
Chapter 2
The Psychology and Economics of Software Testing
Software testing is a technical task, yes, but it also involves some important considerations of economics and human psychology.
In an ideal world, we would want to test every possible permutation of a program. In most cases, however, this simply is not possible. Even a seemingly simple program can have hundreds or thousands of possible input and output combinations. Creating test cases for all of these possibilities is impractical. Complete testing of a complex application would take too long and require too many human resources to be economically feasible.
In addition, the software tester needs the proper attitude (perhaps “vision” is a better word) to successfully test a software application. In some cases, the tester's attitude may be more important than the actual process itself. Therefore, we will start our discussion of software testing with these issues before we delve into the more technical nature of the topic.
One of the primary causes of poor application testing is the fact that most programmers begin with a false definition of the term. They might say:
“Testing is the process of demonstrating that errors are not present.”
“The purpose of testing is to show that a program performs its intended functions correctly.”
“Testing is the process of establishing confidence that a program does what it is supposed to do.”
These definitions are upside down.
When you test a program, you want to add some value to it. Adding value through testing means raising the quality or reliability of the program. Raising the reliability of the program means finding and removing errors.
Therefore, don't test a program to show that it works; rather, start with the assumption that the program contains errors (a valid assumption for almost any program) and then test the program to find as many of the errors as possible.
Thus, a more appropriate definition is this:
Testing is the process of executing a program with the intent of finding errors.
Although this may sound like a game of subtle semantics, it's really an important distinction. Understanding the true definition of software testing can make a profound difference in the success of your efforts.
Human beings tend to be highly goal-oriented, and establishing the proper goal has an important psychological effect on them. If our goal is to demonstrate that a program has no errors, then we will be steered subconsciously toward this goal; that is, we tend to select test data that have a low probability of causing the program to fail. On the other hand, if our goal is to demonstrate that a program has errors, our test data will have a higher probability of finding errors. The latter approach will add more value to the program than the former.
This definition of testing has myriad implications, many of which are scattered throughout this book. For instance, it implies that testing is a destructive, even sadistic, process, which explains why most people find it difficult. That may go against our grain; with good fortune, most of us have a constructive, rather than a destructive, outlook on life. Most people are inclined toward making objects rather than ripping them apart. The definition also has implications for how test cases (test data) should be designed, and who should and who should not test a given program.
Another way of reinforcing the proper definition of testing is to analyze the use of the words “successful” and “unsuccessful”—in particular, their use by project managers in categorizing the results of test cases. Most project managers refer to a test case that did not find an error a “successful test run,” whereas a test that discovers a new error is usually called “unsuccessful.”
Once again, this is upside down. “Unsuccessful” denotes something undesirable or disappointing. To our way of thinking, a well-constructed and executed software test is successful when it finds errors that can be fixed. That same test is also successful when it eventually establishes that there are no more errors to be found. The only unsuccessful test is one that does not properly examine the software; and, in the majority of cases, a test that found no errors likely would be considered unsuccessful, since the concept of a program without errors is basically unrealistic.
A test case that finds a new error can hardly be considered unsuccessful; rather, it has proven to be a valuable investment. An unsuccessful test case is one that causes a program to produce the correct result without finding any errors.
Consider the analogy of a person visiting a doctor because of an overall feeling of malaise. If the doctor runs some laboratory tests that do not locate the problem, we do not call the laboratory tests “successful”; they were unsuccessful tests in that the patient's net worth has been reduced by the expensive laboratory fees, the patient is still ill, and the patient may question the doctor's ability as a diagnostician. However, if a laboratory test determines that the patient has a peptic ulcer, the test is successful because the doctor can now begin the appropriate treatment. Hence, the medical profession seems to use these words in the proper sense. The analogy, of course, is that we should think of the program, as we begin testing it, as the sick patient.
A second problem with such definitions as “testing is the process of demonstrating that errors are not present” is that such a goal is impossible to achieve for virtually all programs, even trivial programs.
