Chapter 5. Understanding Layers with Services and Microservices

This chapter provides a concise overview of what lies at the very core of the service-orientation paradigm and the service-oriented architectural model: the identification and aggregation of agnostic and non-agnostic logic into composable units. These units represent the foundational moving parts that collectively define and enable service-oriented solutions.
The upcoming sections explore this topic area by focusing on a series of primitive process steps, as they are applied to the early stages of service modeling and subsequent service design (Figure 5.1).
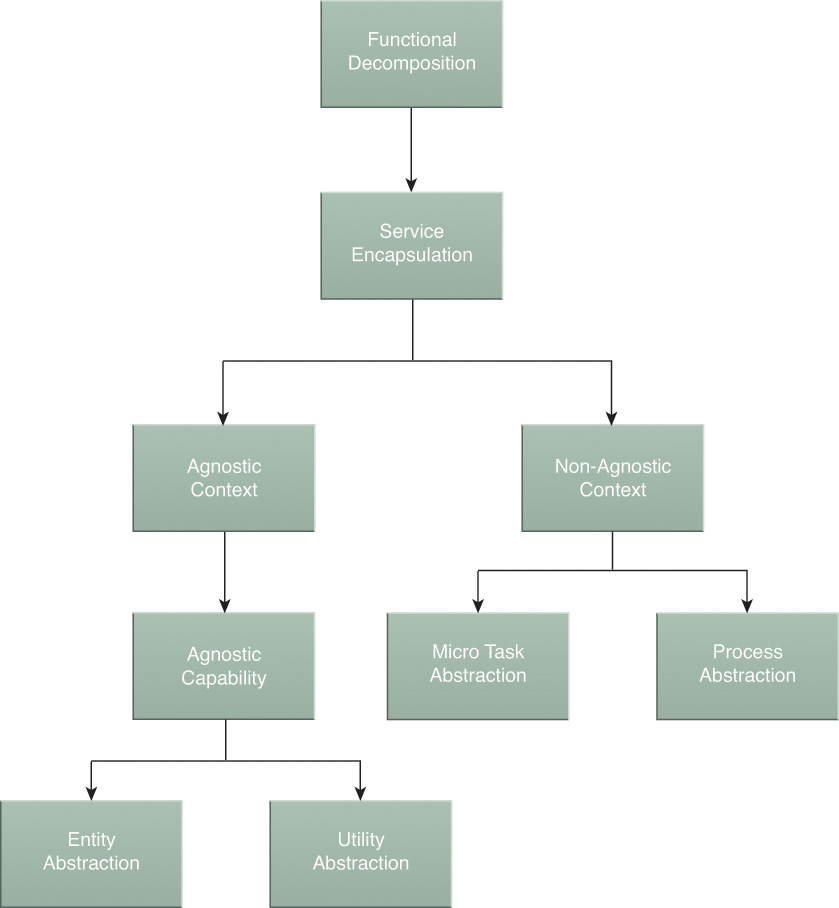
Figure 5.1 A primitive service modeling process that results in the definition of candidate services and capabilities.
5.1 Introduction to Service Layers
The purpose of the service modeling process is essentially to organize a potentially large amount of units of logic so that they can eventually be reassembled into service-oriented solutions. Achieving this requires a set of labels that can be used to group and categorize these units into layers according to the nature of their logic. The following terms, all of which are referenced in the upcoming sections, help us accomplish this goal.
Service Models and Service Layers
A service model is a classification used to indicate that a service belongs to one of several pre-defined types based on the type of logic it contains, the reuse potential of the logic, and how the service may relate to elements of the actual business logic it will help to automate.
The following are common service models:
• Task Service – A service with a non-agnostic functional context that generally corresponds to single-purpose, parent business process logic. A task service will usually encapsulate the composition logic required to compose several other services to complete its task.
• Microservice – A non-agnostic service often with a small functional scope encompassing logic with specific processing and implementation requirements. Microservice logic is typically not reusable but can have intra-solution reuse potential. The nature of the logic may vary.
• Entity Service – A reusable service with an agnostic functional context associated with one or more related business entities (such as invoice, customer, or claim). For example, a Purchase Order service has a functional context associated with the processing of purchase order-related data and logic.
• Utility Service – Although a reusable service with an agnostic functional context as well, this type of service is intentionally not derived from business analysis specifications and models. It encapsulates low-level technology-centric functions, such as notification, logging, and security processing.
A variation of the task service model called the orchestrated task service performs the same overall function as a task service, but is typically responsible for encompassing extensive orchestration logic, which can involve distinct technologies and middleware. Orchestrated task services are not covered in this book.
Even though a microservice can contain reusable logic, it is considered a non-agnostic service because any reuse potential its logic may have is typically limited to reuse within the parent business process logic being automated by an application. For a service to be considered agnostic, it must contain logic that is potentially reusable by multiple business processes.
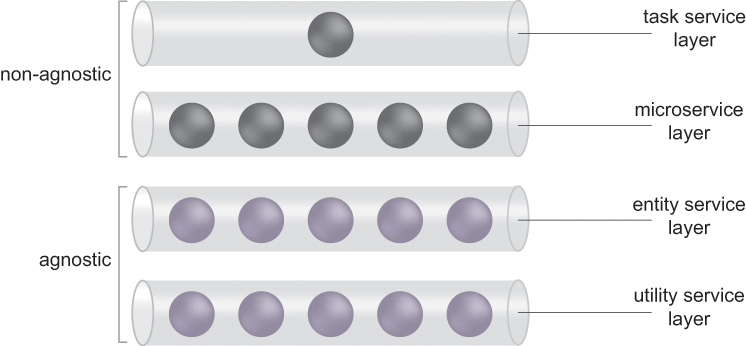
A given service inventory will usually contain multiple services that are grouped based on each of these service models. Each of these groupings is referred to as a service layer (Figure 5.2).
Service and Service Capability Candidates
The upcoming process is focused on modeling service logic prior to the actual building of the service logic. At this early stage, we are essentially conceptualizing services and their capabilities, which is why qualifying them with the word “candidate” is helpful. The terms “service candidate” and “service capability candidate” are used to distinguish conceptualized service logic from service logic that has already been implemented. This distinction is important, particularly because candidate service logic that has not yet been conceptualized may be subject to further practical considerations that may result in additional changes during service design and development.
5.2 Breaking Down the Business Problem
The typical starting point is termed a “business problem,” which can be any business task or process for which an automation solution is required. To apply service-orientation, we first must break down a business process by functionally decomposing it into a set of granular actions. This enables us to identify potential functional contexts and boundaries that may become the basis of services and service capabilities. During this initial decomposition stage, we focus primarily on organizing business process actions into two primary categories: agnostic and non-agnostic.
Functional Decomposition
The separation of concerns theory is based on an established software engineering principle that promotes the decomposition of a larger problem into smaller problems (called “concerns”) for which corresponding units of solution logic can be built. The rationale is that a larger problem, such as the execution of a business process, can be more easily and effectively solved when separated into smaller parts. Each unit of solution logic that is built exists as a separate body of logic that is responsible for solving one or more of the identified smaller concerns (Figure 5.3). This design approach forms the basis for distributed computing.
