
8
Incident Management
This chapter discusses where and how a public key infrastructure compromise might occur and the steps necessary to prepare for such an incident. Incident management includes preparing a PKI incident response plan and executing the plan in the event of a breach. Thus far in this book, we have alluded to security incidents in a variety of ways:
- Chapter 2, “Cryptography Basics,” identified key compromise as a type of incident.
- Chapter 4, “PKI Management and Security,” addressed incidents in the certificate policy and certificate practice statement.
- Chapter 5, “PKI Roles and Responsibilities,” discussed incidents and separation of duties.
- Chapter 6, “Security Considerations,” mentioned incidents relating to physical and logical security controls.
- Chapter 7, “Operational Considerations,” discussed incidents affecting PKI operations including disaster recovery plans.
Incidents can originate from insider threat or external attacks, system or application misconfigurations, software or hardware failures, zero-day faults, and other vulnerabilities. Components of incident management include monitoring, response, discovery, reporting, and remediation. To begin the incident management discussion, let’s first look at the areas of a PKI where a compromise might occur and the impact it has to an organization.
8.1 Areas of Compromise in a PKI
If we initially look at the areas that can be compromised in a PKI, it will give us an idea on how to respond if a compromise or breach occurs, and it will provide an idea of what should be in a PKI incident response plan. Because it is difficult to determine when a compromise occurred and because certificate issuance dates can be predated, any compromise puts the existing certificate population in question. We now consider the impact of compromise at various areas within the PKI starting at the root certificate authority (CA) and working through the hierarchy (Figure 8.1).
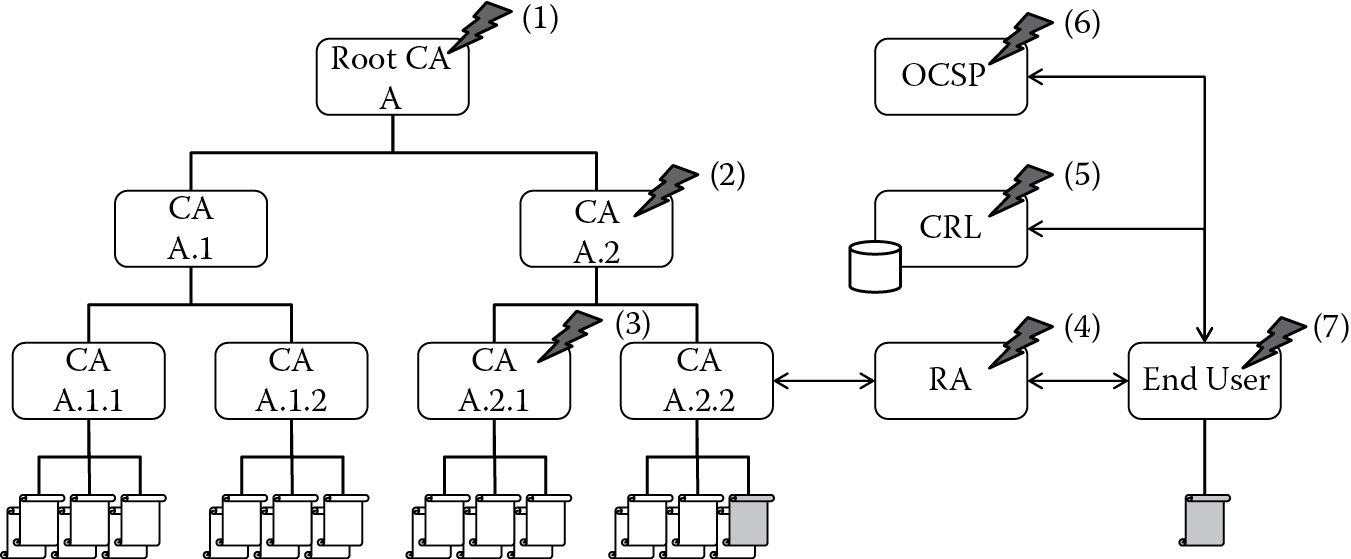
8.1.1 Offline Root CA
As shown in Figure 8.2, the compromise of an offline root CA private key (A) that has two subordinate CA trees (A.1, A.1.1, A.1.2 and A.2, A.2.1, A.2.2)—this scenario negates all of the certificates issued under the hierarchy of the root CA including all of the online issuing CA certificates and all end-user certificates that the online issuing CAs issued. This is a worst-case scenario and amounts to the most severe disaster of a PKI system.
