {
return rc;
}
snprintf(str.ptr, str.bufsize, "%s(%d)", argv[0], argc);
}
printf("%s
", str.ptr);
free(str.ptr);
str.ptr = NULL;
str.bufsize = 0;
return SUCCESS;
}
6.2 Strings
The basic C string data structure (a null-terminated character array) is error prone, and the built-in library functions for string manipulation only make matters worse. This section begins by going over the original set of string-manipulation functions and then the second-generation string-manipulation functions (most have an n in their names) and the problems they can cause, too. Then we look at problems that stem from using a null terminator to specify the length of a string. After that, we discuss two other ways that strings lead to buffer overflow: multibyte characters and format strings. We end by taking a tour of alternative libraries that provide safer ways to handle strings.
Inherently Dangerous Functions
Many C string-manipulation functions are easy to misuse. Instead of trying to be extra careful with them, the best thing to do is to avoid them altogether. Specifically, avoid using inherently dangerous string-manipulation functions that behave like gets(), scanf(), strcpy(), or sprintf(). We look at each of these functions and then discuss a related pitfall: reimplementation of these dangerous interfaces.
gets() and Friends
When you ask a room full of security experts for an example of a buffer overflow vulnerability, the first answer often includes a call to gets(). The behavior of gets() is quite simple: The function reads from the stream pointed to by stdin and copies the data into a buffer until it reaches a newline (
) character. The function will overflow its destination buffer anytime the number of characters read from the input source is larger than the buffer passed to gets(). Functions that mimic the behavior of gets(), such as _getws(), are equally dangerous. Table 6.1 summarizes the gets() function.
Table 6.1. Function prototype and description for gets() [ISO “C99,” 2005].

The first widely publicized buffer overflow exploit was written against a vulnerability in the Berkeley fingerd daemon. The Morris Worm leveraged the exploit to help it wreak havoc on the then-infantine Internet (approximately 60,000 computers). The worm caused some machines to become unavailable due to the worm’s load and others to be pulled off the network to avoid infection.
The vulnerable code in fingerd came down to one thing: a call to gets(), as shown in Example 6.10. The code was used to read data from a socket connection, which meant that anyone who could open a connection to fingerd could exploit the vulnerability. Clearly, gets() need not always be used to read network data, so not every call to the function presents the potential for a remote exploit. However, a call to gets() does mean that the security of your program depends on it receiving only well-intentioned input.
Example 6.10. An unsafe call to gets() similar to the one exploited by the Morris worm.
![]()
char line[512];
gets(line);
C++ first appeared 12 years after C, but it repeated many of the same mistakes. At best, C++ could have been as safe as C because it is (mostly) backward compatible, so it supports the same constructs and libraries as its predecessor. However, despite the opportunity to learn from past mistakes, the designers of C++ replicated some of the same blatant vulnerabilities that exist in C. Among the most obvious examples is the reproduction of the faulty behavior of gets() with the definition of the operator >> for reading into a character array. The behavior is almost identical to the behavior of gets(). The C++ code shown in Example 6.11 is functionally equivalent to the code from fingerd in Example 6.10.
Example 6.11. An unsafe use of the C++ operator >>.
![]()
char line[512];
cin >> (line);
scanf() and Friends
Although slightly more complex than gets(), scanf() is vulnerable in much the same way because it is designed to read an arbitrary amount of formatted data into one or more fixed-size buffers. When scanf() encounters a %s specifier in its format string, it reads characters into the corresponding buffer until a non-ASCII value is encountered, potentially resulting in a buffer overflow if the function is supplied with more data than the buffer can accommodate. If a width specifier is included, such as %255s, scanf() will read up to the specified number of characters into the buffer. Because of the capability to limit the amount of input read, scanf() can potentially be used safely if the format specifier properly bounds the amount of data read. Even when it is used, correct bounds enforcement through format string specifiers is error prone. Functions that mimic the behavior of scanf(), such as fscanf() and wscanf(), are equally dangerous. Table 6.2 summarizes the scanf() class of functions.
Table 6.2. Function prototype and description for scanf() [ISO “C99,” 2005].

The code in Example 6.12 is from Version 2.0.11 of the w3-msql CGI program, which provides a lightweight Web interface for Mini-SQL [Zhodiac, 1999]. Because buffer is allocated to hold 15 × 1,024 bytes, an attacker can use the unbounded call to scanf() to fill it with a large amount of malicious code before the buffer overflows, which makes the exploit easier. Ironically, the code ignores the value used in the exploit; it is read only to advance the input source. This vulnerability has been remotely exploited to gain root privileges.
Example 6.12. Code from w3-msql 2.0.11 that is vulnerable to a remote buffer overflow caused by an unsafe call to scanf().
![]()
char var[128], val[15 * 1024], ..., boundary[128], buffer[15 * 1024];
...
for(;;) {
...
// if the variable is followed by '; filename="name"' it is a file
inChar = getchar();
if (inChar == ';') {
...
// scan in the content type if present, but simply ignore it
scanf(" Content-Type: %s ", buffer);
strcpy() and Friends
Unlike gets() and scanf(), strcpy() operates on data already stored in a program variable, which makes it a less obvious security risk. Because strcpy() copies the contents of one buffer into another until a null byte is encountered in the source buffer, it can be used safely if the code surrounding it correctly ensures that the contents of the source buffer are guaranteed to be no larger than the capacity of the destination buffer. The combination of the lack of a direct connection to user input and the possibility of safe behavior means the use of strcpy() is more frequently tolerated than the use of gets(). In practice, the conditions that must be met to use strcpy() safely are often too difficult to meet, primarily because they are inherently distinct from the invocation of strcpy(). Functions that mimic the behavior of strcpy(), such as wcscpy() and lstrcpy(), are equally dangerous. Table 6.3 summarizes the strcpy() function.
Table 6.3. Function prototype and description for strcpy() [ISO “C99,” 2005].

The code in Example 6.13 is from the php.cgi program in Version 2.0beta10 of PHP/FI [Network Associates “PHP,” 1997]. The filename parameter to FixFilename() is user controlled and can be as large as 8KB, which the code copies into a 128-byte buffer, causing a buffer overflow. This vulnerability has been remotely exploited to gain root privileges.
Example 6.13. Code from the php.cgi program in PHP/FI 2.0beta10 that is vulnerable to a remote buffer overflow caused by an unsafe call to strcpy().
![]()
char *FixFilename(char *filename, int cd, int *ret) {
...
char fn[128], user[128], *s;
...
s = strrchr(filename,'/'),
if(s) {
strcpy(fn,s+1);
sprintf() and Friends
To use sprintf() safely, you must ensure that the destination buffer can accommodate the combination of all the source arguments, the string size of which could vary, depending on what conversions are performed as they are formatted, and the nonformat specifier components of the format string. In the same way that scanf() can be used safely if proper width-limiters are used, a carefully calculated format string with the appropriate width-limiters can make a call to sprintf() safe. However, the likelihood of error is even worse than with scanf() because here the calculation must accommodate many variables and formatting options. Functions that mimic the behavior of sprintf(), such as fprintf() and swprintf(), are equally dangerous. See Table 6.4 for a summary of the sprintf() class of functions.
Table 6.4. Function prototype and description for sprintf() [ISO “C99,” 2005].

The code in Example 6.14 contains a buffer overflow caused by the unsafe use of sprintf() in Version 1.0 of the Kerberos 5 Telnet daemon [Network Associates, 1997]. If an attacker supplies a large value of TERM, the code will overflow the speed buffer. Because the daemon runs with root privileges and can be invoked by a remote user under certain configurations, this vulnerability has been exploited remotely to gain root privileges.