Again, psychological studies tell us that people perform poorly when they set out on a task that they know to be infeasible or impossible. For instance, if you were instructed to solve the crossword puzzle in the Sunday New York Times in 15 minutes, you probably would achieve little, if any, progress after 10 minutes because, if you are like most people, you would be resigned to the fact that the task seems impossible. If you were asked for a solution in four hours, however, we could reasonably expect to see more progress in the initial 10 minutes. Defining program testing as the process of uncovering errors in a program makes it a feasible task, thus overcoming this psychological problem.
A third problem with the common definitions such as “testing is the process of demonstrating that a program does what it is supposed to do” is that programs that do what they are supposed to do still can contain errors. That is, an error is clearly present if a program does not do what it is supposed to do; but errors are also present if a program does what it is not supposed to do. Consider the triangle program of Chapter 1. Even if we could demonstrate that the program correctly distinguishes among all scalene, isosceles, and equilateral triangles, the program still would be in error if it does something it is not supposed to do (such as representing 1, 2, 3 as a scalene triangle or saying that 0, 0, 0 represents an equilateral triangle). We are more likely to discover the latter class of errors if we view program testing as the process of finding errors than if we view it as the process of showing that a program does what it is supposed to do.
To summarize, program testing is more properly viewed as the destructive process of trying to find the errors in a program (whose presence is assumed). A successful test case is one that furthers progress in this direction by causing the program to fail. Of course, you eventually want to use program testing to establish some degree of confidence that a program does what it is supposed to do and does not do what it is not supposed to do, but this purpose is best achieved by a diligent exploration for errors.
Consider someone approaching you with the claim that “my program is perfect” (i.e., error free). The best way to establish some confidence in this claim is to try to refute it, that is, to try to find imperfections rather than just confirm that the program works correctly for some set of input data.
Given our definition of program testing, an appropriate next step is to determine whether it is possible to test a program to find all of its errors. We will show you that the answer is negative, even for trivial programs. In general, it is impractical, often impossible, to find all the errors in a program. This fundamental problem will, in turn, have implications for the economics of testing, assumptions that the tester will have to make about the program, and the manner in which test cases are designed.
To combat the challenges associated with testing economics, you should establish some strategies before beginning. Two of the most prevalent strategies include black-box testing and white-box testing, which we will explore in the next two sections.
Black-Box Testing
One important testing strategy is black-box testing (also known as data-driven or input/output-driven testing). To use this method, view the program as a black box. Your goal is to be completely unconcerned about the internal behavior and structure of the program. Instead, concentrate on finding circumstances in which the program does not behave according to its specifications.
In this approach, test data are derived solely from the specifications (i.e., without taking advantage of knowledge of the internal structure of the program).
If you want to use this approach to find all errors in the program, the criterion is exhaustive input testing, making use of every possible input condition as a test case. Why? If you tried three equilateral-triangle test cases for the triangle program, that in no way guarantees the correct detection of all equilateral triangles. The program could contain a special check for values 3842, 3842, 3842 and denote such a triangle as a scalene triangle. Since the program is a black box, the only way to be sure of detecting the presence of such a statement is by trying every input condition.
To test the triangle program exhaustively, you would have to create test cases for all valid triangles up to the maximum integer size of the development language. This in itself is an astronomical number of test cases, but it is in no way exhaustive: It would not find errors where the program said that −3, 4, 5 is a scalene triangle and that 2, A, 2 is an isosceles triangle. To be sure of finding all such errors, you have to test using not only all valid inputs, but all possible inputs. Hence, to test the triangle program exhaustively, you would have to produce virtually an infinite number of test cases, which, of course, is not possible.
If this sounds difficult, exhaustive input testing of larger programs is even more problematic. Consider attempting an exhaustive black-box test of a C++ compiler. Not only would you have to create test cases representing all valid C++ programs (again, virtually an infinite number), but you would have to create test cases for all invalid C++ programs (an infinite number) to ensure that the compiler detects them as being invalid. That is, the compiler has to be tested to ensure that it does not do what it is not supposed to do—for example, successfully compile a syntactically incorrect program.