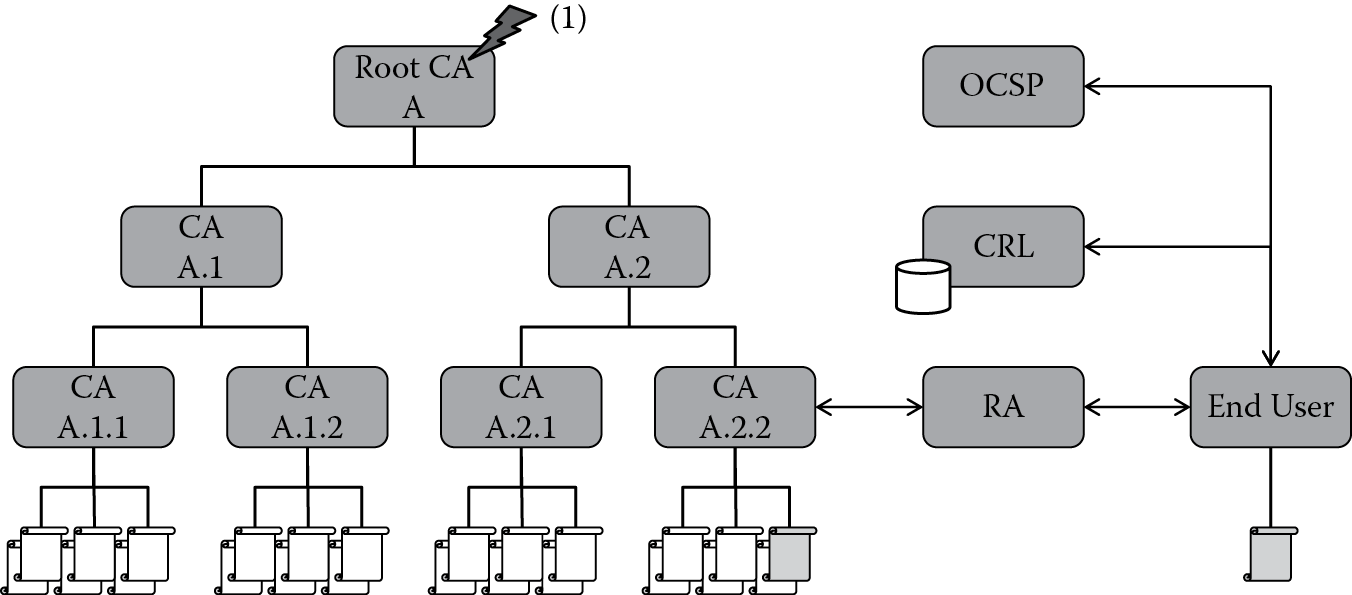
All of the CA and end-user certificates would need to be revoked, if you have the ability to issue an updated certificate revocation list (CRL) and Online Certificate Status Protocol (OCSP) capabilities available that should take top priority. Alerting all subscribers of the breach and compromise is the first order of business. Being able to alert all of the relying parties of the compromise by providing revocation information on the root CA certificate should prevent any reliance on the end-entity certificates for all subscribers who are following best practices and checking the validity of the certificate chain. Being able to revoke all CA certificates and all end-entity certificates is that much better in communicating the compromise. Building the completely new PKI infrastructure beginning with a new root key generation all the way down should be the second priority.
8.1.2 Online Issuing CA That Has Multiple CA Subordinates
As shown in Figure 8.3, the compromise of an online issuing CA private key (A.2) that has two subordinate CAs (A.2.1 and A.2.2) under it negates all of the certificates and CRLs issued under the hierarchy of the online issuing CA certificates and all of the associated end-user certificates. In this case, the root CA (A) is not compromised, and the offline root can revoke the subordinate online issuing CA (A.2) certificate and update the CRL and OCSP information. Then all of the associated subordinate CA and all descending end-user certificates would need to be revoked and reissued.

Online issuing certificate authority compromise that has multiple subordinate certificate authorities.
8.1.3 Online Issuing CA That Does Not Have Subordinate CAs
As shown in Figure 8.4, the compromise of an online issuing CA private key (A.2.1) that has no subordinate CA negates all of the end-user certificates issued under the hierarchy of that CA. In this case, the issuing CA (A.2) is not compromised and can revoke the subordinate online issuing CA (A.2.1) certificate and update the CRL and OCSP information with the subordinate CA revocation information. Then all of the associated end-user certificates would need to be revoked and reissued.

8.1.4 Online RA
If we go back to Figure 8.1 and look at other areas of compromise, we can explore some of the supporting roles of the PKI. First, we will consider the compromise of an online registration authority (RA). This compromise allows unauthorized approval of counterfeit end-user certificates and puts suspicion on all end-user certificates under the hierarchy that were requested from that RA of the online issuing CA that the RA is authorized by. In this case, the RA certificate would need to be revoked, and all of the associated end-user certificates requested from that RA would need to be revoked and reissued. If the time of compromise of RA is known, and that is a big if, then only the end-user certificates during that time period would need to be revoked and reissued.
8.1.5 Online CRL Service HTTP or HTTPS Location for Downloading CRLs
Yet again, as shown in Figure 8.1, the compromise of the CRL service allows denial of service or unauthorized addition, deletion, or modification of files. How you host CRL information may include a Hypertext Transfer Protocol (HTTP) or Hypertext Transfer Protocol Secure (HTTPS) server; this server’s operating system (OS) can be susceptible to attack and compromise. You need to consider what impact there would be to internal and external relying parties. If incorrect or no CRL information was available, what would be the impact to the users? While a counterfeit CRL cannot have a valid signature (unless the CA was likewise compromised), a relying party might (1) ignore the unavailable or invalid CRL and accept the end-user certificate, which is a poor practice, or (2) consider the certificate invalid and deny the transaction initiated by the certificate, which is a correct practice but can result in a denial of service.
8.1.6 OCSP Responder
Once more as shown in Figure 8.1, the compromise of the OCSP responder private key allows false responses to certificate status inquires. Revoked certificates can be made valid, valid certificates can be revoked, or no status can be returned. An OCSP denial of service can also be perpetrated. The OCSP responder certificate must be revoked, and new OCSP responder keys must be generated, and a new OCSP responder certificate must be issued from the CA that originally issued the OCSP responder certificate.
