
Chapter
15
Using Capybara to Test Ajax Web Applications
One of the most popular ways to use Cucumber is to automate the testing of web applications. Here is a dirty little secret:
Cucumber has no idea how to talk to a web application!
That’s right—it’s completely useless for that. Still, people keep using it to test web applications. How come?
Remember, Cucumber isn’t much more than a tool that can parse Gherkin feature files and execute step definitions. It doesn’t know how to talk to databases, web apps, or any external system. People install other libraries for this and use them in their step definitions and support code to connect to those external systems.
At the time of writing, the most popular Ruby library for interacting with a web application is Capybara.[60] It provides an API for accessing web pages and interacting with them in a way that is very similar to how a real user would—entering text in text fields and text areas, checking checkboxes, clicking links and buttons, and so on. Capybara allows you to plug in different drivers that run those interactions in several different ways—using a real browser like Firefox, IE, or Chrome, or a number of different browser simulators. In this chapter, you’ll learn how to use Capybara and when to use the various available drivers it provides.
Watir is the oldest web browser automation tool for Ruby. It was created in 2003 by Bret Pettichord. The original Watir supported only Internet Explorer, but the more recent Watir-WebDriver supports most mainstream web browsers.
Webrat was created in 2008 by Bryan Helkamp and is heavily inspired by Watir. Webrat introduced a browser simulator for quickly running tests and integrated with Selenium WebDriver for real browser tests.
Capybara was created in 2009 by Jonas Nicklas and is essentially an improved implementation of Webrat with a slightly simpler design and is more up-to-date with other frameworks and libraries.
We are not covering Watir or Webrat in this book because they are so similar to Capybara—and Capybara is the most widely used of those libraries.
Have you ever come to a website and thought: If only this site had a search function... Or worse:
They might as well remove this search field—it never finds what I’m looking for!
People have become so accustomed to search that they expect it to be in every system they use, and they expect it to actually find what they are looking for. In this chapter, we’ll explore Capybara’s most important features through the development of a search function for the Squeaker application we started in Chapter 14, Bootstrapping Rails. We won’t get into detail about advanced search engines, but you will get a good understanding about how to specify how a search function should work.
Let’s start by implementing a simple search that consists of a text field, a button, and a list underneath where the search results are displayed. The napkin sketch in the following figure shows what we want.
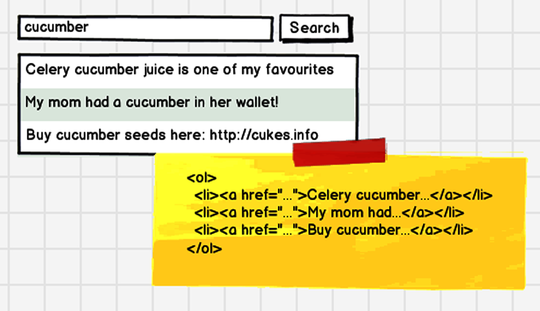
We’ll start off by implementing this feature without any Ajax. This will show you the basics of working with Capybara, using Capybara’s Rack driver to send commands directly to the Rails application. This works very similarly to the in-process approach we showed you in Chapter 12, Testing a REST Web Service, where we used the Rack-Test gem to send web requests to our web service running in the same process as our Cucumber tests (in fact, Capybara’s Rack driver uses Rack-Test under the hood). When that’s done, we’ll make our search more responsive using Ajax by switching to Capybara’s Selenium driver. You’ll see how Capybara makes it easy to run your tests against different browsers.