
Chapter 5. MapR Streams
A second option for a messaging system that supports the requirements of a stream-based architecture is MapR Streams. Developed as a ground-up reimplementation of the Apache Kafka API, MapR Streams provides the same basic functions of Kafka but also some additional capabilities, as we’ll discuss in this chapter. MapR Streams is integrated into the MapR converged data platform, and it is compatible with the Kafka 0.9 API. Most programs written to run on that API will also run efficiently, without change, on MapR Streams. If you know how to use Kafka, you’ll have a head start on understanding how to use Streams. If you are not familiar with Apache Kafka, you may want to review the previous chapter.
Innovations in MapR Streams
Although similar to Kafka, MapR Streams enables you to do some very different things. At a high level, the differences include running a much larger number of topics and applying policies such as time-to-live or controlled access to many topics as a group. (Such a group of topics in MapR is called a stream, as described later.) The ability to set up a very large number of topics in MapR Streams lets you build topics that reflect business goals rather than infrastructural limitations. This capability allows a good fit between architecture and the business problem being addressed.
Integration of the MapR messaging system into the MapR converged data platform means less administration than is required when the messaging technology is run on a separate cluster. Integration also makes it easier to write end-to-end applications, and it lets you operate under the same security system for streams, files, and databases.
Another significant innovation of MapR Streams is geo-distributed replication. This capability makes it possible for you to share streaming data between multiple data centers, even in distant locations. This type of replication means you can update a topic at any of several locations and see the effects at all of your data centers. Geo-distribution via the messaging system is a powerful option that expands stream-based design to some interesting use cases, an example of which is described in Chapter 7.
Here is a more detailed explanation of the differences you’ll find with MapR Streams:
-
MapR Streams includes a new file system object type known as a stream that has no parallel in Kafka. Streams are first-class objects in the MapR file system, alongside files, directories, links, and NoSQL tables.
-
A Kafka cluster consists of a number of server processes called brokers that collectively manage message topics, while a MapR cluster has no equivalent of a broker.
-
Topics and partitions are stored in the stream objects on a MapR cluster. There is no equivalent of a stream in a Kafka cluster since topics and partitions are the only visible objects.
-
Each MapR stream can contain hundreds of thousands or more topics and partitions, and each MapR cluster can have millions of streams. In comparison, it is not considered good practice to have more than about a thousand partitions on any single Kafka broker.
-
MapR streams can be replicated to different clusters across intermittent network connections. The replication pattern can contain cycles without causing problems, and streams can be updated in multiple locations at once. Message offsets are preserved in all such replicated copies.
-
The distribution of topic partitions and portions of partitions across a MapR cluster is completely automated, with no administrative actions required. This is different from Kafka, where it is assumed that administrators will manually reposition partition replicas in many situations.
-
The streams in a MapR cluster inherit all of the security, permissioning, and disaster-recovery capabilities of the basic MapR platform.
-
Most configuration parameters for producers and consumers that are used by Kafka are not supported by MapR Streams.
These differences can have a large impact when you are architecting a large system, but when writing a program for MapR Streams, you will rarely notice any important difference other than the much larger number of topics that can reasonably be supported. There are some differences in the configuration of producers and consumers, but the most critical parameters have similar meaning, and many applications use default values in any case.
If you would like to know a bit of the history of why and how MapR Streams was developed, continue with the next section. Alternatively, if you just want to know how MapR Streams works and how to use it, skip forward to “How MapR Streams Works”.
History and Context of MapR’s Streaming System
The adoption of Apache Kafka for building large-scale applications over the last few years has been dramatic, and it has opened the way for support of a streaming approach. Naturally a large number of those using Kafka up to now have been technology early-adopters, which is typical in this phase of the lifecycle of an open source project. Early adopters are often able to achieve surprising levels of success very quickly with new projects like Kafka, as they have done previously with Apache projects Hadoop, Hive, Drill, Solr/Lucene, and others. These projects are groundbreaking in terms of what they make possible, and it is a natural evolution for new innovations to be implemented in emerging technology businesses before they are mature enough to be adopted by large enterprises as core technologies.
To improve the maturity of these projects, we need to solve standard questions of manageability, complexity, scalability, integration with other major technology investments, and security. In the past, with other open source projects, there have been highly variable success rates in dealing with these “enterprisey” issues. Solr, for instance, responded to security concerns by simply ruling any such concerns as out of scope, to be handled by perimeter security. The Hive community has responded to concerns about integration with SQL-generating tools by adopting Apache Calcite as a query parser and planner.