8.1.7 End User’s Machine That Has a Certificate on It
And finally as shown in Figure 8.1, the compromise of the end-user private key, depending on its usage, allows an adversary to falsify signed messages or decrypt intercepted messages. The end-user certificate would need to be revoked and reissued.
Microsoft has built two charts for categorizing PKI compromises with severity and suggested actions for Microsoft CAs. They are presented in Table 8.1 and Table 8.2.
Microsoft TechNet Example Actions for Server Operating System Compromise
|
Compromise Type |
CA Type |
Attack Type |
Key Integrity |
Severity |
Actions |
|
Server OS compromise |
Offline |
Physical |
Known good |
2 |
Replace server hardware and restore backup. Renew CA keys for entire chain. Force new issuance of end-entity certificates. |
|
Unknown/compromised |
1 |
Retire CA server. Complete CA server replacement and HSM reinitialization. |
|||
|
Online |
Remote/vulnerability |
Known good |
4 |
Patch exploited vulnerability. Use existing server hardware and restore backup. |
|
|
Unknown/compromised |
3 |
Patch exploited vulnerability. Use existing server hardware and restore backup. Revoke CA certificate and publish root CRL. Renew CA key. Force new issuance of end-entity certificates. |
|||
|
Physical |
Known good |
3 |
Replace server hardware and restore backup. |
||
|
Unknown/compromised |
2 |
Replace server hardware and restore backup. Revoke CA certificate and publish root CRL. Renew CA key. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
Microsoft TechNet Example Actions for Cryptographic Compromise
|
Compromise Type |
CA Type |
Category |
Attack Type |
Severity |
Actions |
|
Server OS compromise |
Offline |
Mathematic |
Brute force |
2 |
Use existing server hardware. Renew CA keys for entire CA chain. Use a larger key size. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
|
Algorithm weakness |
2 |
Use existing server hardware. Renew CA keys for the entire CA chain. Use an uncompromised algorithm. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
|||
|
Logical |
MTM or Shim |
1 |
Retire CA server. Complete CA server replacement and HSM reinitialization. Force new issuance of end-entity certificates. Revoke subordinate CAs and publish final CRL. Add CA certificate to untrusted store. |
||
|
Online |
Mathematic |
Brute force |
3 |
Renew CA keys for the entire CA chain. Use a larger key size. Revoke CA certificate and publish root CRL. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
|
|
Algorithm weakness |
3 |
Renew CA keys for the entire CA chain. Use a larger key size. Revoke CA certificate and publish root CRL. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
|||
|
Logical |
OS vulnerability |
2 |
Replace server hardware and restore backup. Revoke CA certificate and publish root CRL. Renew CA key. Force new issuance of end-entity certificates. Add CA certificate to untrusted store. |
||
|
MTM or Shim |
3 |
Patch exploited vulnerability. Use existing server hardware and restore backup. Revoke CA certificate and publish root CRL. Renew CA key. Force new issuance of end-entity certificates. |
The compromise of these points within the PKI can be organized into four main categories that should be considered: (1) private key compromise, (2) private key access, (3) limited access to the private key, and (4) other attacks. We will now review each of these categories.
8.1.7.1 Private Key Compromise
This is where an attacker has gained access to a copy of the CA or RA’s private key and can fraudulently sign information, such as
- CA distributed PKCS #12 file containing the CA private key exported from the hardware security module (HSM)
- CA-issued code-signing certificate to fraudulently sign any executable code
- RA requests for certificates to obtain counterfeit certificates
- RA requests for revocations to illegally revoke legitimate certificates
Therefore, when a CA is compromised, the investigator must assume that every certificate issued by that CA is potentially compromised as well. If the CA is a root CA or an intermediate issuing CA, then all of the CA certificates and all of the certificates that any subordinate CA issues must also be considered to be compromised. A full private key compromise could result from an operating system compromise or a cryptographic compromise. Both of these compromises are covered here.
There are a number of attack vectors for the operating system of a CA server, and the response depends on many factors. Operating systems can be compromised physically or remotely.
Examples of physical attacks involve an attacker gaining access to a server by using the console due to
- An unlocked server
- An attack against credentials
- An insider attack using stolen or known good credentials
- The use of storage media to inject an exploit or create a unique bootable operating system partition to make changes to the primary operating system drive
Both offline and online CA server types are susceptible to physical attack, whether it is by an intruder, an insider attack, or an unknowing person via a social engineering attack or infected file transfer device. If an offline CA is kept offline, it is not susceptible to remote attacks. However, online CA servers as well as web servers responsible for enrollment services or enrollment validation are susceptible.
Examples of remote attacks are
- Brute force attacks against credentials to gain access using remote desktop services or other remote management tools
- Utilizing an operating system vulnerability to gain access to a system
- Malware introduced by an operating system vulnerability or an unknowing person with access to the system being coerced into installing the malware
For CA servers, regardless of whether the operating system compromise is physical or remote, the severity of the compromise and the corresponding response depends on whether the private key integrity is known to be good or if the key integrity is unknown or compromised.*
Another attack vector that can lead to full key access is a cryptographic compromise of the underlying PKI algorithms. For each public key, there is only one mathematically unique private key, and the algorithms to generate keys, generate digital signatures, and perform encryption and decryption are well known. Researchers or persistent attackers can dedicate multiple servers and build testing algorithms to determine the private key by brute force. If a weakness is found in an algorithm used by the CA or weak keys are used, the weakness could be further exploited to identify the private key or issue certificates that appear to come from the CA.