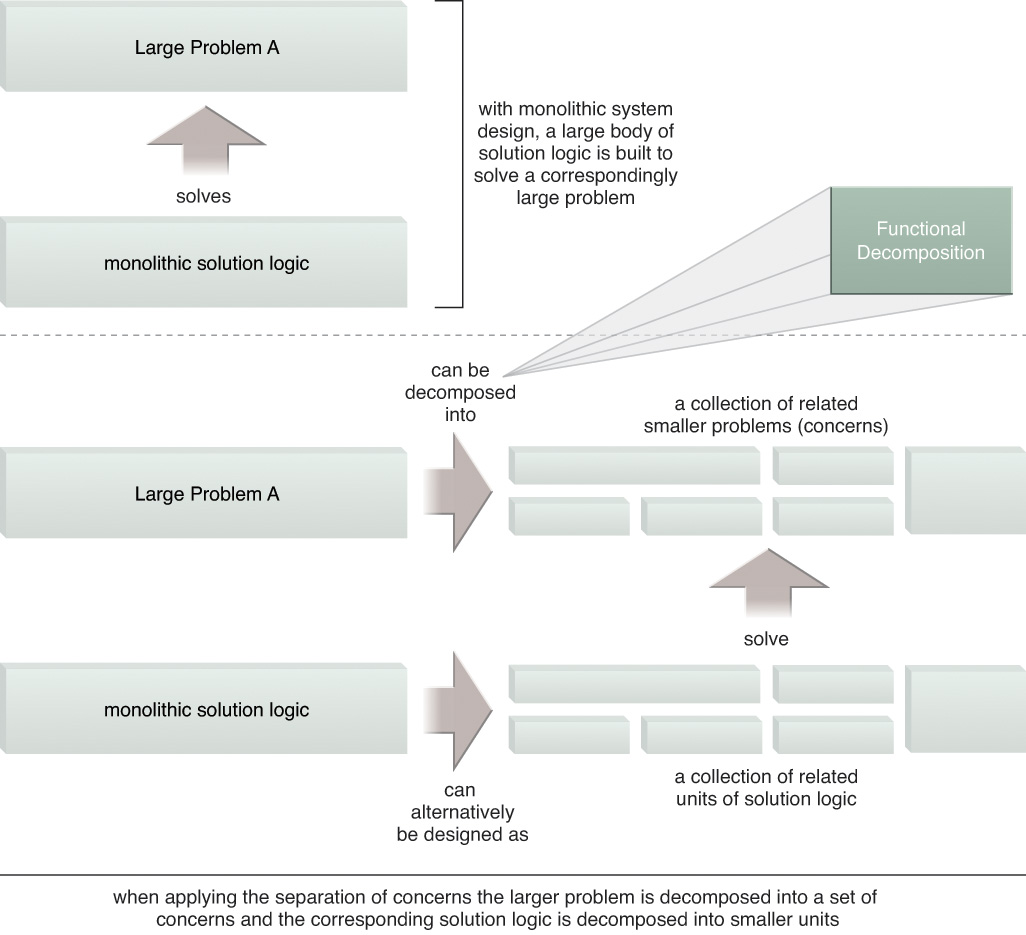
Figure 5.3 A larger problem is decomposed into multiple, smaller problems. Later steps focus on the definition of solution logic units that individually address these smaller problems.
Service Encapsulation
When assessing the individual units of solution logic that are required to solve a larger problem, we may realize that only a subset of the logic is suitable for encapsulation within services. During the service encapsulation step, we identify the parts of the logic required that are suitable for encapsulation by services (Figure 5.4).
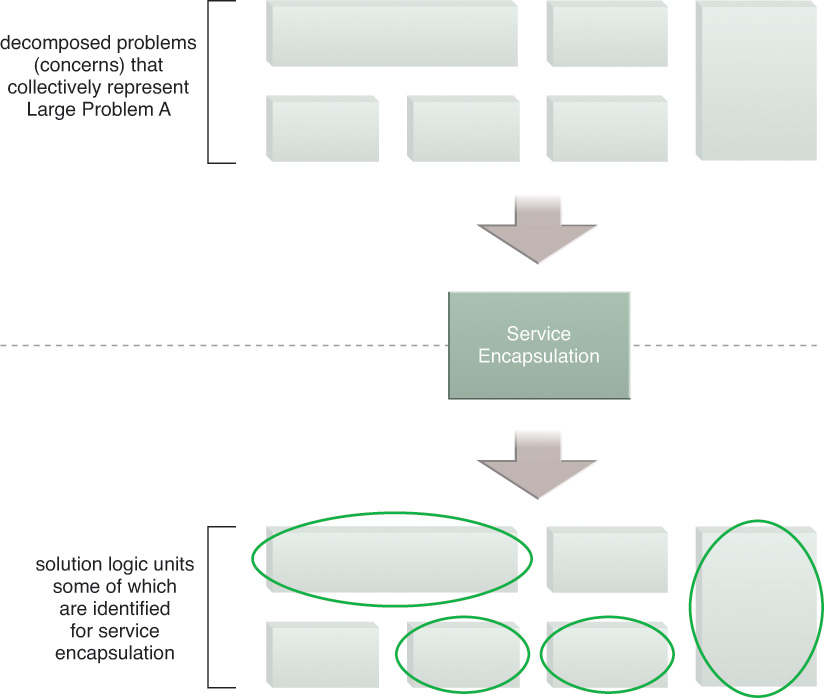
Figure 5.4 Some of the decomposed solution logic is identified as being not suitable for service encapsulation. The highlighted blocks represent logic that is deemed suitable for encapsulation by services.
Agnostic Context
After the initial decomposition of solution logic, we will typically end up with a series of solution logic units that correspond to specific concerns. Although some of this logic may be capable of solving other concerns, grouping single-purpose and multipurpose logic together prevents us from being able to realize any potential reuse. By identifying the parts of this logic that are not specific to known concerns, we are able to separate and reorganize the appropriate logic into a set of agnostic contexts (Figure 5.5).
