
Today “the Cloud” is everywhere, it permeates our lives, and it is impossible to imagine ourselves without it. Without Cloud technology, we wouldn’t have globally available applications like Airbnb, Uber, Facebook, Google, IBM Cloud, Netflix, Apple iTunes, Amazon, and Microsoft Azure, to name but a few Cloud-based services.
Cloud services do not depend on dedicated hardware servers, but on ephemeral APIs1 that can be accessible by everyone, from anywhere, on any type of device, from desktops to smartphones. All it takes is just a computer, like a lightweight laptop, or even a smartphone.
So the Cloud is really thousands and thousands of APIs coupled to swarms of cheap hardware, and into this revolutionary mix we introduce “Serverless,” a new programming model that is changing the world.
Serverless: The next generation of Cloud computing
Serverless has become the new Cloud programming model, which only requires the programmer to pass in the Function-as-a-Service to the Cloud API for execution. It involves no operations or any maintenance for you as a Cloud developer.
Using the Serverless programming model, you can efficiently deploy your APIs with a minimum effort. And serve your APIs without worry while just paying for actual code usage, since the code is being executed by an API consumer.
If you are a client-side developer for iOS in Swift or other mobile or traditional platforms using other programming languages or if you are a Cloud engineer and you want to get hands-on experience in using Serverless – the latest and greatest Cloud-side technology – this book is for you.
Serverless will help you develop lean, Cloud-based APIs that are as cost-efficient and lightweight as possible for consumer and business APIs alike. Serverless technology has been mainstreamed by well-established enterprises like Amazon, Microsoft, Google, and IBM and embraced by startups like Slack and so on where Serverless effortlessly enriches stand-alone applications almost effortlessly with information sourced in Social Networks, results of big data processing, or supported by Artificial Intelligence (AI) and Machine Learning (ML).
If the Cloud became the social and industrial infrastructure of today, then Serverless technology is the latest generation of Cloud services. Serverless services are superlight thanks to dynamical allocation of machine resources. Those resources are allocated only when needed, instead of forcing the developer to pre-arrange these resources ahead of time in order to be used later for the estimated earlier loads. Furthermore, in order to stay on the safe side, the typical server-based resources are often oversized and rarely saturated. While Serverless technology allows operators to adapt and respond to the given load, the provided computers are being billed for only the gigabyte seconds of the allocation that was actually used by the applications. Moreover, organizations that use Serverless are responsible only for the functions they deploy, while Cloud operators are taking care of all the maintenance and operations of the underlying libraries, operating systems, and hardware.
Event-based modern architecture is allowing developers to decrease time to market. This chapter answers the questions what it is, when, why to use it, and how.
Traditional client-server computing has dominated the computer scene since at least the 1980s. Clients connected to beefy dedicated servers, called on-premise (or on-prem servers), which provided the compute and data storage needed for crunching the problems and changing the world. The fall of the Berlin Wall in November 1989 not only proved the superiority of Western democracy but also of the client-server model on which democracy was based.
In the beginning of the third millennium, with newly minted millennials, the Cloud made its entry on the world scene with Amazon's Elastic Compute Cloud. Startup companies realized that they could move their own computer services from their own dedicated data centers to Amazon’s Cloud and cut their initial investments and decrease the startup costs dramatically. Instead of paying for hardware upfront, they paid for the access to hardware in time slices.
Servers were cheaper in the Cloud than in each startup’s data center, but you still had to pay for maintenance and support on an ongoing basis. What made Serverless revolutionary is that you can now replace monolithic servers with spinning applications on virtual machines (VMs) with Serverless functions. These functions are only invoked by client requests when they are needed. Serverless is a revolution which, going forward, will have repercussions throughout the world. So now the change concerns moving from paying per servers to actual gigabyte seconds the CPUs were spinning for the Serverless functions.
So what is Serverless more precisely? Let’s consider the following typical scenario for the Serverless function.
A user uploads a picture to her/his Cloud account. As soon as the picture is loaded, it generates an event (the new picture in the folder). As soon as our app detects this event, it triggers a function. The function sends a request to an AI-based Visual Recognition service that tags the pictures. Thanks to provided tags, the app can now update the automatic description and catalogue the picture according to the pre-trained classifiers of Visual Recognition. In such a way, the application may provide a user with suggestions for the image classifications. At the same time, the AI analysis can make the service providers aware if the uploaded content might be Not Suitable for Work (NSFW) due to the explicit or harmful content.