8.1.7.2 Private Key Access
When an attacker or malicious insider has gained access to a CA or RA private key from an operating system compromise, the CA or RA may not have sufficient information to determine which certificates need to be revoked. This is one of the most difficult incidents to recover from because the human tendency is to keep the CA or RA in operation. The recovery options are (1) revoke the fraudulent certificates and leave the CA or RA certificate in use or (2) revoke everything including the CA or RA certificate and rebuild the compromised system.
8.1.7.3 Limited Access to the Private Key
If an attacker gains access to a CA or RA and is able to request or issue certificates, but the breach was recorded at the time and date of the unauthorized certificates, then in this situation, revocation of the unauthorized certificates is possible.
8.1.7.4 Other Attacks
This category includes other attacks such as denial of services (DoS) and theft. DoS may block PKI services preventing the issuance of new certificates or interfere with certificate validation by obstructing access to CRL location or the OCSP responder. Theft of a CA or RA server that has access to an HSM protecting the CA or RA’s private key might allow unauthorized access to the CA or RA private keys. Theft of the HSM itself might compromise the CA or RA private key depending on the sophistication of the attacker, the simplicity of the HSM, and the resources available to the attacker. Loss or theft of a remote access device might allow unauthorized access to the CA or RA systems or the HSM protecting the private keys.
Thus far, we have looked at PKI hierarchy compromise areas, the Microsoft PKI compromise charts, and compromise categories. Now that we understand the points that can be attacked and the compromises that could happen, it is time to look at building and maintaining an incident response plan to cope with a potential PKI compromise.
8.2 PKI Incident Response Plan
As discussed with business continuity and disaster recovery in Chapter 7, “Operational Considerations,” an incident response plan allows an organization to take coordinated action when a security breach occurs. The PKI incident response team must have the correct processes and procedures in place to respond to a PKI-related incident and execute the six basic steps of any incident response plan:
Step 1: Preparation
Step 2: Detection
Step 3: Containment
Step 4: Eradication
Step 5: Remediation
Step 6: Follow-up
In August 2012, the National Institute for Standards and Technology (NIST) released an update to its Computer Security Incident Handling Guide†—Special Publication 800-61. This is the third revision to the guide and offers guidance on issues that have arisen since the previous release in March 2008. This current guide addresses new technologies and attack vectors and changes the prioritization criteria for incident response and facilitating information sharing. There is currently no specific section on PKI incidents, but the guide can be used as a good example for building a specific PKI incident response plan. The old NIST guide had a small set of five categories of incidents:
- Denial of Service
- Malicious Code
- Unauthorized Access
- Inappropriate Usage
- Multiple Component
The new guide has taken these categories and replaced them with the new concept of an attack vector. An attack vector is how an attacker might carry out the attack. The vectors included in the updated guide are
- External / Removable Media: An attack executed from removable media or a peripheral device
- Attrition: An attack that employs brute force methods to compromise, degrade, or destroy systems, networks, or services
- Web: An attack executed from a website or web-based application
- E-mail: An attack executed via an e-mail message or attachment
- Impersonation: An attack involving replacement of something benign with something malicious, for example, spoofing, man in the middle attacks, rogue wireless access points, and SQL injection attacks, all involving impersonation
- Improper Usage: Any incident resulting from violation of an organization’s acceptable usage polices by an authorized user
- Loss or Theft of Equipment: The loss or theft of a computing device or media used by the organization, such as a laptop or smartphone
- Other: An attack that does not fit into any of the other categories
These attack vectors can be used when building a PKI incident response plan. Each attack vector has its own characteristics with regard to detection, containment, eradication, and remediation activities. The new NIST guide also presents a mechanism for prioritizing incidents, pointing out the need for identifying the significant attacks from the large number of minor or nuisance attacks and dealing with those incidents first.
Functional impact describes how the business functions are affected by the system and is categorized as none, low, medium, or high. Incidents with a high functional impact result in a situation where the organization is unable to provide one or more critical services to all users.
Information impact describes the sensitivity of the information breached during the incident and may be categorized as
- None—If no data were breached
- Privacy breach—If sensitive personal identifying information is lost
- Proprietary breach—If trade secrets may have been compromised
- Integrity loss—If data have been modified or substituted
Recoverability impact describes the resources needed to recover from the incident and may be categorized as follows:
- Regular—If no additional resources are needed
- Supplemented—If the company can predict the recovery time but needs additional resources
- Extended—For cases where the company cannot predict recovery time
- Not recoverable—The most serious incidents when recovery is not possible
These three areas of incident prioritization can easily be adapted to the PKI environment. When a PKI area is compromised, the functional, information, and recovery impacts can be estimated based on the area of the compromise, the extent of the compromise, the business processes affected, and the corresponding information disclosed or lost.
The NIST Computer Security Incident Handling Guide is an excellent tool in building or updating a PKI incident response plan.