Example 6.14. Code from Version 1.0 of the Kerberos 5 Telnet daemon that contains a buffer overflow because the length of the TERM environment variable is never validated.
![]()
char speed[128];
...
sprintf(speed, "%s/%d", (cp = getenv("TERM")) ? cp : "",
(def_rspeed > 0) ? def_rspeed : 9600);
Risks of Reimplementation
Functions that are considered dangerous today were created because they provided functionality that programmers found useful. The desirable traits of functions are usually easy to identify; it’s the risks that take some thought and security awareness to uncover. The same needs that led to the creation of gets(), scanf(), strcpy(), sprintf(), and other dangerous functions still exist today, which often leads developers to reimplement both the functionality and the vulnerabilities. When the behavior of a dangerous function is replicated in proprietary code, the overall security of the program is worse off than if the dangerous function were used directly because it can no longer be identified by name alone.
The code in Example 6.15 is part of csv2xml Version 0.6.1. The programmer who coded the method get_csv_token() has unwittingly duplicated the dangerous behavior of gets(), effectively introducing the same class of vulnerability as the standard library function.
Example 6.15. A function from csv2xml that replicates the dangerous interface of gets().
![]()
int get_csv_token(char *token) {
int c;
int quoted;
int len;
len=0;
quoted=0;
while(c=getchar()) {
if(c==-1) { break; }
if(len==0 && c=='"' && quoted==0) { quoted=1; continue; }
if(c=='"') { quoted=0; continue; }
if(quoted==0 && c==',') { *token='�'; return(1); }
if(c==10) { line++; }
if(quoted==0 && c==10) { *token='�'; return(0); }
*token=c;
len++;
token++;
}
*token='�';
return(-1);
}
As its name suggests, csv2xml is a simple comma separated value (CSV) to XML converter that reads CSV files from standard input and generates a valid XML file on standard output. In 2004, Limin Wang discovered an exploitable buffer overflow vulnerability in csv2xml that allows unauthorized commands to be executed on a victim machine by providing a malicious CSV file [Wang, 2004]. The vulnerability is caused by code in get_field_headers() that uses get_csv_token() to read an arbitrary number of bytes into a 1001-byte token[] array. In essence, get_csv_token() implements a gets()-style interface because it will read an arbitrary number of bytes into a fixed-size buffer without performing any bounds checks.
Bounded String Operations
Many early buffer overflow vulnerabilities discovered in C and C++ programs were caused by string operations. When functions such as strcpy() and strcat() were implicated repeatedly, the C standard was revised to introduce bounded equivalents to these functions, such as strncpy() and strncat(). These functions accept a parameter that limits the amount of data that will be written to the target buffer. This section provides an introduction to these bounded string-manipulation functions and demonstrates how they can be used to eliminate many simple buffer overflow vulnerabilities. The following section discusses why these bounded functions are a less-than-perfect solution.
Conceptually, using bounded string-manipulation functions can be as simple as replacing this
strcpy(buf, src);
with this:
strncpy(buf, src, sizeof(buf));
Table 6.5 maps common unbounded string-manipulation functions to their bounded replacements. Bounded equivalents to many standard C library functions have been included in the C standard. On Windows platforms with Visual Studio 2005, the Microsoft Safe CRT [Howard, 2007] library provides bounded string-manipulation functions suffixed with _s (for “secure”). The Microsoft functions are more consistent (they always include a parameter that specifies the size of the target buffer) and safer (they always produce null-terminated strings). Among its other enhancements, the library has deprecated many older and more dangerous functions, as well as added new functions for performing certain sensitive operations safely.
Table 6.5. Common unbounded functions and their bounded equivalents.

You might find other bounded string-manipulation functions that address specific holes in the C standard library in other libraries. Two such functions that have become widespread are strlcpy() and strlcat(), which are similar to strncpy() and strncat() but guarantee that their destination buffers will be null-terminated. If a bounded replacement for a function is unavailable in your environment, consider implementing it as a proprietary wrapper around its unbounded equivalent.
Most string operations can be performed with bounded functions from the standard string-manipulation libraries. Although unbounded functions are still included in the C standard for backward compatibility, treat the proper use of bounded string-manipulation functions as an absolute bare-minimum level of security in any modern program. Replace calls to unbounded string-manipulation functions with bounded equivalents, regardless of whether the unbounded call is provably dangerous in the context in which it is used. Refactoring legacy code to make consistent use of bounded string-manipulation functions makes the code more robust and will likely eliminate security vulnerabilities at the same time. The necessary changes can often be completed quickly and with low risk of introducing new coding errors.
The code in Example 6.16 shows a buffer overflow vulnerability that results from the incorrect use of unbounded string-manipulation functions strcat() and strcpy() in Kerberos 5 Version 1.0.6 [CERT “CA-2000-06,” 2000]. Depending on the length of cp and copy, either the final call to strcat() or the call to strcpy() could overflow cmdbuf. The vulnerability occurs in code responsible for manipulating a command string, which immediately suggests that it might be exploitable because of its proximity to user input. In fact, this vulnerability has been publicly exploited to execute unauthorized commands on compromised systems.
Example 6.16. Unsafe calls to strcat() and strcpy() from Kerberos 5 Version 1.0.6.
![]()
if (auth_sys == KRB5_RECVAUTH_V4) {
strcat(cmdbuf, "/v4rcp");
} else {
strcat(cmdbuf, "/rcp");
}
if (stat((char *)cmdbuf + offst, &s) >= 0)
strcat(cmdbuf, cp);
else
strcpy(cmdbuf, copy);
Example 6.17 shows the same code in the subsequently released Version 1.0.7 patch for Kerberos 5. In the patched code, the three calls to strcat() and the call to strcpy() have all been replaced with properly bounded equivalents to correct the vulnerability.
Example 6.17. Code from Example 6.16 patched to replace unsafe calls to strcat() and strcpy(). This code was released as part of Kerberos 5 Version 1.0.7.
![]()
cmdbuf[sizeof(cmdbuf) - 1] = '�';
if (auth_sys == KRB5_RECVAUTH_V4) {
strncat(cmdbuf, "/v4rcp", sizeof(cmdbuf) - 1 - strlen(cmdbuf));
} else {
strncat(cmdbuf, "/rcp", sizeof(cmdbuf) - 1 - strlen(cmdbuf));
}
if (stat((char *)cmdbuf + offst, &s) >= 0)
strncat(cmdbuf, cp, sizeof(cmdbuf) - 1 - strlen(cmdbuf));
else
strncpy(cmdbuf, copy, sizeof(cmdbuf) - 1 - strlen(cmdbuf));
An alternate approach is to “manually” perform the bounds checks yourself and continue to use the unbounded operations. Checking bounds manually is tougher than it might first appear. Consider the code in Example 6.18, which is taken from the component of Apache Version 1.31 that manipulates usernames as part of the authentication process for .htaccess-protected files. If the variable nofile is nonzero, a buffer overflow can occur at the second call to strcpy() because the check for strlen(argv[i + 1]) > (sizeof(user) - 1) located in the else block of the check on nofile will never be performed.
Example 6.18. Code from Apache Version 1.31 that is susceptible to a buffer overflow because of its use of unbounded string-manipulation functions.
