
7Test Tools
This chapter provides an overview of the various types of tools that can be used to support software testing activities. We look at what these tools are capable of, and how to select and introduce the ones that are best suited to your particular project.
Test tools1 are used to support single or multiple software testing activities (see section 2.3) and a wide range of purposes:
Uses of test tools
- Increase testing efficiency
Manual test activities, and especially those that have to be repeated regularly or are generally time-consuming, can benefit from the use of appropriate tools—for example, automated static code analysis or automated dynamic testing. - Increase test quality
Tool-based test case management helps you to manage large numbers of test cases and retain an overview of your work. Tools help to eliminate duplicate test cases and reveal gaps in the selected test case suites, which helps to keep your testing activities consistent. - Increase testing reliability
Automating manual test activities increases overall testing reliability—for example, when comparing the expected vs. actual values of large amounts of data or when repeating identical test sequences. - Make some tests possible
The use of tools makes it possible to perform tests that cannot be executed manually. These include performance and load tests, or testing real-time systems.
Tool suites
Some tools support only a single task while others cover multiple tasks. There are also complete tool suites that can be used to manage the entire testing process, from test management through test design to test automation, execution, documentation, and evaluation. Such suites are often marketed as “Application Lifecycle Management” (ALM) tools.
Test framework
“Test framework” is another familiar term in the context of test tools, and is usually used to mean one of the following:
- Reusable and extensible program libraries that are used to build test tools or test environments
- The type of methodology used to automate testing (for example, data-driven or keyword-driven, see section 7.1.4)
- The entire test execution process
7.1Types of Test Tools
Tool types
We can differentiate between various types (or classes) of test tools depending on the phase of the testing process you are involved in (see section 2.3) and the type of task you want to automate. Types of test tools are also subdivided into specialized categories2 for use with specific platforms or fields of application (for example, performance testing tools for web applications).
You will rarely need to use the whole spectrum of test tools in the course of a single project, but it is nevertheless useful to know what is available so you can make informed decisions about what you need when the time comes.
The following sections describe the basic functionality of different types of test tools.
7.1.1Test Management Tools
Test management
Test management tools offer ways to register, catalog, and manage test cases and their priorities. They also enable you to monitor the status of test cases—in other words, you can record and evaluate whether, when, or how often a test has been performed and the results it delivered (pass/fail).
They help test managers to plan and manage hundreds or thousands of test cases. Some tools also support project management tasks within the testing process (such as resource planning and scheduling).
Today’s test management tools support requirements-based testing too, with requirements either entered directly or imported from a requirements management tool. Once imported, every requirement can then be linked to the test cases that test whether it has been fully and correctly implemented. The following example illustrates the process.
Case Study: Requirements-based testing for the VSR-II DreamCar module
The team working on the VSR-II DreamCar module uses epics to describe its functionality [URL: Epic]. The vehicle configuration and price calculation functionality is described by the following epic:
- Epic: DreamCar – Vehicle configuration and price calculation
The user can configure a vehicle (model, color, extras, and so on) on a screen. The system displays all available models and equipment variants and displays the corresponding list price in real time. This functionality is implemented in the VSR-II DreamCar module.
The detail of the epic is filled out with user stories. The following user stories are assigned to the DreamCar epic:
- User Story: Select vehicle model
- The system displays all available base models
- The user can select one of the displayed base models
- User Story: Configure vehicle
- The system displays all available options for the selected base model (equipment options, special editions, extras)
- The user can select the desired options (for example, red pearl effect paint, the OutRun sports package, the OverDrive music system, and the Don’tCare autopilot system). Options that are generally available but not for the current configuration are grayed out.
- User Story: Calculate vehicle price
- The list price for the selected base model and configuration options is calculated and displayed
To check whether a user story has been correctly and fully implemented, the team defines corresponding test cases and links them to the corresponding user story using a test management tool. The test cases defined for the configure vehicle user story are as follows:
- Test Case: Base model with one option
- Test Case: Base model with multiple options
- Test Case: Base model with non-selectable option
- Test Case: Base model with equipment package option
- Test Case: Base model with no options
Requirements Management
Requirements management tools save and manage all kinds of data relating to requirements. They also enable you to prioritize requirements and track their implementation status.
These are not test tools in the narrow sense but are nevertheless very useful when it comes to deriving and planning requirements-based tests (see section 3.5.3)—for example, based on the implementation status of individual requirements. Most requirements management tools can swap data with test management tools, which can then create links between requirements, test cases, test results, and defect reports.
Traceability
This in turn enables full traceability (see section 2.3.8) for every defect or defect report (solved or unsolved), the relevant requirements, and with regard to which test cases have been executed. The verification and validation status for every requirement is then fully transparent, so requirements that have been incorrectly implemented or overlooked (i.e., not covered by any test cases), or those with gaps in their specifications can be easily identified.
Defect management
Defect management tools are a must for every test manager. As described in section 6.4, these tools register, manage, distribute, and statistically evaluate reported defects. High-end defect management tools include parameterizable defect status models and enable you to specify the entire process, from discovery of a defect through correction to regression testing. This way, the tool can guide everyone involved through the defect management process.
Configuration management
Configuration management tools too are not test tools in a strict sense (see section 6.5). What they do is enable you to manage multiple versions and configurations of the software being tested, including different version of test cases, test data, and other product and test documentation. This makes it easier to determine which results from a test sequence were produced by which version of a test object.
Continuous Integration
In agile and iterative/incremental projects, integration and integration testing of modified components are usually highly automated. As soon as a block of code is checked in to the integration environment, all of the necessary integration steps and test processes are performed completely automatically (see also [Linz 14, section 5.5]). This process is called continuous integration. Tools that control and perform this process are called continuous integration (CI) tools.