In developing the incident response plan, it is important to use the assumption that every precaution to avoid a PKI compromise will be taken, but the incident response plan must be written with the assumption that sooner or later a breach will happen. As part of planning, the types of information protected by the certificates, the private keys, and associated symmetric keys must be known, as well as the related data breach laws. Data privacy and data breach notification laws vary by jurisdiction and industry. The relative risks must be understood when data are lost or disclosed. For example, personally identifiable information is not the same as personal healthcare information (PHI) that is not the same as payment card industry (PCI) data or even sensitive personal information. For multinational organizations that operate in different jurisdictional areas or whose customers reside in different countries, it is essential to have written in your plan what responses are required, what notifications are needed, who will take the appropriate actions, and the time frames dictated by law—basically, the PKI incident response plan needs to address who, what, when, where, and how.
Organizations need a PKI incident response plan that must be regularly reviewed and rehearsed as part of best practices.
Many organizations have annual business continuity or disaster recovery tests, or even quarterly exercises. Similarly, organizations need to practice their incident response plan. If the plans are not rehearsed, there is no way of knowing if an organization is prepared for a breach or if they need to wing it when an incident occurs. Despite having a plan, an unrehearsed plan is essentially unproven, and the organization is basically unprepared. Establishing an incident response capability should include the following actions as outlined by the NIST guide:
- Developing an incident response policy in addition to the incident response plan
- Developing procedures for performing incident handling and reporting
- Setting guidelines for communicating with outside parties regarding incidents
- Selecting a team structure and staffing model
- Establishing relationships and lines of communication between the incident response team and others, both internal (e.g., legal department) and external (e.g., law enforcement agencies) groups
- Determining what services the incident response team should provide
- Staffing and training the incident response team
The time to create an incident response plan is not during or after a PKI compromise, but before anything happens. Once a PKI incident response plan is in place, the initial process is to monitor the PKI environment prior to an incident occurring.
8.3 Monitoring the PKI Environment Prior to an Incident
Both large and small organizations deploy a variety of security monitoring tools to keep watch over their network and applications. These tools identify what is normal and what is not and raise alerts and alarms when something amiss is detected. Defense in depth means multiple tools and layers are needed. Intrusion detection system (IDS), intrusion prevention system (IPS), and security information and event management (SIEM) all come into play when monitoring the infrastructure. What one tool might miss another might detect.
Monitoring includes active and passive scans of applications, servers, cryptographic modules, middleware, operating systems, and associated network appliances. Active scans include checking domain names and enabled Internet Protocol (IP) addresses for working ports and protocols. Only authorized ports and protocols should be enabled; they should be compliant with the Internet Assigned Numbers Authority‡ and operate current software to avoid known security flaws. Passive scans include collecting system and application logs, reviewing logs for significant events, and performing analysis for current or past attacks. Analysis might be performed in real time as events occur or after events occur that might be hours, days, weeks, or even months. Figure 8.5 provides a conceptual framework for PKI system monitoring and its potential interface with network and application monitoring.

PKI systems such as CA and RA servers generate local operating system logs, middleware logs, cryptographic module logs, and application logs. PKI system monitoring might access the local server logs, collect logs, and also have monitoring agents on the CA and RA servers. Support staff might manage PKI system monitoring applications using local or remote workstations or even tablets including alerts, reports, or analytical processes. PKI-related information might also be collected by other monitoring systems and forwarded to the PKI system monitoring.
For example, PKI-enabled application systems likewise generate local operating system logs, middleware logs, cryptographic module logs, and application logs. Application monitoring might access the local server logs, collect logs, and also have monitoring agents on the application servers. For example, System A does not have an application monitoring agent, but System B has an application monitoring agent. PKI-relevant logs collected by the application monitoring might be forwarded to the PKI system monitoring.
As another example, network appliances, such as routers, firewalls, or switches that connect PKI systems, which support PKI-enabled applications or are themselves PKI-enabled appliances, might generate logs or send Simple Network Management Protocol traps to a network monitoring tool. PKI-relevant logs and traps collected by network monitoring might also be forwarded to the PKI system monitoring. Operating systems, middleware, and cryptographic modules might generate logs for a variety of events that would be common across all systems:
- Operating system events that generate logs include successful and failed access attempts; network connection information such as port, protocol, and IP addresses; device errors; and data management actions such as file and folder creation, modification, and deletion.
- Middleware events that trigger logs include session information such as time stamps and resource issues including system, network, and application errors.
- Cryptographic modules might generate logs for cryptographic actions such as key generation, import, export, and usage including signature generation for certificates and CRL and internal processing errors.
- CA application events that should generate logs include private key and certificate installation, certificate issuance, CRL issuance, and failed access attempts.
- RA application events that should generate logs include private key and certificate installation, certificate signing requests, certificate revocation requests, and failed CA interactions.
- PKI-enabled application events that should generate logs include private key and certificate installation, certificate validation failures, signature verification failures, key transport failures, and key agreement failures.
- Network appliance events that correlate to PKI events include failed connections to CA or RA systems, certificate validation failures, signature verification failures, key transport failures, and key agreement failures.
Monitoring controls support incident management by providing information for initial response, the discovery process, reporting, and ultimately remediation. Initial responses need precise data for quick assessments. Discovery needs additional information to determine the scope of the problem. Reporting needs details for giving an accurate account of the incident. Remediation can be verified to ensure changes have the expected results.