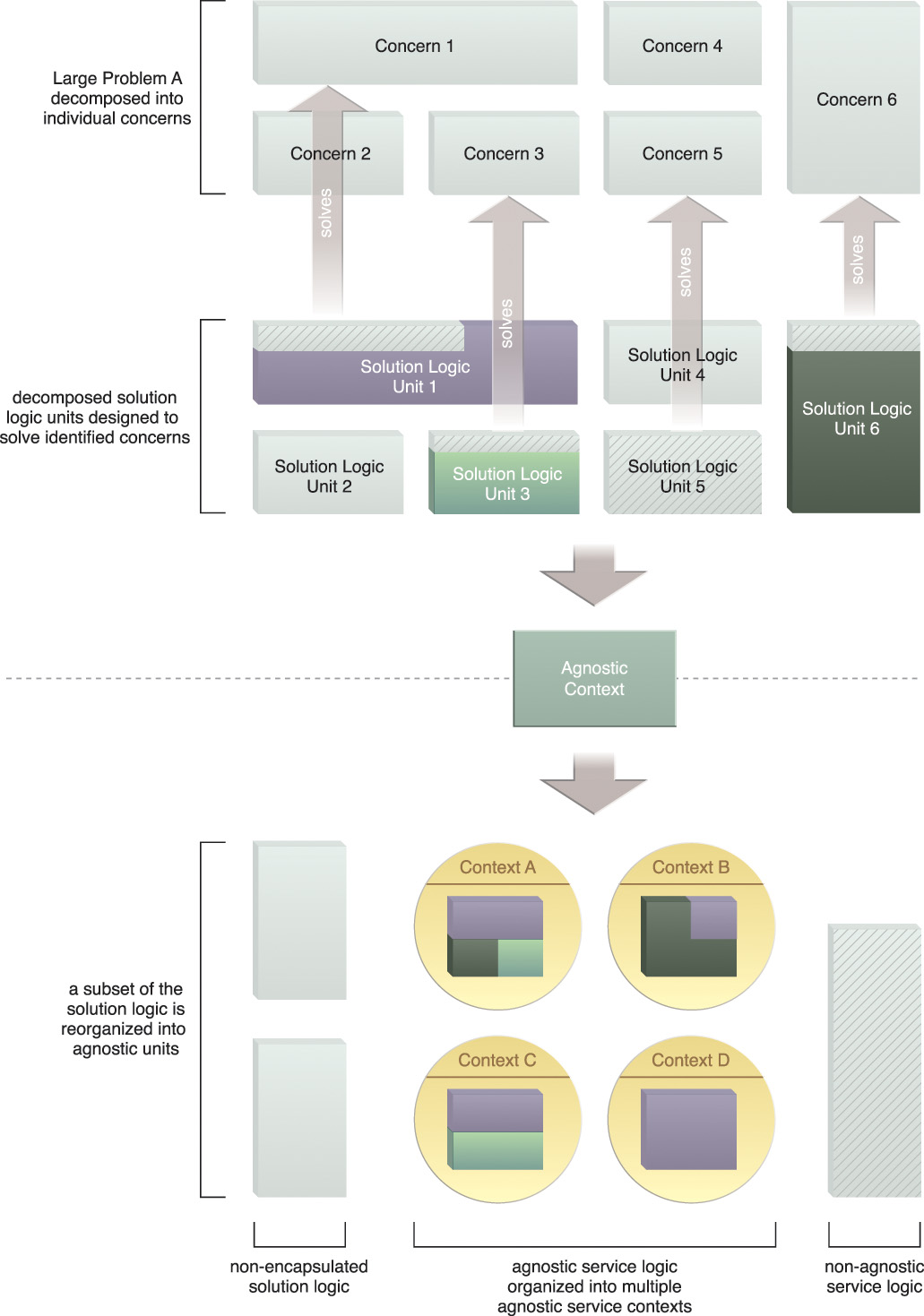
Figure 5.5 Decomposed units of solution logic will naturally be designed to solve concerns specific to a single, larger problem. Solution Logic Units 1, 3, and 6 represent logic that contains multipurpose functionality trapped within a single-purpose (single concern) context. This step results in a subset of the solution logic being further decomposed and distributed into services with specific agnostic contexts.
Agnostic Capability
Within each agnostic service context, the logic is further organized into a set of agnostic service capabilities. It is, in fact, the service capabilities that address individual concerns. Because they are agnostic, the capabilities are multipurpose and can be reused to solve multiple concerns (Figure 5.6).
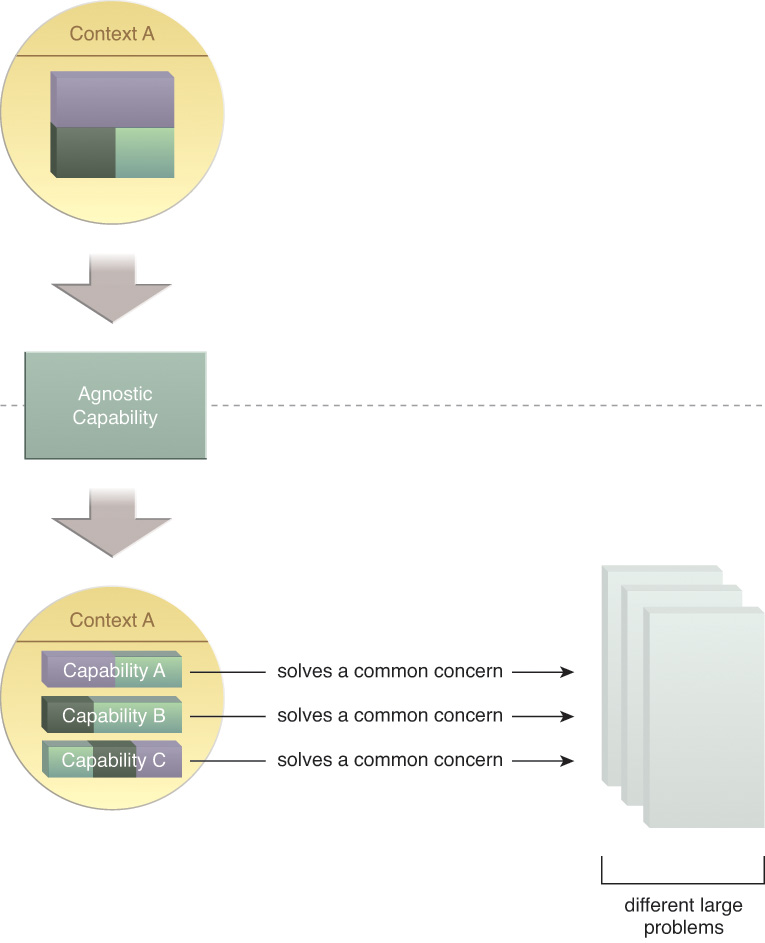
Figure 5.6 A set of agnostic service capabilities is defined, each capable of solving a common concern.
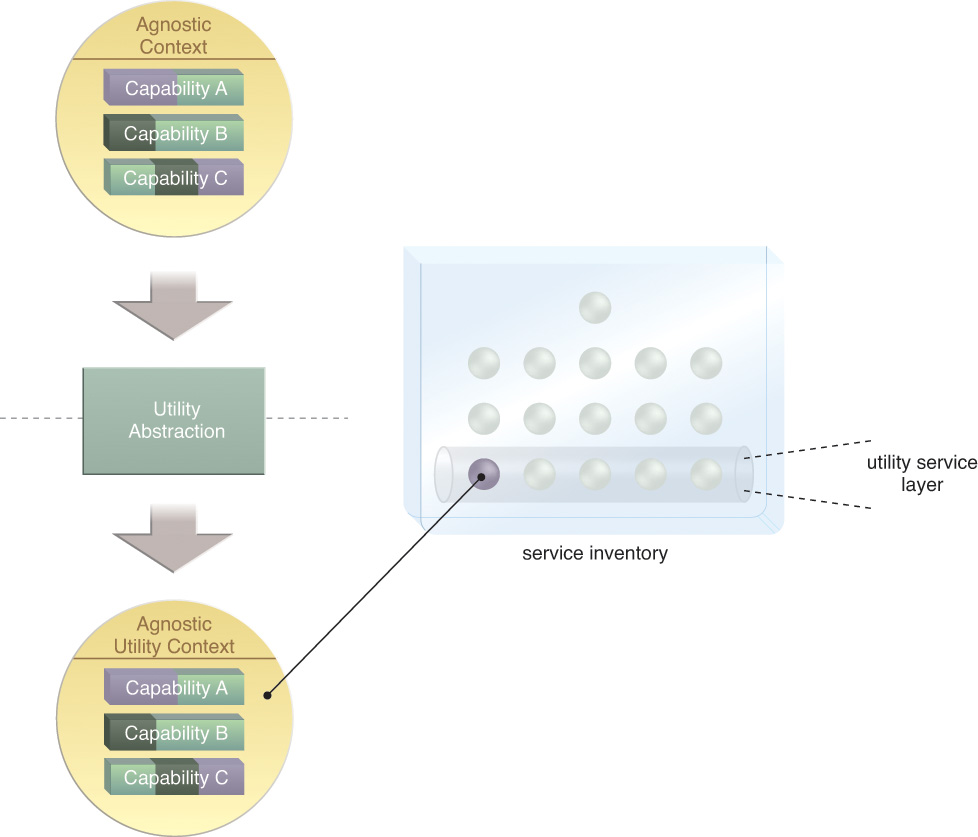
Utility Abstraction
The next step is to separate common, cross-cutting functionality that is neither specific to a business process nor a business entity. This establishes a specialized agnostic functional context limited to logic that corresponds to the utility service model. Repeating this step within a service inventory can result in the creation of multiple utility service candidates and, consequently, a logical utility service layer (Figure 5.7).