Tool integration
Test management tools require high-performance interfaces to a range of other tools. These include:
- A general export interface for converting data into a format that is generally readable for other teams and company departments (for example, in a spreadsheet).
- An interface to the requirements management tools for importing requirements or linking them bi-directionally. This enables requirements-based test planning and traceability of the relationships between requirements and test cases. Ideally, the test status of every requirement can then be tracked by the users of test management and requirements management tools (see section 2.3.8).
- An interface between test management and test execution tools (test robots) for the provision of scripts and starting automated testing. The results are automatically returned and archived.
- An interface between test management and defect management enables seamless confirmation test planning (i.e., a list of the tests that are necessary to verify which defects have been corrected in a specific version of a test object).
- Test management tools can be linked to continuous integration (CI) tools so that tests planned using the test management tool can be executed as part of the CI process.
- Code files can be flagged with version numbers in the configuration management tool. A test management tool that can read such data can then link test cases or defect reports to the corresponding files and file versions.
Generating test summary reports and test documentation
Test management and defect management tools usually offer comprehensive analysis and reporting functionality and can, to an extent, generate test documentation (test schedule, test specifications, test summary report, and so on). The format and content of such documentation is usually configurable.
Test data can be evaluated quantitatively in a variety of ways. For example, you can analyze how many test cases have been run and how many of those were successful, or the frequency with which a particular class of defect is identified (see section 6.4.3). These kinds of data help to judge and manage overall testing progress (see section 6.3).
7.1.2Test Specification Tools
To ensure that a test case is reproducible, the individual testing steps, the test data, and the corresponding pre-and postconditions have to be defined and recorded (see section 2.3). Most test management tools offer templates or familiar notations to support the creation of consistently structured test cases. These include keyword- or interaction-based notations, as well as the generally accepted notations used in behavior-driven development (BDD, see [URL: BDD]) and acceptance test-driven development (ATDD, see [URL: ATDD]). While keyword-based testing using tables to list test cases, the BDD and ATDD methodologies use a text-based notation that is similar to natural language. These notations are explained in more detail in [Linz 14, section 6.4.3].
Test and test data generators
Regardless of the notation used to record a test case, the tester has to specify the test data it uses. Test (data) generators can be used to determine and generate appropriate test data. According to [Fewster 99] there are various approaches to test data generation that depend on the basis from which the test data are derived:
- Database-based test data generators use database structures or contents to generate or filter appropriate test data. The same approach can be applied to generating test data from files of various formats.
- Code-based test data generators analyze the test object’s source code. The downside of this approach is that it cannot effectively derive expected behaviors (which requires a test oracle). As with all white-box testing techniques, only existing code can be used and defects caused by missing statements remain undiscovered. Logically, using code as a basis for generating test cases that are used to test the same code (i.e., the code “tests itself”) doesn’t make much sense and is not an effective testing technique.
- Interface-based test data generators analyze the test object’s interface, identify its parameter range and use techniques such as boundary value analysis and equivalence partitioning (see sections 5.1.1 and 5.1.2) to derive test cases. These tools work with various types of interfaces, and can analyze application programming interfaces (APIs) or graphical user interfaces (GUIs). The tool identifies the types of data fields present in a mask (numerical date/time, or similar) and generates test data that cover the corresponding value ranges. These tools, too, cannot derive expected behaviors but are ideal for generating robustness tests (i.e., testing whether rather than how a test object reacts).
- Specification-based test data generators derive test data and the corresponding expected behaviors from project specifications, but only if the specifications are available in a formal notation. For example, a method call sequence specified using a UML sequence diagram. This approach is known as model-based testing (MBT). The UML model is created using an appropriate tool and is imported by the test generator, which then creates test scripts that are handed over to a test tool for execution.
A tester’s creativity is irreplaceable
However, don’t expect miracles from these kinds of tools. Specifying tests is demanding work that requires comprehensive knowledge of the test object coupled with creativity and intuition. A test data generation tool can apply certain rules (such as boundary value analysis) to create tests systematically, but cannot judge which of those test cases is good or bad, important or irrelevant. This kind of creative/analytical work has to be done by a human tester, and the test object’s expected behaviors usually have to be defined manually too.
7.1.3Static Test Tools
Static tests and analyses (such as reviews) can generally be performed on documents with any kind of structure, but tool-based static analysis relies on documents having as formal a structure as possible. For source code, the structure is prescribed by the syntax of the programming language, while formal specifications or models are governed by the syntax of the modeling language you use (UML, for example).
There are also tools designed to investigate informal documents written in natural language, which can, for example, check spelling, grammar, or readability. These, too, are classed as static analysis tools.
What all these tools have in common is that they do not analyze executable code. Static testing tools can therefore help to identify faults and inconsistencies at an early stage in a project (see the left-hand branch of the V-model in figure 3-2) or during early iterations in the development cycle. Identifying faults immediately or at least early on prevents the occurrence of follow-on defects and thus saves time and money overall.
Review support tools
Reviews are structured, manual checks performed according to the buddy principle (“two pairs of eyes are better than one”—see also section 4.3). Review support tools aid the planning, execution, and evaluation of reviews. They are used to manage information related to planned and past review meetings, participants, findings, and results. Verification aids such as checklists can be managed and provided online. Information collected during reviews can be evaluated and compared to estimate the overall effort involved and to plan subsequent reviews. Comparing review results also helps to bring weaknesses in the development process into the open, where they can be more effectively combated.