![]()
if (nofile) {
i--;
}
else {
if (strlen(argv[i]) > (sizeof(pwfilename) - 1)) {
fprintf(stderr, "%s: filename too long
", argv[0]);
return ERR_OVERFLOW;
}
strcpy(pwfilename, argv[i]);
if (strlen(argv[i + 1]) > (sizeof(user) - 1)) {
fprintf(stderr, "%s: username too long (>%lu)
", argv[0],
(unsigned long)(sizeof(user) - 1));
return ERR_OVERFLOW;
}
}
strcpy(user, argv[i + 1]);
Luiz Carmargo reported this bug along with a group of similar issues related to the unsafe use of strcpy() and strcat() in the htpasswd.c script on the Full Disclosure mailing list in September 2004, but the issues went unpatched by the Apache team [Camargo, 2004]. In October 2004, Larry Cashdollar posted a note to the BugTraq mailing list indicating that the reported buffer overflow vulnerabilities had not been corrected as of Apache Version 1.33 and proposed a home-brew patch that he claimed corrected the vulnerabilities [Cashdollar, 2004]. Unfortunately the patch proposed by Cashdollar appears to have been created by simply searching for and replacing all calls to strcpy() and strcat() with strncpy() and strncat() [Howard “Blog,” 2006]. In some cases, this approach led to a successful fix, such as replacing the dangerous call to strcpy() from Example 6.18 with the following line:
strncpy(user, argv[i + 1], MAX_STRING_LEN - 1);
In other cases, things didn’t go quite as well. The code in Example 6.19 is from another area in the same program. It includes suspect calls to strcpy() and strcat(), which (following our own advice) should be replaced by calls to bounded functions. In this case, the conditional check immediately preceding this code prevents a buffer overflow, but this code should still be repaired.
Example 6.19. Unsafe calls to strcpy() and strcat() from Apache Version 1.31.
![]()
strcpy(record, user);
strcat(record, ":");
strcat(record, cpw);
However, the patch proposed by Cashdollar (shown in Example 6.20) also included an easy-to-overlook and potentially dangerous coding error. In the proposed patch, Cashdollar makes a relatively common mistake in his use of strncat() by assuming that the bound to the function represents the size of the destination buffer rather than amount of space remaining. Unless the destination buffer is empty, the bound will not limit the function to writing inside the allocated memory. In this situation, the vulnerability is still mitigated by a bounds check earlier in the code. However, the overall security risk is now increased because the earlier check might be removed because the bounded call to strncat() appears to render it redundant.
Example 6.20. Code from a patch intended to remedy the vulnerability in Example 6.19. Instead, this code misuses strncat() and is unsafe as well.
![]()
strncpy(record, user,MAX_STRING_LEN - 1);
strcat(record, ":");
strncat(record, cpw,MAX_STRING_LEN - 1);
If the bound is specified incorrectly, a bounded function is just as capable of causing a buffer overflow as an unbounded one. Although errors are easier to avoid with bounded functions, if a bounds error is introduced, the mistake might be harder for a human to spot because it is masked by a seemingly safer bounded function. Even when used correctly, bounded functions can truncate the data they operate upon, which can cause a variety of errors.
Table 6.6. Common Library Functions Banned in the Strsafe and Safe C/C++ Libraries


![]()
#define gets unsafe_gets
#define strcpy unsafe_strcpy
#define strcat unsafe_strcat
#define sprintf unsafe_sprintf
Structural rule
FunctionCall: function is [name == "strcpy"]
Severity: high
Common Pitfalls with Bounded Functions
Bounded string functions are safer than unbounded functions, but there’s still plenty of room for error. This section covers the following common pitfalls programmers encounter with bounded string functions:
• The destination buffer overflows because the bound depends on the size of the source data rather than the size of the destination buffer.
• The destination buffer is left without a null terminator, often as a result of an off-by-one error.
• The destination buffer overflows because its bound is specified as the total size of the buffer rather than the space remaining.
• The program writes to an arbitrary location in memory because the destination buffer is not null-terminated and the function begins writing at the location of the first null character in the destination buffer.
We first propose guidelines for avoiding these pitfalls with two of the most often misused bounded string-manipulation functions: strncpy() and strncat(). Then we address the broader topic of truncation errors, which can occur even when bounded functions are used correctly.
strncpy()
David Wagner and a group of students at UC Berkeley (Jacob was one of them) identified a series of common misuses of strncpy() (see Table 6.7 for a description of strncpy()) and used static analysis to identify instances of these errors in open source code [Schwarz et al., 2005]. The errors are representative of the types of mistakes related to strncpy() that we see in the field, which can be divided into two high-level groups:
• A call to strncpy() writes past the end of its destination buffer because its bound depends on the size of the source buffer rather than the size of the destination buffer.
• The destination buffer used in a call to strncpy() is left unterminated, either because no terminator is written to the buffer or because the null terminator is overwritten by the call to strncpy().
Table 6.7. Function prototype and description for strncpy() [ISO “C99,” 2005].

To avoid common errors with strncpy(), follow two simple guidelines:
• Use a safe bound—Bound calls to strncpy() with a value derived from the size of the destination buffer.
• Manually null-terminate—Null-terminate the destination buffer immediately after calling strncpy().
Although applying these guidelines decreases the chance that your code will be susceptible to a buffer overflow, they are not sufficient or always necessary to guarantee the safe use of strncpy(). There are any number of ways in which strncpy() can be used without introducing security vulnerabilities. Static bounds or bounds calculated from other dynamic sources can be safe in many circumstances, depending on the structure of the program and feasible execution paths. Proper bounds checks can guarantee that the range of input copied to a destination buffer will always contain a null terminator. Null-terminating or zeroing out the entire destination buffer and then bounding strncpy() to copy 1 byte less than the length of buffer will result in the destination being properly null-terminated. However, many of these usage patterns are error prone because they are more difficult for both humans and tools to verify and should be avoided. Instead, give preference to one simple and easy-to-verify convention.
The rest of this subsection uses real-world examples to demonstrate the importance of these guidelines.
Use a Safe Bound
Bound calls to strncpy() with a value derived from the size of the destination buffer. The pitfall this guideline addresses occurs when strncpy() is bounded by the size of its source rather than destination buffer, which effectively reduces its safety to that of strcpy(). The code in Example 6.21, from Version .80 of the Gaim instant messaging client, contains a remotely exploitable buffer overflow vulnerability. In the code, the call to strncpy() copies data from a user-controlled buffer into the 32-byte stack buffer temp. The buffer overflow can occur because the call to strncpy() is bounded by the number of characters encountered in the source buffer before a terminating character, which could exceed the capacity of the destination.
Example 6.21. An unsafe call to strncpy() from Gaim.
![]()
if (strncmp(status, "200 OK", 6))
{
/* It's not valid. Kill this off. */
char temp[32];
const char *c;
/* Eww */
if ((c = strchr(status, '
')) || (c = strchr(status, '
')) ||
(c = strchr(status, '�')))
{
strncpy(temp, status, c - status);
temp[c - status] = '�';
}
gaim_debug_error("msn", "Received non-OK result: %s
", temp);
slpcall->wasted = TRUE;
/* msn_slp_call_destroy(slpcall); */
return slpcall;
}
Bounding a call to strncpy() with the size of its source buffer rather than its destination is such a common mistake that it even appears in documentation designed to demonstrate proper coding practices. The code in Example 6.22 is from an MSDN documentation page for listing the files in a directory, but it includes a blatant misuse of strncpy() [Microsoft “Listing Files,” 2005]. The bound passed to strncpy(), specified as strlen(argv[1]) + 1, makes a buffer overflow trivial if an attacker passes a command-line argument to the program that is larger than MAX_PATH + 1.