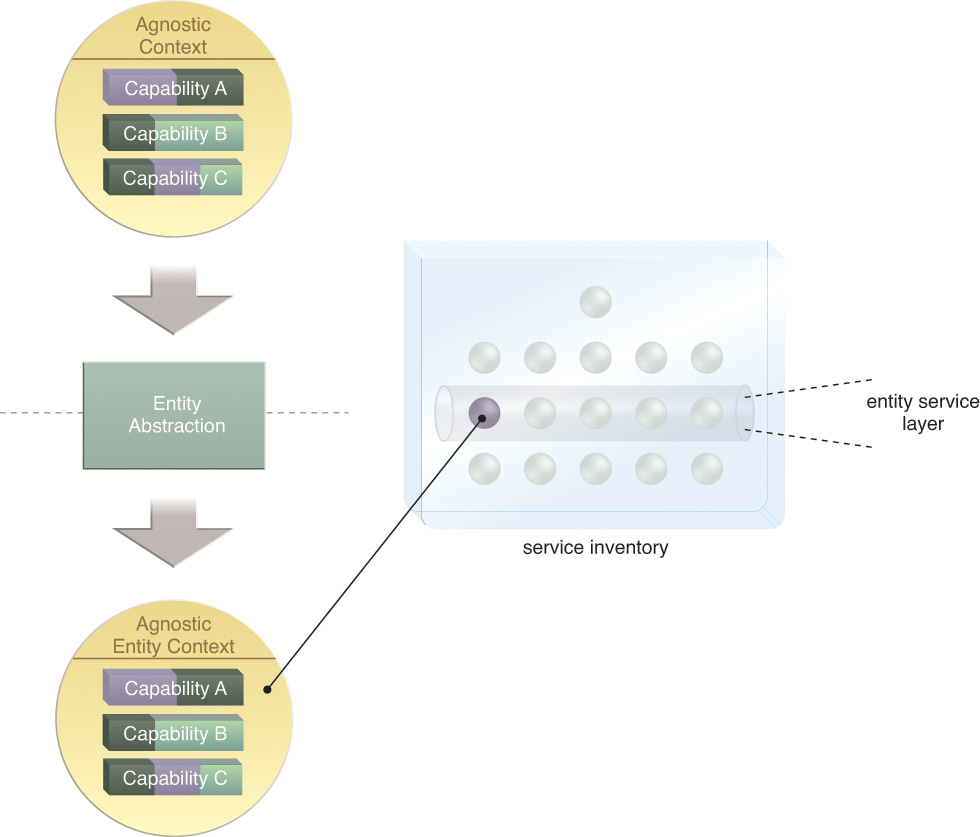
Entity Abstraction
Every organization has business entities that represent key artifacts relevant to how operational activities are carried out. This step is focused on shaping the functional context of a service so that it is limited to logic that pertains to one or more related business entities. As with utility abstraction, repeating this step tends to establish its own logical service layer (Figure 5.8).
Non-Agnostic Context
The fundamental service identification and definition effort detailed so far has focused on the separation of multipurpose, or agnostic, service logic. What remains after the multipurpose logic has been separated is logic that is specific to the business process. Because this logic is considered single-purpose in nature, it is classified as non-agnostic (Figure 5.9).
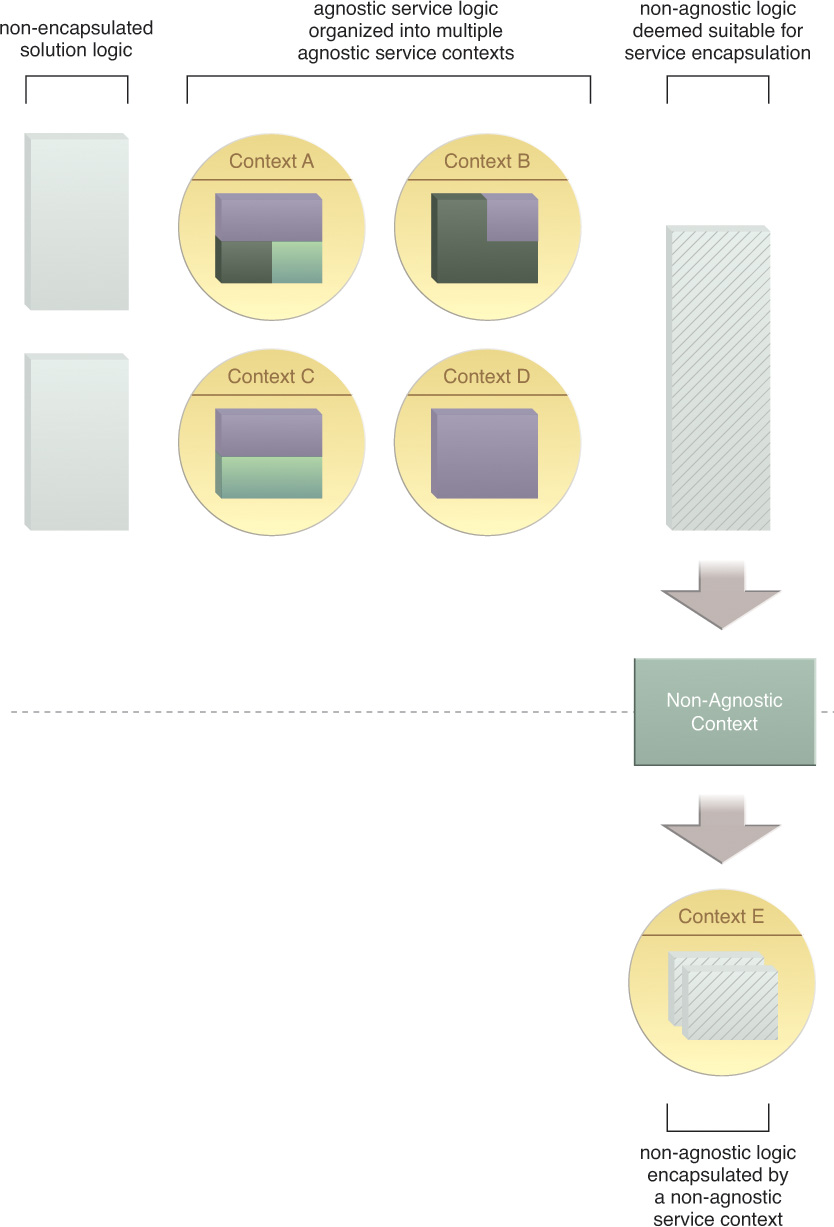
Figure 5.9 By revisiting the decomposition process, the remaining service logic can now be categorized as non-agnostic.