In some cases, these issues are very difficult to address within the context of the existing open source implementation. For instance, Hadoop’s default file system, HDFS, supports append-only files, cannot support very many files, has had a checkered history of instability, and imposes substantial overhead because it requires use of machines that serve only to maintain metadata. Truly fixing these problems using evolutionary improvements to the existing architecture and code base would be extremely difficult. Some improvements can be made by introducing namespace federation, but while these changes may help with one problem (the limited number of files), they may exacerbate another (the amount of nonproductive overhead and instability).
If, however, a project establishes solid interface standards in the form of simple APIs early on, these problems admit a solution in the form of a complete reimplementation, possibly in open source but not necessarily. As such, Accumulo was a reimplementation of Apache HBase, incorporating features that HBase was having difficulties providing. Hypertable was another reimplementation done commercially. MapR-DB is a third reimplementation of HBase that stays close to the original HBase API as well as providing a document-style version with a JSON API.
Similarly, HDFS has seen multiple reimplementations. Some use existing storage systems, such as the S3 system of Amazon’s Web Services. Others add major functionality. One example of the latter is Kosmix file system (KFS), which added mutability to files. Another example of the addition of major functionality is MapR-FS, which added full mutability, snapshotting, and higher performance and eliminated the name node issues by eliminating the name node entirely. Some reimplementations, notably Hypertable and KFS, have failed to gain significant adoption and have largely disappeared. Others, such as the S3 interface for HDFS, MapR-DB, and MapR-FS, have seen widespread adoption and use, particularly in environments very different from those that spawned HDFS in the first place. Thus, Netflix uses S3 extensively because they use Amazon’s cloud infrastructure extensively, while many financial, security, and telecom applications have gravitated to MapR-FS to satisfy their needs for stability and durability. The outcome of a reimplementation typically depends on whether or not the new project actually solves an important problem that is difficult to change in the original project, and whether or not the original project has defined a clean enough API to be able to be reliably implemented.
With Kafka, there are issues that look like they will turn out to be important, and many of these appear to be difficult to resolve in the original project. These include complexity of administration, scaling, security, and the question of how to handle multiple models of data storage (such as files and tables), as well as data streams in a single, converged architecture.
MapR Streams is a reimplementation of Kafka that aims to solve these problems while keeping very close to the API that Kafka provides. Even though the interface is similar, the implementation is very different. MapR Streams is fundamentally based on the same MapR technology core that anchors MapR-FS and MapR-DB. This allows MapR Streams to reuse many of the solutions already available in MapR’s technology core for administration, security, disaster protection, and scale. Interestingly, reimplementing Kafka using different technology only became possible with the Kafka 0.9 API. Earlier APIs exposed substantial amounts of internal implementation details that made it nearly impossible to reimplement in a substantially improved way.
How MapR Streams Works
To understand how MapR Streams works internally, it is useful to know that it operates in a completely different way than Kafka does. Kafka’s internal mechanism establishes a strong identity between individual files and replicas of topic partitions. Messages sent to a topic are appended to the most current file in a partition. When the current file becomes large, a new one is opened. Thus, a producer sending messages results in efficient sequential writes to disk at the Kafka broker. When a consumer reads messages starting at some offset, all that needs to happen is for a file to be opened and messages sent to the consumer using sequential reads. Both of these processes are fast and simple. This simplicity, however, also imposes a number of limitations on Kafka. The limitation on the number of partitions per broker, for instance, stems directly from this implementation choice. Likewise, it is essential that a partition fit entirely on a single file system on a single broker in order to guarantee that the request for messages from a topic partition is received by a broker (regardless of which messages). The key virtue of the sequential file I/O strategy used in Kafka, for the most part, is that batches of messages can be written and read using only relatively large sequential I/O operations on a single file.