Review support tools are especially useful in projects being developed by multiple teams located in different countries or time zones. In such cases, online reviews are not only useful, but may also be the only really practicable solution.
Static analysis
Static analysis tools provide figures relating to various aspects of the code—for example, cyclomatic complexity3 or other code metrics. This kind of data can be used to identify particularly complex, error-prone (i.e., risky) blocks of code that can then be reviewed in more detail separately and manually.
Such tools can also be used to check that coding guidelines are adhered to (for example guidelines that support code security or code portability aspects). Checking HTML code for broken or invalid links is also a form of static analysis.
Our Tip Increase analytical detail step by step
- Static analysis tools list all “suspicious” places in the code, and such lists of findings can quickly become very long indeed. Most tools offer functionality for defining the scope and detail of the analysis. We recommend using a setting that keeps the number of findings small for an initial analysis, and you can always refine your settings later. These kinds of tools are only accepted if they are set up specifically to suit the project at hand.
Side Note: Analyzing data use
Data flow analysis is a good example of a static analytical technique. The aim of the process is to analyze data usage along its path(s) through the program code. Findings detected by this kind of tool are called “data flow anomalies” (or just “anomalies”). An anomaly is an inconsistency that can but doesn’t necessarily cause a failure. Anomalies need to be flagged as risks.
Examples for data flow anomalies are when a variable is referred to although it hasn’t been initialized or a reference to a variable without a value. The following three states of a variable need to be distinguished here:
- defined (d): the variable is assigned a value
- referenced (r): the variable’s value is referenced
- undefined (u): the variable has no defined value
Data flow anomalies
Three types of data flow anomalies can be distinguished:
- ur anomaly
An undefined variable value (u) is read on a path (r) - du anomaly
The variable has a value (d) that becomes invalid (u) without having been used in the meantime - dd anomaly
The variable receives a second value (d) on a program path without having used the first value (d)
Example of anomalies
The following examples illustrate data flow anomalies using a C++ code fragment. The function in question is designed to swap the integer parameters Max and Min using the variable Help if the value of Min is greater than that of Max:
void Swap (int& Min, int& Max) {
int Help;
if (Min > Max) {
Max = Help;
Max = Min;
Help = Min;
}
}
Analyzing the variables’ usage reveals the following anomalies:
- ur anomaly for the variable Help
The variable is only valid within the function and is first used on the right-hand side of an assignment. At this point it is referenced although its value has not been defined. The variable wasn’t initialized when it was declared (this kind of anomaly can be identified by most compilers if you set an appropriately high warning level).
- dd anomaly for the variable Max
The variable is used twice consecutively on the left-hand side of an assignment, and is thus assigned two values. Either the first assignment can be ignored or use of the first value (before the second assignment) has been overlooked. - du anomaly for the variable Help
The final statement assigns a value to the variable Help that cannot be used because the variable is only valid within the function.
Data flow anomalies are not usually obvious
The anomalies in our examples are obvious. However, don’t forget that—in “real-life code”—any number of other assignments using other variables could take place between the ones shown above, making the anomalies much more difficult to identify and easy to overlook during a review. Using a data flow analysis tool will give you a better chance of discovering anomalies like these.
Not every anomaly causes a failure. For example, a du anomaly won’t always have a direct effect, and the program can continue to run. Nevertheless, we need to ask why the assignment occurs at this point before the variable’s validity ends. It is always worth taking a closer look at the parts of a program that show anomalies, and you will usually find further inconsistencies if you do.
Model checkers
Like source code, specifications can be analyzed for certain attributes too, provided that they are written using some kind of formal modeling language or notation. Tools that do this job are called “model checkers”. They “read” the structure of a model while checking static attributes such as missing states, missing state transitions, and other inconsistencies. The specification-based test generators discussed in section 7.1.2 are often addons to static model checkers. This type of tool is particularly useful for developer-side test case generation.
7.1.4Tools for Automating Dynamic Tests
Tools take over repetitious testing tasks
People who refer to “test tools” are often actually referring to the tools used to automate dynamic testing. These are tools that relieve testers of repetitious “mechanical” testing tasks such as providing a test object with test data, recording the test object’s reactions, and logging the test process.
Probe effects
In most cases, these tools run on the same hardware as the test object, what can definitely influence the test object’s behavior. For example, the actual response times of the tested application or the overall memory usage may be different when executing the test object and the test tool in parallel, and therefore the test results may differ too. Accordingly, you need to take such interactions—often called “probe effects”—into account when evaluating your test results. Because they are connected to the test object’s test interface, the nature of these types of tools varies a lot depending on the test level they are used on.
Unit test frameworks
Tools that are designed to address test objects via their APIs are called unit test frameworks. They are used mainly for component and integration testing (see sections 3.4.1 and 3.4.2) or for a number of special system testing tasks (see section 3.4.3). A unit test framework is usually tailored to a specific programming language.
JUnit is a good example of a unit test framework for use with the Java programming language, and many others are available online ([URL: xUnit]). Unit test frameworks are also the foundation of test-driven development (TDD, see section 3.4.1).
System testing using test robots
If the test object’s user interface serves as the test interface, you can use so-called test robots. Which are also known as “capture and replay” tools (for obvious reasons!). During a session, the tool captures all manual user operations (keystrokes and mouse actions) that the tester performs and saves them in a script.
Running the script enables you to automatically repeat the same test as often as you like. This principle appears simple and extremely useful but does have some drawbacks, which we will go into in the next section.