Example 6.22. An unsafe call to strncpy() from MSDN documentation.
![]()
int main(int argc, char *argv[])
{
WIN32_FIND_DATA FindFileData;
HANDLE hFind = INVALID_HANDLE_VALUE;
char DirSpec[MAX_PATH + 1]; // directory specification
DWORD dwError;
printf ("Target directory is %s.
", argv[1]);
strncpy (DirSpec, argv[1], strlen(argv[1])+1);
...
}
Manually Null-Terminate
Null-terminate the destination buffer immediately after calling strncpy(). Because strncpy() fills any remaining space in the destination buffer with null bytes, programmers might mistakenly believe that strncpy() null terminates its destination buffer in all cases. The destination buffer passed to a call to strncpy() will be properly null-terminated only if the range of characters copied from the source buffer contains a null terminator or is less than the size of the destination buffer. Although this misuse does not directly result in a buffer overflow, it can cause a wide variety of buffer overflow vulnerabilities and other errors associated with unterminated strings. See the upcoming section “Maintaining the Null Terminator,” for a broader discussion of this topic.
The code in Example 6.23 is from Version 0.6.1 of the qmailadmin Web-based administration utility for the email server qmail. The code shows a subtle example of the second pitfall. Here, instead of null-terminating the destination buffer before the call to strncat(), the programmer relies on the buffer being null-terminated after the call to strncpy(). The problem is, the bound passed to strncpy() is the string length of the source buffer, strlen(TheUser), which doesn’t leave enough room for a null terminator. If rpath is left unterminated, the subsequent calls to strncat() could write outside the bounds of the destination buffer. This code was patched in a later version to specify the bound for strncpy() as strlen(TheUser) + 1 to account for the null terminator.
Example 6.23. This misuse of strncpy() can leave rpath unterminated and cause strncat() to overflow its destination buffer.
![]()
if ( *rpath == '$' )
{
rpath = safe_malloc( strlen(TheUser) + strlen(TheDomain) + 2);
strncpy( rpath, TheUser, strlen(TheUser) );
strncat( rpath, "@", 1 );
strncat( rpath, TheDomain, strlen(TheDomain) );
}
One way to ensure that destination buffers used in calls to strncpy() are always null-terminated is to replace the function with an alternative implementation that wraps a call to strncpy() with code that terminates its destination buffer. Alternatively, the strlcpy() function shown in Example 5.20 provides the same functionality as strncpy(), but guarantees that its destination buffer will always be null-terminated.
strncat()
Security-relevant bugs related to strncat()(see Table 6.8 for a description of strncat()) typically occur because of one of the following problems:
• A call to strncat() overflows its destination buffer because its bound is specified as the total size of the buffer rather than the amount of unused space in the buffer.
• A call to strncat() overflows its destination buffer because the destination buffer does not contain a null terminator. (The function begins writing just past the location of the first null terminator it encounters.)
Table 6.8. Function prototype and description for strncat() [ISO “C99,” 2005].

To avoid common misuse cases and errors using strncat(), follow two guidelines:
• Use a safe bound—Calculate the bound passed to strncat() by subtracting the current length of the destination string (as reported by strlen()) from the total size of the buffer.
• Null-terminate source and destination—Ensure that both the source and destination buffers passed to strncat() contain null terminators.
It is feasible that there are other ways to use strncat() safely, but unlike strncpy(), we don’t see many distinct conventions where programmers get it right.
We again call on real-world programs to demonstrate the motivation for the following guidelines.
Use a Safe Bound
Calculate the bound passed to strncat() by subtracting the current length of the destination string (as reported by strlen()) from the total size of the buffer. Most errors related to the misuse of strncat() occur because of the unusual interface it implements when compared with other string-manipulation functions with an n in their name. All the n functions accept a parameter that specifies the maximum amount of data they will write. In most cases, it is safe for this value to equal the size of the destination buffer. But the argument for strncat() must equal the amount of space remaining in the buffer.
In Example 6.24, we revisit code from a previous example that was proposed as a patch for vulnerable calls to the unbounded functions strcpy() and strcat() in Apache httpd. In addition to patching several known vulnerabilities, the developer who proposed the patch took it upon himself to replace all calls to string-manipulation functions of the form strXXX() with calls to strnXXX(). However, in the case of the code in Example 6.24, the addition of bounded calls to strncat() resulted in the introduction of a new error. The call to strncat() could overflow record, depending on the size of user and cpw, because its bound is specified as the total size of the buffer, which already contains the values of user.
Example 6.24. An unsafe call to strncat() from a patch proposed for Apache Version 1.31.
![]()
strncpy(record, user, MAX_STRING_LEN - 1);
strcat(record, ":");
strncat(record, cpw, MAX_STRING_LEN - 1);
Null-Terminate Source and Destination
Ensure that both the source and destination buffers passed to strncat() are null-terminated. This guideline addresses a misuse of strncat() caused by its unusual interface. Most string-manipulation functions do not impose any precondition requirements on the destination buffer. But in the case of strncat(), the programmer must ensure that the destination buffer passed to the function is properly terminated. If its destination buffer is not properly terminated, strncat() will search beyond the end of the buffer until it finds a null byte and proceed to copy data from the source to this arbitrary location in memory. Errors of this kind can be difficult to identify with short tests because, during a short test, memory is more likely to be zeroed out.
The code in Example 6.25 has been rewritten to correctly bound the calls to strncat(), but upon further inspection, the code contains another potential vulnerability. Depending on the length of user, the call to strncpy() might truncate the data copied into record and cause it to be unterminated when used as the destination buffer passed to the subsequent calls to strncat(). Next, we cover truncation errors such as this one.
Example 6.25. Code from Example 6.24 with correct bounds specified to strncat(), but truncation problems remain.
![]()
strncpy(record, user, MAX_STRING_LEN - 1);
strncat(record, ":", MAX_STRING_LEN - strlen(record) - 1);
strncat(record, cpw, MAX_STRING_LEN - strlen(record) - 1);
Truncation Errors
Even when used correctly, bounded string functions can introduce errors because they truncate any data that exceed the specified bound. Operations susceptible to truncation errors can either modify the original data or, more commonly, truncate the data in the process of copying the data from one location to another. The effects of truncation errors are hard to predict. Truncated data might have an unexpected meaning or become syntactically or semantically malformed so that subsequent operations on the data produce errors or incorrect behavior. For example, if an access control check is performed on a filename and the filename is subsequently truncated, the program might assume that it still refers to a resource the user is authorized to access. An attacker can then use this situation to access an otherwise unavailable resource.
Example 6.26 shows code from Version 2.6 of Squid, a popular open-source Web proxy cache. The code adds various parameters to a structure that represents a new server. After the primary domain controller and backup domain controller parameters, ParamPDC and ParamBDC, are tested using a DNS lookup, they are copied into the new server structure. Because the code does not perform checks on the length of ParamPDC or the other strings it operates on, they can be truncated by the bounded calls to strncpy(). If the strings are truncated, they are unlikely to represent valid server names, which contradicts the programmer’s expectation because calls to gethostbyname() on these names have already succeeded. Although the strings stored in the current element of ServerArray are valid null-terminated strings, they can cause unexpected and difficult-to-track-down errors elsewhere in the system. If attackers create malicious server entries designed to fail when Squid falls back on the server’s backup domain controller, they could induce unexpected behavior that is susceptible to other exploits or initiate a denial-of-service attack.
Example 6.26. These calls to strncpy() from Squid 2.6 could cause truncation errors.