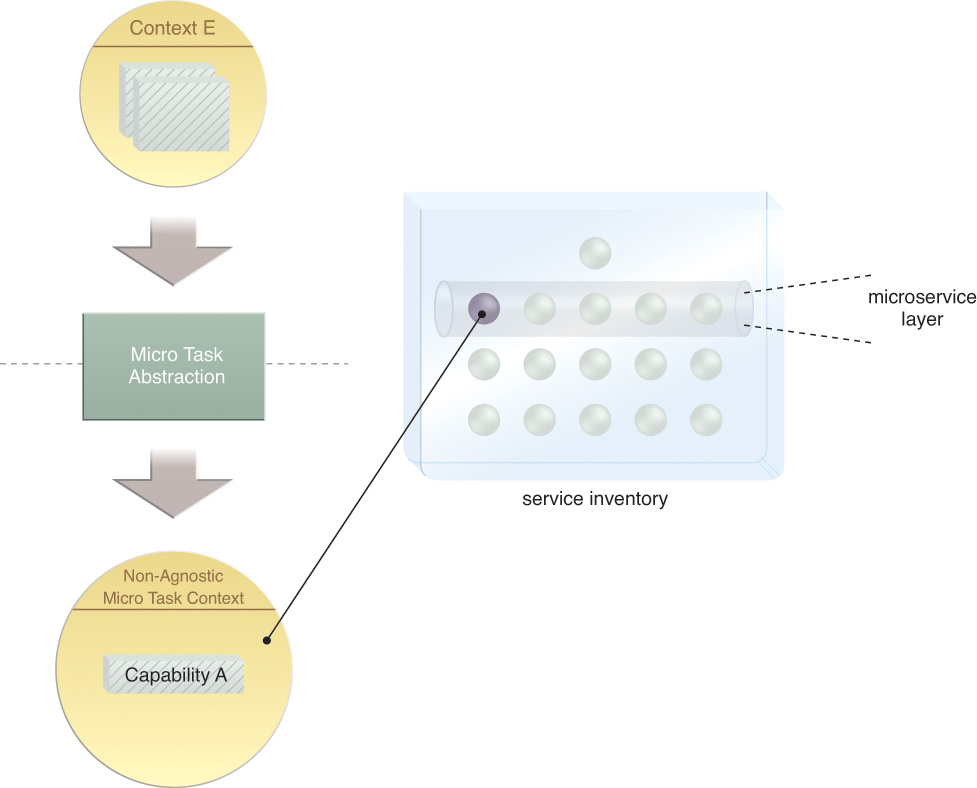
Micro Task Abstraction and Microservices
When reviewing available non-agnostic logic, it can become evident that subsets of this logic (or “micro tasks”) may have specific performance or reliability requirements. This type of processing logic can be abstracted into a separate service layer that can benefit from the distinct implementation characteristics of microservices (Figure 5.10).
Process Abstraction and Task Services
Abstracting the remaining business process-specific logic into its own service layer will typically result in the creation of a task service, the scope of which is generally limited to the parent business process (Figure 5.11). The types of logic that are generally encapsulated by a task service are decision logic, composition logic, and other forms of logic that are unique to the business process they are responsible for automating. This responsibility generally puts the task service in control of the execution of an entire service composition, a role known as the composition controller.
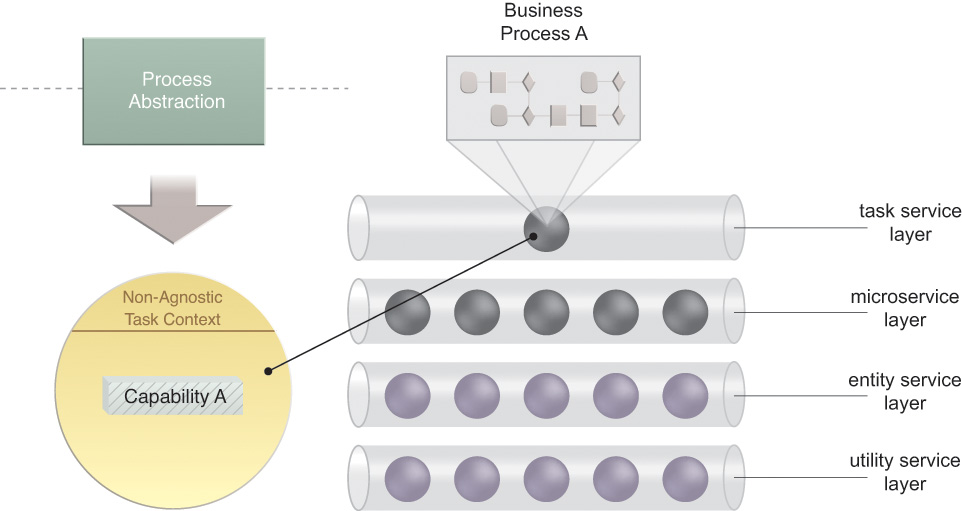
Figure 5.11 The task service represents a part of a parent service layer and is responsible for encapsulating the remaining logic specific to the parent business process.
5.3 Building Up the Service-Oriented Solution
One of the fundamental characteristics that distinguishes service-oriented technology architecture from other forms of distributed architecture is composition-centricity, meaning there is a baseline requirement to inherently support both the composition and recomposition of the moving parts comprising a given solution.
In this section, we cover several key aspects of composition in relation to service-orientation, before continuing with the process steps in order to reassemble the logic that has been decomposed in the preceding steps.
Service-Orientation and Service Composition
A baseline requirement for achieving the strategic goals of service-oriented computing is that those services classified as agnostic be inherently composable. As a means of realizing these goals, the service-orientation design paradigm is naturally focused on enabling flexible composition.
This dynamic is illustrated in Figure 5.12, where we can see how the collective application of service-orientation principles shapes software programs into services that are essentially “composition-ready,” meaning they are interoperable, compatible, and composable with other services belonging to the same service inventory.