The problem is even more onerous for transaction-base programs such as database applications. For example, in a database application such as an airline reservation system, the execution of a transaction (such as a database query or a reservation for a plane flight) is dependent upon what happened in previous transactions. Hence, not only would you have to try all unique valid and invalid transactions, but also all possible sequences of transactions.
This discussion shows that exhaustive input testing is impossible. Two important implications of this: (1) You cannot test a program to guarantee that it is error free; and (2) a fundamental consideration in program testing is one of economics. Thus, since exhaustive testing is out of the question, the objective should be to maximize the yield on the testing investment by maximizing the number of errors found by a finite number of test cases. Doing so will involve, among other things, being able to peer inside the program and make certain reasonable, but not airtight, assumptions about the program (e.g., if the triangle program detects 2, 2, 2 as an equilateral triangle, it seems reasonable that it will do the same for 3, 3, 3). This will form part of the test case design strategy in Chapter 4.
White-Box Testing
Another testing strategy, white-box (or logic-driven) testing, permits you to examine the internal structure of the program. This strategy derives test data from an examination of the program's logic (and often, unfortunately, at the neglect of the specification).
The goal at this point is to establish for this strategy the analog to exhaustive input testing in the black-box approach. Causing every statement in the program to execute at least once might appear to be the answer, but it is not difficult to show that this is highly inadequate. Without belaboring the point here, since this matter is discussed in greater depth in Chapter 4, the analog is usually considered to be exhaustive path testing. That is, if you execute, via test cases, all possible paths of control flow through the program, then possibly the program has been completely tested.
There are two flaws in this statement, however. One is that the number of unique logic paths through a program could be astronomically large. To see this, consider the trivial program represented in Figure 2.1. The diagram is a control-flow graph. Each node or circle represents a segment of statements that execute sequentially, possibly terminating with a branching statement. Each edge or arc represents a transfer of control (branch) between segments. The diagram, then, depicts a 10- to 20-statement program consisting of a DO loop that iterates up to 20 times. Within the body of the DO loop is a set of nested IF statements. Determining the number of unique logic paths is the same as determining the total number of unique ways of moving from point a to point b (assuming that all decisions in the program are independent from one another). This number is approximately 1014, or 100 trillion. It is computed from 520 + 519 +. . .51, where 5 is the number of paths through the loop body. Most people have a difficult time visualizing such a number, so consider it this way: If you could write, execute, and verify a test case every five minutes, it would take approximately 1 billion years to try every path. If you were 300 times faster, completing a test once per second, you could complete the job in 3.2 million years, give or take a few leap years and centuries.
Figure 2.1 Control-Flow Graph of a Small Program.
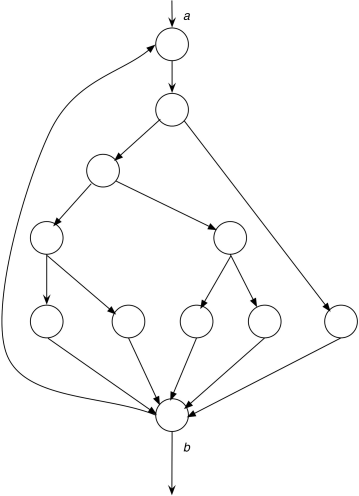
Of course, in actual programs every decision is not independent from every other decision, meaning that the number of possible execution paths would be somewhat fewer. On the other hand, actual programs are much larger than the simple program depicted in Figure 2.1. Hence, exhaustive path testing, like exhaustive input testing, appears to be impractical, if not impossible.
The second flaw in the statement “exhaustive path testing means a complete test” is that every path in a program could be tested, yet the program might still be loaded with errors. There are three explanations for this.
The first is that an exhaustive path test in no way guarantees that a program matches its specification. For example, if you were asked to write an ascending-order sorting routine but mistakenly produced a descending- order sorting routine, exhaustive path testing would be of little value; the program still has one bug: It is the wrong program, as it does not meet the specification.