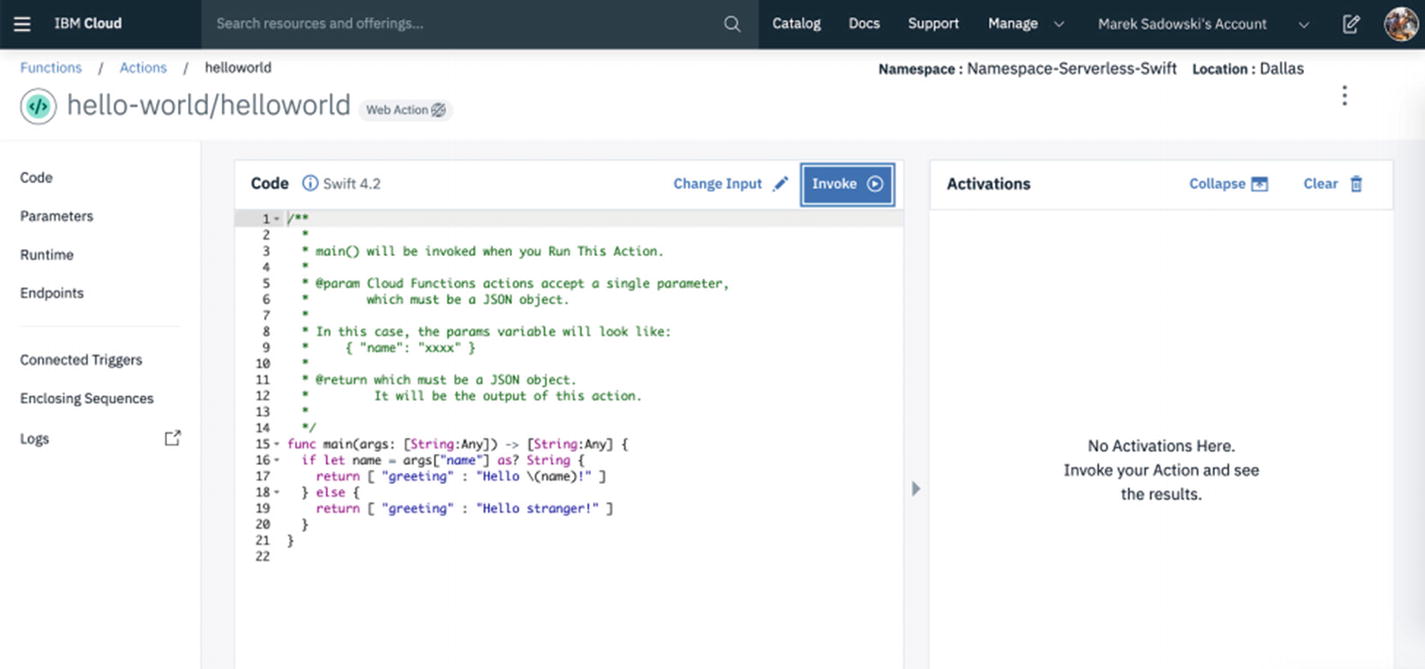
Serverless function implemented in Apache OpenWhisk as it seen in the IBM Cloud Functions browser-based editor

The result of an execution of the Serverless function

Selecting a Quickstart Templates in IBM Cloud

Hello World Serverless template-based example from IBM Cloud

Hello World Serverless function in the Actions library in IBM Cloud

Calling a simple action in Apache OpenWhisk with the text result in JSON format
You will find the full step-by-step description of building such an action in Chapter 4.
What we have discussed so far: Serverless technology refers to a compute model where the existence of servers is entirely abstracted away. Even though servers exist, developers are relieved from the need to care about their operation or the need to worry about low-level infrastructural and operational details such as scalability, high availability, infrastructure security, maintenance, and other details. Serverless computing is essentially about reducing maintenance efforts to allow developers to quickly focus on developing code that adds value and magically scales horizontally in the Cloud with the demand. This magic is being taken care of and delivered by the Cloud and the Serverless infrastructure providers. In Chapter 2, you will be introduced to leading Cloud providers that offer Serverless technology.
