
Chapter 5 - TPump
“I think Google should be like a Swiss Army Knife: clean, simple, the tool you want to take everywhere.”
Do you remember the first Swiss ArmyTM knife you ever owned? Aside from its original intent as a compact survival tool, this knife has thrilled generations with its multiple capabilities. TPump is the Swiss ArmyTM knife of the Teradata load utilities. Just as this knife was designed for small tasks, TPump was developed to handle batch loads with low volumes. And, just as the Swiss ArmyTM knife easily fits in your pocket when you are loaded down with gear, TPump is a perfect fit when you have a large, busy system with few resources to spare. Let’s look in more detail at the many facets of this amazing load tool.
TPump is the shortened name for the load utility Teradata Parallel Data Pump. To understand this, you must know how the load utilities move the data. Both FastLoad and MultiLoad assemble massive volumes of data rows into 64K blocks and then moves those blocks. Picture in your mind the way that huge ice blocks used to be floated down long rivers to large cities prior to the advent of refrigeration. There they were cut up and distributed to the people. TPump does NOT move data in the large blocks. Instead, it loads data one row at a time, using row hash locks. Because it locks at this level, and not at the table level like MultiLoad, TPump can make many simultaneous, or concurrent, updates on a table.
Envision TPump as the water pump on a well; pumping in a very slow, gentle manner resulting in a steady trickle of water that could be pumped into a cup. But strong and steady pumping results in a powerful stream of water that would require a larger container. TPump is a data pump which, like the water pump, may allow either a trickle-feed of data to flow into the warehouse or a strong and steady stream. In essence, you may “throttle” the flow of data based upon your system and business user requirements.

Limitations of TPump
“To keep the heart unwrinkled,, to be hopeful, kindly, cheerful, and reverent – that is to triumph over old age.”
TPump has rightfully earned its place as a superstar in the family of Teradata load utilities. But this does not mean that it has no limits. It has a few that we will list here for you:
Rule #1: No concatenation of input data files is allowed. TPump is not designed to support this.
Rule #2: TPump will not process aggregates, arithmetic functions or exponentiation. If you need data conversions or math, you might consider using an INMOD to prepare the data prior to loading it.
Rule #3: The use of the SELECT function is not allowed. You may not use SELECT in your SQL statements.
Rule #4: No more than four IMPORT commands may be used in a single load task. This means that at most, four files can be directly read in a single run.
Rule #5: Dates before 1900 or after 1999 must be represented by the yyyy format for the year portion of the date, not the default format of yy. This must be specified when you create the table. Any dates using the default yy format for the year are taken to mean 20th century years.
Rule #6: On some network attached systems, the maximum file size when using TPump is 2GB. This is true for a computer running under a 32-bit operating system.
Rule #7: TPump performance will be diminished if Access Logging is used. TPump uses normal SQL to accomplish its tasks.

A Sample TPump Script
“Computer Science is no more about computers than astronomy is about telescopes.”
The script on the following page follows these steps:
- Setting up a Logtable
- Logging onto Teradata
- Identifying the Target, Work and Error tables
- Defining the INPUT flat file
- Defining the DML activities to occur
- Naming the IMPORT file
- Telling TPump to use a particular LAYOUT
- Telling the system to start loading
- Finishing and log off of Teradata

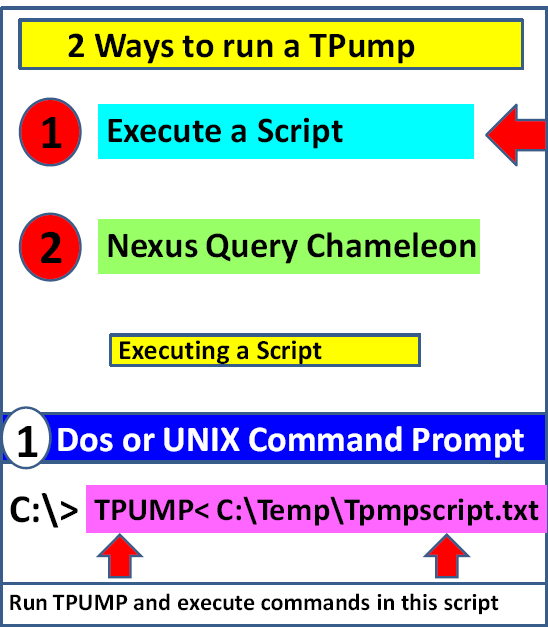
Two Easy Ways to Run a TPump
“It is well, when judging a friend, to remember that he is judging you with the same godlike and superior impartiality.”