Second, a program may be incorrect because of missing paths. Exhaustive path testing, of course, would not detect the absence of necessary paths.
Third, an exhaustive path test might not uncover data-sensitivity errors. There are many examples of such errors, but a simple one should suffice. Suppose that in a program you have to compare two numbers for convergence, that is, to see if the difference between the two numbers is less than some predetermined value. For example, you might write a Java IF statement as
![]()
Of course, the statement contains an error because it should compare c to the absolute value of a-b. Detection of this error, however, is dependent upon the values used for a and b and would not necessarily be detected by just executing every path through the program.
In conclusion, although exhaustive input testing is superior to exhaustive path testing, neither proves to be useful because both are infeasible. Perhaps, then, there are ways of combining elements of black-box and white-box testing to derive a reasonable, but not airtight, testing strategy. This matter is pursued further in Chapter 4.
Continuing with the major premise of this chapter, that the most important considerations in software testing are issues of psychology, we can identify a set of vital testing principles or guidelines. Most of these principles may seem obvious, yet they are all too often overlooked. Table 2.1 summarizes these important principles, and each is discussed in more detail in the paragraphs that follow.
Table 2.1 Vital Program Testing Guidelines
| Principle Number | Principle |
| 1 | A necessary part of a test case is a definition of the expected output or result. |
| 2 | A programmer should avoid attempting to test his or her own program. |
| 3 | A programming organization should not test its own programs. |
| 4 | Any testing process should include a thorough inspection of the results of each test. |
| 5 | Test cases must be written for input conditions that are invalid and unexpected, as well as for those that are valid and expected. |
| 6 | Examining a program to see if it does not do what it is supposed to do is only half the battle; the other half is seeing whether the program does what it is not supposed to do. |
| 7 | Avoid throwaway test cases unless the program is truly a throwaway program. |
| 8 | Do not plan a testing effort under the tacit assumption that no errors will be found. |
| 9 | The probability of the existence of more errors in a section of a program is proportional to the number of errors already found in that section. |
| 10 | Testing is an extremely creative and intellectually challenging task. |
Principle 1: A necessary part of a test case is a definition of the expected output or result.
This principle, though obvious, when overlooked is the cause of one of the most frequent mistakes in program testing. Again, it is something that is based on human psychology. If the expected result of a test case has not been predefined, chances are that a plausible, but erroneous, result will be interpreted as a correct result because of the phenomenon of “the eye seeing what it wants to see.” In other words, in spite of the proper destructive definition of testing, there is still a subconscious desire to see the correct result. One way of combating this is to encourage a detailed examination of all output by precisely spelling out, in advance, the expected output of the program. Therefore, a test case must consist of two components:
1. A description of the input data to the program.
2. A precise description of the correct output of the program for that set of input data.
A problem may be characterized as a fact or group of facts for which we have no acceptable explanation, that seem unusual, or that fail to fit in with our expectations or preconceptions. It should be obvious that some prior beliefs are required if anything is to appear problematic. If there are no expectations, there can be no surprises.
Principle 2: A programmer should avoid attempting to test his or her own program.
Any writer knows—or should know—that it's a bad idea to attempt to edit or proofread his or her own work. They know what the piece is supposed to say, hence may not recognize when it says otherwise. And they really don't want to find errors in their own work. The same applies to software authors.
Another problem arises with a change in focus on a software project. After a programmer has constructively designed and coded a program, it is extremely difficult to suddenly change perspective to look at the program with a destructive eye.
As many homeowners know, removing wallpaper (a destructive process) is not easy, but it is almost unbearably depressing if it was your hands that hung the paper in the first place. Similarly, most programmers cannot effectively test their own programs because they cannot bring themselves to shift mental gears to attempt to expose errors. Furthermore, a programmer may subconsciously avoid finding errors for fear of retribution from peers or a supervisor, a client, or the owner of the program or system being developed.