We will use Apache OpenWhisk to run through most of the book and examples. We will cover in great detail Apache OpenWhisk in Chapter 3 of this book. For now, we want you to simply know that we selected the Apache OpenWhisk as it is an open source project – there is not any lock-in to the specific vendor. Apache OpenWhisk works as a distributed Serverless platform that executes functions in response to events at any scale, and it is based on other open source projects. If you are a hard-code developer, you can even run your own Apache OpenWhisk Serverless instance yourself on a Kubernetes cluster or stand-alone in a Java virtual machine on your desktop using the open source instructions. Apache OpenWhisk manages the infrastructure, servers, and scaling using Docker containers so you can focus on building amazing and efficient applications. Furthermore, Apache OpenWhisk – as a Serverless function flavor – supports Apple Swift language, among other programing languages, and technologies. And this particular feature enabled writing of this book.
Introduction to event-based programming
Amazon Web Services is largely credited with starting the Serverless market hype in 2014 when the company introduced Lambda, its serverless computing product.
General Manager of AWS Strategy Matt Wood said the product was inspired by one of the company’s most popular products: Simple Storage Service (S3).
Blogger Sam Kroonenburg says the relationship between S3 and Lambda is an important analogy. “S3 deals in objects for storage. You provide an object and S3 stores it. You don’t know how, you don’t know where. You don’t care. There are no drives to concern yourself with. There’s no such thing as disk space… All of this is abstracted away. You cannot over-provision or under-provision storage capacity in S3. It just is,” Kroonenburg explains in his A Cloud Guru blog.
Wood says AWS wanted to take that same philosophy to computing. “Lambda deals in functions. You provide function code and Lambda executes it on demand…. You cannot over provision, or under provision execution capacity in Lambda. It just is.”2
AWS Lambda3 lets you run code without provisioning or managing servers. You pay only for the compute time you consume – there is no charge when your code is not running.
With Lambda, you can run code for virtually any type of application or backend service – all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.

The event-based Apache OpenWhisk programming model
In response to an event in the external service, a trigger is being activated. Events from various sources might be grouped under the dedicated feeds. The trigger then engages a rule, which selects which action it needs to invoke. Finally, an action is being executed. In some cases, the action might be started in the stated intervals – in the crone-like manner – or called directly from inside of an external service or an app. An action produces a response in the form of a text formatted as JSON. The action can also manipulate other resources with use of the RESTful API calls. That function is described in more detail in the following section.
An architecture for Serverless

An architecture for a typical Serverless-based system
In a given Serverless-based system, a client first authenticates with the Authentication Service in the Cloud. Then, by accessing the API Gateway, the client activates functions that realize operations in the Software-as-a-Service (SaaS)-based data systems (DBs, CRMs, ERPs, etc.). There is a close synergy between Serverless functions and SaaS-provided data, since Serverless functions do not store any data on their own. The Serverless functions are stateless. All elements of the Serverless system might be placed in different Clouds, as well as on Premise (in the local data center) systems, yet exposed as an API, in the Dedicated or Private Clouds, as well as in the mix of Clouds from various providers. API Gateway allows for combining single functions (create, read, update, delete) into full CRUD operations, as well as for hiding the source URLs by rewriting them.
In the following sections, you will explore a Cloud-based programming model and benefits of using it. Finally, serverless is relatively new, and we will look at what the shortcomings are with the current technology and how to mitigate them.
Cloud-based programming model
The Cloud native programming model aligns with the evolution of the Cloud infrastructure that was provided to first Business to Business (B2B) and when matured also to single users as a Public Cloud, flexibly and on demand. More on this topic in Chapter 2.
In early 2000 while the existing Cloud infrastructure offered only virtualized hardware, the companies needed to engage the entire IT departments to manage servers. The IT industry used to call this approach as the Bare Metal offering or the Infrastructure-as-a-Service (IaaS). Cloud native programming in this case included an approach like with the regular on-premise (on-prem) servers. In IaaS, you have to take care of preparing and uploading the fixes to the hardware even before installing an operating system (OS), patching OS up, there is still a need for the configuration of the networking components, sometimes including the firewalls and their setup. Only then you could possibly start to install the application servers and database engines. Another aspect of IaaS is to connect the required storage servers. Keeping an entire bare metal installation up to date is similar in costs and efforts as to keep your own data center, less the investment in the hardware itself. The so-called value proposition of the bare metal vendors usually was about decreasing Capex (investing and owning the hardware) in favor of Opex (running the operation costs). During the initial Cloud development, the situation was comparable to the discussion at a car dealership, as when you had a need for a car, would you buy it or lease it? Then technology allowed for new options. The programming model here was so traditional. You owned the entire stack, so it has been up to you what kind of application you would run. But you have had to make sure that you could support the entire application installation, new releases, updates to application servers as well as operating systems, the system backups, and even satisfying the requirement of duplicating critical infrastructure. As you could imagine, any change in the system required synchronization among various actors inside and outside of the organization – and therefore it was scheduled only a couple times a year to avoid any outage of the system. I remember being on call or at the customer locations during holiday seasons to facilitate simple updates of the systems, not even the updates of the hosted applications. The monolithic applications, in such an architecture were rarely exchanging information with outside systems, were commonly used in the industry. Message-Oriented Middleware gave some flexibility and connectivity for those core systems. And some features were exposed to early Internet applications.