With MapR Streams, the fundamental internal technology is quite different. Instead of basing the implementation directly on generic file capabilities, Streams explicitly uses mechanisms such as transactions, containers, and B-trees that are available inside the MapR data platform. These primitive mechanisms allow a MapR stream to model all of the necessary user-visible capabilities of the Kafka API, such as messages and producer and consumer offsets, directly in the stream object that lives in the data platform. The MapR data platform has existing segmentation techniques to distribute large objects across multiple containers and to replicate the blocks inside a container so neither of these issues has to be addressed in the stream implementation itself. Likewise, streams benefit from the way that the MapR platform can efficiently transform updates to table-like data structures into large, sequential I/O operations. Therefore, while Kafka is designed to directly implement these large transfers, MapR Streams simply inherits the property of efficient I/O patterns from the core platform. The Kafka strategy is better if there is no technology core beyond simple files; the MapR strategy allows a wide range of capabilities to be implemented very quickly, but only if the core platform is available.
Because each message is addressed individually in MapR Streams, the cost of a stream depends almost entirely on the total number of messages it contains. Whether the messages are in a single topic or in many makes almost no difference. The exception is that the total number of partitions into which messages are actively being written provides a soft bound on the degree of parallelism. This is a soft bound because automatic stream segmentation can cause the hot part of each partition to move from machine to machine very quickly, if need be, to amortize the total load over many machines. This also means that having a very large number of topics and partitions in a stream is not very expensive. The grouping of topics—even a large number of topics—into a stream for collective management is depicted in Figure 5-1. This can be useful, for example, if you are monitoring sensor data from a large number of automobiles, because you can have a topic per car to which all the measurements from that car are sent. Similarly, you could have a topic per visitor on a website. The result of this flexibility about which data goes into which topic and how many topics you have means that you can effectively sort data into sessions or device histories as it arrives. That can be very useful for certain kinds of analytics.
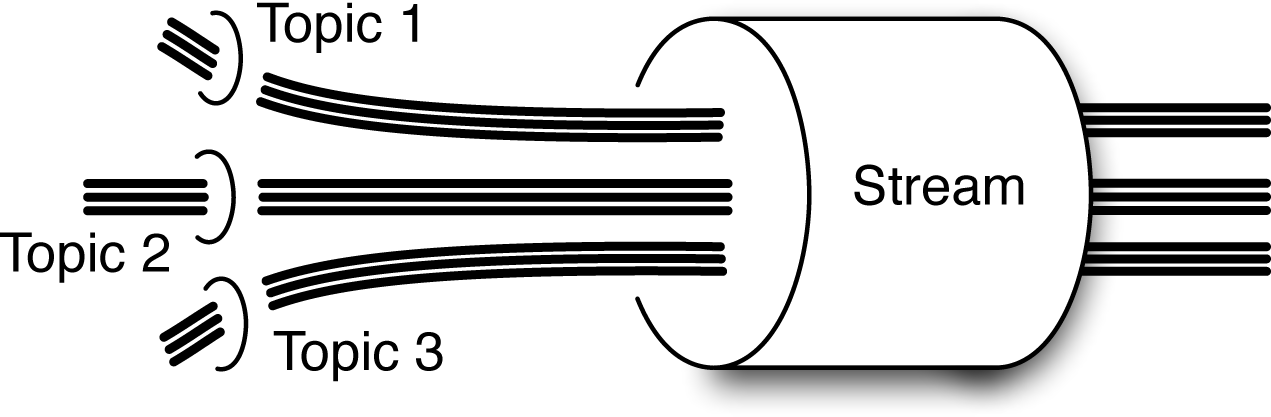
Figure 5-1. With MapR Streams, topics are grouped together into a management structure known as a stream. A MapR stream can contain an astounding number of topics—up to millions. By collecting topics together, it’s convenient to apply policies such as time-to-live to the whole group of topics. Each topic in a MapR stream can be partitioned similarly to how that is done in Kafka. (See Chapter 4, Figure 4-2, for a comparison.) In the current figure, partitions are shown as thick black lines.
How to Configure MapR Streams
One important aspect in which MapR Streams differs from the Kafka 0.9 API is that there are far fewer configuration properties for Streams, and some are unique to Streams. Table 5-1 shows the important producer configuration properties and highlights those properties that are common to both Kafka and Streams, as well as the serialization properties that are common to both producer and consumer configurations.
Key among these differences is a way to set the default stream for a producer. Since Kafka has no concept comparable to a stream, MapR Streams uses the topic name to define which stream is being used. The convention is that the full path of the stream is used, followed by a slash or colon and the topic name. If the streams.producer.default.stream property is set, then for all topic names that do not begin with a slash, the part of the path name up to the topic name is taken from this property instead of from the topic name.