The following page shows two easy ways to run your TPump job. You can execute a script or use the Nexus Query Chameleon to build and execute the script.
To run a script from DOS prompt or COMMAND prompt you type the keyword TPUMP and then use the less than sign < to tell TPUMP to take all of its commands from the script.
The TPUMP script being executed is called TPmpscript.txt and is saved in the C:Temp directory.
Building, Executing or Scheduling TPump with Nexus
“A friend is one who knows us, but loves us anyway.”
The Nexus Query Chameleon will help you build your script by 90%. You just have to fill in a few parameters. The Nexus will then allow you to execute your TPump script or you can schedule it to run at any time.

Building a TPump with Nexus SmartScript
“There are three great friends: an old wife, an old dog, and ready money.”
Right Click on any table in the Nexus System Tree and then go to SmartScript and from there click on TPump. Be prepared to be amazed.
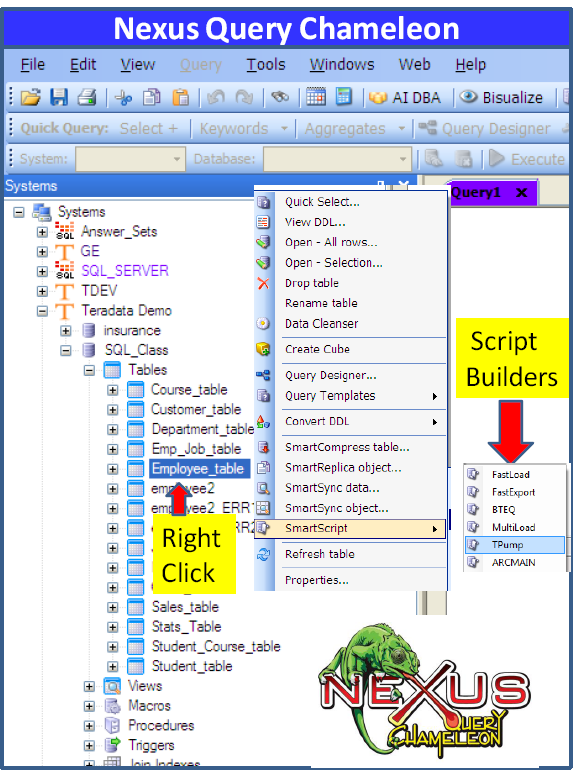
The SmartScript TPump Builder
“Good communication is as stimulating as black coffee and just as hard to sleep after.”
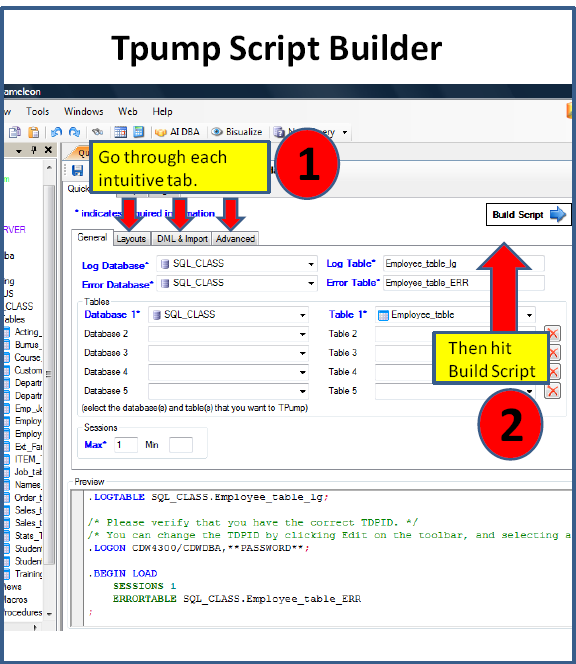
The TPump Script Builder will have already built much of your script for you. Notice on the following page the red arrows that show the different tabs. You merely move through each tab and fill in the TPump parameters. Most of the parameters are already set for you with the defaults. You can change the parameters.
When you are ready hit Build Script where you can see the entire script and still make changes to the script.