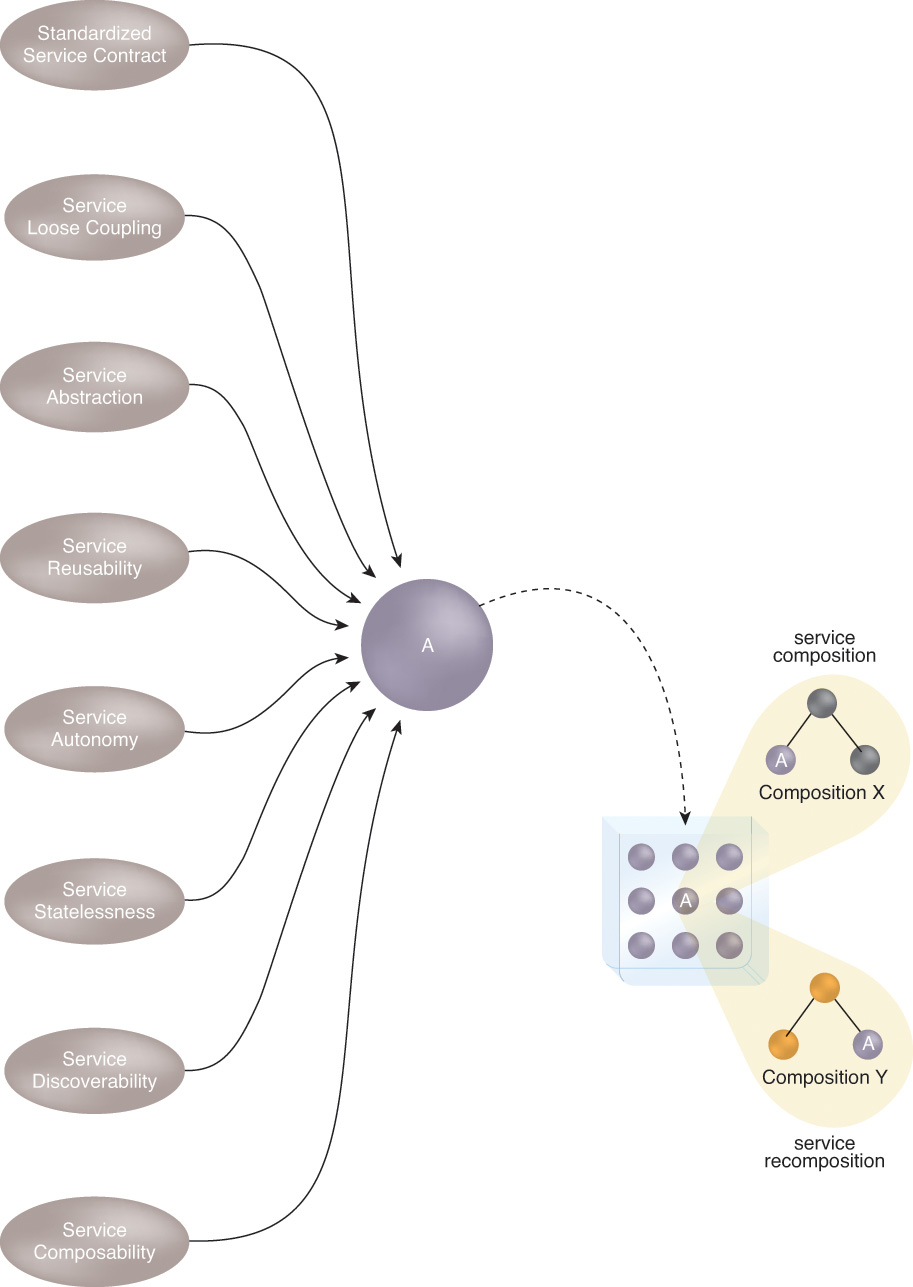
Figure 5.12 Service A (middle) is a software program shaped into a unit of service-oriented logic by the application of service-orientation design principles. Service A is delivered within a service inventory that contains a collection of services to which service-orientation principles were also applied. The result is that Service A can participate initially in Composition X and, more importantly, can later be pulled into Composition Y and additional service compositions as required.
Figure 5.12 does not only illustrate the aggregation that services can participate in. All distributed systems are comprised of aggregated software programs. What is fundamentally distinct about how service-orientation positions agnostic services is that they are repeatedly composable, allowing for subsequent recomposition.
This is what lies at the core of realizing organizational agility as a primary goal of adopting service-oriented computing. Ensuring that a set of services (within the scope determined by the service inventory) is naturally interoperable and designed for participation in complex service compositions enables us to fulfill new business requirements and automate new business processes (Figure 5.13), by augmenting existing service compositions or creating new service compositions with reduced effort and expense. This target state is what leads to the Reduced IT Burden goal of service-oriented computing.
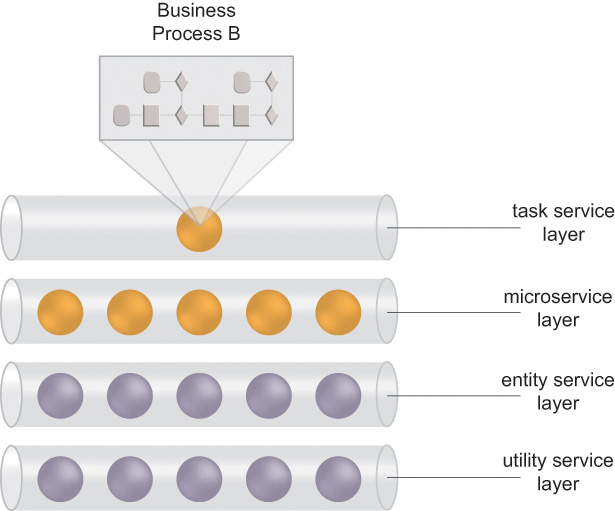
Figure 5.13 The same entity and utility service layers from before, now available for composition by a different set of non-agnostic service candidates in support of the automation of a new business process.
Among the eight service-orientation design principles, one is specifically relevant to service composition design. The Service Composability principle is solely dedicated to shaping a service into an effective composition participant. All other principles support Service Composability in achieving this objective (Figure 5.14). In fact, as a regulatory principle, Service Composability is applied primarily by ensuring that the design goals of the other seven principles are realized to a sufficient degree.
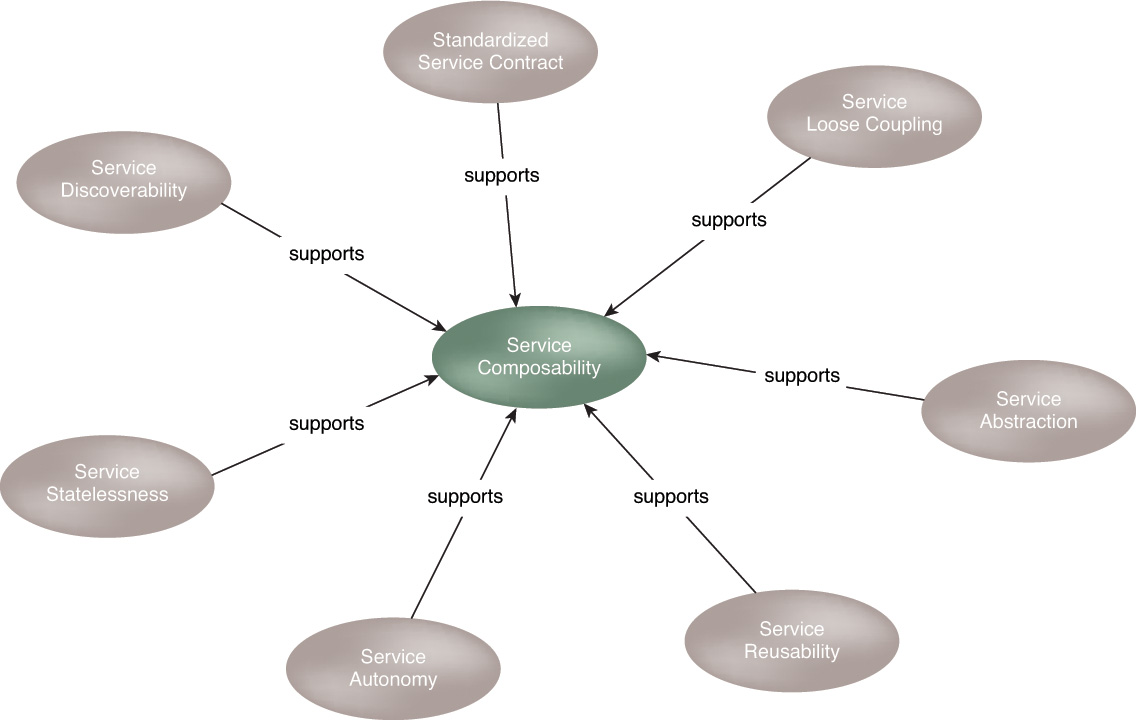
Figure 5.14 A common objective of all service-orientation design principles is the shaping of services in support of increased composability potential.
Capability Composition and Capability Recomposition
Up until now in the process steps, logic has only been separated into individual functional contexts and capabilities. This provides us with a pool of well-defined building blocks from which we can assemble automation solutions. The steps that follow are focused on carrying out this building process via the composition and recomposition of service capability candidates (Figure 5.15).