As soon as the market for virtualizing hardware and offering it in chunks became quite mature, the companies specializing in IaaS started to offer hosting of the virtual machines (VMs). With hosted VMs, the infrastructure became less of a problem for the IT departments (IT). Thanks to the hypervisors responsible for sharing the outsourced hardware platform among various virtual machines (sometimes belonging to various customers), IT was concerned only with installation of the VMs. Each VM consists of the OS, then application servers, and based on it a business application. Still a huge part of the job in a VM environment is to establish the storage elements. Also networking is still an issue, yet more and more taken care of the VM-as-a-Service providers. The VM offering is still more tailored toward B2B customers. The effort to maintain the application in the VM installation is only a fraction of the entire scope. You have to take care of the system administration, its tuning, security hardening, usage authorization, monitoring, and the access control. Only then you can start to contemplate application server administration and finally the business application, tuning the system according to its needs, and respecting the needs of developers. Operations for such a VM-based system is still very time-consuming. The releases are rather on quarterly basis than more often and aligned with the updates or patching of the OS. Everybody in the VM universe follows the waterfall model of delivering applications and its major releases. During first VM adoption, the Service-Oriented Architecture for business applications was ruling in the IT. Systems were assembled into solid blocks that were talking to each other over the Enterprise Service Bus. The Internet 2.0 was born, and applications from various vendors in various places started to connect to each other. Software-as-a-Service was born with the help of SOAP protocol (a messaging protocol specification for exchanging structured information in the implementation of web services in computer networks).6
Recently we started to use the Container technology. The arrival of Docker as an open source software that could decrease the time needed to manage an operating system and networking to the minimum, that opened ability to start DevOps practices. Now companies are able to update the application more often, delivering releases quickly, with monthly or even bi-weekly schedules. Companies started to use the Agile method to adapt to market expectations and feedback faster. Startups could start to compete with larger enterprises, mostly taking advantage of the leaner IT, without all the overhead of OS and application server administration. Now everything was containerized. That gave rise to Public Clouds, since now everybody – not only companies – could use Cloud instead of buying their own servers. Despite the fact that companies lost control over the hardware hidden in the Cloud, they gained elasticity in producing the updates and releases more often. Still there was a need for DevOps engineers, who would plan for the rollout of the new releases, making sure there is autoscaling and availability of the containers for their systems. The applications started to be assembled out of microservices, following RESTful API protocol (web services that conform to the REST architectural style, called RESTful web services (RWS) , provide interoperability between computer systems on the Internet7). The systems started to depend on the exposed APIs to SaaS and specialized in various aspects of technology, from communications, through customer relationship management, to Social Networks. Now a microservice became the fundamental element of the provided system. The rise of the container orchestration technology with Kubernetes as an Open Source project allowed for the real boom for new systems, while DevOps engineers could control larger systems with less effort relying on the automation provided with the Kubernetes technology and release management offered by following up projects like Istio. The containers as such are ephemeral, so they require SaaS based stateful systems to write and read data. Now the releases of particular microservices started to be scheduled on a weekly basis. Now microservices are living their independent lifecycle being consumed by various systems in the microservices economy.