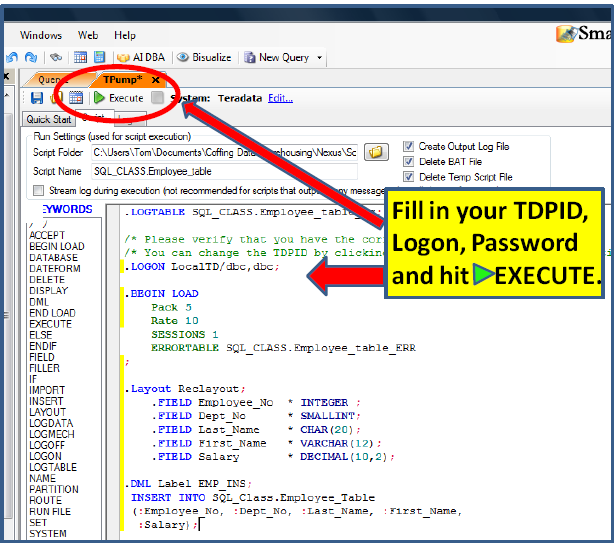
Executing your TPump Script
“The real test of friendship is: Can you literally do nothing with the other person? Can you enjoy together those moments of life that are utterly simple? They are the moments people look back on at the end of life and number as their most sacred experiences.”
All you have to do is fill in your login information and hit EXECUTE.
Supported Input Formats
TPump, like MultiLoad, supports the following five format options: BINARY, FASTLOAD, TEXT, UNFORMAT and VARTEXT. But TPump is quite finicky when it comes to data format errors. Such errors will generally cause TPump to terminate. You have got to be careful! In fact, you may specify an Error Limit to keep TPump from terminating prematurely when faced with a data format error. You can specify a number (n) of errors that are to be tolerated before TPump will halt. Here is a data format chart for your reference:
| BINARY | Each record is a 2-byte integer, n, that is followed by n bytes of data. A byte is the smallest address space you can have in Teradata. |
| FASTLOAD | This format is the same as Binary, plus a marker (X ‘0A’ or X ‘0D’) that specifies the end of the record. |
| TEXT | Each record has a variable number of bytes and is followed by an end of the record marker. |
| UNFORMAT | The format for these input records is defined in the LAYOUT statement of the MultiLoad script using the components FIELD, FILLER and TABLE. |
| VARTEXT | This is variable length text RECORD format separated by delimiters such as a comma. For this format you may only use VARCHAR, LONG VARCHAR (IBM) or VARBYTE data formats in your MultiLoad LAYOUT. Note that two delimiter characters in a row denote a null value between them. |

TPump Script with Error Treatment Options
/* !/bin/ksh* */ |
Load with a Shell Script |
/* ++++++++++++++++++++++++++++++++++ */ /* TPUMP SCRIPT - CDW */ /*This script loads SQL01 .Student_Profile4 */ /* Version 1.1 */ /* Created by Coffing Data Warehousing */ /* +++++++++++++++++++++++++++++++++++++ */ |
Names and describes the purpose of the script; names the author. |
/* Setup the TPUMP Logtables, Logon Statements and Database Default */ .LOGTABLE SQL01 .LOG_PUMP; .LOGON CDW/SQL01 ,SQL01; DATABASE SQL01; |
Sets up a Logtable and then logs on to Teradata. Specifies the database containing the table. |
/* Begin Load and Define TPUMP Parameters and Error
Tables */
.BEGIN LOAD
ERRLIMIT 5
CHECKPOINT 1
SESSIONS 1
TENACITY 2
PACK 40
RATE 1000
ERRORTABLE SQL01.ERR_PUMP; |
BEGINS THE LOAD PROCESS SPECIFIES NAMES THE Single ERROR TABLE; TABLE. |
.LAYOUT FILELAYOUT;
.FIELD Student ID * VARCHAR (11);
.FIELD Last Name * VARCHAR (20);
.FIELD First Name * VARCHAR (14);
.FIELD Class_Code * VARCHAR (2);
.FIELD Grade Pt * VARCHAR (8);
|
Names the LAYOUT of the INPUT file. Defines the structure of the INPUT file; |
.DML LABEL INSREC
IGNORE DUPLICATE ROWS
IGNORE MISSING ROWS
IGNORE EXTRA ROWS;
INSERT INTO Student_Profile4
( Student_ID
,Last_Name
,First_Name
,Class_Code
,Grade Pt )
VALUES
( :Student_ID
,:Last_Name
,:First_Name
,:Class_Code
,:Grade_Pt );
|
Names the DML Label; SPECIFIES 3 ERROR TREATMENT OPTIONS with the ; after the last option.