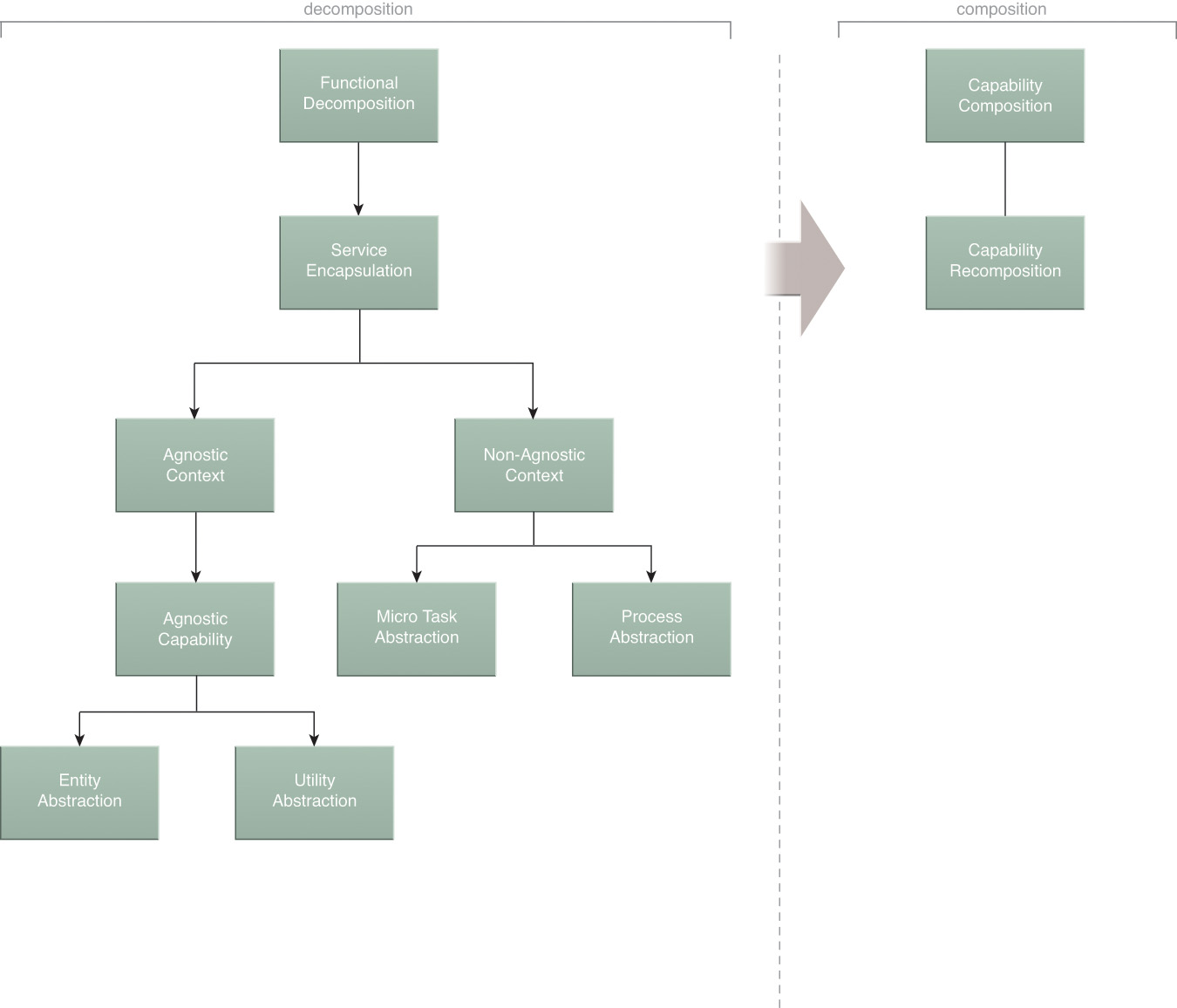
Figure 5.15 Subsequent to the decomposition of a business problem into units of service logic, we focus on how these units can be assembled into service-oriented solutions.
Capability Composition
Candidate service capabilities are sequenced together in order to assemble the decomposed service logic into a specific service composition that is capable of solving a specific larger problem (Figure 5.16). Much of the logic that determines which service capabilities to invoke and in which order they are to be composed will usually reside within the task service.
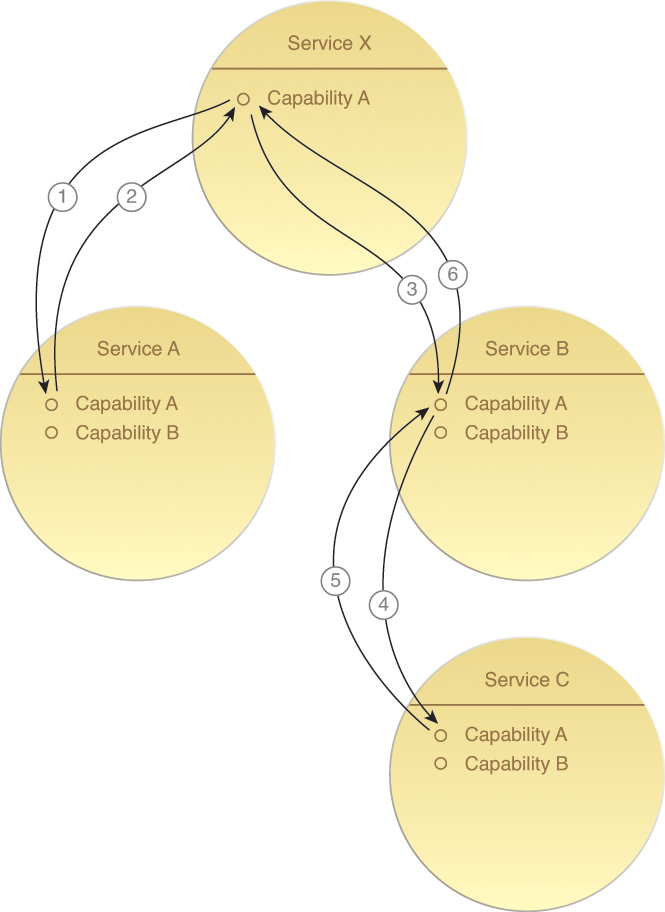
Figure 5.16 Although generally referred to as a service composition, services that compose each other actually do so via their individual service capabilities.
Beyond forming the basis for the basic aggregation of service functionality, this step reinforces functional service boundaries by requiring a service that needs access to logic outside of its context to access this logic via the composition of another service. This requirement avoids redundancy of logic across services.
Capability Composition and Microservices
The type of logic placed in microservices will generally have specific performance and/or reliability requirements. The microservice model can therefore introduce the need for a distinct implementation environment optimized to support special processing demands. Microservice implementations are often highly autonomous in order to minimize dependencies on resources outside of their functional boundaries that could compromise fulfilling their processing requirements.
As a result, when a microservice needs to access other resources, those resources can either be replicated or redundantly implemented so that they remain part of the microservice’s local processing scope. Therefore, when it is decided that a microservice needs to compose another service, the composed service may be redundantly implemented and deployed together with the microservice.
Let’s imagine that Service B in Figure 5.16 is a microservice and Service C is a utility service being composed by the microservice. The logical view provided by Figure 5.16 would stay the same. However, the physical view of this composition architecture could vary, depending on what technologies are utilized as part of the microservice implementation environment. For example, Figure 5.17 shows how both the microservice and utility service could be rolled out in the same deployment bundle and placed onto a dedicated virtual server. Figure 5.18 takes this a step further by physically grouping the services together with system files and libraries within a container. In either architecture, that same utility service may be in use in various other capacities, within this and other solutions, but it is specifically redundantly deployed in support of the one microservice.