![]()
void AddServer(char *ParamPDC, char *ParamBDC, char *ParamDomain)
{
...
if (gethostbyname(ParamPDC) == NULL) {
syslog(LOG_ERR, "AddServer: Ignoring host '%s'. "
"Cannot resolve its address.", ParamPDC);
return;
}
if (gethostbyname(ParamBDC) == NULL) {
syslog(LOG_USER | LOG_ERR, "AddServer: Ignoring host '%s'. "
"Cannot resolve its address.", ParamBDC);
return;
}
/* NOTE: ServerArray is zeroed in OpenConfigFile() */
assert(Serversqueried < MAXSERVERS);
strncpy(ServerArray[Serversqueried].pdc, ParamPDC, NTHOSTLEN-1);
strncpy(ServerArray[Serversqueried].bdc, ParamBDC, NTHOSTLEN-1);
strncpy(ServerArray[Serversqueried].domain, ParamDomain, NTHOSTLEN-1);
Serversqueried++;
}
The code in Example 6.27 demonstrates a string truncation error that turns into a string termination problem. The error is related to the use of the function readlink(). Because readlink() does not null-terminate its destination buffer and can return up to the number of bytes specified in its third argument, the code in Example 6.27 falls into the all-too-common trap of manually null-terminating the expanded path (buf, in this case) 1 byte beyond the end of the buffer. This off-by-one error might be inconsequential, depending on what is stored in the memory just beyond the buffer, because it will remain effectively null-terminated until the other memory location is overwritten. That is, strlen(buf) will return only one larger than the actual size of the buffer, PATH_MAX + 1 in this case. However, when buf is subsequently copied into another buffer with the return value of readlink() as the bound passed to strncpy(), the data in buf are truncated and the destination buffer path is left unterminated. This off-by-one-error is now likely to cause a serious buffer overflow.
Example 6.27. A call to strncpy() that could cause a truncation error because of confusion over the behavior of readlink().
![]()
char path[PATH_MAX];
char buf[PATH_MAX];
if(S_ISLNK(st.st_mode)) {
len = readlink(link, buf, sizeof(path));
buf[len] = '�';
}
strncpy(path, buf, len);
One of the most important decisions that governs how best to avoid truncation errors is whether your program employs static or dynamic memory allocation. Code that manipulates strings can be coded to dynamically reallocate buffers based on the size of the data they operate on, which is attractive because it avoids truncating data in most cases. Within the confines of the total memory of the system, programs that typically perform dynamic memory allocation should rarely find it necessary to truncate data.
Programs that employ static memory allocation must choose between two kinds of truncation errors. Neither option is as desirable as dynamic reallocation because either can result in the program violating the user’s expectations. If data exceed the capacity of an existing buffer, the program must either truncate the data to align with the available resources or refuse to perform the operation and demand smaller input. The trade-offs between truncation and controlled failure must be weighed. The simpler of the two options is to decline to perform the requested operation, which will not likely have any unexpected impact on the rest of the program. However, this can result in poor usability if the system frequently receives input that it cannot accommodate. Alternatively, if the program truncates the data and continues to execute normally, a variety of errors can ensue. These errors typically fall into two camps: The string might no longer convey the same meaning after it is truncated (refer to Example 6.26) or the string might become unterminated (refer to Example 6.27).
The moral of the story is this: Avoid truncating data silently. If the input provided is too large for a given operation, attempt to handle the situation gracefully by dynamically resizing buffers, or decline to perform the operation and indicate to the user what needs to happen for the operation to succeed. As a worst-case option, truncate the data and inform the user that truncation has occurred. The string functions in the Microsoft Strsafe and Safe CRT libraries make identifying and reporting errors easier. Both sets of functions implement runtime checks that cause the functions to fail and invoke customizable error handlers when truncation and other errors occur. This improvement over the quiet or silent failure seen with most standard string manipulation functions makes the Microsoft alternatives a significant step in the right direction.
Maintaining the Null Terminator
In C, strings depend on proper null termination; without it, their size cannot be determined. This dependency is fragile because it relies on the contents of the string to ensure that operations performed on it behave correctly. This section outlines common ways that unterminated strings enter a program, the kinds of errors they are likely to cause, and guidelines for avoiding them.
String termination errors can easily lead to outright buffer overflows and logic errors. These problems often become more insidious because they occur seemingly nondeterministically depending on the state of memory when the program executes. During one execution of a block of buggy code, the memory following an unterminated string variable might be null and mask the error entirely, while on a subsequent execution of the same block of code, the memory following the string might be non-null and cause operations on the string to behave erroneously. Bugs that depend on the runtime state of memory in a complex program are difficult to find and sometimes do not appear until the program reaches a production environment, where it executes for long periods of time and under more dynamic conditions than during testing.
Consider the code in Example 6.28: Because readlink() does not null-terminate its output buffer, strlen() scans through memory until it encounters a null byte and sometimes produces incorrect values for length, depending on the contents of memory following buf.
Example 6.28. An unterminated string introduced by readlink().
![]()
char buf[MAXPATH];
readlink(path, buf, MAXPATH);
int length = strlen(buf);
The ideal answer is to transition away from using C-style strings and move to a string representation that is less fragile. Because this transition is often impractical, programs that must continue to rely on null terminators should take precautions to guarantee that that all strings remain properly terminated. Such a goal is impossible to guarantee, but it can be approximated in a variety of ways, such as by creating secure wrapper functions around string-manipulation operations to guarantee that a null terminator is always inserted.
Improperly terminated strings are commonly introduced into a program in only a handful of ways.
• A small set of functions, such as RegQueryValueEx() and readlink(), intentionally produce unterminated strings. (See Chapter 5, “Handling Input,” for an implementation of a secure wrapper around readlink() designed to always null-terminate its destination buffer and handle long paths gracefully.)
• Certain functions that copy strings from one buffer to another, such as strncpy(), do so blindly, which causes the termination of the destination buffer to depend on the existence of a null terminator in the range of bytes copied from the source buffer. Example 5.20 shows the implementation of strlcpy(), which mimics the behavior strncpy(), but with the additional guarantee that its destination buffer will always be null-terminated.
• Functions that read generic bytes from outside the program, such as fread() and recvmsg(), can be used to read strings. Because these functions do not distinguish between strings and other data structures, they do not guarantee that strings will be null-terminated. When programmers use these functions, they might accidentally depend on the data being read to include a null terminator.
Never assume that data from the outside world will be properly null-terminated. In particular, when reading data structures that contain strings, ensure that the strings are properly null-terminated.
In addition to inserting a null terminator in situations in which a string might lose its terminator, avoid blindly relying upon proper null termination. (This is the primary motivator behind moving to the n or _s functions that constrain string length through an explicit parameter.)
When you must rely on null termination, such as with open() and unlink(), the safest approach is to manually null-terminate strings before using them. This raises a chicken-and-egg question: If the string is not properly terminated, where should the null terminator be placed? If possible, null-terminate the buffer at the last byte of allocated memory.
This is the best option for covering the following possible states the string could be in:
• If the string is shorter than the buffer and properly null-terminated, the addition of a null byte at the end of the string will have no effect on operations performed on the string, which will stop when they encounter the earlier null terminator.
![]()
• If the string is exactly as large as the buffer and properly terminated, the additional null byte will simply overwrite the existing null byte and leave the string effectively unchanged.
![]()
• If the string is not properly terminated, the addition of a null byte at the last byte of the buffer will prevent operations from miscalculating the length of the string or overflowing the buffer.