Tells TPump to INSERT a row into the target table and defines the row format. |
.IMPORT INFILE Cdw_import.txt
FORMAT VARTEXT “,”
LAYOUT FILELAYOUT
APPLY INSREC;
|
Names the IMPORT file; Names the LAYOUT to be called from above; Tells TPump which DML Label to APPLY. Notice the FORMAT with a comma in the quotes to define the delimiter between fields in the input record. |
.END LOAD; .LOGOFF; |
Tells TPump to stop loading and Logs Off all sessions. |
A TPump Script that Uses Two Input Data Files
/* !/bin/ksh* */ |
Load Runs from a Shell Script |
/* ++++++++++++++++++++++++++++++++++ */ /* TPUM+P SCRIPT using 2 Input Files -CDW */ /* It loads STUDT_CONTACT Target Table - CDW */ /*This script loads SQL01. Student_Profile3 */ /* Version 1.1 */ /* Created by Coffing Data Warehousing */ /* ++++++++++++++++++++++++++++++++++++++++ */ |
Nam es an d de sc ribes the purpose of the script; names the author. |
.LOGTABLE SQL01.LOG_TPMP; .LOGON CDW/SQL01 ,SQL01; DATABASE SQL01; |
Sets Up a Logtable and then logs on to Teradata. Specifies the database to work in (optional). |
.BEGIN LOAD
ERRLIMIT 5
CHECKPOINT 1
SESSIONS 1
TENACITY 2
PACK 40
RATE 1000
ERRORTABLE WORK_DB.ERR_TPMP;
|
Begins the load process Specifies multiple parameters to aid in load management Names the error table; TPump HAS ONLY ONE ERROR TABLE PER TARGET TABLE |
.LAYOUT RECLAYOUT1 INDICATORS;
.FIELD Student ID * INTEGER;
.FIELD Last Name * CHAR(20);
.FIELD First Name * VARCHAR(14);
.FIELD Class_Code * CHAR(2);
.FIELD Grade_Pt * DECIMAL(8,2);
|
Defines the LAYOUT for the 1st INPUT file also has the indicators for NULL data. |
.LAYOUT RECLAYOUT2;
.FILLER Rec Type * CHAR(1);
.FIELD Last Name * CHAR(20);
.FIELD First Name * VARCHAR(14);
.FIELD Student_ID * INTEGER;
.FIELD Class_Code * CHAR(2);
.FIELD Grade_Pt * DECIMAL(8,2);
|
Defines the LAYOUT for the 2nd INPUT file with a different arrangement of fields |
.DML LABEL INSREC1
IGNORE DUPLICATE ROWS
IGNORE EXTRA ROWS;
|
Names the 1st DML Label and specifies 2 Error Treatment options. |
INSERT INTO Student Profile OLD
( Student_ID
,Last_Name
,First_Name
,Class_Code
,Grade Pt )
VALUES
( :Student_ID
,:Last_Name
,:First_Name
,:Class_Code
,:Grade_Pt );
|
Tells TPump to INSERT a row into the target table and defines the row format.
Lists, in order, the VALUES to be INSERTED. A colon always precedes values. |
.DML LABEL INSREC2
IGNORE DUPLICATE ROWS;
INSERT INTO Student_Profile_NEW
( Student_ID
,Last_Name
,First_Name
,Class_Code
,Grade Pt )
VALUES
( :Student_ID
,:Last_Name
,:First_Name
,:Class_Code
,:Grade_Pt );
|
Names the 2nd DML Label and specifies 1 Error Treatment options. Tells TPump to INSERT a row into the target table and defines the row format.
Lists, in order, the VALUES to be INSERTED. A colon always precedes values. |
.IMPORT INFILE FILE-REC1.DAT FORMAT FASTLOAD LAYOUT REC_LAYOUT1 APPLY INSREC1 ; .IMPORT INFILE FILE-REC2.DAT FORMAT TEXT LAYOUT REC_LAYOUT2 APPLY INSREC2 ; |
Names the TWO Import Files as FILE-REC1.DAT and FILE-REC2.DAT. The file name is under Windows so the “-” is fine. Names the TWO Layouts that define the structure of the INPUT DATA files; Names the TWO INPUT data files |
.END LOAD; .LOGOFF; |
Tells TPump to stop loading and logs off all sessions. |
A TPump UPSERT Sample Script
.LOGTABLE SQL01.CDW_LOG; .LOGON CDW/SQL01,SQL01; |
Sets Up a Logtable and then logs on to Teradata. |
.BEGIN LOAD
ERRLIMIT 5
CHECKPOINT 10
SESSIONS 10
TENACITY 2
PACK 10
RATE 10
ERRORTABLE SQL01.SWA_ET;
|
Begins the load process Specifies multiple parameters to aid in load management
Names the error table; TPump HAS ONLY ONE ERROR TABLE PER TARGET TABLE |
.LAYOUT INREC INDICATORS;
.FIELD StudentID * INTEGER;
.FIELD Last_Name * CHAR(20);
.FIELD First_Name * VARCHAR(14);
.FIELD Class_Code * CHAR(2);
.FIELD Grade_Pt * DECIMAL(8,2);
|
Defines the LAYOUT for the 1st INPUT file; also has the indicators for NULL data. |
.DML LABEL UPSERTER
DO INSERT FOR MISSING UPDATE ROWS;
UPDATE Student_Profile
SET Last_Name = :Last_Name
,First_Name = :First_Name
,Class_Code = :Class_Code
,Grade_Pt = :Grade_Pt
WHERE Student_ID = :StudentID ;
INSERT INTO Student_Profile
VALUES ( :StudentID
,:Last_Name
,:First_Name
,:Class_Code
,:Grade_Pt );
|
Names the 1st DML Label and specifies 2 Error Treatment options.