How Capture/Replay Tools Work
Capture
In capture mode, the tool records all keystrokes and mouse actions, including the position and the operations it sets in motion (such as clicked buttons). It also records the attributes required to identify the object (name, type, color, label, x/y coordinates, and so on).
Expected/actual comparison
To check whether the program behaves correctly, you can record expected/actual behavior comparisons, either during capture or later during script post-processing. This enables you to verify the test object’s functional characteristics (such as field values or the contents of a pop-up message) and also the layout-related characteristics of graphical elements (such as the color, position, or size of a button).
Replay
The resulting script can then be replayed as often as you like. If the values diverge during an expected/actual comparison, the test fails and the robot logs a corresponding message. This ability to automatically compare expected and actual behaviors makes capture/replay tools ideal for automating regression testing.
One common drawback occurs if extensions or alterations to the program alter the test object’s GUI between tests. In this case, an older script will no longer match the current version of the GUI and may halt or abort unexpectedly. Today’s capture/replay tools usually use attributes rather than x/y coordinates to identify objects, so they are quite good at recognizing objects in the GUI, even if buttons have been moved between versions. This capability is called “GUI object mapping” or “smart imaging technology” and test tool manufacturers are constantly improving it.
Test programming
Capture/replay scripts are usually recorded using scripting languages similar to or based on common programming languages (such as Java), and offer the same building blocks (statements, loops, procedures, and so on). This makes it possible to implement quite complex test sequences by coding new scripts or editing scripts you have already recorded. You will usually have to edit your scripts anyway, as even the most sophisticated GUI object mapping functionality rarely delivers a regression test-capable script at the first attempt. The following example illustrates the situation:
Case Study: Automated testing for the VSR-II ContractBase module
The tests for the VSR-II ContractBase module are designed to check whether vehicle purchase contracts are correctly saved and also retrievable. In the course of test automation, the tester records the following operating sequence:
Switch to the “contract data” form;
Enter customer data for person “Smith”;
Set a checkpoint;
Save the “Smith” contract in the database;
Leave the “contract data” form;
Reenter the form and load the “Smith”
contract from the database;
Check the contents of the form against the checkpoint;
If the comparison delivers a match, we can assume that the system saves contracts correctly. However, the script stalls when the tester re-runs it. So what is the problem?
Is the script regression test-ready?
During the second run, the script stalls because the contract has already been saved in the database. A second attempt to save it then produces the following message:
“Contract already saved.
Overwrite: Yes/No?”
The test object then waits for keyboard input but, because the script doesn’t contain such a keystroke, the script halts.
The two test runs have different preconditions. The script assumes that the contract has not yet been saved to the database, so the captured script is not regression test-capable. To work around this issue, we either have to program multiple cases to cover the different states or simply delete the contract as a “cleanup” action for this particular test case.
The example illustrates a good example of the necessity to review and edit a script. You therefore need programming skills to create this kind of automated test. Furthermore, if you aim to produce automation solutions with a long lifecycle, you also need to use a suitable modular architecture for your test scripts.
Test automation architectures
Using a predefined structure for your scripts helps to save time and effort when it comes to automating and maintaining individual tests. A well-structured automation architecture also helps to divide the work reasonably between test automators and test specialists (see section 6.1.2)
You will often find that a particular script is repeated regularly using varying test data sets. For instance, in the example above, the test needs to be run for other customers too, not just Ms. Smith.
Data-driven test automation
One obvious way to produce a clear structure and reduce effort is to separate the test data from the scripts. Test data are usually saved in a spreadsheet that includes the expected results. The script reads a data set, runs the test, and repeats the cycle for each subsequent data set. If you require additional test cases, all you have to do is add a line to the spreadsheet while the script remains unchanged. Using this method—called “data-driven testing”—even testers with no programming skills can add and maintain test cases.
Comprehensive test automation often requires certain test procedures to be repeated multiple times. For example, if the ContractBase component needs to be tested for pre-owned vehicle purchases as well as new vehicle purchases, it would be ideal if the same script can be used for both scenarios. Such re-use is possible if you encapsulate the appropriate steps in a procedure (in our case, called something like check_contract(customer)). You can then call and re-use the procedure from within as many test sequences as you like.
Keyword-driven test automation
If you apply an appropriate degree of granularity and choose your procedure names carefully, the set of names or keywords you choose reflect the actions and objects from your application domain (in our case, actions and objects such as select(customer), save(contract), or submit_order(vehicle)). This methodology is known as command-driven or keyword-driven testing.
As with data-driven testing, the test cases composed from the keywords and the test data are often saved in spreadsheets, so test specialists who have no programming skills can easily work on them.
To make such tests executable by a test automation robot, each keyword also has to be implemented by a corresponding script using the test robot’s programming language. This type of programming is best performed by experienced testers, developers, or test automation specialists.
Keyword-driven testing isn’t easily scalable, and long lists of keywords and complex test sequences quickly make the spreadsheet tables unwieldy. Dependencies between individual actions or actions and their parameters, are difficult to track and the effort involved in maintaining the tables quickly becomes disproportionate to the benefits they offer.
Side Note: tools supporting data-driven and keyword-driven testing
Advanced test management tools offer database-supported data-driven and keyword-driven testing. For example, test case definitions can include test data variables, while the corresponding test data values are stored and managed (as test data rows) within the tool’s database. During test execution the tool automatically substitutes the test data variables with concrete test data values. In a similar way, keywords can be dragged and dropped from the tool’s keyword repository to create new test sequences, and the corresponding test data are loaded automatically, regardless of their complexity. If a keyword is altered, all affected test cases are identified by the tool, which significantly reduces the effort involved in test maintenance.