Monitoring systems such as intrusion detection system (IDS), intrusion prevention system (IPS), and security information and event management (SIEM) tools may generate alerts that require immediate investigation. If a security breach is confirmed, an investigation is needed to determine which CA or RA systems were attacked, which systems were compromised, and what, if anything, was destroyed; this process begins in an incident response plan. It is essential that Incident Response Plans written by the PKI group are very specific components of an organization’s overall incident response strategy. The increased likelihood of some sort of a data breach was underscored by the Ponemon Institute:
2014: A Year of Mega Breaches survey results, 55% of respondents reported that their organization created an incident response (IR) capability as a result of the recent large-scale data breaches covered in the media.§
Now that we have discussed monitoring the PKI environment prior to an incident, let’s consider the initial response after the incident has occurred.
8.4 Initial Response to an Incident
When a PKI compromise occurs, the impact to an organization can be extremely detrimental and very quickly; therefore, it is critical to respond quickly and effectively. The concept of general computer security incident response has become widely accepted and implemented. The only challenge that the PKI team has is to tailor the response to just the PKI environment. One of the benefits of having a written PKI incident response plan is that a plan gives you a way of responding to incidents in a systematic fashion so that all of the appropriate actions are taken in the correct order.
Performing the initial analysis and validation of a PKI compromise can be very challenging. The NIST guide to incident response provides the following recommendations for making incident analysis easier and more effective; these can be applied directly to the PKI environment:
- Profile networks and systems: Profiling is measuring the characteristics of expected activity so that changes to it can be more easily identified. Examples of profiling are running file integrity checking software on hosts to derive checksums for critical files and monitoring network bandwidth usage to determine what the average and peak usage levels are on various days and times. In practice, it is difficult to detect incidents accurately using most profiling techniques; organizations should use profiling as one of several detection and analysis techniques.
- Understand normal behaviors: Incident response team members should study networks, systems, and applications to understand what their normal behavior is so that abnormal behavior can be recognized more easily. No incident handler will have a comprehensive knowledge of all behavior throughout the environment, but handlers should know which experts could fill in the gaps. One way to gain this knowledge is through reviewing log entries and security alerts. This may be tedious if filtering is not used to condense the logs to a reasonable size. As handlers become more familiar with the logs and alerts, they should be able to focus on unexplained entries, which are usually more important to investigate. Conducting frequent log reviews should keep the knowledge fresh, and the analyst should be able to notice trends and changes over time. The reviews also give the analyst an indication of the reliability of each source.
- Create a log retention policy: Information regarding an incident may be recorded in several places, such as firewall, IDPS, and application logs. Creating and implementing a log retention policy that specifies how long log data should be maintained may be extremely helpful in analysis because older log entries may show reconnaissance activity or previous instances of similar attacks. Another reason for retaining logs is that incidents may not be discovered until days, weeks, or even months later. The length of time to maintain log data is dependent on several factors, including the organization’s data retention policies and the volume of data. See NIST SP 800-92 Guide to Computer Security Log Management for additional recommendations related to logging.
- Perform event correlation: Evidence of an incident may be captured in several logs that each contains different types of data—a firewall log may have the source IP address that was used, whereas an application log may contain a username. A network IDPS may detect that an attack was launched against a particular host, but it may not know if the attack was successful. The analyst may need to examine the host’s logs to determine that information. Correlating events among multiple indicator sources can be invaluable in validating whether a particular incident occurred.
- Keep all host clocks synchronized: Protocols such as the Network Time Protocol synchronize clocks among hosts. Event correlation will be more complicated if the devices reporting events have inconsistent clock settings. From an evidentiary standpoint, it is preferable to have consistent time stamps in logs—for example, to have three logs that show an attack occurred at 12:07:01 a.m., rather than logs that list the attack as occurring at 12:07:01, 12:10:35, and 11:07:06.
- Maintain and use a knowledge base of information: The knowledge base should include information that handlers need for referencing quickly during incident analysis. Although it is possible to build a knowledge base with a complex structure, a simple approach can be effective. Text documents, spreadsheets, and relatively simple databases provide effective, flexible, and searchable mechanisms for sharing data among team members. The knowledge base should also contain a variety of information, including explanations of the significance and validity of precursors and indicators, such as IDPS alerts, operating system log entries, and application error codes.
- Use Internet search engines for research: Internet search engines can help analysts find information on unusual activity. For example, an analyst may see some unusual connection attempts targeting Transmission Control Protocol (TCP) port 22912. Performing a search on the terms “TCP,” “port,” and “22912” may return some hits that contain logs of similar activity or even an explanation of the significance of the port number. Note that separate workstations should be used for research to minimize the risk to the organization from conducting these searches.
- Run packet sniffers to collect additional data: Sometimes the indicators do not record enough detail to permit the handler to understand what is occurring. If an incident is occurring over a network, the fastest way to collect the necessary data may be to have a packet sniffer capture network traffic. Configuring the sniffer to record traffic that matches specified criteria should keep the volume of data manageable and minimize the inadvertent capture of other information. Because of privacy concerns, some organizations may require incident handlers to request and receive permission before using packet sniffers.
- Filter the data: There is simply not enough time to review and analyze all the indicators; at minimum, the most suspicious activity should be investigated. One effective strategy is to filter out categories of indicators that tend to be insignificant. Another filtering strategy is to show only the categories of indicators that are of the highest significance; however, this approach carries substantial risk because new malicious activity may not fall into one of the chosen indicator categories.