In addition to these psychological issues, there is a second significant problem: The program may contain errors due to the programmer's misunderstanding of the problem statement or specification. If this is the case, it is likely that the programmer will carry the same misunderstanding into tests of his or her own program.
This does not mean that it is impossible for a programmer to test his or her own program. Rather, it implies that testing is more effective and successful if someone else does it. However, as we will discuss in more detail in Chapter 3, developers can be valuable members of the testing team when the program specification and the program code itself are being evaluated.
Note that this argument does not apply to debugging (correcting known errors); debugging is more efficiently performed by the original programmer.
Principle 3: A programming organization should not test its own programs.
The argument here is similar to that made in the previous principle. A project or programming organization is, in many senses, a living organization with psychological problems similar to those of individual programmers. Furthermore, in most environments, a programming organization or a project manager is largely measured on the ability to produce a program by a given date and for a certain cost. One reason for this is that it is easy to measure time and cost objectives, whereas it is extremely difficult to quantify the reliability of a program. Therefore, it is difficult for a programming organization to be objective in testing its own programs, because the testing process, if approached with the proper definition, may be viewed as decreasing the probability of meeting the schedule and the cost objectives.
Again, this does not say that it is impossible for a programming organization to find some of its errors, because organizations do accomplish this with some degree of success. Rather, it implies that it is more economical for testing to be performed by an objective, independent party.
Principle 4: Any testing process should include a thorough inspection of the results of each test.
This is probably the most obvious principle, but again it is something that is often overlooked. We've seen numerous experiments that show many subjects failed to detect certain errors, even when symptoms of those errors were clearly observable on the output listings. Put another way, errors that are found in later tests were often missed in the results from earlier tests.
Principle 5: Test cases must be written for input conditions that are invalid and unexpected, as well as for those that are valid and expected.
There is a natural tendency when testing a program to concentrate on the valid and expected input conditions, to the neglect of the invalid and unexpected conditions. For instance, this tendency frequently appears in the testing of the triangle program in Chapter 1.
Few people, for instance, feed the program the numbers 1, 2, 5 to ensure that the program does not erroneously interpret this as an equalateral triangle instead of a scalene triangle. Also, many errors that are suddenly discovered in production software turn up when it is used in some new or unexpected way. It is hard, if not impossible, to define all the use cases for software testing. Therefore, test cases representing unexpected and invalid input conditions seem to have a higher error-detection yield than do test cases for valid input conditions.
Principle 6: Examining a program to see if it does not do what it is supposed to do is only half the battle; the other half is seeing whether the program does what it is not supposed to do.
This is a corollary to the previous principle. Programs must be examined for unwanted side effects. For instance, a payroll program that produces the correct paychecks is still an erroneous program if it also produces extra checks for nonexistent employees, or if it overwrites the first record of the personnel file.
Principle 7: Avoid throwaway test cases unless the program is truly a throwaway program.
This problem is seen most often with interactive systems to test programs. A common practice is to sit at a terminal and invent test cases on the fly, and then send these test cases through the program. The major issue is that test cases represent a valuable investment that, in this environment, disappears after the testing has been completed. Whenever the program has to be tested again (e.g., after correcting an error or making an improvement), the test cases must be reinvented. More often than not, since this reinvention requires a considerable amount of work, people tend to avoid it. Therefore, the retest of the program is rarely as rigorous as the original test, meaning that if the modification causes a previously functional part of the program to fail, this error often goes undetected. Saving test cases and running them again after changes to other components of the program is known as regression testing.
Principle 8: Do not plan a testing effort under the tacit assumption that no errors will be found.
This is a mistake project managers often make and is a sign of the use of the incorrect definition of testing—that is, the assumption that testing is the process of showing that the program functions correctly. Once again, the definition of testing is the process of executing a program with the intent of finding errors. And it should be obvious from our previous discussions that it is impossible to develop a program that is completely error free. Even after extensive testing and error correction, it is safe to assume that errors still exist; they simply have not yet been found.
Principle 9: The probability of the existence of more errors in a section of a program is proportional to the number of errors already found in that section.