Tells TPump to INSERT a row into the target table and defines the row format. Lists, in order, the VALUES to be INSERTED. A colon always precedes values. |
.IMPORT INFILE UPSERT-FILE.DAT FORMAT FASTLOAD LAYOUT INREC APPLY UPSERTER ; |
Names the Import File as UPSERT-FILE.DAT. The file name is under Windows so the “-” is fine.
The file type is FASTLOAD. |
.END LOAD; .LOGOFF; |
Tells TPump to stop loading and logs off all sessions. |
Fundamentals of the .BEGIN Statement
“Guests, like fish, begin to smell after three days.”
Use the .BEGIN chart on the following page and your TPUMP will begin to smell like roses as you will be the company guest of honor.
The following page shows the BEGIN statement parameters. The following pages will give you a much more detailed explanation.

PACK
“History is a pack of lies about events that never happened told by people who weren’t there.”
George doesn’t know anything about the history of the pack in TPump. It is a pack of records that have happened who will soon be there once they’re loaded. Pack in Teradata means the number of statements to pack into a multiple-statement request which improves the network/channel efficiency by reducing the number of sends/receives between apps and Teradata.
The pack and the rate are an important part of TPump. There is no exact science here first of all. To get the best pack and rate for a particular job can be a trial and error situation.
The concept of the pack and the rate is this. You pack a certain amount of records from your flat file into a pack, where the maximum pack is 64K. Then you set a rate per minute of delivery.
You might however find that going from a pack rate of 1 to 2 gives you enormous improvement in speed and going from 2 to 4 gives you even better improvements, but then going from 4-8 gives you a little bit better performance and then going from 8-16 you begin to see worse performance. The key with jobs that you run on a regular basis is to use some trial and error with the Pack and Rate.
Teradata enforces in TPump jobs the column limit of 2550. Just to give you a more technical idea of how it works you might have a USING clause that had 128 columns in it. You could divide 2550 by 128 to get the maximum pack rate, but this would probably blow up because there are some other things (like plastic steps) that would take you over the limit. This would also not necessarily be the best throughput.
If you don’t specify a rate it will default to unlimited!

RATE
“All of us failed to match our dreams of perfection. So I rate us on the basis of our splendid failure to do the impossible.”
Faulkner doesn’t know anything about our dreams because we can achieve splendid success if we take our TPUMP job and match the RATE and PACK to perfection.
RATE is the initial maximum rate at which statements are sent per minute. If the rate is zero or unspecified, the rate is considered unlimited.
Here is an example:
RATE: 10000
PACK: 10
10000 divided by 10 = 1000 packets/minute or 16 packets/second
You can also use a PACKMAXIMUM which will use a trial and error to establish the best PACK rate, but don’t do this in production because it performs a series of tests to determine the best pack and rate.

SERIALIZE
“I think serial monogamy says it all.”
Tracy really knows her TPump because SERIALIZE mONogomy says it all. You can either have SERIALIZE ON or SERIALIZE OFF in your TPUMP job.
SERIALIZE ON will alert TPump to partition the flat file records that touch the same Teradata row to be handled by the same session.
SERIALIZE OFF will alert TPump to process transactions in the order they are received in any of the sessions, thus not to guarantee the order in which transactions are processed. Think of SERIALIZE OFF as statements being executed on the first session available so operations may occur out of order.
You would only want SERIALIZE ON if the order of the updates applied are very important. SERIALIZE ON can also eliminate lock delays or potential deadlocks caused by primary index collisions because ON means that all rows with the same Primary Index will be handled by the same session and most likely the same memory buffer.
If SERIALIZE is specified without being followed by the words ON or OFF, the default is ON. If SERIALIZE is not specified at all, the default is OFF (unless the job contains an UPSERT operation which causes the default to be ON).