- Seek assistance from others: Occasionally, the team will be unable to determine the full cause and nature of an incident. If the team lacks sufficient information to contain and eradicate the incident, then it should consult with internal resources (e.g., information security staff) and external resources (e.g., U.S. Computer Emergency Readiness Team [US-CERT], other CSIRTs, contractors with incident response expertise). It is important to accurately determine the cause of each incident so that it can be fully contained and the exploited vulnerabilities can be mitigated to prevent similar incidents from occurring.
Now that we have discussed monitoring and the initial response, including the NIST guidelines, let’s consider the discovery process for the incident.
8.5 Detailed Discovery of an Incident
PKI application monitoring will provide system logs that will typically provide sufficient operations data to allow the various monitoring and reporting systems to display trends, flag anomalies, and generate alarms. This information and the alarms can then be followed up by PKI staffing after false-positive data are discarded. What can make a PKI incident investigation challenging is the time period before an incident is detected. Days, weeks, and possibly months of logs should also be inspected to determine if the compromise may have been missed some time previously. Security IDS, IPS, and SIEM tools can be used to drill down into the time period before and after a suspected compromise may have taken plan. This is particularly important where an attack’s initial objective is to compromise a system from which further internal attacks can be initiated.
Using existing security monitoring tools with network packet capture tools can help in identifying the system or systems that may have been compromised. Network capture data can be an indispensable addition to the forensic diagnosis if a PKI compromise occurs. Network data are valuable and can provide information on interactions with other systems, unusual activity, or atypical protocol usage. There are simple passive tools available to capture, index, store, and retrieve network packet data¶:
- Data packets passed between CA component and service tiers are a good source of irrefutable data that show exactly what transpired between the various components of the PKI service.
- Network traffic data show what communication occurred among the service tiers, and the same trace also shows what communications did not take place. This can be useful if expected communications did not occur (like a CRL update that did not take place). This lack of information can aid in understanding the root cause of the compromise or actions that were suppressed by the compromise.
- Time stamps on network data packets allow correlations between events as long as the system clocks are synchronized as recommended per the NIST guide.
- Network data packets can be retrieved, and session reconstruction can occur tracing the attacker’s activities that might not be discovered during the initial investigation.
- Network data and host generated logs and events can be used to cross-reference events across different host systems.
An emerging trend in incident management is automated incident management systems. These systems will automate a number of tasks to free up personnel to respond to the serious incidents and real compromises. It is not abnormal for an organization to experience thousands of new security alerts every day. With all of those warnings popping up, it is easy to understand how attacks can go undetected until it is too late. Security operations centers and cyber incident response teams are simply overwhelmed by the volume of threat activity. This is primarily because investigating and responding to many of these events consists of many labor-intensive manual efforts**—collecting information, creating trouble tickets, sending e-mails, and generating reports—that can occupy many of the personnel assigned to respond to actual attacks. These automated incident management systems can be tailored to the PKI environment and reduce the time and effort needed to zero in on PKI-based attacks and compromises.
These automated systems can log into potentially affected systems after an alert is generated to look for something out of the ordinary. These systems can be set to automatically look for new files, search Windows event logs, and compare them to other systems or baselines. When the analysis is complete, a PKI engineer can analyze the results or probe the systems deeper if anomalies are found. Once an attack is identified, much of the work needed to remediate it can already be started.
8.6 Collection of Forensic Evidence
If a breach occurs in the PKI environment, it will be necessary to plan how to collect evidence for analysis without further compromising the situation and making the breach worse. The log files on CAs, RAs, and HSMs will all contribute to and contain information about what has been accessed, what processes have been run, and any connections from the outside that may have been made. The keyboard might have data in its buffers containing the last commands typed on the keyboard. Of course, there are always the permanent files, the non-PKI network and system logs discussed in the previous section, the active network connections, and the users who are currently logged on. However, there are several problems with trying to collect forensic computer evidence:
- Once in the middle of a PKI incident, the actions taken to prevent further system compromise can alter the system state, and may damage or destroy forensics data that could be used to find the attackers. Anything done on the CA system such as running diagnostic programs will make it harder to determine the actual status of the system at the time of the attack—important files might be overwritten, destroying forensic information.
- Shutting down or disconnecting a CA, an RA, a web server, or an HSM from the network to avoid further compromise can delete or alter information that might have been important to the investigation. Any data in memory will be lost when the system gets powered off. Any network connection will likely be dropped by the other system when disconnected from the network.
- Well-intentioned PKI operators may “try and find out what is wrong” and begin working on the affected system. This can be the absolute worst thing to do at the time. PKI operators should be trained to escalate first if they suspect something has been compromised as opposed to becoming a poorly trained investigator poking at the problem.
It is highly recommended that any compromised systems be immediately isolated from all network connections to preserve forensic evidence, and if that cannot be done, then shutting down the systems is the next best thing to reduce the risk of further loss or exposure.
Most professional forensic investigators understand this dilemma and what trade-offs must be taken in the heat of dealing with a breach. Again, dealing with a PKI breach is not the time to plan for an incident. Planning the actions taken during an incident will not necessarily make the event less stressful, but it will provide a game plan to follow in the heat of the moment. The PKI incident response plan should focus on the event as a whole, what it means to the organization, customers, the organization’s reputation, and legal issues. The technical steps to recovery, discussed later in this chapter, will be by far the easiest of the activities in the plan.