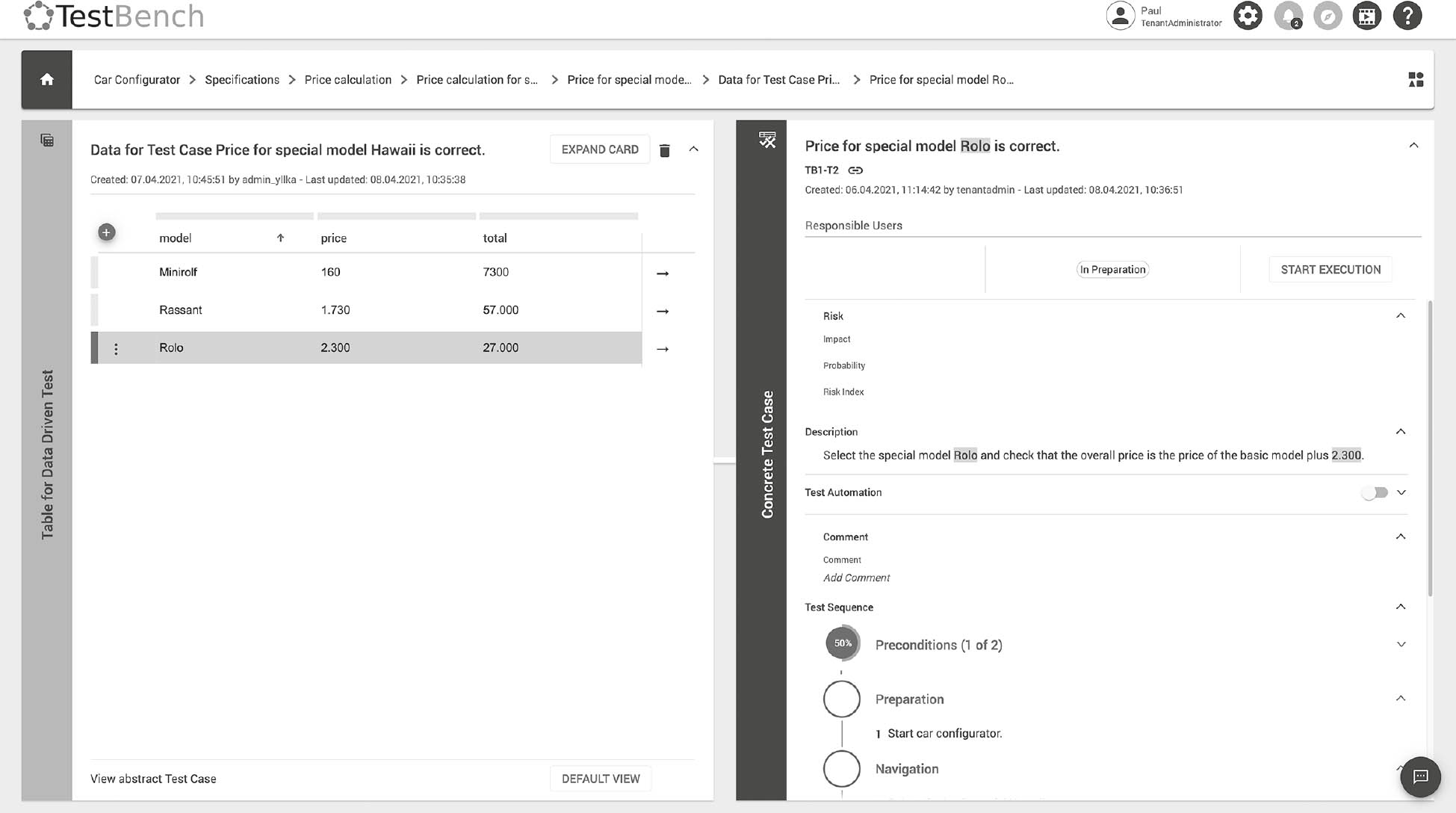
Fig. 7-1Data-driven testing using TestBench [URL: TestBench CS]
Comparators
Comparators are tools that compare expected and actual test results. They can process commonly used file and database formats and are designed to identify discrepancies between expected and actual data. Test robots usually have built-in comparison functionality that works with console content, GUI objects, or copies of screen contents. Such tools usually have filter functionality that enables you to bypass data that isn’t relevant to the current comparison. This is necessary, for example, if the file or screen content being tested includes date or time data, as these vary from test run to test run. Comparing differing timestamps would, of course, raise an unwanted flag.
Dynamic analysis
Dynamic analysis tools provide additional information on the software’s internal state during dynamic testing—for example, memory allocation, memory leaks, pointer assignment, pointer arithmetic4, and so on).
Coverage analysis
Coverage (or “code coverage”) tools provide metrics relating to structural coverage during testing (see section 5.2). To do this, a special “instrumentation” component in the code coverage tool inserts measuring instructions into the test object before testing begins. If an instruction is triggered during testing, the corresponding place in the code is marked as “covered”. Once testing is completed, the log is analyzed to provide overall coverage statistics. Most coverage tools provide simple coverage metrics, such as statement or decision coverage (see sections 5.2.1 and 5.2.2). When interpreting coverage data, it is important to remember that different tools deliver differing results, or that a single metric can be defined differently from tool to tool.
Debuggers
Although they are not strictly test tools, debuggers enable you to run through a program line by line, halt execution wherever you want, and set and read variables at will.
Debuggers are primarily analysis tools used by developers to reproduce failures and analyze their causes. Debuggers can be useful for forcing specific test situations that would otherwise be too complicated to reproduce. They can also be used as interfaces for component testing.