SERIALIZE ON is only important when a Primary Index for the table is specified, but remember you must use the KEY option in the .LAYOUT example below.
Example: .FIELD Customer_Number * INTEGER KEY ;

TPump Commands and Parameters
Each command in TPump must begin on a new line, preceded by a dot. It may utilize several lines, but must always end in a semi-colon. Like MultiLoad, TPump makes use of several optional parameters in the .BEGIN LOAD command. Some are the same ones used by MultiLoad. However, TPump has other parameters. Let’s look at each group.
The group on the next page are also the same in MultiLoad.
| PARAMETER | WHAT IT DOES |
| ERRLIMIT errcount [errpercent] | You may specify the maximum number of errors, or the percentage, that you will tolerate during the processing of a load job. The key point here is that you should set the ERRLIMIT to a number greater than the PACK number. The reason for this is that sometimes, if the PACK factor is a smaller number than the ERRLIMIT, the job will terminate, telling you that you have gone over the ERRLIMIT. When this happens, there will be no entries in the error tables. |
| CHECKPOINT (n) | In TPump, the CHECKPOINT refers to the number of minutes, or frequency, at which you wish a checkpoint to occur. This is unlike Mulitload which allows either minutes or the number of rows. |
| SESSIONS (n) | This refers to the number of SESSIONS that should be established with Teradata. TPump places no limit on the number of SESSIONS you may have. For TPump, the optimal number of sessions is dependent on your needs and your host computer (like a laptop). |
| TENACITY | Tells TPump how many hours to try logging on when less than the requested number of sessions is available. |
| SLEEP | Tells TPump how frequently, in minutes, to try establishing additional sessions on the system. |
.BEGIN LOAD Parameters UNIQUE to TPump
Each command in TPump must begin on a new line, preceded by a dot. It may utilize several lines, but must always end in a semi-colon. Like MultiLoad, TPump makes use of several optional parameters in the .BEGIN LOAD command. Some are the same ones used by MultiLoad. However, TPump has other parameters. Let’s look at each group.
The group below and on the next page are unique to TPump and are not used in MultiLoad.
| MACRODB <databasename> | This parameter identifies a database that will contain any macros utilized by TPump. Remember, TPump does not run the SQL statements by itself. It places them into Macros and executes those Macros for efficiency. |
| NOMONITOR | Use this parameter when you wish to keep TPump from checking either statement rates or update status information for the TPump Monitor application. |
| PACK (n) | Use this to state the number of statements TPump will “pack” into a multiple-statement request. Multi-statement requests improve efficiency in either a network or channel environment because it uses fewer sends and receives between the application and Teradata. |
| RATE | This refers to the Statement Rate. It shows the initial maximum number of statements that will be sent per minute. A zero or no number at all means that the rate is unlimited. If the Statement Rate specified is less than the PACK number, then TPump will send requests that are smaller than the PACK number. |
| ROBUST ON/OFF | ROBUST defines how TPump will conduct a RESTART. ROBUST ON means that one row is written to the Logtable for every SQL transaction. The downside of running TPump in ROBUST mode is that it incurs additional, and possibly unneeded, overhead. ON is the default. If you specify ROBUST OFF, you are telling TPump to utilize “simple” RESTART logic: Just start from the last successful CHECKPOINT. Be aware that if some statements are reprocessed, such as those processed after the last CHECKPOINT, then you may end up with extra rows in your error tables. Why? Because some of the statements in the original run may have found errors, in which case they would have recorded those errors in an error table. |
| SERIALIZE OFF/ON | You only use the SERIALIZE parameter when you are going to specify a PRIMARY KEY in the .FIELD command. For example, “.FIELD Salaryrate * DECIMAL KEY.” If you specify SERIALIZE TPump will ensure that all operations on a row will occur serially. If you code “SERIALIZE”, but do not specify ON or OFF, the default is ON. Otherwise, the default is OFF unless doing an UPSERT. |
Monitoring TPump
TPump comes with a monitoring tool called the TPump Monitor. This tool allows you to check the status of TPump jobs as they run and to change (remember “throttle up” and “throttle down?”) the statement rate on the fly. Key to this monitor is the “SysAdmin.TpumpStatusTbl” table in the Data Dictionary Directory. If your Database Administrator creates this table, TPump will update it on a minute-by-minute basis when it is running. You may update the table to change the statement rate for an IMPORT. If you want TPump to run unmonitored, then the table is not needed.