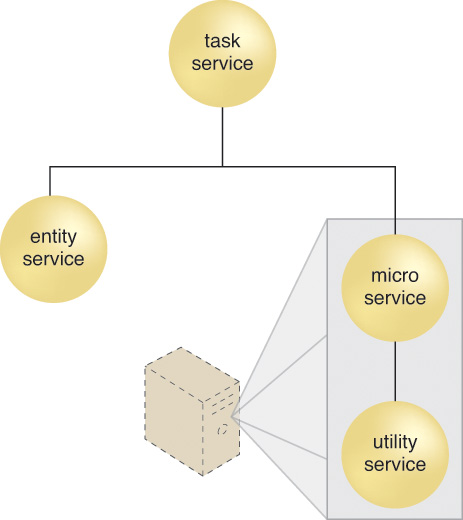
Figure 5.17 The microservice and a redundant implementation of the utility service it is composing are grouped in the same deployment bundle and located on a dedicated virtual server. This increases the autonomy of the microservice, which it may need to fulfill its specialized processing requirements.
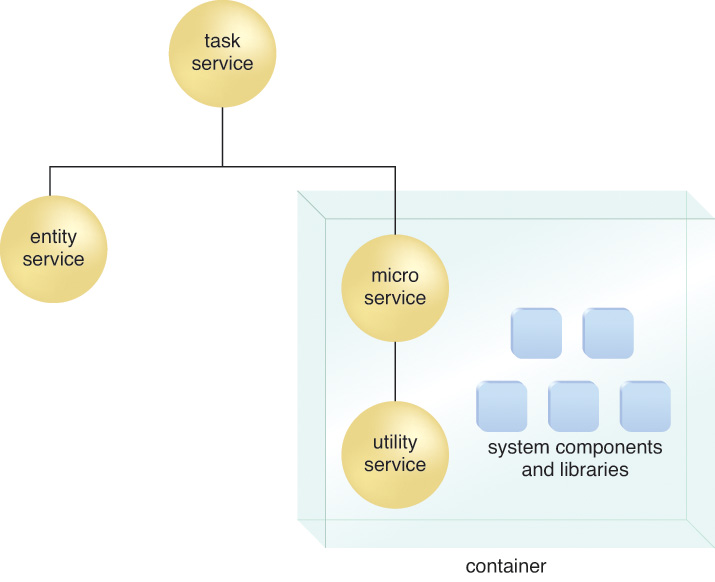
Figure 5.18 The microservice and the redundant implementation of the utility service are positioned within a container that also includes system components and libraries. This is an example of how containerization technology can be used to further increase the autonomy and mobility of services. The extent to which autonomy is increased depends on the extent to which redundant implementations of external resources the service may need to call are included in the container.
Note that Figures 5.17 and 5.18 depict architectures that are commonly associated with microservice implementations. Deployment bundles and containerization technology can also be used for services based on other service models or for entire solutions that are not service-oriented. Due to the typical requirement of a microservice to support specialized processing or deployment requirements, there is usually a greater need for dedicated underlying hosting environments and resources.
Numerous variations of these architectures can exist. For example:
• Services packaged in the same deployment bundle may be able to communicate in-process or out-of-process.
• The microservice in the preceding scenarios may compose the utility service to access an underlying resource or it may disregard the Service Loose Coupling principle and access the underlying resource directly.
• Multiple deployment bundles can be located on the same virtual server, as long as respective autonomy requirements can be fulfilled.
• In Figure 5.18, the container is located on a physical server, but it can also be located on a virtual server.
• A container can host multiple deployment bundles, which may be desirable if communication between services and resources in the respective bundles is required.
Although microservice architecture and related technologies are not covered in this book, summary profiles of the Microservice Deployment [349] and Containerization [333] patterns are provided in Appendix C and are recommended reading. These and other related patterns can also be accessed in the Service Implementation Patterns category at www.soapatterrns.org.
Capability Recomposition
As previously mentioned, the recomposition of services is a fundamental and distinctive goal of service-oriented computing. This step specifically addresses the recurring involvement of a service via the repeated composition of a service capability. The relationship diagram shown in Figure 5.19 highlights how the preceding steps that have been described all essentially lead to opportunities for service capability recomposition.
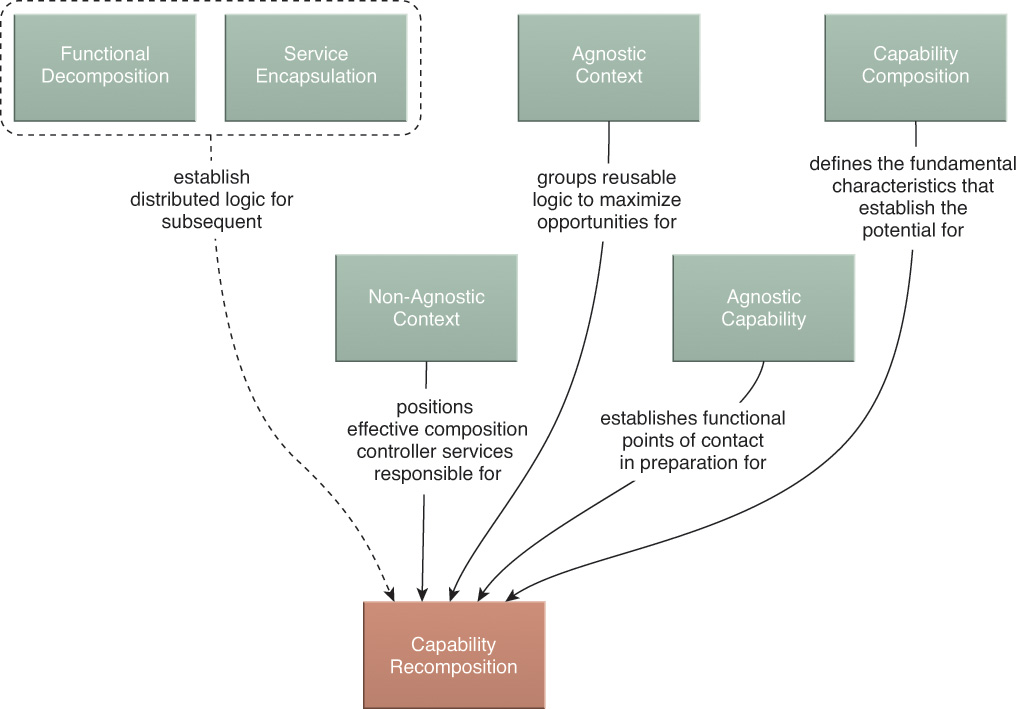
Logic Centralization and Service Normalization
As more services are added to a service inventory, careful attention needs to be given to the respective service boundaries. This introduces the concept of service normalization. Service boundaries are defined on a functional basis and new logic introduced into a service inventory is first analyzed for its coherency in relation to the functional boundaries of existing services in order to avoid functional overlap. Functional overlap results in redundant logic, which can lead to increased maintenance overhead on an ongoing basis and when business requirements change. It can further lead to governance and configuration management issues, especially in cases where the redundant logic is owned by different groups within an organization.
The less functional overlap that is allowed in a service inventory, the less redundant logic exists, and the more normalized the service inventory becomes. Logic centralization is a technique that supports service normalization by centralizing logic in the form of single, normalized services (Figure 5.20).