![]()
A common tactic for preventing string termination errors is to initialize an entire buffer to zero and then bound all operations to preserve at least the final null byte. This is a poor substitute for explicit manual termination because it relies on the programmer to specify correct bounds. Such a strategy is risky because every operation on the string provides another opportunity to introduce a bug.
Follow a strict approach to string termination to avoid the risk that a vulnerable operation appears to be safe. Explicitly terminate strings that could become unterminated before performing an operation that relies upon a null terminator. This can result in redundant code, but it will make it feasible to verify that the program does not contain string termination errors.
![]()
char input[MAX];
int amt = readRawInput(input, MAX-1);
if(ALWAYS_TERMINATE)
input[amt] = NULL;
for(int i = 1; i < argv; i++)
concatStrs(input, argc[i],
sizeof(input) - strlen(input))
Source rule
Function: readRawInput()
Postcondition: first argument is tainted and carries the NOT_NULL_TERMINATED taint flag
Pass-through rule
Function: assignment operator (lhs = rhs)
Postcondition: if lhs is an array and rhs == NULL, then the array does not carry the NOT_NULL_TERMINATED taint flag
Sink rule
Function: concatStrs()
Precondition: the first and second arguments must not carry the NOT_NULL_TERMINATED taint flag
Character Sets, Representations, and Encodings
This section begins with an introduction to the complex topic of character encoding.1 We begin by defining the set of terms and then discuss errors related to character encoding that frequently lead to buffer overflow vulnerabilities, which are particularly prevalent in functions that convert between strings represented in different data types and encodings.
Introduction to Characters
A character set is a collection of printable characters that usually correspond to the characters used in a written language. Over the years, different character sets have been defined to meet the demands placed on software as it permeates different parts of the world. The widely adopted Unicode standard is an attempt to provide unified support for the various character sets used throughout the world. The Unicode Standard [Davis et al., 2004] defines a universal character set that encompasses every major script in the world and a set of character encoding forms to store, manipulate, and share textual information between systems.
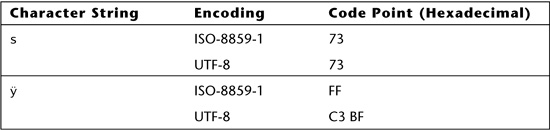
Characters are represented on computers using character encoding forms, which specify a mapping between integer values, called code points, and printable characters. Encodings are fundamentally divided into two groups: fixed width and variable width. Fixed-width encodings, such as ISO-8859-1 and UTF-32, use a fixed number of bits to represent every code point. Fixed-width encodings are uniform and, therefore, simpler for computers and programmers to manipulate. However, fixed-width encodings are not efficient if only a small range of the code points are used in a given string. Variable-width encodings, such as UTF-8 and UTF-16, overcome this problem by using fewer bits to represent some characters and more bits to represent others. Table 6.9 gives the code points for two characters as they are encoded using ISO-8859-1 and UTF-8. The first character, s, has the same code point in both encodings. The second character, ÿ, has a different code point (and a different width) depending on its encoding.
Table 6.9. Code points for two characters encoded in fixed-width and variable-width encodings.
Variable-width encodings can make operating on character strings more difficult because a series of bits, known as a code value, can represent either a valid code point (and, therefore, a character) or an invalid code point, indicating that it must be combined with one or more subsequent code values to form a surrogate pair before the character can be decoded. This difficulty is mostly negated by some variable-width encodings, such as UTF-16, which are designed so that the range of code values used to form the high and low values in surrogate pairs are entirely disjoint from one another and from single units. This property ensures that a stream of UTF-16 characters can be properly decoded starting from any point in the stream and that a dropped code value will corrupt only a single character.
When you move beyond the widely used ISO-8859-1 US-ASCII encoding, the most widely used character-encoding forms are those defined the Unicode standard, whose names begin with Unicode Transformation Format (UTF), and their siblings defined by the International Organization for Standardization (ISO), whose names begin with Universal Character Set (UCS). By convention, UTF encodings are appended with the maximum number of bits they use to represent a code value. For example, the widely used UTF-16 encoding is a variable-width character encoding that is capable of representing every possible Unicode character using code points consisting of either one or two 16-bit code values. Closely related to UTF-16, the UCS-2 encoding is a fixed-width character encoding that corresponds exactly to the valid 16-bit code points in UTF-16. Today UTF-16 is the de facto standard used to represent strings in memory on modern Windows operating systems, the Java and .NET platforms, and a variety of other systems.
On an interesting historical note, the character set represented by UCS-2, known as the Basic Multilingual Plane (BMP), was the widely accepted standard until China began requiring that software sold there support a character set known as GB18030, which includes characters outside the BMP [IBM, 2001].
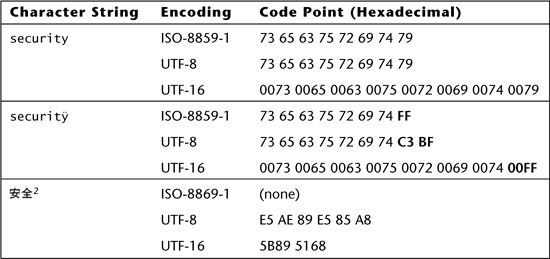
Table 6.10 shows several simple character strings and their corresponding hexadecimal code point values in various encodings. Because different encodings support different character sets, some encodings are not capable of representing certain characters. Also notice that the code points for many characters overlap between different encodings, but that in some cases they differ. This is a side effect of the natural evolution of encodings toward support for larger character sets and a desire to change as few existing code point values as possible.
Table 6.10. Simple strings and their corresponding code point values in various encodings.
Ostensibly independent of the character set and encoding used, programs use different data types to represent strings. For comprehensiveness, we include a discussion of character data types in Java as well as C and C++. In Java, the story regarding data types is relatively straightforward. All strings are represented in memory as UTF-16 characters. The char and Character data types always store 16-bit UTF-16 characters and, therefore, cannot represent characters outside of the BMP [Sun “Internalization,” 2006]. When stored in one of these data types, code values that are part of a surrogate pair are invalid when processed as a single code point. As of Java 1.0, functions that operate on sequences of characters are designed to handle all UTF-16 code point values, including those represented as surrogate pairs [Sun “Supplementary Characters,” 2004]. Functions that operate directly on code points represent them using the int type, which is large enough to handle the full range of UTF-16 code points.
In C and C++, data types are more independent from specific character-encoding forms, which the specification leaves at the discretion of the implementation [ISO “C99,” 2005]. The char data type can be used to store single-byte characters, where one char holds the representation of a single printable character or to represent variable-width multibyte character strings, where a variable number of char elements represents each printable character. Because the char data type is not suitable to represent the 16-bit characters used in UTF-16 and other common encodings, the C90 standard was revised to include the new wchar_t data type, which, by definition, is required only to be capable of representing the basic character set but, in practice, is defined to be 16 bits on Windows and some UNIX platforms, and 32 bits on GNU Linux platforms [FSF, 2001]. The WCHAR data type is a Windows-specific equivalent defined to be synonymous with wchar_t.
To further complicate things, strings in C and C++ are referred to by different names depending on the type of characters they hold. The term multibyte string typically refers to a string consisting of char elements in which sequences of one or more of the elements correspond to single printable characters. Likewise, the term wide character string refers to a similar string consisting of wchar_t elements. This distinction is somewhat muddled in Windows environments, where Unicode is often used incorrectly to refer to UTF-16 encoded strings. It is not uncommon for discussions of string handling to include only references to multibyte and Unicode strings, with no mention of any specific character encoding. As with other common points of confusion in C, buffer overflow vulnerabilities are often the result.