Note that there is no bootstrap.servers property to help connect either producer or consumer to a cluster of brokers. This is unnecessary in programs using MapR Streams since there are no brokers to contact.
| Property | Description | Default value |
|---|---|---|
|
Size of producer buffer memory |
33554432 |
|
Producers can tag data to allow consumers to know the source |
None |
|
The serializer used by the producer and consumer for keys |
None |
|
The serializer used by the producer and consumer for values |
|
|
How long data is buffered by the producer before sending |
3,000 ms |
|
The name of the stream to be used for topics that do not start with / |
The configuration properties for consumers are shown in Table 5-2. Again, properties that Streams has in common with Kafka are marked with an asterisk, and again, there is no bootstrap.servers property since there are no brokers to contact.
On the consumer side, one interesting difference is the streams.consumer.buffer.memory property. This sets the amount of data the consumer will pre-fetch from the stream. With Kafka, no data is read from a broker until the poll() method on the KafkaConsumer object is called. With MapR Streams, however, data is pre-fetched from subscribed topics in order to allow overlap between fetching and computing. This can drive apparent latency for reading messages to essentially zero. Read-ahead does not actually affect the end-to-end latency, however.
As with the producer API, a default stream can be set to allow simple topic names to be used.
| Property | Description | Defult value |
|---|---|---|
|
How often offsets are committed if |
|
|
One of |
|
|
Enables auto-commit of topic offsets |
true |
|
If fewer than this number of bytes are available on the server, the request will block until this many bytes are available |
1 byte |
|
How long a request will wait if it doesn’t have enough bytes to return |
|
|
The name of the consumer group for this consumer |
|
|
The amount of data that the consumer will try to fetch from the stream on each request |
64 kB |
|
Specifies how much memory to use for pre-fetching messages |
64 MB |
|
Specifies the stream to use by default for topics whose names don’t start with / |
Geo-Distributed Replication
MapR Streams supports a number of data center-to-data center replication features. This type of replication goes beyond what can be done at present with Apache Kafka’s MirrorMaker function. The key here is the use of near–real time replication technology similar to the technology used by MapR-DB. This near–real time replication allows continuous transfer of updated records. Interestingly, the replication graph can have loops in it without problems because records that arrive via multiple paths are detected before transmission.