This phenomenon is illustrated in Figure 2.2. At first glance this concept may seem nonsensical, but it is a phenomenon present in many programs. For instance, if a program consists of two modules, classes, or subroutines, A and B, and five errors have been found in module A, and only one error has been found in module B, and if module A has not been purposely subjected to a more rigorous test, then this principle tells us that the likelihood of more errors in module A is greater than the likelihood of more errors in module B.
Figure 2.2 The Surprising Relationship between Errors Remaining and Errors Found.
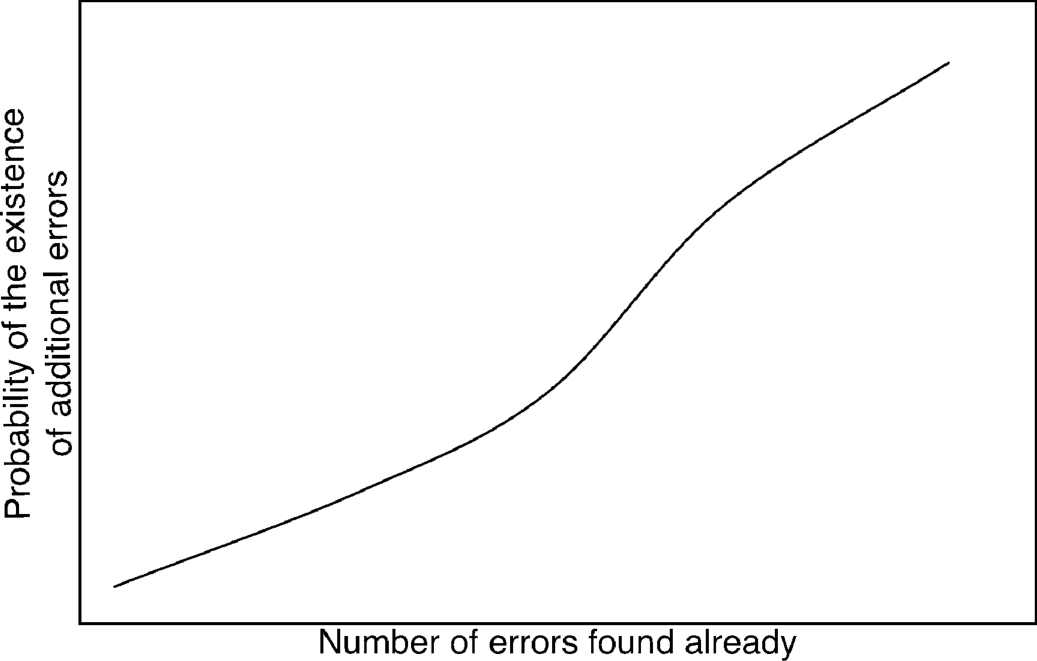
Another way of stating this principle is to say that errors tend to come in clusters and that, in the typical program, some sections seem to be much more prone to errors than other sections, although nobody has supplied a good explanation of why this occurs. The phenomenon is useful in that it gives us insight or feedback in the testing process. If a particular section of a program seems to be much more prone to errors than other sections, then this phenomenon tells us that, in terms of yield on our testing investment, additional testing efforts are best focused against this error-prone section.
Principle 10: Testing is an extremely creative and intellectually challenging task.
It is probably true that the creativity required in testing a large program exceeds the creativity required in designing that program. We already have seen that it is impossible to test a program sufficiently to guarantee the absence of all errors. Methodologies discussed later in this book help you develop a reasonable set of test cases for a program, but these methodologies still require a significant amount of creativity.
As you proceed through this book, keep in mind these important principles of testing:
- Testing is the process of executing a program with the intent of finding errors.
- Testing is more successful when not performed by the developer(s).
- A good test case is one that has a high probability of detecting an undiscovered error.
- A successful test case is one that detects an undiscovered error.
- Successful testing includes carefully defining expected output as well as input.
- Successful testing includes carefully studying test results.