Characters and Buffer Overflow Vulnerabilities
Most buffer overflow errors specifically related to character-encoding issues occur because of a mismatch between size in bytes of a character and the units used to bound operations on a string composed of those characters. If characters can span multiple bytes, the difference between the number of bytes in a string and the number of characters in a string can be significant. When an operation that expects its bound in bytes is passed a bound in characters, it can severely truncate the data on which it operates. In the opposite direction, when a function that expects its bound in characters is passed a bound in bytes, it can result in a buffer overflow that writes well beyond the allocated bounds of memory.
The risk of errors related to bounds specified in the wrong units is magnified in the case of functions that convert between one encoding and another. Some of these functions accept two bounds, one in bytes and one in characters. Refer to Table 6.11 for a summary of the functions Windows provides to convert between multibyte character strings (usually US-ASCII) and wide character (Unicode in the Windows world) strings.3 Notice that the bounds passed to these functions are specified in different units—one in bytes, the other in characters—making them prone to buffer overflows. Even when only a bound on data written to the destination is accepted, confusion over whether the units correspond to the data type of the source or the destination can lead to errors. Table 6.12 summarizes the functions found on Linux and UNIX platforms to support conversion between multibyte and wide character strings.
Table 6.11. Function prototypes and descriptions for Windows string-conversion Functions from MSDN.
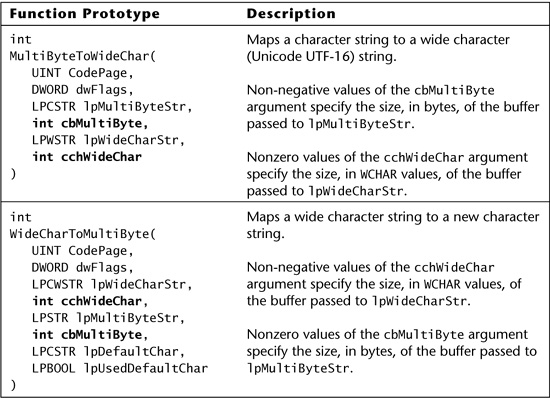
Table 6.12. Function prototypes and descriptions for standard C string-conversion functions from the ISO C99 Standard [ISO “C99,” 2005].
For an example of how easy it is to become confused when working with strings represented with different encodings and data types, consider the function in Example 6.29. The getUserInfo() function takes a username specified as a multibyte string and a pointer to a structure that represents user information, which it populates with information about the specified user. Because Windows authentication uses wide character strings to represent usernames, the username argument is first converted from a multibyte string to a wide character string. The function incorrectly passes the size of unicodeUser in bytes instead of characters. The call to MultiByteToWideChar() can therefore write up to (UNLEN+1)*sizeof(WCHAR) wide characters, or (UNLEN+1)*sizeof(WCHAR)*sizeof(WCHAR) bytes, to the unicodeUser array, which has only (UNLEN+1)*sizeof(WCHAR) bytes allocated. If the username string contains more than UNLEN characters, the call to MultiByteToWideChar() will overflow the buffer unicodeUser. The last argument to MultiByteToWideChar() should have been sizeof(unicodeUser)/ sizeof(unicodeUser[0]). No fun.
Example 6.29. In this unsafe call to MultiByteToWideChar(), the bound is specified in bytes instead of characters.
![]()
void getUserInfo(char *username, struct _USER_INFO_2 info){
WCHAR unicodeUser[UNLEN+1];
MultiByteToWideChar(CP_ACP, 0, username, -1,
unicodeUser, sizeof(unicodeUser));
NetUserGetInfo(NULL, unicodeUser, 2, (LPBYTE *)&info);
}
Format Strings
Format string errors occur when user input is allowed to influence the format string argument to certain string formatting functions. In this section, we give a brief background on format string vulnerabilities and outline the ways they often occur. In the sidebar at the end of the section, we walk through a typical format string exploit to demonstrate how attackers take advantage of these vulnerabilities.
To give you a preview, we begin with a real-world example. The code in Example 6.30 contains a classic format string vulnerability from the popular FTP daemon wuftpd (which has suffered from numerous vulnerabilities.) One of the program’s best-known format string vulnerabilities was found in the way the lreply() function is invoked in Version 2.6.0, which, in a simplified form, looks like the code in Example 6.30. In the vulnerable code, a string is read from a network socket and passed without validation as the format string argument to the function vsnprintf(). By supplying specially crafted command to the server, an attacker can remotely exploit this vulnerability to gain root privileges on the machine.
Example 6.30. A classic format string vulnerability from wuftpd 2.6.0.
![]()
while (fgets(buf, sizeof buf, f)) {
lreply(200, buf);
...
}
void lreply(int n, char *fmt, ...) {
char buf[BUFSIZ];
...
vsnprintf(buf, sizeof buf, fmt, ap);
...
}
We explain format string vulnerabilities in detail, but first a few words about the public history of format string vulnerabilities.
From a historical perspective, new varieties of vulnerabilities don’t come around very often. Unlike virus researchers, software security researchers do not get to identify new root-cause vulnerabilities every day or even every year, but when they do, it’s likely to be relevant for years to come. This was the case with format string vulnerabilities, which were first identified in the wild starting in 1999. The industry had been talking about buffer overflow vulnerabilities for over a decade, but when format string vulnerabilities began to be widely exploited in 2000, a widespread weakness that had always been present in C and C++ suddenly came into the spotlight, and a lot of software was affected:
• Apache with PHP3
• *BSD chpass
• IRIX telnetd
• Linux rpc.statd
• NLS / locale
• Qualcomm Popper 2.53
• screen
• wu-ftpd 2.*
In these programs and others, an attacker supplies the vulnerable program with input that the program later includes in a format string argument. To understand how formatted string functions are misused, consider the formatted output function printf(). The format string that printf() accepts as its first parameter is representative of most format strings. The ISO C99 Standard describes the format string passed to printf() as follows:
The format string is composed of zero or more directives: ordinary characters (not
%), which are copied unchanged to the output stream; and conversion specifications, each of which results in fetching zero or more subsequent arguments. Each conversion specification is introduced by the character%and ends with a conversion specifier. [ISO “C99,” 2005]
String formatting functions in C and C++, such as printf(), are designed to be as flexible as possible. Because valid format strings are not required to contain directives or conversion specifications, the format string argument can be used to process strings that require no formatting. Any parameters beyond the format string that would correspond to format directives or conversion specifications must be optional. This flexibility, which, at its core, is a type problem, leads programmers to take seemingly innocuous shortcuts, such as writing printf(str) instead of the more verbose printf("%s", str). Sometimes these shortcuts are so ingrained that programmers might not even realize that the function they are using expects a format string. Although this often results in outwardly correct behavior because standard characters are simply passed through the format string unchanged, it is also the most common way that format string vulnerabilities occur.
If user input can influence the contents of the format string parameter, an attacker might be able to include malicious conversion specifications in a string that the programmer assumes will contain none. In the most benign case, an attack will include conversion specifications designed to read arbitrary values off the stack and provide unauthorized access to sensitive information. In the more serious and commonly exploited case, the attacker uses the %n directive to write to arbitrary positions in memory. (See the sidebar “A Classic Format String Attack” later in this section for an explanation of how attacks based on the %n directive work.) When an attacker can alter values in memory, all the usual exploits for buffer overflow vulnerabilities become viable, which most often include overwriting the return address of the current stack frame, changing the value of a function pointer, or modifying other important values that govern the behavior of the program.