Examples of replication patterns are found in Figure 5-2. Case A shows a simple bidirectional replication between two data centers. Messages can be inserted in the replicated stream in either data center and the changes will be replicated to the other data center as soon as possible. Case B shows a more complex case in which data is shared bidirectionally between San Francisco and Singapore data centers and between Singapore and Sydney data centers. Messages can be inserted into the replicated stream in any data center, although any given topic should only have messages inserted in one data center at a time. In case C, there are no replication loops. Data from New York propagates to London, as does data from Paris to London, but no data is propagated back. The time-to-live can be adjusted so data in New York and Paris only lasts a short while and data in London can be set to be retained for a long time. The ability to replicate data this way is useful for data acquisition use cases. This last case is the only one of the three that can be done easily in Kafka.
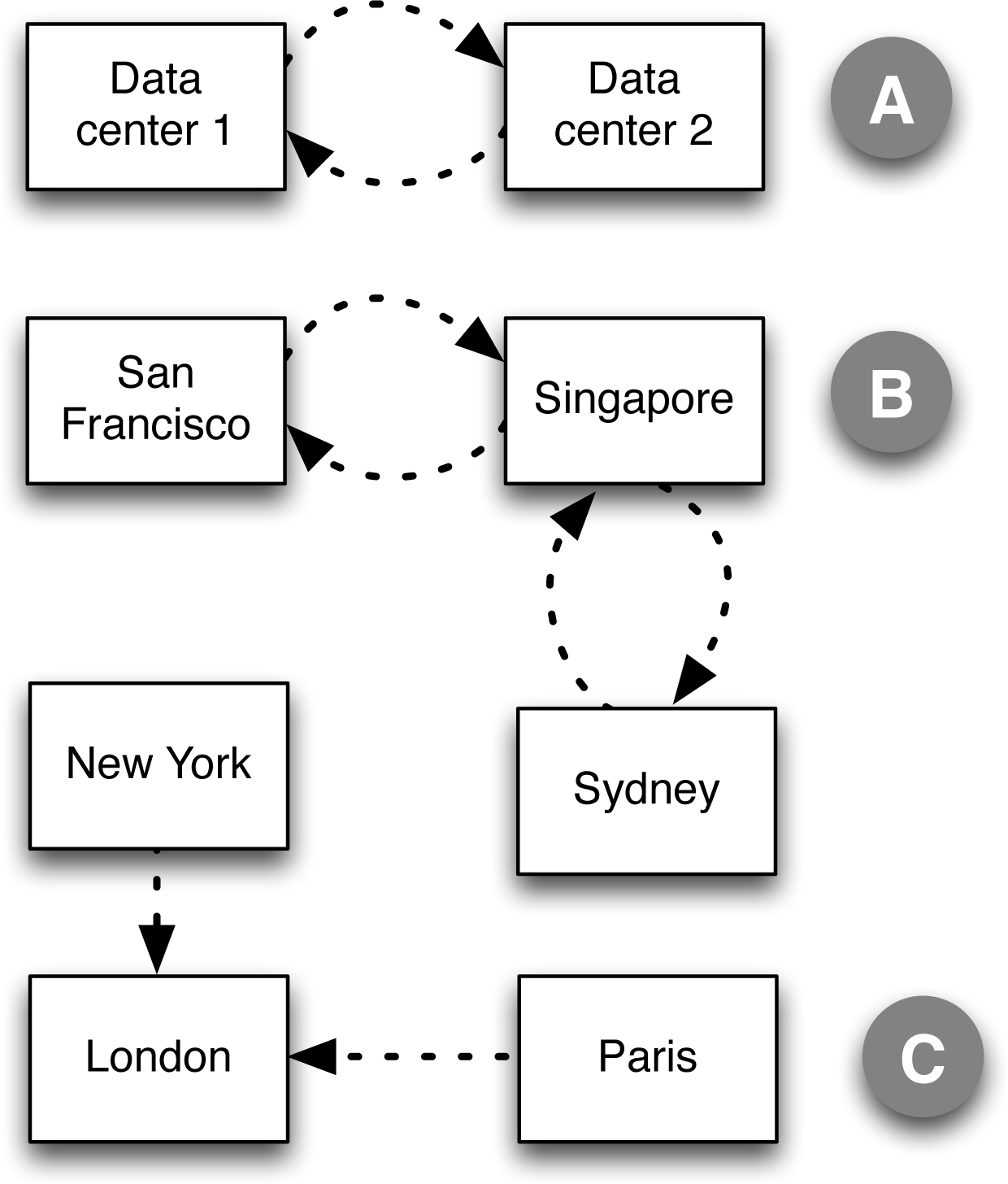
Figure 5-2. Replication of streams between clusters can have loops with MapR Streams. This is not possible using MirrorMaker with Kafka.
MapR Streams Gotchas
There are a number of issues that may affect whether or not MapR Streams is a good choice for streaming architectures in your projects. For one thing, it is relatively new, with a first GA release early in 2016. This youth isn’t quite as serious at it looks, because the underlying technology has been battle-tested since 2010, but it is definitely a consideration, at least in the near term. Since Kafka’s API for version 0.9 is also new but built on solid foundations, both systems share the situation of being both young and mature at the same time.
Another issue is that MapR Streams only supports the new Kafka API that was introduced in the Kafka 0.9 release. Applications based on Kafka 0.8 or earlier APIs will not be directly compatible. The conversion is very simple, but it must be done in order to use MapR Streams, so this requires some additional effort. The same effort is required for Kafka users who choose to take advantage of the improvements in Kafka’s 0.9 release—they would still have to do some rewriting (modifications) to run their older Kafka applications on the new API.
One interesting difference between the two systems is that with Kafka, administrators must take on a much more active role, and in some cases must explicitly position topic partitions in the cluster. In MapR clusters, users have far less control over exactly where different topic partitions are stored and accessed. A stream can be limited to a part of a larger cluster using volume topology, but there is no equivalent of the manual positioning of data that is available in Kafka. Whether this is a virtue or a vice with MapR Streams depends very much on your application and whether low-level administration is a good or bad thing in your environment.
To use the geo-replication features of MapR Streams, you should pay attention to several factors. The first is that, while entire streams can make use of multi-master replication, individual topics in a replicated stream should only have messages inserted in a single replica. If all replicas are up to date, you can change which replica gets the messages first, but you should not insert messages into replicas in the same topic in many locations simultaneously. Typically, the way that this is handled is to either have a topic per location that is used specifically to ingest data from that location, or to change the insert point for each topic relatively slowly with respect to the replication rate.