7.1.5Load and Performance Testing Tools
Load and performance tests are necessary when a system has to execute large numbers of parallel requests or transactions (load), whereby predefined maximum response times (performance) are not to be exceeded. Real-time systems, most client/server systems, and web-based or cloud-based systems have to fulfill these kinds of requirements.
Measuring response times
Performance tests verify how response times change with increasing load (for example, with increasing numbers of parallel user requests) and determine the point at which a system is overloaded and no longer responds quickly enough. Performance testing tools provide testers with comprehensive logs, reports, and graphs that illustrate the changing relationship between performance and load, and provide indications of where performance bottlenecks might occur. If it becomes apparent that the system is likely to underperform under everyday loads, you will need to tune the system accordingly (for example, by adding hardware or tweaking performance-critical software).
Load and performance testing tools have to perform two tasks: generating synthetic load (database queries, user transactions, or network traffic) and measuring, logging, and visualizing the test object’s performance under these loads. Performance can be measured and evaluated in various ways, such as response times, storage requirements, network traffic, and similar. The corresponding “sensors” are called monitors.
The effects of intrusive measurement
The use of the load and performance test tool or the associated monitor can be “intrusive”, i.e. the tool can influence the actual result of the test: The test object’s (timing) behavior can vary depending on how measurements are taken and the type of monitor in use. In other words, the entire process is subject to a certain “examination effect”5 that you have to take into account when interpreting the results. Experience is essential when using load and performance testing tools and evaluating the results.
7.1.6Tool-Based Support for Other Kinds of Tests
System access and data security
Tools are also available to check for security vulnerabilities6 that could be used to gain unauthorized access to a system. Anti-virus apps and firewalls belong to this category of tool, as they produce logs that can be used to identify security flaws. Tests that reveal such flaws or check whether they have been remedied are generally called (IT) security tests.
Evaluating data quality
Projects that replace outdated systems with new ones usually involve the migration or conversion of large amounts of data. System testing then necessarily involves testing data integrity before and after conversion or migration. Tools supporting this kind of testing can check whether the data sets are correct and complete, or whether they satisfy certain syntactic or semantic rules or conditions.
Case Study: VSR-II data quality
Various aspects of data quality are important to the VSR-II project:
- The DreamCar module displays various vehicle model and equipment variants. Even if the DreamCar module is working correctly, missing or incorrect data can produce failures from the user’s point of view. For example, a particular model cannot be configured or non-deliverable combinations of options can be configured. In cases like this, a customer may look forward to purchasing a vehicle that isn’t actually available.
- Dealers use the NoRisk module to provide appropriate insurance. If some of the data are outdated—such as the vehicle’s collision damage rating—the system is likely to calculate an incorrect premium. If insurance is too expensive, the customer might opt to search for a cheaper policy online rather than buying insurance directly from the dealer.
- Dealers use the ContractBase module to manage all historical customer data, including purchase contracts and all repair work. For example, in Germany the sums involved are all displayed in Euros regardless of whether the invoice is dated before or after the currency switch from Deutschmarks to Euros in 2002. Were all the records converted correctly at the time, or did the customer really pay so little for a repair back then?
- As part of regular sales promotions, dealers send out special offers and promotions to regular customers. Customer addresses and data relating to the age and model of the customer’s current vehicle are saved in the system. However, customers will only receive fully tailored advertising if all the data sets are correct and consistent. Does VSR-II prevent data collection errors such as zip codes that don’t match street names? Does the system automatically ensure that all marketing-related attributes are filled out (such as the purchase date and age of a pre-owned vehicle)? Does the system check that customers have agreed to receive advertising?
The customer records saved in the ContractBase module contain a lot of personal data. The ConnectedCar module’s functions also enable the dealer or the manufacturer to look up private data, such as the vehicle’s current position, routes taken, driver behavior, accidents, and so on. The collection, saving and use of such data is subject to appropriate data-protection regulations (such as the European DSGVO, [URL: DSGVO]). The system test therefore has to verify that VSR-II complies with all the relevant laws and other stipulations. Furthermore, these tests must not be performed using the original customer data! They can only be performed using anonymized or fictional data, which requires the use of specialist tools to generate appropriate test data sets.
These examples show that data quality is primarily the responsibility of the system operator and/or user. However, the system’s manufacturer is definitely involved in supporting data quality—for example, by supplying fault-free data conversion software, meaningful input consistency and plausibility checks, legally watertight data usage, and other similar measures.
Other tools
In addition to the types of tools discussed above, there are also tools available for performing other, more specialized tasks—for example:
- Usability and general accessibility testing to make sure all users are catered for
- Localization tests check whether an application and its GUI have been translated completely and correctly into the local language
- Portability tests verify that an application or system runs properly on all its supported platforms
7.2Benefits and Risks of Test Automation
Software automation tool selection, purchase, and maintenance costs money, while acquiring appropriate hardware and training staff to use them uses further resources. The cost of rolling out a complex tool to a large number of workstations can quickly run into six figures. As with any other investment, the planned amortization period of a new testing tool is a critical point when deciding whether to go ahead with a rollout.
Cost-benefit analysis
In the case of tools that automate test execution (test robots), it is relatively simple to estimate the savings compared with running tests manually. The effort involved in programing automated tests has to be subtracted from these savings, so a cost-benefit analysis usually delivers a negative result after a single test run. It is only once you have performed multiple automated regression test runs (see figure 7-2) that you really begin to save money with each test execution cycle.