One of the most important parts of the investigative process is to maintain the security of the evidence chain. This is where a carefully structured incident response plan can really help. In the haste to find the root of the malware or cause of the breach, PKI staffing can jump into many of the logs, databases, and other data files and alter the information that these files contain. If the proper steps and protocol are not followed, the evidence can become compromised leading to difficulties in finding the original source of the PKI compromise. It is important to note that compromised evidence is not going to help solve the original breach or assist with legal issues.
Keeping the PKI staff on task per the plan is an important aspect of running an incident response plan. A forensics expert can provide the step-by-step processes for investigating data sources in a way that preserves the integrity of the evidence. Further legal review of these steps will help head off any missteps that could result in contaminated evidence. Consider a PKI operator who moves a critical log or inadvertently changes the access time of a critical log file. Those actions could create doubt as to what the attacker did versus what the PKI operator did. Every breach should be investigated with the premise that a major PKI compromise could result in legal action from outside your company.
An important aspect is involving legal expertise as part of the PKI forensic investigation.
A compromise of a PKI system may affect more than just your own company. A PKI compromise needs to be evaluated with respect to whether there may be any legal action as a result of the event. The response, investigation, communications, and the overall incident response plan needs to be written with an eye to legal implications. An internal attorney would be a good review point for the incident response plan to point out where legal consequences should be the overriding concern. If your organization does not have an internal legal team, then a review by a practicing technology attorney could be worth the price. Another legal consideration is to have as much of the postcompromise investigation as possible protected under attorney–client privilege especially when a PKI compromise significantly affects outside entities.
It may have been a generally accepted practice to have a PKI administrator or the PKI manager in charge of a forensic investigation postcompromise, but there are many good reasons to have a lawyer either as part of the team or leading the team. Many highly specialized forensic investigation companies will have legal experts who are good at looking at operating systems and digging through computer files. This is not to hamper the PKI engineers or to slow down the investigation, but to make sure that whatever is found is clearly documented in the context of the overall legal situation.
One way to reduce the potential of compromised evidence and inadvertent legal complications is to add a qualified attorney to the incident response team or even have the attorney lead the postcompromise investigation of the PKI environment. This may seem like a very expensive addition to the postcompromise cleanup, but if the attorney prevents the contamination of evidence or avoids a significant legal pitfall, the cost of adding the attorney to the team may be insignificant in comparison.
8.7 Reporting of an Incident
Reporting of a PKI compromise may take both an internal form and an external one. For external reporting requirements, if a PKI protects or includes PCI, HIPAA, or PHI information, then a component of the PKI incident plan must include the disclosures as required under the laws and regulations governing their respective industries.†† Examples of these are as follows:
- PCI DSS 3.0 imposes reporting requirements on organizations that store, process, or transmit credit card holder information. If the PKI compromise event included PCI data—technically called Cardholder Data (CHD), then reporting requirements will have to be made to the relevant card brands and possibly card processors [B.7.23].
- If the PKI compromise, exposed cryptographic keys that protected healthcare data, then HIPAA requires that organizations suffering a security breach notify the affected individuals as well as the Secretary of Health and Human Services.
- And many jurisdictional areas have their own breach notification laws that may require the notification of individuals as well as state governments.
One of the points made in the NIST incident response guide was that companies should share information with trusted partners. In the PKI sense of word, this could be outsourced PKI providers, RAs both in house and potentially outsourced, as well as any trading partners that may be affected by the certificates of the PKI compromise.
The precise set of reporting requirements facing each enterprise varies based upon the types of information that are handled and the jurisdictions in which the organization operates. This is another area in which consulting an attorney well-versed in breach notification laws will come in handy to filling out the details of your incident response plan.
Another external reporting requirement that might arise is that of reporting the PKI compromise to the media. The information gathered from the investigation can be shared when it most makes sense. What may not make sense is to release small bits and pieces of the incomplete story allowing for the news media to speculate on the full extent of the problem and damages it may have caused. By providing a full and complete press release, this will reduce a company’s chance of appearing in multiple news cycles/stories each time a new piece of information comes out. By controlling the reports and sharing information only when it is fully vetted, a good response is much more likely, which can help minimize potentially negative media coverage. This is an area in your Incident Response Plan to factor in your company’s communications specialist rather than using one of the PKI engineers to communicate the message.
The final area of external communications is to share information to any of your customers that might be affected. Stay away from inaccurate or technical jargon-filled communications to customers. This can make the situation worse or can lead to further loss of customer trust.
Internal communications within your company will have the same requirements to be accurate as all external communications. Well-intended but misguided internal individuals may leak information outside the organization before the incident response team was prepared for an external communication. Therefore, all internal communications must be accurate, and not shared internally before the information has been fully vetted and the incident response team is prepared should an information leak occur. Other entities that may need to be included in the reporting section of an incident response plan include
- Your company’s Internet service provider
- Software vendors of the compromised area
- Hardware vendors including, if affected, HSM vendors
- U.S. Computer Emergency Readiness Team (US-CERT)‡‡
It can be far worse to change a story later than to say you don’t know and take the time to verify and validate that the information you are about to release is accurate—balance the need for speed of information release with accuracy. A quick but inaccurate answer will not help the situation. Try to avoid a response that contains excessive jargon or a large number of legal caveats. Find a balance and recognize that it is acceptable to say “we don’t know at this point.”
* technet.microsoft.com/en-us/library/dn786435.aspx (accessed October 2015).