You can start a monitor program under UNIX with the following command:
tpumpmon [-h] [TDPID/] <UserName>,<Password> [,<AccountID>]
Below is a chart that shows the Views and Macros used to access the “SysAdmin.TpumpStatusTbl” table. Queries may be written against the Views. The macros may be executed.
| Views and Macros to access the table SysAdmin.TpumpStatusTbl | |
| View | SysAdmin.TPumpStatus |
| View | SysAdmin.TPumpStatusX |
| Macro | Sysadmin.TPumpUpdateSelect |
| Macro | TPumpMacro.UserUpdateSelect |

Handling Errors in TPump Using the Error Table
One Error Table
Unlike FastLoad and MultiLoad, TPump uses only ONE Error Table per target table, not two. If you name the table, TPump will create it automatically. Entries are made to these tables whenever errors occur during the load process. Like MultiLoad, TPump offers the option to either MARK errors (include them in the error table) or IGNORE errors (pay no attention to them whatsoever). These options are listed in the .DML LABEL sections of the script and apply ONLY to the DML functions in that LABEL. The general default is to MARK. If you specify nothing, TPump will assume the default. When doing an UPSERT, this default does not apply.
The error table does the following:
- Identifies errors
- Provides some detail about the errors
- Stores a portion the actual offending row for debugging
When compared to the error tables in MultiLoad, the TPump error table is most similar to the MultiLoad Acquisition error table. Like that table, it stores information about errors
that take place while it is trying to acquire data. It is the errors that occur when the data is being moved, such as data translation problems that TPump will want to report on. It will also want to report any difficulties compiling valid Primary Indexes. Remember, TPump has less tolerance for errors than FastLoad or MultiLoad.
| COLUMNS IN THE TPUMP ERROR TABLE | |
| ImportSeq | Sequence number that identifies the IMPORT command where the error occurred |
| DMLSeq | Sequence number for the DML statement involved with the error. |
| SMTSeq | Sequence number of the DML statement being carried out when the error was discovered |
| ApplySeq | Sequence number that tells which APPLY clause was running when the error occurred |
| SourceSeq | The number of the data row in the client file that was being built when the error took place |
| DataSeq | Identifies the INPUT data source where the error row came from |
| ErrorCode | System code that identifies the error |
| ErrorMsg | Generic description of the error |
| ErrorField | Number of the column in the target table where the error happened; is left blank if the offending column cannot be identified; This is different from MultiLoad, which supplies the column name. |
| HostData | The data row that contains the error, limited to the first 63,728 bytes related to the error |
Common Error Codes and What They Mean
TPump users often encounter three error codes that pertain to Missing data rows, Duplicate data rows and Extra data rows
#1: Error 2816: Failed to insert duplicate row into TPump Target Table. Nothing is wrong when you see this error. In fact, it can be a very good thing. It means that TPump is notifying you that it discovered a DUPLICATE row. This error jumps to life when one of the following options has been stipulated in the .DML LABEL:
- MARK DUPLICATE INSERT ROWS
- MARK DUPLICATE UPDATE ROWS
The original row is inserted into the target table. the duplicate row is not.
#2: Error 2817: Activity count greater than ONE for TPump UPDATE/DELETE.
Sometimes you want to know if there were too may “successes.” This is the case when there are EXTRA rows when on an UPDATE or DELETE.
TPump will log an error whenever it sees an activity count greater than zero for any such extra rows if you have specified either of these options in a .DML LABEL:
- MARK EXTRA UPDATE ROWS
- MARK EXTRA DELETE ROW
At the same time, the associated UPDATE or DELETE will be performed.
#3: Error 2818: Activity count zero for TPump UPDATE or DELETE.
Sometimes, you want to know if a data row that was supposed to be updated or deleted wasn’t! That is when you want to know that the activity count was zero, indicating that the UPDATE or DELETE did not occur. To see this error, you must have used one of the following parameters:
- MARK MISSING UPDATE ROWS
- MARK MISSING DELETE ROWS
RESTARTING TPump
Like the other utilities, a TPump script is fully restartable as long as the log table and error tables are not dropped. As mentioned earlier you have a choice of setting ROBUST either ON (default) or OFF. There is more overhead using ROBUST ON, but it does provide a higher degree of data integrity, but lower performance.
TPump is restartable through the support environment.