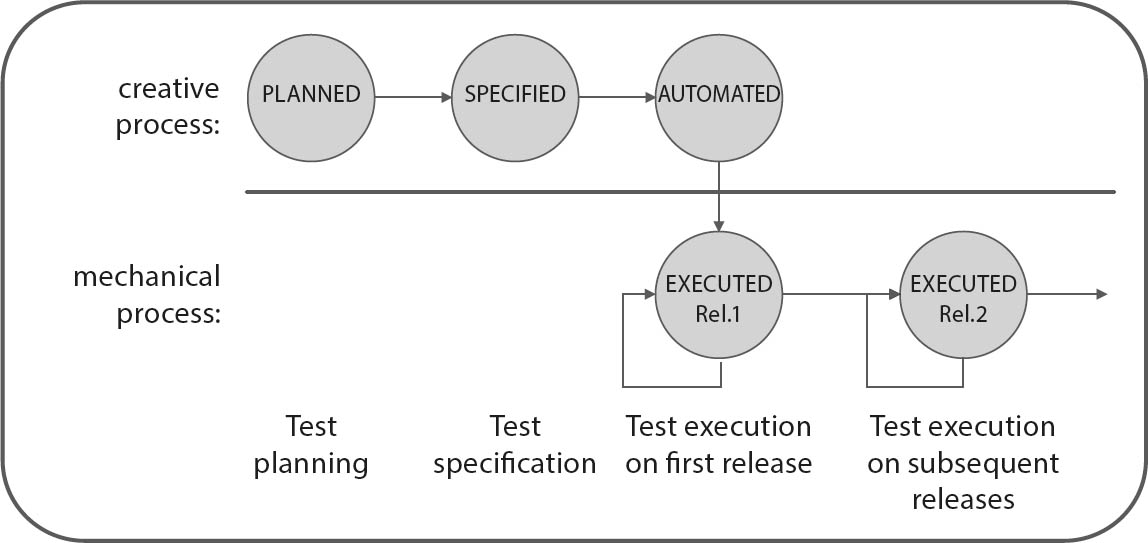
Fig. 7-2Test case lifecycle
The balance becomes positive following a number of regression test runs, although it is still tricky to accurately estimate the amortization period. You will only effectively cover your costs if you can program test cases that are regression test-capable. If this is the case, a capture/replay tool can begin to make real savings after just three test cycles. However, this kind of calculation only makes sense if manual testing is a real alternative. Many tests (for example, performance tests) cannot be performed manually anyway.
Evaluate the influence on overall testing effectiveness
However, evaluating testing effort only doesn’t tell the whole story. You need to consider how a tool increases overall testing effectiveness too—for example, when more failures are revealed and thus corrected. In the medium term, this can reduce the development, support, and maintenance costs of a project, providing a much more attractive potential for overall cost savings.
Potential benefits of introducing a test tool
To summarize, the potential benefits are:
- Tools cannot replace the creative side of testing, but they can support it. Using tools creates better test cases and test data, and increases the overall effectiveness of the testing process.
- Automation reduces testing effort (or increases the number of test cases that can be performed using the same amount of effort). However, using more test cases doesn’t automatically equate to better testing.
- Tools simplify the collection, evaluation and communication of data relating to test progress, achieved coverage, and failures and their distribution among the test objects. These data help you to paint an objective picture of the quality of the software being tested.
Potential risks of introducing tools
Introducing new tools into the testing process also involves risks. These include:
- The expectations attached to a tool can be unrealistic.
- It is all too easy to underestimate the time it takes and the costs involved in introducing a tool. The effort involved in using the new tool can be underestimated too.
- A tool cannot be used effectively (or cannot be used at all) because a defined testing process is either not established or, if it exists, not well practiced.
- The improvements and changes in the testing process required to realize the tool’s potential are more extensive than anticipated.
- The effort involved in maintenance and version control for test cases, test data, and other test documents is greater than expected.
- Using the tool in situations where manual testing is simpler and more economical.
- The new tool does not work well enough with existing tools.
- A tool’s manufacturer goes out of business or no longer supports the product.
- The open source project developing the tool is discontinued.
- New versions of a tool no longer support older technology that is still used in the system being tested.
- Tool support is poor or is no longer provided.
7.3Using Test Tools Effectively
7.3.1Basic Considerations and Principles
Some of the tools listed above (such as comparators or coverage analyzers) are already built into several operating systems (Linux, for example), enabling testers to perform basic testing using “onboard” tools. However, built-in tools often have fairly limited functionality, so you will usually need additional, specialized tools to test effectively.
As described above, there is a broad range of tools available that support all testing activities—from the creative act of planning and specifying test cases to the test drivers and test robots that offer the purely mechanical assistance involved in automating testing processes.
“Automating chaos just gives faster chaos”
If you are thinking about acquiring test tools, test drivers or test robots shouldn’t be your first (or only) choice. The effectiveness of tool support depends a lot on the specific project environment and the maturity of the development and test processes. In poorly organized projects where “on-demand programming” is the order of the day, documentation is unheard of, and testing is either poorly structured or simply doesn’t happen, there is no point in automating the testing process. Even the best tools cannot replace a non-existent or sloppy process. To quote [Fewster 99, p. 11]: “It is far better to improve the effectiveness of testing first than to improve the efficiency of poor testing. Automating chaos just gives faster chaos”.
Only automate well-organized test processes
In such situations, you need to sort out your manual testing processes first. In other words, you need to define, implement, and breathe life into a systematic testing process before you consider using tools to improve productivity or increase product quality.