Although the complexity and variety of possible exploits is large, most format string vulnerabilities can be prevented by choosing the most restrictive of the following guidelines possible in your environment:
• Always pass a static format string to any function that accepts a format string argument.
• If a single static format string is too restrictive, define a set of valid format strings and make selections from this safe set. Accept the added program complexity of selecting from a fixed set of static format strings over the risk that a dynamically constructed string will include unchecked user input.
• If a situation truly demands that a format string include input read from outside the program, perform rigorous whitelist-based input validation on any values read from outside the program that are included in the format string.
Example 6.31 demonstrates how the simplified wuftpd code from Example 6.30 could be rewritten to safely use a static format string.
Example 6.31. Code from Example 6.30 refactored to use a static format string.
![]()
while (fgets(buf, sizeof buf, f)) {
lreply(200, "%s", buf);
...
}
void lreply(int n, const char* fmt, ...) {
char buf[BUFSIZ];
...
vsnprintf(buf, sizeof buf, fmt, ap);
...
}
Better String Classes and Libraries
Like the language itself, native strings in C were designed to value efficiency and simplicity over robustness and security. Null-terminated strings are memory efficient but error prone. In this section, we discuss string libraries (many of which provide alternative string representations) that can eliminate many of the causes of buffer overflow vulnerabilities in string handling code.
Alternatives to native C strings do not need to claim security as a feature to prevent buffer overflows. If you are using C++, use the string representation defined in the standard STL namespace as std::string. The std::string class provides a layer of abstraction above the underlying string representation and provides methods for performing most string operations without the risk of introducing buffer overflow vulnerabilities. Example 6.32 shows a simple block of code that uses std::string to count the number of occurrences of term in a line of input.
Example 6.32. Code that uses std::string to count the number of occurrences of a substring in a line of input.
![]()
std::string in;
int i = 0;
int count = 0;
getline(cin, in, '
'),
for(i = in.find(term, 0); i != string::npos; i = in.find(term, i)) {
count++;
i++;
}
cout<<count;
In Microsoft environments where the use of the STL is frowned on, the ATL/MFC CString string class and CStringT template class provide effective handling of strings and should be used to avoid many of the risks of buffer overflow inherent in C-style strings. Example 6.33 shows the same block of code from Example 6.32 rewritten to use CString.
Example 6.33. Code that uses ATL/MFC CString to count the number of occurrences of a substring in a line of input.
![]()
CString line;
int i = 0;
int count = 0;
f.ReadString(line);
for(i = line.Find(term, 0); i = line.Find(term, i); i != -1, i) {
count++;
i++;
}
cout << count;
A variety of alternative string handling libraries and representations exist for C, but none is widely used. For the most part, programmers continue to use native C strings and hope they get things right. Bad idea. Selecting a string representation that makes it easier to avoid buffer overflows makes it easier to write code that’s more secure and offers other benefits as well. As with the std::string class, many C alternatives to null-terminated strings that are designed to address programming concerns, such as performance overhead in manipulating large amounts of data, also reduce the risk of buffer overflow vulnerabilities. Depending on the types of string operations you perform, you might see performance improvements from moving to a different string representation.
For example, the Vstr library is designed to work optimally with readv() and writev() for input and output. The library provides a variety of features related to common IO tasks, as well as other common string-manipulation tasks, such as searching, parsing, and manipulating strings. Example 6.34 shows a simple block of code from the Vstr tutorial that prints the string "Hello World" using the Vstr library [Vstr, 2003].
Example 6.34. An implementation of a “Hello World” program that uses the Vstr library.
![]()
int main(void) {
Vstr_base *s1 = NULL;
if (!vstr_init()) /* initialize the library */
err(EXIT_FAILURE, "init");
/* create a string with data */
if (!(s1 = vstr_dup_cstr_buf(NULL, "Hello World
")))
err(EXIT_FAILURE, "Create string");
/* output the data to the user */
while (s1->len)
if (!vstr_sc_write_fd(s1, 1, s1->len, STDOUT_FILENO, NULL))
{
if ((errno != EAGAIN) && (errno != EINTR))
err(EXIT_FAILURE, "write");
}
/* cleanup allocated resources */
vstr_free_base(s1);
vstr_exit();
exit (EXIT_SUCCESS);
}
If your biggest concern is avoiding buffer overflow vulnerabilities, a library specifically designed to address security concerns is probably your best bet. The SafeStr library is designed to make string operations simple and safe, and is easier to use in most circumstances than more heavy-weight libraries such as Vstr. Example 6.35 prints the string "Hello World" using the SafeStr library [SafeStr, 2005].
Example 6.35. An implementation of a “Hello World” program that uses the SafeStr library.
![]()
safestr_t fmt, str;
fmt = safestr_create("%s", 0);
str = safestr_create("Hello World", 0);
safestr_fprintf(stdout, fmt, str);
Any solution for handling strings that permits you avoid direct interaction with null-terminated strings will improve your chances of avoiding buffer overflow vulnerabilities. Choose a string library or representation whose features most closely align with the types of string operations you perform. Remember, avoiding buffer overflows could only be one of the benefits of moving away from native C strings. Refer to Table 6.13 for an overview of several string libraries for C available on GNU/Linux and Microsoft platforms.
Table 6.13. Alternative string solutions for C under GNU/Linux and Microsoft Windows.

Pass-through rule
Function: safestr_create()
Postcondition: return value is tainted if the first argument is tainted
![]()
safestr_t str;
str = safestr_create(argv[0], 0);
printf( (char*) str);
Remain cautious: Buffer overflows can and will occur as long as you are using a language that is not memory safe. In particular, watch out for errors introduced when you are forced to convert from your safe string representation back to native C strings. (Such conversions are often necessary when calling APIs that do not support the alternate string representation, such as low-level filesystem operations and other system calls.) Limit your exposure by retaining the high-level representation of the string for as long as possible and extracting the more dangerous C-style string only as it is needed for specific operations. Avoid any unnecessary manipulation of C-style strings in your program, and you will greatly minimize the risk of buffer overflow vulnerabilities.
Summary
Just because you and your colleagues can’t exploit a given vulnerability, don’t assume that the bad guys won’t. Use the advice in this chapter to avoid or remediate every possible buffer overflow vulnerability—obviously exploitable or not.
When it comes to C strings, the deck is stacked against the programmer. Not only does their representation make it difficult to prevent errors, but the standard library provided for manipulation them contains functions that range from difficult to impossible to use safely. Learn which functions are dangerous and why so that you can eradicate them from any code you touch. Even bounded functions, designed to add an element of safety, can introduce a variety of errors that range from truncating data, to introducing unterminated strings, to outright buffer overflows. Don’t let your guard down just because you see a bound on a string operation. Pay extra attention to functions that manipulate strings made up of characters larger than a single byte. Seemingly simple calculations such as the size of a string or buffer can become much more difficult when a single byte may not hold a whole character.
Be careful about what you let the user control. In addition to obvious dangers, such as an attacker controlling the bound on a string operation or the source buffer to an unbounded operation, including user input in a format string makes your program vulnerable. Sophisticated attackers can do just as much damage with a format string vulnerability as they can with any other buffer overflow. Use static format strings whenever possible and perform rigorous input validation whenever user input must be included in a format string.
Consider using an alternative string library. String libraries are a great solution for preventing many buffer overflow vulnerabilities because they abstract away best practices for safe string operations, making it easy to do things the right way. Anything that makes safe operations easier to perform than unsafe ones will make your program more secure and take more pressure off programmers.