TPump and MultiLoad Comparison Chart
| Function | MultiLoad | TPump |
| Error Tables must be defined | Optional, 2 per target table | Optional, 1 per target table |
| Work Tables must be defined | Optional, 1 per target table | No |
| Logtable must be defined | Yes | Yes |
| Allows Referential Integrity | No | Yes |
| Allows Unique Secondary Indexes | No | Yes |
| Allows Non-Unique Secondary Indexes | Yes | Yes |
| Allows Triggers | No | Yes |
| Loads a maximum of n number of tables | Five | 60 |
| Maximum Concurrent Load Instances | 15 | Unlimited |
| Locks at this level | Table | Row Hash |
| DML Statements Supported | INSERT, UPDATE, DELETE, “UPSERT” | INSERT, UPDATE, DELETE, “UPSERT” |
| How DML Statements are Performed | Runs actual DML commands | Compiles DML into MACROS and executes |
| DDL Statements Supported | All | All |
| Transfers data in 64K blocks | Yes | No, moves data at row level |
| RESTARTable | Yes | Yes |
| Stores UPI Violation Rows | Yes, with MARK option | Yes, with MARK option |
| Allows use of Aggregated, Arithmetic calculations or Conditional Exponentiation | No | No |
| Allows Data Conversion | Yes | Yes |
| Performance Improvement | As data volumes increase | By using multi-statement requests |
| Table Access During Load | Uses WRITE lock on tables in Application Phase | Allows simultaneous READ and WRITE access due to Row Hash Locking |
| Effects of Stopping the Load | Consequences | No repercussions |
| Resource Consumption | Hogs available resources | Allows consumption management via Parameters |
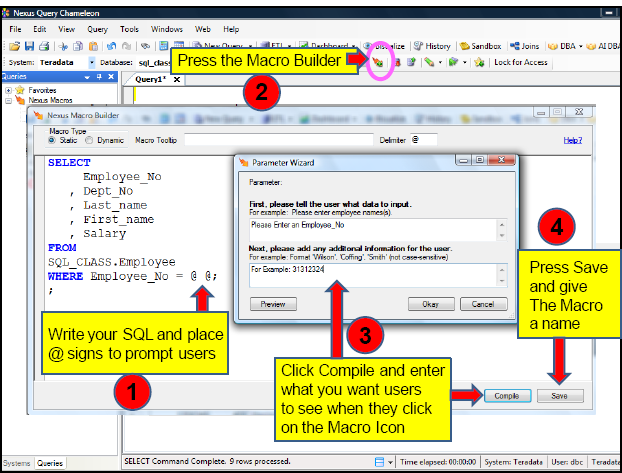
Nexus Query Chameleon - Create Point-and-Click Icons that Prompt Users for Input
Too often the data warehouse is so complex that many of the companies users don’t have the SQL training or expertise to access the warehouse. This is where the Nexus Macro Builder comes in. The Nexus allows you to write SQL that will prompt the user for input, but hide the SQL inside an icon. Users can click on the Macro Icon and they are then instructed on what to do. This allows all employees to take advantage of the information in the data warehouse.
Below is an example on how easy it is to create a Macro Icon that any user will be able to execute and receive the information they need. The following page will show how a user will execute the Macro Icon.
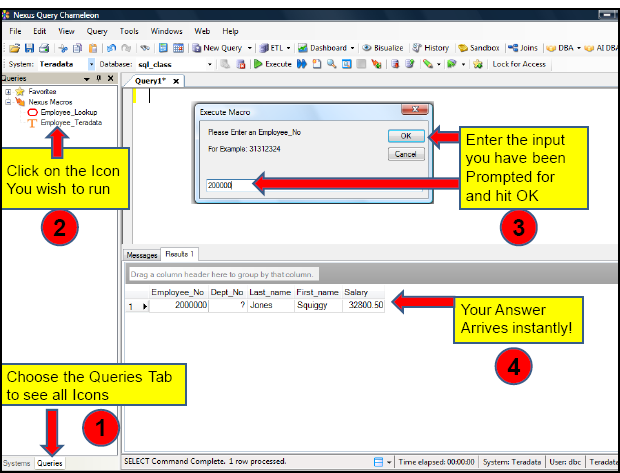
Nexus - How easy it is for Users to execute a Macro Icon
Any user can now access the data warehouse by clicking on the icon. Then they enter the information they are prompted for inside the Macro Icon. They hit OK and the query runs bringing back their Answer Set. We have done a lot of customized work so companies can allow their data warehouse to reach further into the user community. The Macro Icons are the simplest way to allow all users to access the data warehouse with ease, and still allow the DBA’s to maintain a controlled environment where there are no bad performing queries.
Download a FREE Trial of the Nexus Query Chameleon at:
www.CoffingDW.com
See the Nexus Query Chameleon User Guide at:
http://www.coffingdw.com/data/Nexus_Product_Info.pdf