Our Tip Introduce tools in sequence
- Try to stick to the following sequence of tool types when introducing test tools:
- Defect management
- Configuration management
- Test planning
- Test execution
- Test specification
Don’t forget the learning curve
You also need to consider the time it takes for your team to learn how to use new tools. The learning curve involved can cause a drop in productivity in the initial transitional phase, making it extremely risky to introduce new tools in the hope of using “a little automation” to bridge staffing gaps in high-stress development phases.
7.3.2Tool Selection
Once you have decided which test tasks you want to automate, you can begin the tool selection process. Because the cost of investing in a new tool can be very high (see above), you need to plan the process carefully. The tool selection process comprise five steps:
- Specify the requirements for the planned usage
- Research and creation of a list of suitable candidates
- Demos and trials
- Create a shortlist based on your requirements
- Proof of Concept
Selection criteria
In Step 1, the following criteria influence requirements specification:
- Compatibility with the targeted test objects
- Tester know-how regarding the selected tool and/or the test task it supports
- Simplicity of integration into the existing development and test environment
- Potential integration with other existing (test) tools
- The platform the tool is due to run on
- Manufacturer support, reliability, and reputation
- Benefits and drawbacks of the available licensing options (for example, commercial vs. open-source, purchase vs. subscription)
- Price and cost of maintenance
These and other criteria need to be listed and prioritized. Deal-breaker (i.e., essential) criteria need to be flagged as such7.
Market research and shortlisting
The next step is to compile a list of the available tools in each category that includes a description of each. You can then check out the best-sounding choices in-house or have the manufacturer demonstrate them. These experiments and demos usually make it fairly obvious which products work best for you and which manufacturers offer the best service. The most appropriate tools are then put on a shortlist and you need to answer the following questions for the shortlisted products:
- Is the tool compatible with your test objects and your existing development environment?
- Do the attributes that got the tool onto the shortlist function as required in real-world situations?
- Can the manufacturer provide professional-grade support for standard and non-standard queries?
7.3.3Pilot Project
Once you have made a selection, you have to roll out your new tool. This is usually done within the context of a pilot project in order to verify the tool’s usefulness in a real-world, project-based situation. A pilot project should be led and implemented by persons who were not involved in the tool selection and evaluation process, as this can lead to unintentional bias.
Pilot usage
Pilot usage should provide additional technical data and practical experience in using the new tool in the planned environment. This should demonstrate where training is necessary and where you need to make changes to the testing process. You can also establish or update guidelines for a broader-based rollout (for example, naming conventions for files and test cases or test design rules). If you are rolling out test drivers or test robots, you should decide whether it makes sense to plan and build a library of test cases for re-use in different projects.
If you are piloting tools that collect and evaluate metrics, you need to consider which metrics really are relevant to the project and to what extent the tool supports the collection of this kind of data. The tool may need to be configured appropriately to ensure that the desired metrics are captured, recorded, and processed correctly.
7.3.4Success Factors During Rollout and Use
If the pilot project confirms your expectations, you can begin the project-wide and/or company-wide rollout. A rollout requires broad-based acceptance, as a new tool always generates extra work for its users. The following are factors that are important for a successful rollout:
- A large-scale rollout needs to be performed gradually
- Tool usage has to be firmly embedded in the relevant processes
- Make sure you offer relevant user training and coaching
- Always provide usage guidelines and recommendations for the new tool
- Collect user experience and make it available to everyone in the form of a FAQ or a “Tips and Tricks” document
- Offer support via in-house user groups, tool experts, and similar
- Continually track and evaluate the tool’s acceptance levels and usefulness
Testing without tools is inefficient
This chapter has discussed the difficulties and additional effort involved in selecting and implementing tools that support various aspects of the testing process. We hope you are not now thinking that using additional tools is not worth the effort! In fact, the opposite is true—testing without tool-based support is basically impossible, especially in large-scale projects. However, you must always plan tool rollouts very carefully if you want to avoid your investment turning into a dud that just ends up gathering dust.
7.4Summary
- For each phase in the testing process, tools are available to help testers perform their work more efficiently, reliably, or at a higher quality level. Some tasks, such as load and performance testing, can only be performed satisfactorily with tool-based support.
- Component and integration testing tools are squarely aimed at developers. These include unit test frameworks, test-driven development (TDD) frameworks, continuous integration (CI) tools, static analysis tools, and dynamic analysis (code coverage) tools.
- Test tools only provide benefits if the testing process itself is mastered and runs in a well-defined manner.
- The introduction of a new test tool can involve significant investment, so the tool selection process has to be conducted carefully and transparently.
- The potential benefits of tools are offset by risks that can cause tool usage to fail.
- A tool rollout must be appropriately supported, with training and information events for the future users. Information and trainings help to ensure acceptance and thus the regular use of the tool.
- The tool selection and implementation process consists of the following steps: tool selection, pilot project, rollout, permanent user support.
1.Sometimes referred to as CAST (Computer Aided Software Testing) tools, similarly to CASE (Computer Aided Software Engineering) tools.
2.A list of common test tools and providers organized according to tool types is available online at [URL: Tool List].
3.See [URL: McCabe].
4.Many programming languages use “pointers” to enable direct access to specific memory addresses. Pointers are extremely error-prone and therefore play a significant role in dynamic testing.
5.Dynamic analysis tools can have intrusive effects too. For example, coverage metrics can be directly affected by the use of a code coverage tool.
6.The Open Web Application Security Project (OWASP, [URL: OWASP]) publishes a catalog of potential security vulnerabilities that require security testing in web applications.
7.A sample catalog of selection criteria is available for download at [URL: imbus-downloads].