The Cloud providers that expanded their offering from IaaS, thru VMs, and Containers, started to offer also Platform-as-a-Service (PaaS) – where already the fully capable application servers are hosted. The example of such a PaaS platform is IBM Cloud based on Cloud Foundry Open Source project. Now companies start to deploy only the applications or microservices. Still customers had to pay for spinning the application servers with provided CPUs and memory. That gave the space for another innovation – and the Serverless programming concept was born. Now you do not need to worry about the management of the servers, the application server capacity (memory, CPUs, scaling protocols, etc.). In Serverless programming, everything is going to be taken care of by Cloud providers. Serverless Functions can’t exist without the SaaS stateful systems, but otherwise the functions can be updated on a daily basis or even more frequently. And a particular granular function connected with other functions – responsible in all, for example, for Creation, Reading, Updates, and Deletion (CRUD) of the resources – becomes a single traditional microservice. You are only responsible for the implementation of a function. If comparing this approach with our buying a car example, the Serverless function is almost like using a car, sharing service by minutes or by hours.
When to use Serverless
Serverless functions are having the best time to market for business functionality. As it is shown in the example in the preceding section, it takes literally a minute to start hosting a Serverless function. In the creation process, there is no need for any capacity or performance planning. These aspects are taken care of by the Cloud provider.
Another aspect of the Serverless Function that is great for any team, or a startup company, is that all the efforts are put in to making the Serverless function better, instead of stealing the time for building the operations model. At the end of the day, being able to utilize Serverless Functions could be the most effective means to minimize application running cost and allow a Serverless provider to attend to all the operational optimization efforts.
Another aspect of leveraging Serverless Functions is the lack of packaging required for your application. In the Serverless function world, the packaging is just the bare minimum, and the application is suitable for running, without or with minimum packaging processes.
Since all the operations are on the Cloud provider side, you do not need to take care of scaling or planning ahead of time to provide the scaling you might need for your Serverless functions – rarely using fully what was booked. The entire process is automatically accommodated by the Serverless platform and the Cloud providers.
Now being able to deploy a Serverless function easily, without engaging larger overhead of IT, you are able to constantly experiment and create new, better versions of your function. You are able to easily implement and deploy new versions that you might leverage for A/B testing. Also it allows you to test your experimental, occasional workloads – you can easily provide some new functionality without requesting a bunch of approvals to deploy such a new functionality.
Finally, Serverless computing is greener computing where you will pay and use only the servers for the time of execution, not the time of their free spinning.
Traditional servers still have their strengths
Whereas Serverless functions are great for light, short-lived, and ephemeral processing, they don’t feel right for the processes that are longer, requiring a full transaction capture (like financial or logistics operations).
And since Serverless functions are stateless, the best approach for having stateful tailored services is the traditional approach (serverful) using Platform-as-a-Service (PaaS, for example, Cloud Foundry-based), based on Containers (Red Hat OpenShift, or Kubernetes), or even traditional virtual machine-based systems might be better suited.
Another aspect of generally provided Serverless technology, there is a huge risk of having a vendor lock-in. Therefore, we urge you to consider this characteristic of the Serverless system beforehand, with a list of what-if questions. To mitigate that risk, this book gravitates around Apache OpenWhisk that is an Open Source project supported and developed by esteemed Open Source community, as well by IBM and Adobe, among other industry players.
Also, Serverless functions are susceptible to the “noisy neighbor” problems, since they are often run alongside other functions within servers managed by the Cloud platform provider. You would have well founded concerns for your functions’ performance management or traffic steering, since they are still critical to monitor and manage. Also Serverless technology based in the Public Cloud would need to take care of its latency, accidental network shortages, and unexpected performance decreases. To mitigate these aspects, you could opt for the Cloud Private deployments, leveraging projects like Knative eligible for both Private and Public Clouds.
Since the system takes longer for the cold start, some users might experience high latency in their calls. This caveat might be mitigated by keeping a minimum traffic hitting your Serverless functions every couple minutes (some Serverless systems recall the space of unused Serverless services after about 5 minutes of being idle). Or if high QoS is required, it is better to use typical systems based on Containers or PaaS.
Finally, Serverless technology is a new development. There are yet the certifications like HIPAA or SOC to be established for it. At the moment of writing this book, there are scarcely any established tools that support management, monitoring, and operations of your Serverless function-based systems. Therefore, if 99.999% QoS and availability of your system is required or you need fully certified systems (with the HIPAA certification or alike), it is better if you deploy your system on a more mature platform either PaaS-based, a Container-based, or as aforementioned VM- or IaaS-based.
Summary
We hope these cons don’t discourage you and still you are ready to experiment and then deploy your first Serverless functions with Apache OpenWhisk technology. The details are demonstrated in the following chapters.